puppet系列(二)目录介绍以及资源详解
https://blog.51niux.com/?id=105 已经记录了puppet的工作原理、安装过程、命令、主要配置文件、目录结果以及证书认证过程,这篇文章主要以pupept的主机搭建以及资源详解为主。
一、puppet小集群部署
1.1 环境简述
master服务和CA认证服务:192.168.1.108(master.hadoop)
agent服务:192.168.1.111,192.168.1.112
1.2 时间同步(很重要,定时任务ntpdate定时向NTP服务进行时间同步)
1.3 防火墙设置
服务器端:
# iptables -I INPUT -p tcp -m tcp --dport 8140 -j ACCEPT
# iptables -I OUTPUT -p tcp -m tcp --sport 8140 -j ACCEPT
客户端:
#iptables -I INPUT -p tcp -m tcp --sport 8140 -j ACCEPT
#iptables -I OUTPUT -p tcp -m tcp --dport 8140 -j ACCEPT
1.4 服务器端的配置文件设置
第一步、puppet.conf的配置文件设置:
# cat /etc/puppet/puppet.conf
[main]
logdir = /var/log/puppet
rundir = /var/run/puppet
ssldir = $vardir/ssl
[master]
reportdir = /var/lib/puppet/reports
autosign = true
autosign = /etc/puppet/autosign.conf
bindaddress = 0.0.0.0
masterport = 8140
evaltrace = true
manifest = /etc/puppet/manifests/site.pp
modulepath = /etc/puppet/modules
certname = master.hadoop
第二步、创建/etc/puppet/manifests/site.pp
site.pp是puppet站点的导航文件,agent访问master的一切配置管理工作都由site.pp文件开始,它的作用是告诉master寻找并载入agent的配置信息。默认情况下site.pp文件会存放在/etc/puppet/manifests目录中,如果不存在,master是拒绝启动的。首次配置puppet的话,应先自行创建上述目录和文件。
如果/etc/puppet/manifests不存在就#mkdir /etc/puppet/manifests,如果site.pp不存在,就#touch /etc/puppet/manifests/site.pp
第三步、创建自动签名文件
# cat /etc/puppet/autosign.conf #*代表允许所有
*
1.5 客户端的设置
第一步:# vi /etc/hosts #如果我们没有自建dns服务器,可以在hosts里面指定,这也是常用的方式
192.168.1.108 master.hadoop
第二步:puppet.conf的配置文件设置:
# cat /etc/puppet/puppet.conf #runinterval尽量设置的大一点,因为我们一般客户端不会启服务,也不会采取定时任务执行的方式而是借助第三方工具
[main]
logdir = /var/log/puppet
rundir = /var/run/puppet
ssldir = $vardir/ssl
[agent]
certname = 192.168.1.111 #另一台192.168.1.112
daemonize = true
allow_duplicate_certs = true
report = true
report_server = master.hadoop
report_port = 8140
runinterval = 9000m
configtimeout = 2m
color = ansi
ignorecache = true
classfile = $vardir/classes.txt
ocalconfig = $vardir/localconfig
server = master.hadoop
第三步:跟服务器端进行证书认证
# puppet agent -t
博文来自:www.51niux.com
二、manifests和modules目录介绍
2.1 manifests目录介绍
manifests目录中存放了配置管理代码逻辑核site.pp入口文件,所有的agent访问master时都优先匹配到site.pp文件中的Node节点,节点与节点间有支持继承。
2.2 node节点介绍
master会通过facter工具获取agent的hostname,并通过hostname自动匹配site.pp文件中的node节点拉取配置信息,这就是node节点的作用。site.pp文件中可以设置一个node节点,也可以设置多个,它及支持正则表达式匹配,也支持node节点间继承,node节点功能灵活而又强大。
简单小例子:
# vi /etc/puppet/manifests/site.pp # 之前我们没有设置node节点,所有都可以授权,现在设置了node,也就只能指定的node节点才可以
node '192.168.1.111','slave2' { #定义了一个名字叫做192.168.1.111的节点。但是会优先把节点上传的hostname拿过来跟这里匹配,如果主机名跟这里匹配不上,这的节点名称是再跟puppet配置文件里面定义的certname进行匹配。所以一般agent端certname就是设置成主机名,也方便node的正则表达式匹配。
notify{ #这是一个notify资源
"Hello.The master.hadoop is hello you.": #这是最基本的消息通知,如果上面匹配成功了就输出这句话
}
}
下面是客户端测试的截图:
先看192.168.1.111的测试结果:
下图是我服务器端哪里的node设置为192.168.1.111,我客户端的certname设置为192.168.111,是匹配上的。
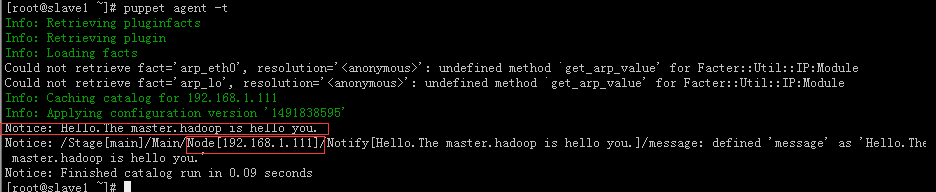
下图是我服务器端哪里的node设置为wokaka,我客户端的certname设置为wokaka的测试结果,结果也是匹配上的。

下图是我服务端那里的Node设置为192.168.1.111,我客户端的certname设置为wokaka的测试结果,结果是没有匹配上的。

再看下192.168.1.112的测试结果,如下图:
下图是我服务端那里的Node设置为slave2也就是192.168.1.112的主机名,我客户端的certname设置为192.168.1.112的测试结果,结果主机名匹配了。

总结:通过上述四张图,可以看出服务器端的node节点只与客户端的hostname或者是certname进行匹配。所以我们的certname与客户端的hostname最好保持一致,生产环境也是保持一致的,因为主机因为机房不同以及业务的不同,主机名都是不一致的,node哪里可以根据主机名做正则表达式的设置。
其中node为关键字是必须要加的,后面单引号里面是agent的hostname或者certname。大括号中可以通过include common的方式来加载模块。当agent访问master时会根据agent的hostname或certname自动匹配site.pp文件中的node节点信息,并通过系统提供的include函数加载common类文件。多个类之间即可以写成include 类名称 写多行的形式,也可以写成include 多类之间用逗号隔开的形式如include common,squid。
多node如果要写在一行可以用逗号隔开,node节点还支持正则表达式的方式管理站点。这个后面会写到。
当然实际生产环境中,我们的site.pp文件里面没有这么多东西的,node的配置都是分散出去的后面也会写到。
2.3 modules目录介绍
modules目录又称基础模块目录,它由不同的目录和class类文件组成,这些目录和文件是完成一个任务的子集,最终最后通过manifests串联modules中的这些子集来完成一个完整任务,这就是基础模块的作用。获取modules基础模块的方式有两种,一种是从官方获取基础模块,另一种是子集开发基础模块。
标准的modules基础模块目录包含6个目录,分别是manifests、files、templates、lib、tests和spec。
在modules目录下面是基础模块的名字,如my_module,在此目录的下方有6个目录:
manifests:存放基础模块的类文件和资源等。
files:存放基础模块的配置文件,目录中配置文件可以通过puppet文件协议下载到agent上。
lib:存放puppet的插件、自定义函数、Provider和库文件等。
templatest:存放ERB模板文件
tests:存放puppet基础模块类测试的用例文件。
spec:存放测试文件和插件库文件。
puppet forge是一个免费的modules基础模块仓库,无需独立开发基础模块,直接从官方网站上获取想要的基础模块。一种是在官方网页搜索基础模块,另一种方式是通过puppet提供的puppet module工具命令来搜索和安装基础模块。
三、资源介绍
# puppet describe -l #可以查看puppet自带了哪些资源可以使用
资源的分类:
常用资源:file,filebucket、group、exec、host、notify、cron、service、user和package。
次常用资源:augeas、computer、interface、maillist、mailalias、mcx、router、schedule、scheduled_task、ssh_authorized_key、sshkey、zpool、yumrepo、zfs、zone、macauthori-zation、resources、selmodule、k5login、mount、selboolean、stage、tidy和vlan。
nagios资源:主要管理nagios监控工具,nagios是一款开源免费的监控工具。
3.1 file资源介绍
管理文件,包括其内容,所有权和权限。“文件”类型可以管理正常的文件,目录和符号链接; 该类型应在`ensure`属性中指定。文件内容可以直接使用`content`属性或
使用`source`属性从远程源下载; 后者也可以用于递归地服务目录(当`recurse`属性设置为`true`或`local``时)。
# puppet describe file #可以查看file资源的参数选项及如何使用
属性:
backup: 决定文件的内容再被修改前是否进行备份。目前puppet支持两种备份方式,一种是将文件备份再agent上被修改的目录中,如果设置为以`.`开头的字符串(例如,`.puppet-bak`),Puppet
将 使用该值将该文件复制在同一目录中,备份文件的文件名就是"."后面的字符串。另一种将源文件通过filebucket备份到远程服务器上,这就需要借助filebucket资源。如果设置为`false`,则不会备份文件内容。
checksum:检查文件内容是否被修改过,通过它可以检查文件的一致性。有几种检查方式,包括md5、mtime和ctime等,默认用md5进行检查。
content:可以向文件中追加内容或者通过调用template函数向ERB模板中追加内容。
ctime:一个只读状态来检查文件ctime。 这是最近更改文件的所有者,组,权限或内容的时间。
ensure:文件是否应该存在。如果是,应该是什么样的文件,可能的值是五个。present值表示匹配文件,它会检查path值中的路径文件是否存在,如果不存在就创建新文件。absent值表示删除path值中的已经存在的文件。file值表示创建文件。directory值表示创建目录但是如果删除目录的话,需要额外增加force=>true属性和值。link值会根据path路径创建文件的软连接,通过target属性后接软连接的路径。
force:执行文件操作,即使它会破坏一个或多个目录。用文件或链接替换目录,当ensure=>absent时删除目录有效值为true,false,yes,no.其中true与yes在这里表示创建目录链接,false与no表示不创建目录链接。
group:指定改文件的用户组,值可以是组的gid或系统组名。
ignore:在递归期间省略与匹配指定模式的文件的操作的参数。 使用Ruby的内置globbing引擎,所以shell元字符完全支持,例如 `[a-z] *`。 将下降到目录结构中的匹配将被忽略,例如`* / *`。
links:定义操作符合链接的文件,可以设置的值是follow和manage。follow表示文件复制时,会复制文件的内容,而不是只复制符合链接本身。manage值,则会复制符合链接本身。
mode:用于设置文件的权限。以符号或数字形式符号。
mtime:只读状态来检查文件mtime。这是文件内容最近更改的时间。
owner:设置文件的属主。
path:指定要管理文件或目录的路径。 必须用双引号引起来,通常path也等于资源的标题。
purge : 是否应清除非托管文件。 当`ensure => directory`和`recurse => true`时,这个选项才有意义。 *当使用`source`属性递归复制整个目录时,`purge => true`会自动清除任何文件那不在源目录中。 *当以个别资源管理目录中的文件时,设置`purge => true将清除任何未被特别管理的文件。 如果你有一个filebucket配置,清除的文件将被上传,但如果不这样做,这将会破坏数据。无论如何设置`force => true`,清除将不会**删除目录,尽管它会删除 它们包含的文件。 如果“recurselimit”被设置,并且没有使用`force => true`,则清除将遵循递归限制; 任何深度超过限制的文件将被视为非托管,并保留.Valid值为“true”,“false”,“yes”,“no”。
recurse : 是否递归地管理目录.此属性仅在设置了`ensure =>directory'时使用。默认情况下,将recurse设置为`remote`或`true`将会管理_all_子目录。您可以使用`recurselimit`属性来限制递归深度.Valid值为`true`,`false`,`inf`,`remote`。
recurselimit : 当使用`ensure =>directory',`recurse => true``或`recurse => remote`.当`purge => true`时可以清除哪些文件。 设置`recurselimit => 0`与设置`recurse => false`相同.设置`recurselimit => 1`将管理目录中的文件和目录,但不管理任何子目录的内容。设置`recurselimit => 2`将管理目录的直接内容以及_first_级子目录的内容。 3将管理第二级子目录的内容,等等。值可以匹配`/ ^ [0-9] + $ /`。
replace : 是否替换本地系统上已经存在的内容不符合“source”或“content”属性指定的文件或符号链接。 将此设置为false允许文件资源初始化文件,而不会覆盖未来的更改。 请注意,这仅影响内容; Puppet仍然会管理所有权和权限。 默认为“true”。 有效值为“true”,“false”,“yes”,“no”。
selinux_ignore_defaults:selinux系统功能,实现自定义selinux。
selrange:文件上下文的SELinux范围组件应该是什么。
selrole:文件上下文的SELinux角色组件应该是什么。
seltype:文件上下文的SELinux类型组件应该是什么。
seluser:文件上下文的SELinux用户组件应该是什么。
show_diff:是否在文件更改时显示差异,默认为true。 此参数对于可能包含密码或其他秘密数据的文件很有用,否则可能会包含在Puppet报告或其他不安全输出中。 如果全局`show_diff`设置为false,那么即使该参数为true,也不会显示diff。 有效值为“true”,“false”,“yes”,“no”。
source:源文件将被复制到本地系统上。值可以是指向远程文件的URI或完全限定的路径 本地系统上可用的文件(包括NFS共享或 Windows映射驱动器)。
source_permissions:puppet是否(以及如何)应该从中复制所有者,组和模式权限当没有明确指定权限时,`source`到`file`资源。 (在所有情况下,显式权限都将优先。)有效值`use`,`use_when_creating`和`ignore`.`use`(默认值)将导致Puppet将所有者,组和模式从`source`给它管理的任何文件。`use_when_creating`只会在创建文件时从`source'应用所有者,组和模式;现有文件将不会覆盖其权限。`ignore`将永远不会在管理文件时从`source'应用所有者,组或模式。在没有显式权限的情况下创建新文件时,他们收到的权限将取决于平台特定的行为。
sourceselect : 是否复制所有有效的资料,或只是第一个。 此参数仅影响递归目录副本; 默认情况下,第一个有效的源是唯一使用的源,但如果此参数设置为“all”,则所有有效的源将其所有内容复制到本地系统。 如果给定的文件存在于多个源中,则将使用列表中最早的源的版本。 有效值为“first”,“all”。
target : 指定创建软连接的目录。
type:用于检查文件类型的只读状态。
3.2 filebucket资源介绍
在很多场景中file与filebucket资源会一起使用,filebucket资源主要用于文件的备份与恢复,它通常与file资源配合使用。
# puppet describe filebucket
属性:
name:filebucket的名称。
path:服务器备份数据路径。
port : 备份服务器的端口。
server : 备份服务的域名。
3.3 group资源介绍
管理系统组的资源。group资源的主要功能是管理系统组,包含组的名字、增减/删除组、组成员、组的gid等。
属性:
allowdupe:是否允许系统存在同样账户的gid。 默认为“false”。有效值为“true”,“false”,“yes”,“no”。
attribute_membership:是否应将指定的属性值对对待为用户的唯一属性,还是应将其视为最小列表。 有效值为“inclusive”,“minimum”。
attributes:在“key = value”对的数组中指定组AIX属性。 需要功能manage_aix_lam。
auth_membership : 供应商是否具有组织成员资格的权威性。 这必须设置为true,以允许将组设置为不具有`members => []的成员,`.Valid值“true”,“false”,“yes”,“no”。
ensure:创建或者删除组,设置absent为删除组,设置present为创建组。
forcelocal:当帐户也被其他NSS管理时,强制管理本地帐户有效值为“true”,“false”,“yes”,“no”。 需要功能libuser。
gid:设置组的gid,必须是数字,如果不指定,将自动分配,不同系统自动分配的算法不一样,还是不要自动分配gid的好。
members:该组的成员。
name:该用户组的名称,默认与标题相同。
3.4 exec资源介绍
exec资源的功能是调用unix系统命令,完成系统管理的基础操作。
属性:
command:执行的实际命令。 必须绝对路径或必须提供命令的搜索路径。 如果命令成功,则会在实例的正常日志级别(通常为`notice`)中记录任何产生的输出,但如果命令失败(意味着其返回代码与指定的代码不匹配),那么任何输出都将记录在`err `日志级别。
creates:此参数会创建一个临时文件,当次临时文件不存在时exec调用系统命令才会执行成功,防止出现同一时刻多次执行的情况。
cwd : 运行命令的目录。 如果此目录不存在,则该命令将失败。
environment : 要为命令设置的任何其他环境变量。 请注意,如果您使用它设置PATH,它将覆盖系统的环境变量。 添加多个环境变量需要使用数组指定。
group : 执行命令运行的账户组。
logoutput : 决定是否记录输出日志信息。默认会根据exec资源的日志登记来记录输出信息,使用on_failure时只有命令执行有误的情况下才会记录输出信息。值可以为true、false、on_failure和任何合法的日志等级。
onlyif:如果这个参数被设置,那么这个`exec`只有在命令的退出代码为0的情况下才会运行。
path: 用于命令执行的搜索路径。 如果没有指定路径,则命令必须填写完整路径。 可以将路径指定为数组或“:”分隔列表。
refresh:刷新命令执行状态。 默认情况下,当它从另一个资源接收到一个事件时,再次调用exec,但是该参数允许您定义一个不同的刷新命令。
refreshonly:该命令只能作为刷新机制运行,当依赖的对象改变时命令才会执行。当下发的配置文件发送变更时,exec通过subscribe和refreshonly监听到依赖文件的状态,则触发exec资源的执行。
returns:预期退出代码。如果执行的命令有其他退出代码,将返回错误。默认为0.可以指定为可接受的退出代码或单个值的数组。
timeout:命令应该占用的最长时间。 如果命令所花费的时间超过了超时时间,则该命令被认为已经失败并将被停止。 超时时间以秒为单位。 默认超时为300秒,您可以将其设置为0以禁用超时。
tries : 应该尝试执行命令的次数。 默认为“1”。设置这个值以后命令会重试设置的次数直到正确的代码返回。请注意,超时参数适用于每次尝试,而不适用于完整的尝试集。
try_sleep:设置命令重试的时间间隔,单位是秒。
umask : 设置在执行此命令时使用的umask.
unless : 如果设置了这个参数,那么这个`exec`将会运行,除非该命令的退出代码为0.
user : 指定执行命令的用户名。
3.5 host资源介绍
host资源主要用来管理操作系统的hosts功能,就是操作/etc/hosts的配置文件
属性:
comment:将附加到带有#个字符的行的注释。
ensure:资源应该在的基本属性.有效值为`present`,`absent`。
host_aliases:主机可能有任何别名。 多个值必须指定为数组。
ip:主机的IP地址,IPv4或IPv6。
name : 主机名。
target:存储服务信息的文件。 仅供写入磁盘的提供者使用。 在大多数系统上,它默认为`/ etc / hosts'。
3.6 notify资源介绍
向客户端运行时日志发送任意消息。简单说就是向puppet发送一些我们事先定义好的信息。
属性:
message:要发送到日志的消息。
name : 消息的名称。
withpath : 是否显示完整的对象路径。 默认为false。有效值为“true”,“false”。
3.7 cron资源介绍
cron资源主要用来管理操作系统的定时任务。时间周期属性为:(hour, minute,month, monthday, weekday, or special)
属性:
command:在cron作业中执行的命令。因为系统环境有差异,最好是绝对路径。
ensure:此crontab设置是否启用的设置,有效值是`present`,`absent`。
environment:与此cron作业相关联的任何环境设置。 它们将被存储在头部和crontab中的作业之间。 不能保证其他较早的设置不会影响给定的cron作业。 此外,Puppet不能自动确定现有的非托管环境设置是否与给定的cron作业相关联。 如果您已经具有环境设置的cron作业,那么Puppet将把这些设置保存在文件的相同位置,但不会将它们与特定的作业相关联。 应该正确设置设置,就像它们应该出现在crontab中一样,例如`PATH = / bin:/ usr / bin:/ usr / sbin`。
hour:运行cron工作的时间,单位是时。可选;如果指定,必须介于0和23之间(含)。
minute:运行cron作业的时刻,单位是分。可选的; 如果指定,必须介于0和59之间(含)。
month:一年中的一个月。可选的,单位是月; 如果指定必须在1到12之间或月份名称(例如,12月)。
monthday:运行命令的月份的日期。 可选的; 如果指定,必须介于1到31之间。
weekday:运行命令的工作日。可选; 如果指定,必须介于0和7之间,包括0和7(星期日)
name:此次cron作业的名称,也就是给此次作业添加一个注释。
special :一个特殊的价值,如“重新启动”或“每年”。 仅在受支持的系统(例如Vixie Cron)上可用。更改日期/周的更多特定时间设置。设置为“absent”以使puppet恢复为简单的数字计划。
target:应该存储cron作业的crontab文件的名称。此属性默认为“user”属性的值,如果设置,则运行Puppet或“root”的用户。对于默认的crontab提供程序,此属性在功能上相当于 到`user`属性,应该避免。 特别地,将`user`和`target`设置为不同的值会导致未定义的行为。
user:指定此cron写入到哪个用户的crontab文件里,默认是运行puppet程序的用户或者'root'的用户。
3.8 service资源介绍
通过service资源不但可以启动、重启和关闭程序的守护进程,监控进程状态,还可以将守护进程加入自动启动中。
binary:守护进程的路径。 这仅适用于不支持init脚本的系统。如果守护进程没有自启动脚本,可以通过此属性启动服务。
control:用于管理服务的控制变量。对于支持“可控”功能的提供者,默认为升级的服务名称加上“START”替换带有下划线的点。
enable:指定服务在开机的时候是否启动,可以设置true和false。
ensure:一个服务是否应该运行 有效值为“stopped”(也称为“false”),“running”(也称为“true”)。
flags:指定要传递给启动脚本的标志字符串。需要功能标记。
hasrestart:指出管理脚本是否支持restart值。如果不支持就用stop值和start值来实现restart效果。默认值为false .有效值为“true”,“false”。
hasstatus: 如果服务正在运行,init脚本的status命令必须返回0,否则返回非零值。 如果一个服务的init脚本不支持任何类型的status命令,你应该将`hasstatus`设置为false。
manifest:指定配置服务的命令或清单的路径。
name:守护进程服务的名称。
path:init启动脚本的搜索路径,可以用冒号分隔多个路径,或者用数组指定。
pattern:在进程表中搜索的模式。 这用于在不支持init脚本的平台上停止服务,并且还用于确定其init脚本中不包含status命令的那些服务的服务状态。 默认为服务的名称。 该模式可以是一个简单的字符串或任何合法的Ruby模式,包括正则表达式(应该引用没有包围的斜杠)。
restart:手动指定restart命令。 如果未指定,只能手工的停止服务,然后启动。
start:手动指定start 命令。 大多数服务子系统支持start命令,所以这不需要手工指定。
status :手动指定status命令。 如果服务正在运行,则该命令必须返回0,否则返回非零值。如果不指定,就从进程列表查询该服务。
stop:指定停止服务的脚本。
3.9 user资源介绍
user资源主要用来管理操作系统的账号,如账号的增加/删除、账号uid/gid的管理、shell的解析器、宿主目录的设置和账户密码的设置。
属性:
allowdupe:是否允许重复的UID。 默认为“false”。 有效值为“true”,“false”,“yes”,“no”。
attribute_membership:指定的属性值对是否应被视为用户的属性/值对的完整列表(inclusive)或最小列表(minimum)。 默认值为“minimum”.
attributes : 在attribute = value对的数组中为用户指定AIX属性。需要功能zones_aix_lam.
auth_membership : 指定的认证是否应被视为用户拥有的完整列表(`inclusive`)或最小列表(minimum)。 默认值为“minimum”.
auths : 用户的认证。 多个认证应该被指定为一个数组。需要的功能是manage_solaris_rbac。
comment : 用户说明.一般用户的全名。
ensure : 设置账户的增加和删除,可以设置为present值表示增加账户,设置为absent值表示删除账户。
expiry:此用户的到期日期。 必须以零填充的YYYY-MM-DD格式提供 - 例如。 2010-02-19。 如果要确保用户帐户永远不会过期,您可以传递特殊值absent。值可以匹配`/ ^ \ d {4} - \ d {2} - \ d {2} $ /`。 需要功能manage_expiry。
forcelocal : 当帐户也被其他NSS管理时,强制管理本地帐户有效值为“true”,“false”,“yes”,“no”。 需要功能libuser。
gid : 系统账户的gid可以用数字或者组名称。
groups:用户所属的组。 主组不必在这里列出,群体应以名称而不是GID来标识。 多个组应指定为数组如'[test1]','[test2]'。
home:系统账户的宿主目录。注意这个目录需要提前通过mkdir系统命令创建。
key_membership:指定的键/值对是否应被视为用户属性的完整列表(`inclusive`)或最小列表(最小值)。 默认值为“minimum”.
keys:在key = value对的数组中指定用户属性。需要的功能是manage_solaris_rbac。
managehome:是否在管理用户时管理主目录。 当`ensure => present`时,这将创建主目录,当`ensure => absent`时删除主目录。 默认为“false”。 有效值为“true”,“false”,“yes”,“no”。
membership:指定的组是否应被视为用户所属的组的完整列表(`inclusive`)或最小列表(minimum)。 默认值为“minimum”.
name:创建系统用户名,这里建议用户名长度小于8,并以字母开头。
password : 系统账户的密码,具体用什么加密方式由操作系统决定。需manage_passwords特性,如果密码里面带有$符号,需要用单引号引起来。
password_max_age:密码过期的期限。需要的功能是manage_password_age。
password_min_age:密码必须使用的最短天数才能更改。需要的功能是manage_password_age。
profile_membership:指定角色是否应被视为用户所属角色的完整列表(`inclusive`)或最小列表(minimum)。 默认为“minimum”。
profiles:用户拥有的配置文件。 多个配置文件应该被指定为一个数组。需要的功能管理solaris rbac。
project:与用户关联的项目的名称。需要功能manage_solaris_rbac。
purge_ssh_keys:是否清除此用户的授权SSH密钥,如果它们不使用`ssh_authorized_key`资源类型进行管理。 允许的值是:`false`(默认),不要清除此用户的SSH密钥。`true`是在用户主目录中的`.ssh / authorized_keys`文件中查找密钥。 清除任何未作为`ssh_authorized_key`资源管理的密钥。
role_membership:指定的角色是否应被视为完整列表(`inclusive`)或最小列表(`minimum`)的用户角色 具有。 默认为“minimum”。
roles:用户拥有的角色 多个角色应该被指定为一个数组。需要的功能管理solaris rbac。
shell : 用户的登录shell。 shell必须存在且可执行。该属性无法在Windows系统上进行管理。 需要功能manage_shell。
system : 用户是否是系统用户,根据操作系统的标准; 在大多数平台上,UID小于或等于500表示系统用户。 此参数仅在创建资源时使用,并且在用户存在时不会影响UID。 默认为“false”。 有效值为“true”,“false”,“yes”,“no”。
uid : 系统账户的uid必须设置成数字,如果不设置此属性系统将会自动分配账户。
3.10 package资源介绍
package资源可以借助本地包管理系统帮我们安装软件,也可以通过参数指定软件包来安装。
属性:
allow_virtual:指定是否允许虚拟包名称进行安装和卸载.有效值为“true”,“false”,“yes”,“no”。 需要功能virtual_packages。
allowcdrom:通知apt允许使用cdrom作为软件源,可以设置成false或者true.
category:由包设置的只读参数。
description:描述软件包,软件包设置的一个只读属性。
ensure:设置软件包的安装状态。installed值或present值均表示安装软件包,其最终结果是一致的。absent值表示卸载软件包;pureged值表示移除软件包;latest表示安装软件包最新的软件包。
install_options:安装软件包时要传递的一系列附加选项。指定安装软件包的相关参数。
name:安装包的名称。
package_settings:可以更改包的内容或配置的设置。package_settings的格式和效果是提供者特定的; 任何实现它们的提供者必须解释如何在其文档中使用它们。 (我们的一般期望是,如果安装了软件包,但其设置不同步,则提供程序应重新安装该软件包并进行所需的设置。)
source:指定软件包的安装源,如rpm包的URL地址或本地路径等。
uninstall_options:卸载软件包,指定卸载软件包的相关参数。
四、资源示例
# cat manifests/site.pp #首先我们再site.pp这个入口文件里面指定,我们要去哪里找配置文件。
import "nodes/*.pp" #import函数可以导入manifests目录中的一个文件如:import 'nodes/common.pp',当然多个文件就以*表示了。
# mkdir manifests/nodes #创建此目录,这个目录是创建不同的主机匹配.pp文件允许那些主机进行匹配
4.1 file资源示例
# cat manifests/nodes/test.pp
node /192.168.1.\d+$/{ #这是匹配node节点,允许192.168.1.数字的节点进行匹配,这里用到了正则表达式的匹配方式,生产也是主机名正则表达式的匹配方式。
include filetest1 #加载filetest1模块
}
# mkdir modules/filetest1/{files,manifests,templates} -p #创建filetest1模块的相关目录,上面关于modules目录以及子目录的结构已经做了说明,这样比较标准点。
# cat /etc/puppet/modules/filetest1/manifests/init.pp #init.pp文件是puppet基础模块的默认加载文件,在这里可以通过include函数引用类。
class filetest1 { #这就是定义了一个filetest1类,因为我们test.pp里面已经include引用了这个类
include filetest1::file1 #这是表示filetest1这个大类下面有哪些子类,也是为了可以加载多个子类和类的继承做准备。
}
示例1:创建/opt/file1文件
# cat /etc/puppet/modules/filetest1/manifests/file1.pp #这个就是以子类名称命名的pp文件
class filetest1::file1{ #先定义了这个子类的名称
file {'/opt/file1': #这是这个类的标题,一般file类的标题都是以要操作的文件来或目录名称来命名的。资源标题用单引号或者双引号引起来,同时标题中不能包含空格和连字符。
ensure => present, #这表示创建操作,资源中所有的属性与值需要以=>符号为准,所以要像这样尽量对齐。而且ensure此属性尽量写在首部
owner => 'root', #文件的属主是root
group => 'root', #文件的属组是root
mode => '0644', #文件权限是644,这里应该是由四位数字构成,而非3位。并且权限要通过单引号引起来。
}
}
客户端的操作截图:
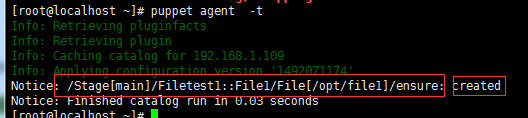
# cd /var/lib/puppet/client_data/catalog/ #进入客户端的catalog目录
# ll #查看一下发现产生了一个json文件
total 4
-rw-rw----. 1 root root 1522 Apr 13 16:12 192.168.1.109.json
# cat 192.168.1.109.json #查看下json文件,你会发现内容就是我们要做的操作
示例2:向文件追加内容。
# cat file2_content.pp #这里是又创建了一个类名称相同的.pp文件
class filetest1::file2_content { #为啥是file2而不是file1了呢,当然这个名称主要是为了有点标志性,这里就是说明是对file2文件的操作。
file {'file2': #这里是标题,是不能跟其他的重复的,就算这里只是指定文件名称,用path来指定全路径,也是不可以的,不然就会提示你已经存在这个别名了。
ensure => present, #加上这个参数,就算没有这个文件,也是会创建并添加内容的。
content => "666 yiqilai", #content后面用“”,在双引号里面写入我们要添加的内容。
path => '/opt/file2' , #这里要注意,如果不指定文件名的话,就会被理解为是一个目录,只有加了文件名才会认为指定的是文件,通常path也等于资源的标题
}
# cat init.pp #因为我们又多了一个子类filetest1::file2_content,所以要在这里添加一下,后面我就不贴这个文件了,有新的子类就在这里包含一下。
class filetest1 {
include filetest1::file1,filetest1::file2_content
}
当然content一般不像上面那么用,太浪费了,一般会跟模板template一起使用。
# cat /etc/puppet/modules/filetest1/templates/puppet.conf.erb #我们拿puppet.conf模板举例,模板都是.erb结尾哈
[main]
logdir = /var/log/puppet
rundir = /var/run/puppet
ssldir = $vardir/ssl
[agent]
classfile = $vardir/classes.txt
localconfig = $vardir/localconfig
daemonize = true
allow_duplicate_certs = true
report = true
reports = store,http
report_server = master.puppet
report_port = 8140
runinterval = 9999m
splay = true
splaylimit = 10m
configtimeout = 2m
color = ansi
report_server = <%= scope.lookupvar('filetest1::puppet::puppetserver') %> #这三个就是变量了
certname = <%= scope.lookupvar('filetest1::puppet::certname') %>
server = <%= scope.lookupvar('filetest1::puppet::puppetserver') %>
environment = production
# cat /etc/puppet/modules/filetest1/manifests/puppet_config.pp #这是我们要更改文件内容的类文件
class filetest1::puppet_config {
include filetest1::puppet_params #这里还调用了另一个类
file {'/opt/puppet.conf':
ensure => present,
content => template('filetest1/puppet.conf.erb'), #括号里面指的是哪个模块下面的哪个模板文件
}
}
# cat /etc/puppet/modules/filetest1/manifests/puppet_params.pp #这是上面哪个引用的类的文件
class filetest1::puppet_params { #定义了三个变量被引用
$puppetserver = 'master.puppet'
$certname = "${::fqdn}"
$report_server= 'master.puppet'
}
下面是客户端的测试结果(服务端不要忘记把定义的哪两个类加到init.pp文件中引用起来哦):

示例3、file传输文件
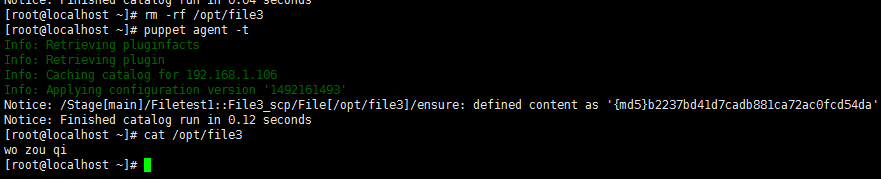
# cat file3_scp.pp #这里写了一个简单的文件传输类文件
class filetest1::file3_scp {
file {'/opt/file3': #要复制到客户端的文件位置是:/opt/file3'
source => "puppet://master.puppet/filetest1/file3", #客户端下载文件的链接。我们一般在文件传输的时候会采取搭建一个文件共享服务器来负责文件的传输,不过一些小的配置文件可以这样进行传输
}
}
# cat /etc/puppet/fileserver.conf #上面的source链接就是这里定义的
[filetest1] #filetest1就是puppet://master.puppet/filetest1/file3里的fitest1,master.puppet就是puppet在客户端设置的server名称,file3就是我们要传送的文件名
path /etc/puppet/modules/filetest1/files #这里就是filetest1指定的实际路径,就像samba的那种设置。
allow /192.168.1.\d+/ #模式auth认证模式是开启的,这里就是允许所有certname或者主机名是192.168.1.数字的主机可以来访问此目录。不过一般设置为allow *。
下面是客户端的操作:
示例4,file创建多级目录
上面写的pp文件过于简陋了,我们不可能什么都直接放到/opt或者/tmp这种目录下面,一般我们都是要放到一个二级三级目录下面,比如我们想传一个脚本过去,肯定不能直接的丢到/opt目录下面,所以呢,一般应该是先把目录创建好,然后把文件丢过去。这样会规范一点。
# cat /etc/puppet/modules/filetest1/manifests/file3_scp.pp
class filetest1::file3_scp {
file {["/opt/test2/","/opt/test2/test2"]: #file的递归参数是在传输目录的时候和清空目录的时候才是有效的,在创建目录的时候无效,所以要用数组的形式。
ensure => directory,
}
file {'/opt/test2/test2/file3':
source => "puppet://master.puppet/filetest1/file3",
}
}
客户端测试结果是OK的,这样,我们就可以将我们的文件传输到指定的目录中去,并且可以把控目录的深度。
示例5, file创建软链接的操作
#cat /etc/puppet/modules/filetest1/manifests/file1_link.pp
class filetest1::file1_link{
file{'/tmp/file1': #这是是链接文件或者目录的位置。这是文件还是目录是取决于源目录是文件还是目录。
ensure => link, #指定是链接形式
target => '/opt/file1', #这是是链接的源目录或者文件。
}
}
客户端测试是没有问题的:lrwxrwxrwx 1 root root 10 Apr 15 10:54 /tmp/file1 -> /opt/file1
4.2 group资源示例
# cat /etc/puppet/modules/grouptest1/manifests/zabbix_add.pp
class grouptest1::zabbix_add{
group {'zabbix': #这里标题是zabbix,就代表我们创建的是zabbix组
ensure => "present", #present就是表示创建此组,absent为删除此组
gid => 2530, #如果加了gid,当客户端有此组的时候会强制更改为指定的gid号,如果没有指定的话,如果客户端没有此组那么gid是随机的,有的话也不会去替换gid号。
}
}
#当然如果要删除用户组用ensure => “absent",当然一般要配合着user资源来用,因为如果你这组下面有属主用户的话,是不能将组删除掉的。
4.3 exec资源示例
示例1:将iptables服务关闭,并将iptables设置为开机不启动。
# cat /etc/puppet/modules/exectest1/manifests/iptables_off.pp
class exectest1::iptables_off{
exec { ["service iptables stop","chkconfig iptables off",]: #要执行多命令用数组的形式,这里就相当于common里面制定命令。
path => ["/usr/bin","/usr/sbin","/bin","/sbin"], #如果这里不指定path,也就是命令的搜索路径,全面的操作就要用绝对路径了。
}
}
示例2:客户端下载脚本,并在客户端执行。
# cat /etc/puppet/modules/exectest1/manifests/bash_test.pp #简单的操作exec里面的command就可以解决了,因为环境的复杂度,一般比较复杂的操作我会采取将执行脚本分发到客户端,然后让客户端执行操作的方式。
class exectest1::bash_test{
file {'/opt/test.sh': #一般脚本会分发到我们指定的目录
source => "puppet://master.hadoop/exectest1/test.sh",
}
exec {'test': #这里就只是一个标题的作用
command => 'bash /opt/test.sh', #这里是我们要执行的操作,我们来运行脚本
path => ["/usr/bin","/usr/sbin","/bin","/sbin"],
timeout => '10', #执行的超时时间,默认是300秒,可以让其时间变小点
}
}
4.4 host资源介绍
示例1:向/etc/hosts里面添加域名解析:
# cat /etc/puppet/modules/hosttest1/manifests/host_add.pp
class hosttest1::host_add{
host{'test.puppet.com': #要添加的域名,如果是多域名可用数组[‘域名1’,‘域名2’]:来添加多域名
ensure => present, #默认就是present,可不加,有一点要注意,absent是将这个域名从/etc/hosts里面删除而不是注释。
ip => '192.168.1.200', #要解析的IP
comment => '192.168.1.200', #这是在我们添加的这个解析后面添加注释,一般不用加这句话。
}
示例2:将/etc/hosts里面的某个解析修改掉:
# cat /etc/puppet/modules/hosttest1/manifests/host_update.pp
class hosttest1::host_update{
host{'slave7.hadoop': #其实还是上面添加的另一种,加不加ensure参数都没关系,如果此解析不存在就添加,如果存在就将IP改为下面的IP。
#ensure => present,
#host_aliases => ['puppet','puppet1'], #这里为什么注释掉呢,因为host_aliases和name跟上面的域名是不能共用的,如果他们出现,上面的域名就失去作用了,这里就是类似于127.0.0.1 后面跟localhost localhost.localdomain 一样的效果,会同时有多个空行隔开的别名。
# name => 'test4', #name跟上面的别名如果同时出现,会写在同一行。
ip => '192.168.1.113'
}
}
4.5 notify资源介绍
# cat /etc/puppet/modules/notifytest1/manifests/notify_hello.pp
class notifytest1::notify_hello{
notify {'notice': #资源标题
name => 'Hello.mastet', #如果没有下面的message输出的话,会输出name的内容
message => 'Hello,this is master.puppet!', #消息要输出的内容
}
}
4.6 cron资源介绍
示例1:添加时间服务同步
# cat /etc/puppet/modules/crontest1/manifests/ntpdate_add.pp
class crontest1::ntpdate_add{
cron {'ntpdate': #标题是ntpdate
command => "/sbin/ntpdate 0.centos.pool.ntp.org", #要执行的命令,命令应该是全路径
user => root, #这里是写到root用户的定时任务,不过一般给其他用户指定
minute => '*/3', #这里代表是每3分钟,如果是3分的话,就直接3就可以了。
name => 'ntpdate to 3 min' #这里是注释
}
}
客户端执行下面是执行后的效果:
# crontab -l
# Puppet Name: ntpdate to 3 min
*/3 * * * * /sbin/ntpdate 0.centos.pool.ntp.org
示例2:添加httpd服务重启任务
# cat /etc/puppet/modules/crontest1/manifests/http_restart.pp class crontest1::http_restart{
cron {'httpd':
command => "service httpd restart", #要执行的命令
user => apache, #定时任务添加到apache用户
minute => 0, #0代表不设置分钟数,也就是按整小时算。
hour => '3-5', #每天的3点到5点。也就是3,4,5点。
monthday => 1, #每个月的1号
month => [3,6,9], #多数值用[]括起来,这里代表3,6,9月
name => 'httpd to restart' #注释
}
}
客户端执行的结果:
# crontab -u apache -l
# Puppet Name: httpd to restart
0 3-5 1 3,6,9 * service httpd restart
当然很多时候我们是定时去执行一个脚本,意思一样的,就调试好后放到command中用双括号括起来就行,当然默认就是添加一个定时任务,如果任务存在就是修改,如果要删除某个定时任务的话,就加上ensure => absent。
4.7 service资源介绍
示例1:将httpd服务启动并添加到开机启动项
# cat /etc/puppet/modules/servicetest1/manifests/httpd_on.pp
class servicetest1::httpd_on{
service {'apache': #下面如果没有指定name,这里不仅只是标题,也表示要对那个服务做操作。
ensure => true, #这里表示服务的状态,true或running都可以,表示启动。stopped或false表示关闭。
enable => true, #这里表示开机启动。
name => "httpd", #这里就是守护服务进程的名称,如apache的服务启动,就是service httpd start。一般标题如果设置的是对的,这里就不用设置了。但是如果有的标题只是做一个标识作用,这个name是一定要填写的,如现在这种情况,如果不填写name客户端执行的时候肯定是要报错的。
path => "/etc/rc.d/init.d", #init启动脚本的搜索路径,可以用冒号分隔多个路径,或者用数组指定。
}
}
示例2:将zabbix服务启动
# cat /etc/puppet/modules/servicetest1/manifests/zabbix_start.pp #puppet默认启动的都是service 服务 start,可以启动的服务。
class servicetest1::zabbix_start{
service{'zabbix_server':
ensure => 'running', #这是启动是一定要定义的,不过引用的的启动就不再是service zabbix_server start命令了,因为我们有好多是编译安装的服务,启动命令并非是service 服务名称 start。就需要下面的自定义了。
start => "/usr/local/zabbix/sbin/zabbix_server start", #这里就是指定了start服务需要进行的操作,就是按照此方式启动服务。
}
}
下面是客户端执行结果:

如果不用start =>启动服务呢?下面是报错信息(默认就是用service 服务名称 start):
Error: Could not start Service[zabbix_server]: Execution of '/sbin/service zabbix_server start' returned 1: zabbix_server: unrecognized service
注:restart不太好用,不如exec模块指定服务重启呢......
4.8 user资源介绍
# grub-md5-crypt #先要用此命令创建一个加密后的密码,因为puppet里面user资源哪里的给用户创建密码是指定的密文的形式。
Password:
Retype password:
$1$Rq3XH/$.F69RHlTcJivkfe.o/7hH/
示例1:创建一个test5用户,密码为123456,可以登录用户并且自动创建家目录
# cat /etc/puppet/modules/usertest1/manifests/test5_add.pp
class usertest1::test5_add {
user{'user_test5': #这个标题就不多做介绍了,下面如果没有name这里就不仅仅是标题这么简单了,也就是要创建的用户
ensure => present, #默认就是present,如果要删除用户就用absent
uid => '601', #指定用户的uid号,gid一般不用制定,一般跟uid是一致的。
managehome => true, #puppet默认是不会自动创建家目录的,但是如果这里设置为true的话,会自动创建家目录的
name => 'test5', #要创建用户的名称
shell => '/bin/bash', #是否可以登录,/bin/bash是可以登录,要绝对路径哦。不能登录时sbin/nologin
password => '$1$Rq3XH/$.F69RHlTcJivkfe.o/7hH/', #这是次用户的密码,可以看到是加密后的密文形式。
}
}
示例2:删除test5用户
# cat /etc/puppet/modules/usertest1/manifests/test5_del.pp
class usertest1::test5_del {
user{'test5':
ensure => absent, #ensure 改为absent就是删除用户。
home => '/home/test5',
managehome => true, #这里还是true,就表示删除家目录了,这里是创建还是删除,取决于ensure的值。
}
}
#当然你要改密码,改uid,改是否能登录,都是按上面的样子改下对应的值就可以了。
注:gid和groups,在这里的区别。
gid是将此用户的属组改为gid对应的用户组,如gid => 2534,而我们客户端上面gid2534对应的组为test4,也就是下面的一种效果。但是前提你要保证客户端的gid都是一致的,不然的话,你的属组就乱套了。

groups是让此用户额外再拥有什么属组。如groups => test4,这种用户还是有些作用的,看下面的截图。

注:home和managehome的配合用法。
首先home的用法就是指定家目录嘛,一般家目录都是/home下面嘛,但是也有例外的,如ftp做系统登录等,一些例外的情况,但是既然集群操作一般不会做这种蛋疼的事情。如:home => '/tmp/test6',指定test6用户的家目录为/tmp/test6.然后你就想修改家目录变为了,home => '/home/test6',这也是可以的,客户端不会报错,但是呢就是你只是改变了/etc/passwd里面用户家目录的状态,家目录是不会随之而创建的。
然后就是managehome,上面已经讲了状态为true,会为我们创建用户。但是当我们跟home配合,第一次创建完家目录,home又想改变家目录的时候,客户端就报错,也就是为你创建一次家目录以后,以后就不伺候你了.......。还有就是如果这里启用了,一定要设置ensure,不然客户端倒是不会报错不过无操作
4.9 package资源示例
示例1,根据不同的系统环境安装mysql软件包
# cat /etc/puppet/modules/packagetest1/manifests/mysql_install.pp
class packagetest1::mysql_install{
package {'mysql':
name => $operatingsystem ? #这里name表示安装包的名称,我们知道不同的系统环境,安装的包的名称不一样,为了使用多环境,我们这里用了一个简单的三元运算,$operatingsystem是根据客户端facter的变量来判断,此变量是操作系统的变量。?后面是不同的值对应的名称。
{
/(?i-mx:RedHat|CentOS)/ => "mysql", #/(|)/这是用了一个正则表达式,//里面是正则,(|)用|将两个字符串隔离开,这两个字符串的匹配是或的关系,匹配成功其中一种便可以,?-mx是忽略大小写的意思,这里就是如果系统是redhat或者centos,name包的名称就是mysql。
/(?i-mx:ubuntu|debian)/ => "mysql-client", #这里的意思就是如果系统是ubuntu或者debian,就安装mysql-client包。
default => "mysql", #如果上面两个都没有匹配上,是其他的系统,name的包名称就是mysql。
},
ensure => installed, #这就是安装的意思。
}
}
#注意:我的name包都是字符串而非数组,这里name报设置不了数组,(name不支持数组,但是标题支持数组,标题哪里可以是数组,也可以定义一个top作用域的变量来定义数组,然后标题来引用这个变量)如果你设置了数组在客户端执行的时候,客户端会包下面的错误:
Error: Failed to apply catalog: Parameter name failed on Package[mysql]: Name must be a String not Array
示例2,根据不同的系统环境更新软件至最新版本
# cat /etc/puppet/modules/packagetest1/manifests/mysql_update.pp
class packagetest1::mysql_update{
package {'mysql':
name => $operatingsystem ?
{
/(?i-mx:RedHat|CentOS)/ => "mysql",
/(?i-mx:ubuntu|debian)/ => "mysql-client",
default => "mysql",
},
ensure => latest, #这个参数还是很有意思的,实际生产环境中一般有专门的人员来关注系统中软件的旧版本漏洞,也会有专门的网站来纰漏这些问题,就如之前的openssh漏洞,就需要集中的更新一下版本,还有后来的nginx漏洞,等等,所以这个更新软件版本是一个很有意思的参数。
}
}
下面是客户端的截图:

示例3,安装本地rpm包。(要么rpm包就不存在什么依赖关系,要么依赖关系已经通过上面的安装解决了,要不就是自制的rpm包)
# cat /etc/puppet/modules/packagetest1/manifests/postfix_install.pp
class packagetest1::postfix_install{
package {'postfix':
source => "/tmp/postfix-2.6.6-8.el6.x86_64.rpm" #这是以本地rpm包的方式安装软件。这种可以先通过file资源把rpm传送到客户端。
#source => "http://mirror.centos.org/centos-6/6/os/x86_64/Packages/postfix-2.6.6-8.el6.x86_64.rpm" #以url的方式一般不用。
}
}
