OpenStack(四)Cinder结合Ceph做多存储后端
https://blog.51niux.com/?id=170 #已经介绍了cinder以及如何简单的使用LVM做后端存储,这里呢主要是针对与Ceph的结合来做介绍。
https://blog.51niux.com/?id=162 #已经记录了ceph的部署过程
http://docs.ceph.com/docs/master/rbd/rbd-openstack/ #ceph官网记录了openstack如何跟ceph结合使用
一、配置Ceph为Openstack后端
1.1 环境梳理
为了搞这个分布式加openstack的混合使用,特意重新把环境重新又规划了一下。
| IP地址 | 节点角色 | 所属集群 |
| 192.168.1.11 | nova节点 | openstack |
| 192.168.1.12 | nova节点 | |
| 192.168.1.13 | 控制节点加数据节点 | |
| 192.168.1.14 | 网络节点 | |
| 192.168.1.20 | ceph节点 | ceph |
| 192.168.1.21 | ceph节点 | |
| 192.168.1.22 | ceph节点 |
#/etc/hosts都配置好,所有的数据流通都是通过另一个vlan(1.1.1.0/24网段),所有节点与ceph之间都是在万兆光纤交换机下面,数据之间的输出走的是万兆网卡。
#关于ceph集群这里简单搞了一个测试的所以三个节点既是mon节点又是osd节点。
# ceph osd tree
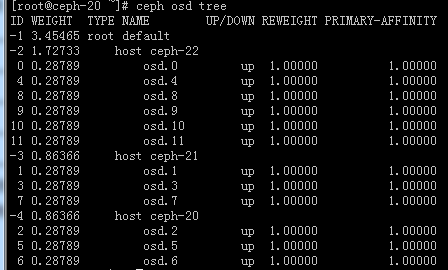
#我这是由12块盘组成的一个osd集群。
# cat /etc/hosts #此文件设置好,尤其是cinder节点和openstack集群上面,我这里直接选择ceph-20作为cinder节点
192.168.1.20 ceph-20 192.168.1.21 ceph-21 192.168.1.22 ceph-22 192.168.1.11 compute01 192.168.1.12 compute02 192.168.1.13 controller 192.168.1.14 network
博文来自:www.51niux.com
1.2 控制节点上面的授权操作
创建数据库
# mysql -uroot -p MariaDB [(none)]> create database cinder; MariaDB [(none)]>GRANT ALL PRIVILEGES ON cinder.* TO 'cinder'@'192.168.1.%' IDENTIFIED BY '51niux'; MariaDB [(none)]> GRANT ALL PRIVILEGES ON cinder.* TO 'cinder'@'localhost' IDENTIFIED BY '51niux'; MariaDB [(none)]> flush privileges;
keystone创建cinder用户:
# source /root/admin-openrc # openstack user create --domain default --password-prompt cinder #需要输入密码,密码还是51niux # openstack role add --project service --user cinder admin #添加admin角色到cinder用户上
创建cinder和cinderv2服务实体:
# openstack service create --name cinder --description "OpenStack Block Storage" volume # openstack service create --name cinderv2 --description "OpenStack Block Storage" volumev2
创建块设备存储服务的API入口点:
也就是创建Cinder端点,服务端点就是Cinder服务的具体提供者的URL,因为对Cinder服务的操作是通过基于HTTP或HTTPS的Rest API来完成的。
#volume服务注册 # openstack endpoint create --region RegionOne volume public http://controller:8776/v1/%\(tenant_id\)s # openstack endpoint create --region RegionOne volume internal http://controller:8776/v1/%\(tenant_id\)s # openstack endpoint create --region RegionOne volume admin http://controller:8776/v1/%\(tenant_id\)s #volumev2服务注册 # openstack endpoint create --region RegionOne volumev2 public http://controller:8776/v2/%\(tenant_id\)s # openstack endpoint create --region RegionOne volumev2 internal http://controller:8776/v2/%\(tenant_id\)s # openstack endpoint create --region RegionOne volumev2 admin http://controller:8776/v2/%\(tenant_id\)s
安装软件包:
# yum install openstack-cinder -y
编辑 /etc/cinder/cinder.conf:
[DEFAULT] rpc_backend = rabbit my_ip = 1.1.1.13 auth_strategy = keystone [database] connection = mysql+pymysql://cinder:51niux@controller/cinder [oslo_messaging_rabbit] rabbit_host = controller rabbit_userid = openstack rabbit_password = 51niux [keystone_authtoken] auth_uri = http://controller:5000 auth_url = http://controller:35357 memcached_servers = controller:11211 auth_type = password project_domain_name = default user_domain_name = default project_name = service username = cinder password = 51niux [oslo_concurrency] lock_path = /var/lib/cinder/tmp
同步数据库:
# su -s /bin/sh -c "cinder-manage db sync" cinder
配置nova计算服务使用块设备存储:
# vim /etc/nova/nova.conf
[cinder] os_region_name = RegionOne
重启nova计算API服务:
# systemctl restart openstack-nova-api.service
启动cinder块设备存储服务,并将其配置为开机自启:
#systemctl enable openstack-cinder-api.service openstack-cinder-scheduler.service
#systemctl restart openstack-cinder-api.service openstack-cinder-scheduler.service
博文来自:www.51niux.com
1.3 ceph节点上面的操作(任意一台mon节点)
创建pool并授权
#ceph osd pool create images 128 #创建一个images的pool,里面有128个pg #ceph osd pool create backups 128 #创建一个backups的pool,里面有128个pg #ceph osd pool create vms 128 #创建用于存储虚拟机系统镜像的pool,名称叫做vms #ceph osd pool create volumes 200 #创建用于存储数据的pool,名称叫做volumes #ceph auth get-or-create client.cinder mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=volumes , allow rwx pool=vms, allow rx pool=images' #ceph auth get-or-create client.glance mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=images' #创建一个glance用户并授权 #ceph auth get-or-create client.cinder-backup mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=backups' #创建一个cinder-backup用户并授权
# ceph osd lspools #用此命令查看一下存储池是否创建成功
安装软件包
# yum install openstack-cinder targetcli python-keystone -y
查看各种key
#这三份key文件都要在控制节点上面存一份,等下面计算节点、glance节点、cinder节点都创建完对应的keyring文件之后,都发送一份到控制节点的/etc/ceph目录下面。切记!
#如果控制节点不做cinder节点,而那台cinder节点(做volume)的/etc/ceph目录下面一定要有ceph.client.cinder.keyring文件,不然会有下面的提示:
2017-09-20 15:08:25.606 10228 ERROR cinder.volume.drivers.rbd client.connect() 2017-09-20 15:08:25.606 10228 ERROR cinder.volume.drivers.rbd File "rados.pyx", line 785, in rados.Rados.connect (rados.c:8969) 2017-09-20 15:08:25.606 10228 ERROR cinder.volume.drivers.rbd ObjectNotFound: error connecting to the cluster 2017-09-20 15:08:25.606 10228 ERROR cinder.volume.drivers.rbd
# ceph auth get-or-create client.cinder
[client.cinder]
key = AQBeQ79Z0aCYHhAAX6HMWJ67zeXHDyTKSXWP8A==
# ceph auth get-or-create client.glance #查看glance的auth信息
[client.glance]
key = AQDhQL9ZZS5eBxAA9yyHRY0LIMy3OALAnIaNag==
# ceph auth get-or-create client.cinder-backup #查看cinder-backup的auth信息
[client.cinder-backup]
key = AQCGQ79Zc03VDRAAa5lW02H6xxjlbQqd1GNt3Q==
1.4 计算节点上面的操作(每台计算节点都要做)
安装相关软件并创建相关访问ceph的key:
# yum install ceph-common -y
# yum install ceph -y #ceph的yum源配置请参考上面的链接,需要里面一些关联的软件包工具。
#注意:上面的ceph是一定要安装的在计算节点上面,不然使用卷创建实例会有报错:
2017-09-21 15:45:39.692 43196 ERROR nova.compute.manager [instance: a3dc82bb-fe43-45a0-a546-d59272d6ec6d] if ret == -1: raise libvirtError ('virDomainCreateWithFlags() failed', dom=self)
2017-09-21 15:45:39.692 43196 ERROR nova.compute.manager [instance: a3dc82bb-fe43-45a0-a546-d59272d6ec6d] libvirtError: internal error: qemu unexpectedly closed the monitor: 2017-09-21T07:45:39.437600Z qemu-kvm: -drive file=rbd:volumes/volume-191008ef-e17e-4401-b9b4-0a1263890298:id=cinder:key=AQA2CcJZ98Q2FBAA1M0LGf6oj2jOylRDKkBujQ==:auth_supported=cephx\;none:mon_host=192.168.14.20\:6789\;192.168.14.21\:6789\;192.168.14.22\:6789,format=raw,if=none,id=drive-virtio-disk0,serial=191008ef-e17e-4401-b9b4-0a1263890298,cache=writeback: error reading header from volume-191008ef-e17e-4401-b9b4-0a1263890298
2017-09-21 15:45:39.692 43196 ERROR nova.compute.manager [instance: a3dc82bb-fe43-45a0-a546-d59272d6ec6d] 2017-09-21T07:45:39.440130Z qemu-kvm: -drive file=rbd:volumes/volume-191008ef-e17e-4401-b9b4-0a1263890298:id=cinder:key=AQA2CcJZ98Q2FBAA1M0LGf6oj2jOylRDKkBujQ==:auth_supported=cephx\;none:mon_host=192.168.14.20\:6789\;192.168.14.21\:6789\;192.168.14.22\:6789,format=raw,if=none,id=drive-virtio-disk0,serial=191008ef-e17e-4401-b9b4-0a1263890298,cache=writeback: could not open disk image rbd:volumes/volume-191008ef-e17e-4401-b9b4-0a1263890298:id=cinder:key=AQA2CcJZ98Q2FBAA1M0LGf6oj2jOylRDKkBujQ==:auth_supported=cephx\;none:mon_host=192.168.14.20\:6789
2017-09-21 15:45:39.692 43196 ERROR nova.compute.manager [instance: a3dc82bb-fe43-45a0-a546-d59272d6ec6d]# scp 192.168.1.20:/etc/ceph/ceph.conf /etc/ceph/ #从ceph节点上面将ceph.conf配置文件拷贝到计算节点上面
#注意:/etc/ceph/ceph.conf (计算节点和控制节点都要有的,如果glance节点分离出去了也是要有的,cinder节点肯定也是要有的,如果没有会有下面的报错:)
#注意:/etc/ceph/ceph.conf (计算节点和控制节点都要有的,如果glance节点分离出去了也是要有的,cinder节点肯定也是要有的,如果没有会有下面的报错:) 2017-09-20 17:04:15.909 80688 ERROR glance.common.wsgi [req-cbc78972-6c81-482e-98cf-2ababd4b859c a5607bd53c2c4342bcf4b3f0136909c5 c785335e96a340c4b2b7def3b72be40d - - -] Caught error: error calling conf_read_file: errno EINVAL 2017-09-20 17:04:15.909 80688 ERROR glance.common.wsgi Traceback (most recent call last):
# vim /etc/ceph/ceph.client.cinder.keyring
[client.cinder] key = AQBeQ79Z0aCYHhAAX6HMWJ67zeXHDyTKSXWP8A==
创建Secret并配置配置文件:
#uuidgen
b7711ce4-4515-4c99-9894-fff9914cd150
# vim /root/secret.xml
<secret ephemeral='no' private='no'> <uuid>b7711ce4-4515-4c99-9894-fff9914cd150</uuid> <usage type='ceph'> <name>client.cinder secret</name> </usage> </secret>
# virsh secret-define --file secret.xml #如果没有virsh命令执行#yum install libvirt -y
生成 secret b7711ce4-4515-4c99-9894-fff9914cd150
# virsh secret-set-value --secret b7711ce4-4515-4c99-9894-fff9914cd150 --base64 AQA2CcJZ98Q2FBAA1M0LGf6oj2jOylRDKkBujQ==
secret 值设定
# virsh secret-list #查看一下
配置nova.conf文件并重启服务:
OpenStack 需要一个驱动和 Ceph 块设备交互。还得指定块设备所在的存储池名。编辑 OpenStack 节点上的 /etc/cinder/cinder.conf ,添加:
# vim /etc/nova/nova.conf
[libvirt] images_type = rbd images_rbd_pool = vms images_rbd_ceph_conf = /etc/ceph/ceph.conf rbd_user = cinder rbd_secret_uuid = b7711ce4-4515-4c99-9894-fff9914cd150 disk_cachemodes="network=writeback" inject_password = false inject_key = false inject_partition = -2 live_migration_flag="VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,VIR_MIGRATE_LIVE,VIR_MIGRATE_PERSIST_DEST,VIR_MIGRATE_TUNNELL ED" #这句话注意一下如果直接复制的话,因为换行了重启可能会报错,要手工操作一下这里 hw_disk_discard = unmap
#systemctl restart libvirtd.service openstack-nova-compute.service
1.5 cinder节点上面的操作:
这里我们让192.168.1.20这台ceph-01做cinder节点
安装软件包并配置文件:
#yum install openstack-cinder targetcli python-keystone -y
# vim /etc/ceph/ceph.client.cinder.keyring #不创建此key在创建实例的时候会有报错的,下面标红的地方是报错信息,导致控制节点那里查看cinder-volume节点是down的状态。
[client.cinder] key = AQA2CcJZ98Q2FBAA1M0LGf6oj2jOylRDKkBujQ==
下面是/var/log/cinder/volume.log中的部分报错信息:
2017-09-20 14:50:48.990 9354 ERROR oslo_service.service return r.call(f, *args, **kwargs) 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service File "/usr/lib/python2.7/site-packages/retrying.py", line 229, in call 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service raise attempt.get() 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service File "/usr/lib/python2.7/site-packages/retrying.py", line 261, in get 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service six.reraise(self.value[0], self.value[1], self.value[2]) 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service File "/usr/lib/python2.7/site-packages/retrying.py", line 217, in call 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service attempt = Attempt(fn(*args, **kwargs), attempt_number, False) 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service File "/usr/lib/python2.7/site-packages/cinder/volume/drivers/rbd.py", line 345, in _connect_to_rados 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service raise exception.VolumeBackendAPIException(data=msg) 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service VolumeBackendAPIException: Bad or unexpected response from the storage volum e backend API: Error connecting to ceph cluster. 2017-09-20 14:50:48.990 9354 ERROR oslo_service.service
# vim /etc/ceph/ceph.client.cinder-backup.keyring
[client.cinder-backup] key = AQCGQ79Zc03VDRAAa5lW02H6xxjlbQqd1GNt3Q==
#vim /etc/cinder/cinder.conf
[DEFAULT] rpc_backend = rabbit my_ip = 1.1.1.20 auth_strategy = keystone verbose = True enabled_backends = ceph rbd_max_clone_depth = 5 rbd_store_chunk_size = 4 rados_connect_timeout = -1 glance_api_version = 2 backup_driver = cinder.backup.drivers.ceph backup_ceph_conf = /etc/ceph/ceph.conf backup_ceph_user = cinder-backup backup_ceph_chunk_size = 134217728 backup_ceph_pool = backups backup_ceph_stripe_unit = 0 backup_ceph_stripe_count = 0 restore_discard_excess_bytes = true glance_host = 1.1.1.13 #这个地方一定要记得加上指向glance节点的IP地址,如果cinder节点没有跟控制节点(也就是跟glance节点在一起),默认找的是自己的IP和端口。不加的话就会报错 [database] connection = mysql+pymysql://cinder:51niux@controller/cinder [oslo_messaging_rabbit] rabbit_host = controller rabbit_userid = openstack rabbit_password = 51niux [keystone_authtoken] auth_uri = http://controller:5000 auth_url = http://controller:35357 memcached_servers = controller:11211 auth_type = password project_domain_name = default user_domain_name = default project_name = service username = cinder password = 51niux [oslo_concurrency] lock_path = /var/lib/cinder/tmp [ceph] #再定义一个后端就再搞配置区域,多后端设置也很简单的 volume_driver = cinder.volume.drivers.rbd.RBDDriver volume_backend_name = ceph rbd_pool = volumes rbd_user = cinder rbd_secret_uuid = b7711ce4-4515-4c99-9894-fff9914cd150 #为了挂载 Cinder 块设备(块设备或者启动卷),必须告诉 Nova 挂载设备时使用的用户和uuid 。libvirt会使用该用户来和 Ceph 集群进行连接和认证。所以就是需要rbd_secret_uuid和rbd_user,这两个标志同样用于 Nova 的临时后端。 rbd_ceph_conf = /etc/ceph/ceph.conf rbd_flatten_volume_from_snapshot = false rbd_max_clone_depth = 5 rbd_store_chunk_size = 4 rados_connect_timeout = -1
下面是不加glance_host=1.1.1.13的/var/log/cinder/volume.log 部分报错信息,也就是你将系统镜像上传到ceph里面上传不了,因为api接口找错了,下面是部分报错信息:
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance [req-328e0f88-f001-4c33-9db7-1b0d3ade7bb1 754a771fbbdb4766ab6d11fb698baacb c
038cc6839fd4713a1828d7e180ee622 - - -] Error contacting glance server '1.1.1.20:9292' for 'get', done trying.
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance Traceback (most recent call last):
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance File "/usr/lib/python2.7/site-packages/cinder/image/glance.py", line 177,
in call
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance return getattr(controller, method)(*args, **kwargs)
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance File "/usr/lib/python2.7/site-packages/glanceclient/v2/images.py", line 18
1, in get
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance resp, body = self.http_client.get(url)
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance File "/usr/lib/python2.7/site-packages/glanceclient/common/http.py", line
275, in get
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance return self._request('GET', url, **kwargs)
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance File "/usr/lib/python2.7/site-packages/glanceclient/common/http.py", line
256, in _request
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance raise exc.CommunicationError(message=message)
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance CommunicationError: Error finding address for http://1.1.1.20:9292/v2/images
/e3719210-ab3c-49bd-ac21-bfebfe325793: HTTPConnectionPool(host='1.1.1.20', port=9292): Max retries exceeded with url: /v2/images/e37
19210-ab3c-49bd-ac21-bfebfe325793 (Caused by NewConnectionError('<requests.packages.urllib3.connection.HTTPConnection object at 0x50
d28d0>: Failed to establish a new connection: [Errno 111] ECONNREFUSED',))
2017-09-21 09:40:52.169 10295 ERROR cinder.image.glance重启相关服务:
#systemctl enable openstack-cinder-volume.service openstack-cinder-backup.service
#systemctl restart openstack-cinder-volume.service
#systemctl restart openstack-cinder-backup.service
博文来自:www.51niux.com
1.6 glance镜像节点(也就是控制节点上面的操作)
安装软件包并进行配置:
#yum install python-rbd -y
#yum install ceph-common -y
#yum install ceph
# vim /etc/glance/glance-api.conf
[DEFAULT] default_store = rbd show_image_direct_url = True #允许使用 image 的写时复制克隆 show_multiple_locations = True hw_scsi_model=virtio-scsi #添加 virtio-scsi 控制器以获得更好的性能、并支持 discard 操作 hw_disk_bus=scsi #把所有 cinder 块设备都连到这个控制器; hw_qemu_guest_agent=yes #启用 QEMU guest agent (访客代理) os_require_quiesce=yes #通过 QEMU guest agent 发送fs-freeze/thaw调用 [glance_store] stores = rbd default_store = rbd rbd_store_pool = images rbd_store_user = glance rbd_store_ceph_conf = /etc/ceph/ceph.conf rbd_store_chunk_size = 8 #stores = file,http #原来的注释掉,不存储在本地了 #default_store = file #filesystem_store_datadir = /var/lib/glance/images/ [paste_deploy] flavor = keystone
# vim /etc/ceph/ceph.client.glance.keyring
[client.glance] key = AQBECcJZpYSPExAAeVJwbH9QkSqBMMEfO7T3Ww==
#systemctl restart openstack-cinder-api.service openstack-cinder-scheduler.service #一般glance节点跟控制节点在一起嘛,所以这个cinder重启放到最后。
#systemctl restart openstack-glance-api.service openstack-glance-registry.service
二、测试并操作
2.1 控制节点的操作
# cinder service-list #在控制节点执行查看一下现在cinder服务的状态

#从上面可以看出,关于cinder的各节点和服务至少在状态上显示都已经OK了。
#cinder type-create ceph
#cinder type-key ceph set volume_backend_name=ceph #上面lvm已经做过操作了,这里给ceph后端存储一个类型,这在多后端存储的时候很有用,用于区分你到底用哪种存储。
2.2 glance上传镜像测试
# source /root/admin-openrc
# openstack image create "Centos6.8-20G" --file /opt/centos6_20G.img --disk-format raw --container-format bare --public #注意要是raw格式的镜像上传哈,这个镜像呢用KVM做一个传过来就可以了
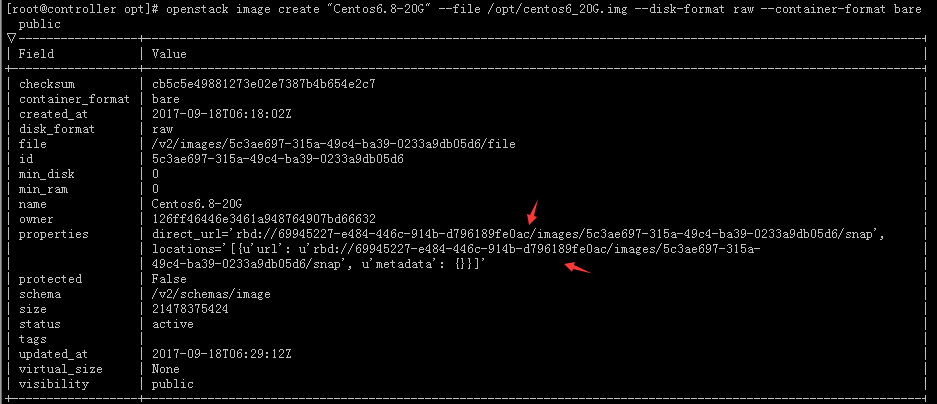
#从上图可以看出镜像可以上传并且url也变成rbd://开头的了。
#虽然可以以qcow2格式上传,但是创建实例的时候就要报错了,如下面的报错截图:
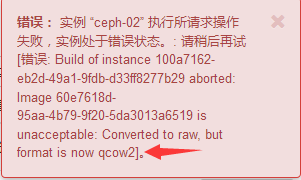
#从上图的提示可以看出提示必须是raw格式。

#可以看到glance的镜像已经不创建到本地了。
# openstack image list
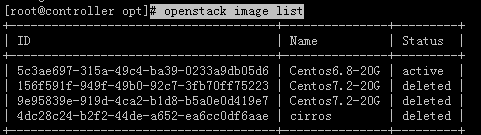
#为了起到测试效果,我已经将之前创建的一些镜像全都删除了。

#到这里glance验证结束,下面来查看一下创建虚拟机实例如何。
博文来自:www.51niux.com
2.3 虚拟机实例创建验证
#其实这个虚拟机实例创建基本也就跟云盘(卷一起测试了)
错误的虚拟机实例创建过程示例:
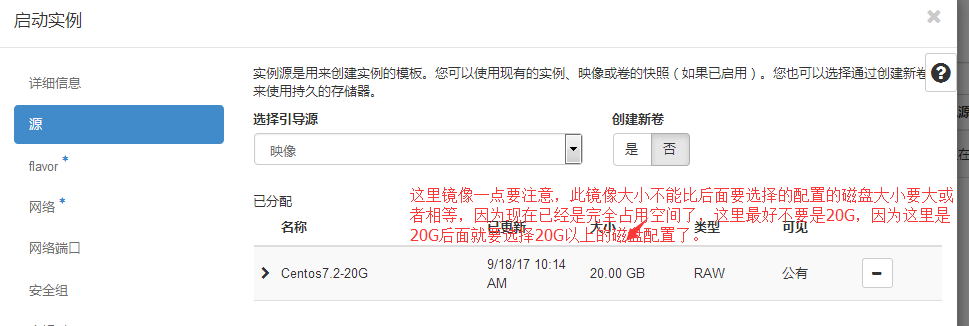
#这里一定要特别注意,镜像文件的大小一定要比选择的配置实例的磁盘空间要小那么一丢丢,不然创建的时候会提示你无法创建实例,但是所有的节点日志都不会报错,就是这个问题,所以你要是想创建20G的虚拟机实例的话,镜像模板最好做成19G多一点,以免你创建实例失败而又找不到报错的原因,因为日志就不会报错。
下面是报错示范:
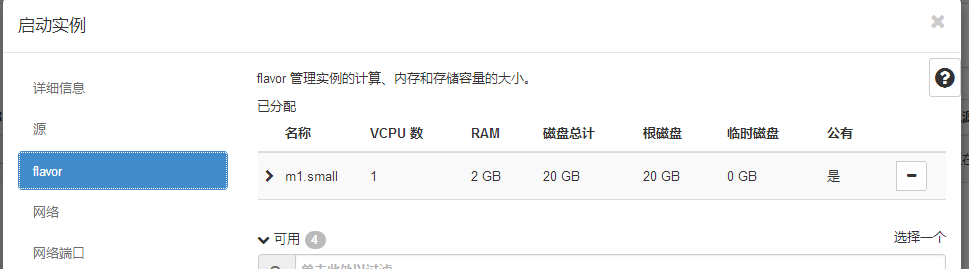
#我选择了一个磁盘是20GB的配置,跟我磁盘镜像大小20G一摸一样。

#就是这个问题:提示你无法创建服务器,但是日志都不会报错的。
#现在我换成40G配置:
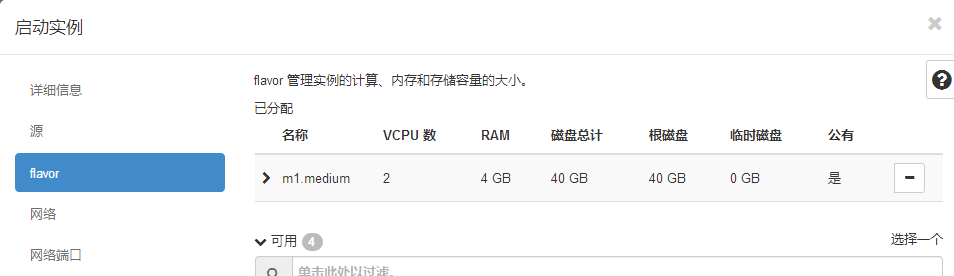

但是我要说的是这种创建方式是不对的,虽然不报错,但是你的点开控制台是下面的效果:
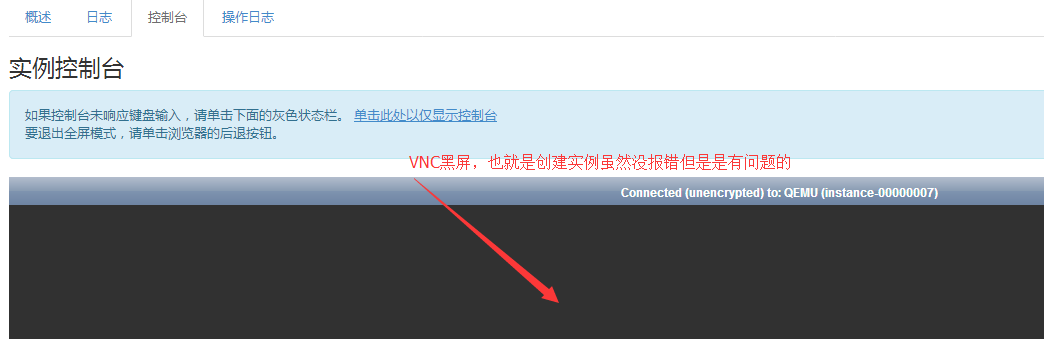
#这并非VNC配置有问题,如果你将libvirt缓存本地存储就是OK的,就算你配上浮动IP也是没用的,因为你系统本身就没有启动成功,这就算是实例创建失败。
正确的虚拟机实例创建过程:
创建启动卷:

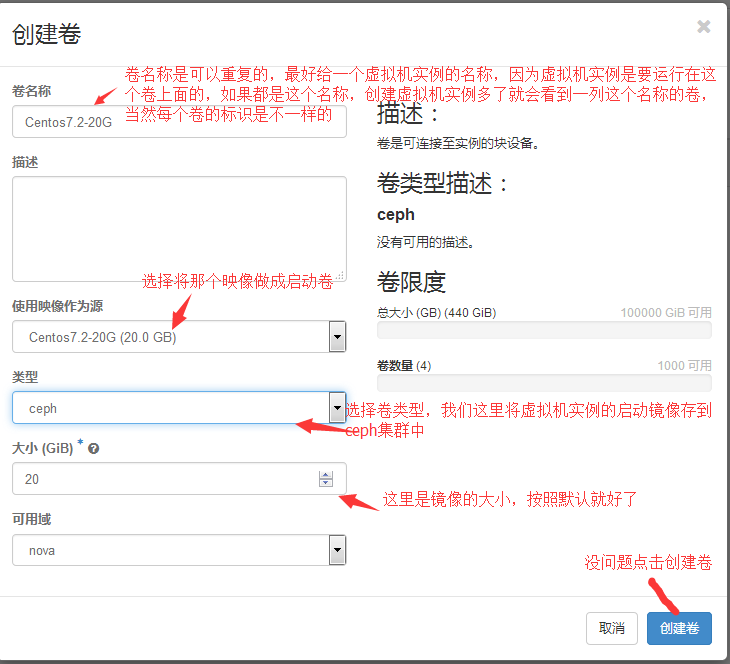

#这里一定要明确可启动那一列True和False的区别。
创建虚拟机实例:
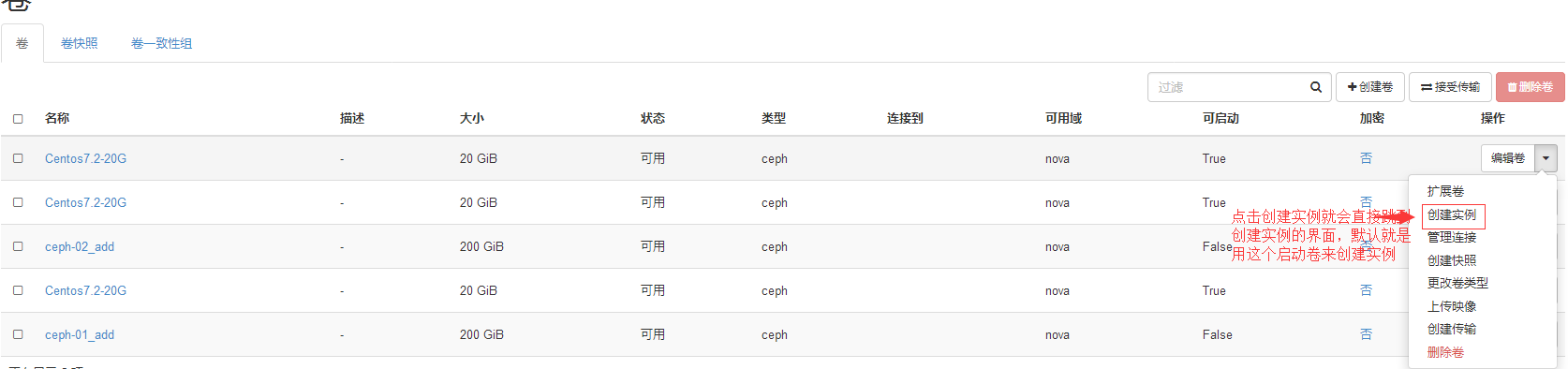
#这种方式是比较好的,因为你如果同名卷比较多,如我上面同名卷有三个,你这里就可以明确指定用哪个卷来创建虚拟机实例。
#后面就是创建虚拟机实例的过程了跟之前一样,我就截源那里的图吧。
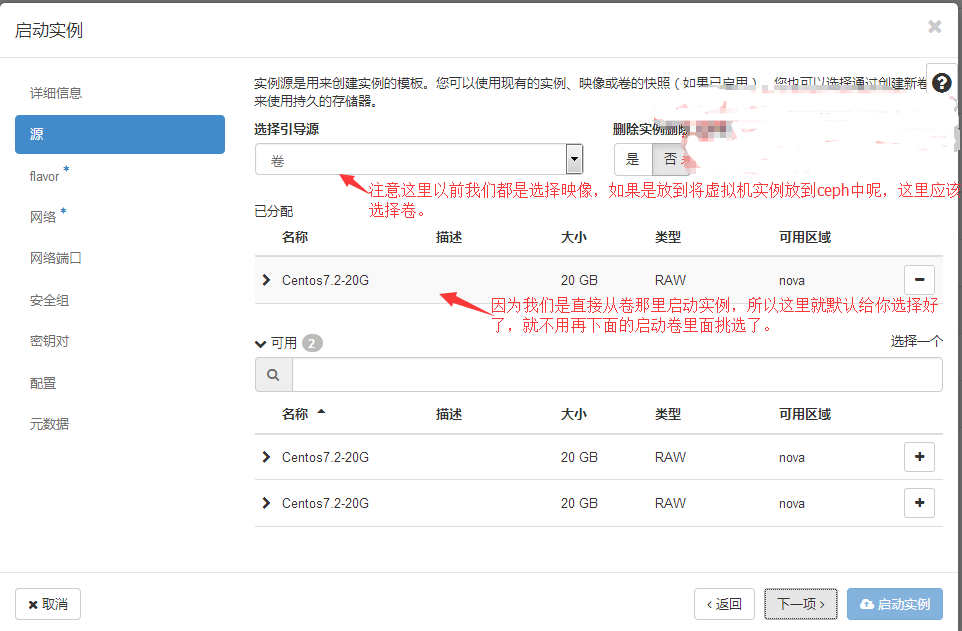
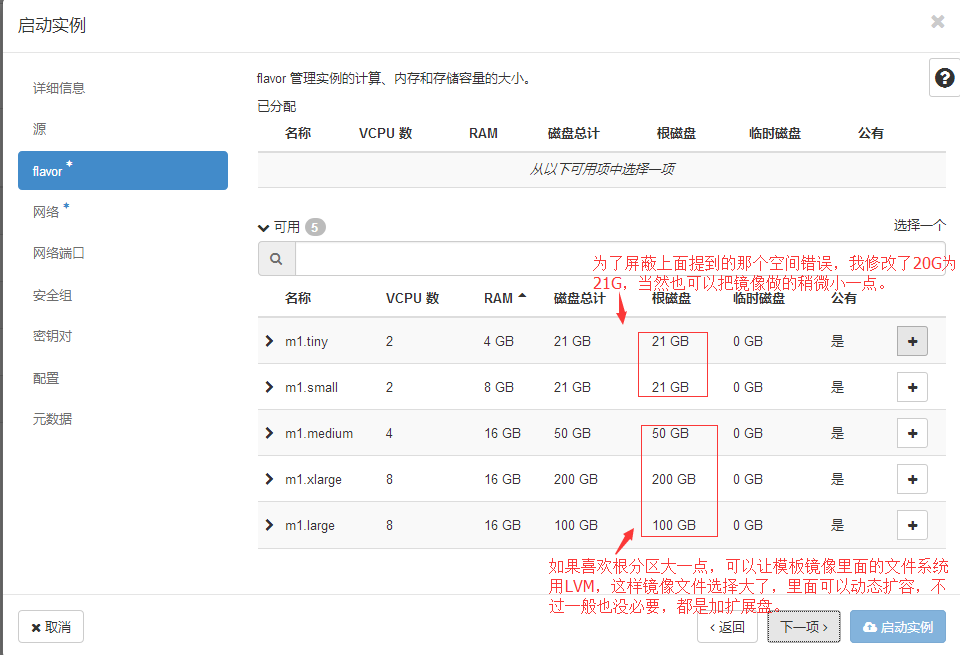
#注意:上面那种搞成21G的做法没必要,因为之前演示的本身就是错误的方式,现在都已经将镜像做成卷了,卷是20G,你实例大小就选20G就可以了。没问题的。
==============================分割线==================================================================

============================就跟卷大小一样没问题可以的不用特意的调整flavor关于磁盘空间这块==============================

#从上图可以看出实例创建是OK的,并且我们给他绑了一个浮动IP,为了能远程登陆看一下,系统是否OK了。
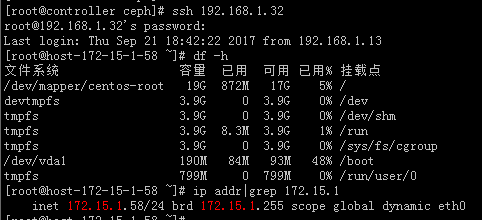
#测试是OK的可以登录。
# virsh edit instance-00000023 #来查看一下这个新创建的虚拟机关于磁盘部分
<devices> <emulator>/usr/libexec/qemu-kvm</emulator> <disk type='network' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <auth username='cinder'> <secret type='ceph' uuid='b7711ce4-4515-4c99-9894-fff9914cd150'/> </auth> <source protocol='rbd' name='volumes/volume-b3eff172-ee4e-4d9b-869a-162bc150c30f'> <host name='192.168.14.20' port='6789'/> <host name='192.168.14.21' port='6789'/> <host name='192.168.14.22' port='6789'/> </source> <target dev='vda' bus='virtio'/> <serial>b3eff172-ee4e-4d9b-869a-162bc150c30f</serial> <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/> </disk>
#从上面的内容可以看出虚拟机实例所使用的系统镜像是存放到ceph集群中的。
2.4 创建云盘并挂载
项目==》计算==》卷==》创建卷
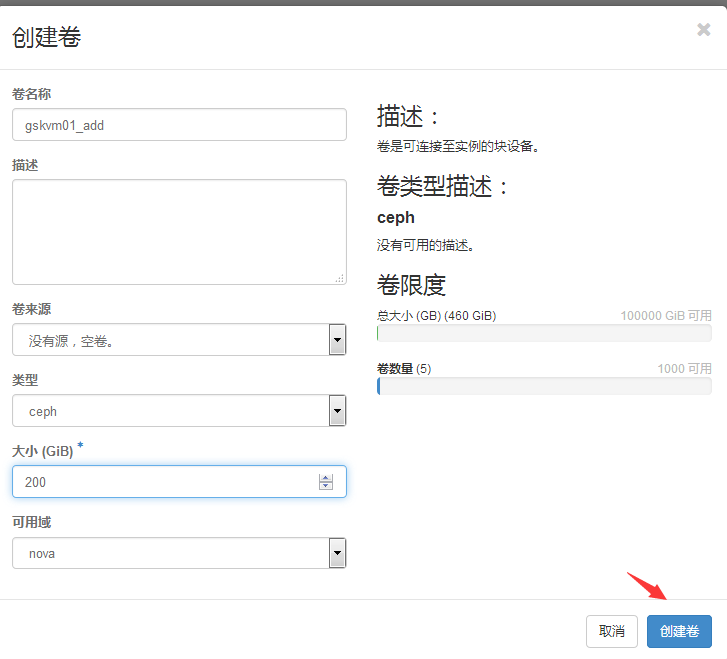

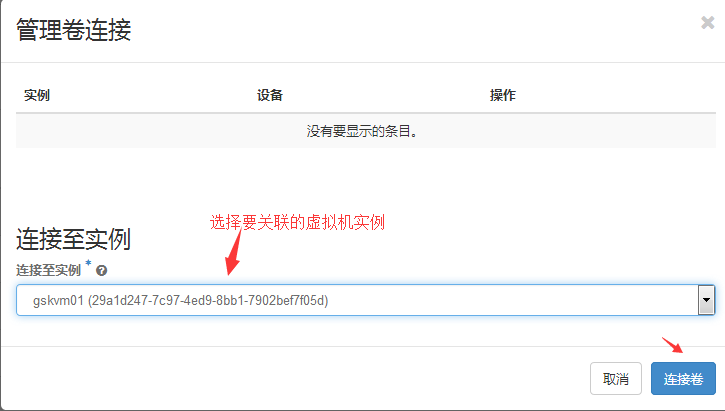
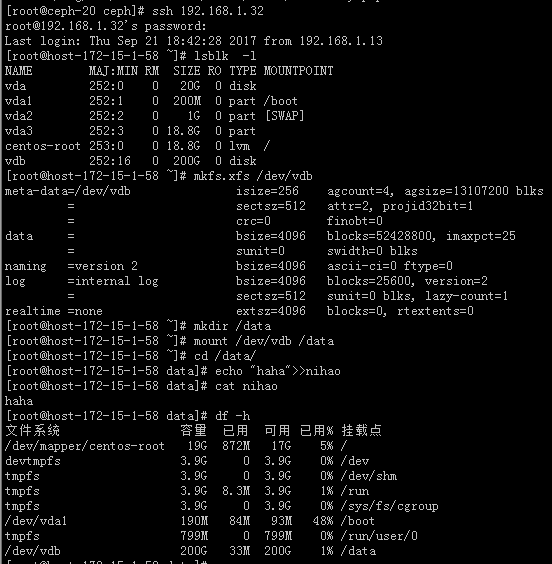
#从上图的测试结果可以看出,格式化新挂载的云盘,挂载读写都是没问题的。
2.5 稍微查看一下
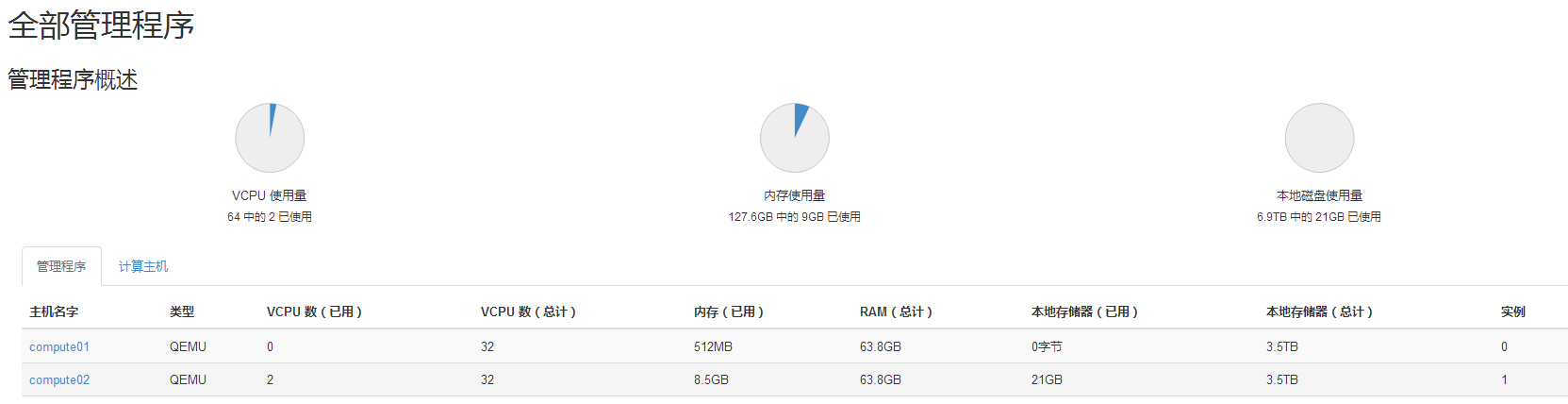
#从admin用户可以看出两个计算节点都是用的是ceph存储,总大小是3.5T,并且因为创建了一个节点已经用去了21GB的存储空间。
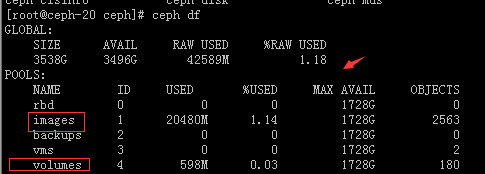
#从ceph的查看结果来看,有两个pool被占用了,images是妥妥的占了20G的空间,但是volumes创建了一个云盘创建了一个实例却没有占用多少空间,可以看出实例还是按照那种增量形式走的,而云盘是用多少占多少空间。因为一份数据存两份副本,所以实际可以使用的空间只有1.7T左右。
#当然Horizon还有各种操作可以多点点熟悉熟悉,并且为了保证效率还是要掌握Shell的操作命令。
2.6 疏散主机
比如说因为我们是将虚拟机实例放到了ceph中,那么就算虚拟机实例所在的计算节点宕机了,那上面跑的虚拟机实例当然也是跟着down了,但是却不是down应该类似于一种假死状态,因为你通过Horizon界面还是活动状态,只是访问不通了而已嘛。
我们上面创建的实例是运行在计算节点compute02上面,现在我们手工的将这台机器关闭。
项目==》管理员==》系统==》管理程序==》计算主机

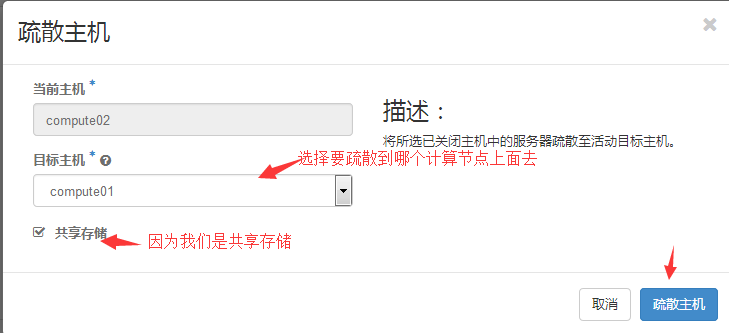
#这里提示开始疏散,但是不是疏散成功了哦。可以进入到实例那里看,可以看到重新构建的过程直到恢复到正常状态。
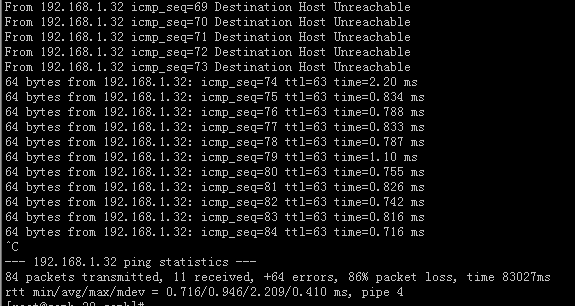
#可以进行实时ping测试,不到一分钟就会发现能ping通。
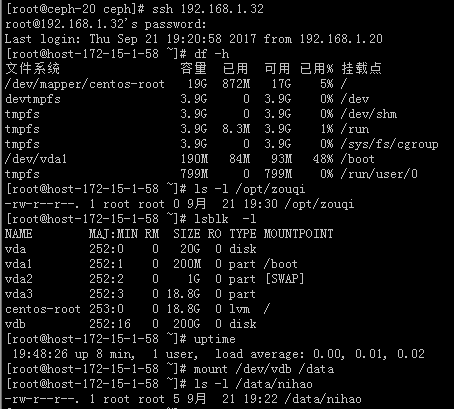
#登录测试发现,主机数据都在不管是本身虚拟机实例本身的数据以及挂载云盘的数据,IP也没有变化,但是云盘并非挂载状态,uptime也是运行时间不长,所以说它有一个重启的过程,这个要注意。
#当原来的计算节点重新开机之后呢,虚拟机实例不会迁移过去了。
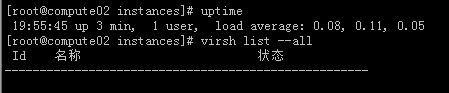
#从上图可以看出原来出问题的计算节点启动之后,哪些疏散的虚拟机实例不会再跑回来。
#那么就可以结合监控,当发现计算节点主机出现问题的时候,将它上面运行的虚拟机实例迅速的切换到其他的计算主机上面去,当然虚拟实例会小小的down一段时间,但是这个时间是很快的,当然这只是伪高可用而已。
