grafana结合Elasticsearch进行一些出图展示(六)
用Elasticsearch做数据源:https://grafana.com/docs/features/datasources/elasticsearch/
如果的dashboard不知道整成啥样,可以参考别人的式例:https://grafana.com/grafana/dashboards
一、官网翻译学习
Grafana附带对Elasticsearch的高级支持。 可以执行许多类型的简单或复杂的Elasticsearch查询,以可视化方式存储在Elasticsearch中的日志或指标。 还可以使用存储在Elasticsearch中的日志事件来注释图形。
1.1 添加数据源(Adding the data source):
1. 通过单击顶部标题中的Grafana图标打开侧面菜单。 2. 在“Dashboards”链接下的侧面菜单中,应该找到一个名为“Data Sources”的链接。 3. 点击顶部标题中的“+ Add data source”按钮。 4. 从Type下拉列表中选择Elasticsearch。 #注意:如果在侧边菜单中没有看到“Data Sources”链接,则表示当前用户没有当前组织的管理员角色。
| Name | Description |
| Name | 数据源名称。 这是在面板和查询中引用数据源的方式。 |
| Default | 默认数据源意味着将为新面板预先选择它。 |
| Url | Elasticsearch服务器的HTTP协议,IP和端口。 |
| Access | 服务器(default)=需要从Grafana后端/服务器访问URL,Browser=需要从浏览器访问URL。 |
访问模式控制如何处理对数据源的请求。 如果没有其他说明,Server应该是首选方式。
Server access mode (Default):
所有请求都将从browser发出到Grafana backend/server,后者再将请求转发到数据源,从而避免可能的跨源资源共享(CORS)要求。 如果选择此访问方式,则需要可以从grafana backend/server访问该URL。
Browser (Direct) access:
所有请求都将从浏览器直接向数据源发出,并且可能要遵守跨域资源共享(CORS)的要求。 如果选择此访问方式,则需要可以从浏览器访问URL。
如果选择browser访问,则必须更新Elasticsearch配置,以允许其他域从浏览器访问Elasticsearch。 可以通过在elasticsearch.yml配置文件中为选项指定这些来实现。
http.cors.enabled: true http.cors.allow-origin: "*"
Index settings:
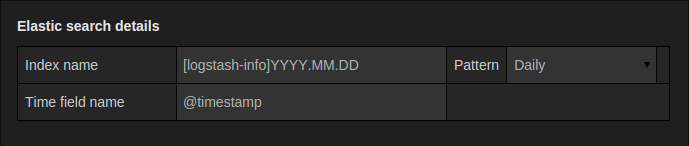
在这里,可以为time field指定默认值,并指定Elasticsearch索引的名称。 可以使用时间模式作为索引名称或通配符。
Elasticsearch version:
确保在版本选择下拉列表中指定你的Elasticsearch版本。 这一点非常重要,因为查询的组成方式有所不同。 当前可用的版本是2.x,5.x,5.6 +,6.0 +或7.0+。 值5.6+表示版本5.6或更高版本,但低于6.0。 值6.0+表示版本6.0或更高版本,但低于7.0。 最后,7.0 +表示7.0版或更高版本,但低于8.0版。
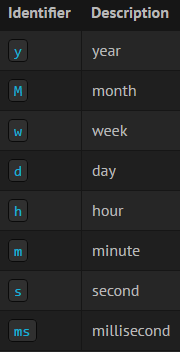
Min time interval:
时间间隔自动分组的下限。 建议设置为写入频率,例如,如果每分钟写入一次数据,则为1m。 还可以在仪表板面板中的数据源选项下overridden/configured此选项。 请务必注意,此值必须设置为数字格式,后跟有效的时间标识符,例如 1m(1分钟)或30s(30秒)。 支持以下时间标识符:
Logs (BETA):
仅在Grafana v6.3 +中可用。
有两个参数,Message field名称和Level field字段名称,可以选择从数据源设置页面配置这些参数,这些参数确定在可视化资源管理器(https://grafana.com/docs/features/explore/)中的日志时将哪些字段用于日志消息和日志级别。
例如,如果使用默认的Filebeat设置将日志传送到Elasticsearch,则以下配置应适用:
Message field name: message Level field name: fields.level
1.2 Metric Query editor
Elasticsearch查询编辑器允许选择多个指标并按多个术语或过滤器分组。 使用右侧的加号和减号图标来添加/删除指标或分组依据子句。 某些度量标准和“分组依据”子句具有选项,请单击选项文本以展开行以查看和编辑度量标准或“分组依据”选项。
1.3 系列名称和别名模式(Series naming and alias patterns)
可以通过“Alias”输入字段控制时间序列的名称。
| Pattern | Description |
| {{term fieldname}} | 用术语组的值替换为 |
| {{metric}} | 替换为指标名称(例如,Average, Min, Max) |
| {{field}} | 替换为度量标准字段名称 |
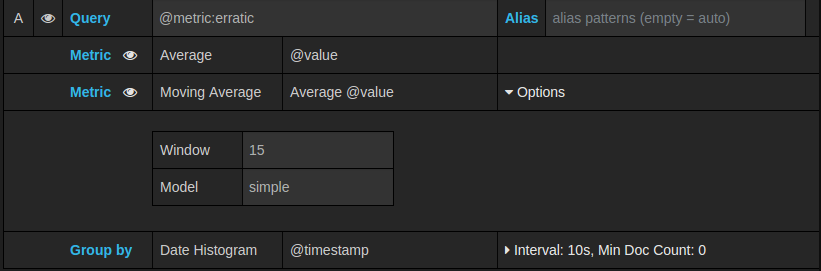
1.4 Pipeline metrics
一些度量标准聚合称为“Pipeline aggregations(管道聚合)”,例如,“Moving Average”和“Derivative(导数)”。 Elasticsearch管道指标需要另一个指标作为基础。 使用指标旁边的眼睛图标可以隐藏指标,使其不显示在图形中。 这对于仅在查询中用于管道指标的指标很有用。
1.5 Templating
可以在变量中使用变量,而不必在指标查询中对服务器,应用程序和传感器名称之类的东西进行硬编码。 变量在仪表板顶部显示为下拉选择框。 这些下拉菜单使你可以轻松更改仪表板上显示的数据。
Query variable:
Elasticsearch数据源支持两种查询类型,可以在查询变量的查询字段中使用它们。 该查询是使用自定义JSON字符串编写的。
| Query | Description |
| {“find”: “fields”, “type”: “keyword”} | 返回带有索引类型keyword(关键字)的字段名称列表。 |
| {“find”: “terms”, “field”: “@hostname”, “size”: 1000} | 使用术语汇总返回字段的值列表。 查询将使用当前仪表板时间范围作为查询时间范围。 |
| {“find”: “terms”, “field”: “@hostname”, “query”: ‘’} | 使用术语聚合和指定的lucene查询过滤器返回字段的值列表。 查询将使用当前仪表板时间范围作为查询时间范围。 |
字词查询的默认大小限制为500。 在查询中设置size属性以设置自定义限制。 可以在查询中使用其他变量。 名为$host的变量的示例查询定义。
{"find": "terms", "field": "@hostname", "query": "@source:$source"}在上面的示例中,我们在查询定义中使用了另一个名为$source的变量。 每当通过下拉列表更改$source变量的当前值时,它都会触发$host变量的更新,因此它现在仅包含由@source document属性过滤的主机名。
默认情况下,这些查询以术语顺序返回结果(然后可以按照字母或数字对任何变量进行排序)。 要生成按文档计数排序的术语列表(前N个值列表),请添加orderBy属性“ doc_count”。 这将自动选择一个降序排序; 通过将doc_count(底部N列表)与“ asc”一起使用可以通过设置以下命令来完成:“ asc”,但不建议使用,因为它“增加了文档计数上的错误”。 为了使术语保持在文档计数顺序中,请将变量的“Sort”下拉列表设置为“Disabled”; 可能仍然想使用例如 按字母顺序重新排序。
{"find": "terms", "field": "@hostname", "orderBy": "doc_count"}Using variables in queries:
There are two syntaxes(语法):
$<varname> : Example: @hostname:$hostname [[varname]]:Example: @hostname:[[hostname]]
为什么有两种方式? 第一种语法更易于读写,但不允许在单词中间使用变量。 启用“Multi-value”或“Include all value”选项后,Grafana会将标签从纯文本转换为与Lucene兼容的条件。
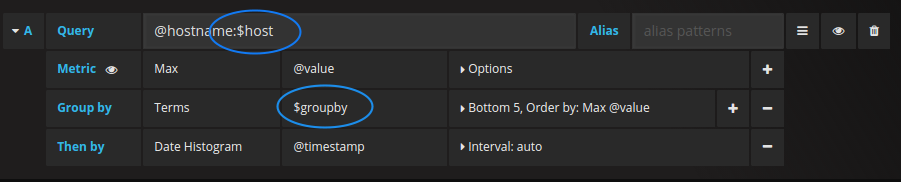
在上面的示例中,我们有一个Lucene查询,该查询使用名为$hostname的变量基于@hostname属性过滤文档。 它还在“Terms”按字段分组”输入框中使用了一个变量。 这使你可以使用变量来快速更改数据的分组方式。Example dashboard: https://play.grafana.org/d/000000015/elasticsearch-templated?
1.6 Annotations
注释使您可以将丰富的事件信息覆盖在图形之上。 可以通过“Dashboard""menu / Annotations”视图添加批注查询。 Grafana可以查询任何Elasticsearch索引以获取注释事件。
| Name | Description |
| Query | 可以将搜索查询保留为空白或指定lucene查询 |
| Time | 时间字段的名称,必须是日期字段。 |
| Text | 事件描述字段。 |
| Tags | 用于事件标签的可选字段名称(可以是数组或CSV字符串)。 |
1.7 Querying Logs (BETA)
仅在Grafana v6.3 +中可用。可通过浏览器从Elasticsearch查询和显示日志数据。
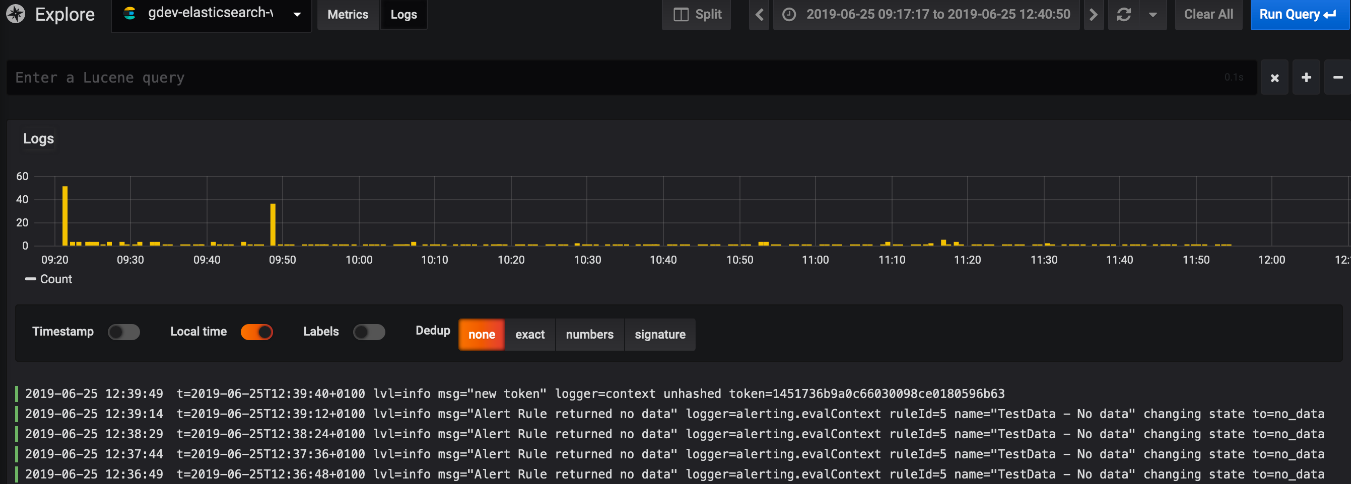
选择Elasticsearch数据源,使用“Metrics/Logs”切换器更改为“Logs”,然后选择在查询字段中输入lucene查询以过滤日志消息。最后,按Enter键或“Run Query”按钮以显示你的日志。
Log Queries:
返回结果后,日志面板将显示日志行列表和条形图,其中x轴显示时间,y轴显示频率/计数。请注意,用于日志消息和级别的字段基于可选的数据源配置。
Filter Log Messages:
(可选)在查询字段中输入lucene查询,以过滤日志消息。 例如,使用默认的Filebeat设置,应该能够使用fields.level:error仅显示错误日志消息。
1.8 Configure the data source with provisioning(使用配置来配置数据源)
现在,可以通过Grafana的配置系统使用配置文件来配置数据源。 可以在配置文档页面上了解有关其工作原理以及可以为数据源设置的所有设置的更多信息。
这是此数据源的一些供应示例。
apiVersion: 1 datasources: - name: Elastic type: elasticsearch access: proxy database: "[metrics-]YYYY.MM.DD" url: http://localhost:9200 jsonData: interval: Daily timeField: "@timestamp"
or, for logs:
apiVersion: 1 datasources: - name: elasticsearch-v7-filebeat type: elasticsearch access: proxy database: "[filebeat-]YYYY.MM.DD" url: http://localhost:9200 jsonData: interval: Daily timeField: "@timestamp" esVersion: 70 logMessageField: message logLevelField: fields.level
二、结合ES数据源实际操作
2.1 配置单个索引并做最简单的数据显示
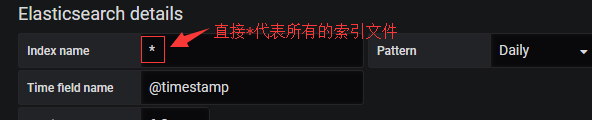
配置只有某个索引的数据源:
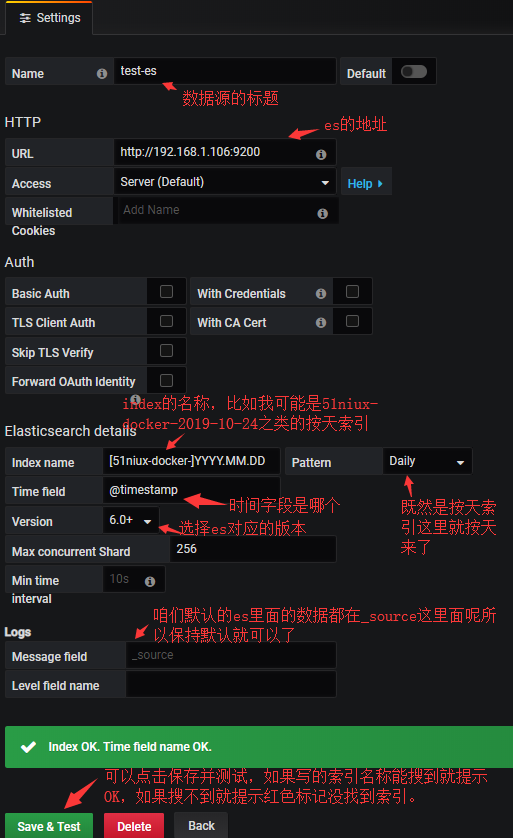
#如果是按月产生的索引怎么配置呢?
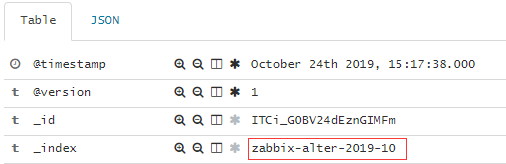
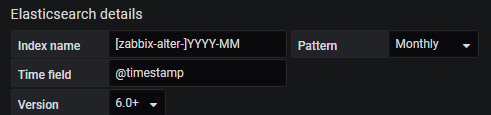
#可见意思都差不多。当然也可以写成[zabbix-alter]*意思也是一样的。
博文来自:www.51niux.com
配置一个简单的报警次数显示:
#先简单介绍一下,我将报警信息经过加工处理存入到es中,这样我在历史回查的时候就可以知道什么时候报警了,报警内容等。

#下面我们用grafana现在下报警次数:
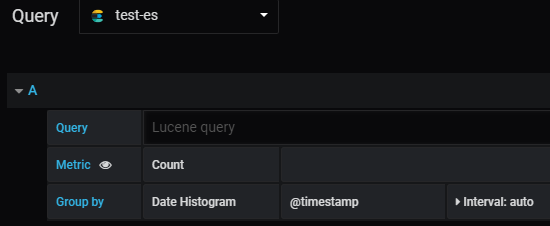
#只要选择我们刚创建的数据源什么都不用配置就可以看到次数了。
#Metric:Unique Count就是根据某个字段去重的意思,如果你是Nginx日志想要根据来源IP进行统计IP数很有用。
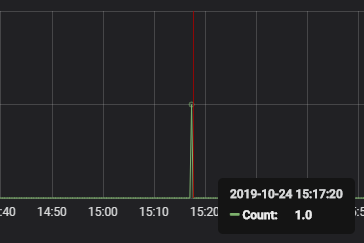
2.2 配置所有或者多个索引并做最简单的数据显示
#上面是拿单个索引做的出图展示,如果我们有10个索引要显示,是不是要创建10个数据源呢?显然我们应该有很好的方式。
#那么数据源是匹配所有的索引了,显示数据的时候怎么来区分要显示那个索引的数据呢?
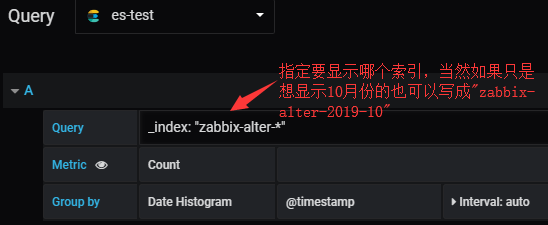
#亦然是可以显示数据的这里就不截图了。
2.3 将es中的信息进行展示
#我们只是显示了次数也只是知道了什么时候有次报警,但是具体报警内容并不清楚,如何让报警信息再grafana上面显示呢?
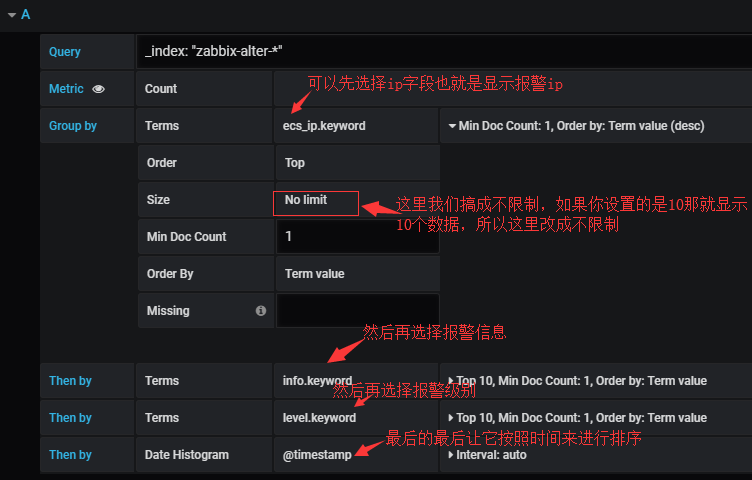
博文来自:www.51niux.com
下面显示结果:
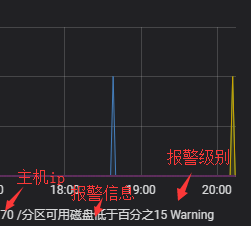
#这有什么好处,这样你就可以很只直观的看到某个时间段都有哪些主机进行了什么报警。
2.4 让报警信息按照饼图统计比例
#显然还不够嗨,我们如果想查看某个时间段不同主机报警信息的比例是多少呢?也就是画个饼图
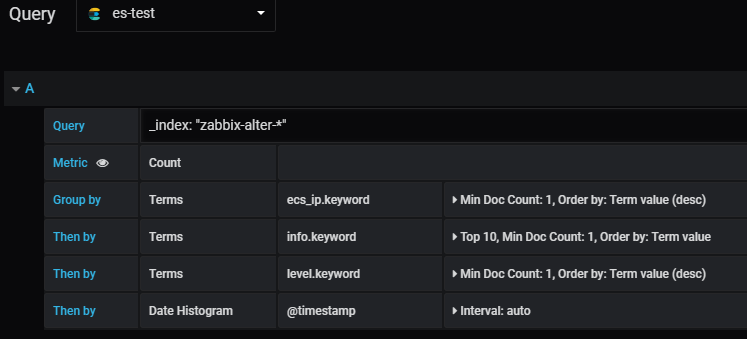
#这里选择的就跟上面一致,当然如果你只是比较某一项,比如ip,info,level那就只留一项就可以了。
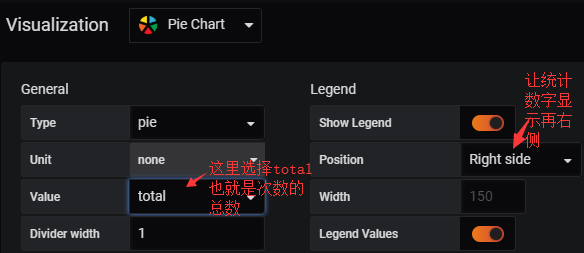
#下面让我们看看效果
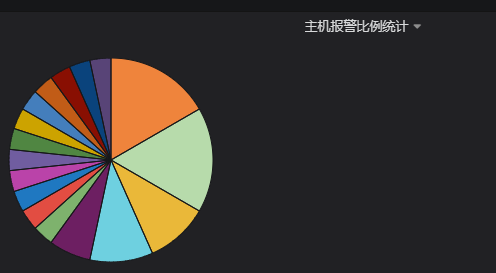
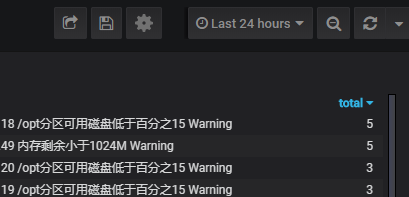
#从上面可以看到左侧是不同报警的百分比右侧是报警项的详细数据。
2.5 多Query和使用Filters
#上面讲述的都是我们没有加Query条件的,如果我们想用ES的Query怎么用呢?
首先先来一个求并集的:
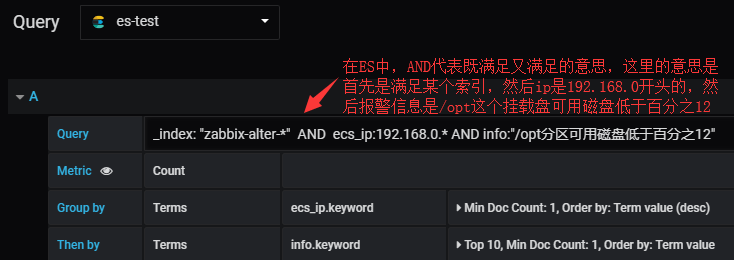
_index: "zabbix-alter-*" AND ecs_ip:192.168.0.* AND info:"/opt分区可用磁盘低于百分之12"
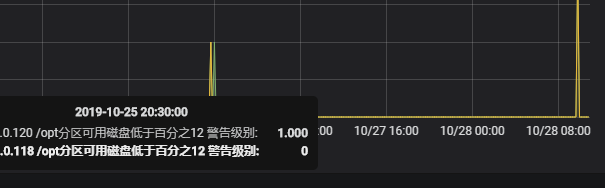
#从上图的效果图可以看到将满足三个条件的数据显示出来了。
然后我们再来一个取或者的:
_index: "zabbix-alter-*" AND ecs_ip:(192.168.0.120|192.168.0.119) AND info:"/opt分区可用磁盘低于*"
#上面一句话的意思,就是只取出磁盘报警的信息并且IP是192.168.120或者192.168.0.119
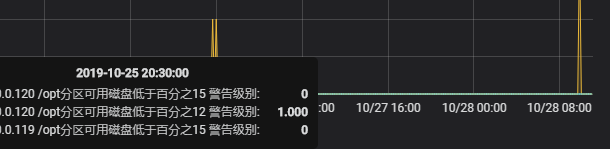
#从上图可以看到只取出了192.168.0.120或者192.168.0.119的报警信息,主要记住如果取或的关系要用()包起来。
最后再来说下Filters:
#上图中为啥有个"警告级别:”呢?

#这句话的意思是将level:Warning匹配到并且再字段后面加上"警告级别:”标记。
#如果我们换成Level:High会怎么样呢?
#如果在报警信息中匹配不到level:HIgh的,报警出图这里就全是0了,但是报警信息还是会有的,只是绘图计数这里为0.
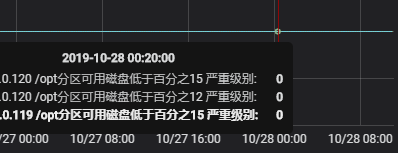
#从上图可以看到,报警信息还是会显示出来的,并且虽然没有匹配上也是会加上严重级别的标记,当然绘图计数那里就是为0.
#如果再加一个Query会怎么样呢?

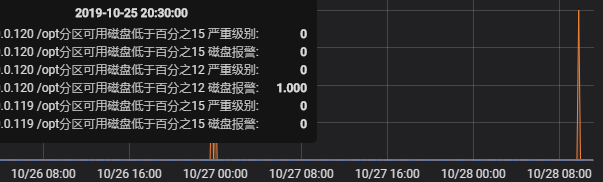
#从上图的结果我们可以得出两个结论,结论一Filters的Query它是或的关系不是与的关系,第二个就是你又多少个Query就会有多少个重复的level,这本来是去重后的三条报警信息,因为我们加了两个Query所以3*2变成了6条,一条严重级别一条磁盘报警。
博文来自:www.51niux.com
2.6 原始文档展示
#如果说有人想看es的原始内容,又不想跳转到kibana上面去查看,就像在grafana上面查看怎么办呢?
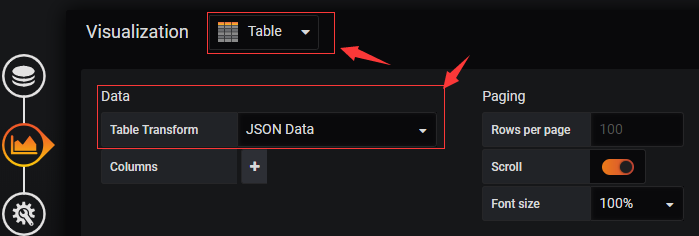
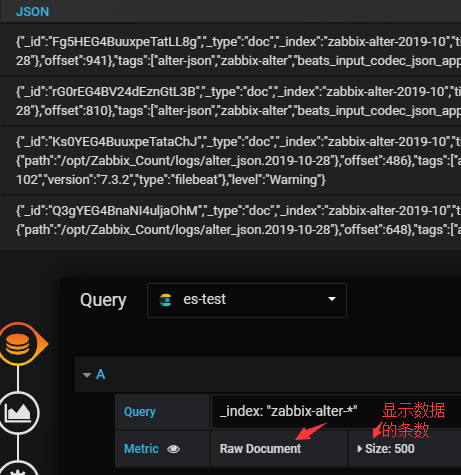
#如上图显示,选择Table面板,然后Metric选择"Raw Document”顾名其意就是原始文档的意思。
我擦这一坨坨的数据,看着也没啥意思啊,我想看一些过滤之后的数据怎么办呢?
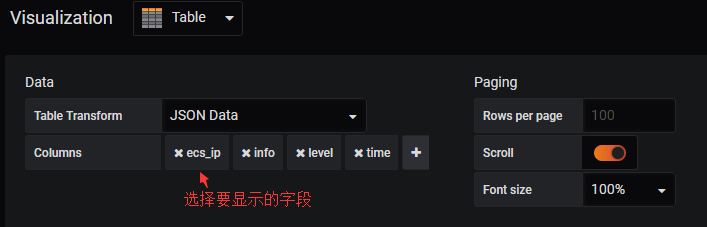

#这下子明显看着要很多了。
2.7 $Filters临时变量
#这个变量一开始你是看不到的,再设置变量那里也没有这个变量,怎么产生的呢?
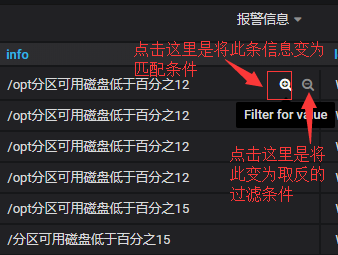
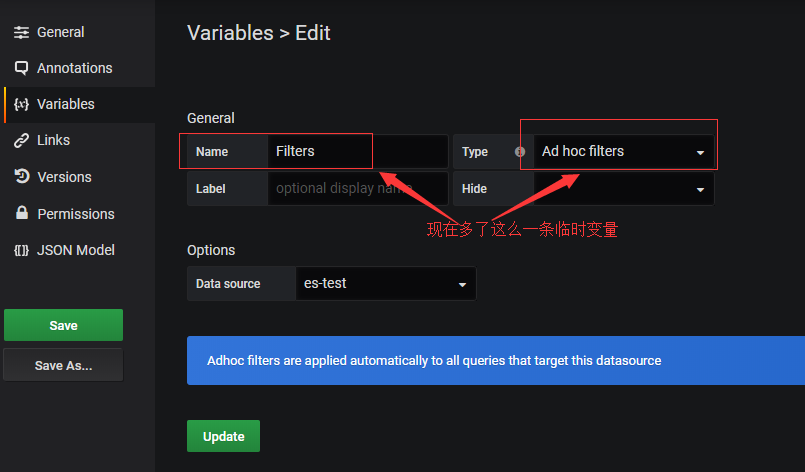
#这个变量有什么用呢?很有用。当你选择了对应的变量,整个dashboard都会引用此变量,比如你只是想查看内存不足的报警,想查看某个IP的报警之类的,只要开启了这个Filters临时变量,整个dashboard中其他的panel都会跟着你的选择而变化。
#这些匹配条件是AND的关系。
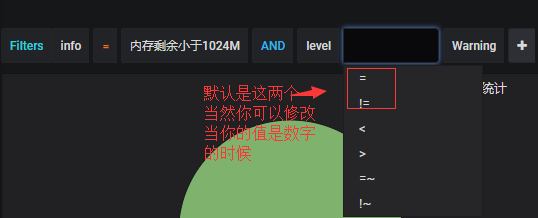
那么我既然可以增加过滤条件,如何删除过滤条件呢?
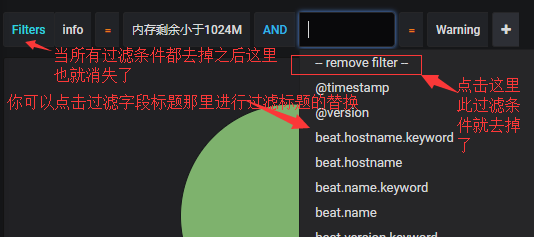
#上图说的Filters那个字段如果过滤条件都去掉之后会消失指的是刷新浏览器页面会消失。
2.8 注意一下Group by
这里简单说几句也是很重要的,Group by不是有个Size吗,比如我想统计某个时间段不同类型的信息分别出现了多少次也就是total,当你选择No limit的时候基本是没问题的会将信息从高到低进行排序,但是当你选择10,20之类的,当你的类型去重之后的总数大于这个Size值的时候,你所选择的类型和数值要比实际少很多,这里是要特别注意下的,所以如果数据量不大尽量选择No limit这样对你的数据统计影响不大。
还有就是Order By那里不是有一个Term value和Doc Count吗,如果你还是想选择Size,比如你可能要列出100条数据,你就想列出top10,那么久选择Doc Count就可以了,这样数据也是对的,而且也只会显示你列的top数。

官网资料比较少,我这只是通过现象推导出来的结论,如果有不对的地方还望指正。
#还有如果你想将某一个小时的次数合并之类的,比如你想让报警数按小时来统计显示:
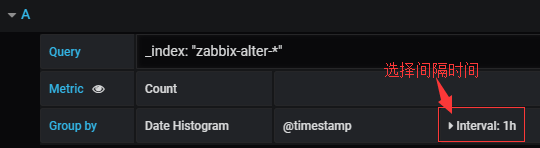
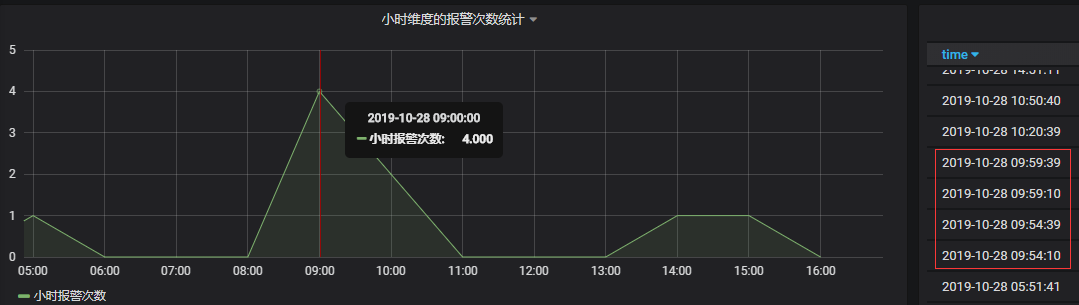
#从上图的报警结果来看是对的上的,9点到10点确实发生了四次报警。
2.9 按照部门显示报警信息统计
#好的我们已经针对报警信息进行了一些展示,但是还有个问题,上面是把所有部门的报警信息一起展示的,现在有个新的需求确实也是一个很正常的需求。比如我是A部门的我就只想看我们自己部门的主机报警不想看到其他部门的。
#好了针对这个需求我们应该怎么设计呢,首先在存储es的时候再加一个关于部门的字段?这样其实就是把部门写死了,万一主机发生了部门的变化,那就不准了,所以部门应该是一个动态的。那应该怎么搞?之前再说falcon的时候我说过,变量和源其实是两回事,我们可以用zabbix的源做成变量交给其他源进行引用使用。
#可能有点乱,让我们用实际的操作来展示一下。
首先添加两个变量:
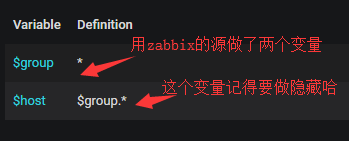
#上面第二个host变量只选择开启ALL就行了,这样当我们选择一个部门的时候默认就是选择ALL所有主机。

panel进行修改:
#如果已经做了panel,那么所有的panel都要进行修改。

_index: "zabbix-alter-*" AND ecs_ip:$host
#那么多个IP之间就是OR的关系了,类似于:
query":"_index: \"zabbix-alter-*\" AND ecs_ip:(\"192.168.1.101\" OR \"192.168.1.102\" )"
#这样就实现了根据你group这个变量选择不同的部门,来进行ip变量传参来显示指定部门的报警统计,这样我们也把es怎么使用变量用起来了。
2.10 简单记录下这数据怎么来的(可忽略)
#把zabbix的报警信息展示出来做个统计,这样方便报警回查,但是查询mysql显然不太好,就写了个程序读取zabbix的数据库将报警信息转换成了json格式,然后通过filebeat=>logstash=>es。当然还有logstash使用jdbc的方式:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html
mysql的jar包下载地址:https://downloads.mysql.com/archives/c-j/
采集端的处理:
mysql查询语句:
sql = 'select message from alerts where status=1 and clock>=%s and clock<%s and p_eventid is NULL;' %(old_time,now_time)
下面是程序根据数据库中返回的信息经过处理后,产生的文件中的json格式样例:
{"ecs_ip": " 192.168.1.164", "level": "Warning", "info": "报警信息", "time": "2021-01-16 13:07:27"}filebeat的简单配置:
# cat beats/filebeat.yaml
filebeat.inputs: - input_type: log enabled: true paths: - /opt/Zabbix_Count/logs/alter_json.* tags: ["alter-json","zabbix-alter"] scan_frequency: 30s ignore_older: 48h clean_inactive: 72h output.logstash: hosts: ["192.168.1.165:5066"] loadbalance: true compression_level: 6 name: "192.168.1.101"
接收端的处理:
# cat logstash/conf/logstash-alter.conf
input {
beats {
host => "192.168.1.165"
port => 5066
codec => "json"
}
}
filter {
date {
match => [ "time", "yyyy-MM-dd HH:mm:ss"]
}
}
output {
#stdout { codec => rubydebug }
if "zabbix-alter" in [tags]{
elasticsearch {
action => "index"
hosts => ["192.168.1.164:9200","192.168.1.165:9200","192.168.1.166:9200"]
index => "zabbix-alter-%{+YYYY-MM}"
}
}
}