Centos7.2 KVM的搭建(三)之常用操作
前面两篇文章针对KVM介绍和一些常用命令做了介绍,这篇文章记录一下可能用到的操作和注意事项。
一、Virtio半虚拟化驱动
1.1 半虚拟化网卡
介绍:
要使用Virtio必须要在宿主机和客户机中分别安装Virtio驱动,Linux内核从2.6.24开始支持Virtio,现在Linux发行版都自带Virtio驱动模块。Window版需要安装驱动。
# grep -i Virtio /boot/config-3.10.0-327.el7.x86_64 #可以通过此命令查看,如果有输出则表示支持
CONFIG_VIRTIO_BLK=m
CONFIG_SCSI_VIRTIO=m
CONFIG_VIRTIO_NET=m
CONFIG_VIRTIO_CONSOLE=m
CONFIG_HW_RANDOM_VIRTIO=m
CONFIG_VIRTIO=m
# Virtio drivers
CONFIG_VIRTIO_PCI=m
CONFIG_VIRTIO_PCI_LEGACY=y
CONFIG_VIRTIO_BALLOON=m
CONFIG_VIRTIO_INPUT=m
# CONFIG_VIRTIO_MMIO is not set
配置半虚拟化网卡(创建的时候就可以指定模式为virtio,在之前的文章里面已经提到了):
第一种方法:
使用Libvirt管理虚拟机,修改虚拟机的xml配置文件:
<interface type='bridge'>
<mac address='52:54:00:97:31:d7'/>
<source bridge='br0'/>
<model type='virtio'/> #指定使用Virtio网卡,默认是8139的全虚拟化网卡为百兆网卡,e1000模拟的是Intel公司的千兆网卡。
<driver name='vhost' queues='8'/> #name='vhost'表示网卡使用vhost_net技术,vhost_net技术使虚拟机的网络绕过用户空间的虚拟化层,可以直接和内核通信,从而提高虚拟机的网络性能,但是必须使用Virtio网卡才行。
<address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
</interface>
第二种方法:
就是通过VNC的图形化管理使用virt-manager来修改:

window网卡使用virtio的操作(windows使用的是e1000的全虚拟化网卡):
windows默认没有此驱动,可以通过:https://fedorapeople.org/groups/virt/virtio-win/direct-downloads/或者https://fedoraproject.org/wiki/Windows_Virtio_Drivers#Direct_download
下载iso的驱动包,然后挂载到windows虚拟机上面以光盘的形式(如何通过光盘更新驱动的形式我就不说了)。


但是硬盘驱动对于版本来说还是又要求的,上面是用的0.1-81版本的,但是用0.1-96版本以上的就又找不到驱动了,所以对于windows要使用virtio硬盘来说,驱动软件的版本也是有要求的。

上面是virtio-win-0.1.96.iso要寻找的驱动路径,2k8R2就是我要装的虚拟机的操作系统为windows-server2008 R2版的。
1.2 半虚拟化硬盘
如果操作系统是linux操作系统,就不做说明了,在创建的时候指定格式为Virtio就可以了,这里主要是说一下windows系统。我们再创建的时候就要将磁盘格式修改为Virtio,不能像网卡那样进入系统再去创建。
当然还是在安装系统的时候将我们下载的驱动光盘镜像也挂载上,但是有一点不同的是,直接扫描光盘不行会提示你找不到驱动,要指定到特定的目录才可以加载磁盘镜像文件。下面的图为我们要进入到的目录以及选择的驱动。

博文来自:www.51niux.com
二、SR-IOV 虚拟化技术
2.1 介绍
首先要提到的是网卡PCI Passthrough技术,通过此技术可以将物理网卡直接分配给虚拟机使用,虚拟机单独使用网卡,可以达到几乎和物理网卡一样的性能(跳过了虚拟网卡,虚拟化层,内核网桥层)。
虚拟机直接绑定物理网卡过程(虚拟机独占一块物理网卡):
# lspci |grep Eth #找到网卡的PCI信息
01:00.0 Ethernet controller: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe
01:00.1 Ethernet controller: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe
02:00.0 Ethernet controller: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe
02:00.1 Ethernet controller: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe
04:00.0 Ethernet controller: Intel Corporation Ethernet 10G 2P X520 Adapter (rev 01)
04:00.1 Ethernet controller: Intel Corporation Ethernet 10G 2P X520 Adapter (rev 01)
# virsh nodedev-list --tree|grep 04 #根据网卡pci心里里面的关键字再过滤出网卡的PCI名称
| +- net_em4_c8_1f_66_d8_65_04
| +- pci_0000_04_00_0 #这个和下面的明显是万兆网卡的PCI名称
| +- pci_0000_04_00_1
# virsh nodedev-dumpxml pci_0000_04_00_0 #virsh nodedev-dumpxml PCI名称 可以得到的详细的设备XML配置信息
编辑虚拟机的xml文件,加入PCI设备信息:
<hostdev mode='subsystem' type='pci' managed='yes'>
<source>
<address domain='0x0000' bus='0x04' slot='0x00' function='0x0' />
</source>
</hostdev>
上面那种技术一般不会用到,但是SR-IOV这种虚拟化技术挺好的。
这个技术具体的技术可以上网搜索,简单来说就是一块物理网卡,可以开多个VFs(只有轻量级的PCI-E功能,只包含数据传输必要的资源)实例。
2.2 SR-IOV操作(以网卡举例主要也是应用在网卡上)
第一步:
主板集成的网卡一般BIOS里面的SR-IOV功能是关闭的。当然不开启也是能使用的,但是一定要开启啊,不然你在使用中可能会出现更改完内存,CPU的配置等启动时间特别漫长或者崩溃啊等其他的一些原因。





第二步:
查看网卡是否支持SR-IOV模式
# lspci|grep Eth #看出我们系统除了自带的四块千兆网卡以外,还有另外两块加的万兆网卡
01:00.0 Ethernet controller: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe
01:00.1 Ethernet controller: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe
02:00.0 Ethernet controller: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe
02:00.1 Ethernet controller: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe
04:00.0 Ethernet controller: Intel Corporation Ethernet 10G 2P X520 Adapter (rev 01)
04:00.1 Ethernet controller: Intel Corporation Ethernet 10G 2P X520 Adapter (rev 01)
# lspci -v -s 04:00.0 #先查看一下万兆网卡是否支持SR-IOV
04:00.0 Ethernet controller: Intel Corporation Ethernet 10G 2P X520 Adapter (rev 01)
Subsystem: Intel Corporation 10GbE 2P X520 Adapter
Flags: bus master, fast devsel, latency 0, IRQ 47, NUMA node 0
Memory at d9d00000 (64-bit, non-prefetchable) [size=1M]
I/O ports at ecc0 [size=32]
Memory at d9ff8000 (64-bit, non-prefetchable) [size=16K]
Expansion ROM at d9000000 [disabled] [size=512K]
Capabilities: [40] Power Management version 3
Capabilities: [50] MSI: Enable- Count=1/1 Maskable+ 64bit+
Capabilities: [70] MSI-X: Enable+ Count=64 Masked-
Capabilities: [a0] Express Endpoint, MSI 00
Capabilities: [e0] Vital Product Data
Capabilities: [100] Advanced Error Reporting
Capabilities: [140] Device Serial Number a0-36-9f-ff-ff-80-7c-50
Capabilities: [150] Alternative Routing-ID Interpretation (ARI)
Capabilities: [160] Single Root I/O Virtualization (SR-IOV) #因为有SR-IOV的标志,这里表示此网卡支持SR-IOV
Kernel driver in use: ixgbe
Kernel modules: ixgbe
# lspci -v -s 01:00.0 #查看一下我们服务器的千兆网卡是否支持SR-IOV模式
01:00.0 Ethernet controller: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe
Subsystem: Dell Device 1f5b
Flags: bus master, fast devsel, latency 0, IRQ 33, NUMA node 0
Memory at d51a0000 (64-bit, prefetchable) [size=64K]
Memory at d51b0000 (64-bit, prefetchable) [size=64K]
Memory at d51c0000 (64-bit, prefetchable) [size=64K]
Expansion ROM at d8800000 [disabled] [size=256K]
Capabilities: [48] Power Management version 3
Capabilities: [50] Vital Product Data
Capabilities: [58] MSI: Enable- Count=1/8 Maskable- 64bit+
Capabilities: [a0] MSI-X: Enable+ Count=17 Masked-
Capabilities: [ac] Express Endpoint, MSI 00
Capabilities: [100] Advanced Error Reporting
Capabilities: [13c] Device Serial Number 00-00-c8-1f-66-d8-65-01
Capabilities: [150] Power Budgeting <?>
Capabilities: [160] Virtual Channel #没有SR-IOV标志输出,可见服务器只带的BCM5720不支持SR-IOV。
Kernel driver in use: tg3
Kernel modules: tg3
第三步:
加载SR-IOV内核模块
# ethtool -i p5p1|grep driver #首先要判断网卡模块,我这是万兆的网卡,如果千兆的网卡一般为igb
driver: ixgbe
# modprobe -r ixgbe && modprobe ixgbe max_vfs=7 && /etc/init.d/network restart & #要先先删除模块再重新加载才能生效,直接加载是不生效的,放到后台是为了modprobe -r ixgbe导致网络中断而连不上服务器。
# lspci -Dnn|grep Eth #再次查看,会发现出现了好多模式出来的VF网卡。一个网卡最大是7个,两个网卡加起来正好是14个VF。
0000:01:00.0 Ethernet controller [0200]: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe [14e4:165f]
0000:01:00.1 Ethernet controller [0200]: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe [14e4:165f]
0000:02:00.0 Ethernet controller [0200]: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe [14e4:165f]
0000:02:00.1 Ethernet controller [0200]: Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet PCIe [14e4:165f]
0000:04:00.0 Ethernet controller [0200]: Intel Corporation Ethernet 10G 2P X520 Adapter [8086:154d] (rev 01)
0000:04:00.1 Ethernet controller [0200]: Intel Corporation Ethernet 10G 2P X520 Adapter [8086:154d] (rev 01)
0000:04:10.0 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:10.1 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:10.2 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:10.3 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:10.4 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:10.5 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:10.6 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:10.7 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:11.0 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:11.1 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:11.2 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:11.3 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:11.4 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
0000:04:11.5 Ethernet controller [0200]: Intel Corporation 82599 Ethernet Controller Virtual Function [8086:10ed] (rev 01)
但是上面只是临时生效的方法,如果想要永久生效的方法就是:
# echo "options modprobe ixgbe max_vfs=7" >>/etc/modprobe.d/ixgbe.conf #如果是igb模块就是echo "options modprobe igb max_vfs=7" >>/etc/modprobe.d/igb.conf
当然我们也可以加入的支持IOMMU的支持(非必须)在/etc/grub.conf的kernel的尾部加上intel_iommu=on,这就需要重启操作系统了,如下方:
#cat /etc/grub.conf |grep intel #intel_iommu=on 基于 Intel 的系统 amd_iommu=on 基于 AMD 的系统
kernel /vmlinuz-2.6.32-358.el6.x86_64 ro root=/dev/mapper/VolGroup-LogVol01 rd_NO_LUKS rd_NO_MD rd_LVM_LV=VolGroup/LogVol01 rd_LVM_LV=VolGroup/LogVol00 crashkernel=auto.UTF-8 KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet intel_iommu=on
注:如果是Centos7系统的话执行命令:# grubby --update-kernel=ALL --args="intel_iommu=on" ,/boot/efi/EFI/centos/grub.cfg文件会发生更改,linuxefi开头的行会发生更改。
IOMMU的虚拟化技术的优点:
Guest OS直接被分配到实际的Device;
用户空间的应用程序可以直接访问Device;
增强了安全性:1)增加了Device对地址空间的访问控制;2)创建I/O保护域;
增强了可靠性:1)Device之间是独立,互不干扰;2) 保护系统内存不被不明的Device读/写;
支持可信任的输入/输出:在Device和Driver之间创建了保护通道
让传统32位PCI设备能够访问可寻址范围之外的系统内存区域,并且避免使用Bounce Buffer
注:
一般使用ixgbe的万兆的网卡是最多支持63个VF,像igb驱动的I350等千兆网卡支持最多7个VF:
# modinfo ixgbe|grep parm:
parm: max_vfs:Maximum number of virtual functions to allocate per physical function - default is zero and maximum value is 63 (uint)
parm: allow_unsupported_sfp:Allow unsupported and untested SFP+ modules on 82599-based adapters (uint)
parm: debug:Debug level (0=none,...,16=all) (int)
第四步:子网卡的查看
# ls -l /sys/bus/pci/devices/0000\:04\:*/*|grep phy #通过设备PCI号来查看虚拟网卡所对应的物理网卡的PCI号
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:10.0/physfn -> ../0000:04:00.0
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:10.1/physfn -> ../0000:04:00.1
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:10.2/physfn -> ../0000:04:00.0
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:10.3/physfn -> ../0000:04:00.1
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:10.4/physfn -> ../0000:04:00.0
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:10.5/physfn -> ../0000:04:00.1
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:10.6/physfn -> ../0000:04:00.0
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:10.7/physfn -> ../0000:04:00.1
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:11.0/physfn -> ../0000:04:00.0
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:11.1/physfn -> ../0000:04:00.1
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:11.2/physfn -> ../0000:04:00.0
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:11.3/physfn -> ../0000:04:00.1
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:11.4/physfn -> ../0000:04:00.0
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:11.5/physfn -> ../0000:04:00.1
# ls -l /sys/bus/pci/devices/0000\:04\:00.0/virtfn* #当然也可以直接通过物理网卡来查看
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:00.0/virtfn0 -> ../0000:04:10.0
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:00.0/virtfn1 -> ../0000:04:10.2
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:00.0/virtfn2 -> ../0000:04:10.4
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:00.0/virtfn3 -> ../0000:04:10.6
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:00.0/virtfn4 -> ../0000:04:11.0
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:00.0/virtfn5 -> ../0000:04:11.2
lrwxrwxrwx. 1 root root 0 Feb 21 11:07 /sys/bus/pci/devices/0000:04:00.0/virtfn6 -> ../0000:04:11.4
第五步:
在宿主机上隐藏子网卡。(使用pci_stub内置内核模块来对VF进行隐藏,可以让宿主机和未分配该设备的客户机都无法使用该设备,达到隔离和安全使用的目的。)
# dmesg |grep DMAR -i #通过内核打印信息来检查VT-d是否处于打开可用状态,如下所示
[ 0.000000] ACPI: DMAR 00000000cd3346f4 000F0 (v01 DELL PE_SC3 00000001 DELL 00000001)
[ 0.034687] DMAR: Host address width 46
[ 0.034688] DMAR: DRHD base: 0x000000dc900000 flags: 0x1
[ 0.034695] DMAR: dmar0: reg_base_addr dc900000 ver 1:0 cap d2078c106f0466 ecap f020de
[ 0.034696] DMAR: RMRR base: 0x000000cf458000 end: 0x000000cf46ffff
[ 0.034697] DMAR: RMRR base: 0x000000cf450000 end: 0x000000cf450fff
[ 0.034699] DMAR: RMRR base: 0x000000cf452000 end: 0x000000cf452fff
[ 0.034700] DMAR: ATSR flags: 0x0
[ 0.034702] DMAR-IR: IOAPIC id 0 under DRHD base 0xdc900000 IOMMU 0
[ 0.034703] DMAR-IR: IOAPIC id 1 under DRHD base 0xdc900000 IOMMU 0
[ 0.034704] DMAR-IR: HPET id 0 under DRHD base 0xdc900000
[ 0.034706] DMAR-IR: x2apic is disabled because BIOS sets x2apic opt out bit.
[ 0.034707] DMAR-IR: Use 'intremap=no_x2apic_optout' to override the BIOS setting.
[ 0.034895] DMAR-IR: Enabled IRQ remapping in xapic mode
# dmesg |grep IOMMU -i #这是IOMMU未打开状态
[ 0.034702] DMAR-IR: IOAPIC id 0 under DRHD base 0xdc900000 IOMMU 0
[ 0.034703] DMAR-IR: IOAPIC id 1 under DRHD base 0xdc900000 IOMMU 0
# dmesg |grep IOMMU -i #这是IOMMU打开状态
[ 0.000000] Command line: BOOT_IMAGE=/vmlinuz-3.10.0-514.2.2.el7.x86_64 root=/dev/mapper/centos-root ro rd.lvm.lv=centos/root rhgb quiet.UTF-8 intel_iommu=on
[ 0.000000] Kernel command line: BOOT_IMAGE=/vmlinuz-3.10.0-514.2.2.el7.x86_64 root=/dev/mapper/centos-root ro rd.lvm.lv=centos/root rhgb quiet.UTF-8 intel_iommu=on
[ 0.000000] DMAR: IOMMU enabled
[ 0.034727] DMAR-IR: IOAPIC id 0 under DRHD base 0xdc900000 IOMMU 0
[ 0.034728] DMAR-IR: IOAPIC id 1 under DRHD base 0xdc900000 IOMMU 0
[ 0.701130] iommu: Adding device 0000:00:00.0 to group 0
[ 0.701150] iommu: Adding device 0000:00:01.0 to group 1
# grep -i CONFIG_PCI_STUB /boot/config-3.10.0-327.el7.x86_64
CONFIG_PCI_STUB=y #如果配置为y(说明编译进内核,不需要作为模块来加载,就不需要# modprobe pci_stub)
# ls -l /sys/bus/pci/drivers/pci-stub/ #检查pci-stub目录存在说明可以使用pci_stub驱动来隐藏设备
bind new_id remove_id uevent unbind
查看设备的vendor ID和device ID,如下所示:
# lspci -Dn -s 04:11.5
0000:04:11.5 0200: 8086:10ed (rev 01) #0000:04:11.5 表示设备在PCI/PCI-E总线中的具体位置,依次是设备的domain(0000)、bus(04)、slot(11)、function(5),其中domain的值一般为0,设备的vendor ID是“8086”, device ID是10ed
# sh /root/pcistub.sh -h 04:11.5 #这里就直接通过脚本进行更改了,将子网卡04:11.5隐藏
Unbinding 0000:04:11.5 from ixgbevf
Binding 0000:04:11.5 to pci-stub
# lspci -v -s 04:11.5 #查看自网卡
04:11.5 Ethernet controller: Intel Corporation 82599 Ethernet Controller Virtual Function (rev 01)
Subsystem: Intel Corporation Device 7b11
Flags: fast devsel, NUMA node 0
[virtual] Memory at d5418000 (64-bit, prefetchable) [size=16K]
[virtual] Memory at d5518000 (64-bit, prefetchable) [size=16K]
Capabilities: [70] MSI-X: Enable- Count=3 Masked-
Capabilities: [a0] Express Endpoint, MSI 00
Capabilities: [100] Advanced Error Reporting
Capabilities: [150] Alternative Routing-ID Interpretation (ARI)
Kernel driver in use: pci-stub #从ixgbevf变为了pci-stub
Kernel modules: ixgbevf
# sh /root/pcistub.sh -u 04:11.5 -d ixgbevf #这是将自网卡还原会原来的驱动也就是取消隐藏的操作
# ls -l /sys/bus/pci/devices/0000\:04\:*/*|grep driver|grep pci-stub #可以这样查看哪些自网卡被隐藏了
lrwxrwxrwx. 1 root root 0 Feb 21 15:13 /sys/bus/pci/devices/0000:04:11.2/driver -> ../../../../bus/pci/drivers/pci-stub
lrwxrwxrwx. 1 root root 0 Feb 21 15:13 /sys/bus/pci/devices/0000:04:11.3/driver -> ../../../../bus/pci/drivers/pci-stub
lrwxrwxrwx. 1 root root 0 Feb 21 14:59 /sys/bus/pci/devices/0000:04:11.4/driver -> ../../../../bus/pci/drivers/pci-stub
# virsh nodedev-dumpxml pci_0000_04_11_4 和 # virsh nodedev-dumpxml pci_0000_04_11_5 做比较的话会发现<name>pci-stub</name>和<name>ixgbevf</name>也是一种单独查看是否隐藏的方式
第六步:
虚拟机绑定PCI网卡设备
第一种方法:最简单的方法就是通过VNC连接宿主机通过virt-manager来图形化的为虚拟机添加


第二种办法:在配置文件中添加下面的几句话(以04:11.4举例):
<hostdev mode='subsystem' type='pci' managed='yes'>
<source>
<address domain='0x0000' bus='0x04' slot='0x11' function='0x4'/>
</source>
</hostdev>
第三种方法:用qumu-system命令安装,这里只是记录下安装过程,我也没有用过这个命令安装过。
wget http://download.qemu-project.org/qemu-2.8.0.tar.xz
tar xvJf qemu-2.8.0.tar.xz
cd qemu-2.8.0
./configure
make
make install
安装可能遇到的第一个问题:
# make
(cd /root/qemu-2.8.0/pixman; autoreconf -v --install)
/bin/sh: autoreconf: command not found
make: *** [/root/qemu-2.8.0/pixman/configure] Error 127
解决办法:
# yum install automake
安装可能遇到的第二个问题:
# make
(cd /root/qemu-2.8.0/pixman; autoreconf -v --install)
autoreconf: Entering directory `.'
autoreconf: configure.ac: not using Gettext
autoreconf: running: aclocal
autoreconf: configure.ac: tracing
autoreconf: configure.ac: not using Libtool
autoreconf: running: /usr/bin/autoconf
configure.ac:75: error: possibly undefined macro: AC_PROG_LIBTOOL
If this token and others are legitimate, please use m4_pattern_allow.
See the Autoconf documentation.
autoreconf: /usr/bin/autoconf failed with exit status: 1
make: *** [/root/qemu-2.8.0/pixman/configure] Error 1
make: *** Deleting file `/root/qemu-2.8.0/pixman/configure'
解决办法:
# yum install libtool
注:下面是pcisub.sh脚本的内容:
# cat pcistub.sh
#!/bin/bash
#A script to hide/unhide PCI/PCIe device for KVM (using 'pci_stub' driver)
#author: Jay <smile665@gmail.com>
ide_dev=0
nhide_dev=0
river=0
#check if the device exists
function dev_exist()
{
local line_num=$(lspci -s "$1" 2>/dev/null | wc -l)
if [ $line_num = 0 ]; then
echo "Device $pcidev doesn't exists. Please check your system or your command line."
exit 1
else
return 0
fi
}
# output a format "<domain>:<bus>:<slot>.<func>" (e.g. 0000:01:10.0) of device
function canon()
{
f=`expr "$1" : '.*\.\(.\)'`
d=`expr "$1" : ".*:\(.*\).$f"`
b=`expr "$1" : "\(.*\):$d\.$f"`
if [ `expr "$d" : '..'` == 0 ]
then
d=0$d
fi
if [ `expr "$b" : '.*:'` != 0 ]
then
p=`expr "$b" : '\(.*\):'`
b=`expr "$b" : '.*:\(.*\)'`
else
p=0000
fi
if [ `expr "$b" : '..'` == 0 ]
then
b=0$b
fi
echo $p:$b:$d.$f
}
# output the device ID and vendor ID
function show_id()
{
lspci -Dn -s "$1" | awk '{print $3}' | sed "s/:/ /" > /dev/null 2>&1
if [ $? -eq 0 ]; then
lspci -Dn -s "$1" | awk '{print $3}' | sed "s/:/ /"
else
echo "Can't find device id and vendor id for device $1"
exit 1
fi
}
# hide a device using 'pci_stub' driver/module
function hide_pci()
{
local pre_driver=NULL
local pcidev=$(canon $1)
local pciid=$(show_id $pcidev)
dev_exist $pcidev
if [ -h /sys/bus/pci/devices/"$pcidev"/driver ]; then
pre_driver=$(basename $(readlink /sys/bus/pci/devices/"$pcidev"/driver))
echo "Unbinding $pcidev from $pre_driver"
else
echo "$pcidev wasn't bound to any drirver"
fi
echo -n "$pciid" > /sys/bus/pci/drivers/pci-stub/new_id
echo -n "$pcidev" > /sys/bus/pci/devices/"$pcidev"/driver/unbind
echo "Binding $pcidev to pci-stub"
echo -n "$pcidev" > /sys/bus/pci/drivers/pci-stub/bind
return $?
}
# unhide a device from 'pci_stub' driver and bind it to a new driver
function unhide_pci()
{
local driver=$2
local pcidev=$(canon $1)
local pciid=$(show_id $pcidev)
local pre_driver=NULL
dev_exist $pcidev
if [ $driver != 0 -a ! -d /sys/bus/pci/drivers/$driver ]; then
echo "No $driver interface under sys. Failed."
exit 1
fi
if [ -h /sys/bus/pci/devices/"$pcidev"/driver ]; then
pre_driver=$(basename $(readlink /sys/bus/pci/devices/"$pcidev"/driver))
if [ "$pre_driver" = "$driver" ]; then
echo "$1 has been already bound with $driver, no need to unhide and bind."
exit 1
elif [ "$pre_driver" != "pci-stub" ]; then
echo "$1 is not bound with pci-stub, it is bound with $pre_driver, no need to unhide"
exit 1
else
echo "Unbinding $pcidev from $pre_driver"
if [ $driver != 0 ]; then
echo -n "$pciid" > /sys/bus/pci/drivers/$driver/new_id
fi
echo -n "$pcidev" > /sys/bus/pci/drivers/pci-stub/unbind
if [ $? -ne 0 ]; then
return $?
fi
fi
fi
if [ $driver != 0 ]; then
echo "Binding $pcidev to $driver"
echo -n "$pcidev" > /sys/bus/pci/drivers/$driver/bind
fi
return $?
}
# show the usage of this script
function usage()
{
echo "Usage: pcistub -h pcidev [-u pcidev] [-d driver]"
echo " -h pcidev: <pcidev> is BDF number of the device you want to hide"
echo " -u pcidev: Optional. <pcidev> is BDF number of the device you want to unhide."
echo
" -d driver: Optional. When unhiding the device, bind the device with
<driver>. The option should be used together with '-u' option"
echo ""
echo "Example1: sh pcistub.sh -h 06:10.0 # Hide device 01:10.0 to 'pci_stub' driver"
echo "Example2: sh pcistub.sh -u 08:00.0 -d e1000e # Unhide device 08:00.0 and bind the device with 'e1000e' driver"
exit 1
}
if [ $# -eq 0 ] ; then
usage
fi
# parse the options in the command line
OPTIND=1
while getopts ":h:u:d:" Option
do
case $Option in
h ) hide_dev=$OPTARG;;
u ) unhide_dev=$OPTARG;;
d ) driver=$OPTARG;;
* ) usage ;;
esac
done
if [ ! -d /sys/bus/pci/drivers/pci-stub ]; then
modprobe pci_stub
if [ ! -d /sys/bus/pci/drivers/pci-stub ]; then
echo "There's no 'pci-stub' module? Please check your kernel config."
exit 1
fi
fi
if [ $hide_dev != 0 && $unhide_dev != 0 ]
then
echo "Do not use -h and -u option together."
exit 1
fi
if [ $unhide_dev = 0 && $driver != 0 ]
then
echo "You should set -u option if you want to use -d option to unhide a device and bind it with a specific driver"
exit 1
fi
if [ $hide_dev != 0 ]; then
hide_pci $hide_dev
elif [ $unhide_dev != 0 ]; then
unhide_pci $unhide_dev $driver
fi
exit $?博文来自:www.51niux.com
三、 磁盘缓存方式
磁盘I/O从虚拟机到宿主机物理存储的历程:
应用程序==》虚拟机文件系统或者块设备==》虚拟机磁盘驱动==》虚拟化层==》虚拟机镜像==》宿主机文件系统或者块设备==》宿主机磁盘

上图就是虚拟机磁盘的缓存模式,也就是虚拟化层和宿主机的文件系统或者块设备打开或关闭缓存的各种组合。在CentosOS上虚拟机默认的缓存模式为none。
当前只有raw、qcow2、qed的镜像格式支持在线迁移。如果没使用集群文件系统的话,只有none模式支持在线迁移。但是virsh命令使用unsafe参数或者使用API,可以强制在线迁移。

none模式要求I/O方式设为为aio=native模式。如果是其他缓存模式,I/O方式会静默切换为aio=threads。KVM虚拟机可以使用fdatasync()方式实现再宿主机上刷盘。
各种缓存方式的应用场景:
none模式:I/O直接再QEMU-KVM的用户空间缓存和宿主机设备间发生。虚拟机的存储控制器被告知有回写缓存,虚拟机会发出刷盘命令,相当于直接访问主机的磁盘。用于需要虚拟机在线迁移的环境,主要是虚拟化集群。
writethrough模式:透过缓存,虚拟机的磁盘驱动告知虚拟机没有回写缓存,不需要发出刷盘命令以保持数据一致性,数据只有合并并写入存储设备才会返回成功报告。用于单机虚拟化,突然断电不会造成数据丢失。
writeback模式:使用宿主机的页面缓存。测试环境可以考虑这种模式,如果再脏数据没有刷盘的时候宿主机停电,有可能造成虚拟机数据丢失,脏数据的刷盘周期取决于文件系统的配置,如:ext4文件系统默认刷盘周期是五秒。
directsync模式:类似于writethough模式,绕过宿主机的页面缓存,只有数据被合并并写入存储设备才会报告操作成功。
unsafe模式:虚拟机所有的刷盘指令会被忽略。性能好但不安全,只有再虚拟机的进程结束的时候,宿主机才会执行刷盘动作。
四、虚拟机磁盘的动态扩展
之前生产环境中使用的是lvm,lvm可以动态的进行调整,也可以做快照,一般我们都是300G的sas盘,如果虚拟机对硬盘没需求的话就直接将一个单盘做成一个lvm组分给虚拟机使用,也相当于单盘创建虚拟机,如果对磁盘需要比较大的话,如,可以用两块盘做成一个lvm卷组分给虚拟机。但是这种方式真的很恶不推荐使用,因为每次更换硬盘都很麻烦不然lvm配置信息就会有错误了,如果误拔硬盘,再插回去做了lvm的硬盘直接就读写错误了。
所以还是推荐宿主机不要做lvm,正常的做raid就行了。不确定磁盘后续是否要调整的虚拟机也是用的lvm,这样如果虚拟机如果涉及到扩容,也能动态的对虚拟机磁盘进行扩容。可以采取虚拟机上面是lvm,空间要不够了再添加一块磁盘上去,然后还是用lvm扩充就可以了。
另外:宿主机通过virt-manager的命令可以动态的添加和删除磁盘设备和网卡设备。
我这里先说一种
宿主机给虚拟机新添加一块硬盘,虚拟机扩容的方式(这种方式就需要虚拟机重启):
宿主机的操作:
# qemu-img create -f qcow2 /KVM/data12/192.168.1.125_add.img 20G #先创建一个新的img镜像
# virsh edit 192.168.1.125 #添加下面一段话
<disk type='file' device='disk'> <driver name='qemu' type='qcow2'/> <source file='/KVM/data12/192.168.1.125_add.img'/> <target dev='vda' bus='virtio'/> </disk>
# virsh destroy 192.168.1.125 #虚拟机自己shutdown和reboot是不会生效的,需要在宿主机强制关掉域再运行域
Domain 192.168.1.125 destroyed
# virsh start 192.168.1.125
Domain 192.168.1.125 started
虚拟机的操作:
# pvcreate /dev/vdb
# vgextend VolGroup /dev/vdb
# lvextend -L +19G -n /dev/mapper/VolGroup-LogVol00 /dev/vdb
# fsck -f /dev/VolGroup/LogVol00
# resize2fs /dev/VolGroup/LogVol00
# df -h #虚拟机成功扩容
文件系统 容量 已用 可用 已用%% 挂载点
/dev/mapper/VolGroup-LogVol00
37G 1022M 34G 3% /
tmpfs 939M 0 939M 0% /dev/shm
/dev/vda1 194M 27M 157M 15% /boot
第二种:
通过命令为虚拟机动态添加硬盘
宿主机的操作:
# qemu-img create -f qcow2 -o preallocation=falloc /var/lib/libvirt/images/192.168.1.125-4.qcow2 20G #提前创建一块20G的img硬盘镜像
# virsh attach-disk 192.168.1.125 /var/lib/libvirt/images/192.168.1.125-4.qcow2 vde #动态的为192.168.1.125的虚拟机添加一块硬盘并将磁盘名称命令为vde,但是这种方式虚拟机重启后配置就消失了。
(# virsh detach-disk 192.168.1.125 vde #这个命令为动态缩减命令,动态的删除虚拟机域的某一块盘符)
Disk attached successfully #提示都是相同的
# virsh dumpxml 192.168.1.125|grep -B 4 -A 3 vdd|egrep -v 'backingStore|alias' #将现在的192.168.1.125域的配置导出一份进行查看,找到新添加那边vde磁盘的配置
# virsh edit 192.168.1.125 或者 # vi /etc/libvirt/qemu/192.168.1.125.xml 在上一块磁盘的配置下面,添加下面的配置文件
<disk type='file' device='disk'> <driver name='qemu' type='qcow2'/> <source file='/var/lib/libvirt/images/192.168.1.125-4.qcow2'/> <target dev='vde' bus='virtio'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x0b' function='0x0'/> </disk>
在虚拟机上面的操作:
更上面第一种方法虚拟机的操作一致了,将新盘符/dev/vde添加到lvm卷组里面去。(/dev/hda是IDE标识,/dev/sda是SATA硬盘标识,/dev/vda是virtio_blk驱动标识)
第三种:
也是需要关闭虚拟机(不是虚拟机自动重启,虚拟机reboot是不会生效的,虚拟机shutdown再启动倒是可以生效),通过调整单个img的方式来对虚拟机进行扩容:
宿主机的操作:
# qemu-img resize 192.168.1.125.img 40G
# virsh destroy 192.168.1.125
# virsh start 192.168.1.125
虚拟机的操作:
# df -h #查看现在的根分区为9G左右
文件系统 容量 已用 可用 已用%% 挂载点
/dev/mapper/kvm-lvm1 8.7G 994M 7.3G 12% /
tmpfs 939M 0 939M 0% /dev/shm
/dev/vda1 194M 27M 157M 15% /boot
# fdisk /dev/vda #因为我们之前的分区已经分好了,现在磁盘扩容了30G进来,但是我又不想做调整分区表这样比较有风险的操作,那我就是再重新创建一个/dev/sda4的分区并入到lvm卷组里面了。下面为主要操作:
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
First cylinder (1-83220, default 1): 4
First cylinder (20806-83220, default 20806):
Last cylinder, +cylinders or +size{K,M,G} (20806-83220, default 83220):
Command (m for help): w
因为有提示:
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: 设备或资源忙.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
结果你会发现/dev/vda4没有出现,但是fdisk -l /dev/vda却能看到/dev/vda4(虚拟机这样,物理机不会这样)。
# partx -a /dev/vda #执行此命令将新创建的分区添加到分区表里面去。 或者使用:#partprobe 此命令可以使kernel重新读取分区信息,从而避免重启系统。
BLKPG: Device or resource busy
error adding partition 1
BLKPG: Device or resource busy
error adding partition 2
BLKPG: Device or resource busy
error adding partition 3
[root@localhost ~]# ls -l /dev/vd #vda4出现了
vda vda1 vda2 vda3 vda4 vdb vdc vdd vde vdf
#如果将vda4用fdisk删除掉后,可以直接执行# partx -d --nr 4 /dev/vda 直接用ls -l命令就查看不到/dev/vda4了
# pvcreate /dev/vda4
# vgextend kvm /dev/vda4
# lvextend -L +29G -n /dev/mapper/kvm-lvm1 /dev/vda4
# fsck -f /dev/mapper/kvm-lvm1
# resize2fs /dev/mapper/kvm-lvm1
# df -h #再次查看我们的根分区扩容了。
文件系统 容量 已用 可用 已用%% 挂载点
/dev/mapper/kvm-lvm1 38G 1001M 35G 3% /
tmpfs 939M 0 939M 0% /dev/shm
/dev/vda1 194M 27M 157M 15% /boot
注:
1. 如果你不是用virt-manager添加的磁盘的话,而是用上面三种方法命令行搞的话,如果你不把你的virt-manager关闭再重新打开的话,你那里新添加的磁盘磁盘大小是UNKNOW状态或者旧有磁盘的空间是木有变化的。
2. 关闭lvm的写缓存。
# cat /etc/lvm/lvm.conf |grep cache_state
write_cache_state = 1 #让虚拟机使用裸盘可以获得更高的读/写性能,但是如果使用了Lvm建议将lvm cache关闭,防止宿主机突然断电或者虚拟机突然关机造成的数据丢失。默认是开启状态,将1变为0就是关闭写缓存。
3. 如果是windows,直接将虚拟机所在的img文件调整大之后,直接用window自带的扩展卷把剩余的空间填充进来便可。
博文来自:www.51niux.com
第四种:
如果我们的虚拟机没有做lvm如何将根分区扩展呢或者扩展某一个分区呢,还是使用采用红帽子自带的插件virt-resize进行拓展?
# yum -y install libguestfs-tools #安装此工具
# virsh destroy 192.168.1.115 #需要提前关闭虚拟机
# qemu-img create -f qcow2 /KVM/data13/test_extend.img 20G #新建一个比原来大一倍的镜像,这个镜像的大小是你原来镜像打算加到多少G之和。
# virt-resize --expand /dev/vda3 /KVM/data13/192.168.1.115.img /KVM/data13/test_extend.img #使用virt-resize 进行拉升分区
[ 0.0] Examining /KVM/data13/192.168.1.115.img #改名了首先获取原来的分区信息还有其他文件信息。
**********
Summary of changes:
/dev/sda1: This partition will be left alone.
/dev/sda2: This partition will be left alone.
/dev/sda3: This partition will be resized from 8.8G to 18.8G. The #然后对新的镜像文件进行重新分区、格式化。我们看到sda3分区从8.8G变为了18.8G。
filesystem ext4 on /dev/sda3 will be expanded using the 'resize2fs' method.
**********
[ 3.1] Setting up initial partition table on /KVM/data13/test_extend.img #最后拷贝原镜像中的文件到新文件系统中。
[ 3.4] Copying /dev/vda1
[ 3.7] Copying /dev/vda2
[ 5.1] Copying /dev/vda3
100% [#############################################################################################################################################################################################################] 00:00
[ 38.0] Expanding /dev/vda3 using the 'resize2fs' method
Resize operation completed with no errors. Before deleting the old disk,
carefully check that the resized disk boots and works correctly.
# mv /KVM/data13/test_extend.img /KVM/data13/192.168.1.115.img #用新创建的镜像替换原来旧的镜像
# virsh start 192.168.1.115 #再次开启虚拟机
# virt-filesystems --long -h --all -a /KVM/data13/192.168.1.115.img #可见分区大小已经发生了变化
Name Type VFS Label MBR Size Parent
/dev/vda1 filesystem ext4 - - 200M -
/dev/vda2 filesystem swap - - 1.0G -
/dev/vda3 filesystem ext4 - - 19G -
/dev/vda1 partition - - 83 200M /dev/sda
/dev/vda2 partition - - 82 1.0G /dev/sda
/dev/vda3 partition - - 83 19G /dev/sda
/dev/vda device - - - 20G -
注:这种方式实际采用的是copy的方式,所花费的时间比较长,而且需要关闭虚拟机。如果是一个大镜像不建议使用此方法。
第五种:
#上面主要说的是LVM扩展的形式,当然下面这种方式也算动态扩展,但是就需要shutdown虚拟机然后再开机了。
<disk type='network' device='disk'> <driver name='qemu' type='raw'/> <auth username='libvirt'> <secret type='ceph' uuid='681854b8-0184-44dd-9fb5-eeab9612626e'/> </auth> <source protocol='rbd' name='kvmpool/192.168.1.66_add3.img'> <host name='192.168.1.20' port='6789'/> <host name='192.168.1.21' port='6789'/> <host name='192.168.1.22' port='6789'/> </source> <target dev='vdd' bus='virtio'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x0b' function='0x0'/> </disk>
#如上图配置,比如我们搞了一个ceph集群然后给kvm虚拟机挂载了一块存储盘类似于云盘的形式。
# qemu-img resize -f rbd rbd:kvmpool/192.168.1.66_add3.img +20G #然后加扩展两次空间从40G加到100G
# qemu-img resize -f rbd rbd:kvmpool/192.168.1.66_add3.img +40G
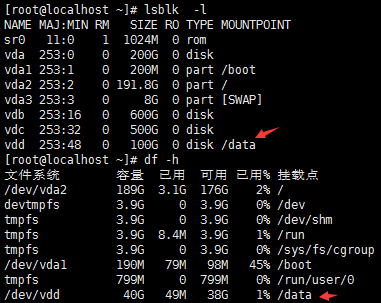
#kvm虚拟机shutdown之后再启动,可以看到kvm虚拟机的vdd磁盘已经变成了100G,但是挂载点还是40G。(reboot不管用,大概意思就是virsh destroy然后再virsh start一下,让其重新加载)
# resize2fs /dev/vdd #动态调整一下(不管有没有mount都要这么来一把,当然也可能让你先执行# e2fsck -f /dev/vdd)
resize2fs 1.42.9 (28-Dec-2013) Filesystem at /dev/vdd is mounted on /data; on-line resizing required old_desc_blocks = 5, new_desc_blocks = 13 The filesystem on /dev/vdd is now 26214400 blocks long.
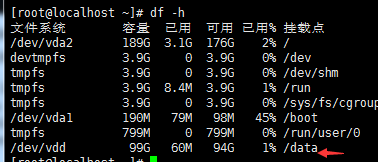
#有上图可以看到挂载盘从40G动态调整到了100G。
五、虚拟机网卡的动态扩展(virt-manager这种动态添加的形式就不说了)。
# virsh attach-interface 192.168.1.115 --type bridge --source br0 --model virtio #添加一个virtio类型的网卡
Interface attached successfully
# virsh attach-interface 192.168.1.115 --type bridge --source br0 #添加一个默认类型的网卡
Interface attached successfully
# virsh domiflist 192.168.1.115 #查看此虚拟机的网卡情况,我们新增的两块网卡出现了
Interface Type Source Model MAC
-------------------------------------------------------
vnet4 bridge br0 e1000 52:54:00:2a:fd:d1
vnet6 bridge br0 virtio 52:54:00:3b:fd:ce
vnet7 bridge br0 rtl8139 52:54:00:7d:28:95
# virsh detach-interface 192.168.1.115 --type bridge --mac 52:54:00:7d:28:95 #动态的删除一个网卡
Interface detached successfully

#查看虚拟机也是生效的
# virsh dumpxml 192.168.1.115|grep -B 1 -A 6 '52:54:00:3b:fd:ce'|egrep -v 'target|alias' #过滤出生成的配置文件
<interface type='bridge'> <mac address='52:54:00:3b:fd:ce'/> <source bridge='br0'/> <model type='virtio'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x08' function='0x0'/> </interface>
# virsh edit 192.168.1.115 #将上面那句话添加到配置文件的第一个网卡的下方,以保证虚拟机重启之后依旧生效
博文来自:www.51niux.com
六、虚拟机的删除操作(举个例子)
# virsh destroy 192.168.1.127 #删除域之前先将虚拟机关机
# virsh dumpxml 192.168.1.127|grep -A 2 'qcow2' #先查看一下192.168.1.127这个域的硬盘img文件存放的位置
<driver name='qemu' type='qcow2'/>
<source file='/KVM/data14/192.168.1.127.img'/>
<target dev='vda' bus='virtio'/>
# virsh undefine 192.168.1.127 #删除192.168.1.127这个域
Domain 192.168.1.127 has been undefined
# virsh list --all|grep 192.168.1.127 #查看域名已经不存在了
# ls -l /KVM/data14/192.168.1.127.img #但是虚拟磁盘文件还存在所以上面的删除域的命令并不能删除磁盘文件
-rw-------. 1 root root 10739318784 Feb 22 17:30 /KVM/data14/192.168.1.127.img
# rm -rf /KVM/data14/192.168.1.127.img #所以还要删除一下虚拟机的磁盘镜像文件
七、虚拟机的迁移过程
7.1 虚拟机静态迁移
第一步:确定虚拟机为关机状态。
第二步:查看准备迁移虚拟机相关的磁盘镜像文件拷贝至对端宿主机。
第三步:导出虚拟机配置文件并迁至对端宿主机。
第四步:确认配置文件和迁移过来的虚拟机的磁盘镜像文件都是正确的。
第五步:virsh define /etc/libvirt/qemu/迁移主机.xml
第六步:启动并确认
7.2 虚拟机动态迁移(不推荐)
#virsh migrate --live --verbose test01 qemu+ssh://192.168.1.15/system #这是热迁移的命令就是将或者的虚拟机test01迁移到宿主机192.168.1.15上面。
#如果还想加参数的话可以自己--help来查看。
#首先这种方式是基于共享存储的方式的,也就是img镜像在共享存储上面,这种迁移的作用就类似于旧的宿主机shutdown然后把配置文件迁移到新的宿主机然后define然后start,中间可能会断网几秒钟或者十几秒,但是很快就好了,这就是在虚拟机存活的情况下实现动态迁移也叫热迁移,上面关机迁移的方式叫做冷迁移。
#如果没用共享怎么搞呢,那你就要提前先把img镜像发送到对端的宿主机上面去(你不拷贝可以试试传过去的镜像只有100多KB)当然可以加上--copu-storafe-all,迁移的过程是先迁移磁盘,然后迁移内存,迁移内存的时候,虚拟机会连不上,虚拟机会在一边宿主机上面关闭,在另一边宿主机上面开启。,然后再执行上面的命令就可以了,但是有没有问题不清楚,线上也没用这种方式搞过也就试验过。
八、NUMA技术与应用
NUMA是一种解决多CPU共同工作的技术方案,先回顾一下多CPU共同工作技术的架构历史。多CPU共同工作主要有3种架构,分别是SMP、MPP、NUMA架构。SMP、MPP、NUMA都是为了解决多CPU共同工作的问题。
8.1 三种模式的介绍
SMP技术:早起的时候,每台服务器都是单CPU,随着技术的发展,出现了多CPU共同工作的需求,最早的多CPU技术是SMP。SMP即多个CPU通过一个总线访问存储器,因此SMP系统有时也被称为一致内存访问(UMA)结构体系。一致性意指无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。SMP的缺点是扩展性有限,因为在存储器接口达到饱和的时候,增加处理器并不能获得更高的性能,因此SMP方式支持的CPU个数有限。
MPP模式:MPP模式则是一种分布式存储器模式,能够将跟多的处理器纳入一个系统的存储器。一个分布式存储器模式具有多个节点,每个节点都有自己的存储器,可以配置为SMP模式,也可以配置为非SMP模式。单个的节点相互连接起来就形成了一个总系统。MPP可以近似理解成一个SMP的横向扩展集群。MPP一般要依靠软件实现。
NUMA技术:NUMA模式则是每个处理器有自己的存储器,每个处理器也可以访问别的处理器的存储器。如下图:

8.2 KVM宿主机NUMA调优
宿主机的NUMA信息查看与配置:
因为NUMA架构每个处理器都可以访问自己和别的处理器的存储器,访问自己的存储器要比访问别的存储器快很多,速度相差10~100倍,所以NUMA调优的目标就是让处理器尽量访问自己的存储器,以提高处理速度。
# numactl --hardware #可以看到当前CPU硬件的情况,有两颗,每颗6个核,每颗有32G内存可以使用,我物理机内存一共64G内存。如果没此命令:# yum install numactl -y
available: 2 nodes (0-1) node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 node 0 size: 32768 MB node 0 free: 3870 MB node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 node 1 size: 32755 MB node 1 free: 3033 MB node distances: node 0 1 0: 10 20 1: 20 10
# numastat #可以查看每颗CPU的内存统计
node0 node1 numa_hit 215030480 225207713 #使用本节点内存次数 numa_miss 83467145 10466190 #计划使用本节点内存而被调度到其他节点次数 numa_foreign 10466190 83467145 #计划使用其他节点内存而使用本地内存次数 interleave_hit 21867 21784 #交叉分配使用的内存中使用本节点的内存次数 local_node 215029886 225181798 #在本节点运行的程序使用本节点内存次数 other_node 83467739 10492105 #在其他节点运行的程序使用本节点内存次数
#numastat -c qemu-kvm #可以查看相关进程的NUMA内存使用情况
Per-node process memory usage (in MBs) PID Node 0 Node 1 Total --------------- ------ ------ ------ 5307 (qemu-kvm) 5836 968 6804 5363 (qemu-kvm) 7910 3194 11104 5380 (qemu-kvm) 5948 2910 8858 5597 (qemu-kvm) 1900 11291 13191 5646 (qemu-kvm) 7054 1558 8612 30662 (qemu-kvm) 4021 5473 9494 30718 (qemu-kvm) 3753 5393 9146 33332 (qemu-kvm) 1290 5181 6471 33407 (qemu-kvm) 1022 14176 15198 33474 (qemu-kvm) 6731 3413 10144 33550 (qemu-kvm) 11105 1267 12372 --------------- ------ ------ ------ Total 56570 54824 111394
#cat /proc/sys/kernel/numa_balancing #Linux系统默认是自动NUMA平衡策略的,如果要关闭Linux系统的自动平衡,可以#echo 0 >/proc/sys/kernel/numa_balancing来关闭掉。
1
虚拟机NUMA信息查看与配置:
#virsh numatune 77 #可以通过此命令指定虚拟机运行的ID来查看虚拟机的NUMA配置
numa_mode : strict numa_nodeset :
NUMA工作方式可以是strict指定CPU,或者auto使用系统的numad服务。
8.3 CPU绑定操作方法:
更改配置文件方式:
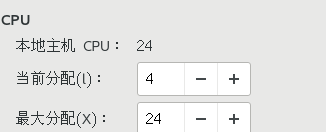
可以设置一个虚拟机给24个虚拟CPU,但是一开始只能使用4个,然后根据系统压力,热添加CPU给虚拟机。
可以先使用给虚拟机CPU指定具体的物理机CPU pinning策略:
<vcpu placement='auto' current='4'>24</vcpu> <cputune> <vcpupin vcpu='0' cpuset='1,3-4'/> #vcpu是虚拟机的cpu的逻辑核,后面cpuset是物理机的cpu的逻辑核 <vcpupin vcpu='1' cpuset='0-1'/> <vcpupin vcpu='2' cpuset='2-3'/> <vcpupin vcpu='3' cpuset='0,4'/> </cputune> <numatune> <memory mode='strict' placement='auto'/> </numatune>
在线绑定CPU的方式:
https://blog.51niux.com/?id=82 #的virsh emulatorpin 192.168.1.101 0-5 --live 有说就不多介绍了。
强制VCPU和物理机CPU一对一绑定:
强制VCPU和物理机CPU一对一绑定。
# virsh emulatorpin 192.168.14.66 #可以看到虚拟机可以运行在任何一个CPU上面
模拟器: CPU 亲和性 ---------------------------------- *: 0-23
# virsh vcpupin 192.168.14.66 0 10 #让192.168.14.66虚拟机的VCPU0 跟物理机的CPU10想绑定,下面的依次类推
# virsh vcpupin 192.168.14.66 1 11
# virsh vcpupin 192.168.14.66 2 12
# virsh vcpupin 192.168.14.66 3 13
# virsh vcpuinfo 192.168.14.66
VCPU: 0 CPU: 10 状态: running CPU 时间: 10.2s CPU关系: ----------y------------- VCPU: 1 CPU: 11 状态: running CPU 时间: 1.9s CPU关系: -----------y------------ VCPU: 2 CPU: 12 状态: running CPU 时间: 2.2s CPU关系: ------------y----------- VCPU: 3 CPU: 13 状态: running CPU 时间: 2.8s CPU关系: -------------y----------
#你反复刷新结果也不会变了,因为NUMA的自动平衡服务已经作用不聊了,之前一个虚拟机默认只能使用同一颗物理CPU内部的逻辑核,现在强制绑定了,可以看到VCPU只跟一个物理逻辑CPU有亲和度了。
#但是命令只是临时生效,如果重启的话就这种强制绑定就会失效了,所以还是要更改下配置文件。
<vcpu placement='static'>4</vcpu> <cputune> <vcpupin vcpu='0' cpuset='10'/> <vcpupin vcpu='1' cpuset='11'/> <vcpupin vcpu='2' cpuset='12'/> <vcpupin vcpu='3' cpuset='13'/> </cputune>
#不过跟上面那种方式指定CPU范围是一个意思哈,尴尬了。现在不就不怕重启了,不会再变回去了。
8.4 CPU绑定技术的原理及应用场景
技术原理:
CPU绑定实际上是Libvirt通过CGroup来实现的,通过CGroup来实现的,通过CGroup直接去绑定KVM虚拟机进程也可以。通过CGroup可以坐CPU绑定,还可以限制虚拟机磁盘、网络的资源控制。
应用场景:
系统的CPU压力比较大可以给它绑定固定的CPU防止CPU飘来飘去,多核CPU压力不平衡,可以通过cpu pinning技术人工进行调配。
#CPU Nested技术简单的说就是虚拟机上运行虚拟机,Centos7官方宣称不正式支持Nested技术,所以不多做介绍。
九、KVM虚拟机网络资源限制
#前面已经介绍了CPU、内存、磁盘怎么限制,但是还有个网络资源怎么限制没记录,但是一般也不限制,这里记录一下。如果对网络资源进行限制,CGroups就不方便了,一般对网络流量的限制也不适用CGroups。iptables和tc的方式就不说了,就记录一种简单易用的Libvirtd限制虚拟机带宽的方式。
Libvirt的虚拟机流量限制,配置分成方便,在虚拟机配置文件中的网卡部分加入如下内容:
<interface type='bridge'> <mac address='52:54:00:d7:96:82'/> <source bridge='br0'/> <bandwidth> <inbound average='100' peak='50' burst='1024'/> <outbound average='100' peak='50' burst='1024'/> </bandwidth> <model type='virtio'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </interface>
#上面是限制进出带宽的平均不超过100KB/S,最高不超过50KB/S,实际结果流出要稍大些,流入限制的很好。切记虚拟机一定要shutdown关机再启动而不是重启,不然虚拟机不生效。

#上面是流入和流出的测试截图,限速效果已经生效了。其实Libvirt实际还是使用的TC限制虚拟机流量,但是TC配置较为麻烦,可以这样简单搞一下。
# tc -s -d qdisc ls|grep htb #通过TC队列查看命令
qdisc htb 1: dev vnet7 root refcnt 2 r2q 10 default 1 direct_packets_stat 0 ver 3.17
# ifconfig |grep -A 4 vnet7 #可以看到虚拟网卡名称和mac地址对上了,正好是对这个虚拟机使用的虚拟网卡做了流量限制
vnet7: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet6 fe80::fc54:ff:fed7:9682 prefixlen 64 scopeid 0x20<link> ether fe:54:00:d7:96:82 txqueuelen 1000 (Ethernet) RX packets 6117 bytes 11383844 (10.8 MiB) RX errors 0 dropped 0 overruns 0 frame 0
