awk命令详解(二)
https://blog.51niux.com/?id=91 说了awk的介绍,基础入门和内置变量,这里继续讲述其他的部分。
一、awk的操作符
1.1 算数操作符示例
# awk 'BEGIN{a=5;b=2;print "(a+b)=",(a+b)}' #a+b
(a+b)= 7
# awk 'BEGIN{a=5;b=2;print "(a-b)=",(a-b)}' #a-b
(a-b)= 3
# awk 'BEGIN{a=5;b=2;print "(a*b)=",(a*b)}' #a*b
(a*b)= 10
# awk 'BEGIN{a=5;b=2;print "(a/b)=",(a/b)}' #a/b
(a/b)= 2.5
# awk 'BEGIN{a=5;b=2;print "(a%b)=",(a%b)}' #a和b相除取余
(a%b)= 1
1.2 一元运算符
# awk 'BEGIN{a=-5;a = +a;print "a =", a}'
a = -5
[root@master ~]# awk 'BEGIN{a=-5;a = -a;print "a =", a}' #负负得正
a = 5
1.3 自增自减运算符
# awk 'BEGIN{a=5;b=++a;printf "a=%d,b=%d\n", a,b}' #b=++a,相当于++a;b=a。在这里++a表示先算++,再执行
a=6,b=6
# awk 'BEGIN{a=5;b=a++;printf "a=%d,b=%d\n", a,b}' #b=a++,相当于b=a;a++表示先执行。再算++
a=6,b=5
# awk 'BEGIN{a=5;b=--a;printf "a=%d,b=%d\n", a,b}'
a=4,b=4
# awk 'BEGIN{a=5;b=a--;printf "a=%d,b=%d\n", a,b}'
a=4,b=5
# awk '/ldap/{++a}END{print "Count=",a}' /etc/passwd #统计/etc/passwd中带有ldap关键字的行数,这个a可以是任意的字母,一个变量代表累加计数
Count= 5
# grep "ldap" /etc/passwd|wc -l
5
1.4 三元操作符
# awk 'BEGIN{a=5;b=2;(a>b)?max=a:max=b;print "Max=",max}'
Max= 5
#三元运算(条件为真)?执行1,:否则要执行2,这里就是如果a>b则执行max=a,否则执行max=b,然后打印max的值。
1.5 赋值运算符
# awk 'BEGIN{name="51niux";print"My name is",name}' #= 让name等于51niux,name就是一个变量
My name is 51niux
# awk 'BEGIN { num = 10; num += 10; print "Number =", num}' #num+=10 等同于num=num+10
Number = 20
# awk 'BEGIN { num = 10; num -= 10; print "Number =", num}' #-= 减等
Number = 0
# awk 'BEGIN { num = 10; num *= 10; print "Number =", num}' #*= 乘等
Number = 100
# awk 'BEGIN { num = 10; num /= 10; print "Number =", num}' #/= 除等
Number = 1
# awk 'BEGIN { num = 10; num %= 10; print "Number =", num}' #%= 取余等
Number = 0
# awk 'BEGIN { num = 10; num ^= 3; print "Number =", num}' #^= 幂等
Number = 1000
# awk 'BEGIN { num = 10; num **= 3; print "Number =", num}' #^= 幂等
Number = 1000
1.6 关系操作符
# awk 'BEGIN {a =5;b=5;if(a==b) print "a==b" }' #如果a==b,就打印a==b
a==b
# awk 'BEGIN {a = "abc";b="ab";if(a!=b) print "a!=b" }' #如果是字符串的比较的话就用双括号扩起来,!=为不等于
a!=b
# awk 'BEGIN {a = 10;b=5;if(a>b) print "a>b" }' #>大于
a>b
# awk 'BEGIN {a = 5;b=10;if(a<b) print "a<b" }' #<小于
a<b
# awk 'BEGIN {a = 5;b=5;if(a<=b) print "a<=b" }' #<=小于等于
a<=b
# awk 'BEGIN {a = 5;b=5;if(a>=b) print "a>=b" }' #>=大于等于
a>=b
1.7 逻辑操作符
# awk 'BEGIN{num=5;if (num>=0 && num<= 10) printf "%d is ni 10 yinei\n",num}' #&&逻辑与关系。两个条件都要满足,两个条件都要为真。
5 is ni 10 yinei
# awk 'BEGIN{num=5;if (num>=0 && num>= 10) printf "%d is ni 10 yinei\n",num}'
# awk 'BEGIN{num=5;if (num>=0 || num>= 10) printf "%d is ni 10 yinei\n",num}' #||逻辑或关系,两个条件只要满足其中一个就可以了。
5 is ni 10 yinei
# awk 'length($0)>68 || /root/' /etc/passwd #匹配/etc/passwd文件中长度大于68或者内容中包含有root的行
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
luci:x:141:141:luci high availability management application:/var/lib/luci:/sbin/nologin
oprofile:x:16:16:Special user account to be used by OProfile:/home/oprofile:/sbin/nologin
# awk 'length($0)>68 && /luci/' /etc/passwd #打印/etc/passwd文件中长度大于68并且内容中包含有luci的行
luci:x:141:141:luci high availability management application:/var/lib/luci:/sbin/nologin
1.8 字符串连接操作
# awk 'BEGIN{str1 ="Hello,";str2="World";str3=str1 str2;print str3}' #str1和str2之间默认一定要有一个空格
Hello,World
# awk 'BEGIN{str1 ="Hello,";str2="World";str3=str1"-"str2;print str3}' #str1和str2之间如果要用别的连接符代替的话,用双括号里面制定连接符
Hello,-World
1.9 数组成员操作符
# awk 'BEGIN { arr[0] = 1; arr[1] = 2; arr[2] = 3; arr[3] =d; for (i in arr) print i}' #这就跟linux里的for循环一样你数组里面有几个元素,就从0开始循环。
0
1
2
3
# awk 'BEGIN { arr[0] = 1; arr[1] = 2; arr[2] = 3; arr[3] = "d"; for (i in arr) printf "arr[%d] = %s\n", i, arr[i]}' #看了上面的就能理解下面的数组循环了,我们其实就是循环的去执行arr[0],arr[1],arr[n],当然如果你中又非数字的话要用“”包起来。当然%d\n也要变为%s\n了。
arr[0] = 1
arr[1] = 2
arr[2] = 3
arr[3] = d
1.10 正则表达式操作符
# awk '$0 ~ 501' /etc/passwd #~匹配文件中带有501的行
bind:x:501:501::/usr/local/named:/sbin/nologin
# awk '$0 ~ /bind/' /etc/passwd #匹配字符串一种是这种形式,或者这种:# awk '$0 ~ "bind"' /etc/passwd
rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
bind:x:501:501::/usr/local/named:/sbin/nologin
# awk '$0 !~ 501' /etc/passwd #!~ 就是不匹配的意思了,后面跟不匹配的条件
# ifconfig | awk '$0 ~ /inet.*:[1-9].[1-9].[1-9].[1-9]/' #如果要匹配正则表达式的话,正则表达式外面用//包起来
inet addr:192.168.1.108 Bcast:192.168.1.255 Mask:255.255.255.0
inet addr:192.168.122.1 Bcast:192.168.122.255 Mask:255.255.255.0
博文来自:www.51niux.com
二、printf语句和修饰符
2.1 、 %c示例
# echo abc|awk '{printf("%c\n",$0)}' #abc的第一个字符是a
a
# echo dba|awk '{printf("%c\n",$0)}' #cba的第一个字符是d
d
# echo 98|awk '{printf("%c\n",$0)}' #98对应的ascll码是b
b
# echo 97|awk '{printf("%c\n",$0)}' #97对应的ascll码是a
a
2.2、 %d和%i的示例
# echo "1.7 2.52"|awk '{printf("%i-%d\n",$1,$2)}' #%i和%d都是取整数部分
1-2
#echo "3.7 2.52"|awk '{printf("%i-%d\n",$1,$2)}'
3-2
# echo "abc 2.52"|awk '{printf("%i-%d\n",$1,$2)}' #如果非数字就变为了0
0-2
# echo "abc ccc"|awk '{printf("%i-%d\n",$1,$2)}'
0-0
2.3、%e和%E的示例
# echo "abc ccc"|awk '{printf("%e-%E\n",$1,$2)}' #%e和%E,指数形式的浮点数,科学计数法
0.000000e+00-0.000000E+00
# echo "3.7 2.52"|awk '{printf("%e-%E\n",$1,$2)}'
3.700000e+00-2.520000E+00
# echo "37 252"|awk '{printf("%e-%E\n",$1,$2)}'
3.700000e+01-2.520000E+02
2.4、%f和%F的示例
# echo "1.7"|awk '{printf("%f\n",$1)}' #默认是小数点后六位的浮点数,不足用0代替。
1.700000
# echo "1.7"|awk '{printf("%3.1f\n",$1)}' #%3.1f,就表示总共是3位,小数点是1位,所以1,7正好是3位,7正好是小数点后一位。
1.7
# echo "1.7"|awk '{printf("%6.3f\n",$1)}' #%6.3f,就是表示总共是6位。小数点是3位,整数也就是3位,不足的话前面用空格代替,所以看1.7前面有空格
1.700
# echo "1.7"|awk '{printf("%7.3f\n",$1)}' #1.7前面有两个空格
1.700
# echo "1.7"|awk '{printf("%0.3f\n",$1)}' #%0.3% 就表示小数点后面有三个小数的浮点数
1.700
# echo "1234.72312321"|awk '{printf("%1.2f\n",$1)}' #前面说了如果位数不够用空格代替,但是现在明显数字是够的,所以不用代替。
1234.72
# echo "1234.72312321"|awk '{printf("%11.2f\n",$1)}'
1234.72
# echo "1.761"|awk '{printf("%3.1f\n",$1)}' #%.f 是四舍五入的显示数字。
1.8
2.5、%g示例
# echo "1234.72312321"|awk '{printf("%1.10g\n",$1)}' #%g以科学计数法或浮点数的格式显示数值,自动选择合适的表示法
1234.723123
# echo "1234.72312321"|awk '{printf("%1.10f\n",$1)}'
1234.7231232100
# echo "1234.72312321"|awk '{printf("%.5g\n",$1)}' #%.5g 是正确的格式
1234.7
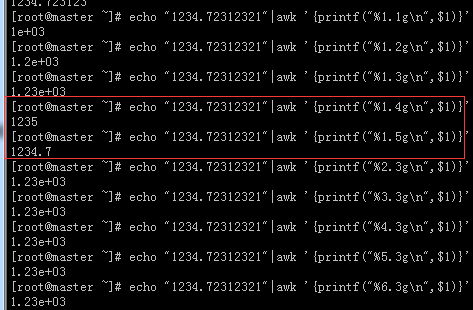
2.6、%o和%u示例
# echo "1234.72312321"|awk '{printf("%o\n",$1)}' #%o无符号八进制整数
2322
# echo "1234.72312321dasds"|awk '{printf("%o\n",$1)}'
2322
# echo "1234.7231232112321321"|awk '{printf("%o\n",$1)}'
2322
# echo "3213211234.7231232112321321"|awk '{printf("%o\n",$1)}'
27741333142
# echo "1234.72312321"|awk '{printf("%u\n",$1)}' #%u十进制整数
1234
# echo "1234.7231232112321321"|awk '{printf("%u\n",$1)}'
1234
# echo "3213211234.7231232112321321"|awk '{printf("%u\n",$1)}'
3213211234
# echo "3213211234.7231232112321321"|awk '{printf("%16u\n",$1)}' #位数不够16前面补空格
3213211234
2.7 、%s示例
# echo "3213211234.abc"|awk '{printf("%s\n",$1)}' #%s 是字符串嘛,所以abc依旧可以输出
3213211234.abc
# echo "3213211234.abcdef"|awk '{printf("%.4s\n",$1)}' #选择输出的位数,这里是4位
3213
# echo "3213211234.abcdef"|awk '{printf("%.15s\n",$1)}'
3213211234.abcd
2.8、%x示例
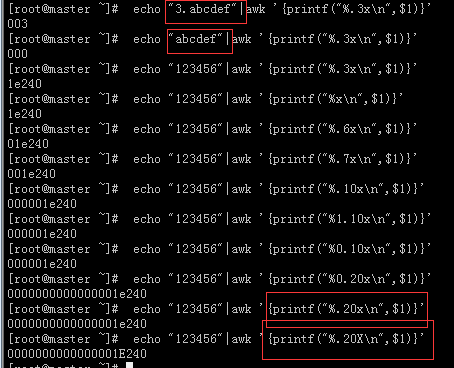
2.9、 - 左对齐
# df -h|awk '{printf ("%12s\n",$1)}' #不加-默认是右对齐
Filesystem
/dev/sda3
tmpfs
/dev/sda1
# df -h|awk '{printf ("%-12s\n",$1)}' #加上-就是左对齐
Filesystem
/dev/sda3
tmpfs
/dev/sda1
博文来自:www.51niux.com
三、awk的控制语句
3.1 if-else语句示例
第一种语句:if (条件1){动作 1}else {动作2}
# cat user.txt #测试文本
Wanglei 35 F
Chaishao 20 M
Zhangwei 25 M
Tianliang 40 F
# awk '{if($2<=25){printf ("User:%s age is %d,the gender is %s.\n",$1,$2,$3)}else{printf("User:%s age is %d,the gender is %s more than 25 years old.\n",$1,$2,$3)}}' user.txt
User:Wanglei age is 35,the gender is F more than 25 years old.
User:Chaishao age is 20,the gender is M.
User:Zhangwei age is 25,the gender is M.
User:Tianliang age is 40,the gender is F more than 25 years old.
#if($2<=25)如果$2小于25,就打印{printf ("User:%s age is %d,the gender is %s.\n",$1,$2,$3,否则就打印printf("User:%s age is %d,the gender is %s more than 25 years old.\n",$1,$2,$3)},对user.txt测试文本进行逐行匹配输出。
下面是第二种形式:if (条件1){动作 1}elif(条件2){动作2}else {动作3}
# awk '{if ($2<25){printf("User:%s is so young.\n",$1)} else if ($2>=25 && $2<=35){printf("User:%s is not young.\n",$1)}else{printf("User:%s is so old.\n",$1)}}' user.txt
User:Wanglei is not young.
User:Chaishao is so young.
User:Zhangwei is not young.
User:Tianliang is so old.
#if ($2<25) :如果$2小于25,则输出("User:%s is so young.\n",$1),else if ($2>=25 && $2<=35):又或者当$2大于等于25并且$2<=35的时候,则输出("User:%s is not young.\n",$1),否则输出f("User:%s is so old.\n",$1)
3.2 for语句
# awk '{for(i=1;i<=NF;i++){print $i;i++;}}' user.txt #for (计算器的初始化;条件;计数器累加){动作}
Wanglei
F
Chaishao
M
Zhangwei
M
Tianliang
F
#这个例子,NF是三因为我们测试文本是3个域,首先i=1,i<3,所以打印$1,然后i++现在i就变成了2了,然后for循环里面还有个i++,所以i就变为了3,3<=NF,所以又可以打印$3,然后i就大于3了,所以只打印了第一个域和第三个域。而第二个域没有被打印。
# awk '{for (i=1;i<=NF;i++){if(i==NF-1){printf "This is second last:%-3s\t",$i}else if(i==NF){printf "This is last:%-5s\n",$i}else{printf "This is not second last:%-10s\t",$i}}}' user.txt
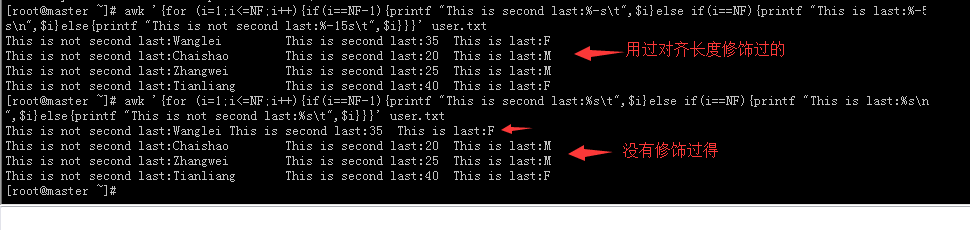
#上面主要是在for循环里面还加了if else判断,而且还加了对齐长度来修饰输出,不然的话会因为语句长度的不同,而看着不是很整齐。
3.3 while语句
# awk 'BEGIN{i=1;while(i<6){print i;i++}}' #最简单的while循环。
1
2
3
4
5
# awk 'BEGIN{top=100;total=0;while(i<=100){total+=i;i++;}{print total}}' #{total+=i;i++;}{print total}分开只打印最后的结果,要是再一个{}打印过程
5050
break、continue和exit
break、continue 可用于影响程序的控制流。
break:退出当前循环,不再继续执行循环体
continue:终止当前循环,从循环的顶部提前进入新的循环
exit:直接退出循环
注意:continue 在while 和 for 循环不同之处在于,在for循环主体中使用时,continue将使循环控制变量自动增加!
四、数组(数组下标是从1开始的)
在文本处理中,awk数组是必不可少的工具,awk的数组下标可以是数字或者字符串。无需对数组名和元素提前声明和指定元素个数。
4.1 一维数组
# awk 'BEGIN{ #直接回车,就可以进行换行的输入
array[1]="I" #创建数组的操作。array[index] =value:数组名是array,下标是index这里是1,对应的值value,这里是I
array[2]="AM" #这是创建数字形式的下标
array[3]="IS"
array[4]="A"
array["first"]="www" #这是创建字符串形式的下标
array["second"]="51niux"
array["three"]="com"
print array[1],array["4"] #通过数组名称array以及[]里面的下标,就可以取出对应的value值
print array[3],array["first"],array["three"]}'
I A
IS www com
下面是循环遍历数组取值的两个例子
# awk 'BEGIN{
array[1]="I"
array[2]="AM"
array[3]="IS"
array[4]="A"
array["first"]="www"
array["second"]="51niux"
array["three"]="com"
len=length(array) #计算数组的长度
for (i=1;i<=len;i++){print i,array[i]}}' #通过for循环的形式,通过遍历数组下标的形式,输出数组的array值,但是你会发现只打印了数字下标的值
1 I
2 AM
3 IS
4 A
5
6
7
# awk 'BEGIN{
array[1]="I"
array[2]="AM"
array[3]="IS"
array[4]="A"
array["first"]="www"
array["second"]="51niux"
array["three"]="com"
for (n in array){print n,array[n]}}' #这种in的形式,可以遍历出数组里的所有元素,但是输出顺序不是按照定义数组的顺序输出的,如果要按照顺序遍历数组,就要使用第一种方式遍历数组了。但是当数组的下标不都是统一的数组,又要取出所有的值得话就要用in来遍历了。
4 A
second 51niux
three com
1 I
2 AM
first www
3 IS
4.2、多维数组
awk多维数组在本质上是一维数组,因awk在存储上并不支持多维数组,awk提供了逻辑上模拟二维数组的访问方式。例如,array[2,3] = 1这样的访问时允许的。awk使用一个特殊的字符串SUBSEP (\034)作为分割字段,在上面的例子 array[2,3] = 1 中,关联数组array存储的键值实际上是2\0343,2和3分别为下标(2,3),\034为SUBSEP分隔符。
类似一维数组的成员测试,多维数组可以使用 if ( (i,j) in array) 语法,但是下标必须放置在圆括号中。
类似一维数组的循环访问,多维数组使用 for ( item in array ) 语法遍历数组。与一维数组不同的是,多维数组必须使用split()函数来访问单独的下标分量,格式: split ( item, subscr, SUBSEP), 例如: split (item, array2, SUBSEP); 后,array2[1]为下标“2”, array2[2]为下标“3”
# awk 'BEGIN{
for(i=1;i<=3;i++){
for(j=1;j<=3;j++){
array[i,j] = i * j;
print i" * "j" = "array[i,j];}}}'
1 * 1 = 1
1 * 2 = 2
1 * 3 = 3
2 * 1 = 2
2 * 2 = 4
2 * 3 = 6
3 * 1 = 3
3 * 2 = 6
3 * 3 = 9
# awk 'BEGIN{
for(i=1;i<=3;i++){
for(j=1;j<=3;j++){
array[i,j] = i * j;}}
for(n in array){
split(n,array2,SUBSEP); #split(n, array2, SUBSEP); 把二维数组作为一维数组处理,同样数组元素顺序不确定。
print array2[1]"*"array2[2]"="array[n]}}'
3*3=9
1*1=1
2*1=2
1*2=2
3*1=3
2*2=4
1*3=3
3*2=6
2*3=6
4.3 数组函数
示例1,length和split函数
# awk 'BEGIN{
message="This is a body";
len = split(message,array," "); #split分割字符串为并且返回数组的长度。
print len,length(array);}' #lebgth(数组名称)获取数组长度
4 4
# awk 'BEGIN{
message="This is a body";
split(message,array," ");
for(i in array){
print i" = " array[i];}}'
4 = body
1 = This
2 = is
3 = a
# awk 'BEGIN{
message="This is a body";
len=split(message,array," ");
for(i=1;i<=len;i++){print i" = "array[i]}}'
1 = This
2 = is
3 = a
4 = body
示例2、asort数组排序
asort对数组array按照首字母进行排序,返回数组长度;如果要得到数组原本顺序,需要使用数组下标依次访问;
# awk 'BEGIN{
message="This is a body";
split(message,array," ");
len=asort(array);
for(i=1;i<=len;i++){print i" = "array[i]}}' #如果用for的话还是无序的,看不出效果,所以这里要用数字下标的形式来查看。
1 = This #可以看到结果已经按照首字母进行排序
2 = a
3 = body
4 = is
4.4 键值操作
示例1,查找键值(in)
先说一个错误的用法:
# awk 'BEGIN{
message="This is a body";
split(message,array," ");if(array[5]!="haha"){print "not found array[5] value"};
for(i in array){
print i" = " array[i];}}'
not found array[5] value
4 = body
5 = #没有定义下标5但是却for循环出来了该键值,它的值为空。这是因为awk数组是关联数组,只要通过数组引用它的key,就会自动创建改序列
1 = This
2 = is
3 = a
下面是正确用法:
# awk 'BEGIN{
message="This is a body";
split(message,array," ");if(5 in array){print "not found array[5] value"}; #用in的形式查找 ,没有引用array下标5,因此没有添加到数组中
for(i in array){
print i" = " array[i];}}'
4 = body
1 = This
2 = is
3 = a
示例2,delete删除键值
# awk 'BEGIN{
message="This is a body";
split(message,array," ");delete array[2]; #结果显示下标2的键被删除了,如果是字符串的下标要用双引号括起来
for(i in array){
print i" = " array[i];}}'
4 = body
1 = This
3 = a
五、内置算数函数
# awk 'BEGIN{print atan2(3,2)}'
0.982794
# awk 'BEGIN{print cos(2)}'
-0.416147
# awk 'BEGIN{print sin(2)}'
0.909297
# awk 'BEGIN{print exp(2)}'
7.38906
# awk 'BEGIN{print log(2)}'
0.693147
# awk 'BEGIN{print sqrt(2)}'
1.41421
# awk 'BEGIN{print int(2.123)}'
2
下面主要是rand函数和srand函数:
# awk 'BEGIN{print rand()}' #rand函数 rand函数生成一个大于或等于0、小于1的伪随机浮点数。
0.237788
# awk 'BEGIN{print rand()}'
0.237788
# awk '{print rand()}' 3.txt
0.237788
0.291066
0.845814
# awk '{print rand()}' 3.txt
0.237788
0.291066
0.845814
#从上面的结果我们可以发现确实是随机了,但是每次调用rand都只会重复出现同一数列。显然达不到随机的效果啊。
srand函数如果未指定参数,srand函数会根据当前时刻为rand函数生成一个种子。srand(x)则把x设成种子。这样程序在运行过程中不断地改变x的值。
下面是效果:
# awk 'BEGIN{srand()}{print rand()}' 3.txt
0.246249
0.202152
0.96187
# awk 'BEGIN{srand()}{print rand()}' 3.txt #跟上面比两次的执行结果发生了改变,随机数不是同一个值了。
0.742378
0.309722
0.795881
#srand函数为rand设置了一个新种子,起点是当前时刻。因此,每次调用rand都打印出一组新的数列
下面是一个取1-25之间随机数的一个例子:
# awk 'BEGIN{srand();print 1+int(rand()*25)}'
23
# awk 'BEGIN{srand();print 1+int(rand()*25)}'
2
# awk 'BEGIN{srand()}{print 1+int(rand()*25)}' 3.txt
25
1
13
六、内置字符串函数
6.1 gsub和sub函数示例
# echo "a b c 2017-03-12"|awk '$4=gsub(/-/,"",$4)' #gsub(/-/,"",$4)的值是2,你将2赋值给$4 ,gsub返回的是替换的次数。
a b c 2
# echo "a b c 2017-03-12"|awk 'gsub(/-/,"",$4)' #如果是想单纯的替换,这样用就可以了
a b c 20170312
# echo "a b c 2017-03-12"|awk 'gsub(/-/,"_",$4)'
a b c 2017_03_12
# cat 3.txt #测试文本
123 123adsb123dsa 3421321da
221 321dsa123dsa dasdsada132
331 das213das321a dasdsa
# awk 'gsub(/[0-9]/,"",$2)' 3.txt #将第二个域中,所有的数字都去掉了
123 adsbdsa 3421321da
221 dsadsa dasdsada132
331 dasdasa dasdsa
# awk 'sub(/[0-9]/,"",$2)' 3.txt #这就是sub和gsub的区别,sub匹配第一次出现的符合模式的字符串,相当于 sed 's//' 。
gsub匹配所有的符合模式的字符串,相当于 sed 's//g' 。
123 23adsb123dsa 3421321da
221 21dsa123dsa dasdsada132
331 das13das321a dasdsa
# awk 'sub(/[0-9]+/,"",$2)' 3.txt #倒是可以这样用,但也只是把最左边出现的去掉了,后面的数字还是没有去掉。
123 adsb123dsa 3421321da
221 dsa123dsa dasdsada132
331 dasdas321a dasdsa
6.2 index函数、length函数、match函数
# awk 'BEGIN{info="this is a test2017test!";print index(info,"test")}' #查询字符串中""中的内容出现的第一位置。必须用双引号将字符串括起来。这里是查询this is a test2017test!中test出现的位置。
11
# awk '$0~/root/{print length($0),$0}' /etc/passwd #length返回所需字符串长度
31 root:x:0:0:root:/root:/bin/bash
44 operator:x:11:0:operator:/root:/sbin/nologin
# awk 'BEGIN{print match("ABCD",/d/)}' #match测试目标字符串是否包含查找字符的一部分。可以对查找部分使用正则表达式,返
回值为成功出现的字符排列数。如果未找到,返回0
0
# awk 'BEGIN{print match("ABCD",/D/)}' #如果存在。返回D出现的首位置字符数
4
awk '$0~/root/{print match($0,"root")}' /etc/passwd
1
27
6.3 toupper和tolower函数(另外asort和split函数前面已经说了)
# echo "a b c d E F o p"|awk '{print toupper($0)}' #将选中的域小写字符变大写
A B C D E F O P
# echo "a b c d E F o p"|awk '{print tolower($0)}' #将选中的域大写字母变小写字母
a b c d e f o p
6.4 substr函数
# awk '$0~/root/{print substr($0,1);}' /etc/passwd #substr(s,p) 返回字符串s中从p开始的后缀部分,这里返回了第一个位置到后面所有的内容
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
# awk '$0~/root/{print substr($0,2);}' /etc/passwd
oot:x:0:0:root:/root:/bin/bash
perator:x:11:0:operator:/root:/sbin/nologin
# awk '$0~/root/{print substr($0,2,5);}' /etc/passwd #substr(s,p,n) 返回字符串s中从p开始长度为n的后缀部分,这里返回了从第二个位置开始,向后一共5个长度的内容。
oot:x
perat
七、内置时间函数
# awk 'BEGIN{now=strftime("%D",systime());print now}' #strftime格式化时间输出,将时间戳转为时间字符串,“%D”就是时间的输出格式,systime()得到时间戳,返回从1970年1月1日开始到当前时间(不计闰年)的整秒数
03/13/17
# awk 'BEGIN{now=strftime("%Y-%m-%d",systime());print now}'
2017-03-13
# awk 'BEGIN{now=strftime("%m/%d/%y");print now}' #strftime函数通过一个参数所给出的格式来设置时间和日期的形式。如果以systime作为第2个参数,或者不带第2个参数,将使用本地的当前时间。如果带了第2个参数,则它必须与systime函数的返回值格式一致。
03/13/17
# awk 'BEGIN{ttime=mktime("2017 03 13 21 33 30");print ttime}' #mktime( YYYY MM DD HH MM SS[ DST])将时间转换为时间戳
1489412010
# awk 'BEGIN{ttime=mktime("2017 03 13 21 33 30");print strftime("%c",ttime);}' #再将时间戳转换成指定格式的日期显示
Mon Mar 13 21:33:30 2017
# awk 'BEGIN{ttime1=mktime("2017 03 13 21 33 30");ttime2=mktime("2016 03 13 21 33 30");print ttime1-ttime2;}' #时间戳想减
31536000
# awk 'BEGIN{ttime1=mktime("2017 03 13 21 33 30");ttime2=systime();print ttime1-ttime2;}' #过去时间和现在的时间戳想减。
-280
博文来自:www.51niux.com
八、一般函数(只是记录一下)
# awk 'BEGIN{while("cat /root/1.txt"|getline){print $0;}close("/root/1.txt");}' #用close打开外部文件,用getline逐行读取,这条语句感觉跟直接用awk没啥区别哈。
# time awk 'BEGIN{while(getline<"/root/1.txt"){print $0;}close("/root/1.txt");}'|wc -l #getline逐行读取外部文件
9298165
real 0m2.895s
user 0m2.358s
sys 0m0.535s
# time awk {'print $0'} /root/1.txt |wc -l
9298165
real 0m2.253s
user 0m1.778s
sys 0m0.472s
# awk 'BEGIN{a=system("ls -l /etc/passwd");print a;}' #a是执行结果。system("")里面是要执行的命令 ,然后打印结果
-rw-r--r-- 1 root root 2646 Mar 5 22:23 /etc/passwd #执行结果
0 #这是返回值,0表示正确
# awk 'BEGIN{a=system("ls -l /root/dsadsadsa");print a;}' #我们查看一个不存在的文件
ls: cannot access /root/dsadsadsa: No such file or directory #执行返回的错误信息
2 #返回值也不是0,而是2了。
九、next和getline
当其左右无重定向符 | 或 < 时,getline作用于当前文件,读入当前文件的下一行给其后跟的变量var或$0(无变量);由于awk在处理getline之前已经读入了一行,所以getline得到的返回结果是隔行的。当其左右有重定向符 | 或 < 时,getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行。
next和getline在awk执行过程中都用于读取下一行数据,但他们却有着很重要的不同。next读取下一行之后,把控制权交给了awk脚本的顶部,及next后面的语句将被忽略,重头执行那个awk的action,同时内置变量FNR等被重置。而getline却没有改变脚本的控制,读取下一行之后,继续运行当前的awk脚本,内置变量也不会被重置。getline执行之后,会覆盖$0的内容。
另外,nextfile : 强迫awk立刻停止处理当前的输入文件而处理输入文件列表中的下一个文件。exit : 使awk停止执行而跳出。如果有END 存在,awk会去执行END 的actions。
next和getline示例比较:
# awk '{getline;}{print NR,$0}' test.txt
2 b
4 d
6 f
# awk '{next;}{print NR,$0}' test.txt
# awk '{print NR,$0}{getline;}' test.txt
1 a
3 c
5 e
# awk '{print NR,$0}{next;}' test.txt
1 a
2 b
3 c
4 d
5 e
6 f
next示例1:
# awk 'NR%2==1{print NR,$0;}NR%2==0{print NR,$0}' test.txt #这个反正就是两个匹配
1 a
2 b
3 c
4 d
5 e
6 f
# awk 'NR%2==1{print NR,$0;}{next;}NR%2==0{print NR,$0}' test.txt #这个我们在两个匹配条件中间加了个{next;}会发现,后面的匹配条件直接就忽略了。
1 a
3 c
5 e
next示例2:
# awk 'BEGIN{a=0}{if($0!=""){print $0}else{next;"\n"}}' 2.txt #将非空字符之间的空行都去掉。
a
b
c
d
f
# awk 'BEGIN{a=0} {if($0==""){a=1;next;}if (a){print "\n"$0;a=0;}else print $0;}' 2.txt #我们2.txt文本里面每个非空字符下面都有N行空格,可能是一个空行两个或者多个,这个语句的作用就是要将多行合并我一行。
a
b
c
d
f
十、自定义函数
自定义函数就像shell里面的函数写法一样。
格式为(一般函数定义在脚本顶部,所有模式操作之前):
function name(parameter-list){ #parameter-list是用逗号分隔的变量列表
statements
return expression
}
示例1,insert函数,指定字符串的插入位置插入字符串
# awk '
function insert(STRING,POS,INS){ #()定义了三个变量。
before_tmp = substr(STRING,1,POS) #substr就是取出了传入内容的开始位置到我们指定的POS位置的内容。
after_tmp = substr(STRING,POS+1) #这里就是取出了传入内容(下面对应的是1234),的指定位置+1,也就是指定位置后面的内容。
return before_tmp INS after_tmp #字符串的连接不是用空格连接嘛。这里就是把三段内容连接起来。INS就是要插入的内容,正好在中间部分
}
BEGIN{print insert("1234",2,"AAA")}' #1234就是上面的变量STRING,2就是上面的变量POS,AAA就是上面的变量INS
12AAA34
示例2,传值比较大小
# awk '
function max(a,b){
return a>b?a:b}
BEGIN{print max(3,5)}'
5
