FastDFS之基础知识
分布式文件系统是什么,大家都已经接触很长时间了,简单来说一块磁盘的容量是有限的现在最大是8T,以后可能十几T,但是现在是一个数据爆炸的年代,就算你12个盘做成一个大RAID也是不够的,那么用硬件存储吧。随随便便都是百万级的,接触这种硬件级别的存储也有几年了,一般这种硬件级别的存储可能会考虑用来做数据库之类的存储,如果用来存储海量的数据就太浪费了。
不同的场景用不同的东西,这里记录的这块开源的FastDFS分布式文件系统,也是大家都熟悉的,用来专门存储小文件的。
一、FastDFS简介
1.1 FastDFS介绍
fastdfs是一个开源的,高性能的的分布式文件系统,他主要的功能包括:文件存储,同步和访问,设计基于高可用和负载均衡,fastfd非常适用于基于文件服务的站点,例如图片分享和视频分享网站
fastfds有两个角色:跟踪服务(tracker)和存储服务(storage),跟踪服务控制,调度文件以负载均衡的方式访问;存储服务包括:文件存储,文件同步,提供文件访问接口,同时以key value的方式管理文件的元数据跟踪和存储服务可以由1台或者多台服务器组成,同时可以动态的添加,删除跟踪和存储服务而不会对在线的服务产生影响,在集群中,tracker服务是对等的。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
1.2 FastDFS结构图
fastdfs系统架构图

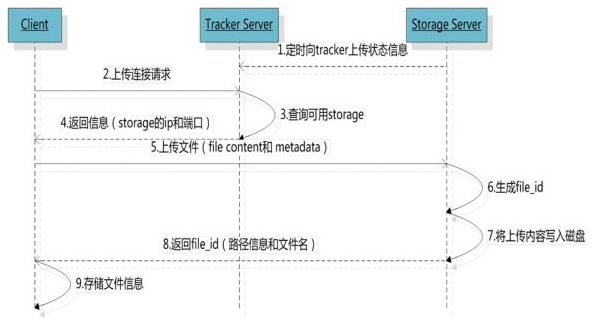
系统架构-上传文件流程图
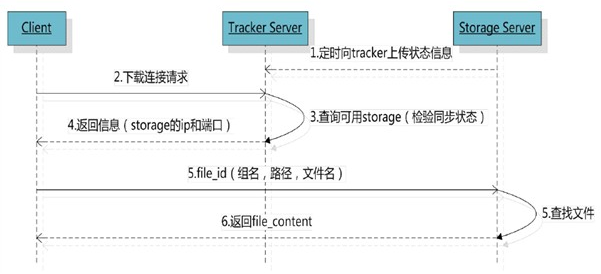
系统架构-下载流程图
1.3 相关术语
Tracker Server:跟踪服务器,主要做调度工作,在访问上起负载均衡的作用。记录storage server的状态,是连接Client和Storage server的枢纽。
Storage Server:存储服务器,文件和meta data都保存到存储服务器上
group:组,也可称为卷。同组内服务器上的文件是完全相同的
文件标识:包括两部分:组名和文件名(包含路径)
meta data:文件相关属性,键值对(Key Value Pair)方式,如:width=1024,heigth=768
博文来自:www.51niux.com
二、FastDFS的安装部署
经过上面的简单了解之后,我们安装部署起来,剩下的内容在部署中再去了解。
2.1 yum安装相关软件包
# yum -y install gcc gcc+ gcc-c++ openssl openssl-devel pcre pcre-devel
2.2 安装libfastcommon(公共代码)
# wget https://github.com/happyfish100/libfastcommon/archive/master.zip
# unzip master.zip
# cd libfastcommon-master/
# ./make.sh
# ./make.sh install
下面是安装结果输出:
mkdir -p /usr/lib64 mkdir -p /usr/lib install -m 755 libfastcommon.so /usr/lib64 install -m 755 libfastcommon.so /usr/lib mkdir -p /usr/include/fastcommon install -m 644 common_define.h hash.h chain.h logger.h base64.h shared_func.h pthread_func.h ini_file_reader.h _os_define.h sockopt.h sched_thread.h http_func.h md5.h local_ip_func.h avl_tree.h ioevent.h ioevent_loop.h fast_task_queue.h fast_timer.h process_ctrl.h fast_mblock.h connection_pool.h fast_mpool.h fast_allocator.h fast_buffer.h skiplist.h multi_skiplist.h flat_skiplist.h skiplist_common.h system_info.h fast_blocked_queue.h php7_ext_wrapper.h id_generator.h char_converter.h char_convert_loader.h /usr/include/fastcommon
# ls -l /usr/lib64/libfastcommon.so #查看此库文件是否存在,存在则表示安装成功
2.3 安装FastDFS
# cd ..
# wget https://github.com/happyfish100/fastdfs/archive/V5.10.zip
# unzip V5.10.zip
# cd fastdfs-5.10/
# ./make.sh
# ./make.sh install
下面是安装结果输出:
mkdir -p /usr/bin mkdir -p /etc/fdfs cp -f fdfs_trackerd /usr/bin if [ ! -f /etc/fdfs/tracker.conf.sample ]; then cp -f ../conf/tracker.conf /etc/fdfs/tracker.conf.sample; fi if [ ! -f /etc/fdfs/storage_ids.conf.sample ]; then cp -f ../conf/storage_ids.conf /etc/fdfs/storage_ids.conf.sample; fi mkdir -p /usr/bin mkdir -p /etc/fdfs cp -f fdfs_storaged /usr/bin if [ ! -f /etc/fdfs/storage.conf.sample ]; then cp -f ../conf/storage.conf /etc/fdfs/storage.conf.sample; fi mkdir -p /usr/bin mkdir -p /etc/fdfs mkdir -p /usr/lib64 mkdir -p /usr/lib cp -f fdfs_monitor fdfs_test fdfs_test1 fdfs_crc32 fdfs_upload_file fdfs_download_file fdfs_delete_file fdfs_file_info fdfs_appender_test fdfs_appender_test1 fdfs_append_file fdfs_upload_appender /usr/bin if [ 0 -eq 1 ]; then cp -f libfdfsclient.a /usr/lib64; cp -f libfdfsclient.a /usr/lib/;fi if [ 1 -eq 1 ]; then cp -f libfdfsclient.so /usr/lib64; cp -f libfdfsclient.so /usr/lib/;fi mkdir -p /usr/include/fastdfs cp -f ../common/fdfs_define.h ../common/fdfs_global.h ../common/mime_file_parser.h ../common/fdfs_http_shared.h ../tracker/tracker_types.h ../tracker/tracker_proto.h ../tracker/fdfs_shared_func.h ../storage/trunk_mgr/trunk_shared.h tracker_client.h storage_client.h storage_client1.h client_func.h client_global.h fdfs_client.h /usr/include/fastdfs if [ ! -f /etc/fdfs/client.conf.sample ]; then cp -f ../conf/client.conf /etc/fdfs/client.conf.sample; fi
# ls -l /usr/bin/fdfs_* #查看一下fdfs的相关命令

博文来自:www.51niux.com
三、FastDFS相关配置文件介绍
配置文件在/etc/fdfs目录下面,默认是以.sample为后缀,这些后缀要去掉。配置文件大部分是保持默认的,要修改的地方也不多。
#df -h #先查看FastDFS的磁盘挂载情况
文件系统 容量 已用 可用 已用% 挂载点 /dev/sda4 7.1T 52M 7.1T 1% /data01 /dev/sdb1 7.3T 202G 7.1T 3% /data02 /dev/sdc1 7.3T 202G 7.1T 3% /data03 /dev/sdd1 7.3T 201G 7.1T 3% /data04 /dev/sde1 7.3T 201G 7.1T 3% /data05 /dev/sdf1 7.3T 201G 7.1T 3% /data06 /dev/sdg1 7.3T 201G 7.1T 3% /data07 /dev/sdh1 7.3T 201G 7.1T 3% /data08 /dev/sdi1 7.3T 202G 7.1T 3% /data09 /dev/sdj1 7.3T 201G 7.1T 3% /data10 /dev/sdk1 7.3T 203G 7.1T 3% /data11 /dev/sdl1 7.3T 202G 7.1T 3% /data12
#还有就是磁盘的文件系统要格式化为xfs,因为FastDFS是用来存储小文件的,如果你设置成ext4就可能会造成磁盘还有空间,但是inode号已经耗尽的情况,虽然磁盘越大inode号越多。但是同磁盘大小情况下,xfs的inode号的数量相差太多了,比如8T的磁盘,如果做成xfs文件系统,一块单盘的inode号总数为:1562692608,如果做成ext4文件系统,一块单盘的inode号总数为:7630336。
3.1 tracker.conf配置文件介绍
# cat /etc/fdfs/tracker.conf
# ===========================基本配置==================================== disabled=false #配置tracker.conf这个配置文件是否生效,因为在启动fastdfs服务端进程时需要指定配置文件,所以需要使次配置文件生效。false是生效,true是让此文件不生效。 bind_addr= #程序的监听地址,如果不设定则监听所有地址 port=22122 #tracker监听的端口 connect_timeout=30 #连接超时时间,针对socket套接字函数connect,默认为30秒 network_timeout=60 #网络通讯超时(秒) base_path=/home/yuqing/fastdfs #Tracker数据/日志目录地址,这里一般要修改的,如:/opt/fdfs max_connections=256 #允许的最大连接数,这里要根据需求调整.如设置成2048. accept_threads=1 #接收数据的线程数 work_threads=4 #工作线程数,一般为cpu个数,当然CPU核数太多的话可以稍小一点。如我们是12CCPU,这里设置为8. min_buff_size = 8KB #接收/发送数据的buff大小,必须大于8KB max_buff_size = 128KB #接收/发送数据的buff大小必须小于128KB store_lookup=2 #在存储文件时选择group的策略也就是文件上传选取group的规则,0:轮训策略 1:指定某一个组 2:负载均衡,选择空闲空间最大的group。 store_group=group2 #如果上面store_lookup=1,这里就起作用了,这里就要指定某一个组来存储上传的文件了。(一般store_lookup=1是由于旧的组已经没有空间了,因为下面有规则设置,所以就要新添加的机器就要放到新组里面,所以再上传就要传到新组里面。) store_server=0 # 选择哪个storage server 进行上传操作一个文件被上传后,这个storage server就相当于这个文件的storage server源,会对同组的storage server推送这个文件达到同步效果 # 0: 轮询方式(默认) # 1: 根据ip 地址进行排序选择第一个服务器(IP地址最小者) # 2: 根据优先级进行排序(上传优先级由storage server来设置,参数名为upload_priority),优先级值越小优先级越高。 store_path=0 #选择文件上传到storage中的哪个(目录/挂载点),storage可以有多个存放文件的base path 0:轮训策略 2:负载均衡,选择空闲空间最大的。我们线上选择的是2,让其选择空闲空间最大的去存放。 download_server=0 # 选择哪个 storage server 作为下载服务器。 # 0: 轮询方式,可以下载当前文件的任一storage server # 1: 哪个为源storage server就用哪一个,就是之前上传到哪个storage server服务器就是哪个了 reserved_storage_space = 10% #系统预留空间,当一个group中的任何storage的剩余空间小于定义的值,整个group就不能上传文件了(V4开始支持百分比方式),如:10G(字节数可以是GB,MB,KB,B)或者10%。 log_level=info #日志信息级别 run_by_group= #进程以那个用户组运行,不指定默认是当前用户组 run_by_user= #进程以那个用户运行,不指定默认是当前用户 allow_hosts=* # 可以连接到此 tracker server 的ip范围,默认是允许所有(对所有类型的连接都有影响,包括客户端,storage server) # for example: # allow_hosts=10.0.1.[1-15,20] # allow_hosts=host[01-08,20-25].domain.com # allow_hosts=192.168.5.64/26 sync_log_buff_interval = 10 #同步或刷新日志信息到硬盘的时间间隔,单位为秒。注意:tracker server的日志不是时时写硬盘的,而是先写内存。 check_active_interval = 120 #检测storage服务器的间隔时间,storage定期主动向tracker发送心跳,如果在指定的时间没收到信号,tracker认为storage故障,默认120s thread_stack_size = 64KB #线程栈的大小。FastDFS server端采用了线程方式。线程栈越大,一个线程占用的系统资源就越多。如果要启动更多的线程可以适当降低本参数值。 storage_ip_changed_auto_adjust = true #这个参数控制当storage server IP地址改变时,集群是否自动调整。注:只有在storage server进程重启时才完成自动调整。 # ===========================同步====================================== storage_sync_file_max_delay = 86400 # V2.0引入的参数。存储服务器之间同步文件的最大延迟时间,缺省为1天。根据实际情况进行调整。 storage_sync_file_max_time = 300 # V2.0引入的参数。存储服务器同步一个文件需要消耗的最大时间,缺省为300s,即5分钟。 # 注:本参数并不影响文件同步过程。本参数仅在下载文件时,作为判断当前文件是否被同步完成的一个阀值。 # ===========================trunk 和 slot============================ use_trunk_file = false # V3.0引入的参数。是否使用小文件合并存储特性,缺省是关闭的。 slot_min_size = 256 #V3.0引入的参数。trunk file分配的最小字节数。比如文件只有16个字节,系统也会分配slot_min_size个字节。 slot_max_size = 16MB #V3.0引入的参数。只有文件大小<=这个参数值的文件,才会合并存储。如果一个文件的大小大于这个参数值,将直接保存到一个文件中(即不采用合并存储方式)。 trunk_file_size = 64MB #V3.0引入的参数。合并存储的trunk file大小,至少4MB,缺省值是64MB。不建议设置得过大。 trunk_create_file_advance = false #是否开启创建trunk file。只有当这个参数为true,下面3个以trunk_create_file_打头的参数才有效。默认我们开启trunk合并。 trunk_create_file_time_base = 02:00 # 提前创建trunk file的起始时间点(基准时间),02:00表示第一次创建的时间点是凌晨2点 trunk_create_file_interval = 86400 #创建trunk file的时间间隔,单位为秒。如果每天只提前创建一次,则设置为86400 trunk_create_file_space_threshold = 20G # 提前创建trunk file时,需要达到的空闲trunk大小,比如本参数为20G,而当前空闲trunk为4GB,那么只需要创建16GB的trunk file即可。 trunk_init_check_occupying = false #trunk初始化时,是否检查可用空间是否被占用 trunk_init_reload_from_binlog = false #是否无条件从trunk binlog中加载trunk可用空间信息,FastDFS缺省是从快照文件storage_trunk.dat中加载trunk可用空间,该文件的第一行记录的是trunk binlog的offset,然后从binlog的offset开始加载 trunk_compress_binlog_min_interval = 0 #压缩trunk binlog 的最小时间间隔,单位:秒。默认值为0,0代表不压缩。FastDFS会在trunk初始化或者被销毁的时候压缩trunk binlog文件,如果设置的话建议设置成86400,一天设置一次。 # ===========================其他设置============================ use_storage_id = false #是否使用storage id替换ip作为storage server标识,默认为false storage_ids_filename = storage_ids.conf #在文件中设置组名、server ID和对应的IP地址,参见源码目录下的配置示例:storage_ids.conf id_type_in_filename = ip #存储服务器的文件名中的id类型,取值如下 # IP:存储服务器的IP地址 # id:被存储服务器的服务器标识 # 只有当use_storage_id设置为true时此参数是有效的,默认值是IP store_slave_file_use_link = false #存储从文件是否采用symbol link(符号链接)方式。如果设置为true,一个从文件将占用两个文件:原始文件及指向它的符号链接。 rotate_error_log = false #是否定期轮转error log,目前仅支持一天轮转一次 error_log_rotate_time=00:00 #error log定期轮转的时间点,只有当rotate_error_log设置为true时有效 rotate_error_log_size = 0 #error log按大小轮转,设置为0表示不按文件大小轮转,否则当error log达到该大小,就会轮转到新文件中 log_file_keep_days = 0 #保留日志文件0表示不删除旧日志文件,默认值为0 use_connection_pool = false #是否使用连接池 connection_pool_max_idle_time = 3600 #连接的空闲时间超过这个时间将被关闭,单位:秒 # ===========================HTTP 相关================================= http.server_port=8080 #tracker server上的HTTP服务器端口号 http.check_alive_interval=30 # 检查storage http server存活的间隔时间,单位为秒 http.check_alive_type=tcp #检查存储HTTP服务器的活动类型,值为:tcp:仅连接到具有HTTP端口的存储服务器,不要求和获取响应http:storage check alive url必须返回http状态200默认值为tcp http.check_alive_uri=/status.html #检查storage http server是否alive的uri/url
#上面有很大一部分提到了trunk合并,一般我们是默认不合并的,小文件就是存储到目录里面。下面两篇链接讲的比较详细和专业:
http://blog.csdn.net/hfty290/article/details/42026215
http://blog.csdn.net/liuaigui/article/details/9981135
3.2 storage.conf配置文件介绍
disabled=false #是否启用禁用配置文件,false是不启用禁用,true是启动禁用。 group_name=group1 #本storage server所属组名 bind_addr= #绑定IP,默认就是监听在0.0.0.0上面 client_bind=true #bind_addr通常是针对server的。当指定bind_addr时,本参数才有效。本storage server作为client连接其他服务器(如tracker server、其他storage server),是否绑定bind_addr。true:绑定bind_addr所指定的IP。false:绑定本机的任意IP port=23000 #storage server服务端口 connect_timeout=30 #连接超时(秒),默认值 30s network_timeout=60 #网络超时(秒),默认值 60s heart_beat_interval=30 #心跳间隔时间,单位为秒 (这里是指主动向tracker server 发送心跳) stat_report_interval=60 #storage server向tracker server报告磁盘剩余空间的时间间隔,单位为秒。 base_path=/home/yuqing/fastdfs # base_path目录地址,根目录必须存在子目录会自动生成。注 :这里不是上传的文件存放的地址,之前是的,在某个版本后更改了 max_connections=256 #最大连接数,根据需求可以调大,如设置成2048. buff_size = 256KB #接收/发送数据的buff大小,必须大于8KB,如这里可以设置成2048KB,设置的大一点。 accept_threads=1 #接收数据的线程数 work_threads=4 #接收数据的线程数,可以是CPU的核数或者比CPU核数小。 disk_rw_separated = true #磁盘IO读写是否分离,缺省是分离的。磁盘读/写分离为false则为混合读写,如果为true则为分离读写的。默认值为V2.00以后为true。 disk_reader_threads = 1 # 针对单个存储路径的读线程数,缺省值为1。我们这里设置为4. # 读写分离时,系统中的读线程数 = disk_reader_threads * store_path_count # 读写混合时,系统中的读写线程数 = (disk_reader_threads + disk_writer_threads) * store_path_count disk_writer_threads = 1 # 针对单个存储路径的写线程数,缺省值为1。我们这里设置为4. # 读写分离时,系统中的写线程数 = disk_writer_threads * store_path_count # 读写混合时,系统中的读写线程数 = (disk_reader_threads + disk_writer_threads) * store_path_count sync_wait_msec=50 # 同步文件时,如果从binlog中没有读到要同步的文件,休眠N毫秒后重新读取。0表示不休眠,立即再次尝试读取。如果没特别需求,默认值50毫秒就可以了。 # 出于CPU消耗考虑,不建议设置为0。如何希望同步尽可能快一些,可以将本参数设置得小一些,比如设置为10ms sync_interval=0 #同步完一个文件后间隔多少毫秒同步下一个文件,0表示不休息直接同步 sync_start_time=00:00 sync_end_time=23:59 #上面两段表示这段时间内同步文件,也就是说全天都在同步数据。第一条是开始时间段,第二条是结束时间段。 write_mark_file_freq=500 #同步完多少文件后写mark标记,什么是mak标记等下面搭建的时候会文件举例。 store_path_count=1 #storage在存储文件时支持多路径,默认只设置一个,通俗的将也就是你要挂载几个存储盘,你这里就设置对应的磁盘数,比如12块盘当store,这里就设置为12. store_path0=/home/yuqing/fastdfs #逐一配置store_path个路径,索引号基于0。注意配置方法后面有0,1,2 ......,需要配置0到store_path - 1。如果不配置base_path0,那边它就和base_path对应的路径一样。 #如下面的配置(这里是两块盘,所以store_path_count=2): #store_path0=/data01/fastdfs #store_path1=/data02/fastdfs subdir_count_per_path=256 # FastDFS存储文件时,采用了两级目录。如果本参数只为N(如:256),那么storage server在初次运行时,会自动创建 N * N 个存放文件的子目录。 tracker_server=192.168.209.121:22122 #tracker_server 的列表要写端口(是主动连接tracker_server)有多个tracker server时,每个tracker server写一行,如下面: #192.168.1.103:22122 #192.168.1.104:22122 log_level=info #日志级别,我们这里设置为了warn。 run_by_group= #指定运行该程序的用户组,不设置就默认为当前启动程序的用户组。 run_by_user= #指定运行该程序的用户,不设置就默认为当前启动程序的用户。 allow_hosts=* #默认是允许所有主机连接 file_distribute_path_mode=0 # 0: 轮流存放,在一个目录下存储设置的文件数后(参数file_distribute_rotate_count中设置文件数),使用下一个目录进行存储。 # 1: 随机存储,根据文件名对应的hash code来分散存储。 file_distribute_rotate_count=100 # 当上面的参数file_distribute_path_mode配置为0(轮流存放方式)时,本参数有效。 # 当一个目录下的文件存放的文件数达到本参数值时,后续上传的文件存储到下一个目录中。 fsync_after_written_bytes=0 #写大文件时调用fsync到磁盘,0:永远不要调用fsync。other:写多少字节后开始同步,当写入字节> =这个字节时调用fsync。默认值为0(从不调用fsync) sync_log_buff_interval=10 # 同步或刷新日志信息到硬盘的时间间隔,单位为秒。注意:storage server 的日志信息不是时时写硬盘的,而是先写内存。 sync_binlog_buff_interval=10 #同步binglog(更新操作日志)到硬盘的时间间隔,单位为秒。本参数会影响新上传文件同步延迟时间 sync_stat_file_interval=300 # 把storage的stat文件同步到磁盘的时间间隔,单位为秒。注:如果stat文件内容没有变化,不会进行同步 thread_stack_size=512KB # 线程栈的大小。FastDFS server端采用了线程方式。应该大于等于512KB。 upload_priority=10 #本storage server作为源服务器,上传文件的优先级,可以为负数。值越小,优先级越高。里就和 tracker.conf 中store_server= 2时的配置相对应了。 if_alias_prefix= #网卡别名,用ifconfig -a可以看到很多本机的网卡别名,类似eth0,eth0:0等等。多个网卡别名使用逗号分割,默认为空,让系统自动选择。 check_file_duplicate=0 # 是否检测上传文件已经存在。如果已经存在,则不存文件内容,建立一个符号链接以节省磁盘空间。 这个应用要配合FastDHT 使用,所以打开前要先安装FastDHT。1或yes 是检测,0或no 是不检测 file_signature_method=hash #文件签名方法用于检查文件重复,hash:四个32位哈希码。md5:MD5签名。默认值是V4.01之后的哈希 key_namespace=FastDFS #当参数check_file_duplicate设定为1 或 yes时(true/on也是可以的),在FastDHT中的命名空间。 keep_alive=0 # 与FastDHT servers 的连接方式 (是否为持久连接) ,默认是0(短连接方式)。可以考虑使用长连接,这要看FastDHT server的连接数是否够用。 use_access_log = false #是否记录访问日志 rotate_access_log = false # 是否定期轮转access log,目前仅支持一天轮转一次 access_log_rotate_time=00:00 # access log定期轮转的时间点,只有当rotate_access_log设置为true时有效 rotate_error_log = false #是否定期轮转error log,目前仅支持一天轮转一次 error_log_rotate_time=00:00 # error log定期轮转的时间点,只有当rotate_error_log设置为true时有效 rotate_access_log_size = 0 # access log按文件大小轮转,设置为0表示不按文件大小轮转,否则当access log达到该大小,就会轮转到新文件中 rotate_error_log_size = 0 # error log按文件大小轮转,设置为0表示不按文件大小轮转,否则当error log达到该大小,就会轮转到新文件中 log_file_keep_days = 0 #保留日志文件的日期0表示不删除旧的日志文件 file_sync_skip_invalid_record=false #文件同步的时候,是否忽略无效的binlog记录 use_connection_pool = false # 是否使用连接池 connection_pool_max_idle_time = 3600 # 连接的空闲时间超过这个时间将被关闭,单位:秒 http.domain_name= #如果domain_name为空,请使用此存储服务器的IP地址,否则此域名将在由跟踪服务器重定向的URL中出现 http.server_port=8888 #该存储服务器上的Web服务器的端口
博文来自:www.51niux.com
3.3 client.conf配置文件介绍
# cat /etc/fdfs/client.conf
connect_timeout=30 #连接的超时时间 network_timeout=60 #网络超时(秒),默认值 60s base_path=/home/yuqing/fastdfs #存储日志文件的基本路径,如/opt/fastdfs tracker_server=192.168.0.197:22122 #tracker server的列表,多个的话就是多行,如: #192.168.1.103:22122 #192.168.1.104:22122 log_level=info #日志级别 use_connection_pool = false #是否使用连接池 connection_pool_max_idle_time = 3600 #连接的空闲时间超过这个时间将被关闭,单位:秒 load_fdfs_parameters_from_tracker=false #是否加载来自跟踪服务器的FastDFS参数,默认值为false。这里可以设置为true。 use_storage_id = false #是否使用storage id替换ip作为storage server标识,默认为false storage_ids_filename = storage_ids.conf #在文件中设置组名、server ID和对应的IP地址,参见源码目录下的配置示例:storage_ids.conf http.tracker_server_port=80 #HTTP设置,tracker server上的HTTP服务器端口号
3.4 fastdfs副本数定制
上面对fastdfs的三个配置文件进行了参数详解,细心的你会发现并不像mfs和hdfs一样,里面会指定副本数,也就是一个文件存相同的几份,这就跟fastdfs的存储机制有关系。
Storage server(后简称storage)以组(卷,group或volume)为单位组织,一个group内包含多台storage机器,数据互为备份,存储空间以group内容量最小的storage为准。其简单意思就是,以组内的storage机器为副本数,比如你group1组内有三个storage,那么你一份文件的副本数就是三。以group为单位组织存储能方便的进行应用隔离、负载均衡、副本数定制(group内storage server数量即为该group的副本数),比如将不同应用数据存到不同的group就能隔离应用数据,同时还可根据应用的访问特性来将应用分配到不同的group来做负载均衡。缺点是group的容量受单机存储容量的限制,同时当group内有机器坏掉时,数据恢复只能依赖group内地其他机器,使得恢复时间会很长。
通过上面可以看出,fastdfs的副本数是依赖于group组内的storage数量,而容量受单机存储的限制,如果想让fastdfs的存储容量扩容,一般就是建新group组在新group组里面加新机器,旧组扩容的话就是换单盘空间更大的磁盘了。
另外一个知识点:storage接受到写文件请求时,会根据配置好的规则(后面会介绍),选择其中一个存储目录来存储文件。为了避免单个目录下的文件数太多,在storage第一次启动时,会在每个数据存储目录里创建2级子目录,每级256个,总共65536个文件夹,新写的文件会以hash的方式被路由到其中某个子目录下,然后将文件数据直接作为一个本地文件存储到该目录中。
3.5 Tracker server简述
Tracker是FastDFS的协调者,负责管理所有的storage server和group,每个storage在启动后会连接Tracker,告知自己所属的group等信息,并保持周期性的心跳,tracker根据storage的心跳信息,建立group==>[storage server list]的映射表。
Tracker需要管理的元信息很少,会全部存储在内存中;另外tracker上的元信息都是由storage汇报的信息生成的,本身不需要持久化任何数据,这样使得tracker非常容易扩展,直接增加tracker机器即可扩展为tracker cluster来服务,cluster里每个tracker之间是完全对等的,所有的tracker都接受stroage的心跳信息,生成元数据信息来提供读写服务。
