open-falcon搭建(一)
小米监控大家已经不陌生了,当采集节点过千的时候就要采用小米监控了,关于小米监控的优势百度一搜一大把,就不多做介绍了。
文档:http://book.open-falcon.org/zh_0_2/
一、产品介绍
#还是把官网介绍盗过来吧,要不老得去打官网。
1.1 介绍:
监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供翔实的数据用于追查定位问题。监控系统作为一个成熟的运维产品,业界有很多开源的实现可供选择。 当公司刚刚起步,业务规模较小,运维团队也刚刚建立的初期,选择一款开源的监控系统,是一个省时省力,效率最高的方案。之后,随着业务规模的持续快速增长,监控的对象也越来越多,越来越复杂, 监控系统的使用对象也从最初少数的几个SRE,扩大为更多的DEVS,SRE。这时候,监控系统的容量和用户的“使用效率”成了最为突出的问题。
1.2 特点:
1、强大灵活的数据采集:自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags) 2、水平扩展能力:支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询 3、高效率的告警策略管理:高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用 4、人性化的告警设置:最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期 5、高效率的graph组件:单机支撑200万metric的上报、归档、存储(周期为1分钟) 6、高效的历史数据query组件:采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据 7、dashboard:多维度的数据展示,用户自定义Screen 8、高可用:整个系统无核心单点,易运维,易部署,可水平扩展 9、开发语言: 整个系统的后端,全部golang编写,portal和dashboard使用python编写。
1.3 架构:

每台服务器,都有安装falcon-agent,falcon-agent是一个golang开发的daemon程序,用于自发现的采集单机的各种数据和指标,这些指标包括不限于以下几个方面,共计200多项指标。
CPU相关 磁盘相关 IO Load 内存相关 网络相关 端口存活、进程存活 ntp offset(插件) 某个进程资源消耗(插件) netstat、ss 等相关统计项采集 机器内核配置参数
只要安装了falcon-agent的机器,就会自动开始采集各项指标,主动上报,不需要用户在server做任何配置(这和zabbix有很大的不同),这样做的好处,就是用户维护方便,覆盖率高。当然这样做也会server端造成较大的压力,不过open-falcon的服务端组件单机性能足够高,同时都可以水平扩展,所以自动多采集足够多的数据,反而是一件好事情,对于SRE和DEV来讲,事后追查问题,不再是难题。
另外,falcon-agent提供了一个proxy-gateway,用户可以方便的通过http接口,push数据到本机的gateway,gateway会帮忙高效率的转发到server端。
falcon-agent,可以在我们的github上找到 : https://github.com/open-falcon/falcon-plus
1.4 数据模型
Data Model是否强大,是否灵活,对于监控系统用户的“使用效率”至关重要。比如以zabbix为例,上报的数据为hostname(或者ip)、metric,那么用户添加告警策略、管理告警策略的时候,就只能以这两个维度进行。举一个最常见的场景:
hostA的磁盘空间,小于5%,就告警。一般的服务器上,都会有两个主要的分区,根分区和home分区,在zabbix里面,就得加两条规则;如果是hadoop的机器,一般还会有十几块的数据盘,还得再加10多条规则,这样就会痛苦,不幸福,不利于自动化(当然zabbix可以通过配置一些自动发现策略来搞定这个,不过比较麻烦)。
open-falcon,采用和opentsdb相同的数据格式:metric、endpoint加多组key value tags,举两个例子:
{
metric: load.1min,
endpoint: open-falcon-host,
tags: srv=falcon,idc=aws-sgp,group=az1,
value: 1.5,
timestamp: `date +%s`,
counterType: GAUGE,
step: 60
}
{
metric: net.port.listen,
endpoint: open-falcon-host,
tags: port=3306,
value: 1,
timestamp: `date +%s`,
counterType: GAUGE,
step: 60
}通过这样的数据结构,我们就可以从多个维度来配置告警,配置dashboard等等。 备注:endpoint是一个特殊的tag。
1.5 数据采集
transfer,接收客户端发送的数据,做一些数据规整,检查之后,转发到多个后端系统去处理。在转发到每个后端业务系统的时候,transfer会根据一致性hash算法,进行数据分片,来达到后端业务系统的水平扩展。
transfer 提供jsonRpc接口和telnet接口两种方式,transfer自身是无状态的,挂掉一台或者多台不会有任何影响,同时transfer性能很高,每分钟可以转发超过500万条数据。
transfer目前支持的业务后端,有三种,judge、graph、opentsdb。judge是我们开发的高性能告警判定组件,graph是我们开发的高性能数据存储、归档、查询组件,opentsdb是开源的时间序列数据存储服务。可以通过transfer的配置文件来开启。
transfer的数据来源,一般有三种:
1.falcon-agent采集的基础监控数据 2.falcon-agent执行用户自定义的插件返回的数据 3.client library:线上的业务系统,都嵌入使用了统一的perfcounter.jar,对于业务系统中每个RPC接口的qps、latency都会主动采集并上报
说明:上面这三种数据,都会先发送给本机的proxy-gateway,再由gateway转发给transfer。
基础监控是指只要是个机器(或容器)就能加的监控,比如cpu mem net io disk等,这些监控采集的方式固定,不需要配置,也不需要用户提供额外参数指定,只要agent跑起来就可以直接采集上报上去; 非基础监控则相反,比如端口监控,你不给我端口号就不行,不然我上报所有65535个端口的监听状态你也用不了, 这类监控需要用户配置后才会开始采集上报的监控(包括类似于端口监控的配置触发类监控,以及类似于mysql的插件脚本类监控),一般就不算基础监控的范畴了。
1.6 报警
报警判定,是由judge组件来完成。用户在web portal来配置相关的报警策略,存储在MySQL中。heartbeat server 会定期加载MySQL中的内容。judge也会定期和heartbeat server保持沟通,来获取相关的报警策略。
heartbeat sever不仅仅是单纯的加载MySQL中的内容,根据模板继承、模板项覆盖、报警动作覆盖、模板和hostGroup绑定,计算出最终关联到每个endpoint的告警策略,提供给judge组件来使用。
transfer转发到judge的每条数据,都会触发相关策略的判定,来决定是否满足报警条件,如果满足条件,则会发送给alarm,alarm再以邮件、短信、米聊等形式通知相关用户,也可以执行用户预先配置好的callback地址。
用户可以很灵活的来配置告警判定策略,比如连续n次都满足条件、连续n次的最大值满足条件、不同的时间段不同的阈值、如果处于维护周期内则忽略 等等。
另外也支持突升突降类的判定和告警。
1.7 API
到这里,数据已经成功的存储在了graph里。如何快速的读出来呢,读过去1小时的,过去1天的,过去一月的,过去一年的,都需要在1秒之内返回。
这些都是靠graph和API组件来实现的,transfer会将数据往graph组件转发一份,graph收到数据以后,会以rrdtool的数据归档方式来存储,同时提供查询RPC接口。
API面向终端用户,收到查询请求后,会去多个graph里面,查询不同metric的数据,汇总后统一返回给用户。
1.8 Dashboard
dashboard首页,用户可以以多个维度来搜索endpoint列表,即可以根据上报的tags来搜索关联的endpoint。
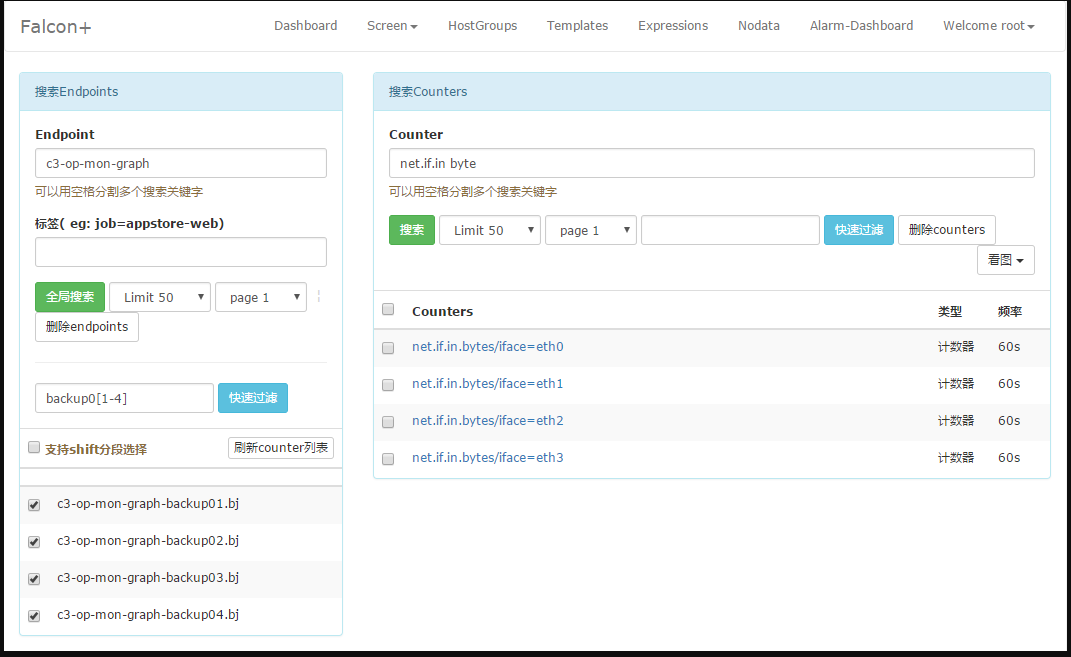
用户可以自定义多个metric,添加到某个screen中,这样每天早上只需要打开screen看一眼,服务的运行情况便尽在掌握了。
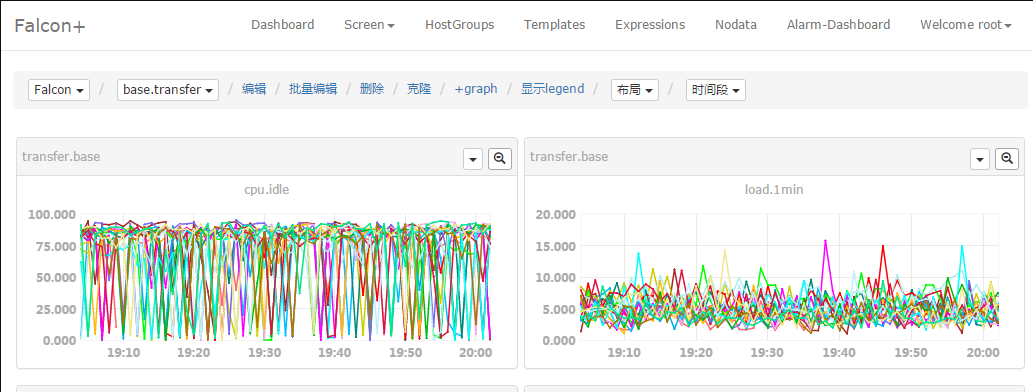
当然,也可以查看清晰大图,横坐标上zoom in/out,快速筛选反选。总之用户的“使用效率”是第一要务。

一个高效的portal,对于提升用户的“使用效率”,加成很大,平时大家都这么忙,能给各位SRE、Devs减轻一些负担,那是再好不过了。
这是host group的管理页面,可以和服务树结合,机器进出服务树节点,相关的模板会自动关联或者解除。这样服务上下线,都不需要手动来变更监控,大大提高效率,降低遗漏和误报警。
一个最简单的模板的例子,模板支持继承和策略覆盖,模板和host group绑定后,host group下的机器会自动应用该模板的所有策略。
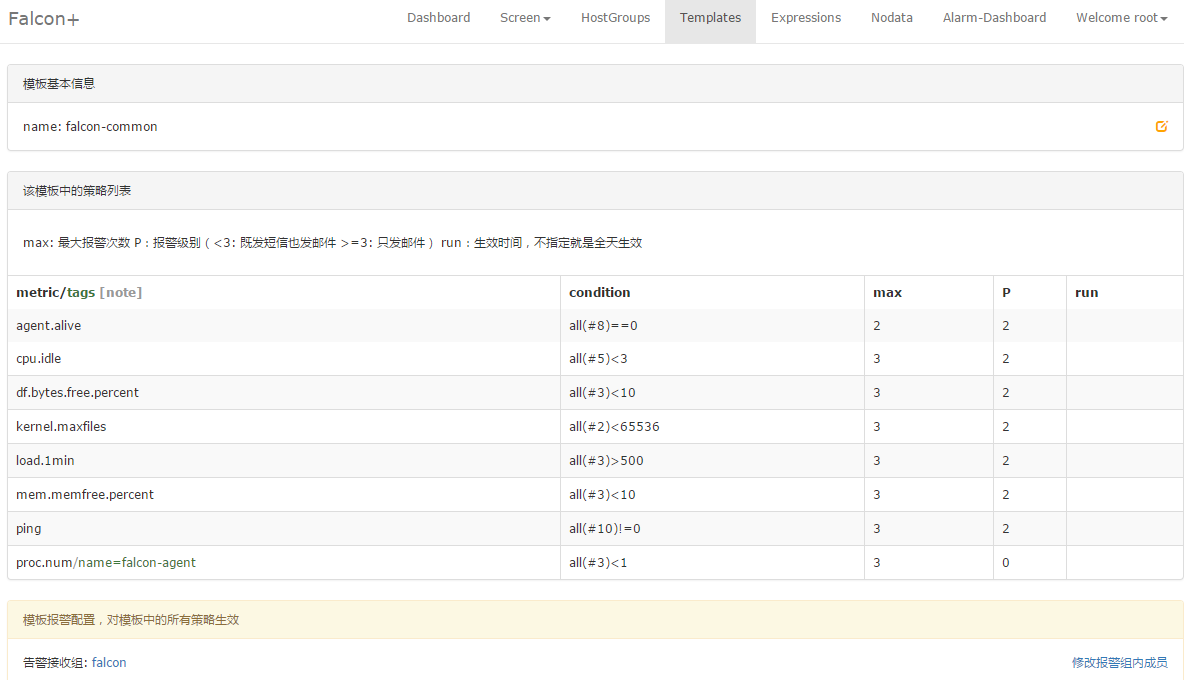
当然,也可以写一个简单的表达式,就能达到监控的目的,这对于那些endpoint不是机器名的场景非常方便。
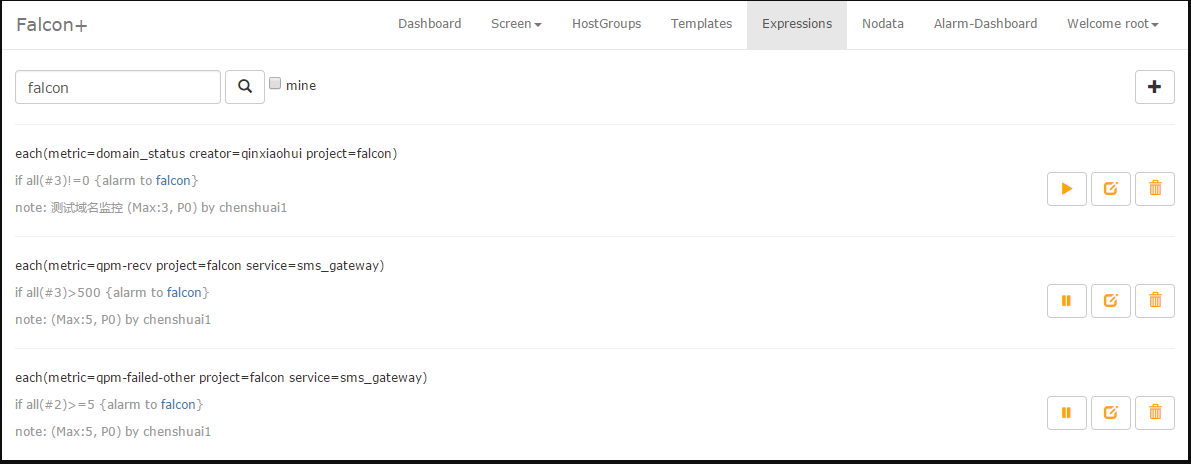
1.9 存储
对于监控系统来讲,历史数据的存储和高效率查询,永远是个很难的问题!
1. 数据量大:目前我们的监控系统,每个周期,大概有2000万次数据上报(上报周期为1分钟和5分钟两种,各占50%),一天24小时里,从来不会有业务低峰,不管是白天和黑夜,每个周期,总会有那么多的数据要更新。 2. 写操作多:一般的业务系统,通常都是读多写少,可以方便的使用各种缓存技术,再者各类数据库,对于查询操作的处理效率远远高于写操作。而监控系统恰恰相反,写操作远远高于读。每个周期几千万次的更新操作,对于常用数据库(MySQL、postgresql、mongodb)都是无法完成的。 3. 高效率的查:我们说监控系统读操作少,是说相对写入来讲。监控系统本身对于读的要求很高,用户经常会有查询上百个meitric,在过去一天、一周、一月、一年的数据。如何在1秒内返回给用户并绘图,这是一个不小的挑战。
open-falcon在这块,投入了较大的精力。我们把数据按照用途分成两类,一类是用来绘图的,一类是用户做数据挖掘的。
对于绘图的数据来讲,查询要快是关键,同时不能丢失信息量。对于用户要查询100个metric,在过去一年里的数据时,数据量本身就在那里了,很难1秒之类能返回,另外就算返回了,前端也无法渲染这么多的数据,还得采样,造成很多无谓的消耗和浪费。我们参考rrdtool的理念,在数据每次存入的时候,会自动进行采样、归档。我们的归档策略如下,历史数据保存5年。同时为了不丢失信息量,数据归档的时候,会按照平均值采样、最大值采样、最小值采样存三份。
// 1分钟一个点存 12小时
c.RRA("AVERAGE", 0.5, 1, 720)
// 5m一个点存2d
c.RRA("AVERAGE", 0.5, 5, 576)
c.RRA("MAX", 0.5, 5, 576)
c.RRA("MIN", 0.5, 5, 576)
// 20m一个点存7d
c.RRA("AVERAGE", 0.5, 20, 504)
c.RRA("MAX", 0.5, 20, 504)
c.RRA("MIN", 0.5, 20, 504)
// 3小时一个点存3个月
c.RRA("AVERAGE", 0.5, 180, 766)
c.RRA("MAX", 0.5, 180, 766)
c.RRA("MIN", 0.5, 180, 766)
// 1天一个点存1year
c.RRA("AVERAGE", 0.5, 720, 730)
c.RRA("MAX", 0.5, 720, 730)
c.RRA("MIN", 0.5, 720, 730)对于原始数据,transfer会打一份到hbase,也可以直接使用opentsdb,transfer支持往opentsdb写入数据。
博文来自:www.51niux.com
二、单机安装
2.1 环境准备
# yum install git golang -y #我用的是Centos7的操作系统,Git >= 1.7.5,Go >= 1.6
# yum install mariadb mariadb-server -y #安装mysql,当然实际情况mysql一般在别的机器上
# service mariadb start
#安装redis并启动redis:http://blog.51niux.com/?id=127
2.2 下载源码
#open-falcon有0.1与0.2版本,0.1版本各个模块独立运行,非常不方便,0.2版本各个模块集成,编译打包很方便
# vi /etc/profile
export FALCON_HOME=/usr/local export GOPATH=/opt export WORKSPACE=$FALCON_HOME/open-falcon
# source /etc/profile
# mkdir -p $GOPATH/src/github.com/open-falcon
# cd $GOPATH/src/github.com/open-falcon
# git clone https://github.com/open-falcon/falcon-plus.git
2.3 数据库初始化及编译打包
数据库初始化:
#cd $GOPATH/falcon-plus/scripts/mysql/db_schema
# mysqladmin -uroot -p password "test123"
mysql -h 127.0.0.1 -u root -ptest123 < 1_uic-db-schema.sql mysql -h 127.0.0.1 -u root -ptest123 < 2_portal-db-schema.sql mysql -h 127.0.0.1 -u root -ptest123 < 3_dashboard-db-schema.sql mysql -h 127.0.0.1 -u root -ptest123 < 4_graph-db-schema.sql mysql -h 127.0.0.1 -u root -ptest123 < 5_alarms-db-schema.sql
编译打包:
# cd $GOPATH/src/github.com/open-falcon/falcon-plus/
# make all
# make agent
# make pack
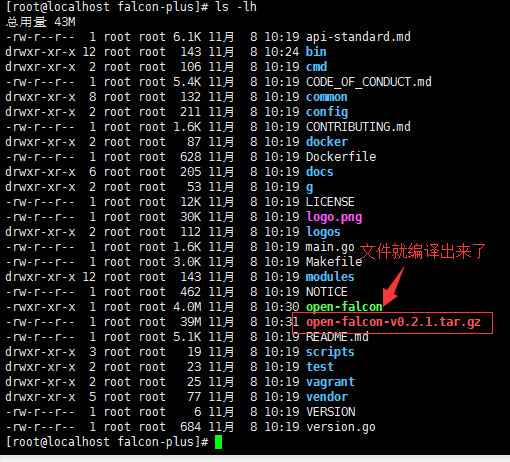
2.4 解压运行
# mkdir $WORKSPACE
# tar zxf open-falcon-v0.2.1.tar.gz -C $WORKSPACE
# cd $WORKSPACE
2.5 启动后端
#在一台机器上启动所有的后端组件
# grep -Ilr 3306 ./ | xargs -n1 -- sed -i 's/root:/root:test123/g' #首先修改配置文件中的数据库账号和密码,不然的话启动会卡主
# cd $WORKSPACE
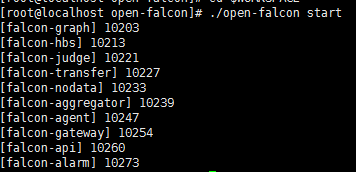
# ./open-falcon start #启动服务
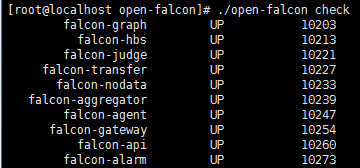
# ./open-falcon check #检查所有模块的启动状况
#日志记录在$WorkDir/$moduleName/log/logs/xxx.log
2.6 安装前端
#open-falcon采用前后端分离,前端dashboard为另外一个项目https://github.com/open-falcon/dashboard,支持docker与i18n,源码运行,为python环境
克隆前端组件代码:
# cd $WORKSPACE
# git clone https://github.com/open-falcon/dashboard.git
安装依赖包:
#yum install -y python-virtualenv
#yum install -y python-devel
#yum install -y openldap-devel
#yum install -y mysql-devel
#yum groupinstall "Development tools"
#cd $WORKSPACE/dashboard/
#virtualenv ./env
#./env/bin/pip install -r pip_requirements.txt -i https://pypi.douban.com/simple
修改配置:
# vim rrd/config.py
# app config
import os
LOG_LEVEL = os.environ.get("LOG_LEVEL",'DEBUG')
SECRET_KEY = os.environ.get("SECRET_KEY","secret-key")
PERMANENT_SESSION_LIFETIME = os.environ.get("PERMANENT_SESSION_LIFETIME",3600 * 24 * 30)
SITE_COOKIE = os.environ.get("SITE_COOKIE","open-falcon-ck")
# Falcon+ API
API_ADDR = os.environ.get("API_ADDR","http://192.168.1.151:8080/api/v1")
#上面讲127.0.0.1修改为本机的对外IP
API_USER = os.environ.get("API_USER","admin")
API_PASS = os.environ.get("API_PASS","password")
# portal database
# TODO: read from api instead of db
PORTAL_DB_HOST = os.environ.get("PORTAL_DB_HOST","127.0.0.1")
PORTAL_DB_PORT = int(os.environ.get("PORTAL_DB_PORT",3306))
PORTAL_DB_USER = os.environ.get("PORTAL_DB_USER","root")
PORTAL_DB_PASS = os.environ.get("PORTAL_DB_PASS","test123")
#上面就是mysql真实的链接地址和账号密码等
PORTAL_DB_NAME = os.environ.get("PORTAL_DB_NAME","falcon_portal")
# alarm database
# TODO: read from api instead of db
ALARM_DB_HOST = os.environ.get("ALARM_DB_HOST","127.0.0.1")
ALARM_DB_PORT = int(os.environ.get("ALARM_DB_PORT",3306))
ALARM_DB_USER = os.environ.get("ALARM_DB_USER","root")
ALARM_DB_PASS = os.environ.get("ALARM_DB_PASS","test123")
#上面就是mysql真实的链接地址和账号密码等
ALARM_DB_NAME = os.environ.get("ALARM_DB_NAME","alarms")2.7 启动前端
#注意一下这个命令:# ./env/bin/python wsgi.py #这是以开发者模式启动,也就是输出输出到屏幕
# pwd
/usr/local/open-falcon/dashboard
# bash control start #以生产环境启动,另外bash control stop就是停止dashboard运行的方法
falcon-dashboard started..., pid=25113
# bash control tail #查看日志
博文来自:www.51niux.com
2.8 Dashboard登录
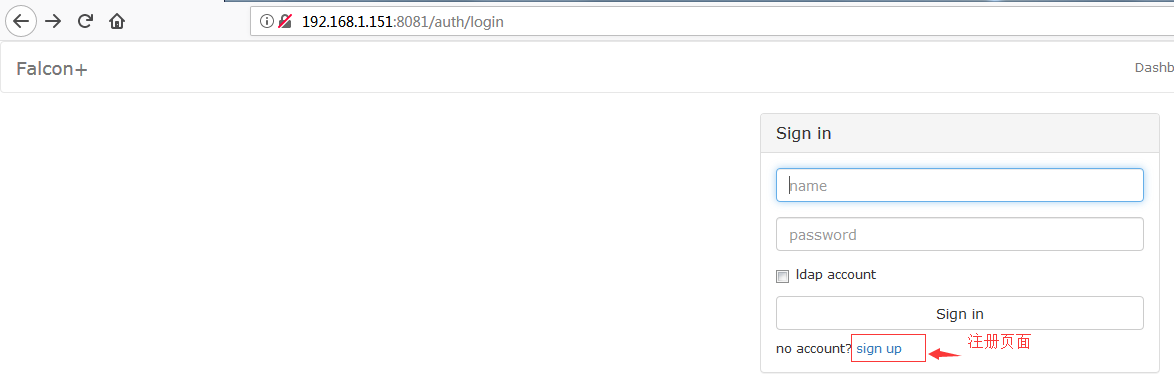
#dashbord没有默认创建任何账号包括管理账号,需要你通过页面进行注册账号。想拥有管理全局的超级管理员账号,需要手动注册用户名为root的账号(第一个帐号名称为root的用户会被自动设置为超级管理员)。超级管理员可以给普通用户分配权限管理。

#成功的话会有提示你注册成功

2.9 查看一下监控
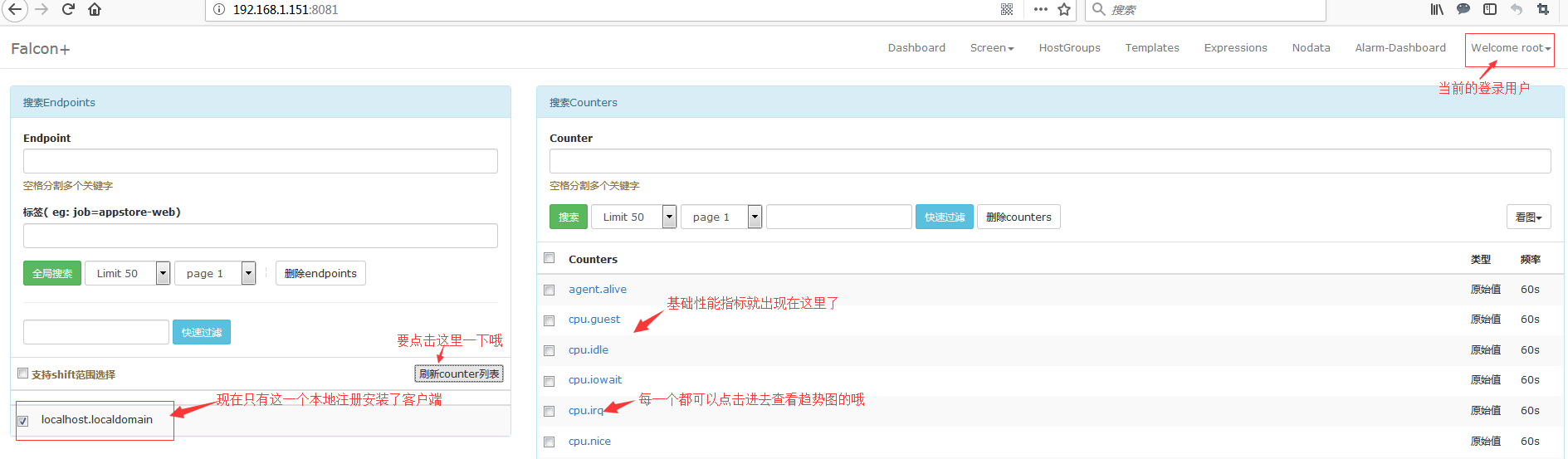
# netstat -lntup #查看一下本机都启动了哪些服务吧
Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 1843/mysqld tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6702/redis-server 1 tcp 0 0 0.0.0.0:8081 0.0.0.0:* LISTEN 25113/python tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 982/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1084/master tcp6 0 0 :::16060 :::* LISTEN 10254/falcon-gatewa tcp6 0 0 :::4444 :::* LISTEN 10227/falcon-transf tcp6 0 0 :::6080 :::* LISTEN 10221/falcon-judge tcp6 0 0 :::18433 :::* LISTEN 10254/falcon-gatewa tcp6 0 0 :::6081 :::* LISTEN 10221/falcon-judge tcp6 0 0 :::1988 :::* LISTEN 10247/falcon-agent tcp6 0 0 :::6055 :::* LISTEN 10239/falcon-aggreg tcp6 0 0 :::6090 :::* LISTEN 10233/falcon-nodata tcp6 0 0 :::14444 :::* LISTEN 10254/falcon-gatewa tcp6 0 0 :::6060 :::* LISTEN 10227/falcon-transf tcp6 0 0 :::6030 :::* LISTEN 10213/falcon-hbs tcp6 0 0 :::6031 :::* LISTEN 10213/falcon-hbs tcp6 0 0 :::8080 :::* LISTEN 10260/falcon-api tcp6 0 0 :::8433 :::* LISTEN 10227/falcon-transf tcp6 0 0 :::6070 :::* LISTEN 10203/falcon-graph tcp6 0 0 :::22 :::* LISTEN 982/sshd tcp6 0 0 :::6071 :::* LISTEN 10203/falcon-graph tcp6 0 0 :::9912 :::* LISTEN 10273/falcon-alarm tcp6 0 0 ::1:25 :::* LISTEN 1084/master udp 0 0 127.0.0.1:323 0.0.0.0:* 596/chronyd udp 0 0 0.0.0.0:68 0.0.0.0:* 768/dhclient udp6 0 0 ::1:323 :::* 596/chronyd
绘图组件列表:
Agent #部署在目标机器采集机器监控项 #http:1988端口 Transfer #数据接收端,转发数据到后端Graph和Judge #http:6060 rpc:8433 socket:4444 端口 Graph #操作rrd文件存储监控数据 #http:6070 rcp:6071端口 #可部署多实例做集群,需要连接数据库graph Query #查询各个Graph数据,提供统一http查询接口 #http:9966端口 Dashboard #查询监控历史趋势图的web端 #http:8081端口 #需要python虚拟环境,需要连接数据库dashbora Task #负责一些定时任务,索引全量更新、垃圾索引清理、自身组件监控等 #http:8002端口 #需要连接数据库graph
报警组件列表:
Sender #报警发送模块,控制并发度,提供发送的缓冲queue #http:6666端口 UTC(fe) #用户组管理,单点登录 #http:80端口 #需要连接数据库:uic Portal #配置报警策略,管理机器分组的web端 #http:5050端口 #需要连接数据库:falcon_portal,需要python虚拟环境 HBS #HeartBeat Server,心跳服务器 #http:6031 rpc:6030端口 #需要连接数据库:falcon_portal Judge #报警判断模块 #http:6081 rpc:6080端口 #可部署多实例 Links #报警合并依赖的web端,存放报警详情 #http:5090端口 #需要连接数据库:falcon_links,需要python虚拟环境 Alarm #报警事件处理器 #http:9912端口 mail-provider #报警邮件http api #http:4000端口 #小米提供 sms-provider #报警短信http api #http:4040端口 #自行编写 Nodata #检测监控数据的上报异常 #http:6090端口 #需要连接数据库falcon_portal Aggregato #集群聚合模块--聚合某集群下的所有机器的某个指标的值,提供一种集群视觉的监控体验 #http:6055端口 #需要连接数据库falcon_portal proxy-gateway #用户可以方便的通过http接口,push数据到本机的gateway,gateway会帮忙高效率的转发到server端.站在client端的角度,gateway和transfer提供了完全一致的功能和接口。 #只有遇到网络分区的情况时,才有必要使用gateway组件。https://github.com/open-falcon/falcon-plus/blob/master/modules/gateway/README.md
2.10 关闭自动注册
#注册账号能够被任何打开dashboard页面的人注册,所以当给相关的人注册完账号后,需要去关闭注册账号功能。只需要去修改api组件的配置文件cfg.json,将signup_disable配置项修改为true,重启api即可。当需要给人开账号的时候,再将配置选项改回去,用完再关掉即可。
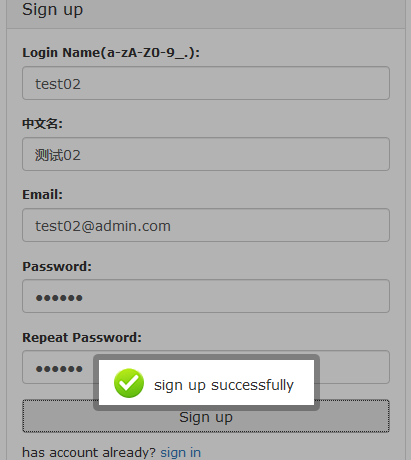
#如上图还是可以自动注册的,现在来关闭一下自动注册。
# cd $WORKSPACE
# vim api/config/cfg.json #关闭自动注册
"signup_disable": true,
# ./open-falcon restart #重启一下后端服务
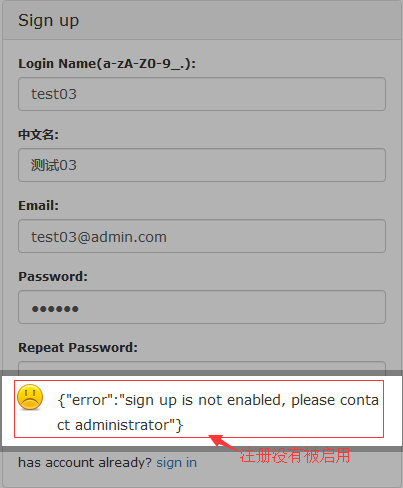
#关闭注册成功了
博文来自:www.51niux.com
#分布式安装参照官网文档:https://book.open-falcon.org/zh_0_2/distributed_install/
三、open-falcon agent安装使用
3.1 客户端压缩包的编译
#只需在第一台客户端配置,其他的客户端就不需要了
# vim /etc/profile
export FALCON_HOME=/home/work export GOPATH=/opt export WORKSPACE=$FALCON_HOME/open-falcon
#source /etc/profile
#cd $GOPATH/src/github.com/open-falcon
#git clone https://github.com/open-falcon/falcon-plus.git
# cd $GOPATH/src/github.com/open-falcon/falcon-plus/modules/agent
# go get ./... #需要主机可以连接外网,通过go get下载相关源码包。
#./control build
# ./control pack #编译pack 出的包,在其他agent主机上部署时,无需连接外网 ,pack出的包,可以类似的理解为由c源代码编译后得出的二进制文件。

# ls -lh
总用量 14M -rw-r--r--. 1 root root 1.3K 11月 9 18:28 cfg.example.json -rwxr-xr-x. 1 root root 2.3K 11月 9 18:28 control drwxr-xr-x. 2 root root 94 11月 9 18:28 cron -rwxr-xr-x. 1 root root 9.6M 11月 9 18:55 falcon-agent -rw-r--r--. 1 root root 4.0M 11月 9 18:55 falcon-agent-5.1.2.tar.gz #这个编译出来的agent包就可以给其他客户端用了 drwxr-xr-x. 2 root root 4.0K 11月 9 18:28 funcs drwxr-xr-x. 2 root root 127 11月 9 18:28 g -rw-r--r--. 1 root root 8 11月 9 18:55 gitversion drwxr-xr-x. 2 root root 210 11月 9 18:28 http -rw-r--r--. 1 root root 12K 11月 9 18:28 LICENSE -rw-r--r--. 1 root root 1.5K 11月 9 18:28 main.go -rw-r--r--. 1 root root 462 11月 9 18:28 NOTICE drwxr-xr-x. 2 root root 61 11月 9 18:28 plugins drwxr-xr-x. 5 root root 56 11月 9 18:28 public -rw-r--r--. 1 root root 698 11月 9 18:28 README.md drwxr-xr-x. 2 root root 6 11月 9 18:55 var
3.2 客户端的配置
# mkdir $WORKSPACE
# tar zxf falcon-agent-5.1.2.tar.gz -C /home/work/open-falcon/
# mv cfg.example.json cfg.json
# ls -lh
总用量 9.6M -rw-r--r--. 1 root root 1.3K 11月 9 18:28 cfg.json -rwxr-xr-x. 1 root root 2.3K 11月 9 18:28 control -rwxr-xr-x. 1 root root 9.6M 11月 9 19:11 falcon-agent -rw-r--r--. 1 root root 8 11月 9 19:11 gitversion drwxr-xr-x. 5 root root 56 11月 9 18:28 public
# vim /home/work/open-falcon/cfg.json
{
"debug": true, # 控制一些debug信息的输出,生产环境通常设置为false
"hostname": "", # agent采集了数据发给transfer,endpoint就设置为了hostname,默认通过`hostname`获取,如果配置中配置了hostname,就用配置中的
"ip": "", # agent与hbs心跳的时候会把自己的ip地址发给hbs,agent会自动探测本机ip,如果不想让agent自动探测,可以手工修改该配置
"plugin": {
"enabled": false, # 默认不开启插件机制
"dir": "./plugin", # 把放置插件脚本的git repo clone到这个目录
"git": "https://github.com/open-falcon/plugin.git", # 放置插件脚本的git repo地址
"logs": "./logs" # 插件执行的log,如果插件执行有问题,可以去这个目录看log
},
"heartbeat": {
"enabled": true, # 此处enabled要设置为true
"addr": "192.168.1.151:6030", #hbs的地址,端口是hbs的rpc端口就是修改这里将IP换成hearbeat服务端的IP地址
"interval": 60, # 心跳周期,单位是秒,
"timeout": 1000 # 连接hbs的超时时间,单位是毫秒
},
"transfer": {
"enabled": true,
"addrs": [
"192.168.1.151:8433"
], # transfer的地址,端口是transfer的rpc端口, 可以支持写多个transfer的地址,agent会保证HA
"interval": 60, # 采集周期,单位是秒,即agent一分钟采集一次数据发给transfer。这里要特别注意:
#如果这里一开始设置的是60秒,后来你改成30秒或者其他的步长重启客户端你会发现服务端历史图没有了,如果你将步长改回去
#会发现历史图又回来了,是因为这里不同插入的地方也不同,是查询是带着步长来的,所以一开始最好定好这里多长时间发送一次数据省的后面尴尬。
"timeout": 1000 # 连接transfer的超时时间,单位是毫秒
},
"http": {
"enabled": true, # 是否要监听http端口
"listen": ":1988",
"backdoor": false
},
"collector": {
"ifacePrefix": ["eth", "em","ens"], # 默认配置只会采集网卡名称前缀是eth、em的网卡流量,配置为空就会采集所有的,lo的也会采集。可以从/proc/net/dev看到各个网卡的流量信息
"mountPoint": []
},
"default_tags": {
},
"ignore": { # 默认采集了200多个metric,可以通过ignore设置为不采集
"cpu.busy": true,
"df.bytes.free": true,
"df.bytes.total": true,
"df.bytes.used": true,
"df.bytes.used.percent": true,
"df.inodes.total": true,
"df.inodes.free": true,
"df.inodes.used": true,
"df.inodes.used.percent": true,
"mem.memtotal": true,
"mem.memused": true,
"mem.memused.percent": true,
"mem.memfree": true,
"mem.swaptotal": true,
"mem.swapused": true,
"mem.swapfree": true
}
}#上面的配置文件建议稍微修改一下,因为那个:1988默认是监听在所有的IP上面,所以外部也可以通过web来进行查看,显然每个客户端开个对外的web服务不太好,重点是我们不会一台一台的web页面去查看,建议只监听本地:
"http": {
"enabled": true,
"listen": "127.0.0.1:1988",
"backdoor": false
},3.2 启动客户端并验证
# chown -R work:work /home/work/
# su - work
$cd /home/work/open-falcon
$ ./control start #启动客户端 # ./control stop 停止进程 #./control tail 查看日志 #./control status 可以看启动状态
falcon-agent started..., pid=23747 #这表示客户端启动了
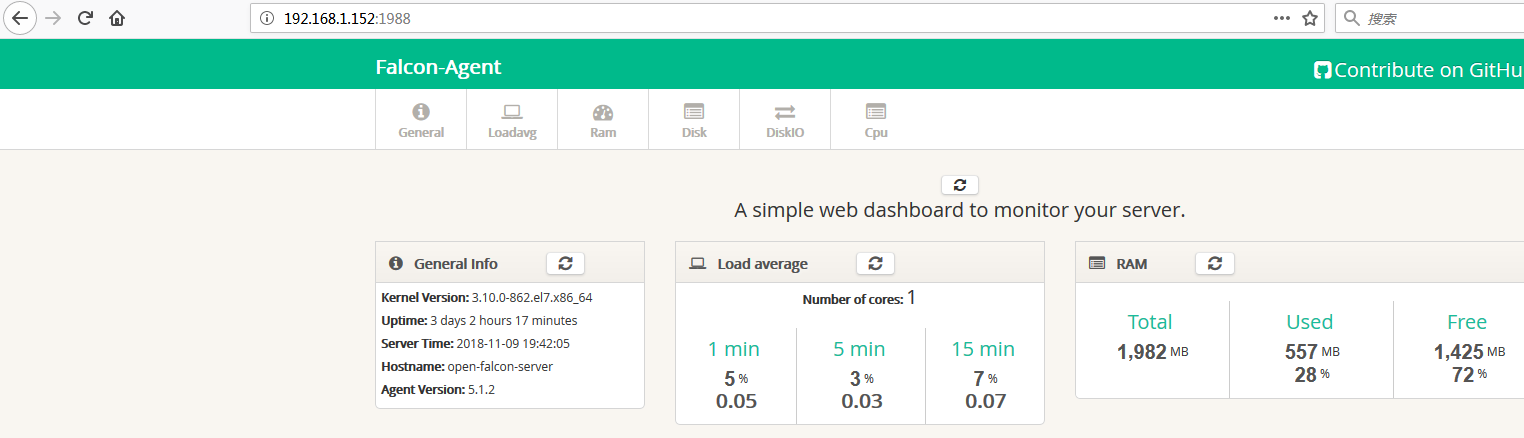
$ ./falcon-agent --check #看var目录下的log是否正常,或者浏览器访问其1988端口。另外agent提供了一个--check参数,可以检查agent是否可以正常跑在当前机器上
ss -tln ... ok du -bs ... ok df.bytes ... ok net.if ... ok loadavg ... ok cpustat ... ok memory ... ok ss -s ... ok kernel ... ok disk.io ... ok netstat ... ok ps aux ... ok
# tail -f /home/work/open-falcon/var/app.log
2018/11/09 19:41:29 var.go:109: <= <Total=6, Invalid:0, Latency=0ms, Message:ok> 2018/11/09 19:41:52 var.go:102: => <Total=5> <Endpoint:open-falcon-server, Metric:value, Type:GAUGE, Tags:name=SendQueueSize, Step:60, Time:1541763712, Value:0> 2018/11/09 19:41:52 var.go:109: <= <Total=5, Invalid:0, Latency=0ms, Message:ok> 2018/11/09 19:42:29 gpu.go:31: Initialize error: could not load NVML library 2018/11/09 19:42:29 var.go:102: => <Total=120> <Endpoint:open-falcon-server, Metric:agent.alive, Type:GAUGE, Tags:, Step:60, Time:1541763749, Value:1> 2018/11/09 19:42:29 var.go:102: => <Total=7> <Endpoint:open-falcon-server, Metric:df.bytes.free.percent, Type:GAUGE, Tags:mount=/,fstype=xfs, Step:60, Time:1541763749, Value:80.7510067550013> 2018/11/09 19:42:29 var.go:102: => <Total=6> <Endpoint:open-falcon-server, Metric:ss.estab, Type:GAUGE, Tags:, Step:60, Time:1541763749, Value:14> 2018/11/09 19:42:29 var.go:109: <= <Total=120, Invalid:0, Latency=0ms, Message:ok> 2018/11/09 19:42:29 var.go:109: <= <Total=7, Invalid:0, Latency=0ms, Message:ok> 2018/11/09 19:42:29 var.go:109: <= <Total=6, Invalid:0, Latency=0ms, Message:ok> 2018/11/09 19:42:52 var.go:102: => <Total=5> <Endpoint:open-falcon-server, Metric:value, Type:GAUGE, Tags:name=pfc.push.ms, Step:60, Time:1541763772, Value:1> 2018/11/09 19:42:52 var.go:109: <= <Total=5, Invalid:0, Latency=0ms, Message:ok>
3.3 最后上服务端检查一下:
数据采集:https://book.open-falcon.org/zh_0_2/philosophy/data-collect.html
#我就不复制了我就总结一下,基础性能指标直接采集,硬件性能指标用插件,服务监控数据日志之类自定义的可以通过curl -X POST -d '[{字典}]' http://127.0.0.1:1988/v1/push
3.4 客户端配置文件有两个配置:
hbs:
agent应该随装机过程部署到每个机器实例上。agent从hbs拉取配置信息,进行数据采集、收集,将数据上报给transfer。agent资源消耗很少、运行稳定可靠。hbs是Open-Falcon的配置中心,负责 适配系统的配置信息、管理agent信息等。hbs单实例部署,每个实例都有完整的配置信息。Portal的数据库中有一个host表,维护了公司所有机器的信息,比如hostname、ip等等。这个表中的数据通常是从公司CMDB中同步过来的。但是有些规模小一些的公司是没有CMDB的,那此时就需要手工往host表中录入数据,这很麻烦。于是我们赋予了HBS第一个功能:agent发送心跳信息给HBS的时候,会把hostname、ip、agent version、plugin version等信息告诉HBS,HBS负责更新host表。
Agent按照配置文件说明(默认以一分钟为周期)定期给HBS发送心跳连接请求,上报主机存活信息、同步主机监控插件、同步主机监控进程端口等。
transfer:
transfer是一个无状态的集群。transfer接收agent上报的数据,然后使用一致性哈希进行数据分片、并把分片后的数据转发给graph、judge集群(transfer还会打一份数据到opentsdb)。
Agent 按照配置文件说明(默认以一分钟为周期)定期给transfer发送主机个项监控数据,包括:cpu、磁盘、内存等等。
还有一张表:
Portal的数据库中有一个host表,维护了公司所有机器的信息,比如hostname、ip等等。这个表中的数据通常是从公司CMDB中同步过来的。但是有些规模小一些的公司是没有CMDB的,那此时就需要手工往host表中录入数据,这很麻烦。于是赋予了HBS第一个功能:agent发送心跳信息给HBS的时候,会把hostname、ip、agent version、plugin version等信息告诉HBS,HBS负责更新host表。
# mysql -uroot -p
MariaDB [(none)]> show databases; MariaDB [(none)]> use falcon_portal; MariaDB [falcon_portal]> select * from host;
#下面是表结构:
+----+-----------------------+---------------+---------------+--------------------+----------------+--------------+---------------------+ | id | hostname | ip | agent_version | plugin_version | maintain_begin | maintain_end | update_at | +----+-----------------------+---------------+---------------+--------------------+----------------+--------------+---------------------+ | 1 | localhost.localdomain | 127.0.0.1 | 5.1.2 | plugin not enabled | 0 | 0 | 2018-11-08 10:42:41 | | 4 | open-falcon-server | 192.168.1.152 | 5.1.2 | plugin not enabled | 0 | 0 | 2018-11-09 19:23:22 | +----+-----------------------+---------------+---------------+--------------------+----------------+--------------+---------------------+
Agent模块通信方式:
Agent模块使用单向同步的rpc通信方式,把数据信息以发送请求的方式推送到服务端,并且返回发送错误以及请求响应结果。
rpc通信方式:
Agent模块推送信息时,使用tcp协议连接rpc服务端,推送数据并且接受服务器返回的响应数据后,关闭rpc连接,等待下一次的通信。
正常来说,只有在Agent向HBS服务器请求插件同步、进程端口同步时,服务器才会返回相应数据,其他的请求只会返回请求状态,成功或者失败。
rpc数据结构:
rpc数据结构:SingleConnRpcClient、Call、Client等,这里只关注SingleConnRpcClient即可,其他的大部分是go语言封装的rpc通信相关结构体。
struct {
sync.MutexrpcClient *
rpc.Client
RpcServer string
Timeout time.Duration
}
sync.Mutex :Go语言的排它锁,其他开发语言会不一样,根据情况使用。此处目的是实现rpc通信进程与主进程同步,主进程等待rpc通信结束后才继续往下执行任务。
rpcClient :声明一个rpc通信的客户端,用于连接服务端并且发送消息。
RpcServer :声明一个rpc通信的服务端描述,是rpcClient的通信对象,读取配置文件。
Timeout :rpc连接超时,读取配置文件。3.5 主机监控
#上面描述了好多主要是引出下面的第一个要注意的地方,Open-falcon和hostname之间的关系。
先修改一下hostname让问题出现:
# hostnamectl set-hostname falcon-agent-01 #修改一下客户端的hostname
# ./control restart #重启客户端

#查看mysql表会发现同一个IP有两个hostname。
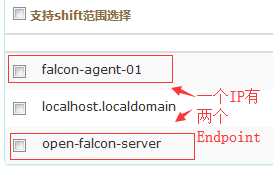
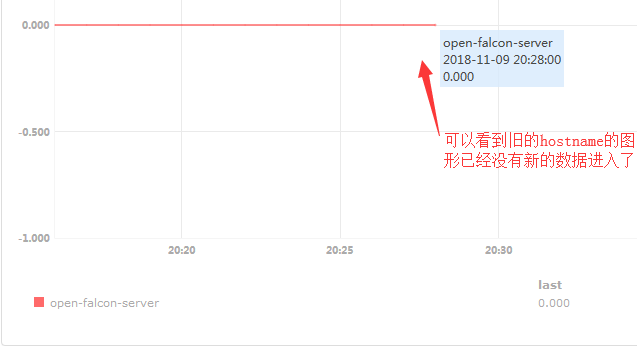
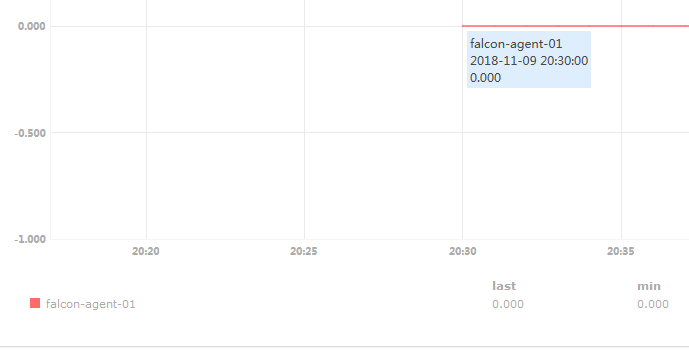
#从上面两张图可以看出新老交替,新的hostname有图了旧的hostname也就是旧的Endpoints没有数据了。
#这就反映出一个问题,我们不能随便修改主机的hostname,难道真的是这样吗?不是的,使我们姿势不对。
修改配置文件,让hostname的修改不再影响:
# vim /home/work/open-falcon/cfg.json
"hostname": "online-web-01",
# ./control restart #重启客户端
#上面默认是""的,设置上值之后,你的hostname想怎么改都不会再影响到客户端的Endpoint。
总结:
1. cfg.json的hostname配置决定了Endpoint 2. cfg.json的默认hostname配置为system.hostname 3. cfg.json的hostname配置为空字符串,Endpoint也是system.hostname,就是/etc/sysconfig/network里面配置的那个,就是hostname这个命令的返回值
