GlusterFS文件系统简单搭建
此GFS并非谷歌的三宝之一GFS(The Google File System)。
如果有兴趣的话可以详细了解:http://blog.csdn.net/liuaigui (刘爱贵博士的博客)。我这里就是学习简单记录一下。
官方文档:http://gluster.readthedocs.io/en/latest/ #GlusterFS2于2011年10月已经被redhat收购了,被收购之后增加了针对KVM许多特性,并且获得了QEMU的原生支持。
一、GlusterFS文件介绍
1.1 GlusterFS简介
GlusterFS的官网:https://www.gluster.org/
Gluster File System 是自由软件,主要由 Z RESEARCH 公司负责开发,基于GNU协议的集群文件系统,是一款全对称的开源分布式文件系统。没有中心节点,所有的节点全部平等。
Glusterfs是一个开源的分布式文件系统,是Scale存储的核心,能够处理千数量级的客户端.在传统的解决 方案中Glusterfs能够灵活的结合物理的,虚拟的和云资源去体现高可用和企业级的性能存储.
Glusterfs通过TCP/IP或InfiniBand RDMA网络链接将客户端的存储资块源聚集在一起,使用单一的全局命名空间来管理数据,磁盘和内存资源.
Glusterfs基于堆叠的用户空间设计,可以为不同的工作负载提供高优的性能.
Glusterfs支持运行在任何标准IP网络上标准应用程序的标准客户端,如下图1所示,用户可以在全局统一的命名空间中使用NFS/CIFS等标准协议来访问应用数据.
1.2 GlusterFS设计特色
弹性存储
线性横向扩展
高可靠性
完全软件实现
无元数据服务
1.3 Glusterfs特点
图文并茂的介绍链接:http://blog.csdn.net/liuaigui/article/details/6284551
官方文档:http://gluster.readthedocs.io/en/latest/
扩展性和高性能
GlusterFS利用双重特性来提供几TB至数PB的高扩展存储解决方案。Scale-Out架构允许通过简单地增加资源来提高存储容量和性能,磁盘、计算和I/O资源都可以独立增加,支持10GbE和InfiniBand等高速网络互联。Gluster弹性哈希(Elastic Hash)解除了GlusterFS对元数据服务器的需求,消除了单点故障和性能瓶颈,真正实现了并行化数据访问。
高可用性
GlusterFS可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是可以访问,甚至是在硬件故障的情况下也能正常访问。自我修复功能能够把数据恢复到正确的状态,而且修复是以增量的方式在后台执行,几乎不会产生性能负载。GlusterFS没有设计自己的私有数据文件格式,而是采用操作系统中主流标准的磁盘文件系统(如EXT4、ZFS)来存储文件,因此数据可以使用各种标准工具进行复制和访问。
全局统一命名空间
全局统一命名空间将磁盘和内存资源聚集成一个单一的虚拟存储池,对上层用户和应用屏蔽了底层的物理硬件。存储资源可以根据需要在虚拟存储池中进行弹性扩展,比如扩容或收缩。当存储虚拟机映像时,存储的虚拟映像文件没有数量限制,成千虚拟机均通过单一挂载点进行数据共享。虚拟机I/O可在命名空间内的所有服务器上自动进行负载均衡,消除了SAN环境中经常发生的访问热点和性能瓶颈问题。
弹性哈希算法
GlusterFS采用弹性哈希算法在存储池中定位数据,而不是采用集中式或分布式元数据服务器索引。在其他的Scale-Out存储系统中,元数据服务器通常会导致I/O性能瓶颈和单点故障问题。GlusterFS中,所有在Scale-Out存储配置中的存储系统都可以智能地定位任意数据分片,不需要查看索引或者向其他服务器查询。这种设计机制完全并行化了数据访问,实现了真正的线性性能扩展。
弹性卷管理
数据储存在逻辑卷中,逻辑卷可以从虚拟化的物理存储池进行独立逻辑划分而得到。存储服务器可以在线进行增加和移除,不会导致应用中断。逻辑卷可以在所有配置服务器中增长和缩减,可以在不同服务器迁移进行容量均衡,或者增加和移除系统,这些操作都可在线进行。文件系统配置更改也可以实时在线进行并应用,从而可以适应工作负载条件变化或在线性能调优。
基于标准协议
Gluster存储服务支持NFS, CIFS, HTTP, FTP以及Gluster原生协议,完全与POSIX标准兼容。现有应用程序不需要作任何修改或使用专用API,就可以对Gluster中的数据进行访问。这在公有云环境中部署Gluster时非常有用,Gluster对云服务提供商专用API进行抽象,然后提供标准POSIX接口。
1.4 GlusterFS堆栈式软件架构
GlusterFS采用模块化、堆栈式的架构,可通过灵活的配置支持高度定制化的应用环境,比如大文件存储、海量小文件存储、云存储、多传输协议应用等。每个功能以模块形式实现,然后以积木方式进行简单的组合,即可实现复杂的功能。比如,Replicate模块可实现RAID1,Stripe模块可实现RAID0,通过两者的组合可实现RAID10和RAID01,同时获得高性能和高可靠性。如下图所示:
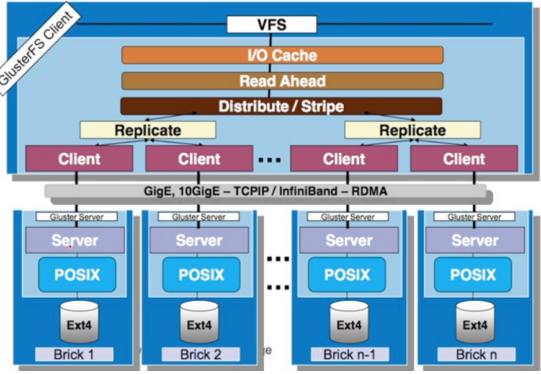
GlusterFS协议层面支持IP和RDMA。RDMA(Remote Direct Memory Access)技术全称为远程支持数据存储,是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网络把资料直接传入计算机的缓冲区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就很少用到计算机的处理功能。它消除了外部存储器复制和文本交换操作,因为能解放内存带宽和CPU周期用于改进应用系统性能。
RDMA最初是为Infiniband互连开发的技术。它在无须扩展缓存、干扰CPU或呼叫OS内核的情况下直接在两个系统间进行主数据转换,因此有助于缩短延时,提高系统间数据传输性能。
InfiniBand架构是一种支持多并发链接的“转换线缆”技术,在这种技术中,每种链接都可以达到2.5GB/s的运行速度。这种架构在一个链接的时候速度是500MB/s,4个链接的时候速度是2GB/s,12个链接的时候速度可以达到6GB/s。
InfinBand技术不是用于一般网络连接的,它的主要设计目的是针对服务器端的连接访问。因此,InfiniBand技术被应用于服务器与服务器、服务器和存储设备以及服务器和网络之间的通信。
对于这种技术比较详细的介绍链接:http://blog.csdn.net/educast/article/details/7918922
1.5 GlusterFS术语简介
Brick: GFS中的存储单元,通过是一个受信存储池中的服务器的一个导出目录。可以通过主机名和目录名来标识,如'SERVER:EXPORT' Metadata: 元数据,关于数据的数据,用于描述文件、目录等信息 Client: 挂载了GFS卷的设备 Extended Attributes: xattr是一个文件系统的特性,其支持用户或程序关联文件/目录和元数据。 FUSE: Filesystem Userspace是一个可加载的内核模块,其支持非特权用户创建自己的文件系统而不需要修改内核代码。通过在用户空间运行文件系统的代码通过FUSE代码与内核进行桥接。 GFID: GFS卷中的每个文件或目录都有一个唯一的128位的数据相关联,其用于模拟inode Namespace: 每个Gluster卷都导出单个ns作为POSIX的挂载点 Node: 一个拥有若干brick的设备 RDMA: 远程直接内存访问,支持不通过双方的OS进行直接内存访问。 RRDNS: round robin DNS是一种通过DNS轮转返回不同的设备以进行负载均衡的方法 Self-heal: 用于后台运行检测复本卷中文件和目录的不一致性并解决这些不一致。 Split-brain: 脑裂 Volfile: glusterfs进程的配置文件,通常位于/var/lib/glusterd/vols/volname Volume: 一组bricks的逻辑集合
官网术语链接:http://gluster.readthedocs.io/en/latest/Quick-Start-Guide/Terminologies/
1.6 GlusterFS几种卷的实现
官网链接:http://gluster.readthedocs.io/en/latest/Quick-Start-Guide/Architecture/
http://gluster-documentations.readthedocs.io/en/latest/Administrator%20Guide/Setting%20Up%20Volumes/ #链接里面除了有卷的介绍,还有各种卷的创建语句
GlusterFS卷类型:
基本卷:哈希卷、复制卷、条带卷
复合卷:哈希复制卷、哈希条带卷、复制条带卷、哈希复制条带卷
分布式卷/哈希卷( Distributed Glusterfs Volume )

当对卷的请求是大规模存储和冗余不是很重要可以使用,分布卷可以将某个文件随机的存储在卷内的一个brick内,通常用于扩展存储能力,不支持数据的冗余。除非底层的brick使用RAID等外部的冗余措施。相当于文件级raid 0不具备容错能力。默认的就是这种卷。
使用场景:大量小文件
优点:读/写性能好
缺点:使用分部卷,存储的弹性扩展和冗余,需要其他层面的软件或硬件解决。如果服务器或者磁盘故障,会导致分布在服务器或者磁盘上的数据丢失。
# gluster volume create [transport tcp | rdma | tcp,rdma] # gluster volume create test-volume server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 #使用tcp创建具有四个存储服务器的分布式卷 # gluster volume create test-volume transport rdma server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 #通过InfiniBand创建具有四个存储服务器的分布式卷
复制型卷(Replicated Glusterfs Volume)

当在急需高可用和高可靠性的环境时可以使用它,复本卷在创建时可指定复本的数量,复本在存储时会在卷的不同brick上,因此有几个复本就必须提供至少多个brick。注意:在创建复本卷时,brick数量与复本个数必须相等;否则将会报错。另外如果同一个节点提供了多个brick,也可以在同一个结点上创建复本卷,但这并不安全,因为一台设备挂掉,其上面的所有brick就无法访问了。文件级RAID1,写性能下降,读性能提升。
使用场景:对可靠性和读性能要求高的场景。
优点:读性能好
缺点:写性能差,用磁盘空间换取可靠性。
# gluster volume create [replica ] [transport tcp | rdma | tcp,rdma] # gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 #要创建具有两个存储服务器的复制卷
条带式卷(Striped Glusterfs Volume)
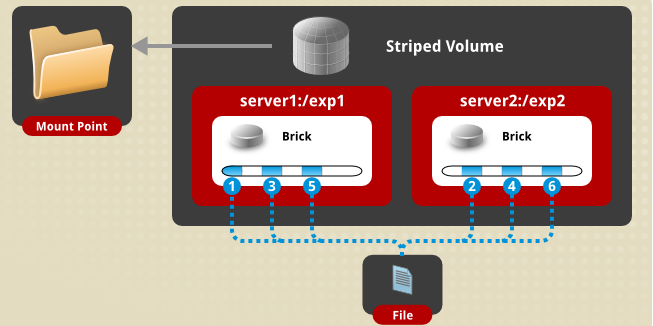
当在高并发性接收大文件的环境时必须使用条带式分布卷,分片卷将单个文件分成小块(块大小支持配置,默认为128K),然后将小块存储在不同的brick上,以提升文件的访问性能。stripe后的参数指明切片的分布位置个数。注意:brick的个数必须等于分布位置的个数
使用场景:大文件
优点:用条带的方法使大文件能够存储
缺点:可靠性不高,有brick故障,数据全部丢失
# gluster volume create [stripe ] [transport tcp | rdma | tcp,rdma] # gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2 #要跨两个存储服务器创建条带卷
分布式条带卷(Distributed Striped Glusterfs Volume)
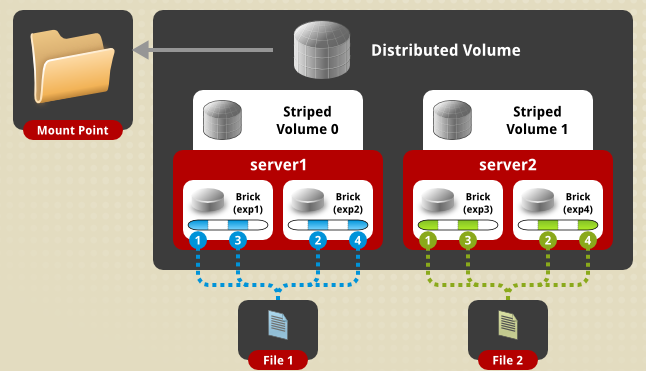
创建时需求两个或多于两个的节点, 当需求大规模存储和高可靠性的访问非常大的文件环境时必须使用这种模式的卷。此类型卷是基本复本卷的扩展,可以指定若干brick组成一个复本卷,另外若干brick组成另个复本卷。单个文件在复本卷内数据保持复制,不同文件在不同复本卷之间进行分布。注意:复本卷的组成依赖于指定brick的顺序。brick必须为复本数K的N倍,brick列表将以K个为一组,形成N个复本卷
使用场景:读/写性能高的大量大文件场景
优点:高并发支持,存储池可以弹性扩展
缺点:没有冗余,可靠性不高。
分布条带卷需要的brick数量是条带数的倍数。
# gluster volume create [stripe ] [transport tcp | rdma | tcp,rdma] # gluster volume create test-volume stripe 4 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 server7:/exp7 server8:/exp8 #要跨八个存储服务器创建分布式条带卷
分布式复制卷(Distributed Replicated Glusterfs Volume)
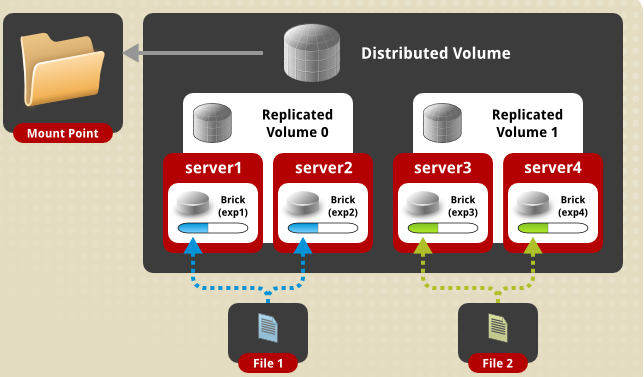
当需求是急需大规模存储和高可靠性的环境下可以使用它,类似于分布式复本卷,若创建的卷的节点提供的bricks个数为stripe个数N倍时,将创建此类型的卷。注意:切片卷的组成依赖于指定brick的顺序brick必须为复本数K的N倍,brick列表将以K个为一组,形成N个切片卷。
使用场景:大量文件读和可靠性要求高的场景
优点:存储空间弹性扩展,高可用,读性能高
分布式复制卷需要brick的数量是复制卷的倍数。另外,对brick的选择影响数据的安全性,同一台服务器有多个brick的时候,数据复制应该配置在多台服务器之间进行,而不是在同一台服务器内部之间进行,否则当服务器发生故障的时候,有可能造成数据丢失。
# gluster volume create [replica ] [transport tcp | rdma | tcp,rdma] # gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 #具有双向镜像的四个节点分布(复制)卷 # gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 #要创建具有双向镜像的六节点分布式(复制)卷
条带式复制卷(Striped Replicated )

一个大文件存储的时候划分条带,并且保存多份
使用场景:超大文件,并且对可靠性要求高的场景。
优点:使大文件能够存储并且获得可靠性
缺点:需要更大的磁盘空间,写性能差。
条带辅助卷需要的brick数量是条带数和复制数的乘积。
# gluster volume create [stripe ] [replica ] [transport tcp | rdma | tcp,rdma] # gluster volume create test-volume stripe 2 replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 #要跨四个存储服务器创建条带化复制卷 # gluster volume create test-volume stripe 3 replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 #要跨六个存储服务器创建条带化复制卷
分布式条带复制卷(Distributed Striped Replicated )
数据将进行切片,切片在复本卷内进行复制,在不同卷间进行分布。多个文件在多个节点哈希存储,存储的时候划分条带,并且保持多份。
使用场景:多份大文件并且对可靠性要求高的场景,虚拟机的镜像存储就是一个典型场景。
优点:读、写、可靠性比较均衡
缺点:牺牲磁盘空间和写性能
分布条带复制卷需要的birck数量是条带数和复制数的乘积倍数。
# gluster volume create [stripe ] [replica ] [transport tcp | rdma | tcp,rdma] # gluster volume create test-volume stripe 2 replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 server7:/exp7 server8:/exp8 #要跨八个存储服务器创建分布式复制的条带卷
分散卷(dispersed volume)
分散卷基于纠错码,它基于条带编码,添加冗余编码,并分布到多个brick上存储。分散卷以最小的磁盘空间消耗实现冗余,并且冗余级别可以配置。
使用场景:对冗余和磁盘空间都敏感的场景。
优点:在冗余和磁盘空间上取得平衡。
缺点:需要消耗额外的资源进行验证,对性能也有一定影响。
# gluster volume create [disperse [<count>]] [redundancy <count>] [transport tcp | rdma | tcp,rdma]
# gluster volume create test-volume disperse 4 server{1..4}:/bricks/test-volume
# gluster volume create test-volume disperse 6 server{1..6}:/bricks/test-volume分布式分散卷(Distributed Dispersed Volumes)
多个文件在多个节点上哈希分布存储,存储的时候基于条带编码并有冗余度设置。
应用场景:对冗余和磁盘空间都敏感的场景。
优点:在冗余、磁盘空间、读/写性能上取得平衡。
缺点:需要消耗额外的资源进行验证,对性能也有一定影响。
# gluster volume create disperse <count> [redundancy <count>] [transport tcp | rdma | tcp,rdma]
二、GlusterFS的搭建和管理
GlusterFS是一个开源的分布式文件系统,于2011年被红帽收购.所以直接yum就可以了。
我们这里的操作系统是Centos,服务端是192.168.1.121,192.168.1.122,192.168.1.111 客户端是192.168.1.108
2.1 服务器端编译安装方式:
yum install -y automake autoconf libtool flex bison openssl-devel libxml2-devel python-devel libaio-devel libibverbs-devel librdmacm-devel readline-devel lvm2-devel glib2-devel userspace-rcu-devel libcmocka-devel
# wget https://download.gluster.org/pub/gluster/glusterfs/3.8/3.8.11/glusterfs-3.8.11.tar.gz
# tar zxf glusterfs-3.8.11.tar.gz
# cd glusterfs-3.8.11
# ./configure --prefix=/usr/local/glusterfs-3.8
# make && make install #但是这里3.8版本开始nake编译有个错误,我没有解决:Glusterfs Makefile:90: *** missing separator. Stop. 这里就是把编译过程中如果出现的错误是缺什么包记录了一下,还是推荐yum的安装方式。
一大波报错及解决方法:
configure: error: Flex or lex required to build glusterfs.
#上面报错解决办法:# yum -y install flex
configure: error: GNU Bison required to build glusterfs.
#上面报错解决办法:# yum -y install bison
configure: error: Support for POSIX ACLs is required
#上面报错解决办法:# yum install libacl* -y
configure: error: OpenSSL crypto library is required to build glusterfs
#上面报错解决办法:# yum install -y openssl openssl-devel
Transaction check error: file /usr/lib64/libkadm5clnt_mit.so.8.0 from install of libkadm5-1.14.1-27.el7_3.x86_64 conflicts with file from package krb5-libs-1.13.2-10.el7.x86_64
#上面报错解决办法:# rpm -e krb5-libs-1.14.1-27.el7_3.x86_64 #可能存在了两个版本的软件包
configure: error: pass --disable-tiering to build without sqlite
#上面错解决办法:# ./configure --prefix=/usr/local/glusterfs-3.8 --disable-tierin
configure: error: liburcu-bp not found #liburcu是LGPLv2.1用户空间RCU(read-copy-update)图书馆。
#yum install automake libtool && git clone git://git.liburcu.org/userspace-rcu.git &&./bootstrap
&& ./configure && make && make install &&ldconfig
2.2 yum安装方式
# cat /etc/yum.repos.d/epel.repo #可以做一个简单的yum源
[epel] name=CentOS-$releasever - epel baseurl=https://buildlogs.centos.org/centos/6/storage/x86_64/gluster-3.9/ gpgcheck=0
#如果是Centos7就是下面的这个链接:baseurl=https://buildlogs.centos.org/centos/7/storage/x86_64/gluster-3.9/
#https://download.gluster.org/pub/gluster/glusterfs/ 在这个目录下面要下载哪个版本进入对应的Centos目录只有一个文件会告诉你rpm包的地址
#yum install glusterfs-server -y #会将关联包都下载
# rpm -qa|grep gluster #可以看看下载的包
glusterfs-3.9.1-1.el7.x86_64 glusterfs-client-xlators-3.9.1-1.el7.x86_64 glusterfs-libs-3.9.1-1.el7.x86_64 glusterfs-cli-3.9.1-1.el7.x86_64 glusterfs-server-3.9.1-1.el7.x86_64 glusterfs-fuse-3.9.1-1.el7.x86_64 glusterfs-api-3.9.1-1.el7.x86_64
#service glusterd start #启动glusterd服务。

#默认启动的是24007端口
三、模拟集群的配置
现在我们有6台机器是192.168.1.103-108,每个上面有两个挂载盘,都是50G。
给集群增加节点:
现在六台机器都已经Yum安装完毕,并且启动了服务,在任何一台机器上面运行命令都是可以的,因为没有中心节点,每个节点都是平等。
# gluster peer status #查看集群的状态,起始状态结果应该是0,下面是结果。
Number of Peers: 0
# gluster peer probe 192.168.1.103 #下面提示成功了,但是本地不需要这样操作
peer probe: success. Probe on localhost not needed
# gluster peer probe 192.168.1.104 #把另外一台机器加到集群里面来,下面是提示成功了。
peer probe: success.
#gluster peer status #现在查看下节点状态,你会发现在192.168.1.104上面看到的是192.168.1.103的信息

#从上图可以看到,可以看到除本节点以外其他节点的信息。现在你在192.168.1.105等上面查看的话,还是Number:0状态,因为他们没有再这个集群里面。
#现在我们再192.168.1.105上面执行:# gluster peer probe 192.168.1.103 #192.168.1.103已经在别的集群里面了所以不能再添加了。
peer probe: failed: 192.168.1.103 is either already part of another cluster or having volumes configured
#所以现在我们再192.168.1.104上面执行:# gluster peer probe 192.168.1.105,然后再次查看结果(gluster peer detach 192.168.1.105 #就是删除节点):
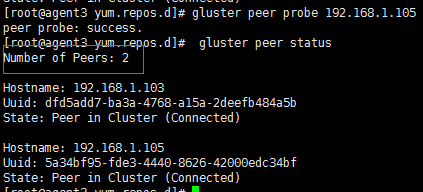
创建卷:
# gluster volume info #先查看下卷的状态,从结果看现在还没有卷呢
No volumes present
#mkdir /data01/gfsdata #我每个节点都是两个挂载点/data01和/data02,下面要创建gfsdata目录
#mkdir /data02/gfsdata
#因为如果不加-force是不让挂载根目录或者系统盘作为存储使用的,要在下面创建目录才能用,不然你执行命令的时候会报错。
# gluster volume create gv0 replica 2 192.168.1.103:/data01/gfsdata 192.168.1.104:/data01/gfsdata 192.168.1.105:/data01/gfsdata 192.168.1.103:/data02/gfsdata #创建一个名字叫gv0的复制卷
#因为我们制定了relica形式的卷,逻辑卷名是gv0,然后制定了blick的份数是2,所以我们的挂载目录必须是2的倍数,不能是奇数,不然报错。当然不指定replica参数默认是分布卷。
# gluster volume start gv0 #启动创建的pv0卷组,下面是提示成功。
volume start: gv0: success
# gluster volume info #再次查看逻辑卷的信息

#箭头标红的地方是很容易理解的,就不解释了,可以看到我们这个卷的状态。
# gluster help #查看所有的使用命令
# gluster volume help #查看逻辑卷的命令操作
四、客户端的操作:
#yum -y install glusterfs glusterfs-fuse #不用创建epel源直接yum就可以了
#mkdir /gfstest
# mount -t glusterfs 192.168.1.105:/gv0 /gfstest/ #指定任何集群里面任何一个IP进行挂载都可以,直接将gv0卷组挂载到我们创建的目录
# df -h #查看一下,我们集群里面是挂载了四快盘,每块盘是50G,然后是一个文件保留双份,所以200G/2=100G。

#mount -t fuse.glusterfs #也可以通过此命令查看一下。
192.168.1.105:/gv0 on /gfstest type fuse.glusterfs (rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
# cd /gfstest/ #然后试着往里面放了两个文件(查看客户端的话看到的也是增加了30MB左右的空间使用量)

#因为我们指定一个文件保存2份,所以四个目录两个目录存了redis文件,两个目录存放了python目录,如下图:

#现在我们把剩下的两个挂载盘也添加到卷里面增加下空间
# gluster volume add-brick gv0 192.168.1.104:/data02/gfsdata 192.168.1.105:/data02/gfsdata #在集群中的任何一个节点执行此命令
volume add-brick: success
# df -h #客户端再次查看会发现直接就扩容到150G了

五、创建各种形式的卷
默认就是创建分布卷。上面也创建了分布式复制卷,就是记得制定好复制卷的份数,然后brick数要是复制卷的倍数,如果是复制卷呢就是1倍数。
# gluster volume stop gv0 #删除卷之前先把卷关闭

# gluster volume delete gv0 #删除卷,按确认Y就可以删除掉了。我们把卷删除掉,重新来创建。
# gluster peer probe 192.168.1.106 #把另外三个节点也加入进来
# gluster peer probe 192.168.1.107
# gluster peer probe 192.168.1.1068
5.1 创建条带卷:
# gluster volume create str_vol stripe 3 192.168.1.103:/data01/gfsdata 192.168.1.104:/data01/gfsdata 192.168.1.105:/data01/gfsdata #通过参数stripe创建条带卷,3是存放到三个brick上。
volume create: str_vol: failed: /data01/gfsdata is already part of a volume #这个报错提示是/data01/gfsdata已经被占用了,但是明明我们已经将卷删除掉了。
下面是解决办法:
rm -rf /data01/gfsdata/* #当然如果盘下面已经有数据了还要把数据清掉 rm -rf /data01/gfsdata/.glusterfs setfattr -x trusted.glusterfs.volume-id /data01/gfsdata setfattr -x trusted.gfid /data01/gfsdata

5.2 创建分布条带卷:
# gluster volume create dir_str_vol stripe 4 192.168.1.103:/data02/gfsdata 192.168.1.104:/data02/gfsdata 192.168.1.105:/data02/gfsdata 192.168.1.106:/data01/gfsdata 192.168.1.106:/data02/gfsdata 192.168.1.107:/data01/gfsdata 192.168.1.108:/data01/gfsdata 192.168.1.108:/data02/gfsdata
#通过参数stripe和brick数量来创建分布条带卷,brick数量是条带数的倍数。这里创建一个有8个brick的分布条带卷。
# gluster volume info dir_str_vol #查看一下卷信息
Volume Name: dir_str_vol #卷名称 Type: Distributed-Stripe #类型是分布条带卷 Volume ID: 6f13bff5-e1fd-445d-94c3-d68cca3e417c #卷ID Status: Created Snapshot Count: 0 Number of Bricks: 2 x 4 = 8 #文件存储的时候在4个brick上划分条带存储,多个文件在两组brick上哈希分布 Transport-type: tcp Bricks: Brick1: 192.168.1.103:/data02/gfsdata Brick2: 192.168.1.104:/data02/gfsdata Brick3: 192.168.1.105:/data02/gfsdata Brick4: 192.168.1.106:/data01/gfsdata Brick5: 192.168.1.106:/data02/gfsdata Brick6: 192.168.1.107:/data01/gfsdata Brick7: 192.168.1.108:/data01/gfsdata Brick8: 192.168.1.108:/data02/gfsdata Options Reconfigured: transport.address-family: inet performance.readdir-ahead: on nfs.disable: on
5.3 创建复制卷和分布复制卷:
创建复制卷:
# gluster volume create rep_vol replica 2 192.168.1.105:/data02/gfsdata 192.168.1.106:/data02/gfsdata
# gluster volume info rep_vol
Volume Name: rep_vol Type: Replicate Volume ID: b8b9a6c0-0004-43ca-b15a-8ed4ee903fd0 Status: Created Snapshot Count: 0 Number of Bricks: 1 x 2 = 2 #复制卷就是brick数是存储份数的1倍数,文件只能存在在这两个brick上面。 Transport-type: tcp Bricks: Brick1: 192.168.1.105:/data02/gfsdata Brick2: 192.168.1.106:/data02/gfsdata Options Reconfigured: transport.address-family: inet performance.readdir-ahead: on nfs.disable: on
创建分布复制卷:
# gluster volume create dir_rep_vol replica 2 192.168.1.103:/data01/gfsdata 192.168.1.104:/data01/gfsdata 192.168.1.105:/data01/gfsdata 192.168.1.106:/data01/gfsdata 192.168.1.107:/data01/gfsdata 192.168.1.108:/data01/gfsdata 192.168.1.103:/data02/gfsdata 192.168.1.104:/data02/gfsdata #通过参数replica和brick数量来创建分布复制卷,brick数量是replica参数的倍数。
# gluster volume info dir_rep_vol
Volume Name: dir_rep_vol Type: Distributed-Replicate Volume ID: 4d7d2d52-c926-4b6a-9f35-a9eff42dba11 Status: Created Snapshot Count: 0 Number of Bricks: 4 x 2 = 8 #分布复制卷就是brick数是存储份数的N倍数,这就表示1个文件要存储2分,可以在8个brick上面选两个存储。 Transport-type: tcp Bricks: Brick1: 192.168.1.103:/data01/gfsdata Brick2: 192.168.1.104:/data01/gfsdata Brick3: 192.168.1.105:/data01/gfsdata Brick4: 192.168.1.106:/data01/gfsdata Brick5: 192.168.1.107:/data01/gfsdata Brick6: 192.168.1.108:/data01/gfsdata Brick7: 192.168.1.103:/data02/gfsdata Brick8: 192.168.1.104:/data02/gfsdata Options Reconfigured: transport.address-family: inet performance.readdir-ahead: on nfs.disable: on
创建分布条带复制卷:
# gluster volume create dis_str_rep_vol stripe 2 replica 2 192.168.1.103:/data01/gfsdata 192.168.1.104:/data01/gfsdata 192.168.1.105:/data01/gfsdata 192.168.1.106:/data01/gfsdata 192.168.1.107:/data01/gfsdata 192.168.1.108:/data01/gfsdata 192.168.1.103:/data02/gfsdata 192.168.1.104:/data02/gfsdata #通过stripe、replica参数及brick数量创建分布条带复制卷
# gluster volume info dis_str_rep_vol
Volume Name: dis_str_rep_vol Type: Distributed-Striped-Replicate Volume ID: 2b9149c2-fedb-47ca-a6d8-db27fd8c8600 Status: Created Snapshot Count: 0 Number of Bricks: 2 x 2 x 2 = 8 #多个文件存储的时候在4组brick上哈希存储,每个文件存储2份,就相当于raid1+0,比如一个160MB的文件,劈成两半,两个brick存两份这半份文件,四个盘存了四个半份文件。 Transport-type: tcp Bricks: Brick1: 192.168.1.103:/data01/gfsdata Brick2: 192.168.1.104:/data01/gfsdata Brick3: 192.168.1.105:/data01/gfsdata Brick4: 192.168.1.106:/data01/gfsdata Brick5: 192.168.1.107:/data01/gfsdata Brick6: 192.168.1.108:/data01/gfsdata Brick7: 192.168.1.103:/data02/gfsdata Brick8: 192.168.1.104:/data02/gfsdata Options Reconfigured: transport.address-family: inet performance.readdir-ahead: on nfs.disable: on
创建条带复制卷:
# gluster volume create dis_str_rep_vol stripe 2 replica 2 192.168.1.103:/data01/gfsdata 192.168.1.104:/data01/gfsdata 192.168.1.105:/data01/gfsdata 192.168.1.106:/data01/gfsdata
创建分散卷和分布式分散卷:
创建分散卷:
# gluster volume create disperse_vol disperse 4 192.168.1.103:/data01/gfsdata 192.168.1.104:/data01/gfsdata 192.168.1.105:/data01/gfsdata 192.168.1.106:/data01/gfsdata #分散卷需要指定冗余brick数,冗余数要小于brick数量。这里创建一个4个brick冗余的分散数,最多允许1个brick故障而不丢失数据。
# gluster volume info disperse_vol
Volume Name: disperse_vol Type: Disperse Volume ID: 47bd20e1-1c98-4050-ad0e-15c021b888b6 Status: Created Snapshot Count: 0 Number of Bricks: 1 x (3 + 1) = 4 Transport-type: tcp Bricks: Brick1: 192.168.1.103:/data01/gfsdata Brick2: 192.168.1.104:/data01/gfsdata Brick3: 192.168.1.105:/data01/gfsdata Brick4: 192.168.1.106:/data01/gfsdata Options Reconfigured: transport.address-family: inet performance.readdir-ahead: on nfs.disable: on
# gluster volume create disperse_vol3 disperse 3 192.168.1.103:/data02/gfsdata 192.168.1.104:/data02/gfsdata 192.168.1.105:/data02/gfsdata 192.168.1.106:/data02/gfsdata 192.168.1.107:/data01/gfsdata 192.168.1.107:/data02/gfsdata #分散卷需要指定分散卷和冗余数,如果分散卷大于brick数,就是分布分散卷,冗余数也可以不指定,GlusterFS有默认的算法。这里创建了一个6个brick分布分散卷,最多允许2个brick故障而不丢失数据。
# gluster volume info disperse_vol3
Volume Name: disperse_vol3 Type: Distributed-Disperse Volume ID: b4198070-21a8-4fba-a5e0-141967c6845e Status: Created Snapshot Count: 0 Number of Bricks: 2 x (2 + 1) = 6 #这个就是类似于raid5那种形式,一份文件哈希存储在了三块盘上,坏一块盘,数据还在。这里就是在6块盘上找三块盘上(比如文件是160MB的,每块盘都只存80MB文件) Transport-type: tcp Bricks: Brick1: 192.168.1.103:/data02/gfsdata Brick2: 192.168.1.104:/data02/gfsdata Brick3: 192.168.1.105:/data02/gfsdata Brick4: 192.168.1.106:/data02/gfsdata Brick5: 192.168.1.107:/data01/gfsdata Brick6: 192.168.1.107:/data02/gfsdata Options Reconfigured: transport.address-family: inet performance.readdir-ahead: on nfs.disable: on
六、其他的操作:
# cat /etc/glusterfs/glusterd.vol #卷管理文件,通过这个文件可以找到glusterfs的工作目录是在/var/lib/glusterd中
#/var/lib/glusterd #进入此目录会看到以不同功能命名的目录,然后进去就可以看到各种info展示的信息存储在文件中
剩下的是一些博客记录的常用的操作(记录一下如果懒的用gluster help查看了,可以点击链接查看一下如果链接还在的话):
http://blog.csdn.net/xdgouzongmei/article/category/6449545
http://blog.csdn.net/zzulp/article/details/39527441
http://blog.chinaunix.net/uid-22166872-id-4347579.html
