Hadoop(二)操作命令与目录结构
上一章:http://blog.51niux.com/?id=175 #已经对hadoop进行了介绍和hadoop的集群部署做了介绍,这里在深入的继续记录。
官网文档:https://hadoop.apache.org/docs/ #这里有各个版本的一些文档
一、操作命令
1.1 Hadoop命令
概述:
官网文档:https://hadoop.apache.org/docs/r2.7.4/hadoop-project-dist/hadoop-common/CommandsManual.html
$ /home/hadoop/hadoop/bin/hadoop #所有hadoop命令调用的bin/hadoop脚本。 不带任何参数运行hadoop脚本打印所有命令的描述。
用法:hadoop [--config confdir] [--loglevel loglevel] [COMMAND] [GENERIC_OPTIONS] [COMMAND_OPTIONS]
--config confdir #覆盖默认配置目录。 默认是${HADOOP_HOME}/conf
--loglevel loglevel #覆盖的日志级别。 有效的日志级别是致命的,错误、警告信息,调试和跟踪。 默认是信息。
GENERIC_OPTIONS #常见的一组选项支持多个命令。
COMMAND_OPTIONS #各种命令的选项中描述这对Hadoop documention常见的子项目。 HDFS和YARN覆盖在其它文档。通用选择:
-archives <comma separated list of archives> #在计算机上指定要解除归档的逗号分隔的归档。 仅适用于job。 -conf <configuration file> #指定应用程序配置文件。 -D <property>=<value> #使用给定属性值。 -files <comma separated list of files> #指定要复制到map reduce cluster的逗号分隔文件。 仅适用于job。 -jt <local> or <resourcemanager:port> #指定一个ResourceManager。 仅适用于job。 -libjars <comma seperated list of jars> #指定在类路径中包含逗号分隔的jar文件。 仅适用于job。
用户命令:
hadoop archive #创建一个hadoop存档 hadoop checknative [-a] [-h] #-a:检查所有库是否可用。-h:打印帮助说明 hadoop classpath [--glob |--jar <path> |-h |--help] #--glob:展开通配符。--jar path:将classpath写入jar命名的路径中。-h, --help打印帮助说明 hadoop credential <subcommand> [options] #create alias [-provider provider-path]: 提示用户将凭据存储为给定的别名。 将使用core-site.xml文件中的hadoop.security.credential.provider.path,除非指定-provider。 #delete alias [-provider provider-path] [-f]: 使用提供的别名删除凭据。 将使用core-site.xml文件中的hadoop.security.credential.provider.path,除非指定-provider。 该命令要求确认,除非指定-f #list [-provider provider-path]: 列出所有凭据别名core-site.xml文件中的hadoop.security.credential.provider.path将被使用,除非指定-provider。 hadoop distcp #递归复制文件或目录。 hadoop fs #当HDFS正在使用时,它是hdfs dfs的同义词。 hadoop jar <jar> [mainClass] args... #运行jar文件。使用yarn jar来启动YARN应用程序。 hadoop key <subcommand> [options] #通过KeyProvider管理密钥。 hadoop trace #查看和修改Hadoop跟踪设置。 hadoop version #打印hadoop版本 hadoop CLASSNAME #运行名为CLASSNAME的类。
管理命令:
对于hadoop群集的管理员有用的命令。
hadoop daemonlog -getlevel <host:httpport> <classname> #在由host:httpport运行的守护程序中打印由合格类名称标识的日志的日志级别。 此命令在内部连接到http://<host:httpport>/logLevel?log=<classname> hadoop daemonlog -setlevel <host:httpport> <classname> <level> #在由host:httpport运行的守护程序中设置由限定类名称标识的日志的日志级别。 此命令内部连接到http://<host:httpport>/logLevel?log=<classname>&level=<level>
获取/设置由守护程序中由限定类名称标识的日志的日志级别。如:
$ bin/hadoop daemonlog -setlevel 127.0.0.1:50070 org.apache.hadoop.hdfs.server.namenode.NameNode DEBUG
博文来自:www.51niux.com
1.2 文件系统层命令
官网文档:https://hadoop.apache.org/docs/r2.7.4/hadoop-project-dist/hadoop-common/FileSystemShell.html
文件系统(FS)shell包括与Hadoop分布式文件系统(HDFS)以及Hadoop支持的其他文件系统(如本地FS,HFTP FS,S3 FS等)直接交互的各种类似shell的命令。FS shell被调用:
bin/hadoop fs <args>
$ hadoop fs 或者$ hadoop dfs #都可以将参数以及参数格式都打印出来。(不过还是用dfs把,加url来进行对HDFS的操作,跟hdfs dfs一样)
appendToFile
#将本地文件添加到远端文件系统
用法: hadoop fs -appendToFile <localsrc> ... <dst>
例子:
$ hadoop fs -appendToFile test.txt /user/hadoop/test1 #这是把test.txt文件发送到HDFS文件系统的/user/hadoop/目录下面的test1文件,前面的目录不存在会一次创建 $ hadoop fs -appendToFile test.txt /test1/ #这里并不是把test.txt放到目标的test1/目录下面,因为最后只能是文件名称而非目录 $ hadoop fs -appendToFile test.txt hdfs://192.168.14.49:8020/test/test.txt #这里跟上面的的意思一样,上面也不是把文件发送到本地,而是发送到hdfs文件系统里面去,只是上面使用的是默认URL
#没有任何输出就表示没出错,成功返回0,错误返回1。



#这个命令只能是将文件添加到HDFS文件系统中,不能将目录发送到HDFS系统中。
cat
#将源路径复制到stdout。其实也就是查看的意思。
用法:hadoop fs -cat [-ignoreCrc] URI [URI ...] #-ignoreCrc选项禁用校验和验证。
$ hadoop fs -cat hdfs://master.hadoop:8020/test1 /test2/test2.txt
$ hadoop fs -cat test1 /test2/test2.txt
count
#计算与指定文件模式匹配的路径下的目录,文件和字节数。
用法:hadoop fs -count [-q] [-h]<paths>
$ hadoop fs -count hdfs://master.hadoop:8020/user #这是查看/user目录的计数信息
$ hadoop fs -count -q -h hdfs://master.hadoop:8020/test2 #这是以可读的方式显示/test2目录的信息
$ hadoop fs -count -q hdfs://master.hadoop:8020/test2/1.txt #这是查看/test2/1.txt文件的信息
#可以看到count主要还是用在对目录来统计计数好一点,可以看到目录里面包括根目录在内一共有多少个目录和有多少个文件,当然也可以看到目录的大小,当然对于单个文件目录计数就为0了。

#可以看到/test2下面确实是2个文件,并且两个文件大小加起来差不多为47.8KB.
df
#显示可用空间。用法:hadoop fs -df [-h] URI [URI ...] #-h以“可读”的方式格式化文件大小
$ hadoop fs -df -h hdfs://master.hadoop:8020 #查看当前集群空间使用情况

#上图的输出很好理解就不解释了
du
#显示目录或文件的大小。用法: hadoop fs -du [-s] [-h] URI [URI ...] #-s是汇总,主要还是用来统计目录大小好点。
$ hadoop fs -du -h hdfs://master.hadoop:8020/test2 #/test2目录下文件和目录的大小

$ hadoop fs -du -h -s hdfs://master.hadoop:8020/test2/ #加上-s是对指定的目录进行大小汇总

find
查找与指定表达式匹配的所有文件,并将选定的操作应用到它们。 如果没有指定路径,则默认为当前工作目录。 如果没有指定表达式,则默认为-print。以下主要表达式被识别:
-name pattern -iname pattern
#如果文件的基础名称与使用标准文件系统globbing的模式匹配,则将其评估为true。 如果使用-iname,则匹配不区分大小写。
-print -print0Always
#评估为true。 导致将当前路径名写入标准输出。 如果使用-print0表达式,则会附加ASCII NULL字符。
expression -a expression expression -and expression expression expression
#用于连接两个表达式的逻辑AND运算符。 如果两个子表达式都返回true,则返回true。 由两个表达式的并置所暗示,因此不需要明确指定。 如果第一个失败,则不会应用第二个表达式。
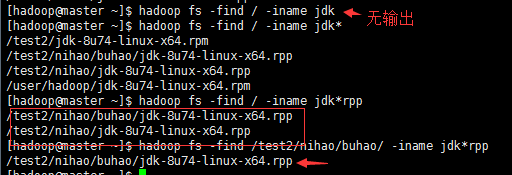
$ hadoop fs -find / -iname jdk #从根开始查找,将名称是jdk的打印出来
$ hadoop fs -find / -iname jdk* #这就是用到了正则表达式了,将jdk*的打印出来
$ hadoop fs -find /test2/nihao/buhao/ -iname jdk*rpp #将/test2/nihao/buhao/下jdk开头rpp结尾的打印出来
get
#将文件复制到本地文件系统。 可能使用-ignorecrc选项复制CRC校验失败的文件。 文件和CRC可以使用-crc选项进行复制。
#用法:hadoop fs -get [-ignorecrc] [-crc] [-p] [-f] <src> <localdst>
-p:保留访问和修改时间,所有权和权限。(假设权限可以跨文件系统传播) -f:覆盖目的地(如果已经存在)。 -ignorecrc:跳过对下载的文件进行CRC校验。 -crc:为下载的文件写CRC校验和。
$ hadoop fs -get /test2/nihao/buhao/jdk-8u74-linux-x64.rpp #将HDFS上面的/test2/nihao/buhao/jdk-8u74-linux-x64.rpp下载到本地,这样就是不改名称
$ hadoop fs -get /test2/nihao #这是get目录下载到本地,不改目录名称
$ hadoop fs -get /test2/nihao haha #这种就是get到本地并更名为haha目录
ls
#这个在linux上面是什么意思在这里就是什么意思,不过是对HDFS文件系统而言
用法:hadoop fs -ls [-d] [-h] [-R] <args>
-d:目录列为纯文件。 -h:以人类可读的方式格式化文件大小(例如,64.0m而不是67108864)。 -R:递归列出遇到的子目录。
mkdir
#以路径uri为参数,创建目录。
用法:hadoop fs -mkdir [-p] <paths> #-p选项行为非常像Unix mkdir -p,沿路径创建父目录。创建多个目录,目录之间用空格隔开
moveFromLocal
#类似于put命令,除了源localsrc在被复制之后被删除。也就是从本地mv到HDFS的指定目录下。
用法:hadoop fs -moveFromLocal <localsrc> <dst>
mv
#将文件从源移动到目标。 此命令还允许多个源,在这种情况下,目标需要是目录。 不允许跨文件系统移动文件。
用法:hadoop fs -mv URI [URI ...] <dest>
例子:
hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2 hadoop fs -mv hdfs://nn.example.com/file1 hdfs://nn.example.com/file2 hdfs://nn.example.com/file3 hdfs://nn.example.com/dir1
put
#将单个src或多个srcs从本地文件系统复制到目标文件系统。 如果源设置为“ - ”,如果目标文件已经存在,则复制失败,除非给出了-f标志,否则从stdin读取输入并写入目标文件系统。
用法: hadoop fs -put [-f] [-p] [-l] [ - | <localsrc1> .. ]. <dst>
-p:保留访问和修改时间,所有权和权限.(假设权限可以跨文件系统传播) -f:覆盖目的地(如果已经存在)。 -l:允许DataNode将文件延续到磁盘,强制复制系数为1.此标志将导致持久性降低。小心使用。注意这里是小L而不是1.

#上图可以看到如果文件存在就不能put,但是加上-f就是强制替换,然后加上-l就是让副本数变为1.

rm
#删除指定为args的文件。如果垃圾桶已启用,文件系统将删除的文件移动到垃圾桶目录(由FileSystem#getTrashRoot提供)。目前,垃圾邮件功能默认是禁用的。 用户可以通过为参数fs.trash.interval(在core-site.xml中)设置一个大于零的值来启用垃圾箱。
用法:hadoop fs -rm [-f] [-r|-R] [-skipTrash] <src> ...]
-f: 文件不存在,-f选项将不显示诊断消息或修改退出状态以反映错误。 -R: 会递归地删除目录及其下的任何内容。 -r: 等效于-R -skipTrash:绕过垃圾箱,如果启用,并立即删除指定的文件。 当需要从超配额目录中删除文件时,这可能很有用。
tail
#将文件的最后一千字节显示为stdout。
用法:hadoop fs -tail [-f] URI #-f选项将在文件增长时输出附加数据,如Unix中那样。
test
#测试一个文件或目录的属性。
用法:hadoop fs -test -[defsz] <path>
-d:如果路径是一个目录,返回0。 -e:如果路径存在,则返回0。 -f:如果路径是文件,则返回0。 -s:如果路径不为空,则返回0。 -z:如果文件的长度为零,则返回0。
touchz
#创建一个零长度的文件。 如果文件存在非零长度,则返回错误。
用法:hadoop fs -touchz URI [URI ...]
truncate
#将与指定文件模式匹配的所有文件截断为指定长度。
用法:hadoop fs -truncate [-w] <length> <paths>
-w:标志请求该命令等待块恢复完成。 如果没有-w标志,则在恢复过程中文件可能会保持未关闭一段时间。 在此期间,文件无法重新打开以进行追加。
截取前:
![_VA4KO3R()VTH5]RO4EQADS.png](http://blog.51niux.com/zb_users/upload/2017/10/201710301509334823468244.png)
$ hadoop fs -truncate -w 66 /test2/666.txt
截取后:

#截取不能加单位,只能从大文件往小里截取。
其他选项参数:
checksum #返回文件的校验和信息。用法: hadoop fs -checksum URI
chgrp #更改文件组的关联。 -R递归。用户必须是文件的所有者,否则是超级用户。用法:hadoop fs -chgrp [-R] GROUP URI [URI ...]
chmod #更改文件的权限。 使用-R,通过目录结构递归地进行更改。用法:hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI ...]
chown #更改文件的所有者。-R递归。用法: hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
copyFromLocal #与fs -put命令类似,除了源被限制为本地文件引用。用法: hadoop fs -copyFromLocal <localsrc> URI #下面是一些选项
-p:保留访问和修改时间,所有权和权限。 (假设权限可以跨文件系统传播) -f:覆盖目的地(如果已经存在)。 -l:允许DataNode将文件延续到磁盘,强制复制系数为1.此标志将导致持久性降低。 小心使用。 -d:跳过使用后缀._COPYING_创建临时文件。
copyToLocal #与get命令类似,除了目的地限制为本地文件引用。用法:hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
cp #在HDFS上面将文件或目录复制到目的地。 这个命令允许多个源,在这种情况下,目标必须是一个目录。用法:hadoop fs -cp [-f] [-p | -p[topax]] URI [URI ...] <dest>
-f选项将覆盖目的地(如果它已经存在)。 -p选项将保留文件属性[topx](时间戳,所有权,权限,ACL,XAttr)。
createSnapshot #创建快照,参考链接:https://hadoop.apache.org/docs/r2.7.4/hadoop-project-dist/hadoop-hdfs/HdfsSnapshots.html
deleteSnapshot #删除快照,参考链接:https://hadoop.apache.org/docs/r2.7.4/hadoop-project-dist/hadoop-hdfs/HdfsSnapshots.html
expunge #hadoop fs -expunge #在垃圾邮件目录下永久删除保留阈值以前的检查点中的文件,并创建新的检查点。
getfacl #显示文件和目录的访问控制列表(ACL)。如果一个目录具有默认的ACL,那么getfacl也会显示默认的ACL。 用法:hadoop fs -getfacl [-R] <path>
-R:递归列出所有文件和目录的ACL。 path:要列出的文件或目录。
getfattr #显示文件或目录的扩展属性名称和值(如果有)。用法:hadoop fs -getfattr [-R] -n name | -d [-e en] <path>
-R:递归列出所有文件和目录的属性。 -n name:转储指定的扩展属性值。 -d:转储与路径名关联的所有扩展属性值。 -e encoding:在检索它们后对其进行编码。有效的编码是“文本”,“十六进制”和“base64”。 编码为文本字符串的值以双引号(“)括起来,并且以十六进制和base64编码的值分别以0x和0为前缀。 path:文件或目录。
getmerge #将源目录和目标文件作为输入,并将src中的文件连接到目标本地文件。 可选择-nl可以设置为在每个文件的末尾添加换行符(LF)。简单来说就是将HDFS里的文件或者目录下面的所有内容追加到本地文件中,是向末尾追加的形式哦,以空行隔开。用法:hadoop fs -getmerge [-nl] <src> <localdst> #src支持目录和多个路径文件的形式。
help #返回帮助输出。用法:hadoop fs -help
moveToLocal #把HDFS上面的目录或者文件mv到本地。用法:hadoop fs -moveToLocal [-crc] <src> <dst>。 注意:这种方式还未实现。
renameSnapshot #重命名快照。 此操作需要快照目录的所有者权限。用法:hadoop fs -renameSnapshot <snapshotDir> <oldName> <newName>]
rmdir #删除一个目录用法:hadoop fs -rmdir [--ignore-fail-on-non-empty] <dir> ...] #--ignore-fail-on-non-empty:使用通配符时,如果目录仍然包含文件,请不要失败。
setfacl #设置文件和目录的访问控制列表(ACL)。用法:hadoop fs -setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]
-b:删除除基本ACL条目之外的所有内容。 保留用户,组和其他条目以与权限位兼容。 -k:删除默认的ACL。 -R:递归地对所有文件和目录应用操作。 -m:修改ACL。 新的条目将添加到ACL中,并保留现有的条目。 -x:删除指定的ACL条目。 其他ACL条目被保留。 --set:完全替换ACL,丢弃所有现有条目。 acl_spec必须包含用户,组和其他用户的条目以与权限位的兼容性。 acl_spec:逗号分隔的ACL条目列表。 path:要修改的文件或目录。
setfattr #为文件或目录设置扩展属性名称和值。用法:hadoop fs -setfattr {-n name [-v value] | -x name} <path>
-b:删除除基本ACL条目之外的所有内容。 保留用户,组和其他条目以与权限位兼容。 -n name:扩展属性名称。 -v value:扩展属性值。 有三种不同的编码方法。 如果参数用双引号括起来,那么该值就是引号内的字符串。 如果参数前缀为0x或0X,则将其视为十六进制数。 如果参数以0或0开始,则将其作为base64编码。 -x名称:删除扩展属性。 path:文件或目录。
setrep #更改文件的复制因子,也就是更改文件或者目录下面文件的副本数。 如果path是一个目录,则命令会递归地更改根据路径的目录树下的所有文件的复制因子。用法: hadoop fs -setrep [-R] [-w] <numReplicas> <path>
-w:标志请求该命令等待复制完成。 这可能需要很长时间。 -R: 标志被接受为向后兼容性。 没有效果
stat #以指定格式打印<path>上的文件/目录的统计信息。 如果未指定格式,则默认使用%y。用法:hadoop fs -stat [format] <path> ...] ,例如:hadoop fs -stat "%F %u:%g %b %y %n" /file
text #获取源文件并以文本格式输出文件。 允许的格式是zip和TextRecordInputStream。用法:hadoop fs -text [-ignoreCrc] <src> ...
usage #返回单个命令的帮助。用法:hadoop fs -usage [cmd ...]
博文来自:www.51niux.com
1.3 HDFS命令
官方文档:https://hadoop.apache.org/docs/r2.7.4/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html#dfsadmin
$ hdfs
用法:hdfs [--config confdir] [--loglevel loglevel] COMMAND COMMAND如下: dfs #在Hadoop支持的文件系统上运行文件系统命令。 classpath #打印所需的类路径获取Hadoop jar和所需的库 namenode -format #格式化DFS文件系统 secondarynamenode #运行DFS secondary namenode namenode #运行DFS namenode journalnode #运行DFS journalnode zkfc #运行ZK Failover Controller守护程序 datanode #运行DFS datanode dfsadmin #运行DFS管理客户端 haadmin #运行DFS HA管理客户端 fsck #运行DFS文件系统检查实用程序 balancer #运行集群平衡实用程序 jmxget #从NameNode或DataNode获取JMX导出的值。 mover #运行一个实用程序以跨存储类型移动块副本 oiv #将离线fsimage查看器应用到fsimage oiv_legacy #将离线fsimage查看器应用于传统的fsimage oev #将离线编辑查看器应用到编辑文件 fetchdt #从NameNode获取一个委托令牌 getconf #从配置中获取配置值 groups #获取用户所属的组 snapshotDiff # diff目录的两个快照,或者将当前目录内容与快照区分开来 lsSnapshottableDir #列出当前用户拥有的所有snaphottable目录 portmap #RPC portmap开始使用HDFS NFS3服务 nfs3 #启动NFS3网关使用HDFS NFS3服务 cacheadmin #配置HDFS缓存 crypto #配置HDFS加密区 storagepolicies #list/ get / set块存储策略 version #打印版本
getconf
$ hdfs getconf
[-namenodes] #获取集群中的namenode列表。 [-secondaryNameNodes] #获取集群中secondaryNameNode的列表。 [-backupNodes] #获取集群中备份节点的列表。 [-includeFile] #获取定义可以加入群集的数据库的包含文件路径。 [-excludeFile] #获取定义需要停用的数据库的排除文件路径。 [-nnRpcAddresses] #获取namenode rpc地址 [-confKey [key]] #从配置中获取一个特定的密钥
dfsadmin
#hdfs dfsadmin 和hadoop dfsadmin一致
$ hdfs dfsadmin #注意:管理命令只能作为HDFS超级用户运行。
-report [-live] [-dead] [-decommissioning] #报告基本文件系统信息和统计信息。 可选标志可用于过滤显示的DataNodes列表。 -safemode <enter | leave | get | wait> #安全模式维护命令。 安全模式是Namenode状态1.不接受对名称空间的更改(只读)2.不复制或删除块。在Namenode启动时自动输入安全模式,当配置的最小百分比的数据块满足最小复制条件时,将自动离开安全模式。 安全模式也可以手动输入,但也可以手动关闭。 -saveNamespace #将当前命名空间保存到存储目录中并重置修改日志。 需要安全模式。 -rollEdits #在活动的NameNode上滚动编辑日志。 -restoreFailedStorage true|false|check #此选项将打开/关闭自动尝试恢复失败的存储副本。 如果故障存储器再次可用,系统将在检查点期间尝试恢复编辑和/或fsimage。 'check'选项将返回当前设置。 -refreshNodes #重新读取主机并排除文件以更新允许连接到Namenode的数据节点以及应该停用或重新调试的数据。 -setQuota <quota> <dirname>...<dirname> #设置名称为每个目录配额N。 -clrQuota <dirname>...<dirname> #删除任何名称为每个目录配额。 -setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname> #设置空间配额N个字节为每个目录。 这是一个硬限制的总大小的目录树下的所有文件。 -clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname> #为每个目录删除任何空间配额。 -finalizeUpgrade #完成HDFS升级。 Datanodes删除其以前的版本工作目录,其次是Namenode执行相同操作。 完成升级过程。 -rollingUpgrade [<query|prepare|finalize>] #query 查询当前的滚动升级状态。prepare 准备一个新的滚动升级。finalize 确定当前的滚动升级。 -refreshServiceAcl #重新加载服务级授权策略文件。 -refreshUserToGroupsMappings #刷新用户到组的映射。 -refreshSuperUserGroupsConfiguration #刷新超级用户代理组映射 -refreshCallQueue #从配置重新加载呼叫队列。 -refresh <host:ipc_port> <key> [arg1..argn] #在<host:ipc_port>上触发由<key>指定的资源的运行时刷新。 之后的所有其他参数都将发送到主机。 -reconfig <datanode|...> <host:ipc_port> <start|status> #开始重新配置或获取持续重新配置的状态。 第二个参数指定节点类型。 目前,只支持重新加载DataNode的配置。 -printTopology #按照Namenode的报告,打印机架及其节点的树 -refreshNamenodes datanode_host:ipc_port #对于给定的数据库,重新加载配置文件,停止提供已移除的块池并开始提供新的块池。 -deleteBlockPool datanode_host:ipc_port blockpoolId [force] #如果传递强制,则给定数据库中给定块池ID的块池目录及其内容将被删除,否则只有当目录为空时,才会删除该目录。 如果datanode仍在服务块池,命令将失败。 -setBalancerBandwidth <bandwidth in bytes per second> #在HDFS块平衡期间更改每个数据线使用的网络带宽。 <bandwidth>是每个datanode将使用的每秒最大字节数。 该值覆盖dfs.balance.bandwidthPerSec参数。 注意:DataNode上的新值不会持久存在。 -fetchImage <local directory> #从NameNode下载最新的fsimage并将其保存在指定的本地目录中。 -allowSnapshot <snapshotDir> #允许创建目录的快照。 如果操作成功完成,则该目录将变为快照。 -disallowSnapshot <snapshotDir> #禁止要创建的目录的快照。 在禁止快照之前,必须删除目录的所有快照。 -shutdownDatanode <datanode_host:ipc_port> [upgrade] #提交给定datanode的关闭请求。 -getDatanodeInfo <datanode_host:ipc_port> #获取有关给定datanode的信息。 -metasave filename #将Namenode的主数据结构保存到由hadoop.log.dir属性指定的目录中的filename。 如果文件名存在,文件名将被覆盖。 文件名将包含以下每一行的一行1。 Datanodes心跳与Namenode2。 等待复制的块3。 目前正在复制的块4。 等待被删除的块 -triggerBlockReport [-incremental] <datanode_host:ipc_port> #触发给定数据库的块报告。 如果指定了'incremental',否则将是一个完整的块报告。 -help [cmd] #显示给定命令或所有命令的帮助,如果没有指定。
1.4 MapReduce命令
#所有mapreduce命令都由bin/mapred脚本调用。没有任何参数运行映射脚本会打印所有命令的描述。
用法: mapred [--config confdir] [--loglevel loglevel] COMMAND #其中COMMAND是其中之一:
pipes #运行一个管道的工作。 job #操纵MapReduce作业 queue #命令交互,查看作业队列信息 classpath #打印所需的类路径获取Hadoop jar和所需的库。 historyserver #将作业历史记录服务器作为独立守护进程运行 distcp <srcurl> <desturl> #递归地复制文件或目录。 archive -archiveName NAME -p <parent path> <src>* <dest> #创建一个hadoop存档。 hsadmin #负责执行MapReduce hsadmin客户机JobHistoryServer行政命令。
job
$ mapred job #用法:CLI <command> <args>
-submit <job-file> #提交作业 -status <job-id> #打印map并减少完成百分比和所有作业计数器。 -counter <job-id> <group-name> <counter-name> #打印计数器值。 -kill <job-id> #杀死job -set-priority <job-id> <priority> #更改作业的优先级。允许的优先级值为VERY_HIGH,HIGH,NORMAL,LOW,VERY_LOW -events <job-id> <from-event-#> <#-of-events> #打印给定范围的jobtracker收到的事件的详细信息。 -history <jobHistoryFile> #打印作业详细信息 -list [all] #显示尚未完成的作业。 -list all全部显示所有作业。 -list-active-trackers # -list-blacklisted-trackers # -list-attempt-ids <job-id> <task-type> <task-state> # -kill-task <task-attempt-id> #杀死任务。 杀死的任务不计入失败的尝试。 -fail-task <task-attempt-id> #失败的任务.失败的任务会计入失败的尝试次数。 -logs <job-id> <task-attempt-id>
pipes
$ mapred pipes #跟hadoop pipes一样
-input <path> #输入目录 -output <path> #输出目录 -jar <jar file> #jar文件名 -inputformat <class> #InputFormat类 -map <class> #Java映射类 -partitioner <class> #Java分区 -reduce <class> #Java reduce类 -writer <class> #Java RecordWriter -program <executable> #可执行URI -reduces <num> #reduces的数量 -lazyOutput <true/false> #createOutputLazil
queue
$ mapred queue
-list #获取系统中配置的作业队列列表。 以及与作业队列相关联的调度信息。 -info <job-queue-name> [-showJobs] #显示特定作业队列的作业队列信息和关联的调度信息。 如果存在-showJobs选项,则显示提交到特定作业队列的作业列表。 -showacls #显示当前用户允许的队列名称和关联的队列操作。 列表只包含用户可以访问的队列。
hsadmin
-refreshUserToGroupsMappings #刷新用户到组的映射 -refreshSuperUserGroupsConfiguration #刷新超级用户代理组映射 -refreshAdminAcls #刷新管理工作历史服务器的acls -refreshLoadedJobCache #刷新作业历史记录服务器的作业缓存 -refreshJobRetentionSettings #刷新工作历史期,工作clean设置 -refreshLogRetentionSettings #刷新日志保留期和日志保留检查间隔 -getGroups [username] #获取用户所属的组 -help [cmd] #显示给定命令或所有命令的帮助,如果没有指定。
博文来自:www.51niux.com
二、 目录结构及文件
2.1 hadoop的目录结构
$ ls -l /home/hadoop/hadoop/|grep '^d'
bin #存放对hadoop相关服务(HDFS,YARN)进行操作的脚本 etc #hadoop的配置文件目录,存放hadoop的配置文件 include #对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 lib #该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 libexec #各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 logs #日志文件存放目录 sbin #相关服务启动关闭脚本目录 share #Hadoop各个模块编译后的jar包所在的目录。 src #hadoop源码
2.2 namenode上的元数据目录结构和文件
$ ls -l /home/hadoop/dfs/name/
drwxrwxr-x 2 hadoop hadoop 483328 10月 30 17:10 current #元数据信息都存放在这个目录中 -rw-rw-r-- 1 hadoop hadoop 19 10月 30 17:08 in_use.lock #防止一台机器同时启动多个Namenode进程导致目录数据不一致
$ ls -l /home/hadoop/dfs/name/current/
#HDFS metadata主要存储两种类型的文件,fsimage:记录某一永久性检查点(Checkpoint)时整个HDFS的元信息。edits:所有对HDFS的写操作都会记录在此文件中。
-rw-rw-r-- 1 hadoop hadoop 340 10月 26 18:59 edits_0000000000000000001-0000000000000000006 -rw-rw-r-- 1 hadoop hadoop 42 10月 26 19:00 edits_0000000000000000007-0000000000000000008 -rw-rw-r-- 1 hadoop hadoop 42 10月 26 19:01 edits_0000000000000000009-0000000000000000010 #好多这种形式的文件,HDFS的写造作就记录在此文件中 -rw-rw-r-- 1 hadoop hadoop 1048576 10月 30 17:18 edits_inprogress_0000000000000011498 #当前正在被追加的edit log -rw-rw-r-- 1 hadoop hadoop 323 10月 26 18:01 fsimage_0000000000000000000 -rw-rw-r-- 1 hadoop hadoop 62 10月 26 18:01 fsimage_0000000000000000000.md5 -rw-rw-r-- 1 hadoop hadoop 2905 10月 30 17:04 fsimage_0000000000000011472 -rw-rw-r-- 1 hadoop hadoop 62 10月 30 17:04 fsimage_0000000000000011472.md5 #每次checkpoing(合并所有edits到一个fsimage的过程)产生的最终的fsimage,同时会生成一个.md5的文件用来对文件做完整性校验 -rw-rw-r-- 1 hadoop hadoop 6 10月 30 17:16 seen_txid #保存最近一次fsimage或者edits_inprogress的transaction ID。需要注意的是,这并不是Namenode当前最新的transaction ID,该文件只有在checkpoing(merge of edits into a fsimage)或者edit log roll(finalization of current edits_inprogress and creation of a new one)时才会被更新。 #这个文件的目的在于判断在Namenode启动过程中是否有丢失的edits,由于edits和fsimage可以配置在不同目录,如果edits目录被意外删除了,最近一次checkpoint后的所有edits也就丢失了,导致Namenode状态并不是最新的,为了防止这种情况发生,Namenode启动时会检查seen_txid,如果无法加载到最新的transactions,Namenode进程将不会完成启动以保护数据一致性。 #checkpoint介绍:HDFS会定期(dfs.namenode.checkpoint.period,默认3600秒)的对最近的fsimage和一批新edits文件进行Checkpoint(也可以手工命令方式),Checkpoint发生后会将前一次Checkpoint后的所有edits文件合并到新的fsimage中,HDFS会保存最近两次checkpoint的fsimage。Namenode启动时会把最新的fsimage加载到内存中。 -rw-rw-r-- 1 hadoop hadoop 205 10月 30 17:04 VERSION
$ cat VERSION
#Mon Oct 30 17:04:51 CST 2017 namespaceID=1522387214 clusterID=CID-2cb48463-f5fa-4a1e-9cd0-68171a758f0b cTime=0 #cTime是namenode存储系统的创建时间。对刚格式化的存储系统,这个值为0。但在文件系统升级后该值会更新到新的时间戳。 storageType=NAME_NODE #有两种取值NAME_NODE/JOURNAL_NODE,对于JournalNode的参数dfs.journalnode.edits.dir,其下的VERSION文件显示的是JOURNAL_NODE blockpoolID=BP-218151797-192.168.14.49-1509012087773 layoutVersion=-63 #属性layoutVersion是一个负整数, 描述了HDFS持久化数据结构的版本,也称为布局。只要布局变更,版本号就会递减(每次递减1),此时hdfs也需要升级。 否则磁盘仍然使用旧的版本的布局,新版本的namenode和datanode就无法正常工作了。
#namespaceID/clusterID/blockpoolID - 这三个ID在整个HDFS集群全局唯一,作用是引导Datanode加入同一个集群。在HDFS Federation机制下,会有多个Namenode,所以不同Namenode直接namespaceID是不同的,分别管理一组blockpoolID,但是整个集群中,clusterID是唯一的,每次format namenode会生成一个新的,也可以使用-clusterid手工指定ID
NameNode启动过程中fsimage文件处理流程:
首先加载硬盘上的fsimage文件和edits文件,在内存中merge后将新的fsimage写到磁盘上,这个过程叫checkpoint(一般NameNode会配置两个目录来存放fsimage和edits文件,分别是本地磁盘和NFS,防止NameNode所在机器的磁盘坏掉后数据丢失。NameNode启动时会比较NFS和本地磁盘中的fstime中记载的checkpoint时间加载最新的fsimage。)
NameNode加载完fsimage&edits文件后,会将merge后的结果同时写到本地磁盘和NFS。此时磁盘上有一份原始的fsimage文件和一份checkpoint文件:fsimage.ckpt。同时edits文件为空。
写完checkpoint后,将fsimage.ckpt改名为fsimage(覆盖原有的fsimage),并将最新时间戳写入fstime文件
2.3 datanode存储目录结构和文件
$ ls -l /data01/
drwxrwxr-x 3 hadoop hadoop 4096 10月 26 18:02 current #存储数据和文件都在这个文件中 -rw-rw-r-- 1 hadoop hadoop 20 10月 30 17:08 in_use.lock #防止一台机器同时启动多个Datanode进程导致数据不一致
$ ls -l /data01/current/
drwx------ 4 hadoop hadoop 4096 10月 30 17:08 BP-218151797-192.168.14.49-1509012087773 #BP代表BlockPool的意思,就是上面Namenode的VERSION中的集群唯一blockpoolID,如果是Federation HDFS,则该目录下有两个BP开头的目录,IP部分和时间戳代表创建该BP的NameNode的IP地址和创建时间戳 -rw-rw-r-- 1 hadoop hadoop 229 10月 30 17:08 VERSION
$ cat /data01/current/VERSION
#Mon Oct 30 17:08:18 CST 2017 storageID=DS-714d0801-975c-4fa3-ba9a-502bf7dc2d5d #这个是此块盘的Id号,所有每块盘下面VERSION文件里面此ID都是不一样的 clusterID=CID-2cb48463-f5fa-4a1e-9cd0-68171a758f0b #这里是整个集群的ID号,所以这个号是唯一的,大家都一样,主要是跟namenode哪里一致,这样大家都在一个集群里面。 cTime=0 datanodeUuid=2b7148e7-3082-4e2b-a258-342fc0b101a5 #这个是本datanode节点的uuid,本机下面所有的数据盘都一样,但是跟其他datanode节点不一样 storageType=DATA_NODE #storageType是DATA_NODE layoutVersion=-56
$ ls -l /data01/current/BP-218151797-192.168.14.49-1509012087773/
drwxrwxr-x 4 hadoop hadoop 4096 10月 30 17:07 current #保存了已写入HDFS文件系统的数据块和一些系统工作时需要的文件 -rw-rw-r-- 1 hadoop hadoop 166 10月 26 18:02 scanner.cursor drwxrwxr-x 2 hadoop hadoop 4096 10月 30 17:08 tmp #保存用于数据块复制时,当前正在写的数据块
$ ls -l /data01/current/BP-218151797-192.168.14.49-1509012087773/current/
-rw-rw-r-- 1 hadoop hadoop 22 10月 30 17:07 dfsUsed drwxrwxr-x 3 hadoop hadoop 4096 10月 27 14:41 finalized drwxrwxr-x 2 hadoop hadoop 4096 10月 30 11:01 rbw #rbw是“replica being written”的意思,该目录用于存储用户当前正在写入的数据。 -rw-rw-r-- 1 hadoop hadoop 132 10月 30 17:08 VERSION
$ ls -lh /data01/current/BP-218151797-192.168.14.49-1509012087773/current/finalized/subdir0/subdir0/
-rw-rw-r-- 1 hadoop hadoop 64M 10月 30 10:59 blk_1073741847 #HDFS种的文件数据库,存储的是原始文件内容 -rw-rw-r-- 1 hadoop hadoop 513K 10月 30 10:59 blk_1073741847_1024.meta #块的元数据文件:包括版本和类型信息的头信息,与一系列块的区域检验和组成。 -rw-rw-r-- 1 hadoop hadoop 4 10月 30 11:01 blk_1073741859 -rw-rw-r-- 1 hadoop hadoop 11 10月 30 11:01 blk_1073741859_1036.meta
DataNode启动过程:
datanode启动时,每个datanode对本地磁盘进行扫描,将本datanode上保存的block信息汇报给namenode
namenode在接收到每个datanode的块信息汇报后,将接收到的块信息,以及其所在的datanode信息等保存在内存中。
Namenode将block ->datanodes list的对应表信息保存在BlocksMap中。
