Hadoop(五)HA高可用
前面我们玩的都是单点namenode,如果namenode出问题了后者说元数据丢失了一部分,那就呵呵哒了,这也是以前存在的一个很大的安全隐患,但是现在已经不是啥问题了。再来吹一波。
HDFS就是Hadoop加DFS,所以我们这里就用Hadoop HA来统称了。
一、Hadoop HA的发展史
1.1 hadoop 1.0的单点问题
在hadoop 1.0时代,只有一个Namenode,这也是被人胆小的地方,用各种措施来保证元数据的安全。如果NameNode数据丢失或者不能工作,那么整个集群就不能恢复了。虽然有Secondary NameNode,但是它并不是namenode,它只是负责阶段性的合并edits和fsimage,以缩短集群启动的时间。当NN出问题的时候,Secondary NN并无法立刻提供服务,Secondary NN甚至无法保证数据完整性:如果NN数据丢失的话,在上一次合并后的文件系统的改动会丢失。所以元数据一般存多份,再保险点的话还要保存到共享存储上面一份。但是如果Namenode挂掉了,并不能自动切换,还要手动来一把如果没问题的话还能再重新启动起来。
1.2 Hadoop 2.x对单点的解决
单NN的架构使得HDFS在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NN进程使用的内存可能会达到上百G,常用的估算公式为1G对应1百万个块,按缺省块大小计算的话,大概是64T (这个估算比例是有比较大的富裕的,其实,即使是每个文件只有一个块,所有元数据信息也不会有1KB/block)。同时,所有的元数据信息的读取和操作都需要与NN进行通信,譬如客户端的addBlock、getBlockLocations,还有DataNode的blockRecieved、sendHeartbeat、blockReport,在集群规模变大后,NN成为了性能的瓶颈也成了隐患。Hadoop 2.0里的HDFS Federation就是为了解决这两个问题而开发的。
对NameNode单点的解决:
为了解决hadoop 1.0中的单点问题,在hadoop 2.0中NameNode不再是只有一个,可以有多个(目前只支持2个,超过两个执行会报错的)。一个是active状态,一个是standby状态。当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作了,通过手工或者自动切换,standby状态的namenode节点就可以转变为active状态,整个集群就可以继续工作,这样就提高了可靠性。
对数据共享的解决:
新的HDFS采用了一种共享机制,Quorum Journal Node(JournalNode)集群或者Nnetwork File System(NFS)进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这里使用JournalNode集群进行数据共享(这也是主流的做法)。
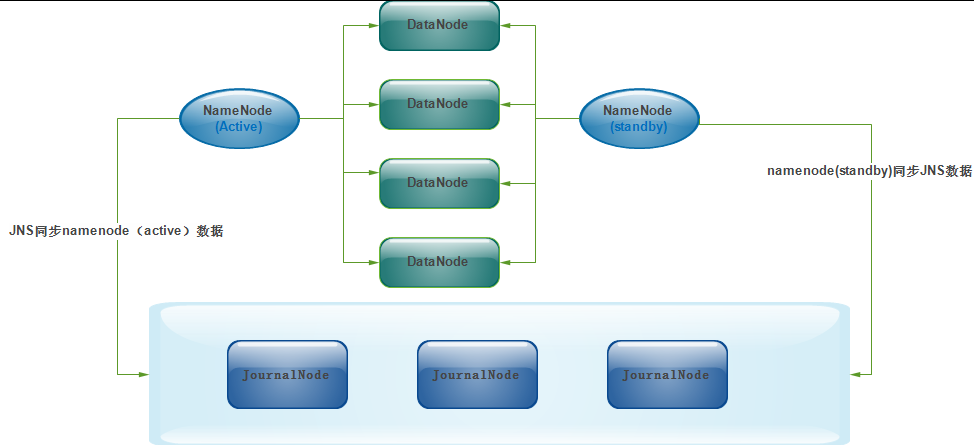
#此图和此图的解释内容来自:http://eksliang.iteye.com/blog/2226986
#为了让Standby Node与Active Node保持同步,这两个Node都与一组称为JNS的互相独立的进程保持通信(Journal Nodes)。两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了
NameNode之间的故障切换
hadoop已经支持两个namenode节点,当然要确保同一时刻只有一个namenode处于active状态是很重要的(另一个namenode处于备份状态,活动状态的namenode会响应集群中所有的客户端,备份状态的namenode只是作为一个副本,保证在必要的时候提供一个快速的转移),不然的话就是传说中的脑裂"split-brain"(三节点通讯阻断,即集群中不同的datanode却看到了两个Active Namenode,将会导致集群操作的混乱,那么两个NameNode将会分别由两种不同的状态,可能会导致数据丢失,或者状态异常)。
为了支持快速的故障转移(failover)Standby node持有集群中blocks的最新位置是非常必要的。为了达到这一目的,DataNodes上需要同时配置这两个Namenode的地址,同时和它们都建立心跳链接,并把block位置发送给它们。
对于HA集群,为了确保同一时刻只有一个NameNode,就需要使用ZooKeeper了。首先HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。
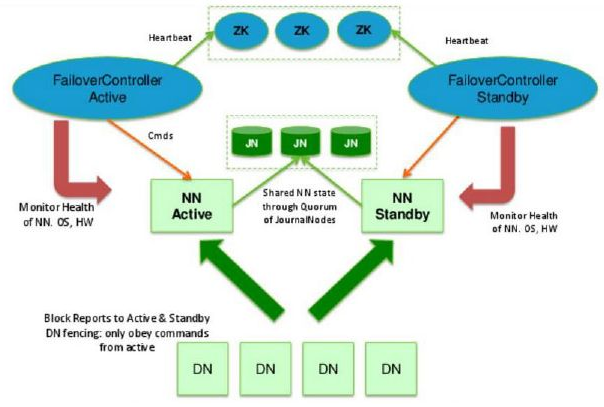
#上图就是hadoop2.X ha的原理图,也叫QJM(qurom Journal Manager),这是一种基于Paxos算法实现的HDFS HA方案。
#其处理流程为:集群启动后一个NameNode处于Active状态,并提供服务,处理客户端和DataNode的请求,并把editlog写到本地和share editlog(这里是QJM)中。另外一个NameNode处于Standby状态,它启动的时候加载fsimage,然后周期性的从share editlog中获取editlog,保持与Active节点的状态同步。为了实现Standby在Active挂掉后迅速提供服务,需要DataNode同时向两个NameNode汇报,使得Stadnby保存block to DataNode信息,因为NameNode启动中最费时的工作是处理所有DataNode的blockreport。为了实现热备,增加FailoverController和Zookeeper,FailoverController与Zookeeper通信,通过Zookeeper选举机制,FailoverController通过RPC让NameNode转换为Active或Standby。
#这种选举仲裁的方案很早在以前处理各种脑裂问题的时候就已经运用上了,我记得当时还有硬件设备来专门的负责仲裁防止脑裂。
关于HA详细的解释清参照链接:
http://www.cnblogs.com/tgzhu/p/5790565.html
http://blog.csdn.net/dr_guo/article/details/50939537
关于Journalnode的源码分析:http://blog.csdn.net/androidlushangderen/article/details/48415073
二、Hadoop HA部署
Zookeeper集群搭建部署:http://blog.51niux.com/?id=182
2.1 机器列表
| Namenode | JournalNode | DataNode | ZooKeeper |
| 192.168.14.49 | 192.168.14.49 | 192.168.14.51 | 192.168.14.54 |
| 192.168.14.50 | 192.168.14.50 | 192.168.14.52 | 192.168.14.55 |
| 192.168.14.51 | 192.168.14.53 | 192.168.14.56 | |
| 192.168.14.54 | |||
| 192.168.14.55 | |||
| 192.168.14.56 |
#http://blog.51niux.com/?id=175 #还是那票机器,主机名jdk什么的都配置好了啊,现在集群也是再跑的,现在将其改为HA模式,让192.168.14.50改为namenode的备节点。
2.2 修改配置文件
修改core-site.xml配置文件:
# cat /home/hadoop/hadoop/etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <! -- 为hadoop客户端配置HA集群的URI作为默认路径。这里是使用"mycluster"作为名称服务ID --> <property> <name>fs.default.name</name> <value>hdfs://mycluster</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <!--指定所有用户可以访问--> <property> <name>hadoop.proxyuser.hduser.hosts</name> <value>*</value> </property> <!--指定所有用户组可以访问--> <property> <name>hadoop.proxyuser.hduser.groups</name> <value>*</value> </property> <property> <name>io.compression.codecs </name> <value>org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.SnappyCodec</value> </property> <property> <name>io.compression.codec.lzo.class </name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property> <!--zk&ha --> <!--HA模式下的edit log文件会同时写入多个JournalNodes节点的dfs.journalnode.edits.dir路径下--> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/data/journal</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>slave04.hadoop:2181,slave05.hadoop:2181,slave06.hadoop:2181</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> <description>Number of minutes between trash checkpoints. If zero, the trash feature is disabled. </description> </property> </configuration>
#fs.trash.interval:丢进回收站中的文件多久后(准确的说是多少分钟后)会被系统永久删除;默认是0也就是没有回收站。这里1440是1天;
#fs.trash.checkpoint.interval:前后两次检查点的创建时间间隔(单位也是分钟);新的检查点被创建后,随之旧的检查点就会被系统永久删除;默认也是0.
修改hdfs-site.xml配置文件:
# cat /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
<configuration> <! --已经不需要这个节点提供这个服务了--> <!--property> <name>dfs.namenode.secondary.http-address</name> <value>smaster.hadoop:9001</value> </property--> <! --既然已经有了journalnode同步edit.log这里就一个目录就可以了--> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///data01,file:///data02,file:///data03,file:///data04,file:///data05,file:///data06,file:///data07,file:///data08,file:///data09,file:///data10</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.block.size</name> <value>67108864</value> </property> <property> <name>dfs.balance.bandwidthPerSec</name> <value>104857600</value> </property> <property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/hadoop/etc/hadoop/excludes</value> </property> <!-- ha&zk --> <!--命名空间的逻辑名称。如果使用HDFS Federation,可以配置多个命名空间的名称,使用逗号分开即可。--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--命名空间中所有NameNode的唯一标示名称。可以配置多个,使用逗号分隔。该名称是可以让DataNode知道每个集群的所有NameNode。当前,每个集群最多只能配置两个NameNode。--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--namenode监听的RPC地址--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>master.hadoop:8020</value> </property> <!--namenode监听的http地址--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>master.hadoop:50070</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>smaster.hadoop:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>smaster.hadoop:50070</value> </property> <!-- 这是NameNode读写JNs组的uri。通过这个uri,NameNodes可以读写edit log内容。URI的格式"qjournal://host1:port1;host2:port2;host3:port3/journalId"。 这里的host1、host2、host3指的是Journal Node的地址,这里必须是奇数个,至少3个;其中journalId是集群的唯一标识符,对于多个联邦命名空间,也使用同一个journalId。--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master.hadoop:8485;smaster.hadoop:8485;slave01.hadoop:8485/mycluster</value> </property> <!--HDFS客户端连接到Active NameNode的一个java类--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--配置active namenode出错时的处理类。当active namenode出错时,一般需要关闭该进程。处理方式可以是ssh也可以是shell。这个机制在hadoop中称为fencing(包括ssh发送kill指令,执行自定义脚本两道保障) 如果配置为sshfence,当主NameNode异常时,使用ssh登录到主NameNode,然后使用fuser将主NameNode杀死,因此需要确保所有NameNode上可以使用fuser。用来保证同一时刻只有一个主NameNode,以防止脑裂。--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!--使用sshfence隔离机制时需要ssh免登陆,指定私钥--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!--dfs.ha.automatic-failover.enabled 为 true (即自动故障状态切换),默认是false也就是需要手工切换--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
HDFS和YARN的HA故障切换可参照连接:http://blog.csdn.net/u011414200/article/details/50336735
修改mapred-site.xml配置文件:
# cat /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>slave01.hadoop:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>slave01.hadoop:19888</value> </property> <property> <name>mapred.child.env </name> <value>LD_LIBRARY_PATH=/home/hadoop/hadoop/lzo/lib</value> </property> <property> <name>mapreduce.map.output.compress</name> <value>true</value> </property> <property> <name>mapreduce.map.output.compress.codec</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property> <property> <name>mapreduce.output.fileoutputformat.compress.type</name> <value>BLOCK</value> </property> <property> <name>mapreduce.output.fileoutputformat.compress</name> <value>true</value> </property> <property> <name>mapreduce.output.fileoutputformat.compress.codec</name> <value>org.apache.hadoop.io.compress.DefaultCodec</value> </property> <property> <name>mapreduce.map.memory.mb</name> <value>2048</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>2048</value> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/history/done</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/history/done_intermediate</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/history/done_intermediate</value> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx1024m</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx1024m</value> </property> <property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/hadoop/etc/hadoop/excludes</value> </property> </configuration>
#这里倒是没什么要调整的用默认参数就行,我就把mapreduce.jobhistory.address调整到某一个节点吧。
修改yarn-site.xml配置:
#这里也是保持默认没有什么好修改的,就是贴下配置。
# cat /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>slave01.hadoop:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>slave01.hadoop:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>slave01.hadoop:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>slave01.hadoop:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>slave01.hadoop:8088</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>57344</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>57344</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>20</value> </property> </configuration>
创建对应的目录:
# mkdir -p /home/hadoop/data/journal
# mkdir -p /home/hadoop/dfs/name
# chown -R hadoop:hadoop /home/hadoop
将配置文件同步到所有节点,并将私钥从master.hadoop给smaster.hadoop和slave01.hadoop一份:
2.3 启动相关服务
启动zookeeper服务:
$ /home/hadoop/zookeeper/bin/zkServer.sh start
创建命名空间:
$ /home/hadoop/hadoop/bin/hdfs zkfc -formatZK #再其中一个namenode上执行,仅在第一次的时候执行此操作
启动所有JournalNode:
#NameNode将元数据操作日志记录在JournalNode上,主备NameNode通过记录在JouralNode上的日志完成元数据同步。
$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start journalnode #这条命令要在三个JournalNode节点上面执行,注意只有第一次需要这么启动,之后启动hdfs会包含journalnode
初始化JournalNode:
#如果是非HA转HA才需要这一步,在其中一个JournalNode上执行:
#如果是新的集群直接执行:hdfs namenode -format #这样在两台namenode集群上面都会进行初始化操作。因为我这里集群已经有数据了就不用执行这步了。
$ /home/hadoop/hadoop/bin/hdfs namenode -initializeSharedEdits #此命令默认是交互式的,加上参数-force转成非交互式。在一个namenode节点执行此命令,下图可以看到元数据在同步

#如果是旧的集群这个从/home/hadoop/dfs/name往三个节点的/home/hadoop/data/journal/同步的时间比较久。
#在往三个JournalNode节点的/home/hadoop/data/journal/目录下面进行同步。
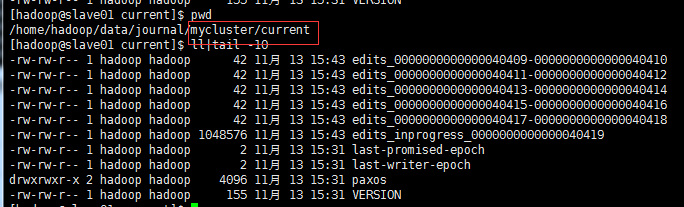
#随便登录一个JournalNode节点可以看到目录下面创建了mycluster目录,这是我们集群名,然后又创建了current目录,然后下面就是同步过来的元数据。
启动hdfs服务:
$ scp -r /home/hadoop/dfs smaster.hadoop:/home/hadoop #先把/home/hadoop/dfs/name从master同步到smaster一份,不然smaster的namenode节点启动不了
$ /home/hadoop/hadoop/sbin/start-dfs.sh #在master.hadoop节点执行
启动yarn服务:
$ /home/hadoop/hadoop/sbin/start-yarn.sh #在slave01.hadoop节点执行
$ /home/hadoop/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver #在slave01.hadoop节点执行,方便后面进行历史查看
启动ZookeeperFailoverController:
$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start zkfc #在master.hadoop和smaster.hadoop上面分别执行此命令启动主备切换进程
#只有启动了DFSZKFailoverController进程,HDFS才能自动切换主备。注:zkfc是zookeeper failover controller的缩写。
#上面提到的要开启的服务记得添加开机自启动哦。
2.4 检查:
检查zookeeper:
#检查三个节点slave04.hadoop,slave05.hadoop,slave06.hadoop
#echo ruok|nc 127.0.0.1 2181 #都是OK状态
imok
$ jps #三个都查看一下,启动的进程是一样的
10709 Jps 9606 NodeManager 10585 QuorumPeerMain #都有这个进程,当然其他的进程也启动起来了。 3770 DataNode
$ /home/hadoop/zookeeper/bin/zkCli.sh -server localhost:2181 #进入zk里面查看一下都创建了点啥
[zk: localhost:2181(CONNECTED) 6] ls2 /hadoop-ha/mycluster #查看/hadoop-ha/mycluster目录 [ActiveBreadCrumb, ActiveStandbyElectorLock] #可以看到还有两个目录 cZxid = 0x40000000a ctime = Mon Nov 13 14:56:44 CST 2017 mZxid = 0x40000000a mtime = Mon Nov 13 14:56:44 CST 2017 pZxid = 0x400000021 cversion = 10 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 2 [zk: localhost:2181(CONNECTED) 7] get /hadoop-ha/mycluster/ActiveBreadCrumb #这个节点里面保存了这个 Active NameNode 的地址信息 master.hadoop �>(�>1 #可以看到当前是master.hadoop cZxid = 0x40000000e ctime = Mon Nov 13 15:06:21 CST 2017 mZxid = 0x500000001 mtime = Mon Nov 13 18:45:28 CST 2017 pZxid = 0x40000000e cversion = 0 dataVersion = 3 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 37 numChildren = 0 [zk: localhost:2181(CONNECTED) 8] get /hadoop-ha/mycluster/ActiveStandbyElectorLock #中心思想为创建临时(EPHEMERAL)节点"ActiveStandbyElectorLock",并且只要有一台机器成功创建了该节点就成为leader。由于该节点是临时的,当会话过期或者连接失败时当前active leader可能lose这个节点,因此其他节点就有机会来创建相同的节点而成为leader。 master.hadoop �>(�>1 #可以当成一个锁,锁定了当前的主namenode节点是master.hadoop cZxid = 0x400000021 ctime = Mon Nov 13 17:24:03 CST 2017 mZxid = 0x400000021 mtime = Mon Nov 13 17:24:03 CST 2017 pZxid = 0x400000021 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x15fb41da1210002 dataLength = 37 numChildren = 0
详细的过程可参考:http://blog.csdn.net/liu812769634/article/details/53097268
详细的代码流程可以参考:http://blog.csdn.net/xfg0218/article/details/60320782
检查datanode节点:
$ jps #下面两个进程都是存在的
8450 NodeManager 2665 DataNode
$ yarn node -list #随便一个节点执行,列举YARN集群中的所有NodeManager
17/11/13 19:00:15 INFO client.RMProxy: Connecting to ResourceManager at slave01.hadoop/192.168.14.51:8032 Total Nodes:6 Node-Id Node-State Node-Http-Address Number-of-Running-Containers slave04.hadoop:44176 RUNNING slave04.hadoop:8042 0 slave02.hadoop:50925 RUNNING slave02.hadoop:8042 0 slave03.hadoop:52900 RUNNING slave03.hadoop:8042 0 slave05.hadoop:54279 RUNNING slave05.hadoop:8042 0 slave06.hadoop:49154 RUNNING slave06.hadoop:8042 0 slave01.hadoop:54252 RUNNING slave01.hadoop:8042 0
检查namenode节点:
$ jps #在master.hadoop和smaster.hadoop上面查看
22202 JournalNode 21947 NameNode 22379 DFSZKFailoverController 24463 Jps
#smaster.hadoop节点由于是备用节点,是看不了目录结构的。
检查ResourceManager节点:
$ jps #在slave01.hadoop节点上面查看,因为这个节点又是datanode节点,又是JournalNode节点,所以启动的进程是比较多的。
9553 ResourceManager 12536 Jps 3096 JournalNode 2969 DataNode 9679 NodeManager

2.5 namenode的HA切换测试
在master.hadoop节点上面执行:
$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh stop namenode #手工将namenode节点关闭掉
#然后你可能会发现并么有切换,这时候如果有问题应该查看日志了。
#查看备机的日志:
[hadoop@smaster ~]$ tail -f /home/hadoop/hadoop/logs/hadoop-hadoop-zkfc-smaster.hadoop.log
2017-11-13 23:07:44,201 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Next authentication method: gssapi-with-mic 2017-11-13 23:07:44,208 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Authentications that can continue: publickey,keyboard-interactive,password 2017-11-13 23:07:44,208 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Next authentication method: publickey 2017-11-13 23:07:44,244 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Authentication succeeded (publickey). 2017-11-13 23:07:44,245 INFO org.apache.hadoop.ha.SshFenceByTcpPort: Connected to master.hadoop 2017-11-13 23:07:44,245 INFO org.apache.hadoop.ha.SshFenceByTcpPort: Looking for process running on port 8020 2017-11-13 23:07:44,283 WARN org.apache.hadoop.ha.SshFenceByTcpPort: PATH=$PATH:/sbin:/usr/sbin fuser -v -k -n tcp 8020 via ssh: bash: fuser: 未找到命令 2017-11-13 23:07:44,284 INFO org.apache.hadoop.ha.SshFenceByTcpPort: rc: 127 2017-11-13 23:07:44,284 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Disconnecting from master.hadoop port 22 2017-11-13 23:07:44,284 WARN org.apache.hadoop.ha.NodeFencer: Fencing method org.apache.hadoop.ha.SshFenceByTcpPort(null) was unsuccessful. 2017-11-13 23:07:44,284 ERROR org.apache.hadoop.ha.NodeFencer: Unable to fence service by any configured method. 2017-11-13 23:07:44,284 WARN org.apache.hadoop.ha.ActiveStandbyElector: Exception handling the winning of election java.lang.RuntimeException: Unable to fence NameNode at master.hadoop/192.168.14.49:8020 at org.apache.hadoop.ha.ZKFailoverController.doFence(ZKFailoverController.java:533) at org.apache.hadoop.ha.ZKFailoverController.fenceOldActive(ZKFailoverController.java:505) at org.apache.hadoop.ha.ZKFailoverController.access$1100(ZKFailoverController.java:61) at org.apache.hadoop.ha.ZKFailoverController$ElectorCallbacks.fenceOldActive(ZKFailoverController.java:892) at org.apache.hadoop.ha.ActiveStandbyElector.fenceOldActive(ActiveStandbyElector.java:921) at org.apache.hadoop.ha.ActiveStandbyElector.becomeActive(ActiveStandbyElector.java:820) at org.apache.hadoop.ha.ActiveStandbyElector.processResult(ActiveStandbyElector.java:418) at org.apache.zookeeper.ClientCnxn$EventThread.processEvent(ClientCnxn.java:599) at org.apache.zookeeper.ClientCnxn$EventThread.run(ClientCnxn.java:498) 2017-11-13 23:07:44,284 INFO org.apache.hadoop.ha.ActiveStandbyElector: Trying to re-establish ZK session
#当然可能还会有别的问题比如ssh权限问题啊等等,查看日志排查问题,这里列出了一个比较容易忽视的问题,我上面配置文件选择的是sshfence方法,是指通过ssh登陆到active namenode节点杀掉namenode进程。这里提示找不到fuser命令。
解决办法:
在master.hadoop和smaster.hadoop节点上面执行yum安装操作:
# yum -y install psmisc

#已经可以成功切换了。这时候你把master.hadoop的namenode节点启动起来,它也只能当备机了。
#当然也可以通过命令来获得节点的状态:
$ /home/hadoop/hadoop/bin/hdfs haadmin -getServiceState nn1
active
$ /home/hadoop/hadoop/bin/hdfs haadmin -getServiceState nn2
standby
#手工切换成主的方式:hdfs haadmin -transitionToActive nn1
新NameNode如何加入:
当有NameNode机器损坏时,必然存在新NameNode来替代。把配置修改成指向新NameNode,然后以备机形式启动新NameNode,这样新的NameNode即加入到Cluster中:
1) hdfs namenode -bootstrapStandby 2) hadoop-daemon.sh start namenode
2.6 HDFS操作测试:
$ hadoop fs -mkdir hdfs://192.168.14.49:8020/hatest
$ hadoop fs -put /opt/songs.access.log.lzo /hatest/
$ hadoop fs -ls hdfs://192.168.14.49:8020/hatest/ #因为现在192.168.14.49所以操作什么的都没问题
-rw-r--r-- 2 hadoop supergroup 5809589 2017-11-14 11:25 hdfs://192.168.14.49:8020/hatest/songs.access.log.lzo
$ hadoop fs -put /opt/master.zip hdfs://192.168.14.50:8020/hatest/ #下面是提示,因为是备节点,虽然有8020端口但是是不能提供访问的。
put: Operation category READ is not supported in state standby
#但是显然不能再这么用了啊,我们都做了HA,还用单namnoede的IP的形式,那台机器出问题了,你的HDFS操作也就GG了啊。
$ hadoop fs -put /opt/master.zip hdfs://mycluster/hatest/ #还记得前面配置文件里面指定了默认url嘛,hdfs://mycluster,使用这个后面到底是交给49的8020端口还是50的8020端口,你就不用管了。

#文件上传已经没问题了。
$ cd /home/hadoop/hadoop
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount hdfs://mycluster:8020/test2/lzotest.log hdfs://mycluster:8020/songs/logs/songs_tj_2017_11_14_1
17/11/14 16:43:57 INFO client.RMProxy: Connecting to ResourceManager at slave01.hadoop/192.168.14.51:8032 17/11/14 16:44:00 INFO input.FileInputFormat: Total input paths to process : 1 17/11/14 16:44:00 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 17/11/14 16:44:00 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev f1deea9a313f4017dd5323cb8bbb3732c1aaccc5] 17/11/14 16:44:02 INFO mapreduce.JobSubmitter: number of splits:32 17/11/14 16:44:04 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510648608692_0001 17/11/14 16:44:04 INFO impl.YarnClientImpl: Submitted application application_1510648608692_0001 17/11/14 16:44:04 INFO mapreduce.Job: The url to track the job: http://slave01.hadoop:8088/proxy/application_1510648608692_0001/ 17/11/14 16:44:04 INFO mapreduce.Job: Running job: job_1510648608692_0001 17/11/14 16:44:11 INFO mapreduce.Job: Job job_1510648608692_0001 running in uber mode : false 17/11/14 16:44:11 INFO mapreduce.Job: map 0% reduce 0% 17/11/14 16:44:27 INFO mapreduce.Job: map 4% reduce 0%

#从上图可以看出,两G的日志文件,切成了32份,32个map并行计算分析然后再汇总,也就用了几十秒。点开job那里能看到更详细的信息。
2.7 HA推荐配置及其他:
摘自链接:http://blog.csdn.net/dr_guo/article/details/50939537 最后一段,这篇博客做了很多测试可以看一看。
HA推荐配置:
ha.zookeeper.session-timeout.ms = 10000
#ZK心跳是2000,缺省的5000很容易因为网络拥塞或NN GC等导致误判,为避免电源闪断,不要把start-dfs.sh放在init.d里
dfs.ha.fencing.methods = shell(/path/to/the/script)
#STONITH (Shoot The Other Node In The Head)不一定可行,当没有网络或掉电的时候,是没法shoot的缺省的隔离手段是sshfence,在掉电情况下就无法成功完成,从而切换失败
唯一能保证不发生脑裂的方案就是确保原Active无法访问NFS通过script修改NFS上的iptables,禁止另一台NN访问管理员及时介入,恢复原Active,使其成为Standby。恢复iptables
客户端重试机制:
代码可在org.apache.hadoop.io.retry.RetryPolicies.FailoverOnNetworkExceptionRetry里找到。目前的客户端在遇到以下Exception时启动重试:
// 连接失败 ConnectException NoRouteToHostException UnKnownHostException // 连到了Standby而不是Active StandbyException
其重试时间间隔的计算公式为:
RAND(0.5~1.5) * min (2^retryies * baseMillis, maxMillis)
baseMillis = dfs.client.failover.sleep.base.millis,缺省500
maxMillis = dfs.client.failover.sleep.max.millis,缺省15000
最大重试次数:dfs.client.failover.max.attempts,缺省15
三、ResourceManager HA部署
上面的namenode的HA已经实现了,但是resourcemanager还没有做啊,因为resourcemanager基本很少出现挂了的情况,而且线上resourcemanager挂掉了影响也没有namenode影响那么大,所以也并不一定非要做。下面来做一下:
修改配置文件:
$ vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> <!-- 指定RM的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定RM的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>slave01.hadoop</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>slave02.hadoop</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>57344</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>57344</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>20</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>slave04.hadoop:2181,slave05.hadoop:2181,slave06.hadoop:2181</value> </property> </configuration>
#然后把此配置文件同步到集群其他节点的目录下面
启动服务:
$ /home/hadoop/hadoop/sbin/stop-yarn.sh #重启yarn服务
$ /home/hadoop/hadoop/sbin/start-yarn.sh
$ yarn-daemon.sh start resourcemanager #在slave2.hadoop上面单独执行,启动服务
[hadoop@slave02 ~]$ jps
2905 ResourceManager 2235 DataNode 3311 Jps 2655 NodeManager

#查看zk的信息,发现上面有有类似于namenode的节点信息。
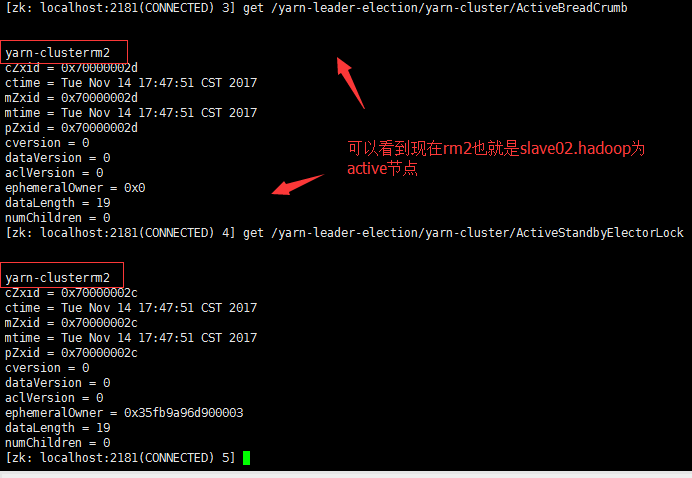
#用xshell工具查看啊,用CRT乱码
切换测试:
$ yarn rmadmin -getServiceState rm1 #获取rm1节点的状态
$ yarn rmadmin -getServiceState rm2 #获取rm2节点的状态

$ yarn rmadmin -transitionToStandby rm2 --forcemanual #让rm2转为备用节点

#这样两个都是备用节点了
$ yarn rmadmin -transitionToActive rm1 --forcemanual #让rm1成为active节点,--forcemanual就是强制转换的意思

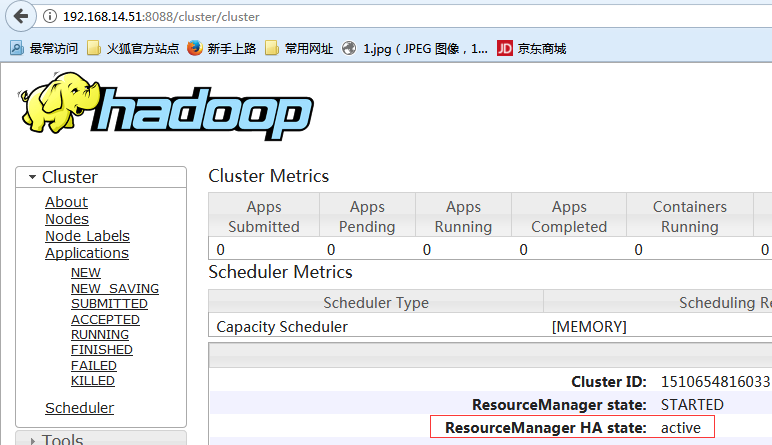
#可以看出slave01.hadoop的8088端口是可以查看的,要注意的是slave02.hadoop的8088端口虽然是启用状态,但是现在连接是无效的。
$ yarn-daemon.sh stop resourcemanager #手工关闭slave01.hadoop上面的 resourcemanager服务
#我擦 你会发现等待了半天HA并没有自动切换,是因为我们上面手工指定了让rm2作为备用的操作的影响。
$ yarn rmadmin -transitionToActive rm2 --forcemanual #改回来,再重新测试一波

#再来手工的关闭一个节点的resourcemanager 服务,发现已经可以正常的自动切换了。现在slave01.hadoop启动也是白扯的,因为zk那里已经锁定了,只能等slave02.hadoop的resourcemanager服务死掉才能再切回active状态。
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount hdfs://mycluster:8020/test2/lzotest.log hdfs://mycluster:8020/songs/logs/songs_tj_2017_11_14_18 #再处理波日志
17/11/14 18:34:35 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2 #默认先找rm1 然后失败了又去找了rm2 17/11/14 18:34:37 INFO input.FileInputFormat: Total input paths to process : 1 17/11/14 18:34:37 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 17/11/14 18:34:37 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev f1deea9a313f4017dd5323cb8bbb3732c1aaccc5] 17/11/14 18:34:37 INFO mapreduce.JobSubmitter: number of splits:32 17/11/14 18:34:38 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510655528064_0001 17/11/14 18:34:38 INFO impl.YarnClientImpl: Submitted application application_1510655528064_0001 17/11/14 18:34:38 INFO mapreduce.Job: The url to track : http://slave02.hadoop:8088/proxy/application_1510655528064_0001/ 17/11/14 18:34:38 INFO mapreduce.Job: Running job: job_1510655528064_0001 17/11/14 18:34:45 INFO mapreduce.Job: Job job_1510655528064_0001 running in uber mode : false 17/11/14 18:34:45 INFO mapreduce.Job: map 0% reduce 0% 17/11/14 18:35:02 INFO mapreduce.Job: map 2% reduce 0% 17/11/14 18:35:03 INFO mapreduce.Job: map 13% reduce 0%
#在上面的执行过程中在rm2(当然同时它也是datanode节点)上面查看一下:
$ jps
12832 YarnChild 12706 YarnChild 5155 NodeManager 12711 YarnChild 13927 Jps 12807 YarnChild 12808 YarnChild 12522 YarnChild 12780 YarnChild 12397 YarnChild 12429 YarnChild 4529 JournalNode 9361 JobHistoryServer 4402 DataNode 12375 YarnChild 12824 YarnChild 12508 YarnChild 12093 RunJar 12319 YarnChild 12287 YarnChild
#在另外一台datanode节点上面查看一下:
$ jps
2402 YarnChild 2115 YarnChild 1955 YarnChild 1542 MRAppMaster 3654 Jps 2279 YarnChild 2281 YarnChild 2186 YarnChild 2347 YarnChild 1933 YarnChild 2253 YarnChild 2287 YarnChild 1232 NodeManager 2256 YarnChild 2034 YarnChild 947 DataNode 2292 YarnChild 2297 YarnChild 1977 YarnChild 2077 YarnChild 2237 YarnChild 2078 YarnChild 2015 YarnChild
#hadoop集群中主要进程有 master: NameNode, ResourceManager, slaves: DataNode, NodeManager, RunJar, MRAppMaster,YarnChild 其中RunJar,MRAppMaster,YarnChild与随着某个job的创建而创建,随着job的完成而终止。它们的作用分别是: RunJar:完成job的初始化,包括获取jobID,将jar包上传至hdfs等。 MRAppMaster:每个job一个进程,主要跟踪job的运行情况,向RM申请资源等。 YarnChild:运行具体的map/reduce task。 #job启动过程: ResourceManage,NodeManager->RunJar->MRAppMaster->YarnChild #job退出过程: YarnChild->MRAppMaster->RunJar 即所有的map/reduce均完成后,MRAppMaster才退出,最后RunJar退出,job完成。
#MRAppMaster剖析:http://blog.csdn.net/zhangzhebjut/article/details/37742491utm_source=tuicool&utm_medium=referral
#测试也是OK的成功了。至此Hadoop的HA部署操作完毕。
还有两篇博客总结了点东西:
http://database.51cto.com/art/201710/555048.htm
http://blog.csdn.net/liu812769634/article/details/53097268
