大数据(十)学习kafka集群部署
一、kafka介绍
1.1 kafka是什么?
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
流媒体平台具有三个关键功能:
它可以让你发布和订阅记录流。 在这方面,它类似于消息队列或企业消息传递系统。 它允许您以容错方式存储记录流。 它可以让你处理记录发生的流。
kafka被用于两大类的应用程序:
构建可在系统或应用程序之间可靠获取数据的实时流数据管道 构建实时流应用程序,可以转换或响应数据流
kafka的几个概念:
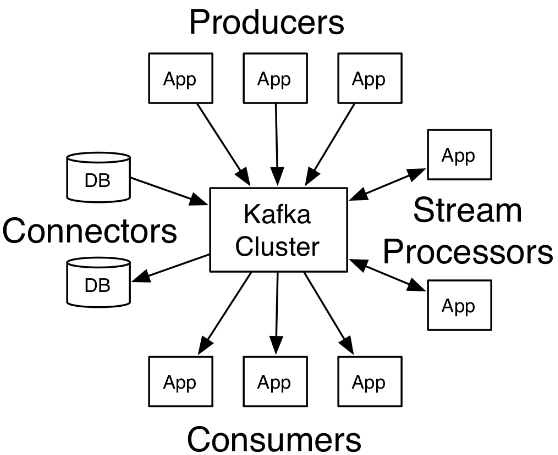
Kafka作为一个或多个服务器上的集群运行。 Kafka集群以称为主题的类别存储记录流。 每个记录由一个键,一个值和一个时间戳组成。
kafaka的四个核心API:
![]()
Producer API #允许应用程序将一组记录发布到一个或多个Kafka主题。 Consumer API #允许应用程序订阅一个或多个主题并处理产生给他们的记录流。 Streams API #允许应用程序充当流处理器,从一个或多个主题中消费输入流,并将输出流生成为一个或多个输出主题,从而将输入流有效地转换为输出流。 Connector API #允许构建和运行可重复使用的生产者或消费者,将Kafka主题连接到现有的应用程序或数据系统。 例如,连接到关系数据库的连接器可能会捕获对表的每个更改。
#在Kafka中,客户端和服务器之间的通信是通过一个简单的,高性能的,与语言无关的TCP协议完成的。 这个协议是版本化的,并保持与旧版本的向后兼容性。 虽然为为Kafka提供了一个Java客户端,但客户端可以使用多种语言(https://cwiki.apache.org/confluence/display/KAFKA/Clients)。
1.2 Kafka消息队列简介
基本术语:
Broker #Kafka集群包含一个或多个服务器,这种服务器被称为broker Topic #每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处) Partition #Partition是物理上的概念,每个Topic包含一个或多个Partition.(一般为kafka节点数cpu的总核数) Producer #负责发布消息到Kafka broker Consumer #消息消费者,向Kafka broker读取消息的客户端。 Consumer Group #每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
基本特性:
可扩展:
在不需要下线的情况下进行扩容 数据流分区(partition)存储在多个机器上
高性能:
单个broker就能服务上千客户端 单个broker每秒种读/写可达每秒几百兆字节 多个brokers组成的集群将达到非常强的吞吐能力 性能稳定,无论数据多大 Kafka在底层摒弃了Java堆缓存机制,采用了操作系统级别的页缓存,同时将随机写操作改为顺序写,再结合Zero-Copy的特性极大地改善了IO性能。
持久存储:
存储在磁盘上 冗余备份到其他服务器上以防止丢失
消息格式:
一个topic对应一种消息格式,因此消息用topic分类
一个topic代表的消息有1个或者多个patition(s)组成
一个partition应该存放在一到多个server上。
如果只有一个server,就没有冗余备份,是单机而不是集群 如果有多个server,一个server为leader,其他servers为followers;leader需要接受读写请求;followers仅作冗余备份;leader出现故障,会自动选举一个follower作为leader,保证服务不中断;每个server都可能扮演一些partitions的leader和其它partitions的follower角色,这样整个集群就会达到负载均衡的效果 #另外 消息按顺序存放,顺序不可变 只能追加消息,不能插入 每个消息都有一个offset,用作消息ID, 在一个partition中唯一 offset有consumer保存和管理,因此读取顺序实际上是完全有consumer决定的,不一定是线性的 消息有超时日期,过期则删除
Topics and Logs:
topic是记录发布到的类别或feed名称。 kafka的topic总是多用户的; 也就是说,一个topic可以有零个,一个或多个订阅写入数据的消费者。
对于每个topic,Kafka集群维护一个分区日志,如下所示:
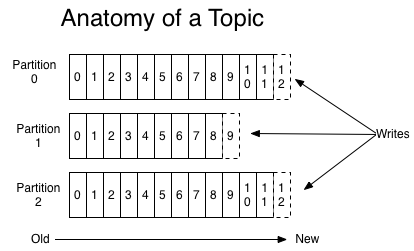
每个分区是一个有序的,不可变的记录序列,不断追加到结构化的提交日志中。 分区中的记录每个分配一个连续的id号,称为偏移量,用于唯一标识分区内的每条记录。
Kafka集群使用可配置的保留期限来保留所有已发布的记录(无论是否已被使用)。 例如,如果保留策略设置为两天,则在记录发布后的两天内,保留策略可供使用,之后将被丢弃以腾出空间。 kafka的性能在数据大小方面是有效的,所以长时间存储数据不成问题。
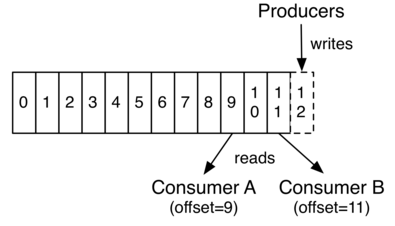
实际上,以消费者为单位保留的唯一元数据是消费者在日志中的偏移或位置。这个偏移量是由消费者控制的:消费者通常会在读取记录时线性地推进其偏移量,但事实上,由于消费者的位置是由消费者控制的,所以它可以以任何喜欢的顺序消费记录。例如,消费者可以重置为较旧的偏移量以重新处理来自过去的数据,或者跳至最近的记录并从“now”开始消费。
这些功能的组合意味着kafla的消费者非常cheap --他们可以来来去去,对集群或其他消费者没有太大的影响。例如,可以使用命令行工具来“tail”任何主题的内容,而不会更改任何现有使用者使用的内容。
日志中的分区有几个用途。首先,它们允许日志的大小超出适合单个服务器的大小。每个单独的分区必须适合托管它的服务器,但是一个主题可能有许多分区,因此它可以处理任意数量的数据。其次,它们作为并行的单位-更多的是在一点上。
Distribution(分布):
日志的分区分布在Kafka集群中的服务器上,每个服务器处理数据并请求共享分区。 每个分区都通过可配置数量的服务器进行复制,以实现容错。
每个分区有一个服务器充当“领导者”,零个或多个服务器充当“追随者”。 领导处理分区的所有读取和写入请求,而追随者被动地复制领导。 如果领导失败,其中一个追随者将自动成为新领导。 每个服务器充当其中一些分区的领导者和其他人的追随者,因此负载在集群内平衡良好。
Producers(生产者):
生产者发布数据到他们选择的topic。 生产者负责选择哪个记录分配给主题内的哪个分区。 这可以以循环的方式完成,只是为了平衡负载,或者可以根据某些语义分区功能(例如基于记录中的某个键)来完成。
Consumers(消费者):
消费者用消费者组名称标记自己,并且发布到主题的每个记录被传递到每个订阅消费者组中的一个消费者实例。 消费者实例可以在不同的进程中或在不同的机器上。
如果所有消费者实例具有相同的消费者组,则记录将有效地在消费者实例上负载平衡。
如果所有消费者实例具有不同的消费者组,则每个记录将被广播给所有消费者进程。
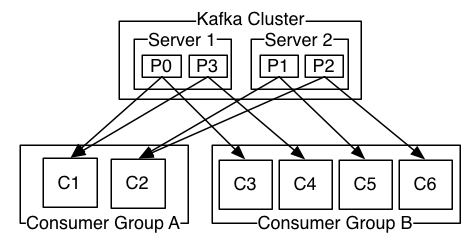
两个服务器Kafka集群托管四个分区(P0-P3)与两个消费者组。消费者组A有两个消费者实例,而组B有四个消费者实例。
然而,更普遍的是,话题中有少量消费群体,每个“逻辑用户”都有一个消费群体。每个组由许多消费者实例组成,具有可扩展性和容错性。这不过是发布 - 订阅语义,订阅者是一群消费者而不是一个进程。
在Kafka中实现消费的方式是将日志中的分区划分为消费者实例,以便每个实例在任何时间点都是“公平分享”分区的唯一消费者。这个维护组中成员资格的过程是由Kafka协议动态地处理的。如果新实例加入组,他们将接管来自组中其他成员的一些分区;如果一个实例死亡,其分区将分配给其余的实例。
kafka只提供一个分区内记录的总顺序,而不是主题中不同分区之间的顺序。每个分区排序与按键分区数据的能力相结合,足以满足大多数应用程序的需求。但是,如果需要全部订单而不是记录,则可以通过仅具有一个分区的主题来实现,但这意味着每个消费者组只有一个消费者进程。
Guarantees
在一个高层次的kafka提供以下保证:
由制作者发送到特定主题分区的消息将按照它们发送的顺序附加。 也就是说,如果记录M1由同一个生产者作为记录M2发送,并且M1被首先发送,则M1将具有比M2更低的偏移并且出现在日志中的更早。
消费者实例按照存储在日志中的顺序查看记录。
对于具有复制因子N的主题,我们将容忍多达N-1个服务器故障,而不会丢失任何提交给日志的记录。
博文来自:www.51niux.com
1.3 Kafka与常见消息队列的对比
RabbitMQ:
Erlang编写 支持很多的协议:AMQP,XMPP, SMTP, STOMP 非常重量级,更适合于企业级的开发 发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。
Redis:
基于Key-Value对的NoSQL数据库 入队时,当数据比较小时Redis的性能要高于RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受; 出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ的出队性能则远低于Redis。
ZeroMQ:
号称最快的消息队列系统,尤其针对大吞吐量的需求场景。 高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战。 具有一个独特的非中间件的模式,不需要安装和运行一个消息服务器或中间件 ZeroMQ仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。
ActiveMQ:
类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。 类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
Kafka/Jafka:
高性能跨语言分布式发布/订阅消息队列系统 快速持久化,可以在O(1)的系统开销下进行消息持久化; 高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率; 完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡; 支持Hadoop数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行加载机制统一了在线和离线的消息处理。 一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。
1.4 kafka可以做的系统
kafka作为消息系统
kafka的流概念如何与传统的企业消息传递系统相比较?
消息传统上有两种模式:队列和发布 - 订阅。在一个队列中,消费者池可以从服务器读取并且每个记录到达其中的一个;在发布 - 订阅记录被广播给所有消费者。这两种模式都有其优点和缺点。队列的优势在于它允许您将数据处理划分为多个消费者实例,这样可以扩展处理。不幸的是,队列不是多用户的,一旦一个进程读取数据就消失了。发布 - 订阅允许您将数据广播到多个进程,但无法进行扩展处理,因为每条消息都发送给每个订阅者。
kafka的消费群体概念概括了这两个概念。与队列一样,消费者组允许您将一系列流程(消费者组的成员)的处理分开。与发布 - 订阅一样,Kafka允许您向多个消费者群体广播消息。
Kafka模型的优点是每个主题都具有这些属性 - 它可以扩展处理,也可以是多用户 - 不需要选择其中一个。
Kafka也比传统的消息系统有更强的指令保证。
传统队列在服务器上按顺序保留记录,并且如果多个使用者从队列中消耗,则服务器按照它们存储的顺序来提交记录。但是,虽然服务器按顺序提交记录,但是记录是异步传递给消费者的,所以它们可能会针对不同的消费者而出现故障。这实际上意味着记录的排序在并行消耗的情况下丢失。消息传递系统通常具有“排他消费者”的概念,只允许一个进程从队列中消耗,但这当然意味着在处理中没有并行性。
kafaka做得更好。通过在主题内部有一个并行的概念 - 分区,Kafka能够提供ordering保证和负载平衡。这是通过将主题中的分区分配给使用者组中的使用者来实现的,以便每个分区仅由组中的一个使用者使用。通过这样做,我们确保消费者是该分区的唯一读者,并按顺序使用这些数据。由于有很多分区,这仍然可以平衡许多消费者实例的负载。但请注意,消费群组中的消费者实例不能多于分区。
kafka作为存储系统
任何允许将消息发布出去的消息队列都可以充当存储系统。 Kafka的不同之处在于它是一个非常好的存储系统。
写入Kafka的数据写入磁盘并进行复制以实现容错。 Kafka允许生产者等待确认,以便在完全复制之前写入不被认为是完整的,并且即使写入的服务器失败也能保证持续。
Kafka的磁盘结构使用了很好的规模 - 无论您在服务器上有50 KB还是50 TB的持久性数据,Kafka都会执行相同的操作。
由于认真考虑存储并允许客户端控制其读取位置,所以可以将Kafka视为专用于高性能,低延迟提交日志存储,复制和传播的专用分布式文件系统。
kafka的流处理
只读取,写入和存储数据流是不够的,目的是启用流的实时处理。
在Kafka中,流处理器是指从输入主题获取连续数据流,对该输入执行一些处理,并产生连续数据流以输出主题的任何东西。
例如,零售应用程序可能会接受销售和发货的输入流,并输出一系列重新排序和对这些数据进行计算的价格调整。
直接使用生产者和消费者API可以做简单的处理。但是对于更复杂的转换,Kafka提供了一个完全集成的Streams API。这允许构建应用程序进行非平凡的处理,从而计算聚合关闭流或将流连接在一起。
这个工具有助于解决这类应用程序面临的难题:处理乱序数据,重新处理代码更改的输入,执行有状态的计算等等。
流API基于Kafka提供的核心原语构建:它使用生产者和消费者API进行输入,使用Kafka进行有状态存储,并在流处理器实例之间使用相同的组机制来实现容错。
合到一起
消息传递,存储和流处理的这种组合可能看起来很不寻常,但对于Kafka作为一个流媒体平台来说,这是非常重要的。
像HDFS这样的分布式文件系统允许存储用于批处理的静态文件。有效地,这样的系统允许存储和处理过去的历史数据。
传统的企业消息传递系统允许处理将来订阅的消息。以这种方式构建的应用程序在到达时处理将来的数据。
Kafka结合了这两种功能,而且这两种组合对于Kafka用作流媒体应用平台和流式数据流水线都是至关重要的。
通过将存储和低延迟订阅相结合,流式应用程序可以同样的方式处理过去和未来的数据。这是一个单一的应用程序可以处理历史,存储的数据,而不是结束,当它达到最后一个记录,它可以继续处理未来的数据到达。这是流处理的概括概念,包括批处理以及消息驱动的应用程序。
同样,对于流式传输数据流水线,订阅实时事件的组合使得可以将Kafka用于非常低延迟的流水线;但是可靠地存储数据的能力可以将其用于必须保证数据交付的关键数据,或者与只能定期加载数据的离线系统集成,或者可能长时间停机进行维护。流处理设施可以在数据到达时进行转换。
1.5 kafka用例
Messaging(消息系统):
kafka可以很好地替代传统的信息系统。 消息代理被用于各种原因(将数据处理与数据生成器分离,缓冲未处理的消息等)。 与大多数消息系统相比,Kafka具有更好的吞吐量,内置的分区,复制和容错能力,使其成为大型消息处理应用的理想解决方案。 根据我们的经验,消息传递的使用往往是相对较低的吞吐量,但可能需要较低的端到端延迟,并且通常取决于Kafka提供的强大的持久性保证。 在这个领域,Kafka与传统的消息系统(如ActiveMQ或RabbitMQ)相当。
ActiveMQ官网:http://activemq.apache.org/
RabbitMQ官网:http://activemq.apache.org/
Website Activity Tracking(网站活动跟踪):
Kafka的原始用例是能够将用户活动跟踪管道重建为一组实时发布 - 订阅订阅源。 这意味着网站活动(用户可能采用的网页浏览量,搜索或其他操作)将发布到每个活动类型一个主题的中心主题。 这些订阅源可用于订阅各种用例,包括实时处理,实时监控,加载到Hadoop或离线数据仓库系统以进行离线处理和报告。 活动跟踪通常是非常高的量,因为为每个用户页面视图生成许多活动消息。
Metrics(指标):
kafka通常用于运行监控数据。 这涉及从分布式应用程序汇总统计数据以生成操作数据的集中式源。
Log Aggregation(日志聚合):
许多人使用Kafka作为日志聚合解决方案的替代品。 日志聚合通常从服务器收集物理日志文件,并将其置于中央位置(可能是文件服务器或HDFS)进行处理。 Kafka提取文件的细节,并将日志或事件数据作为消息流进行更清晰的抽象。 这样可以实现更低延迟的处理,并且更容易支持多个数据源和分布式数据消耗。 与Scribe或Flume等以日志为中心的系统相比,Kafka提供了同样好的性能,由于复制而提供了更强的耐久性保证,并且端到端的延迟更低。
Stream Processing(流处理):
Kafka的许多用户在处理管道中处理数据,这些数据由多个阶段组成,其中原始输入数据从Kafka主题中消耗,然后聚合,丰富或以其他方式转化为新的主题,以供进一步消费或后续处理。 例如,用于推荐新闻文章的处理流水线可以从RSS提要抓取文章内容并将其发布到“文章”主题; 进一步的处理可以对这个内容进行标准化或者重复删除,并且将已清理的文章内容发布到新的主题; 最终处理阶段可能会尝试将这些内容推荐给用户。 这种处理流水线基于各个主题创建实时数据流的图表。 从0.10.0.0开始,在Apache Kafka中可以使用称为Kafka Streams的轻量但功能强大的流处理库执行如上所述的数据处理。 除了Kafka Streams之外,替代性的开源流处理工具还包括Apache Storm和Apache Samza。
Kakka streams API官网:http://kafka.apache.org/documentation/streams/
Apache Strom官网介绍:https://storm.apache.org/
Apache Samza官网介绍:http://samza.apache.org/
Event Sourcing(事件逆源):
事件溯源是一种应用设计模式,在这类应用中状态改变会被记录为一系列按时间排序的日志记录。Kafka支持非常大量的日志数据,因此非常适合做这种类型应用的后端。
Commit Log(提交日志):
Kafka可以作为分布式系统的一种外部提交日志。 日志有助于复制节点之间的数据,并作为失败节点恢复数据的重新同步机制。 Kafka中的日志压缩功能有助于支持这种用法。 在这个用法中,Kafka与Apache BookKeeper项目类似。
Apache BookKeeper官网:http://bookkeeper.apache.org/index.html
二、跟着官网快速入门搭建一下
2.1 kafka的安装
安装
# wget http://mirrors.hust.edu.cn/apache/kafka/1.0.0/kafka_2.11-1.0.0.tgz
# tar zxf kafka_2.11-1.0.0.tgz -C /home/hadoop/
配置(192.168.14.51上面的配置)
#Kafka使用ZooKeeper,因此如果您还没有ZooKeeper服务器,则需要先启动ZooKeeper服务器。 您可以使用与kafka一起打包的便捷脚本来获得一个快速而简单的单节点ZooKeeper实例。zookeeper集群我们还是使用前面搭建好的那个zookeeper集群。
# cd /home/hadoop/kafka_2.11-1.0.0/
# vim /home/hadoop/kafka_2.11-1.0.0/config/server.properties #修改kafka的配置文件
broker.id=1 #当前机器在集群中的唯一标识,如果是第一台就设置1,第二台就设置为2,后面的以此类推。 listeners=PLAINTEXT://192.168.14.51:9092 #注意绑定host.name,否则可能出现莫名其妙的错误如consumer找不到broker。这个host.name是Kafka的server的机器名字,会注册到Zookeeper中 log.dirs=/home/hadoop/kafka/kafkalogs/ #kafka数据的存放地址,多个地址的话用逗号分割,多个目录分布在不同磁盘上可以提高读写性能 log.retention.hours=72 #日志保存时间为3天 log.segment.bytes=1073741824 #个日志文件的最大的大小,这里为1GB zookeeper.connect=192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 #设置zookeeper的连接端口
#详细配置参数解释查看官网:http://kafka.apache.org/documentation/#configuration
#将/home/hadoop/kafka_2.11-1.0.0发送给192.168.14.52和192.168.14.52
#192.168.14.52配置文件中修改:broker.id=2 和 listeners=PLAINTEXT://192.168.14.52:9092
#192.168.14.53配置文件中修改:broker.id=3 和 listeners=PLAINTEXT://192.168.14.53:9092
做软连接并启动服务(三台机器都做):
# ln -s /home/hadoop/kafka_2.11-1.0.0 /home/hadoop/kafka
# mkdir /home/hadoop/kafka/kafkalogs
# chown -R hadoop:hadoop /home/hadoop/kafka_2.11-1.0.0
# /home/hadoop/kafka/bin/kafka-server-start.sh -daemon /home/hadoop/kafka/config/server.properties #启动kafka服务
查看并测试:
# jps #多了Kafka进程
28819 Kafka
# ps -aux|grep server.properties #进程输出比较多只粘贴部分内容
hadoop 23899 38.3 1.9 7229368 328096 pts/0 Sl 16:23 0:04 /usr/java/jdk/bin/java -Xmx1G -Xms1G -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true -Xloggc:/home/hadoop/kafka/ ...... in/../libs/validation-api-1.1.0.Final.jar:/home/hadoop/kafka/bin/../libs/zkclient-0.10.jar:/home/hadoop/kafka/bin/../libs/zookeeper-3.4.10.jar kafka.Kafka /home/hadoop/kafka/config/server.properties
# netstat -lntup|grep :9092 #端口启用状态
tcp6 0 0 192.168.14.51:9092 :::* LISTEN 28819/java
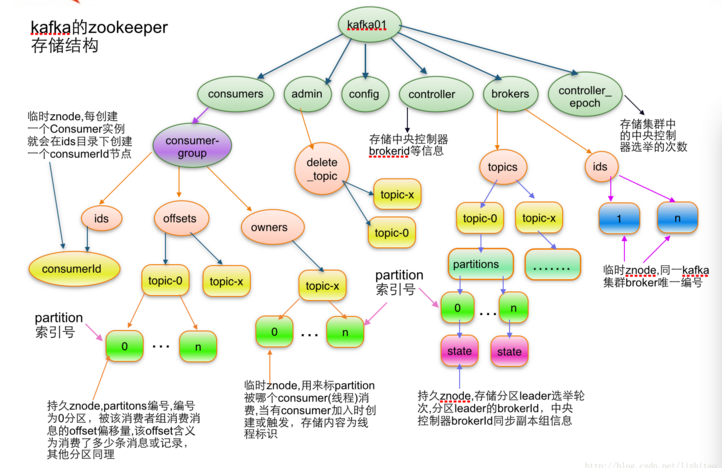
#此图来自:http://blog.csdn.net/lizhitao/article/details/23744675
[zk: localhost:2181(CONNECTED) 5] ls /brokers/ids/ #启动zk客户端,查看broker的列表
1 2 3
博文来自:www.51niux.com
2.2 测试消息的收发
创建一个 topic:
# cd /home/hadoop/kafka
# bin/kafka-topics.sh --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --topic mytopic --replication-factor 3 --partitions 1 --create #下面是消息提示
Created topic "mytopic".
#--create #创建
#--zookeeper #连接的zookeeper
#--replication-factor 3 #复制因子,备份数,类似于hadoop的冗余策略
#partitions 1 #为topic分配多少个parition
#--topic mytopic #主题的名字
查看topic列表:
# bin/kafka-topics.sh --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --list
mytopic
#此时也可以在zk上面查看:
[zk: localhost:2181(CONNECTED) 3] ls /brokers/topics
[mytopic]
生产者和消费者测试:
#在192.168.14.51上面执行下面的操作(开始发消息):
# bin/kafka-console-producer.sh --broker-list 192.168.14.51:9092,192.168.14.52:9092,192.168.14.53:9092 --topic mytopic #下面就是要发送的消息
>hai laoxiong >zailai yitiao
在192.168.14.52上面执行下面操作(开始收消息):
# bin/kafka-console-consumer.sh --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --topic mytopic
hai laoxiong zailai yitiao
#51是实时发送,52是实时接收。
注意:如果kafka是新版本消费命令就要变了,因为--zookeeper参数已经弃用掉了,改成下面的方式了:#bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.51:9092,192.168.14.52:9092,192.168.14.53:9092 --topic mytopic
# bin/kafka-topics.sh --describe --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --topic mytopic #可以查看topic的详细信息。
Topic:mytopic PartitionCount:1 ReplicationFactor:3 Configs: Topic: testtopic Partition: 0 Leader: 2 Replicas: 1,2,3 Isr: 2,3,1 #“leader”是负责给定分区的所有读取和写入的节点。 每个节点将成为分区随机选择部分的领导者。 #“replica”是复制此分区日志的节点列表,无论它们是否是领导者,或者即使他们当前处于活动状态。 #“isr”是一组“同步”副本。 这是复制品列表的子集,当前活着并被引导到领导者。
#做个测试,可以看到现在的Leader节点是ID为2的机器,也就是192.168.14.52
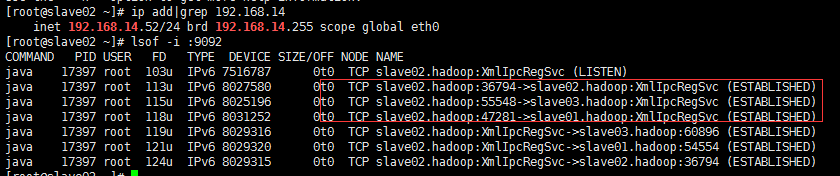
#从上图可以看到另外两个节点都会跟leader节点192.168.14.52的9092端口建立长连接
#然后现在手工的将192.168.14.52的kafka服务关闭掉。# /home/hadoop/kafka/bin/kafka-server-stop.sh #再次进行查看
# bin/kafka-topics.sh --describe --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --topic mytopic
Topic:mytopic PartitionCount:1 ReplicationFactor:3 Configs: Topic: testtopic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 3,1

#从上面的结果和上图可以看到现在Leader节点变成了1也就是192.168.14.51。也可以通过Lsr那里可以看到2节点不存在了。
# bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.51:9092,192.168.14.52:9092,192.168.14.53:9092 --from-beginning --topic mytopic #查看mytopic里面发送过的消息
Hello World I am chaishaoshao zaima hai laoxiong zailai yitiao ^CProcessed a total of 6 messages #CTRL+C退出
2.3 使用Kafka Connect来导入/导出数据
从控制台写入数据并将其写回控制台是一个方便的起点,但可能想要使用其他来源的数据或将数据从Kafka导出到其他系统。 对于许多系统,可以使用Kafka Connect来导入或导出数据,而不必编写自定义集成代码。
Kafka Connect是Kafka包含的一个工具,可以将数据导入和导出到Kafka。 它是一个可扩展的工具,运行连接器,实现与外部系统交互的自定义逻辑。 在这个快速入门中,我们将看到如何使用简单的连接器运行Kafka Connect,这些连接器将数据从文件导入到Kafka主题,并将数据从Kafka主题导出到文件。
#通俗点啥这就是在模拟日志收集
首先,我们将通过创建一些种子数据开始测试:
$ echo -e "foo\nbar" > /home/hadoop/kafka/test.txt
$ cat /home/hadoop/kafka/test.txt
foo bar
$bin/kafka-topics.sh --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --topic connect-test --replication-factor 3 --partitions 1 --create
$ bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties #下面是最后的信息,没有WARN没有ERROR,只要你不停止就会一直往下刷,这是在干嘛,这是在等待信息的继续写入。
[2017-11-27 17:30:30,259] INFO WorkerSourceTask{id=local-file-source-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:323)
[2017-11-27 17:30:40,259] INFO WorkerSourceTask{id=local-file-source-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask:306)
[2017-11-27 17:30:40,259] INFO WorkerSourceTask{id=local-file-source-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:323)
[2017-11-27 17:30:50,260] INFO WorkerSourceTask{id=local-file-source-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask:306)
[2017-11-27 17:30:50,260] INFO WorkerSourceTask{id=local-file-source-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:323)
[2017-11-27 17:31:00,261] INFO WorkerSourceTask{id=local-file-source-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask:306)
[2017-11-27 17:31:00,262] INFO WorkerSourceTask{id=local-file-source-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:323)
[2017-11-27 17:31:10,263] INFO WorkerSourceTask{id=local-file-source-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask:306)
[2017-11-27 17:31:10,264] INFO WorkerSourceTask{id=local-file-source-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:323)
[2017-11-27 17:31:20,264] INFO WorkerSourceTask{id=local-file-source-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask:306)
[2017-11-27 17:31:20,265] INFO WorkerSourceTask{id=local-file-source-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:323)
[2017-11-27 17:31:30,265] INFO WorkerSourceTask{id=local-file-source-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask:306)
[2017-11-27 17:31:30,266] INFO WorkerSourceTask{id=local-file-source-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:323)# cat /home/hadoop/kafka/test.sink.txt #可以看到已经从/home/hadoop/kafka/test.txt将信息读出来写入到了/home/hadoop/kafka/test.sink.txt文件
foo bar
# echo "haha\n zaiciceshi" >>/home/hadoop/kafka/test.txt #再次插入数据
#另一个窗口可以看到数据日志输出发送了变化,offset的偏移量发生了改变,又采集到了数据
[2017-11-27 17:34:10,173] INFO WorkerSinkTask{id=local-file-sink-0} Committing offsets asynchronously using sequence number 92: {connect-test-0=OffsetAndMetadata{offset=3, metadata=''}} (org.apache.kafka.connect.runtime.WorkerSinkTask:311)
[2017-11-27 17:34:10,284] INFO WorkerSourceTask{id=local-file-source-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask:306)# cat /home/hadoop/kafka/test.sink.txt #再次查看这个日志收集文件,文件内容已经发生了变化,新写入的文件同步过来了
foo bar haha\n zaiciceshi
$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.53:9092 --topic connect-test --from-beginning #查看推送到topic connect-test的数据
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
{"schema":{"type":"string","optional":false},"payload":"haha\\n zaiciceshi"}分析下这个过程:
$ bin/connect-standalone.sh config/connect-standalone.properties
config/connect-file-source.properties
config/connect-file-sink.properties
#创建两个连接器:第一个是源连接器,用于从输入文件中读取行,并将每个连接生成为Kafka主题,第二个为连接器连接器 它从Kafka主题读取消息,并在输出文件中产生每行消息。
#在启动过程中,您会看到一些日志消息,其中一些指示连接器正在实例化。 一旦Kafka Connect过程开始,源连接器应该从test.txt开始读取行并将它们生成到主题connect-test,并且接收器连接器应该开始从主题connect-test读取消息并将它们写入文件test.sink.txt。
查看下几个配置文件:
$ cat config/connect-standalone.properties |grep -v "^#"
bootstrap.servers=192.168.14.53:9092 #我这里稍微做了下改变,因为默认是localhost:9092,因为我这里做了集群,这里应该是leader节点的IP,因为只有leader节点才能写 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true internal.key.converter=org.apache.kafka.connect.json.JsonConverter internal.value.converter=org.apache.kafka.connect.json.JsonConverter internal.key.converter.schemas.enable=false internal.value.converter.schemas.enable=false offset.storage.file.filename=/tmp/connect.offsets #topic的偏移量存储在/tmp/connect.offsets这个文件中,每次connect启动的时候会根据connector的name获得topic偏移量,然后在继续读取或者写入数据 offset.flush.interval.ms=10000
#注意,如果bootstrap.servers设置的不是leader节点,启动的时候会有下面的报错,也就是成功不了:
[2017-11-27 17:09:06,126] ERROR WorkerSourceTask{id=local-file-source-0} Failed to flush, timed out while waiting for producer to flush outstanding 1 messages (org.apache.kafka.connect.runtime.WorkerSourceTask:328)
[2017-11-27 17:09:06,127] ERROR WorkerSourceTask{id=local-file-source-0} Failed to commit offsets (org.apache.kafka.connect.runtime.SourceTaskOffsetCommitter:111)$ cat config/connect-file-source.properties |grep -v "^#"
name=local-file-source connector.class=FileStreamSource tasks.max=1 file=test.txt #可以看到取的默认是当前目录下的test.txt里面的内容,这也就是监听的数据文件,如果发送变化就会写入到下方的topic中 topic=connect-test #选择的topic是connect-test,也就是把test.txt里面的内容写入到topic connect-test中。
$ cat config/connect-file-sink.properties |grep -v "^#"
name=local-file-sink connector.class=FileStreamSink tasks.max=1 file=test.sink.txt #将topic connect-test的数据保存到此文件 topics=connect-test
2.4 使用Kafka Streams 来处理数据(忽略这块就是翻译一下官网)
Kafka Streams是用于构建关键任务实时应用程序和微服务的客户端库,输入和/或输出数据存储在Kafka集群中。 Kafka Streams结合了在客户端编写和部署标准Java和Scala应用程序的简单性以及Kafka服务器端集群技术的优势,使这些应用程序具有高度可伸缩性,弹性,容错性,分布式等特性。
官网文档:http://kafka.apache.org/10/documentation/streams/quickstart
#这个前提是zookeeper集群启动了,kafka启动了。
准备输入主题并启动Kafka producer:
接下来,我们创建名为streams-plaintext-input的输入主题和名为streams-wordcount-output的输出主题:
$ bin/kafka-topics.sh --create --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --replication-factor 3 --partitions 1 --topic streams-plaintext-input #下面为输出结果
Created topic "streams-plaintext-input".
注意:因为输出流是一个更改日志流(请参考下面的应用程序输出),所以我们创建了压缩启用的输出主题:
$ bin/kafka-topics.sh --create --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --replication-factor 3 --partitions 1 --topic streams-wordcount-output --config cleanup.policy=compact #下面为输出结果
Created topic "streams-wordcount-output".
$bin/kafka-topics.sh --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --describe #查看创建主题的描述信息
Topic:streams-plaintext-input PartitionCount:1 ReplicationFactor:3 Configs: Topic: streams-plaintext-input Partition: 0 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3 Topic:streams-wordcount-output PartitionCount:1 ReplicationFactor:3 Configs:cleanup.policy=compact Topic: streams-wordcount-output Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1 Topic:testtopic PartitionCount:1 ReplicationFactor:3 Configs: Topic: testtopic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 3,1,2
启动Wordcount应用程序:
以下命令启动WordCount演示应用程序:
$ bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
#演示应用程序将从输入主题stream-plaintext-input中读取,对每个读取的消息执行WordCount算法的计算,并将其当前结果连续写入输出主题流-wordcount-output。 因此,除了日志条目外,不会有任何STDOUT输出,因为结果会写回到Kafka中。
#现在我们可以在一个单独的终端中启动控制台生产者来为这个主题写入一些输入数据:
$ bin/kafka-topics.sh --describe --zookeeper 192.168.14.54:2181,192.168.14.55:2181,192.168.14.56:2181 --topic streams-plaintext-input
Topic:streams-plaintext-input PartitionCount:1 ReplicationFactor:3 Configs: Topic: streams-plaintext-input Partition: 0 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
#可以看到现在Leader节点是2节点,也就是192.168.14.52节点
$ bin/kafka-console-producer.sh --broker-list 192.168.14.52:9092 --topic streams-plaintext-input #下面就是开始输入数据了
>nihao this is one test #生成了一条数据 > #还要生产数据就继续输入,如果不想输入了就CTRL+C
#上面产生了一条消息,如果你在别的窗口消费一下会看到这边生成的数据。如下面:
$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.51:9092,192.168.14.52:9092,192.168.14.53:9092 --from-beginning --topic streams-plaintext-input ...... #中间有很多别的信息就不粘贴了 nihao this is one test #消费到了最新生产的消息
并通过在单独的终端中使用控制台客户端读取其输出主题来检查WordCount演示应用程序的输出:
$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.52:9092 \ --topic streams-wordcount-output \ --from-beginning \ --formatter kafka.tools.DefaultMessageFormatter \ --property print.key=true \ --property print.value=true \ --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \ --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
处理一些数据:
现在我们通过输入一行文本,然后按下<RETURN>,将控制台生产者的一些消息写入输入主题streams-plaintext-input。 这将向输入主题发送一条新消息,其中消息密钥为空,消息值为刚才输入的字符串编码文本行(实际上,应用程序的输入数据通常会连续流入Kafka,而不是 手动输入,就像我们在这个快速入门一样):
$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.52:9092 \
--topic streams-wordcount-output --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true \
--property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
#这里,第一列是java.lang.String格式的Kafka消息键,表示正在计数的单词,第二列是java.lang.Longformat中的消息值,表示单词的最新计数。
#现在让我们继续用控制台生产者写入一个更多的消息到输入主题streams-plaintext-input中。 输入文本行“hello kafka streams”,然后按<RETURN>。 你的终端应该如下所示:
$ bin/kafka-console-producer.sh --broker-list 192.168.14.52:9092 --topic streams-plaintext-input
>all streams lead to kafka >hello kafka streams
在控制台使用者正在运行的其他终端中,您将观察到WordCount应用程序编写了新的输出数据。
可以看出,Wordcount应用程序的输出实际上是连续的更新流,其中每个输出记录(即,上面原始输出中的每行)是单个词的更新计数,也就是诸如“kafka”的记录键。 对于具有相同密钥的多个记录,每个以后的记录都是前一个记录的更新。
下面的两个图表说明了幕后发生的事情。 第一列显示KTable <String,Long>的当前状态的演变,计数count的单词出现次数。 第二列显示从KTable的状态更新得到的更改记录,这些记录正在发送到输出的Kafka主题流-wordcount-output。
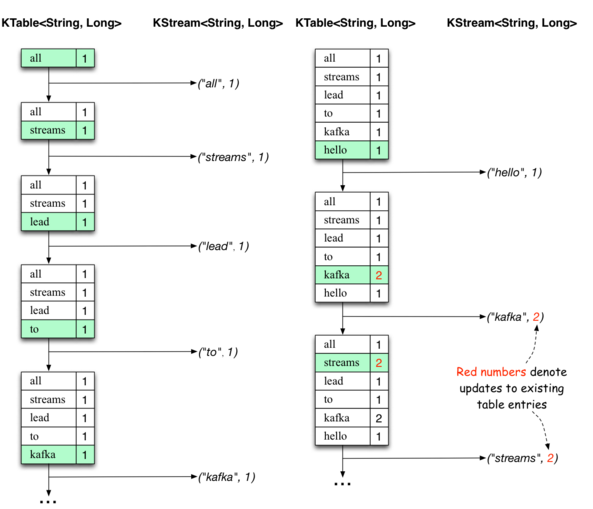
首先正在处理文本行“所有流向kafka”。当每个新单词产生一个新的表格(用绿色背景突出显示)时,KTable被建立起来,并且相应的改变记录被发送到下游的KStream。
当处理第二行文本“hello kafka streams”时,我们首先观察到KTable中现有的条目正在被更新(这里是:“kafka”和“streams”)。再次,更改记录正在发送到输出主题。等等(我们跳过如何处理第三行的说明)。这就解释了为什么输出主题具有上面显示的内容,因为它包含了更改的完整记录。
在这个具体例子的范围之外,Kafka Streams在这里做的是利用表和变更日志流之间的对偶性(这里:table = KTable,changelog stream =下游KStream):你可以发布表转换为流,如果您从头到尾使用整个更新日志流,则可以重新构建表的内容。
#现在可以通过Ctrl-C按顺序停止控制台使用者,控制台生产者,Wordcount应用程序,Kafka代理和ZooKeeper服务器。
博文来自:www.51niux.com
三、跟着官网继续学习(还是忽略翻译官网文档方便查看)
配置文件详细参数:http://kafka.apache.org/documentation/#configuration
3.1 主题级配置
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my-topic --partitions 1 --replication-factor 1 --config max.message.bytes=64000 --config flush.messages=1
#与主题相关的配置既包含服务器默认值,也包含可选的每个主题覆盖值。 如果没有给出每个主题的配置,则使用服务器默认值。 可以在主题创建时通过给出一个或多个--config选项来设置覆盖。 上面示例使用自定义的最大消息大小和冲刷率创建一个名为my-topic的主题。
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my-topic --alter --add-config max.message.bytes=128000
#也可以使用alter configs命令稍后更改或设置覆盖。 上面示例更新my-topic的最大消息大小。
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my-topic --describe
#要检查在主题上设置的覆盖,可以执行上面的操作
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my-topic --alter --delete-config max.message.bytes
#要删除覆盖可以照上面这样操作
3.2 DESIGN(设计)
动机:
设计的Kafka能够作为一个统一的平台来处理大公司可能拥有的所有实时数据馈送。要做到这一点,必须考虑相当广泛的用例。它将不得不具有高吞吐量来支持高容量事件流,例如实时日志聚合。它将需要正常处理大量的数据积压,以便能够支持来自离线系统的周期性数据加载。这也意味着系统将不得不处理低延迟传递来处理更传统的消息传递用例。希望支持对这些提要进行分区,分布式,实时处理,以创建新的派生提要。这激发了分区和消费者模式。最后,在流被送入其他数据系统进行服务的情况下,知道系统必须能够在出现机器故障时保证容错。支持这些用途导致我们设计了一些独特的元素,更类似于数据库日志而不是传统的消息传递系统。
续篇:
不要害怕文件系统!
kafka在很大程度上依赖文件系统来存储和缓存消息。人们普遍认为,“磁盘速度慢”使人们怀疑一个持久的结构可以提供有竞争力的表现。实际上,磁盘比人们所期望的要慢得多,速度也要快得多,这取决于它们的使用方式。一个设计合理的磁盘结构通常可以和网络一样快。
关于磁盘性能的关键事实是,硬盘的吞吐量与过去十年的磁盘搜索的延迟已经不同了。因此,使用6个7200rpm SATA RAID-5阵列的JBOD配置的线性写入性能约为600MB / sec,但随机写入的性能仅为100k / sec左右,相差6000多倍。这些线性读取和写入是所有使用模式中最可预测的,并且由操作系统进行了大量优化。现代操作系统提供预读和后写技术,以大块数倍预取数据,并将较小的逻辑写入分组到大型物理写入中。关于这个问题的进一步讨论可以在这个ACM队列文章中找到。他们实际上发现顺序磁盘访问在某些情况下可能比随机存储访问更快!
为了弥补这种性能差异,现代操作系统在使用主内存进行磁盘缓存方面变得越来越积极。现代操作系统将愉快地将所有空闲内存转移到磁盘高速缓存,并在回收内存时性能降低。所有的磁盘读写操作都将通过这个统一的缓存。如果不使用直接I / O,该功能就不能轻易关闭,因此即使进程维护数据的进程内高速缓存,该数据也可能会在操作系统页面缓存中复制,从而有效地存储所有内容两次。
而且,我们正在建立在JVM的基础之上,任何花时间使用Java内存的人都知道两件事情:
对象的内存开销很高,通常会使所存储数据的大小加倍(或更糟糕)。
随着堆内数据的增加,Java垃圾收集变得越来越复杂和缓慢。
由于使用文件系统和依赖页面缓存的这些因素优于维护内存缓存或其他结构,所以我们至少将可用缓存翻了一番,方法是自动访问所有可用内存,并且可能再次通过存储一个压缩包字节结构而不是单个对象。这样做会导致在32GB的机器上高达28-30GB的缓存,而不受GC惩罚。此外,即使服务重新启动,该缓存也会保持温暖,而进程内缓存将需要在内存中重建(对于10GB的缓存可能需要10分钟),否则将需要以完全冷的缓存开始(这可能意味着糟糕的初始表现)。这也极大地简化了代码,因为所有保持高速缓存和文件系统之间的一致性的逻辑现在都在OS中,这比一次性的进程内尝试更高效和更正确地执行。如果您的磁盘使用情况支持线性读取,则预读使用每个磁盘读取的有用数据有效地预先填充此缓存。
这表明一个非常简单的设计:当我们在空间不足的时候,不是尽可能的保持内存中的空间,而是把它全部冲洗到文件系统中。所有数据立即写入文件系统的持久日志,而不必冲刷到磁盘。实际上,这只是意味着它被转移到内核的页面缓存中。
这种以页面缓存为中心的设计风格在这里的一个关于Varnish设计的文章中描述(伴随着一种健康的傲慢态度)。
Constant Time Suffices
消息传递系统中使用的持久数据结构通常是具有关联的BTree或其他通用随机访问数据结构的按消费者队列来维护关于消息的元数据。 BTrees是可用的最通用的数据结构,可以在消息传递系统中支持各种各样的事务性和非事务性语义。但它们的成本相当高:Btree操作是O(logN)。通常O(log N)被认为基本上等同于常量时间,但是对于磁盘操作来说这不是真的。磁盘寻道是在10毫秒的时间来进行的,每个磁盘一次只能做一个寻道,所以并行性是有限的。因此,即使是少数磁盘寻找导致非常高的开销。由于存储系统将非常快的缓存操作与非常缓慢的物理磁盘操作混合在一起,所以观察到的树形结构的性能通常是超线性的,因为数据随着固定的缓存而增加 - 将数据翻倍会使事情变得比两倍慢。
直观地说,持久队列可以建立在简单的读取上,并附加到文件中,这与记录解决方案的情况相同。这个结构的优点是所有的操作都是O(1),读操作不会阻止写操作或者彼此之间的操作。由于性能与数据大小完全分离,这具有明显的性能优势 - 现在一台服务器可以充分利用大量廉价,低转速的1 + TB SATA驱动器。虽然它们的搜寻性能很差,但这些驱动器在大型读写方面的性能还是可以接受的,达到了三分之一的价格和三倍的容量。
在没有任何性能损失的情况下访问几乎没有限制的磁盘空间意味着我们可以提供通常在邮件系统中找不到的一些功能。例如,在Kafka中,我们可以保留相对较长的时间(比如说一个星期),而不是试图在消费后马上删除消息。正如我们将要描述的,这给消费者带来了很大的灵活性。
3.3 效率:
我们已经付出了很大的努力效率。我们的主要用例之一是处理网页活动数据,这是非常高的数据量:每个页面视图可能会产生数十个写入。此外,我们假设发布的每条消息都被至少一个消费者阅读(通常很多),因此我们努力使消费尽可能便宜。
我们还发现,从建立和运行一系列类似系统的经验来看,效率是实现多租户有效运营的关键。如果下游基础架构服务由于应用程序使用量小而容易成为瓶颈,那么这样的小改动往往会产生问题。通过非常快的速度,我们可以帮助确保应用程序在基础架构之前在负载下翻车。当尝试运行支持数十个或数百个集中式应用程序的集中式服务时,这一点尤为重要,因为使用模式的变化几乎每天都在发生。
我们在上一节讨论了磁盘效率。一旦消除了较差的磁盘访问模式,在这种类型的系统中有两个常见的低效率原因:太多的小I / O操作和过多的字节复制。
客户端和服务器之间以及服务器自身的持久性操作都会发生小I / O问题。
为了避免这种情况,我们的协议是建立在一个“消息集”抽象的基础上,自然将消息分组在一起。这允许网络请求将消息分组在一起,并分摊网络往返的开销,而不是一次发送单个消息。服务器依次将大块消息附加到其日志中,并且消费者一次获取大的线性块。
这个简单的优化产生了数量级的加速。批量导致更大的网络数据包,更大的顺序磁盘操作,连续的内存块等等,所有这些都允许Kafka将随机消息写入的突发流转换为流向消费者的线性写入。
另一个低效率是在字节复制。在低信息率这不是一个问题,但在负载下的影响是显着的。为了避免这种情况,我们使用由生产者,代理和消费者共享的标准二进制消息格式(因此可以在它们之间不加修改地传送数据块)。
由代理维护的消息日志本身就是一个文件目录,每个文件都由一系列消息集合填充,这些消息集合已经以生产者和消费者使用的相同格式写入磁盘。保持这种通用格式可以优化最重要的操作:持久日志块的网络传输。现代的unix操作系统提供了一个高度优化的代码路径,用于将数据从页面缓存转移到套接字;在Linux中,这是通过sendfile系统调用完成的。
要理解sendfile的影响,了解数据从文件传输到套接字的常见数据路径非常重要:
操作系统将数据从磁盘读取到内核空间的pagecache中
应用程序从内核空间读取数据到用户空间缓冲区
应用程序将数据写回内核空间到套接字缓冲区
操作系统将数据从套接字缓冲区复制到通过网络发送的NIC缓冲区
这显然是低效的,有四个副本和两个系统调用。使用sendfile,通过允许操作系统将数据从pagecache直接发送到网络,可以避免重新复制。所以在这个优化的路径中,只需要最终拷贝到NIC缓冲区。
我们期望一个共同的用例在一个主题上成为多个消费者。使用上面的零拷贝优化,数据被复制到页面缓存中一次,并在每次使用时被重用,而不是被存储在内存中,并且每次被读取时拷贝到用户空间。这允许消息以接近网络连接限制的速率消耗。
页面缓存和发送文件的组合意味着,在消费者大多被抓住的卡夫卡群集中,您将看不到磁盘上的读取活动,因为它们将完全从缓存中提供数据。
有关sendfile和Java中零拷贝支持的更多背景信息,请参阅:http://www.ibm.com/developerworks/linux/library/j-zerocopy
端到端的批量压缩:
在某些情况下,瓶颈实际上不是CPU或磁盘,而是网络带宽。对于需要通过广域网在数据中心之间发送消息的数据管道尤其如此。当然,用户总是可以一次压缩一个消息,而不需要Kafka的任何支持,但是这会导致非常差的压缩率,因为冗余的多少是由于相同类型的消息之间的重复(例如, JSON或Web日志中的用户代理或公共字符串值)。有效的压缩需要一起压缩多个消息,而不是单独压缩每个消息。
Kafka以高效的批处理格式支持这一点。一批消息可以压缩在一起并以这种形式发送到服务器。这批消息将以压缩格式写入,并将保持压缩在日志中,只会由消费者解压缩。
Kafka支持GZIP,Snappy和LZ4压缩协议。有关压缩的更多细节:https://cwiki.apache.org/confluence/display/KAFKA/Compression
3.4 生产者
负载均衡:
生产者将数据直接发送给作为分区领导者的代理,而不需要任何中间路由层。为了帮助生产者做到这一点,所有的Kafka节点都可以回答关于哪些服务器处于活动状态的元数据的请求,以及某个主题的分区的领导在哪里给定的时间以允许生产者适当地指示其请求。
客户端控制它将消息发布到哪个分区。这可以随机完成,实现一种随机负载平衡,也可以通过一些语义分区功能完成。我们通过允许用户指定一个键进行分区,并使用它来散列到一个分区(如果需要的话,也可以选择覆盖分区函数),从而公开接口进行语义分区。例如,如果选择的密钥是用户ID,那么给定用户的所有数据都将被发送到同一个分区。这反过来将允许消费者对他们的消费做出当地的假设。这种分区方式明确地设计为允许在消费者中进行局部敏感的处理。
异步发送:
批量是效率的重要推动力之一,为了实现批量生产,卡夫卡生产商将试图在内存中积累数据,并在一个请求中发送大批量的数据。 批处理可以被配置为累加不超过固定数量的消息并且不超过某个固定的延迟限制(比如64k或10ms)。 这允许发送更多字节的累积,并且在服务器上几个较大的I / O操作。 这种缓冲是可配置的,并提供了一种机制来折中少量额外的延迟以获得更好的吞吐量。
有关配置的详细信息和生产者的api:http://kafka.apache.org/082/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html
3.5 消费者
Kafka消费者通过向brokers发出“获取”请求来引导他们想要消费的分区。 消费者在每个请求的日志中指定其偏移量,并从该位置接收一个日志块。 因此,消费者对这个位置具有重要的控制,并且如果需要的话可以倒转以重新消费数据。
Push vs. pull:
我们考虑的一个最初的问题是,消费者是否应该从经纪商或经纪商那里获取数据,以便将数据推送给消费者。在这方面,卡夫卡采用了一种更传统的设计方式,由大多数信息系统共享,数据从制作者推送给经纪人,由消费者从经纪人那里提取。一些以日志为中心的系统(如Scribe和Apache Flume)遵循一种非常不同的基于推送的路径,将数据推向下游。这两种方法都有优点和缺点。然而,基于推送的系统难以处理不同的消费者,因为经纪人控制数据传输的速度。目标通常是消费者能够以最大可能的速度消费;不幸的是,在推动系统中,这意味着当消费率低于生产率(本质上是拒绝服务攻击)时,消费者往往会被压倒。基于拉动的系统具有更好的属性,消费者只要落后就赶上。这可以通过某种退让协议来减轻,消费者可以通过这种退让协议来指示它是不堪重负的,但是让消费者充分利用(但绝不能过度使用)消费者的比例似乎比看起来要复杂。以前以这种方式构建系统的尝试使我们走上了更传统的拉模式。
基于拉式的系统的另一个优点是,它可以使发送给消费者的数据大量批量生产。基于推送的系统必须选择立即发送请求,或者累积更多的数据,然后在不知道下游消费者是否能够立即处理的情况下发送。如果调整为低延迟,则这将导致一次只发送单个消息,以便传输结束被缓冲,这是浪费的。基于拉式的设计修复了这个问题,因为消费者总是将所有可用的消息拉到日志中的当前位置(或达到某个可配置的最大大小)之后。所以人们可以获得最佳的配料而不会引入不必要的延迟
一个天真的基于拉式的系统的缺点是,如果经纪人没有数据,消费者可能会在一个紧密的循环中结束投票,有效地忙于等待数据到达。为了避免这种情况,我们在我们的pull请求中有一些参数,这些参数允许消费者请求以“长轮询”的方式进行阻塞,等待数据到达(并且可选地等待,直到给定数量的字节可用以确保大的传输大小)。
你可以想象其他可能的设计,只会拉,端到端。制片人会在当地写一个当地的日志,经纪人会从消费者那里抽出来。经常提出一个类似的“存储和转发”生产者。这是有趣的,但我们觉得不是很适合我们有成千上万的生产者的目标用例。我们在大规模运行持久数据系统的经验使我们感到,在许多应用程序中涉及系统中数以千计的磁盘实际上不会使事情变得更加可靠,而且会成为一个噩梦般的操作。在实践中,我们发现我们可以大规模地运行带有强大SLA的流水线,而不需要生产者持久性。
消费者定位:
跟踪已经消耗的东西,令人惊讶的是,消息系统的关键性能点之一。
大多数消息传递系统都保留关于代理消费的消息。也就是说,当消息被发送给消费者时,经纪人要么立即在本地记录该事实,要么等待消费者的确认。这是一个相当直观的选择,实际上对于单个机器服务器来说,不清楚这个状态可以去哪里。由于在许多消息传递系统中用于存储的数据结构规模较小,因此这也是一个实用的选择 - 由于代理知道消耗的是什么,它可以立即删除它,保持数据量小。
也许不明显的是,让经纪人和消费者就所消费的东西达成一致并不是一个小问题。如果代理记录消息每次通过网络发送时立即消费,那么如果消费者未能处理该消息(比如说因为崩溃或者请求超时等等),那么消息将会丢失。为了解决这个问题,许多消息传递系统增加了一个确认功能,这意味着消息只在被发送时被标记为发送而不被消费。代理等待来自消费者的特定确认以将消息记录为消费。这个策略解决了丢失信息的问题,但是却产生了新的问题。首先,如果消费者在消息发送失败之前处理消息,那么消息将被消费两次。第二个问题是性能问题,现在代理必须保持每个消息的多个状态(首先锁定它,这样它不会被再次发出,然后将其标记为永久消耗,以便将其删除)。棘手的问题必须得到处理,比如如何处理被发送但未被确认的消息。
卡夫卡处理这个不同。我们的主题被分成一组完全有序的分区,每个分区在任何给定的时间都被每个订阅消费者组中的一个消费者消费。这意味着消费者在每个分区中的位置只是一个整数,即要消耗的下一个消息的偏移量。这使得所消耗的状态非常小,每个分区只有一个数字。这个状态可以定期检查点。这使消息确认的等价物非常便宜。
这个决定有一个好处。消费者可以故意倒回到旧的偏移量并重新使用数据。这违反了队列的共同合同,但是对于许多消费者来说却是一个必不可少的特征。例如,如果消费者代码有一个错误,并且在一些消息被消费之后被发现,则消费者可以在错误得到修复后重新使用这些消息。
离线数据加载:
可伸缩的持久性允许消费者仅仅周期性地消费的可能性,诸如批量数据加载,其周期性地将数据加载到脱机系统(诸如Hadoop或关系数据仓库)中。
在Hadoop的情况下,我们通过在单个映射任务上分割负载来并行化数据负载,每个节点/主题/分区组合都有一个负载,从而在负载中允许完全并行化。 Hadoop提供了任务管理功能,失败的任务可以重新启动,而没有重复数据的危险,只需从原始位置重新启动即可。
3.6 消息传递语义
现在我们对生产者和消费者如何工作有一些了解,让我们来讨论一下Kafka在生产者和消费者之间提供的语义保证。 显然,可以提供多种可能的消息传递保证:
最多一次 - 消息可能会丢失,但永远不会重新发送。 至少一次 - 消息永远不会丢失,但可以重新发送。 确切地说,这是人们真正想要的,每个信息只传递一次。
值得注意的是,这分解成两个问题:发布消息的持久性保证和消费消息时的保证。
许多系统声称提供“恰好一次”的交付语义,但重要的是要阅读细则,这些声明大多是误导性的(即它们不转化为消费者或生产者可能失败的情况,消费者进程,或写入磁盘的数据可能丢失的情况)。
卡夫卡的语义是直截了当的。发布消息时,我们将消息的概念“提交”到日志中。一旦发布的消息被提交,只要复制写入该消息的分区的代理保持“活动”状态,它就不会丢失。提交的消息的定义,活动分区以及我们试图处理哪些类型的失败的描述将在下一节中更详细地描述。现在让我们假设一个完美的,无损的经纪人,并试图了解生产者和消费者的保证。如果生产者试图发布消息并且遇到网络错误,则不能确定在提交消息之前或之后是否发生此错误。这与使用自动生成的键插入到数据库表中的语义相似。
在0.11.0.0之前,如果一个生产者没有收到一个指示消息已经提交的响应,那么除了重新发送消息之外别无选择。这提供了至少一次传送语义,因为如果原始请求实际上已经成功,则在重新发送期间可以再次将消息写入日志。自0.11.0.0开始,Kafka生产者也支持一个幂等递送选项,保证重新发送不会在日志中导致重复条目。为了达到这个目的,代理人为每个生产者分配一个ID,并使用生产者发送的序列号和每一个消息去重复消息。也从0.11.0.0开始,生产者支持使用类似事务的语义将消息发送到多个主题分区的能力:即,所有消息都被成功写入或者没有任何消息。这个主要用例恰好在卡夫卡话题之间进行一次处理(如下所述)。
并不是所有的用例都需要这样的强力保证对于对延迟敏感的用途,我们允许生产者指定它想要的耐久性级别。如果生产者指定它想要等待提交的消息,则可以采用10ms的量级。然而,制作者也可以指定它想要完全异步地执行发送,或者它只想等到领导者(但不一定是跟随者)有消息。
现在让我们从消费者的角度来描述语义。所有副本都具有相同的日志和相同的偏移量。消费者控制在这个日志中的位置。如果消费者没有崩溃,它可以将这个位置存储在内存中,但是如果消费者失败了,我们希望这个主题分区被另一个进程接管,那么新进程需要选择一个合适的位置来开始处理。假设消费者读取一些消息 - 它具有处理消息和更新其位置的多个选项。
它可以读取消息,然后将其位置保存在日志中,最后处理消息。在这种情况下,消费者进程在保存其位置之后但在保存其消息处理的输出之前可能会崩溃。在这种情况下,接管处理的过程将从保存的位置开始,即使在该位置之前的一些消息还没有被处理。这对应于“最多一次”的语义,如在消费者失败的情况下可能不会被处理。 它可以读取消息,处理消息,并最终保存它的位置。在这种情况下,处理消息之后但在保存其位置之前,消费者进程可能会崩溃。在这种情况下,当新的进程接管它接收到的头几条消息时就已经被处理了。在消费者失败的情况下,这对应于“至少一次”的语义。在许多情况下,消息都有一个主键,所以更新是幂等的(接收相同的消息两次,只是用另一个副本覆盖一条记录)。
那么,一次语义(即你真正想要的东西)呢?当从一个Kafka主题中消费并产生到另一个主题(如Kafka Streams应用程序中)时,我们可以利用上面提到的0.11.0.0中的新的事务性生产者功能。消费者的位置作为消息存储在主题中,所以我们可以在接收处理的数据的输出主题的相同事务中将偏移量写入Kafka。如果交易被中止,则消费者的位置将恢复到其旧值,并且根据其“隔离级别”,输出主题上产生的数据对于其他消费者不可见。在默认的“read_uncommitted”隔离级别中,消费者即使是中止事务的一部分,所有消息都是可见的,但是在“read_committed”中,消费者只会从已提交的事务中返回消息(以及任何不是的交易)。
写入外部系统时,限制在于需要将消费者的位置与实际存储为输出的位置进行协调。实现这一目标的经典方法是在消费者位置的存储和消费者输出的存储之间引入两阶段提交。但是,这可以更简单地处理,并且通常通过让消费者将其偏移存储在与其输出相同的位置来进行。这样做更好,因为消费者可能想要写入的许多输出系统不支持两阶段提交。作为一个例子,考虑一个Kafka Connect连接器,它将HDFS中的数据和它所读取的数据的偏移一起填入数据,以保证数据和偏移量都被更新,或者两者都不是。对于许多其他需要这些更强的语义的数据系统,我们也遵循类似的模式,并且对于这些数据系统,消息没有允许重复数据删除的主键。
因此,有效地,Kafka支持在Kafka Streams中一次交付,并且在Kafka主题之间传输和处理数据时,事务性生产者/消费者通常可用于提供准确一次的交付。其他目的地系统的一次交付通常需要与这些系统合作,但是Kafka提供了实现这种可行的补偿(参见Kafka Connect)。否则,Kafka默认保证至少一次交付,并允许用户在处理一批消息之前,通过禁止生产者重试和在消费者中提交补偿来实施至多一次交付。
3.7 复制
Kafka通过可配置数量的服务器复制每个主题分区的日志(您可以在逐个主题的基础上设置此复制因子)。这样,当群集中的服务器出现故障时,可以自动故障转移到这些副本,以便在发生故障时保持可用状态。
其他消息传递系统提供了一些与复制有关的功能,但是在我们(完全有偏见的)看来,这似乎是一个不太常用的东西,而且有很大的缺点:从属处于不活动状态,吞吐量受到严重影响,繁琐的手动配置等等。Kafka默认使用复制,实际上我们将未复制的主题实现为复制因子为1的复制主题。
复制单位是主题分区。在非失败条件下,卡夫卡的每个分区都有一个单独的领导者和零个或更多的追随者。包括领导者的副本总数构成复制因素。所有的读写操作都转到分区的领导。通常情况下,中间商比中间商多得多,而且领导者在经纪商之间平均分配。追随者的日志与领导者的日志相同 - 都有相同顺序的消息和消息(当然,在任何给定的时间,领导者在其日志末尾可能有几个尚未复制的消息)。
追随者像正常的卡夫卡消费者一样消费领导者的消息,并将他们应用到他们自己的日志中。让追随者从领导者身上取得好成绩,可以让追随者自然地把日志条目分配到日志中。
与大多数分布式系统一样,自动处理故障需要精确定义节点“活着”的含义。对于卡夫卡节点的生存有两个条件
节点必须能够维护与ZooKeeper的会话(通过ZooKeeper的心跳机制) 如果它是一个slave,它必须复制发生在领导者上的写作,而不是落后于“太远”
我们将满足这两个条件的节点称为“同步”,以避免“活着”或“失败”的模糊性。领导跟踪“同步”节点的集合。如果追随者死亡,被卡住或落后,领导将从同步副本列表中删除它。停滞和滞后复制品的确定由replica.lag.time.max.ms配置控制。
在分布式系统术语中,我们只尝试处理节点突然停止工作,然后恢复(可能不知道已经死亡)的失败/恢复模式。 Kafka不处理所谓的“拜占庭式”的故障,其中节点产生任意或恶意的反应(可能是由于错误或犯规)。
现在我们可以更准确地定义,当该分区的所有同步副本将其应用于其日志时,将认为该消息已被提交。只有承诺的消息被分发给消费者。这意味着消费者不必担心如果领导者失败,可能会看到可能丢失的消息。另一方面,生产者可以选择是否等待消息被提交,这取决于他们在延迟和持久性之间的权衡。这个首选项由生产者使用的acks设置控制。请注意,主题有一个“最小数量”的同步副本的设置,当生产者请求确认消息已写入完整的同步副本集时,将检查这些副本。如果生产者请求较不严格的确认,则即使同步复制品的数量低于最小值(例如,它可以与领导者一样低),也可以提交和消费该消息。
卡夫卡提供的保证是,只要至少有一个同步副本在任何时间存在,就不会丢失承诺的消息。
在短暂的故障切换期后,卡夫卡将保持可用状态,但在出现网络分区的情况下可能无法保持可用状态。
复制日志:法定人数,ISR和状态机
卡夫卡分区的核心是一个复制日志。复制日志是分布式数据系统中最基本的原语之一,实现它的方法很多。其他系统可以使用复制的日志作为实现其他分布式系统状态的原语。
一个复制日志按照一系列值的顺序(通常是对日志条目编号0,1,2,...)进行建模。有很多方法可以实现这一点,但最简单和最快的方法是选择提供给它的值的排序的领导者。只要领导者还活着,所有的追随者只需要复制价值和领导者选择的命令。
当然,如果领导不失败,我们就不需要追随者!当领导者死亡时,我们需要从追随者中选择一个新的领导者。但追随者本身可能落后或崩溃,所以我们必须确保我们选择一个最新的追随者。日志复制算法必须提供的基本保证是,如果我们告诉客户一个消息被提交,并且领导失败,我们选择的新领导也必须有这个消息。这产生了一个折衷:如果领导者在宣布承诺之前等待更多的追随者承认消息,那么将会有更多潜在的可选领导者。
如果您选择所需的确认数量以及必须比较的日志数量来选择一个领导者,以确保重叠,则称为定额。
这种权衡的一个常见方法是在投票决定和领导者选举中使用多数票。这不是卡夫卡所做的,但是我们仍然可以通过探索来了解这个权衡。假设我们有2f + 1个副本。如果f + 1副本必须在领导者声明提交之前接收到一条消息,并且如果我们通过从至少f + 1个副本中选择具有最完整日志的跟随者来选择一个新领导者,则不超过f失败,领导者保证有所有承诺的信息。这是因为在任何f + 1副本中,必须至少有一个副本包含所有提交的消息。这个副本的日志将是最完整的,因此将被选为新的领导者。每个算法都必须处理许多其他细节(例如,精确定义了什么使得日志更加完整,确保了领导失败期间的日志一致性或更改副本集中的服务器集),但是现在我们将忽略这些细节。
这种多数表决方法有一个非常好的属性:延迟是依赖于只有最快的服务器。也就是说,如果复制因子是3,则等待时间由更快的从属者而不是较慢的从属者确定。
这个系列有很多种算法,包括ZooKeeper的Zab,Raft和Viewstamped Replication。我们知道Kafka的实际实现最类似的学术出版物是来自Microsoft的PacificA。
大多数投票的缺点是,没有多少失败让你没有选举的领导。要容忍一个故障需要三份数据,而要容忍两次故障则需要五份数据。根据我们的经验,只有足够的冗余来容忍单个故障对于一个实际的系统来说是不够的,但是对于大容量数据问题来说,每写五次,磁盘空间要求是5倍,吞吐量是1/5,是不实用的。这可能是为什么仲裁算法更常用于共享群集配置(如ZooKeeper)的原因,但是对于主数据存储则不太常见。例如,在HDFS中,namenode的高可用性功能是建立在大多数投票日志上的,但是这种更昂贵的方法不适用于数据本身。
卡夫卡采取了一种稍微不同的方法来选择法定人数。卡夫卡不是多数投票,而是动态地维护一组被引导到领导者的同步复制品(ISR)。只有这一组的成员才有资格当选领导。写入Kafka分区不会被视为提交,直到所有的同步副本收到写入。这个ISR集合在ZooKeeper发生变化时会被持久化。正因为如此,ISR中的任何复制品都有资格当选领导者。这是卡夫卡使用模式的一个重要因素,其中有很多分区,确保领导力平衡是重要的。有了这个ISR模型和f + 1副本,一个Kafka主题可以容忍f故障,而不会丢失承诺的消息。
对于我们希望处理的大多数用例,我们认为这种权衡是合理的。在实践中,为了容忍f失败,大多数投票和ISR方法都会等待相同数量的副本在提交消息之前承认(例如,在一次失败后仍然存在,大多数法定人数需要三次副本和一次确认,ISR方法要求两个副本和一个确认)。没有最慢的服务器提交的能力是一个好处多数表决方式。但是,我们认为通过允许客户端选择是否阻塞消息提交来改善,并且由于所需的复制因子较低而产生的额外的吞吐量和磁盘空间是值得的。另一个重要的设计区别是,Kafka不要求崩溃的节点恢复所有的数据。在这个空间中的复制算法依赖于存在“稳定存储”的情况并不少见,这种“稳定存储”在没有潜在的一致性违反的情况下在任何故障恢复情况下都不会丢失。这个假设有两个主要的问题。首先,磁盘错误是我们在永久性数据系统的实际操作中观察到的最常见的问题,并且它们通常不会使数据保持原样。其次,即使这不是问题,我们也不希望在每次写入时都要求使用fsync来保证一致性,因为这会使性能降低两到三个数量级。我们允许副本重新加入ISR的协议可以确保在重新加入之前,即使丢失未刷新的数据,它也必须重新同步。
不洁的领导人选:如果他们都死了呢?
请注意,Kafka关于数据丢失的保证是基于至少一个保持同步的副本。 如果复制分区的所有节点都死亡,则此保证不再成立。
然而,一个实际的系统需要做一些合理的事情,当所有的副本死亡。 如果你不幸发生这种情况,重要的是要考虑会发生什么。 有两种行为可以实现:
等待ISR的副本重新回到生活中,并选择这个副本作为领导者(希望它仍然拥有所有的数据)。 选择第一个复制品(不一定在ISR中)作为领导者复活。
这是可用性和一致性之间的简单折衷。如果我们在ISR中等待副本,那么只要这些副本停机,我们将保持不可用状态。如果这样的复制品被毁坏或者他们的数据丢失了,那么我们永远是失败的。另一方面,如果一个不同步的复制品恢复生机,并且我们允许它成为领导者,那么它的日志就成为真相的来源,即使它不能保证每一个提交的信息都是如此。默认情况下,Kafka选择第二种策略,并且当ISR中的所有副本都已经死掉时,选择可能不一致的副本。可以使用配置属性unclean.leader.election.enable来禁用此行为,以支持停机时间优于不一致的用例。
这种困境并不是卡夫卡所特有的。它存在于任何法定人数的计划中。例如,在大多数投票计划中,如果大多数服务器遭受永久性故障,那么您必须选择丢失100%的数据,或者通过将现有服务器上剩下的内容作为新的事实来源来破坏一致性。
可用性和耐久性保证:
写给Kafka时,制作者可以选择是否等待消息被0,1或全部(-1)复制品确认。 请注意,“所有副本确认”并不保证已分配副本的全套已收到消息。 默认情况下,当acks = all时,只要所有当前的同步副本收到消息,确认就会发生。 例如,如果一个主题配置了只有两个副本,一个失败(即只有一个同步副本保留),那么指定acks = all的写入将会成功。 但是,如果剩余副本也失败,这些写入可能会丢失。 尽管这确保了分区的最大可用性,但是对于偏好耐久性而不是可用性的一些用户,这种行为可能是不希望的。 因此,我们提供了两个主题级配置,可用于优先考虑消息的可用性:
#禁用不干净的领导者选举 - 如果所有副本都不可用,那么分区将保持不可用,直到最近的领导者再次可用。这有效地避免了消息丢失的风险。请参阅上一节有关不洁领导人选举的澄清。 #指定最小的ISR大小 - 如果ISR的大小超过某个最小值,分区将只接受写入操作,以防止仅写入单个副本的消息丢失,而后者将不可用。这个设置只有在生产者使用acks = all的情况下才会生效,并保证消息至少被这么多的同步复制品所承认。 此设置提供了一致性和可用性之间的折中。对于最小ISR大小的更高设置保证了更好的一致性,因为保证将消息写入更多的副本,这减少了丢失的可能性。但是,这会降低可用性,因为如果同步副本的数量低于最小阈值,则分区将无法写入。
副本管理:
以上关于复制日志的讨论确实只涉及单个日志,即一个主题分区。然而,一个Kafka集群将管理数百或数千个这样的分区。我们尝试以循环方式平衡集群内的分区,以避免在少量节点上集中高容量主题的所有分区。同样,我们试图平衡领导力,使每个节点成为其分区比例份额的领导者。
优化领导层选举过程也是非常重要的,因为这是不可用的关键窗口。领导者选举的一个天真的实现将最终运行每个分区的选举为该节点失败时托管节点的所有分区运行。相反,我们选择其中一个经纪人作为“控制者”。该控制器检测代理级别的故障,并负责更改故障代理中所有受影响的分区的负责人。结果是,我们可以将许多所需的领导层变更通知批量化,这使得选举过程对于大量分区而言要便宜得多并且速度更快。如果管理者失败,其中一个幸存的brokers将成为新的
3.8 日志压缩
日志压缩可确保Kafka始终至少为单个主题分区的数据日志中的每个消息密钥保留最后一个已知值。它解决用例和场景,例如在应用程序崩溃或系统故障之后恢复状态,或者在运行维护期间重新启动应用程序后重新加载缓存。让我们更详细地介绍这些用例,然后描述压缩是如何工作的。
到目前为止,我们只描述了更简单的数据保留方法,在一段固定的时间之后丢弃旧的日志数据,或者日志达到某个预定的大小。这适用于时间事件数据,例如记录每个记录独立的地方。然而,重要的一类数据流是对键控,可变数据(例如对数据库表的更改)进行更改的日志。
我们来讨论一个这样的流的具体例子。假设我们有一个包含用户邮箱地址的主题,每当用户更新他们的电子邮件地址时,我们都会使用他们的用户ID作为主键向此主题发送消息。现在说我们在一段时间内为id为123的用户发送以下消息,每个消息对应于电子邮件地址的改变(其他id的消息被省略):
123 => bill@microsoft.com . . . 123 => bill@gatesfoundation.org . . . 123 => bill@gmail.com
日志压缩为我们提供了更为细化的保留机制,因此我们保证至少保留每个主键的最新更新(例如bill@gmail.com)。 通过这样做,我们保证日志包含每个密钥的最终值的完整快照,而不仅仅是最近更改的密钥。 这意味着下游消费者可以从这个主题中恢复自己的状态,而不必保留所有更改的完整日志。
我们先看几个有用的用例,然后看看如何使用它。
数据库更改订阅。通常需要在多个数据系统中拥有一个数据集,而且这些系统中的一个往往是某种数据库(RDBMS或可能是一个新开发的键值存储)。例如,您可能有一个数据库,一个缓存,一个搜索集群和一个Hadoop集群。每次对数据库的更改都需要反映在缓存,搜索群集中,最终在Hadoop中。在只处理实时更新的情况下,您只需要最近的日志。但是,如果您希望能够重新加载缓存或恢复失败的搜索节点,则可能需要完整的数据集。 事件采购。这是一种应用程序设计风格,它将查询处理与应用程序设计协同定位,并使用变更日志作为应用程序的主要存储。 日志记录高可用性。执行本地计算的进程可以通过注销对其本地状态所做的更改来实现容错,以便另一个进程可以重新加载这些更改并在出现故障时继续进行。一个具体的例子是在流查询系统中处理计数,聚合和其他“按类”处理。 Samza是一个实时的流处理框架,正是为了这个目的而使用这个特性。
在这些情况下,主要需要处理变化的实时馈送,但是偶尔当机器崩溃或需要重新加载或重新处理数据时,需要满载。日志压缩允许将这两个用例从相同的支持主题中提取出来。本博客文章更详细地介绍了这种日志的使用方式。
总的想法很简单。如果我们有无限的日志保留,并且记录了上述情况下的每一个变化,那么我们就会在每次从第一次开始时就捕获系统的状态。使用这个完整的日志,我们可以通过重放日志中的前N个记录来恢复到任何时间点。对于更新单个记录多次的系统,这个假设的完整日志不是很实用,因为即使对于稳定的数据集,日志也将无限制地增长。抛弃旧更新的简单日志保留机制将限制空间,但是日志不再是恢复当前状态的一种方式 - 现在从日志开始恢复不再重新创建当前状态,因为旧更新可能根本不被捕获。
日志压缩是提供更细粒度的每记录保留的机制,而不是更粗粒度的基于时间的保留。这个想法是有选择地删除我们有一个更新的更新与相同的主键的记录。这样,日志保证至少有每个密钥的最后一个状态。
此保留策略可以按每个主题进行设置,因此单个群集可以有一些主题,其中的保留是按大小或时间强制执行的,其他主题是通过压缩保留保留的主题。
这种功能受到LinkedIn最古老,最成功的基础架构之一 - 数据库变更日志缓存服务Databus的启发。与大多数日志结构存储系统不同的是,Kafka是为订阅而构建的,它组织数据以实现快速的线性读写。与Databus不同的是,Kafka充当真实来源商店,所以即使在上游数据源不可重播的情况下也是如此。
日志压缩基础:
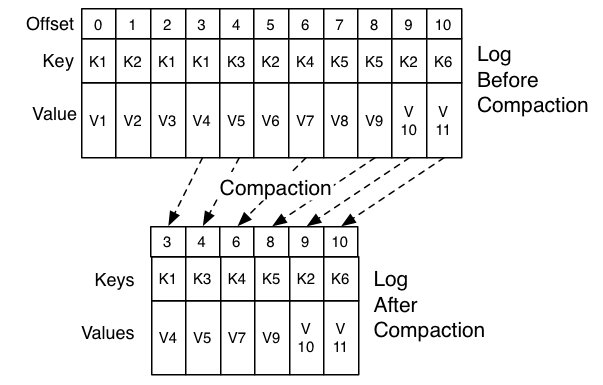
下面一个高级图片,显示每个消息的偏移量的Kafka日志的逻辑结构。
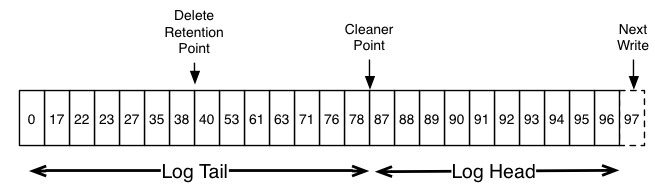
日志的头部与传统的Kafka日志相同。它具有密集的连续偏移并保留所有消息。日志压缩添加了一个处理日志尾部的选项。上面的图片显示了一个压缩尾巴的日志。请注意,日志尾部的消息保留了第一次写入时指定的原始偏移量 - 这些消息永远不会改变。还要注意,即使具有该偏移量的消息已被压缩,所有偏移量仍然保持在日志中的有效位置;在这种情况下,这个位置与日志中出现的下一个最高偏移无法区分。例如,在上面的图片中,偏移量36,37和38都是等同的位置,并且从这些偏移量的任何一个开始的读取将返回从38开始的消息集合。
压缩也允许删除。具有密钥和空有效负载的消息将被视为从日志中删除。这个删除标记会导致任何先前的消息被删除(如同任何带有该密钥的新消息一样),但是删除标记是特殊的,因为在一段时间之后它们自己将被清除出日志以释放空间。删除不再保留的时间点被标记为上图中的“删除保留点”。
压缩是通过定期重新复制日志段在后台完成的。清洗不会阻塞读取,可以通过限制使用不超过可配置数量的I / O吞吐量来避免影响生产者和消费者。压缩日志段的实际过程如下所示:
日志压缩提供了什么保证?
日志压缩保证以下内容:
任何一个处于日志头部的消费者都会看到每个被写入的消息;这些消息将有连续的偏移量。可以使用主题的min.compaction.lag.ms来保证写入消息之前必须经过的最短时间长度,然后才能进行压缩。即它提供了每个消息将保留在(未压缩的)头部多长时间的下限。 消息的排序始终保持不变。压缩永远不会重新排序消息,只是删除一些。 消息的偏移不会改变。它是日志中位置的永久标识符。 从日志开始的任何消费者将至少看到他们写入的所有记录的最终状态。此外,如果用户在小于主题的delete.retention.ms设置(缺省值为24小时)的时间段内到达日志头部,则会看到所有已删除记录的删除标记。换句话说:因为删除标记的删除与读取同时发生,所以如果消费者滞后于delete.retention.ms,则消费者可能错过删除标记。
日志压缩细节:
日志压缩是由日志清理器处理的,日志清理器是后台线程池,用于重新记录日志段文件,删除其日志头部出现的记录。 每个压缩机线程的工作原理如下:
它选择日志头与日志尾比率最高的日志 它为日志头部中的每个键创建最后偏移量的简明摘要 它从头到尾复制日志中的日志,删除日志中稍后出现的日志。 新的,干净的段被立即交换到日志中,所需的额外磁盘空间只是一个额外的日志段(不是日志的完整副本)。 日志头的总结实质上只是一个空间紧凑的散列表。 它使用每个条目正好24个字节。 因此,使用8GB清理缓冲区时,一次清理迭代可以清理大约366GB的日志头(假设1k消息)。
配置日志清理器:
日志清理器默认是启用的。 这将启动更干净的线程池。 要在特定主题上启用日志清理,可以添加特定于日志的属性
log.cleanup.policy=compact
他可以在主题创建时或者使用alter topic命令完成。
日志清理器可以配置为保留日志的未压缩“头”的最小量。 这是通过设置压缩时间滞后来实现的。
log.cleaner.min.compaction.lag.ms
这可以用来防止比最小消息时间更新的消息被压缩。 如果未设置,则除了最后一个分段(即,当前正在写入的那个分段)之外,所有日志段都有资格进行压缩。 即使所有消息都比最小压缩时间滞后更早,活动段也不会被压缩。
这里描述了更清洁的配置:http://kafka.apache.org/documentation.html#brokerconfigs。
3.9 配额
Kafka群集有能力对请求执行配额以控制客户端使用的代理资源。 卡夫卡经纪人可以为每组共享配额的客户端实施两种类型的客户配额:
网络带宽配额定义了字节率阈值(从0.9开始) 请求速率配额将CPU利用率阈值定义为网络和I / O线程的百分比(自0.11开始)
为什么配额是必要的?
生产者和消费者有可能以非常高的速度生产/消费大量的数据或产生请求,从而垄断经纪人资源,导致网络饱和,并且通常会阻碍其他客户和经纪人本身。 拥有配额可以防范这些问题,而在大型多租户群集中,一小部分表现不佳的客户端可能会降低用户体验良好的用户体验,这一点尤为重要。 事实上,当运行Kafka作为一项服务时,甚至可以根据约定的合同强制执行API限制。
Client groups(客户群):
Kafka客户端的身份是代表安全集群中经过身份验证的用户的用户主体。 在支持未经身份验证的客户端的集群中,用户主体是代理使用可配置的PrincipalBuilder选择的未经身份验证的用户的分组。 Client-id是由客户端应用程序选择的具有有意义名称的客户端的逻辑分组。 元组(user,client-id)定义了共享用户主体和客户机id的安全逻辑组的客户机。
配额可以应用于(用户,客户端ID),用户或客户端组。 对于给定的连接,将应用与连接匹配的最具体的配额。 配额组的所有连接共享为组配置的配额。 例如,如果(user =“test-user”,client-id =“test-client”)的产品配额为10MB / sec,则在用户“test-user”的所有生产者实例中与客户端 - ID“测试客户端”。
配额配置:
可以为(用户,客户端ID),用户和客户端组定义配额配置。 可以在任何需要更高(或更低)配额的配额级别上覆盖默认配额。 该机制类似于每个主题日志配置覆盖。 用户和(用户,客户端ID)配额覆盖写入/ config / users下的ZooKeeper,客户端配额覆盖写在/ config / clients下。 这些覆盖被所有 brokers读取,并立即生效。 这使我们可以更改配额,而无需执行整个群集的滚动重新启动。 详情请看这里。 每个组的默认配额也可以使用相同的机制动态更新。
配额配置的优先顺序是:
/config/users/<user>/clients/<client-id> /config/users/<user>/clients/<default> /config/users/<user> /config/users/<default>/clients/<client-id> /config/users/<default>/clients/<default> /config/users/<default> /config/clients/<client-id> /config/clients/<default>
代理属性(quota.producer.default,quota.consumer.default)也可用于为客户端组设置网络带宽配额的默认值。 这些属性已被弃用,将在以后的版本中删除。 客户端ID的默认配额可以在Zookeeper中设置,类似于其他配额覆盖和默认设置。
网络带宽配额:
网络带宽配额定义为每组共享配额的客户端的字节速率阈值。 默认情况下,每个唯一的客户端组都会收到由群集配置的固定配额(以字节/秒为单位)。 这个配额是以每个经纪人为基础定义的。 客户端被限制之前,每个客户端组可以发布/获取每个代理的最大X字节/秒。
请求率配额:
请求率限额定义为客户端可以在请求处理程序的I / O线程和配额窗口内每个代理的网络线程上使用的时间百分比。 n%的配额代表一个线程的n%,所以配额超出了((num.io.threads + num.network.threads)* 100)%的总容量。 每个客户端组在受到限制之前,可以在配额窗口中的所有I / O和网络线程中使用最高达n%的总百分比。 由于为I / O和网络线程分配的线程数通常基于代理主机上可用的内核数量,因此请求速率限额表示可由共享配额的每个客户端组使用的CPU总百分比。
约束:
默认情况下,每个唯一的客户端组都会收到由群集配置的固定配额。这个配额是以每个经纪人为基础定义的。每个客户可以在每个经纪人受到限制之前利用这个配额。我们认为,为每个代理定义这些配额比每个客户端具有固定的群集带宽要好得多,因为这需要一种机制来共享所有代理中的客户端配额使用。这可能比配额实施本身更难得到!
brokers在检测到违反配额时会如何反应?在我们的解决方案中,代理不会返回错误,而是尝试减慢超出配额的客户端。它计算将有罪客户限制在其配额之下所需的延迟时间,并延迟当时的回应。这种方法使配额违反对客户端透明(客户端指标以外)。这也使他们不必执行任何特殊的退避和重试行为,这可能会变得棘手。事实上,糟糕的客户行为(无退避的重试)可能会加剧配额试图解决的问题。
字节率和线程利用率是在多个小窗口(例如每个1秒的30个窗口)上测量的,以便快速检测和纠正配额违规。典型地,具有较大的测量窗口(例如,每个30秒的10个窗口)导致大量的业务量突发,随后是在用户体验方面不太好的长延迟。
3.10 IMPLEMENTATION(实施)
网络层:
网络层是一个相当直接的NIO服务器,不会详细描述。 sendfile实现是通过给MessageSet接口写一个writeTo方法来完成的。 这允许文件支持的消息集使用更有效的transferTo实现,而不是进行中的缓冲写入。 线程模型是单个接受者线程和N个处理器线程,每个线程处理固定数量的连接。 这种设计已经在其他地方进行了相当彻底的测试,发现实施起来很简单,速度也很快 该协议保持相当简单,以允许未来实现其他语言的客户端。
消息:
消息由可变长度头部,可变长度不透明密钥字节数组和可变长度不透明值字节数组组成。 标题的格式在下一节中描述。 离开关键和价值不透明是一个正确的决定:目前在序列化库方面正在取得很大进展,任何特定的选择都不太可能适合所有用途。 毋庸置疑,使用Kafka的特定应用程序可能会要求特定的序列化类型作为其使用的一部分。 RecordBatch接口只是一个迭代器,通过使用专门的方法来批量读取和写入NIO通道。
消息格式:
消息(aka记录)总是分批写入。 一批消息的技术术语是记录批次,而记录批次包含一个或多个记录。 在退化的情况下,我们可以有一个包含单个记录的记录批处理。 记录批次和记录都有自己的标题。 卡夫卡版本0.11.0和更高版本(消息格式版本v2,或magic= 2)描述了每种格式。消息格式0和1的详细信息:https://cwiki.apache.org/confluence/display/KAFKA/A+Guide+To+The+Kafka+Protocol#AGuideToTheKafkaProtocol-Messagesets。
批量记录:
以下是RecordBatch的磁盘格式。
baseOffset: int64 batchLength: int32 partitionLeaderEpoch: int32 magic: int8 (current magic value is 2) crc: int32 attributes: int16 bit 0~2: 0: no compression 1: gzip 2: snappy 3: lz4 bit 3: timestampType bit 4: isTransactional (0 means not transactional) bit 5: isControlBatch (0 means not a control batch) bit 6~15: unused lastOffsetDelta: int32 firstTimestamp: int64 maxTimestamp: int64 producerId: int64 producerEpoch: int16 baseSequence: int32 records: [Record]
请注意,启用压缩时,压缩的记录数据将直接按照记录数进行序列化。
CRC覆盖从属性到批处理结束的数据(即CRC后的所有字节)。它位于魔术字节之后,这意味着在决定如何解释批量长度和魔术字节之间的字节之前,客户端必须解析魔术字节。在CRC计算中不包括分区领导epoch字段,以避免在为代理接收的每个批次分配此字段时需要重新计算CRC。 CRC-32C(Castagnoli)多项式用于计算。
压缩:与旧的消息格式不同,magic v2及以上版本在日志清理时保留原始批次的第一个和最后一个偏移/序列号。这是为了能够在日志重新加载时恢复生产者的状态所必需的。例如,如果我们没有保留最后一个序列号,那么在分区引导失败之后,制作者可能会看到一个OutOfSequence错误。必须保留基本序列号以进行重复检查(代理通过验证传入批次的第一个和最后一个序列号与来自该生产者的最后一个序列号相匹配来检查传入的Produce对重复的请求)。因此,当批次中的所有记录都被清除但批次仍被保留以保留生产者的最后序列号时,可能在记录中有空的批次。奇怪的是,baseTimestamp字段在压缩过程中没有保留,所以如果批量中的第一条记录被压缩,它将会改变。
控制批次包含称为控制记录的单个记录。 控制记录不应该传递给应用程序。 相反,它们被消费者用来过滤掉中止的交易消息。
控制记录的关键符合以下模式:
version: int16 (current version is 0) type: int16 (0 indicates an abort marker, 1 indicates a commit)
控制记录的值的架构取决于类型。 对客户来说价值是不透明的。
记录:
记录级别标头是在Kafka 0.11.0中引入的。 带有标题的记录的磁盘格式如下所示。
length: varint attributes: int8 bit 0~7: unused timestampDelta: varint offsetDelta: varint keyLength: varint key: byte[] valueLen: varint value: byte[] Headers => [Header]
Record Header:
headerKeyLength: varint headerKey: String headerValueLength: varint Value: byte[]
使用与Protobuf相同的varint编码。 关于后者的更多信息可以在这里找到。 记录中标题的数量也被编码为varint。
日志:
具有两个分区的名为“my_topic”的主题的日志由两个目录(即my_topic_0和my_topic_1)组成,数据文件包含该主题的消息。日志文件的格式是一系列的“日志条目”,每个日志条目是一个4字节的整数N,存储着消息长度,后面跟着N个消息字节,每个消息由一个64位的整数偏移将该消息的起始字节位置放在该分区上发送给该主题的所有消息流中,每个消息的磁盘格式如下:每个日志文件都以第一个消息的偏移量命名因此,第一个创建的文件将是00000000000.kafka,每个附加文件将有一个大约S字节的前一个文件的整数名称,其中S是配置中给出的最大日志文件大小。
记录的确切二进制格式是版本化的,并作为标准接口进行维护,因此记录批次可以在生产者,经纪人和客户端之间传输,而无需在需要时重新复制或转换。前一部分包含有关记录的磁盘格式的详细信息。
消息偏移量用作消息ID是不常见的。我们最初的想法是使用生产者生成的GUID,并在每个代理上维护从GUID到偏移量的映射。但是由于消费者必须为每个服务器维护一个ID,所以GUID的全局唯一性没有任何价值。而且,维护从随机id到偏移映射的复杂性需要一个重量级的索引结构,它必须与磁盘同步,本质上需要一个完整的持久随机访问数据结构。因此,为了简化查找结构,我们决定使用一个简单的每分区原子计数器,它可以与分区ID和节点ID相结合来唯一标识一个消息。这使得查找结构更简单,尽管每个消费者请求的多个查找仍然是可能的。然而,一旦我们决定在一个计数器上,跳转到直接使用偏移看起来很自然 - 毕竟是一个分区独特的单调递增整数。由于消费者API隐藏了偏移量,所以这个决定最终是一个实现细节,我们采用了更高效的方法。
写:
该日志允许序列附加,总是去最后一个文件。 当文件达到可配置的大小(比如1GB)时,该文件将被转存到新文件中。 该日志有两个配置参数:M,它给出在强制操作系统将文件刷新到磁盘之前要写入的消息的数量,以及S,在强制刷新之后给出秒数。 这提供了一个持久保证,即在系统崩溃的情况下,最多可以丢失M条消息或S秒的数据。
读:
通过给出消息的64位逻辑偏移量和S字节的最大块大小来完成读取。这将返回包含在S字节缓冲区中的消息的迭代器。 S的意图是大于任何单个消息,但是在消息异常大的情况下,可以多次重试读取,每次将缓冲区大小加倍,直到消息被成功读取。可以指定最大消息和缓冲区大小,以使服务器拒绝大于某个大小的消息,并为客户端提供最大限度的绑定,以便获取完整的消息。读取缓冲区可能以部分消息结束,这很容易通过大小分界来检测。
从偏移量读取的实际过程要求首先定位存储数据的日志段文件,从全局偏移值计算文件特定的偏移量,然后从该文件偏移量中读取。搜索是按照针对每个文件保持的内存范围的简单二分搜索变化完成的。
日志提供了获取最近写入的消息的能力,以允许客户从“现在”开始订阅。在消费者未能在其SLA指定的天数内消费其数据的情况下,这也是有用的。在这种情况下,当客户端试图消耗一个不存在的偏移量时,会给它一个OutOfRangeException异常,并且可以重置自身,也可以根据用例情况进行失败。
以下是发送给消费者的结果格式:
删除:
数据一次删除一个日志段。 日志管理器允许可插入的删除策略来选择哪些文件符合删除条件。 当前策略删除所有修改时间超过N天的日志,尽管保留最后N GB的策略也可能有用。 为了避免锁定读取,同时仍然允许删除修改段列表,我们使用了写时复制样式的段列表实现,它提供了一致的视图,允许二进制搜索在日志段的不可变静态快照视图上进行,同时删除正在进行。
保障:
该日志提供了配置参数M,该参数控制在强制刷新到磁盘之前写入的最大消息数。启动时,将运行一个日志恢复过程,对最新日志段中的所有消息进行迭代,并验证每个消息条目是否有效。如果消息条目的大小和偏移量之和小于文件的长度,则消息条目有效,并且消息有效载荷的CRC32与存储在消息中的CRC相匹配。如果检测到损坏,日志将被截断为最后一个有效的偏移量。
请注意,必须处理两种损坏:由于崩溃而丢失未写入的块的截断以及将无意义块添加到文件的损坏。这是因为操作系统通常不能保证文件索引节点和实际块数据之间的写入顺序,所以除了丢失写入的数据之外,如果索引节点更新为新的大小,文件可以获得无意义的数据,在写入包含该数据的块之前发生崩溃。 CRC检测到这个角落的情况,并防止它损坏日志(虽然不成文的消息,当然,丢失)。
分配:
消费者偏移跟踪:
高级消费者跟踪它在每个分区中消耗的最大偏移量,并周期性地提交其偏移量向量,以便在重新启动时从这些偏移量恢复。卡夫卡提供了一个选项,可以将给定消费者群体的所有偏移量存储在指定的经纪人(对于该组)中,称为抵消经理。即该消费者组中的任何消费者实例应该将其偏移提交和提取发送给该偏移管理器(经纪人)。高级用户自动处理这个问题。如果您使用简单的消费者,则需要手动管理偏移量。这在Java简单使用者中是不支持的,它只能在ZooKeeper中提交或提取偏移量。如果您使用Scala简单使用者,您可以发现偏移量管理器,并明确提交或提取偏移量管理器的偏移量。消费者可以通过向任何Kafka经纪人发出GroupCoordinatorRequest并读取将包含抵消经理的GroupCoordinatorResponse来查找其抵消经理。然后,消费者可以继续从偏移管理器代理处提交或提取偏移量。在偏移量管理器移动的情况下,消费者将需要重新发现偏移量管理器。如果你想手动管理你的偏移,你可以看看这些代码示例,解释如何发出OffsetCommitRequest和OffsetFetchRequest。
当偏移量管理器接收到OffsetCommitRequest时,它将请求附加到名为__consumer_offsets的特定压缩Kafka主题。只有在偏移量主题的所有副本都接收到偏移量后,偏移量管理器才会向使用者发送成功的偏移量提交响应。如果偏移无法在可配置的超时内复制,则偏移提交将失败,并且客户可能会在退出后重试提交。 (这是由高级用户自动完成的。)代理定期压缩偏移量主题,因为它只需要维护每个分区的最近的偏移量提交。偏移量管理器还将偏移量缓存在内存表中以快速提供偏移量提取。
当偏移量管理器接收到偏移量提取请求时,它只是从偏移量缓存中返回最后提交的偏移量向量。如果偏移量管理器刚刚启动,或者它刚成为一组新的消费者组的偏移量管理器(通过成为偏移量主题分区的领导者),则可能需要将偏移量主题分区加载到缓存中。在这种情况下,偏移量获取将失败,并产生OffsetsLoadInProgress异常,并且消费者可能在退避后重试OffsetFetchRequest。 (这是由高级用户自动完成的。)
从ZooKeeper迁移到Kafka:
早期版本中的Kafka使用者默认在ZooKeeper中存储它们的偏移量。 可以通过以下步骤将这些消费者迁移到Kafka中:
在消费者配置中设置offsets.storage = kafka和dual.commit.enabled = true。 做一个消费者的滚动反弹,然后确认你的消费者是健康的。 在消费者配置中设置dual.commit.enabled = false。 做一个消费者的滚动反弹,然后确认你的消费者是健康的。
如果您设置了offsets.storage = zookeeper,则还可以使用上述步骤执行回滚(即,从Kafka迁移回ZooKeeper)。
ZooKeeper目录
下面给出了用于消费者和经纪人之间协调的ZooKeeper结构和算法。
符号:
当一个路径中的元素被表示为[xyz]时,这意味着xyz的值不是固定的,并且实际上对于xyz的每个可能值都有一个ZooKeeper znode。 例如/ topics / [topic]将是一个名为/ topics的目录,其中包含每个主题名称的子目录。 还给出了数值范围,例如[0 ... 5]来指示子目录0,1,2,3,4。箭头 - >用于指示znode的内容。 例如/ hello - > world会指示一个包含值“world”的znode / hello。
代理节点注册表:
/brokers/ids/[0...N] --> {"jmx_port":...,"timestamp":...,"endpoints":[...],"host":...,"version":...,"port":...} (ephemeral node)这是所有当前代理节点的列表,每个代理节点都提供一个唯一的逻辑代理标识符,它将消息标识给消费者(必须作为其配置的一部分给出)。 启动时,代理节点通过在/ brokers / id下创建逻辑代理标识创建znode进行注册。 逻辑代理标识的目的是允许代理移动到不同的物理机器而不影响用户。 尝试注册已在使用的代理标识(例如,因为两个服务器配置了相同的代理标识)会导致错误。由于代理使用临时znode在ZooKeeper中进行注册,因此该注册是动态的,并且在代理关闭或死亡(从而通知消费者不再可用)时将消失。
Broker Topic注册:
/brokers/topics/[topic]/partitions/[0...N]/state --> {"controller_epoch":...,"leader":...,"version":...,"leader_epoch":...,"isr":[...]} (ephemeral node)每个代理在其维护的主题下注册自己,并存储该主题的分区数量。
消费者和消费者群体:
主题的消费者也在ZooKeeper中注册,以便相互协调并平衡数据的消耗。 消费者也可以通过设置offsets.storage = zookeeper将他们的偏移量存储在ZooKeeper中。 但是,这个偏移量存储机制将在未来的版本中被弃用。 因此,建议将抵消存储迁移到Kafka。
多个消费者可以组成一个小组,共同消费一个主题。 在同一组中的每个消费者被给予共享的group_id。 例如,如果一个消费者是您在三台机器上运行的foobar流程,那么您可以将这组消费者分配给“foobar”。 该组ID是在消费者的配置中提供的,并且是告诉消费者它属于哪个组的消息的方式。
一个组中的消费者尽可能公平地划分分区,每个分区恰好被消费者组中的一个消费者消费。
消费者ID注册表:
除了群组中的所有消费者共享的group_id之外,每个消费者还被赋予一个临时唯一的consumer_id(形式为hostname:uuid)用于识别。 消费者ID在以下目录中注册。
/consumers/[group_id]/ids/[consumer_id] --> {"version":...,"subscription":{...:...},"pattern":...,"timestamp":...} (ephemeral node)组中的每个用户都在其组中注册,并使用其consumer_id创建一个znode。 znode的值包含<topic,#streams>的映射。 此ID仅用于识别组中当前处于活动状态的每个消费者。 这是一个短暂节点,所以如果消费者进程死亡,它将消失。
消费者Offsets:
消费者跟踪他们在每个分区中消耗的最大偏移量。 如果offsets.storage = zookeeper,则此值存储在ZooKeeper目录中。
/consumers/[group_id]/offsets/[topic]/[partition_id] --> offset_counter_value (persistent node)
分区所有者注册表:
每个代理分区由给定使用者组中的单个消费者使用。 在消费开始之前,消费者必须确定给定分区的所有权。 为了建立它的所有权,消费者将自己的ID写在它声称的特定经纪人分区下的临时节点中。
/consumers/[group_id]/owners/[topic]/[partition_id] --> consumer_node_id (ephemeral node)
群集ID:
群集ID是分配给Kafka群集的唯一且不可变的标识符。 群集ID最多可以有22个字符,允许的字符是由正则表达式[a-zA-Z0-9 _ \ - ] +定义的,对应于不带填充的URL安全的Base64变体使用的字符。 从概念上讲,它是在第一次启动集群时自动生成的。
在实施方面,当第一次成功启动版本为0.10.1或更高版本的代理时,会生成该代理。 代理尝试在启动期间从/ cluster / id znode获取群集标识。 如果znode不存在,那么代理会生成一个新的集群标识并使用此集群标识创建znode。
Broker node注册:
Broker节点基本上是独立的,所以他们只发布他们有什么信息。 代理加入时,会在代理节点注册表目录下进行注册,并写入有关其主机名和端口的信息。 代理还在代理主题注册表中注册现有主题及其逻辑分区的列表。 在代理上创建新主题时会动态注册。
消费者注册算法:
当消费者启动时,它执行以下操作:
在其组中注册消费者ID注册。 在消费者ID注册表下注册关于更改(新消费者加入或任何现有的消费者离开)的手表。 (每次更改都会触发更改的消费者所属的所有消费者之间的再平衡。) 在经纪人ID注册表下注册一个监视变更(新的经纪人加入或任何现有的经纪人离开)。 (每个变化都会触发所有消费群体中的所有消费者重新平衡。) 如果消费者使用主题过滤器创建消息流,则还会在代理主题注册表下注册关于更改(新增主题)的监视。 (每次更改都将触发对可用主题的重新评估,以确定主题过滤器允许哪些主题。新的允许主题将触发消费者组内所有消费者之间的重新平衡。 强迫自己在消费群体内重新平衡。
消费者重新平衡算法:
消费者重新平衡算法允许组中的所有消费者就哪个消费者正在消费哪个分区达成共识。 消费者重新平衡是在每个添加或删除同一组内的代理节点和其他消费者时触发的。 对于给定的主题和给定的消费者群体,经纪人分区在群组内的消费者之间平均分配。 分区总是由单个用户使用。 这个设计简化了实现。 如果我们允许一个分区被多个消费者同时使用,那么分区上就会出现争用,并且需要某种锁定。 如果消费者比分区多,一些消费者就根本得不到任何数据。 在重新平衡期间,我们尝试以这种方式将分区分配给消费者,以减少每个消费者必须连接的代理节点的数量。
每位消费者在重新平衡期间执行以下操作:
1. For each topic T that C<sub>i</sub> subscribes to 2. let P<sub>T</sub> be all partitions producing topic T 3. let C<sub>G</sub> be all consumers in the same group as C<sub>i</sub> that consume topic T 4. sort P<sub>T</sub> (so partitions on the same broker are clustered together) 5. sort C<sub>G</sub> 6. let i be the index position of C<sub>i</sub> in C<sub>G</sub> and let N = size(P<sub>T</sub>)/size(C<sub>G</sub>) 7. assign partitions from i*N to (i+1)*N - 1 to consumer C<sub>i</sub> 8. remove current entries owned by C<sub>i</sub> from the partition owner registry 9. add newly assigned partitions to the partition owner registry (we may need to re-try this until the original partition owner releases its ownership)
当一个消费者触发再平衡时,同一时间内同一群体内的其他消费者应该重新平衡。
3.11 OPERATIONS
以下是一些基于LinkedIn使用和经验实际运行Kafka作为生产系统的信息。 请给我们任何你知道的额外提示。
基本的Kafka操作:
本节将回顾您将在Kafka集群上执行的最常见操作。 所有在本节中回顾的工具都可以在Kafka发行版的bin/目录下找到,如果没有参数运行,每个工具都会打印所有可能的命令行选项的详细信息。
添加和删除主题:
您可以选择手动添加主题,或者在数据首次发布到不存在的主题时自动创建主题。 如果主题是自动创建的,那么您可能需要调整用于自动创建的主题的默认主题配置(http://kafka.apache.org/documentation/#topicconfigs)。
使用主题工具添加和修改主题:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --create --topic my_topic_name --partitions 20 --replication-factor 3 --config x=y
复制因子控制有多少服务器将复制每个写入的消息。如果复制因子为3,则最多有2个服务器可能会失败,然后您将无法访问数据。我们建议您使用2或3的复制因子,以便在不中断数据消耗的情况下透明地反弹机器。
分区计数控制主题将被分成多少个日志。分区计数有几个影响。首先,每个分区必须完全适合一台服务器。所以,如果你有20个分区,完整的数据集(和读写负载)将由不超过20个服务器(不包括副本)处理。最后,分区数会影响消费者的最大并行度。这在概念部分更详细地讨论(http://kafka.apache.org/documentation/#intro_consumers)。
每个分片分区日志都放在自己的Kafka日志目录下的文件夹中。这些文件夹的名称由主题名称组成,由破折号( - )和分区ID附加。由于典型的文件夹名称长度不能超过255个字符,所以主题名称的长度会受到限制。我们假设分区的数量不会超过10万个。因此,主题名称不能超过249个字符。这在文件夹名称中留下了足够的空间以显示短划线和可能的5位长的分区ID。
在命令行上添加的配置会覆盖服务器的默认设置,例如应该保留数据的时间长度。此处(http://kafka.apache.org/documentation/#topicconfigs)记录了完整的每个主题配置。
修改主题:
您可以使用相同的主题工具更改主题的配置或分区。
要添加分区,你可以做
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name --partitions 40
请注意,分区的一个用例是对数据进行语义分区,并且添加分区不会更改现有数据的分区,因此如果依赖该分区,则可能会影响消费者。 也就是说,如果数据是通过哈希(键)%number_of_partitions进行分区的,那么这个分区可能会通过添加分区进行混洗,但Kafka不会尝试以任何方式自动重新分配数据。
要添加配置:
> bin/kafka-configs.sh --zookeeper zk_host:port/chroot --entity-type topics --entity-name my_topic_name --alter --add-config x=y
要删除配置:
> bin/kafka-configs.sh --zookeeper zk_host:port/chroot --entity-type topics --entity-name my_topic_name --alter --delete-config x
最后删除一个主题:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --delete --topic my_topic_name
Kafka目前不支持减少某个主题的分区数量。在这里(http://kafka.apache.org/documentation/#basic_ops_increase_replication_factor)可以找到更改主题复制因子的说明。
优雅的shutdown:
Kafka集群将自动检测到任何代理关机或故障,并为该机器上的分区选择新的领导。 无论服务器出现故障还是因为维护或配置更改而故意停机,都会发生这种情况。 对于后一种情况,Kafka支持停止服务器的更优雅的机制,而不仅仅是杀死它。 当服务器正常停止时,它有两个优化,它将利用:
它将所有日志同步到磁盘,以避免在重新启动时需要进行任何日志恢复(即验证日志尾部的所有消息的校验和)。 日志恢复需要时间,所以这加速了故意的重新启动。
它将在关闭之前将服务器领导者的任何分区迁移到其他副本。 这将使领导传输更快,并将每个分区不可用的时间缩短到几毫秒。
只要服务器停止而不是通过硬杀死,同步日志就会自动发生,但受控领导迁移需要使用特殊设置:
controlled.shutdown.enable=true
请注意,如果代理上托管的所有分区都具有副本(即复制因子大于1,并且这些副本中至少有一个存活),则受控关闭只能成功。 这通常是你想要的,因为关闭最后一个副本会使主题分区不可用。
领导均衡:
每当broker 停止或崩溃的领导,broker 的分区转移到其他副本。 这意味着,在代理重新启动时,默认情况下,它将只是所有分区的跟随者,这意味着它不会用于客户端读取和写入。
为了避免这种不平衡,卡夫卡有一个首选复制品的概念。 如果分区的副本列表为1,5,9,则节点1首选为节点5或9的组长,因为它在副本列表中较早。 您可以通过运行以下命令让Kafka集群尝试恢复已恢复副本的领导地位:
> bin/kafka-preferred-replica-election.sh --zookeeper zk_host:port/chroot
由于运行此命令可能很乏味,您也可以通过设置以下配置来自动配置Kafka:
auto.leader.rebalance.enable=true
在机架之间平衡复制副本:
机架感知功能可以跨不同机架传播相同分区的副本。 这扩展了Kafka为经纪人故障提供的担保,以弥补机架故障,如果机架上的所有经纪人一次失败,则可以限制数据丢失的风险。 该功能也可以应用于其他代理分组,例如EC2中的可用区域。
您可以通过向代理配置添加属性来指定代理属于特定机架:
broker.rack=my-rack-id
当一个主题被创建,修改或副本被重新分配时,机架约束将被确认,确保副本跨越尽可能多的机架(分区将跨越min(#racks,replication-factor)不同的机架)。
用于向代理分配副本的算法可确保每个代理的领导者数量将保持不变,而不管代理之间如何分布。 这确保平衡的吞吐量。
但是,如果机架被分配不同数量的经纪人,副本的分配将不均匀。 具有较少代理的机架将获得更多复制副本,这意味着他们将使用更多存储并将更多资源投入复制。 因此,每个机架配置相同数量的代理是明智的。
镜像群集之间的数据:
我们指的是在“镜像”之间复制Kafka集群之间的数据的过程,以避免与单个集群中的节点之间发生的复制混淆。 Kafka附带了一个在Kafka集群之间镜像数据的工具。该工具从源集群中消耗并产生到目标集群。这种镜像的常见用例是在另一个数据中心提供副本。这个场景将在下一节中更详细的讨论。
您可以运行许多这样的镜像过程来提高吞吐量和容错能力(如果一个进程死亡,其他进程将承担额外的负载)。
将从源群集中的主题中读取数据,并将其写入目标群集中具有相同名称的主题。事实上,镜子制造商只不过是一个卡夫卡消费者和生产商联合在一起。
源和目标集群是完全独立的实体:它们可以有不同数量的分区,偏移量也不会相同。由于这个原因,镜像集群并不是真正意义上的容错机制(因为消费者的地位将会不同)。为此,我们建议使用正常的群集内复制。然而,镜像制作者进程将保留并使用消息密钥进行分区,所以在每个密钥的基础上保存顺序。
以下示例显示如何从输入集群中镜像单个主题(名为my-topic):
> bin/kafka-mirror-maker.sh --consumer.config consumer.properties --producer.config producer.properties --whitelist my-topic
请注意,我们使用--whitelist选项指定主题列表。此选项允许使用Java风格的正则表达式的任何正则表达式。因此,您可以使用--whitelist'A | B'来镜像名为A和B的两个主题。或者您可以使用--whitelist'*'来镜像所有主题。确保引用任何正则表达式以确保shell不会尝试将其展开为文件路径。为了方便起见,我们允许使用“,”而不是“|”指定主题列表。
有时候更容易说出你不想要的东西。您可以使用--blacklist来说明要排除的内容,而不是使用--whitelist来表示要镜像的内容。这也需要一个正则表达式的参数。但是,启用新的使用者时(即在使用者配置中定义了bootstrap.servers)时,不支持--blacklist。
将镜像与配置auto.create.topics.enable = true结合使用,可以创建一个副本群集,即使添加了新的主题,也可以自动创建和复制源群集中的所有数据。
检查消费者的位置:
有时看到你的消费者的位置是有用的。 我们有一个工具,可以显示消费者群体中所有消费者的位置,以及他们所在日志的结尾。 要在名为my-group的使用者组上运行此工具,使用名为my-topic的主题将如下所示:
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group
这个工具也适用于基于ZooKeeper的消费者:
> bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --describe --group my-group
管理消费者群体:
通过ConsumerGroupCommand工具,我们可以列出,描述或删除使用者组。 请注意,删除仅在组元数据存储在ZooKeeper中时可用。 当使用新的使用者API(http://kafka.apache.org/documentation.html#newconsumerapi)(代理处理分区处理和重新平衡的协调)时,当该组的最后提交的偏移量到期时,该组被删除。 例如,要列出所有主题中的所有消费者组:
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
为了查看偏移量,如前所述,我们“描述”这样的消费者组:
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test-consumer-group
如果您正在使用旧的高级使用者并在ZooKeeper中存储组元数据(即,offsets.storage = zookeeper),请传递--zookeeper而不是bootstrap-server:
> bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --list
扩展群集:
将服务器添加到Kafka集群非常简单,只需为其分配唯一的代理ID,然后在新服务器上启动Kafka。但是,这些新的服务器不会自动分配任何数据分区,除非将分区移动到这些分区,否则直到创建新主题时才会执行任何工作。所以通常当你将机器添加到你的群集中时,你会想把一些现有的数据迁移到这些机器上。
数据迁移过程是手动启动的,但是完全自动化。下面介绍的是,Kafka会将新服务器添加为正在迁移的分区的跟随者,并允许其完全复制该分区中的现有数据。当新服务器完全复制了此分区的内容并加入了同步副本时,其中一个现有副本将删除其分区的数据。
分区重新分配工具可用于跨代理移动分区。理想的分区分布将确保所有代理的数据加载和分区大小。分区重新分配工具不具备自动研究Kafka集群中的数据分布并移动分区以获得均匀负载分配的功能。因此,管理员必须找出哪些主题或分区应该移动。
分区重新分配工具可以运行在3个互斥的模式中:
--generate:在此模式下,给定主题列表和经纪人列表,该工具会生成候选重新分配,以将指定主题的所有分区移至新经纪人。 此选项仅提供了一种便捷的方式,可以根据主题和目标代理列表生成分区重新分配计划。 --execute:在此模式下,该工具根据用户提供的重新分配计划启动分区重新分配。 (使用--reassignment-json-file选项)。 这可以是由管理员制作的自定义重新分配计划,也可以是使用--generate选项提供的自定义重新分配计划 --verify:在此模式下,该工具会验证上次执行过程中列出的所有分区的重新分配状态。 状态可以是成功完成,失败或正在进行
自动将数据迁移到新机器:
分区重新分配工具可用于将当前一组经纪人的一些主题移到新增的经纪人。这在扩展现有集群时通常很有用,因为将整个主题移动到新的代理集比移动一个分区更容易。用于这样做时,用户应该提供应该移动到新的经纪人集合和新的经纪人的目标列表的主题列表。然后,该工具在新的代理集合上均匀分配给定主题列表的所有分区。在此过程中,主题的复制因子保持不变。有效地,主题输入列表的所有分区副本都从旧的代理集合移动到新添加的代理。
例如,以下示例将把主题foo1,foo2的所有分区移动到新的代理集5,6。在本次移动结束时,主题foo1和foo2的所有分区将仅存在于代理5,6上。
由于该工具接受主题的输入列表作为json文件,因此首先需要确定要移动的主题并创建json文件,如下所示:
> cat topics-to-move.json
一旦json文件准备就绪,使用分区重新分配工具来生成候选分配:
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file topics-to-move.json --broker-list "5,6" --generate
该工具会生成一个候选分配,将所有分区从主题foo1,foo2移动到brokers 5,6。 但是,请注意,在这一点上,分区运动还没有开始,它只是告诉你当前的任务和建议的新任务。 应该保存当前的分配,以防你想要回滚到它。 新的任务应该保存在一个json文件(例如expand-cluster-reassignment.json)中,并使用--execute选项输入到工具中,如下所示:
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
最后,可以使用--verify选项来检查分区重新分配的状态。 请注意,与--verify选项一起使用相同的expand-cluster-reassignment.json(与--execute选项一起使用):
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
自定义分区分配和迁移:
分区重新分配工具也可用于选择性地将分区的副本移动到特定的一组代理。 当以这种方式使用时,假定用户知道重新分配计划并且不需要该工具产生候选重新分配,有效地跳过 - 生成步骤并直接移动到 - 执行步骤
例如,以下示例将主题foo1的分区0移动到主题foo2的代理5,6和分区1到代理2,3:
第一步是在json文件中手工制作自定义重新分配计划:
> cat custom-reassignment.json
然后,使用带有--execute选项的json文件来启动重新分配过程:
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file custom-reassignment.json --execute
可以使用--verify选项来检查分区重新分配的状态。 请注意,与--verify选项一起使用相同的expand-cluster-reassignment.json(与--execute选项一起使用):
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file custom-reassignment.json --verify
退役brokers:
分区重新分配工具没有能力为退役代理自动生成重新分配计划。 因此,管理员必须提出重新分配计划,将代理上托管的所有分区的副本移动到其他代理。 这可能比较单调,因为重新分配需要确保所有副本不会从退役经纪人转移到另一个经纪人。 为了使这个过程毫不费力,我们计划在未来为退役经纪人添加工具支持。
增加复制因素:
增加现有分区的复制因子很容易。 只需在自定义重新分配json文件中指定额外的副本,并将其与--execute选项一起使用,以增加指定分区的复制因子。
例如,以下示例将主题foo的分区0的复制因子从1增加到3.在增加复制因子之前,该分区的唯一副本存在于代理5上。作为增加复制因子的一部分,我们将添加更多副本 经纪人6和7。
第一步是在json文件中手工制作自定义重新分配计划:
> cat increase-replication-factor.json
然后,使用带有--execute选项的json文件来启动重新分配过程:
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file increase-replication-factor.json --execute
可以使用--verify选项来检查分区重新分配的状态。 请注意,与--verify选项一起使用相同的increase-replication-factor.json(与--execute选项一起使用):
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file increase-replication-factor.json --verify
您还可以使用kafka-topics工具验证复制因子的增加情况:
> bin/kafka-topics.sh --zookeeper localhost:2181 --topic foo --describe
限制数据迁移过程中的带宽使用:
Kafka允许您将复制流量应用于复制流量,设置用于将复制副本从机器移动到机器的带宽的上限。 这在重新平衡群集,引导新代理或添加或删除代理时非常有用,因为这限制了这些数据密集型操作对用户的影响。
有两个接口可以用来加油门。 最简单也是最安全的是在调用kafka-reassign-partitions.sh时应用一个节流阀,但也可以使用kafka-configs.sh直接查看和修改节流阀值。
例如,如果要执行重新平衡,使用下面的命令,它将以不超过50MB/s的速度移动分区:
$ bin/kafka-reassign-partitions.sh --zookeeper myhost:2181--execute --reassignment-json-file bigger-cluster.json —throttle 50000000
如果你想改变阀值,在重新平衡期间,比如增加吞吐量以便更快地完成,你可以通过重新运行execute命令来传递同样的reassignment-json-file:
$ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --execute --reassignment-json-file bigger-cluster.json --throttle 700000000
重新平衡完成后,管理员可以使用--verify选项检查重新平衡的状态。 如果重新平衡完成,油门将通过--verify命令删除。 一旦重新平衡完成,通过使用--verify选项运行该命令,管理员必须及时删除这个限制。 如果不这样做可能会导致定期复制流量受到限制。当执行--verify选项并且重新分配完成时,脚本将确认阀值已被移除:
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --verify --reassignment-json-file bigger-cluster.json
管理员也可以使用kafka-configs.sh验证分配的配置。 有两对节流阀配置用于管理节流过程。 阀值本身。 这是在代理级别使用动态属性配置的:
leader.replication.throttled.rate follower.replication.throttled.rate
还有一组枚举的复制副本:
leader.replication.throttled.replicas follower.replication.throttled.replicas
哪些是按主题配置的。 所有四个配置值都由kafka-reassign-partitions.sh自动分配(如下所述)。要查看阀值限制配置:
> bin/kafka-configs.sh --describe --zookeeper localhost:2181 --entity-type brokers
这显示应用于复制协议的领导者和追随者一方的节流阀。 默认情况下,双方都被分配相同的节流吞吐量值。要查看节流副本的列表,请执行以下操作:
> bin/kafka-configs.sh --describe --zookeeper localhost:2181 --entity-type topics #下面是输出结果 Configs for topic 'my-topic' are leader.replication.throttled.replicas=1:102,0:101, follower.replication.throttled.replicas=1:101,0:102
这里我们看到领导者节流器被应用于中间人102上的分区1和中间人101上的分区0.同样地,跟随者节流阀被应用于中间人101上的分区1和中间人102上的分区0。
默认情况下,kafka-reassign-partitions.sh将把leader油门应用到rebalance之前存在的所有副本,其中任何一个副本都可能是领导。 它会将跟随器油门应用到所有移动的目的地。 因此,如果broker101,102上有副本的分区,被重新分配到102,103,那么该分区的领导节流阀将被应用于101,102,并且随动节流阀将仅被应用于103。如果需要,还可以使用kafka-configs.sh上的--alter开关手动更改节流阀配置。
安全使用节制复制:
在使用节制复制时应该小心。 尤其是:
(1)阀值删除:一旦重新分配完成(通过运行kafka-reassign-partitions -verify),应及时移除阀值。 (2)确保进展:如果油门设置得太低,与传入的写入速率相比,复制可能无法进行。 这发生在:max(BytesInPerSec) > throttle
其中BytesInPerSec是监控生产者写入每个代理的写入吞吐量的指标。管理员可以使用以下指标监控重新平衡过程中的复制是否正在取得进展:
kafka.server:type=FetcherLagMetrics,name=ConsumerLag,clientId=([-.\w]+),topic=([-.\w]+),partition=([0-9]+)
#在复制期间,滞后应该不断减少。 如果度量不减少,那么管理员应该像上面描述的那样增加节流量。
设定配额:
配额覆盖和默认值可以在(用户,客户端ID),用户或客户端级别进行配置,如此处所述。 默认情况下,客户端收到一个无限制的配额。 可以为每个(用户,客户端ID),用户或客户端组设置自定义配额。
为(user = user1,client-id = clientA)配置自定义配额:
> bin/kafka-configs.sh --zookeeper localhost:2181 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-name user1 --entity-type clients --entity-name clientA
为user = user1配置自定义配额:
> bin/kafka-configs.sh --zookeeper localhost:2181 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-name user1
为客户端ID =客户端配置自定义配额:
> bin/kafka-configs.sh --zookeeper localhost:2181 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type clients --entity-name clientA
通过指定--entity-default选项而不是--entity-name,可以为每个(user,client-id),user或client-id组设置默认配额。为user = userA配置默认客户端配额:
> bin/kafka-configs.sh --zookeeper localhost:2181 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-name user1 --entity-type clients --entity-default
配置用户的默认配额:
> bin/kafka-configs.sh --zookeeper localhost:2181 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-default
配置client-id的默认配额:
> bin/kafka-configs.sh --zookeeper localhost:2181 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type clients --entity-default
以下是如何描述给定(用户,客户端ID)的配额:
> bin/kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type users --entity-name user1 --entity-type clients --entity-name clientA
描述给定用户的配额:
> bin/kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type users --entity-name user1
描述给定客户端ID的配额:
> bin/kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type clients --entity-name clientA
如果未指定实体名称,则描述指定类型的所有实体。 例如,描述所有用户:
> bin/kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type users
类似的(用户,客户):
> bin/kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type users --entity-type clients
通过在代理上设置这些配置,可以设置适用于所有客户端ID的默认配额。 这些属性仅在Zookeeper中未配置配额覆盖或默认配置时应用。 默认情况下,每个客户端ID都会收到一个无限制的配额。 以下设置每个生产者和消费者客户端的默认配额为10MB /秒。
quota.producer.default=10485760 quota.consumer.default=10485760
#请注意,这些属性将被弃用,并可能在未来版本中删除。 使用kafka-configs.sh配置的默认值优先于这些属性。
数据中心
有些部署需要管理跨多个数据中心的数据管道。我们推荐的方法是在每个数据中心部署一个本地的Kafka集群,每个数据中心的应用程序实例只与本地集群交互,并在集群之间进行镜像(http://kafka.apache.org/documentation/#basic_ops_mirror_maker)。
这种部署模式允许数据中心充当独立实体,并允许我们集中管理和调整数据中心之间的复制。这样,即使数据中心间的链路不可用,每个设施也可以独立运行:当发生这种情况时,镜像会落后,直到链路恢复正常时为止。
对于需要所有数据的全局视图的应用程序,可以使用镜像来提供具有从所有数据中心的本地群集镜像的聚合数据的群集。这些聚合群集用于需要完整数据集的应用程序的读取。
这不是唯一可能的部署模式。可以通过广域网读取或写入远程Kafka集群,但显然这将增加获取集群所需的任何延迟。
Kafka自然地在生产者和消费者中批量处理数据,因此即使在高延迟的连接上也可以实现高吞吐量。虽然可能需要使用socket.send.buffer.bytes和socket.receive.buffer.bytes配置来增加生产者,使用者和代理的TCP套接字缓冲区大小。在这里记录设置的适当方法。
通常不建议通过高延迟链路运行跨越多个数据中心的单个Kafka集群。这将对Kafka写入和ZooKeeper写入产生非常高的复制延迟,如果位置之间的网络不可用,Kafka和ZooKeeper都不会在所有位置保持可用。
kafka配置
重要的客户端配置:
最重要的old Scala生产者配置控制:
acks compression sync vs async production batch size (for async producers)
最重要的新Java生产者配置控制:
acks compression batch size
最重要的用户配置是 fetch size。所有配置都记录在配置部分(http://kafka.apache.org/documentation/#configuration)。
A Production Server Config:
以下是生产服务器配置示例:
# ZooKeeper zookeeper.connect=[list of ZooKeeper servers] # Log configuration num.partitions=8 default.replication.factor=3 log.dir=[List of directories. Kafka should have its own dedicated disk(s) or SSD(s).] # Other configurations broker.id=[An integer. Start with 0 and increment by 1 for each new broker.] listeners=[list of listeners] auto.create.topics.enable=false min.insync.replicas=2 queued.max.requests=[number of concurrent requests]
Java版本
从安全角度来看,建议您使用JDK 1.8的最新发布版本,因为较早的免费版本已经披露了安全漏洞。 LinkedIn目前正在使用G1收集器运行JDK 1.8 u5(希望升级到更新的版本)。 如果您决定使用G1收集器(当前的默认值),并且您仍然使用JDK 1.7,请确保您使用的是u51或更新版本。 LinkedIn试用了u21进行测试,但在该版本中,GC实现方面存在一些问题。 LinkedIn的调整看起来像这样:
-Xmx6g -Xms6g -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80
作为参考,这里是LinkedIn最繁忙的群集(峰值)的统计数据:
60 brokers 50k partitions (replication factor 2) 800k messages/sec in 300 MB/sec inbound, 1 GB/sec+ outbound
#调整看起来相当积极,但该集群中的所有brokers都有大约21ms的GC暂停时间的90%,而且他们每秒钟的GC少于1次。
硬件和操作系统
我们正在使用带有24GB内存的双核四核英特尔至强处理器。您需要足够的内存来缓存活动的读者和作者。 您可以通过假设您希望能够缓冲30秒并计算您的内存需求作为write_throughput * 30来执行内存需求的后期估计。
磁盘吞吐量很重要。 我们有8x7200转的SATA硬盘。 一般情况下,磁盘吞吐量是性能瓶颈,更多的磁盘更好。 根据配置刷新行为的方式,您可能会也可能不会从更昂贵的磁盘中受益(如果您经常强制刷新,那么更高RPM的SAS驱动器可能会更好)。
OS
Kafka应该在任何Unix系统上运行良好,并且已经在Linux和Solaris上进行了测试。我们已经看到在Windows和Windows上运行的一些问题目前还不是一个很好的支持平台,尽管我们很乐意改变这个问题。
这不太需要太多的操作系统级别的调整,但有两个潜在的重要的操作系统级别的配置:
文件描述符限制:Kafka为日志段和打开的连接使用文件描述符。 如果代理承载多个分区,则考虑代理至少需要(number_of_partitions)*(partition_size / segment_size)来跟踪代理所做的连接数量以外的所有日志段。 我们推荐至少100000个允许的代理进程文件描述符作为起点。最大套接字缓冲区大小:可以增加以实现数据中心之间的高性能数据传输,如此处所述(http://www.psc.edu/index.php/networking/641-tcp-tune)。
磁盘和文件系统
我们建议使用多个驱动器以获得良好的吞吐量,而不是与应用程序日志或其他操作系统文件系统活动共享用于Kafka数据的相同驱动器,以确保良好的延迟。您可以将这些驱动器一起RAID成单个卷或格式,并将每个驱动器安装为自己的目录。由于Kafka具有复制功能,RAID提供的冗余也可以在应用程序级别提供。这个选择有几个折衷。
如果您配置多个数据目录,则会将分区循环分配到数据目录。每个分区将完全位于其中一个数据目录中。如果分区间的数据不均衡,则可能导致磁盘之间的负载不均衡。
RAID可以更好地平衡磁盘之间的负载(尽管似乎并不总是如此),因为它在较低的级别上平衡负载。 RAID的主要缺点是写入吞吐量通常会大幅度降低可用磁盘空间。
RAID的另一个潜在好处是能够容忍磁盘故障。然而,我们的经验是,重建RAID阵列是如此I / O密集,它有效地禁用服务器,所以这不提供太多的实际可用性改进。
应用程序与操作系统flush管理
Kafka总是立即将所有数据写入文件系统,并支持配置刷新策略的功能,该策略控制何时使用刷新将数据从OS缓存中移出到磁盘上。可以控制该刷新策略,以在一段时间之后或者在写入一定数量的消息之后强制数据到磁盘。这个配置有几个选择。kafka最终必须调用fsync才能知道数据已被刷新。从任何未知的fsync'd日志段的崩溃中恢复时,Kafka将通过检查每个消息的CRC来检查其完整性,并在启动时执行的恢复过程中重建相应的偏移量索引文件。请注意,Kafka中的持久性不需要将数据同步到磁盘,因为失败的节点将始终从其副本中恢复。
我们建议使用完全禁用应用程序fsync的默认刷新设置。这意味着依靠操作系统和Kafka自己的后台刷新完成的背景刷新。这为大多数用途提供了最好的世界:无旋钮调谐,巨大的吞吐量和延迟,以及完全恢复保证。我们一般认为复制提供的保证比同步到本地磁盘更强,但是偏执狂仍然可能更喜欢同时支持fsync和应用程序级别的策略。使用应用程序级刷新设置的缺点是它的磁盘使用模式效率不高(它使操作系统在重新排序时没有什么回旋余地),并且可能会在大多数Linux文件系统块中的fsync写入文件时引入延迟,背景刷新做更多的细粒度页面级锁定。一般来说,您不需要对文件系统进行任何低级调整,但在接下来的几节中,我们将会介绍其中的一些内容,以防万一。
了解Linux操作系统flush行为
在Linux中,写入文件系统的数据在pagecache(https://en.wikipedia.org/wiki/Page_cache)中保存,直到必须写入磁盘(由于应用程序级fsync或操作系统自己的刷新策略)。 数据的刷新是通过一系列叫做pdflush的后台线程来完成的(或者在2.6.32内核中的“刷新线程”)。Pdflush有一个可配置的策略,用于控制在缓存中可以维护多少脏数据,以及在必须将数据写回到磁盘之前多久。 这个政策在这里描述。 当Pdflush无法跟上正在写入的数据速率时,最终会导致写入过程阻止写入延迟,从而减慢数据的积累。您可以通过执行来查看OS内存使用情况的当前状态:
> cat /proc/meminfo
这些值的含义在上面的链接中描述。使用页面缓存相对于进程内高速缓存来存储将被写出到磁盘的数据有几个优点:
I/O调度程序将连续的小写入批量转换为更大的物理写入,从而提高吞吐量。 I/O调度程序将尝试重新排列写入操作,以尽量减少磁盘磁头的移动,从而提高吞吐量。 它会自动使用机器上的所有可用内存
文件系统选择
Kafka使用磁盘上的常规文件,因此它不依赖于特定的文件系统。 然而,使用最多的两个文件系统是EXT4和XFS。 从历史上看,EXT4具有更多的用途,但最近对XFS文件系统的改进已经表明它具有更好的性能特征,而且不会影响稳定性。
使用各种文件系统创建和安装选项,在具有重要消息加载的群集上执行比较测试。 kafka监控的主要指标是“请求本地时间”,表示所附加操作的时间。 XFS导致当地时间好得多(160ms比250ms +最好的EXT4配置),以及更低的平均等待时间。 XFS性能也表现出较小的磁盘性能变化。
一般文件系统说明:
对于用于数据目录的任何文件系统,在Linux系统上,建议在安装时使用以下选项:
noatime:此选项禁止在读取文件时更新文件的atime(上次访问时间)属性。 这可以消除大量的文件系统写入,特别是在引导用户的情况下。 Kafka根本不依赖atime属性,因此禁用这个属性是安全的。
XFS记录:
XFS文件系统具有大量的自动调整功能,因此无需在文件系统创建时或挂载时对默认设置进行任何更改。 唯一值得考虑的调整参数是:
largeio:这会影响统计调用报告的首选I / O大小。 虽然这可以允许在更大的磁盘写入时获得更高的性能,但是实际上它对性能的影响很小或者没有影响。 nobarrier:对于具有电池支持缓存的底层设备,此选项可通过禁用定期写入刷新来提供更多的性能。 但是,如果底层设备运行良好,则会向文件系统报告不需要刷新,此选项不起作用。
EXT4记录:
EXT4是Kafka数据目录的文件系统的一个可选择的选项,但是获得最高的性能需要调整几个安装选项。 另外,这些选项在故障情况下通常是不安全的,并且会导致更多的数据丢失和损坏。 对于单个代理失败,这不是一个问题,因为可以擦除磁盘,并从集群重建副本。 在诸如停电等多故障情况下,这可能意味着不容易恢复的底层文件系统(因此是数据)损坏。 以下选项可以调整:
data=writeback: Ext4默认为data = ordered,这会在某些写入操作上产生强大的顺序。 卡夫卡不需要这样的顺序,因为它在所有未刷新的日志上进行非常偏执的数据恢复。 此设置消除了排序约束,似乎显着减少了延迟。 Disabling journaling: 日志是一个折衷:在服务器崩溃之后,它会使重新启动更快,但会引入大量额外的锁定,从而增加写入性能的差异。 那些不关心重启时间,想要减少写入延迟尖峰的主要来源,可以完全关闭日志。 commit=num_secs: 这调整了ext4向其元数据日志提交的频率。 将其设置为较低的值可以减少崩溃过程中丢失的未刷新数据。 将其设置为更高的值将提高吞吐量。 nobh: 当使用data =回写模式时,此设置控制额外的订购保证。 Kafka应该是安全的,因为我们不依赖写入顺序并提高吞吐量和延迟。 delalloc: 延迟分配意味着文件系统避免分配任何块直到物理写入发生。 这允许ext4分配很大的范围,而不是较小的页面,并有助于确保数据顺序写入。 这个功能非常适合吞吐量。 它似乎涉及到文件系统中的一些锁定,增加了一些延迟差异。
监控
Kafka在服务器和Scala客户端使用Yammer指标进行度量报告。 Java客户端使用Kafka度量标准,这是一个内置的度量标准注册表,最大限度地减少了传递到客户端应用程序的依赖关系。 两者都通过JMX公开度量标准,并且可以配置为使用可插入统计记录器来报告统计信息,以便连接到您的监控系统。
查看可用指标的最简单方法是启动jconsole并将其指向正在运行的kafka客户端或服务器; 这将允许浏览JMX的所有指标。我们对以下指标进行图形化和提醒:http://kafka.apache.org/documentation/#monitoring
生产者/消费者/连接/流的通用监控指标以下度量标准可用于生产者/消费者/连接器/流实例。http://kafka.apache.org/documentation/#selector_monitoring
生产者/消费者/连接/流的Common Per-broker指标,以下度量标准可用于生产者/消费者/连接器/流实例。 http://kafka.apache.org/documentation/#common_node_monitoring
生产者监督以下度量标准适用于生产者实例。 http://kafka.apache.org/documentation/#producer_monitoring
生产者发件人指标:http://kafka.apache.org/documentation/#producer_sender_monitoring
新的消费者监控,以下度量标准适用于新的客户实例:http://kafka.apache.org/documentation/#new_consumer_monitoring
连接监视Connect工作进程包含所有生产者和消费者指标以及特定于Connect的指标。 工作进程本身有很多指标,而每个连接器和任务都有其他指标(http://kafka.apache.org/documentation/#connect_monitoring)。
流监控:
Kafka Streams实例包含所有生产者和消费者指标以及特定于流的其他指标。 默认Kafka Streams有两个记录级别的指标:调试和信息。 调试级别记录所有度量标准,而信息级别仅记录线程级度量标准。
请注意,这些指标有三层结构。 顶层有每线程指标。 每个线程都有自己的指标的任务。 每个任务都有一些处理器节点和自己的度量标准。 每个任务也有一些州商店和记录缓存,都有自己的指标。
使用以下配置选项来指定您希望收集哪些指标:
metrics.recording.level="info"
线程度量
以下所有指标的记录级别都是“info”:http://kafka.apache.org/documentation/#kafka_streams_thread_monitoring
任务度量标准
以下所有指标都具有“调试”的记录级别:http://kafka.apache.org/documentation/#kafka_streams_task_monitoring
处理器节点度量标准
以下所有指标都具有“调试”的记录级别:http://kafka.apache.org/documentation/#kafka_streams_node_monitoring
状态存储指标
以下所有指标都具有“调试”的记录级别:http://kafka.apache.org/documentation/#kafka_streams_store_monitoring
记录缓存度量标准
以下所有指标都具有“调试”的记录级别:http://kafka.apache.org/documentation/#kafka_streams_cache_monitoring
其他
我们建议监视GC时间和其他统计数据以及各种服务器状态,如CPU利用率,I/O服务时间等。在客户端,我们建议监视消息/字节速率(全局和主题),请求速率/大小/ 时间,在消费者方面,所有分区之间的消息的最大滞后和最小提取请求率。 对于一个消费者来说,最大滞后需要小于一个阈值,并且最小读取率需要大于0。
审计
我们所做的最后一个提示是关于数据交付的正确性。 我们审计发送的每条消息都被所有消费者使用,并测量发生的延迟。 对于重要的话题,如果在一定的时间内没有达到一定的完整性,我们会提醒。
ZooKeeper
稳定的版本。目前稳定的分支是3.4,该分支的最新版本是3.4.9。
操作ZooKeeper:
在操作上,我们为健康的ZooKeeper安装做了以下工作:
物理/硬件/网络布局中的冗余:尽量不要将它们全部放在同一个机架上,体面的(但不要硬件)硬件,尽量保持冗余电源和网络路径等。一个典型的ZooKeeper集成有5个7台服务器,分别容忍2台服务器和3台服务器。如果你有一个小的部署,那么使用3台服务器是可以接受的,但请记住,在这种情况下,你只能容忍1台服务器。 I/O隔离:如果你做了很多写类型的流量,你几乎肯定会把事务日志放在一个专用的磁盘组上。写入事务日志是同步的(但为了性能而批处理),因此并发写入会显着影响性能。 ZooKeeper快照可以是并发写入的一个源,理想情况下应该写在与事务日志分开的磁盘组上。快照以异步方式写入磁盘,因此通常可以与操作系统和消息日志文件共享。您可以将服务器配置为使用具有dataLogDir参数的单独磁盘组。 应用程序隔离:除非您真的了解要安装在同一个框中的其他应用程序的应用程序模式,否则独立运行ZooKeeper(尽管这可能是与硬件功能平衡的行为)是一个好主意。 关注虚拟化:它可以工作,具体取决于你的集群布局和读/写模式和SLA,但是由虚拟化层引入的微小的开销可以加起来并且离开ZooKeeper,因为它可以是非常时间敏感的 ZooKeeper配置:这是java,确保你给它足够的堆空间(我们通常用3-5G运行它们,但是这主要是由于我们在这里的数据集的大小)。不幸的是,我们没有一个好的公式,但是请记住,允许更多的ZooKeeper状态意味着快照可能变大,而大的快照会影响恢复时间。实际上,如果快照变得太大(几千兆字节),那么您可能需要增加initLimit参数,以便为服务器提供足够的时间来恢复和加入整体。 监控:JMX和4个字母的单词(4lw)命令都是非常有用的,它们在某些情况下是重叠的(在这种情况下,我们更喜欢4个字母的命令,它们看起来更具可预测性,或者最起码, LI监测基础设施) 不要过度构建集群:特别是在写入繁重的使用模式下,大型集群意味着大量的集群内通信(写入和后续集群成员更新的法定数量),但是不会对其进行低级构建(并且冒险淹没集群)。有更多的服务器添加到您的读取容量。
总的来说,我们尽可能保持ZooKeeper系统小到可以处理负载(加上标准增长容量计划)并且尽可能简单。 与正式版本相比,我们尽量不要对配置或应用程序布局进行任何操作,也不要将其尽量保留。 由于这些原因,我们倾向于跳过操作系统打包的版本,因为它倾向于尝试将操作系统标准层次结构中的东西放在“杂乱”的位置,因为没有更好的方式来表达它。
3.12 安全
安全概述:
在版本0.9.0.0中,Kafka社区添加了许多独立或共同使用的功能,可以提高Kafka集群的安全性。 目前支持以下安全措施:
使用SSL或SASL对来自客户(生产者和消费者),其他 brokers和工具的 brokers的连接进行身份验证。 Kafka支持以下SASL机制:
SASL/GSSAPI(Kerberos) - 从版本0.9.0.0开始 SASL/PLAIN - 从版本0.10.0.0开始 SASL/SCRAM-SHA-256和SASL / SCRAM-SHA-512 - 从版本0.10.2.0开始
2. brokers到ZooKeeper的连接认证
3. 使用SSL在代理和客户之间,代理之间或代理和工具之间传输的数据加密(请注意,启用SSL时性能会降低,其大小取决于CPU类型和JVM实现。)
4. 由客户授权读/写操作
5. 授权是可插入的,并且支持与外部授权服务的集成
#值得注意的是,安全性是可选的 - 支持非安全的集群,以及经过身份验证的,未经身份验证的,加密的和未加密的客户端的混合。 以下指南介绍了如何在客户端和代理中配置和使用安全功能。
剩余部分请参考:http://kafka.apache.org/documentation/#security
