grafana结合zabbix数据对其他Pannel设置学习(三)
#紧接上文,我们已经大概了解了zabbix接入后的一些设置,那么再用数据出一些其他的面板。
一、Singlestat Panel
1.1 官网翻译学习
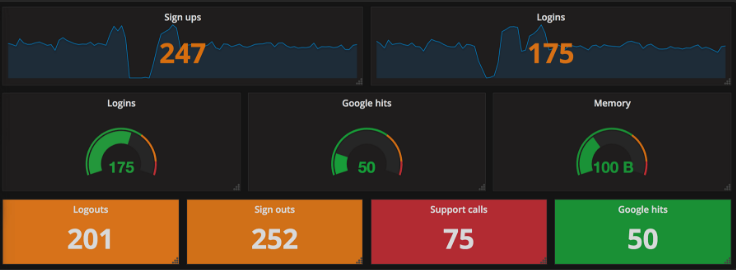
#上图为官方的例子样图
Singlestat面板允许您显示SINGLE系列的一个主要摘要统计。 它将系列缩减为单个数字(通过查看系列中的最大值,最小值,平均值或总和值)。 Singlestat还提供阈值来为统计或面板背景着色。 它还可以将单个数字转换为文本值,并显示该系列的迷你图摘要。
Singlestat面板配置之Options设置:
singlestat面板有一个普通的查询编辑器,允许像许多其他Panel一样定义精确的度量标准查询。 在“Options”选项卡中,可以访问Singlestat特定的功能。
Value(Singlestat Panel Configuration):
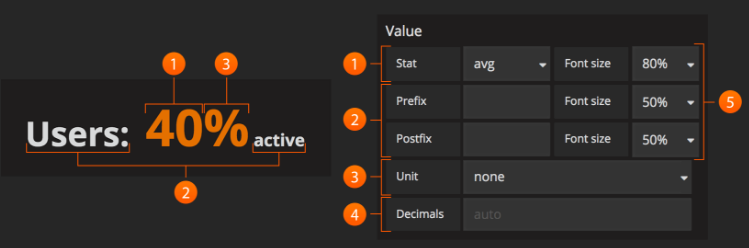
#上图为官网原图,下面是对上面数字地方的解释:
1. Stats: 统计字段允许您将整个查询减少的函数(最小值,最大值,平均值,当前值,总数,第一个值,增量值,范围)设置为单个值。 这会将整个查询减少为显示的单个汇总值。
min - 系列中的最小值 max - 系列中的最大值 avg - 系列中所有非空值的平均值 current - 系列中的最后一个值。 如果系列以null结尾,则将使用先前的值。 total - 系列中所有非空值的总和 first - 系列中的第一个值 delta - 系列中(计数器的)总增量增量。 尝试计算计数器重置,但这仅对单实例度量标准是准确的。 用于显示时间序列中的总计数器增加。 diff - 'current'(最后一个值)和'first'之间的差异。 range - 'min'和'max'之间的差异。 有用的是显示仪表的变化范围。
2. Prefix/Postfix: Prefix / Postfix字段允许您定义要在值before/after显示的自定义标签。 这里可以使用$__name变量来使用度量标准查询中的系列名称或别名。
3.Units: 单位将附加到面板中的Singlestat,并将遵循该值的颜色和阈值设置。
4.Decimals: Decimal字段允许覆盖自动小数精度,并显式设置它。
5.Font Size: 可以使用此部分选择Singlestat面板中不同文本的字体大小,即前缀,值和后缀。
Coloring:
Singlestat Panel配置的着色选项允许根据Singlestat值动态更改颜色。
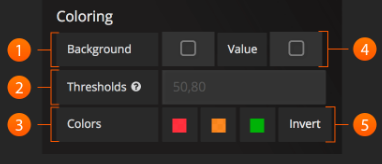
#上面是官网原图
Background: 此复选框将配置的阈值和颜色应用于Singlestat Panel背景的整体。
Thresholds: 根据Singlestat值,在面板中动态更改背景和值颜色。 阈值字段接受2个逗号分隔值,这些值表示直接对应于三种颜色的3个范围。 例如:如果阈值是70,90,那么第一种颜色代表<70,第二种颜色代表70和90之间,第三种颜色代表> 90。
Colors: 选择颜色和不透明度
Value: 此复选框将配置的阈值和颜色应用于摘要统计。
Invert order: 此链接切换阈值颜色顺序。
Spark Lines:
迷你图是查看与摘要统计相关的历史数据的绝佳方式,一目了然地提供有价值的背景信息。 迷你图的行为与传统的图形面板不同,不包括x或y轴,坐标,图例或与图形交互的能力。
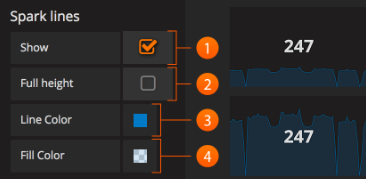
Show: 显示复选框将切换是否在面板中显示火花线。 未选中时,仅显示Singlestat值。
Full Height: 检查是否希望迷你图占据整个面板高度,或取消选中它们是否应低于主Singlestat值。
Line Color: 此颜色选择适用于迷你图本身的颜色。
Fill Color: 此颜色选择适用于迷你图下方的区域。
专业提示:降低填充颜色的不透明度,以获得漂亮的面板。
Gauge:
仪表清晰地显示了值在其上下文中的高度。 这是查看某个值是否接近阈值的好方法。 仪表使用颜色选项中设置的颜色。
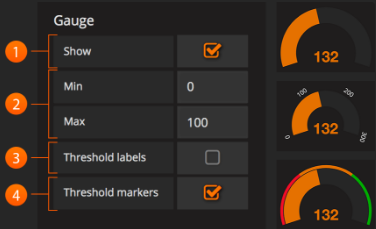
Show: show复选框将切换仪表是否显示在面板中。 未选中时,仅显示Singlestat值。
Min/Max: 这将设置仪表的起点和终点。
Threshold Labels: 检查是否要显示阈值标签。 阈值在颜色选项中设置。
Threshold Markers: 检查是否要显示阈值的第二个仪表。
Value/Range to text mapping:
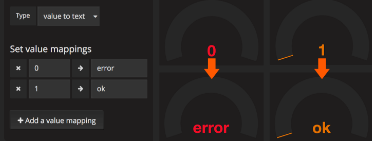
Value/Range到文本映射允许将摘要统计的值转换为显式文本。 该文本将遵循为该值定义的所有样式,阈值和自定义。 这可以用于将主Singlestat值的数量转换为特定于上下文的人类可读单词或消息。
Troubleshooting(故障排除):
Multiple Series Error(多系列错误):
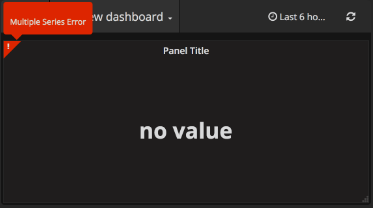
Grafana 2.5对单稳态面板上的多系列进行了更严格的检查。 在以前的版本中,面板逻辑没有验证只使用了一个系列,而是显示遇到的第一个系列。 根据数据源,这可能导致显示不一致的数据和/或对显示哪个度量标准的一般混淆。
要修复你的singlestat面板:
单击Panel Title并选择Edit,编辑面板。是否在“指标”标签中有多个查询?
解决方案:选择要查看的单个查询。 可以通过单击每行上的眼睛图标来切换查询是否可视化。 如果错误仍然存在,请继续执行下一个解决方案。
你有一个查询吗?
解决方案:这可能意味着你的查询返回多个系列。 你将希望将其减少到单个系列。 这可以通过多种方式完成,具体取决于你的数据源。 一些常见的做法包括对系列,平均或任何数量的其他函数求和。 有关其他信息,请参阅数据源文档。
1.2 实例设置
#上面已经对这种面板有个大概的了解,下面做一个面板出来。
先来一个CPU空闲率的图:
General的设置:
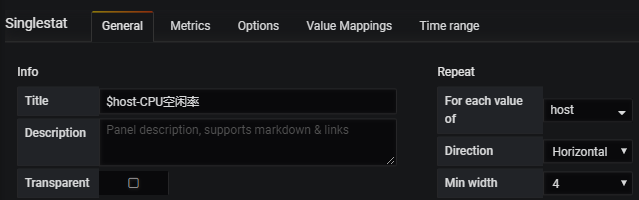
#上图就不多做解释了上一章已经解释过了
Metrics设置:
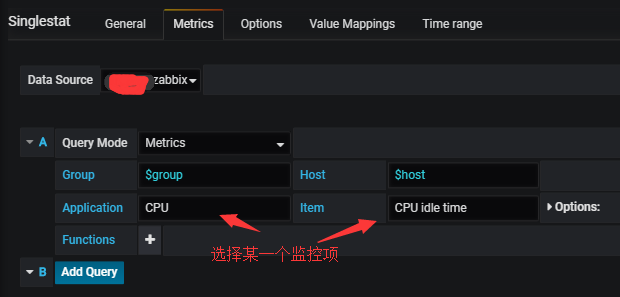
Options设置:
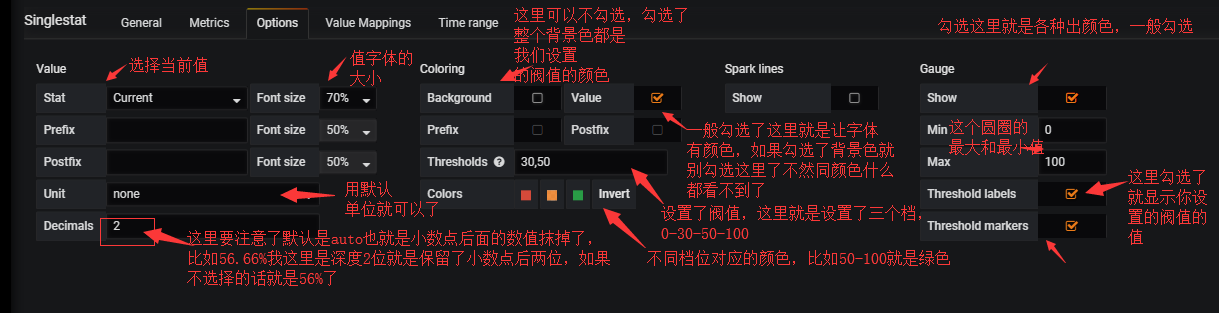
#我擦点错,最后一个markers你可以自己勾选和不勾选比较一下,就是显示Thresholds那里设置的阀值以及对应的颜色。
#特别注意,比如30,50 就是当值0-29的时候是一个档位,30-50是一个档位,51-100是一个档位。
Value Mappings:
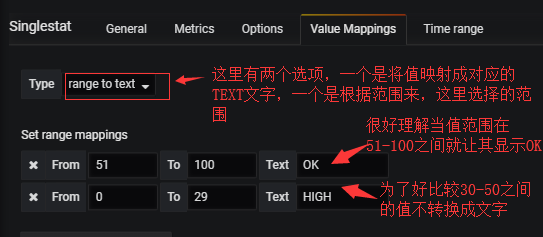
下面查看一下效果:
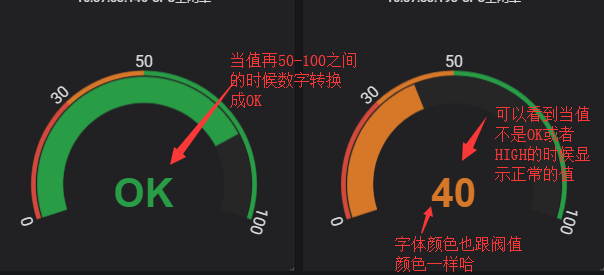
然后我们不想只是显示数字,因为这本来是一个百分比的值吗想值后面带上%怎么弄一下呢?
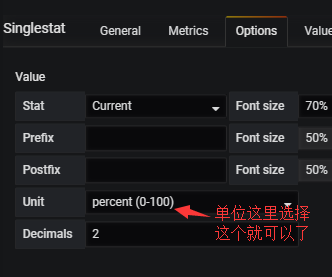
再看:
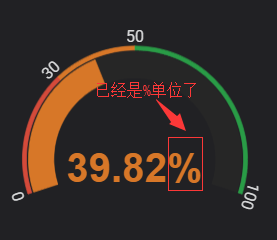
博文来自:www.51niux.com
二、Table Panel
2.1 官网翻译
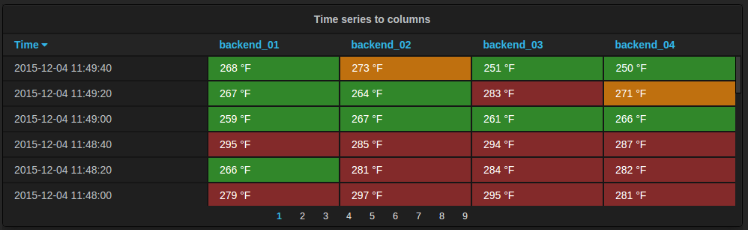
#上图为官方的例子
表格面板非常灵活,支持时间序列的多种模式以及表格,注释和原始JSON数据。 它还提供日期格式和值格式和着色选项。要查看运行中的表格面板并使用示例数据测试不同的配置,请查看Grafana Playground中的“表格面板展示”(https://play.grafana.org/d/000000031/table-panel-showcase?orgId=1)。
Querying Data:
表格面板显示“度量标准”选项卡中指定的查询结果。 显示的结果取决于数据源和查询,但通常每个数据点有一行,关联键和值的额外列,以及数据点的数值的一列。 可以在下面的数据部分中更改行为。
Merge Multiple Queries per Table(合并每个表的多个查询):
仅适用于Grafana v5.0 +。
有时,在相应行的同一表中显示多个查询的结果是有用的,例如,在比较资源的容量和实际使用时。 在此示例中,使用和容量是具有相应数据点的度量,而其关联的键和值可用于匹配它们。 (此匹配仅在表变换设置为表时可用。)
在最简单的情况下,两个查询都返回带有数值和时间戳的时间序列数据。 如果时间戳相同,则数据点将匹配并在同一行上呈现。 某些数据源返回与数据点关联的键和值(labels, tags)。 如果它们存在于两个结果中并且具有相同的值,则它们也匹配。 以下数据点将以一个时间列,两个标签列(“host” and “job”)和两个值列结束在同一行上:
Datapoint for query A: {time: 1, host: "node-2", job: "job-8", value: 3}
Datapoint for query B: {time: 1, host: "node-2", value: 4}以下两个结果无法匹配,将在不同的行上呈现:
Different time
Datapoint for query A: {time: 1, host: "node-2", job: "job-8", value: 3}
Datapoint for query B: {time: 2, host: "node-2", value: 4}
Different label "host"
Datapoint for query A: {time: 1, host: "node-2", job: "job-8", value: 3}
Datapoint for query B: {time: 1, host: "node-9", value: 4}仍然可以通过在列样式(Column Styles)中将冲突列的类型更改为隐藏来合并上述两种情况。
请注意,如果查询结果的每个数据点都有多个值字段,如max,min,mean等,则它们可能具有不同的值,因此不会匹配并在不同的行上呈现。 如果您希望合并行但看到它们在不同的行上呈现,请在Query Inspector(查询检查器)中检查查询结果,以确定应合并到行中的数据点的字段值是否相同。
Options overview(选项概述):
表格面板有许多方法可以操作数据以获得最佳显示效果。
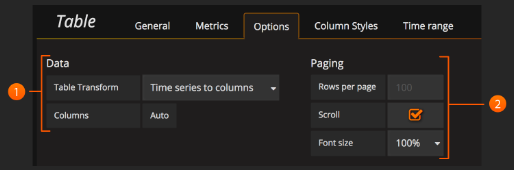
Data: 控制查询如何转换为表格。
Paging: 表格显示选项。
Data to Table(数据列表):
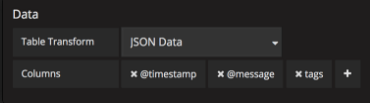
数据部分包含To Table Transform(1)。 这是将数据/度量标准查询转换为表格格式的主要选项。 Columns(2)选项允许选择表中所需的列。 仅适用于某些变换。
Time series to rows(时间序列到行):
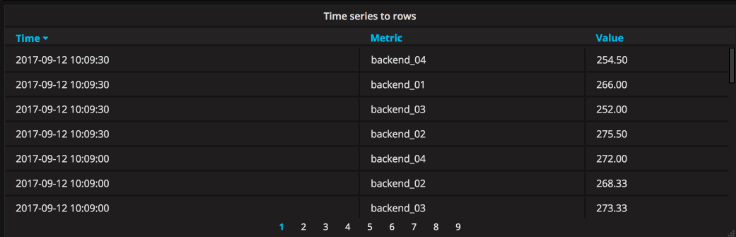
在最简单的模式中,可以将时间序列转换为行。 这意味着你将获得Time, Metric and a Value column。 其中Metric(度量标准)是时间序列的名称。
Time series to columns(时间序列到列):
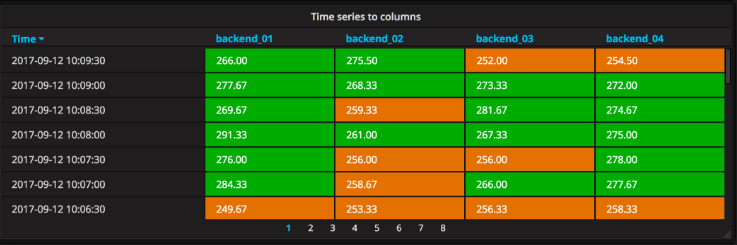
此转换允许你采用多个时间序列并按时间对其进行分组。 这将导致主列为Time和每个时间系列的列。
Time series aggregations(时间序列聚合):
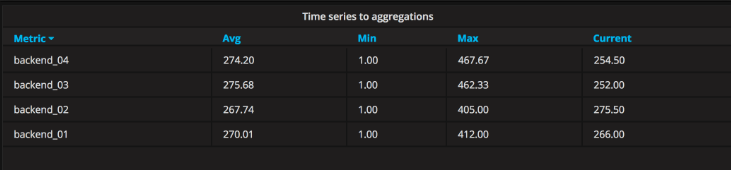
此表转换将按行进度将表格布置为行,允许使用Avg,Min,Max,Total,Current和Count列。 可以添加多个列。
Annotations(注释):
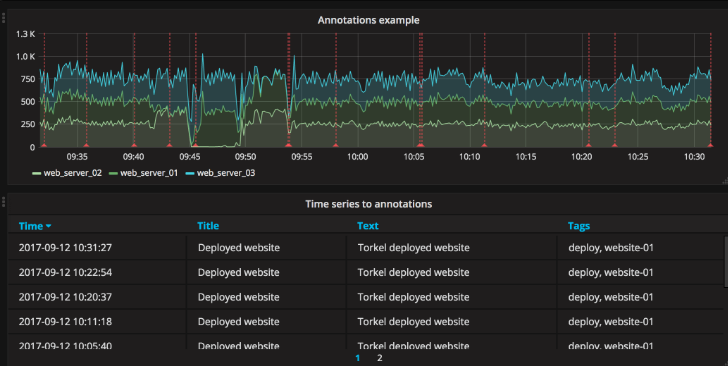
如果在仪表板中启用了注释,则可以让表格显示它们。 如果配置此模式,则会忽略你在“指标”选项卡中的任何查询。
JSON Data:
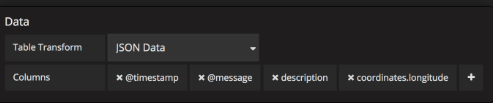
如果你有Elasticsearch原始文档查询或没有日期直方图的Elasticsearch查询,请使用此转换模式并使用“列”部分选择列。

Table Display:
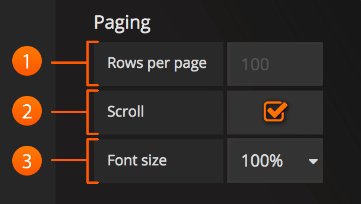
Rows Per Page: 表格显示字段允许您控制每页应有多少行。 例如,如果你的表有95条记录,每页的行数值为10,那么你的表将分为10页。
Scroll: 滚动条复选框切换在面板内滚动的功能,未选中时,面板高度将增大以显示所有行。
Font Size: 字体大小字段允许您相对于默认字体大小增加或减小面板的大小。
Column Styles(列样式):
列样式允许您控制日期和数字的格式。
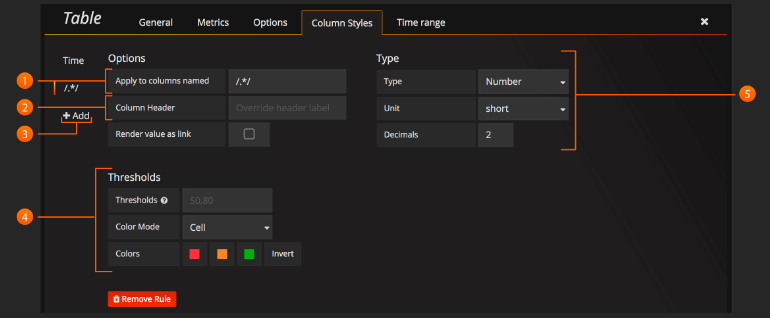
Name or regex(名称或正则表达式): “名称”或“正则表达式”字段控制应该应用规则的列。 正则表达式或名称过滤器将与列名称匹配,而不是与列值匹配。
Column Header(列标题): 列的标题,当使用正则表达式时,标题可以包括替换字符串,如$1。
Add column style rule(添加列样式规则): 添加新列规则。
Thresholds and Coloring(阀值和着色):指定颜色模式和阈值限制。
Type: 支持的三种类型是Number,String和Date。 Unit and Decimals(单位和小数):指定数字的单位和小数精度。 Format: 指定日期的日期格式
String:
Value/Range to text mapping(值/范围到文本映射)。仅适用于Grafana v5.1 +。
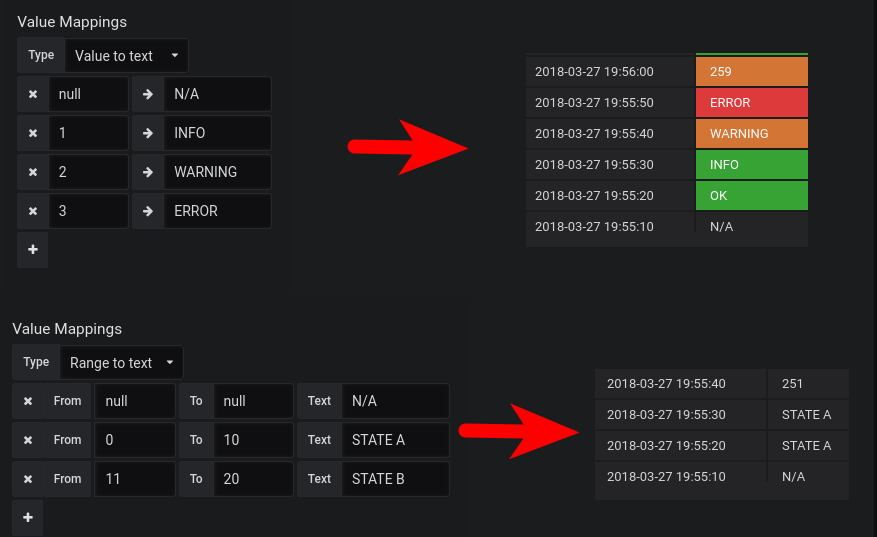
值/范围到文本映射允许您将数值转换为显式文本。 该文本将遵循为该值定义的所有样式,阈值和自定义。 这对于将数值转换为特定于上下文的人类可读单词或消息非常有用。
2.2 实例操作
先来一个最基本的:
#选择完table panle之后我们用最简单的出图方式:

#查看一下:
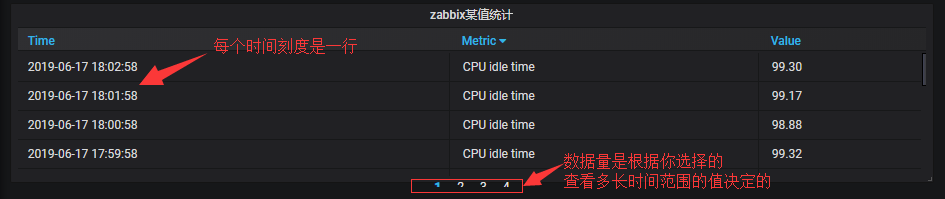
#上图如果用的默认没有配置option,多IP就是多列
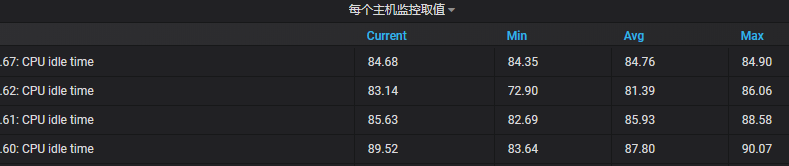
然后你说我想看每个主机ip所选择监控项的最大、最小等一些值:
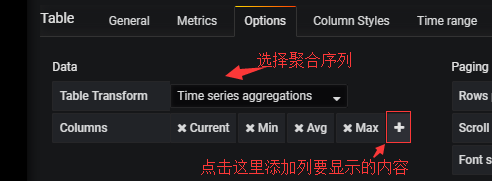
下面是效果图:
三、Heatmap Panel(热图面板)
3.1 官方翻译
新面板仅适用于Grafana v4.3 +
Heatmap面板允许随时间查看直方图。 要完全理解和使用此面板,需要了解直方图是什么以及如何创建它们。 请阅读下面的内容,快速了解直方图这一术语。
Histograms and buckets(直方图和buckets):
直方图是数值数据分布的图形表示。 将值分组到存储桶(有时也称为容器),然后计算每个存储桶中有多少值。 不是绘制实际值的图形,而是绘制桶的图形。 每个条形代表一个桶,条形高度代表落入该桶间隔的值的频率(即计数)。
直方图示例:
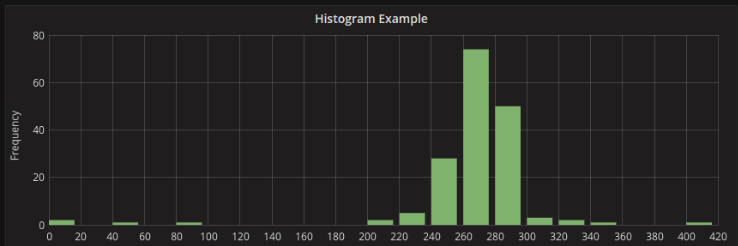
上面的直方图向我们展示了几个时间序列的大多数值分布。 我们可以很容易地看到大多数值落在240-300之间,峰值在260-280之间。 直方图只是查看特定时间范围内的值分布。 因此,随着时间的推移,无法看到分布的任何趋势或变化,这是热图变得有用的地方。
Heatmap:
热图就像直方图,但随着时间的推移,每个时间片代表自己的直方图。 不使用条形高度作为频率的表示,而是使用单元格并将单元格与存储桶中的值数量成比例。
例:
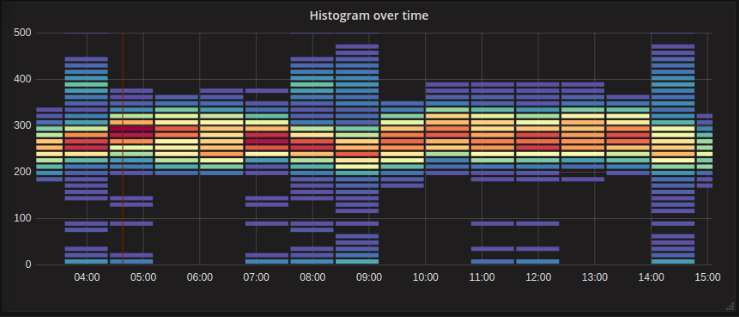
在这里,我们可以清楚地看到哪些值更为常见,以及它们如何随着时间推移。
Data Options(数据选项):
可以在“Axes”选项卡中找到数据和存储桶选项。
Data Formats(数据格式):
| Data format | Description |
|---|---|
| Time series | Grafana通过遍历所有时间序列值来完成任务。bucket sizes & intervals将使用bucket选项确定。 |
| Time series buckets | 每个时间序列都代表一个Y-Axis bucket。 时间序列名称(别名)需要是表示存储桶的上限或下限的数值。 Grafana没有任何分支,因此隐藏了桶大小选项。 |
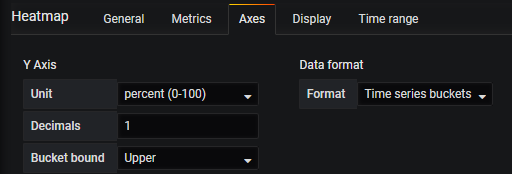
Bucket bound(Bucket范围):
当数据格式为时间序列时,buckets数据源返回带有表示bucket绑定的名称的系列。 但是根据数据源,边界可能是上限或下限。 此选项允许调整绑定类型。 如果设置了Auto,将根据面板的数据源类型选择绑定选项。
Bucket Size(bucket尺寸):
Grafana使用Bucket计数和大小选项来计算热图中每个单元格的大小。 可以通过计数(第一个输入框)或指定大小间隔来定义存储桶大小。 对于Y轴,大小间隔只是一个值,但对于X-bucket,可以在“Size”输入中指定时间范围,例如,时间范围为1h。 这将使单元格在X轴上宽1h。
Pre-bucketed data(预先打包的数据):
如果已将数据组织到存储桶中,则可以使用Time series buckets(时间系列存储桶)数据格式。 此格式要求您的度量标准查询返回常规时间序列,并且每个时间系列都有一个数字名称,表示间隔的上限或下限。
随着时间的推移,有许多支持直方图的数据源,如Elasticsearch(通过使用直方图桶聚合)或Prometheus(histogram metric 类型和Format as option set to Heatmap)。 但通常,如果满足要求,则可以使用任何数据源:返回具有表示桶绑定的名称的系列或返回按绑定按升序排序的系列。
使用Elasticsearch,可以使用直方图间隔(Y轴)和日期直方图间隔(X轴)控制存储桶的大小。

使用Prometheus,只能通过调整Min step和Resolution选项来控制X轴。

Display Options(显示选项):
在热图显示选项卡中,可以定义单元格的呈现方式以及它们的分配颜色。
Color Mode & Spectrum(色彩模式和光谱):
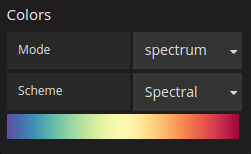
色谱控制值计数(在每个桶中)与分配给每个桶的颜色之间的映射。 光谱上最左边的颜色代表最小数量,最右边的颜色代表最大数量。 使用灯光主题时,某些配色方案会自动反转。
还可以将颜色模式更改为Opacity(不透明度)。 在这种情况下,颜色不会改变,但不透明度将随bucket计数而变化。
Raw data vs aggregated(原始数据和聚合):
如果使用具有常规时间序列数据的热图(不是预先布局)。 然后重要的是要记住,你的数据通常已经由你的时间序列后端汇总。 大多数时间序列查询不返回原始样本数据,但包括按时间间隔分组或maxDataPoints限制以及聚合函数(通常是平均值)。
这一切都取决于查询的时间范围。 但重要的是要知道Grafana执行的直方图分段可以在已经聚合和平均的数据上完成。 要获得更准确的热图,最好在度量标准收集期间执行分段或将数据存储在Elasticsearch中,或者在支持对原始数据执行直方图分段的其他数据源中。
如果在查询中按时间移除或降低组(或raise maxDataPoints)以返回更多数据点,您的热图将更准确,但这也可能会对您的浏览器造成极大的CPU和内存负担,并且如果数量可能会导致挂起和崩溃 数据点变得过大。
3.2 实例操作
先来一个最基本的:

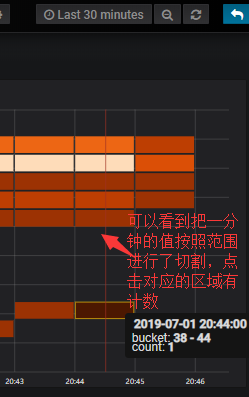
#这样你就可以看到某一个时刻某些主机组里面某一个时刻主机某一个数据指标的范围区间状况。
稍微修改下Axes:
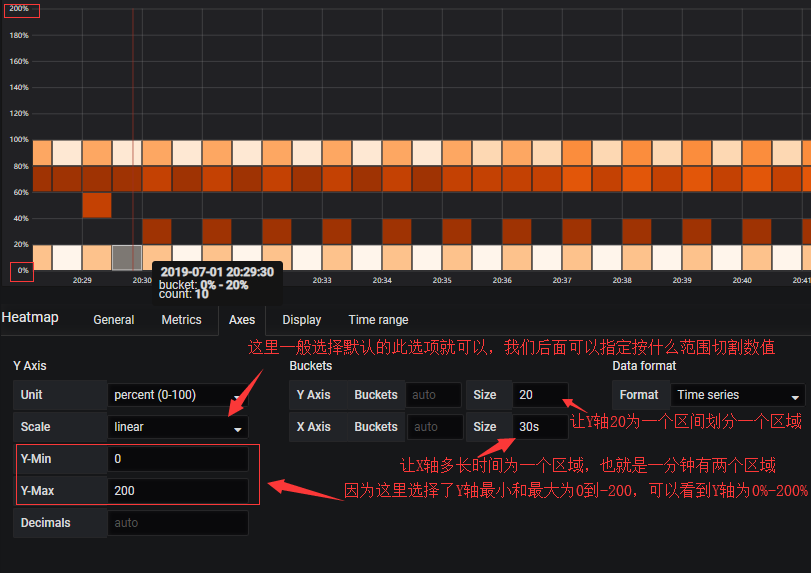
再来一个Time series buckets的例子:

四、Dashboard List Panel
4.1 官网翻译
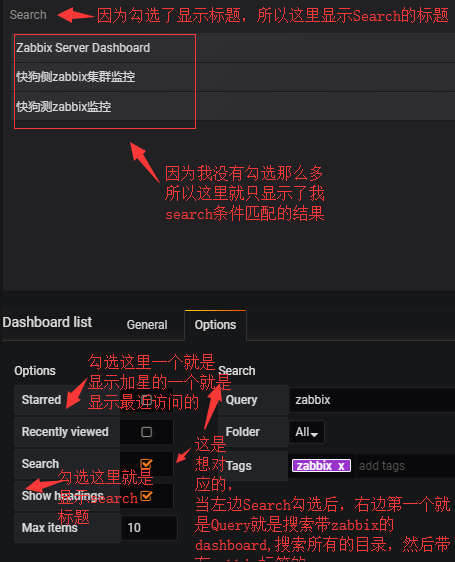
仪表板列表面板允许显示指向其他仪表板的动态链接。 该列表可以配置为使用加星标的仪表板,最近查看的仪表板,搜索查询和/或仪表板标签。在每个仪表板load,仪表板面板将重新查询仪表板列表,始终提供最新的结果。
Dashboard List Options(仪表板列表选项):
Starred: 已加星标的仪表板选项按字母顺序显示已加星标的仪表板。
Recently Viewed: 最近查看的仪表板选择按字母顺序显示最近查看的仪表板。
Search:搜索仪表板选择
Show Headings:勾选显示标题时,所选列表选择(已加星标,最近查看,搜索)显示为标题。
Max Items: 最大项目设置列表中项目的最大值。
Query: 可以在此处输入要搜索的查询。 查询不区分大小写,并且接受部分值。
Tags: 可以在此处输入要搜索的标记。 请注意,现有标记在你type时不会显示,并且区分大小写。 要查看现有标签列表,您始终可以返回仪表板,打开顶部的仪表板选取器,然后单击搜索栏中的标签链接。
4.2 实例记录
五、functions学习
Funcation:https://alexanderzobnin.github.io/grafana-zabbix/reference/functions/#movingaverage
5.1 先跟着链接学习下这写functions的意思
Transform:
groupBy:
groupBy(interval, function)。采用每个时间序列,并使用函数将在给定区间内失控的点合并为一个点,该函数可以是:avg,min,max,median。例子:
groupBy(10m, avg) groupBy(1h, median)
scale:
scale(factor)。 采用时间序列并将每个点乘以给定因子。例子:
scale(100) scale(0.01)
delta:
delta()。 将绝对值转换为delta。 此函数只计算值之间的差异。 对于每秒计算使用rate()。
rate:
rate()。 计算时间序列的每秒增长率。 抗计数器重置。 适合将增长计数器转换为每秒速率。
movingAverage:
movingAverage(windowSize)。 绘制由windowSize参数指定的固定数量的过去点的度量的移动平均值。例子:
movingAverage(60) #计算超过60个点的移动平均线(如果指标具有1秒分辨率,则与1分钟窗口匹配)
exponentialMovingAverage:
exponentialMovingAverage(windowSize)。 采用一系列值和窗口大小,并使用以下公式生成指数移动平均值:
ema(current) = constant * (Current Value) + (1 - constant) * ema(previous)
常数计算如下:
constant = 2 / (windowSize + 1)
如果windowSize <1(例如0.1),则不会计算常量,并且将直接从windowSize(Constant = windowSize)获取。
从系列的第一个点(不是来自Nth = windowSize)绘制EMA是有点棘手的。 为了做到这一点,插件应首先获取前N个点并计算它的简单移动平均值。 为避免这种情况,插件使用此hack:假设,之前的N个点具有与前N个相同的平均值(windowSize)。 所以你应该记住这个事实,不要依赖前N点间隔。
removeAboveValue:
removeAboveValue(N)。 如果值> N,则将系列值替换为null。例子:
removeAboveValue(1)
removeBelowValue:
removeBelowValue(N)。 如果值<N,则将系列值替换为null。
transformNull:
transformNull(N)。 用N替换空值。
Aggregate:
aggregateBy:
aggregateBy(interval, function)。 占用所有时间序列,并使用函数将在给定间隔内的所有点数合并为一个点,该函数可以是:avg,min,max,median。例子:
aggregateBy(10m, avg) aggregateBy(1h, median)
sumSeries:
sumSeries()。 这将在一起添加指标并返回每个数据点的总和。 此方法需要插入每个时间序列,因此可能导致高CPU负载。 尝试将其与groupBy()函数结合使用以减少负载。
average:
average(interval)。 不推荐使用,请改用aggregateBy(interval,avg)。
min:
min(interval)。 不推荐使用,请改用aggregateBy(interval,min)。
max:
max(interval)。 不推荐使用,请改用aggregateBy(interval,max)。
Filter:
top:
top(N, value)。 返回前N个系列,按值排序,可以是以下之一:avg,min,max,median。例子:
top(10, avg) top(5, max)
bottom:
bottom(N, value)。 返回底部N系列,按值排序,可以是以下之一:avg,min,max,median。例子:
bottom(5, avg)
Trends:
trendValue:
trendValue(valueType)。 指定Zabbix在使用趋势时返回的趋势值类型(平均值,最小值或最大值)。
Time:
timeShift:
timeShift(interval)。 绘制随时间移动的选定指标。 如果没有给出符号,则隐含一个减号( - ),这将使指标在时间上移回。 如果给出加号(+),则度量将在时间上向前移动。 例子:
timeShift(24h) - shift metric back in 24h hours timeShift(-24h) - the same result as for timeShift(24h) timeShift(+1d) - shift metric forward in 1 day
Alias:
setAlias:
setAlias(alias)。返回给定别名而不是度量标准名称。例子:
setAlias(load)
setAliasByRegex:
setAliasByRegex(regex)。返回由regex匹配的度量标准名称的一部分。例子:
setAlias(Zabbix busy [a-zA-Z]+)
replaceAlias:
replaceAlias(pattern, newAlias)。使用模式替换度量标准名称 模式是正则表达式或常规字符串。 如果使用正则表达式,则支持以下特殊替换模式:
插入 模式 $$ 插入“$”。 $& 插入匹配的子字符串。 $` 插入匹配子字符串之前的字符串部分。 $' 插入匹配子字符串后面的字符串部分。 $n 其中n是小于100的非负整数,插入第n个带括号的子匹配字符串,前提是第一个参数是RegExp对象。
有关更多详细信息,请参阅String.prototype.replace()函数 https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/replace
例子:
CPU system timereplaceAlias(/CPU (.*) time/, $1) -> system backend01: CPU system timereplaceAlias(/CPU (.*) time/, $1) -> backend01: system backend01: CPU system timereplaceAlias(/.*CPU (.*) time/, $1) -> system backend01: CPU system timereplaceAlias(/(.*): CPU (.*) time/, $1 - $2) -> backend01 - system
Special:
consolidateBy:
consolidateBy(consolidationFunc)。当绘制图形时,图形大小的宽度(以像素为单位)小于要绘制的数据点的数量,插件会合并这些值以防止线条重叠。 consolidateBy()函数将合并函数从默认的平均值更改为sum,min,max或count之一。有效的函数名称是sum,avg,min,max和count。
5.2 例子简单描述一下:
top和bottom:
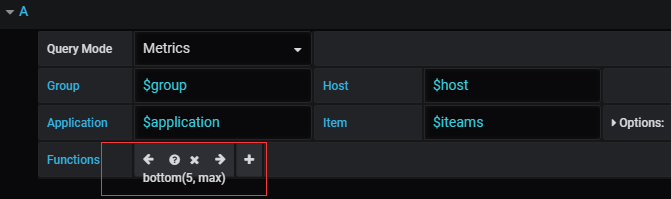
#当你选择多个主机,然后只查看某几个的时候还是比较有用的。
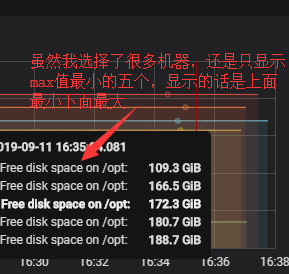
#top也是一样的就是显示最大的五个,排序的话也是上面最小,下面最大那么显示。
#如果你想在最小的五个值里面再选最大的三个值咋办,入下图:

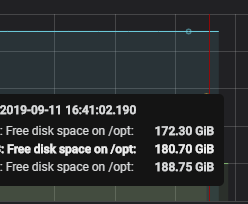
#从显示结果可以看出,是从上图五个返回结果中又选出了三个最大的显示出来。
#另外还有一个sortSeries(),里面就是asc和desc,也就是显示的监控项按照升序或者降序排列显示。
replaceAlias、setAlias和setAliasByRegex:
#比如我们监控项显示的长度很长,或者其他原因,我们想换个名称:
#比如将Free disk space on /opt换成/opt 空闲,下面是函数的:
replaceAlias(/(Free.*on).*(opt)/, /$2 空闲)
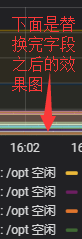
#setAlias就相对而言比较死板了,比如setAlias(哈哈)就是把显示的监控项全部改成"哈哈”。
#setAliasByRegex就是正则截取,setAliasByRegex([0-9].*Free),比如这个就是把上面显示的长度窃取到IP:Free,后面的那些disk space之类的就不显示了。
#又或者你是多个IP再一张图里面,你想显示多个IP的列表,为了保证字段长度就不需要后面的那些描述信息了,如我们用Load负载为例:
replaceAlias(/(P.*)/, ) #,后面是一个空值也就相当于将匹配的那些替换成空值了,这种方式是因为描述性里面有数字比如Processor load (1 min average per core)之类的。 #或者如果整个字段里面只有IP是数字而监控项描述部门没有数字还可以用setAliasByRegex([0-9].*[0-9])这种方式。 #当然也可以replaceAlias(/([:a-zA-Z].*)/, )这样IP后面的:也就没有了。
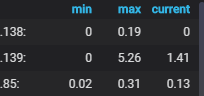
#这样我们就只需要Panel的标题是Load负载,然后表格就只显示IP就可以了,这样效果也达到了了。
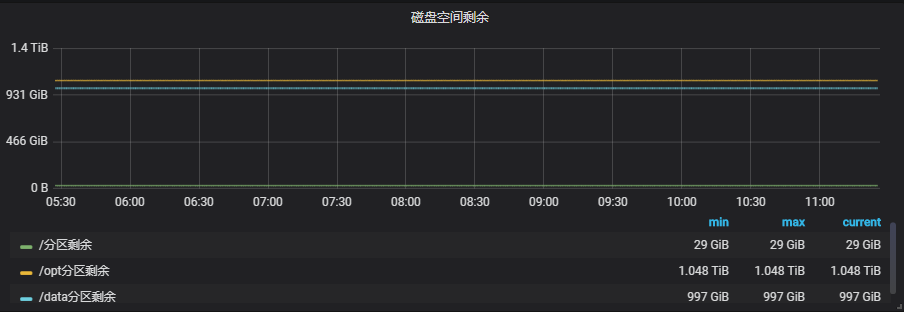
#再比如我们想做一个多分区剩余的一个显示:
replaceAlias(/(Free.*on)\s+(.*)/, $2分区剩余) #而原始的item值是/Free disk space on (\/$|\/[a-z0-9]+)$/