grafana高可用和Alerting(七)
一、grafana版本升级
1.1 还是先跟着官网简单走一波
建议经常升级Grafana,以获取最新的修补程序和增强功能。 为了实现这一点,Grafana升级向后兼容,并且升级过程简单快捷。升级通常是安全的(在许多次要版本和一个主要版本之间),并且仪表板和图形看起来相同。 在某些情况下,可能会有一些小的重大更改,如发行说明和变更日志中所述(https://github.com/grafana/grafana/blob/master/CHANGELOG.md)。
更新插件:
升级后,强烈建议更新所有插件,因为新版本的Grafana会使旧插件停止正常工作。可以使用更新所有插件:grafana-cli plugins update-all
数据库备份:
在升级之前,最好备份你的Grafana数据库。 这将确保你始终可以回滚到以前的版本。 在启动过程中,Grafana将自动迁移数据库架构(如果有更改或新表)。 有时,如果你以后要降级,可能会导致问题。
sqlite:
如果使用sqlite,则只需备份grafana.db文件。它通常位于Unix系统上的/var/lib/grafana/grafana.db中。 如果不确定使用哪个数据库以及将其存储在哪里,请检查grafana配置文件。 如果使用二进制tar/zip将grafana安装到自定义位置,则通常在<grafana_install_dir>/data中。
mysql:
backup: > mysqldump -u root -p[root_password] [grafana] > grafana_backup.sql restore: > mysql -u root -p grafana < grafana_backup.sql
postgres:
backup: > pg_dump grafana > grafana_backup restore: > psql grafana < grafana_backup
升级:
升级到v6.0。如果你有带有script tags的文本面板,则由于新设置(默认情况下不允许未经处理的HTML),它们将不再起作用。
从二进制.tar文件升级:
如果下载了二进制.tar.gz软件包,则只需下载并解压缩新软件包并覆盖所有现有文件即可。但是,这可能会覆盖你的配置更改。建议你将自定义配置更改保存在名为<grafana_install_dir>/conf/custom.ini的文件中。 这使你可以升级Grafana,而不必担心丢失配置更改。
Centos / RHEL:
如果通过下载RPM软件包安装了Grafana,则只需遵循相同的安装指南并执行相同的yum install或rpm -i命令,但使用新软件包即可。它将升级你的Grafana安装包。如果你使用了grafana的YUM存储库:sudo yum update grafana
Docker:
这只是一个示例,详细信息取决于你配置grafana容器的方式。
docker pull grafana docker stop my-grafana-container docker rm my-grafana-container docker run --name=my-grafana-container --restart=always -v /var/lib/grafana:/var/lib/grafana
1.2 实践升级一下
#说是实践升级一下,其实咱们已经看了上面的介绍升级还是很简单的。我是编译安装的,我就按照编译安装的升级方式来了。
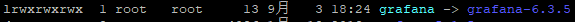
#从上图可以看到我都是软连接的方式,所以我升级就是下载软件包解压然后拷贝过来相关的目录然后重启下服务就行。
#首先是数据库的保存上面有,选择了什么类型的数据库就保存一下以防万一。
# tar zxf grafana-6.5.2.linux-amd64.tar.gz
#kill -9 `ps -aux|grep grafana.ini|grep -v grep|awk {'print $2'}`
#ln -snf grafana-6.5.2 grafana
#cp -f grafana-6.3.5/conf/grafana.ini grafana/conf/
# cp grafana-6.3.5/conf/ldap.toml grafana/conf/ #如果做了ldap的认证还要做这步操作
#cp -rf grafana-6.3.5/data grafana/
#/application/grafana/bin/grafana-cli plugins update-all
#cd /application/grafana/ && ./bin/grafana-server -config ./conf/grafana.ini &
#再打开grafana就可以看到升级成最新版了,这个就不截图了。
博文来自:www.51niux.com
二、Grafana高可用
2.1 还是先跟着官网翻译一波
设置Grafana以获得高可用性非常简单。 只需要一个共享数据库来存储仪表板,用户和其他持久数据。 因此,默认的嵌入式SQLite数据库将无法工作,将不得不切换到MySQL或Postgres。
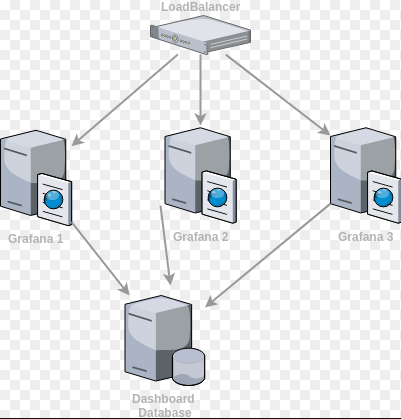
Alerting:
当前,警报支持有限形式的高可用性。 从v4.2.0开始,运行多个服务器时将删除警报通知。这意味着所有警报都在每台服务器上执行,但是警报通知每个警报仅发送一次。 Grafana不支持服务器之间的负载分配。
User sessions:
在Grafana 6.2之后,无需配置会话存储,因为默认情况下将使用该数据库。 如果要从数据库中卸载登录会话数据,则可以配置remote_cache。
要考虑的第二件事是如何处理用户会话以及如何在Grafana前面配置负载均衡器。 Grafana支持两种存储会话数据的方式:本地存储在磁盘上或数据库/缓存服务器中。 如果要将会话存储在磁盘上,则可以在负载均衡器中使用Sticky会话。 如果希望将会话数据存储在数据库/缓存服务器中,则可以在负载均衡器中使用任何无状态路由策略(轮循或最少连接)。
Sticky sessions:
使用粘性会话,一个用户的所有流量将始终发送到同一服务器。 这意味着与会话相关的数据可以存储在磁盘上,而不是存储在共享数据库上。 这是Grafana的默认行为,如果只希望多个服务器进行故障转移,则这是一个很好的解决方案,因为它需要的工作量最少。
Stateless sessions:
还可以选择将会话数据存储在Redis/Memcache/Postgres/MySQL中,这意味着负载均衡器可以将用户发送到任何Grafana服务器,而无需登录每个服务器。 这需要操作员多做一些工作,但使你能够删除/添加grafana服务器而不会影响用户体验。 如果你使用MySQL/Postgres进行会话存储,则首先需要一个表来存储会话数据。
对于Grafana本身,将会话数据存储在磁盘还是数据库/redis/memcache上并不重要。但是建议使用数据库/redis /memcache,因为它可以更轻松地管理grafana服务器。
2.2 实践配置一下
首先要配置使用mysql数据库:
[database] # You can configure the database connection by specifying type, host, name, user and password # as separate properties or as on string using the url property. # Either "mysql", "postgres" or "sqlite3", it's your choice type = mysql host = 192.168.1.101 name = grafana user = grafana # If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;""" password = grafana
#上面的配置很好理解哈,选择数据库类型为mysql类型,选择数据库的地址和用户名和密码,然后启动grafana就可以了,相关表会自动创建:
>use grafana; >show tables; #可以看到下面生成了很多表 alert alert_notification alert_notification_state alert_rule_tag annotation annotation_tag api_key cache_data dashboard dashboard_acl dashboard_provisioning dashboard_snapshot dashboard_tag dashboard_version data_source login_attempt migration_log org org_user playlist playlist_item plugin_setting preferences quota server_lock session star tag team team_member temp_user test_data user user_auth user_auth_token
然后创建一个session表(如果没有这个session表的情况下,但是现在新版的已经有这个session表了):
>use `grafana`; >CREATE TABLE `session` ( `key` CHAR(16) NOT NULL, `data` BLOB, `expiry` INT(11) UNSIGNED NOT NULL, PRIMARY KEY (`key`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
# vim conf/grafana.ini
[session] provider = mysql provider_config = grafana:grafana@tcp(192.168.1.101:3306)/grafana cookie_name = grafana_sess cookie_secure = false session_life_time = 86400
#特别注意6.2版本中已经删除了session选项,改为了remote_cache选项,如下面的配置:
#################################### Cache server ############################# [remote_cache] # Either "redis", "memcached" or "database" default is "database" type = database # cache connectionstring options # database: will use Grafana primary database. # redis: config like redis server e.g. `addr=127.0.0.1:6379,pool_size=100,db=0,ssl=false`. Only addr is required. ssl may be 'true', 'false', or 'insecure'. # memcache: 127.0.0.1:11211 connstr = mysql账号:mysql密码@tcp(mysql地址:3306)/grafana
#然后重启grafana就能共享会话了。
#这里要记录一下我其实并没实现共享会话的效果,我看着官网配置很简单,但是怎么也实现不了会话共享的效果,我用其他方式实现了会话共享,如果成功的大哥们可以指正下我哪里错了.......
2.3 迁移导出sqlite3数据到mysql
#假如你一开始没有考虑高可用方案后面才用起来的,可能一开始用的是sqlite3数据库,可能你已经搞了很多dashboard有很多用户之类的。那么这时候你说让大家才重新登陆一下或者新环境照着旧环境再来一遍就显得有点不合适了,这时候就需要数据库迁移了。而sqlite3跟mysql还是有些区别的,我们需要做一些调整。
#我这里还是有点偷懒的成分的,首先我是把所有的建表语句什么的全不要我只要insert语句,先在新环境用grafana和mysql创建完完整的数据表。
在旧环境导出sql文件:
# sqlite3 grafana.db
sqlite> .output /tmp/grafana_dump.sql sqlite> .dump sqlite> .exit
#修改导出的sql文件:
#首先第一步就是把INSERT语句单独的过滤出来。
#然后呢就是把无用的往表里面INSERT初始信息的语句删除掉,因为我们mysql表里面已经有这些数据了。
#然后呢就要执行类似于:sed -i 's#"dashboard"#`dashboard`#' grafana_dump.sql #将""变成``这样导入mysql的时候才不会报错。
#再然后呢就是进行数据库导入了,然后根据导入的报错信息再具体排查吧。
# cat grafana_dump.sql|grep -o "INSERT INTO.* VALUES"|sort -nr|uniq #这是我导入mysql的文件,多余INSERT语句都没要,就留了这些
INSERT INTO `user` VALUES INSERT INTO `user_auth` VALUES INSERT INTO `temp_user` VALUES INSERT INTO `team` VALUES INSERT INTO `team_member` VALUES INSERT INTO `tag` VALUES INSERT INTO `star` VALUES INSERT INTO `preferences` VALUES INSERT INTO `org_user` VALUES INSERT INTO `data_source` VALUES INSERT INTO `dashboard_version` VALUES INSERT INTO `dashboard` VALUES INSERT INTO `dashboard_tag` VALUES
#另外user表的插入admin的语句和org表的插入Main Org表的语句肯定是要去掉的,可以在导入报错中逐步的删除点mysql表中已存在的数据。
博文来自:www.51niux.com
三、Grafana开启LDAP认证
3.1 grafana开启LDAP认证
#当一个公司系统多了就会做集中认证,所以我们grafana也得是集中认证的一部分。
# vim grafana.ini #下面的意思很简单就不多做解释了
#################################### Auth LDAP ########################### [auth.ldap] enabled = true config_file = conf/ldap.toml allow_sign_up = true
# vim ldap.toml #上面已经引用了ldap.toml并开启了ldap认证,所以这里就要配置此文件了
[[servers]] # LDAP服务器主机(指定多个主机,空格分隔) host = "ldap.51niux.com" #如果use_ssl = true,则默认端口为389或636 port = 389 #如果ldap服务器支持TLS,则设置为true use_ssl = false #如果使用STARTTLS模式连接ldap服务器,则设置为true(以不安全的方式创建连接,然后升级为使用TLS的安全连接) start_tls = false #如果要跳过ssl证书验证,请设置为true ssl_skip_verify = false # set to the path to your root CA certificate or leave unset to use system defaults # root_ca_cert = "/path/to/certificate.crt" # Authentication against LDAP servers requiring client certificates # client_cert = "/path/to/client.crt" # client_key = "/path/to/client.key" #搜索用户绑定dn bind_dn = "cn=ro,dc=51niux,dc=com" #搜索用户绑定密码,如果密码包含#或; 必须用三引号引起来。 例如"""#password;""" bind_password = '51niux.com' #用户搜索过滤器,例如"(cn =%s)"或“”(sAMAccountName =%s)" "或"(uid =%s)" search_filter = "(cn=%s)" #用户搜索的范围 search_base_dns = ["ou=users,dc=51niux,dc=com"]
#好了,配置好ldap认证之后重启服务就好了。当然你也可能遇到一些问题,可以先不要放到后台启动呢,将服务放到前台启动进行查看,基本按照我这么配就OK了,当然也要检查你跟ldap服务是否能够连上,如果连上了还不行可以直接用ldap命令试试。
3.2 ldap用户权限保持
#开启了ldap之后你可能会发现一个问题,比如给某个ldap分配了admin角色或者edit角色,但是退出再登陆或者重新登录就角色就消失了。那比如我想给我运维团队的小伙伴admin角色给其他的人一些edit角色,只能每次重新授权或者共用一个admin账户或者创建本地用户吗?显然有更好的办法:
# vim ldap.toml
## Map ldap groups to grafana org roles #[[servers.group_mappings]] #group_dn = "cn=admins,dc=grafana,dc=org" #org_role = "Admin" ## To make user an instance admin (Grafana Admin) uncomment line below ## grafana_admin = true ## The Grafana organization database id, optional, if left out the default org (id 1) will be used ## org_id = 1 # #[[servers.group_mappings]] #group_dn = "cn=users,dc=grafana,dc=org" #org_role = "Editor" # #[[servers.group_mappings]] ## If you want to match all (or no ldap groups) then you can use wildcard #group_dn = "*" #org_role = "Viewer"
#如上面所示,我们将关于ldap的映射全注释掉,不开启此功能,这样每次用户登陆的时候就不会映射对应的角色,那么授权也就不会变来变去。
四、Grafana开启匿名登录
#当然实际生产过程中,可能需要将grafana的监控图嵌套到其他的平台里面去,这时候可以考虑开启来宾用户访问,当然也叫匿名登录。
# vim grafana.ini
#################################### Anonymous Auth ###################### [auth.anonymous] #启用匿名访问,默认是false的 enabled = true #指定应用于未经身份验证的用户的组织名称 org_name = Main Org. #指定未经身份验证的用户的角色 org_role = Viewer
#好再次重启服务,这样当直接访问grafana的时候就不要登录,我们默认就是Views角色就可以看到允许Views角色可以看到的dashboard了。
#好的,这样就带来了两个问题,第一个问题,那么是不是谁都可以来把grafana嵌套到它的程序页面中,第二个问题因为grafana随着持续的深入所要展示的图标越来越多,不同的人应该看到不同的图,或者说人家一登录你的页面你有100张图而人家实际就关心一张图,所以又不能摊大饼的去展示。
博文来自:www.51niux.com
4.1 如何嵌套grafana界面
#这里就一个简单的demo了
#vim test.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <div style="width: 100%;height: 860px;"> <iframe id='orbitIframe'src="http://grafana.51niux.com/d/andAtAbie/k8s-jian-kong?orgId=1&refresh=5m&from=now-12h&to=now&var-Cluster=51niux-test01&var-Namespace=51niux&var-Pod=51niux-pod-test-01" width="100%" height="100%" frameborder="0" align="center"></iframe> </div> </body> </html>
#这就是嵌套的简单demo了,这样当访问你的页面就可以把grafana某个pod监控的页面嵌套到你的页面了,当然你也可以在你的页面进行其他指标的选择。
4.2 如何防止别人嵌套
#这手段就很多了,可以基于IP层面做限制,只允许指定的IP可以访问你的80端口,但是基于IP也不太好,因为办公网之类的面也很大的。
#前面我们不是用nginx做了反向代理了吗?可以把nginx用起来。
# vim /application/nginx/conf/nginx.conf
#表示该页面可以在相同域名页面的 frame 中展示。
add_header X-Frame-Options SAMEORIGIN;
server {#这样你就可以结合nginx本身的deny外加这个响应头过滤来进行防护。
X-Frame-Options 响应头:X-Frame-Options HTTP 响应头是用来给浏览器指示允许一个页面可否在 <frame>, <iframe> 或者 <object> 中展现的标记。网站可以使用此功能,来确保自己网站的内容没有被嵌到别人的网站中去,也从而避免了点击劫持 (clickjacking) 的攻击。
X-Frame-Options 有三个值:
DENY:表示该页面不允许在 frame 中展示,即便是在相同域名的页面中嵌套也不允许。 SAMEORIGIN:表示该页面可以在相同域名页面的 frame 中展示。 ALLOW-FROM uri:表示该页面可以在指定来源的 frame 中展示。
4.3 如何解决开启匿名登录之后的访问问题
#首先要提到的一点就是如果开启了匿名登录之后啊存在一个体验上面的小问题,就是默认登录进来只能看到一些基本能看到的吗,当别人给你发个链接如果不在权限范围之内呢就会提示此页面没有权限,这时候就要注意一下是否没有登录,就需要点击下页面的左下角进行登录,因为如果就算你没有登录(如果不开启匿名登录打开主页的时候是需要你登录验证的)也不会有登录验证,很多不经常使用的人可能会出现这个误区。
#前面我们已经提到了,默认登录就是给Views角色这也是最低的权限了只能进行查看,但是当我们开启匿名登录之后呢,就算不用登录也可以获取到Views的角色,那么就会带来我们如何保证所结合不同的数据源做的dashboard展示面向不同的用户呢?
#首先我们要知道的当你创建目录的时候默认就是Views用户拥有浏览权限,然后dashboard就会集成目录权限,意思也很直白就是当你给了目录Views觉得可以进行查看的话,你dashboard就不能吧这个Views角色给删除掉了,只能再次基础上进行新的添加操作。
好了既然知道了这个大概的逻辑就好办了,grafana还有一个Teams用户组功能,那么我们可以这样:将要不用登录就可以查看到的Dashboard放到一个目录下或者某一个目录下面,将那些要向不同的人群展示的Dashboard放到其他没有Views的目录下,这样你就可以通过Teams进行灵活的权限把控了,当然就算不开启匿名登录我们也是需要这个进行灵活把控的,只不过多了一步将目录的Views角色去掉的操作。
当然这也只是我想到的比较好的办法,如果大家有更好的办法可以提出来,大家一起学习下。
五、image_rendering
5.1 部署image_rendering插件
Grafana支持将面板和仪表板渲染为PNG图像。渲染图像时,PNG图像会临时写入文件系统,即Grafana数据目录的子目录png。后台作业每10分钟运行一次,并将删除临时图像。 可以通过配置temp-data-lifetime设置来配置在删除图像之前应存储多长时间。
Requirements(要求):
渲染图像可能需要大量内存,主要是因为在后台启动的“browser instances”负责实际渲染。 此外,如果要并行渲染多个图像,则肯定具有更大的内存占用空间。 最小可用内存建议为1GB。
Rendering methods(渲染安装和使用方式):
安装:
# yum install zip -y
#yum -y install gcc gcc-c++ make flex bison gperf ruby openssl-devel freetype-devel fontconfig-devel libicu-devel sqlite-devel libpng-devel libjpeg-devel
#yum install libXcomposite libXdamage libXtst cups libXScrnSaver pango atk adwaita-cursor-theme adwaita-icon-theme at at-spi2-atk at-spi2-core cairo-gobject colord-libs dconf desktop-file-utils ed emacs-filesystem gdk-pixbuf2 glib-networking gnutls gsettings-desktop-schemas gtk-update-icon-cache gtk3 hicolor-icon-theme jasper-libs json-glib libappindicator-gtk3 libdbusmenu libdbusmenu-gtk3 libepoxy liberation-fonts liberation-narrow-fonts liberation-sans-fonts liberation-serif-fonts libgusb libindicator-gtk3 libmodman libproxy libsoup libwayland-cursor libwayland-egl libxkbcommon m4 mailx nettle patch psmisc redhat-lsb-core redhat-lsb-submod-security rest spax time trousers xdg-utils xkeyboard-config -y
#wget https://nodejs.org/dist/v12.13.1/node-v12.13.1-linux-x64.tar.xz
# tar xf node-v12.13.1-linux-x64.tar.xz #环境变量自己配置了哈就不在这体现了
# node -v #先用这个node版本吧,用最新的v12.14.0发现有问题,node的安装前面有讲
v12.13.1
# npm config set registry http://registry.npm.taobao.org #配置taobao为源
#cd /application/grafana/data/plugins/
# git clone https://github.com/grafana/grafana-image-renderer.git
#cd grafana-image-renderer
#export GF_RENDERER_PLUGIN_IGNORE_HTTPS_ERRORS=true
#构建前端
# npm install -g yarn
# yum -y install bzip2
# yarn install --pure-lockfile
# npm run build
#编译安装grafana-image-renderer
# make deps && make build_package ARCH=linux-x64-glibc
# npm install -g node-pre-gyp node-gyp
# npm install
# yarn install --pure-lockfile
# yarn run build
# node build/app.js server --port=8081 #启动测试一下如果没问题使用nohup的方式放到后台启动。
# netstat -lntup|grep 8081 #查看一下有此端口
tcp6 0 0 :::8081 :::* LISTEN 18030/node
#更新配置文件
# vim grafana.ini #修改完重启grafana服务
[rendering] #Rendering服务器的地址可远端也可以本地,下面不要配置localhost可能会出现域名解析找不到host问题,可以写成127.0.0.1 server_url = http://192.168.1.101:8081/render #将渲染的图片返回给哪个grafana服务器可远端也可以本地 callback_url = http://192.168.1.101:3000/
PhantomJS:
从Grafana v6.4开始不推荐使用PhantomJS,并将在以后的版本中将其删除。 请迁移到Grafana image renderer plugin or remote rendering service。
自Grafana v2.x以来,PhantomJS是唯一受支持的默认图像渲染器,并且随Grafana一起提供。请注意,ARM不包含PhantomJS二进制文件。 为此,需要确保在tools/phantomjs/phantomjs二进制文件可用。
Alerting and render limits:
警报通知可以包括图像,但是同时渲染许多图像可能会使运行渲染器的服务器过载。
# vim grafana.ini
[alerting] #此限制将保护服务器免受渲染超负荷的影响,并确保快速发送通知。 concurrent_render_limit = 5
Troubleshooting(故障排除,如果没问题可不设置):
启用调试日志消息以在Grafana配置文件中进行渲染,并检查Grafana服务器日志。
# vim grafana.ini
[log] filters = rendering:debug
5.2 将截图存储于远端(单纯的举个例子没必要非要用)
#既然已经理解了PhantomJS和grafana-image-renderer就是将某一个时刻某个panel当时的状态做成一个截图,这个截图用来做什么用呢?比如可以在报警的时候发出去可以把图片加载着一起发出去又或者可以将当时的状态记录到本地或者远端供程序调用。
# vim conf/grafana.ini
[external_image_storage] # You can choose between (s3, webdav, gcs, azure_blob, local),默认就是local就是存储在本地的data/png/下面 provider = webdav [external_image_storage.webdav] url = https://dav.jianguoyun.com/dav/grafana username = grafana@51niux.com password = 51niux.com public_url = #这里就是坚果云分享链接也就是不需要账号密码的url地址,特别注意的当本地的图片上传到坚果云时候图片名称会发生变化, #比如你本地的图片名称是YECmbmO34A76tfE6Viig.png但是跑到坚果云上面之后是WcPcszYzEw91kaQ6l6fB.png,但是它会把这个url地址吐回来, #这时候比如你这里选择的是图片存储到远端,那么报警消息里面加载的图片的url地址就是你设置的这个public_url+此图片上传到坚果云的名称。
#可以看到我们grafana触发截图操作的时候,比如报警的时候就会本地产生一份截图然后上传到你指定的远端一份截图。这就相当于把报警那个时刻的具体指标图形给抓拍截图了。
博文来自:www.51niux.com
六、ALerting
Grafana中的警报允许你将规则附加到仪表板面板。 保存仪表板时,Grafana会将警报规则提取到单独的警报规则存储中,并安排它们进行评估。在图形面板的警报选项卡中,可以配置应评估警报规则的频率以及警报更改状态并触发其通知所需的条件。
6.1 配置Grafana+prometheus使用钉钉报警
#邮件报警就不说了,修改# vim grafana.ini 的[smtp]下面。
#好钉钉报警我们这里采用钉钉群组报警,那么就是创建钉钉机器人,然后就会得到hook链接。
配置Notification Channels:
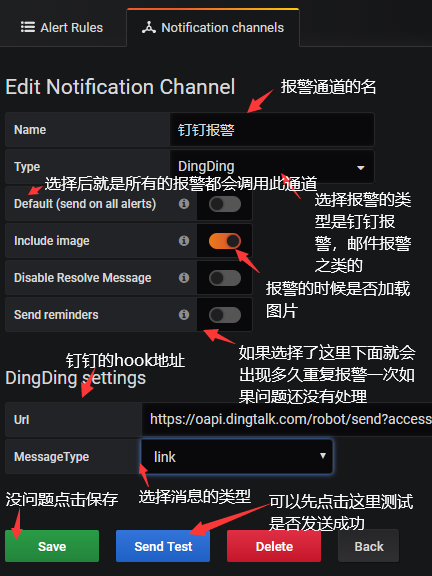
配置文件[server]修改:
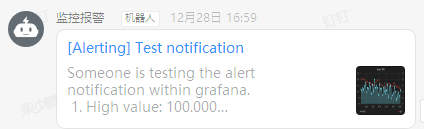
#上图为link类型的测试消息。
#好现在存在一个问题,现在你点开钉钉群的连接会发现跳转到了http://localhost:3000开头的一个URL地址完全打不开嘛。
# vim grafana.ini
[server] #协议类型 protocol = http #面向公众的域名,用于从浏览器访问grafana domain = grafana.51niux.com #完整的公开网址 #root_url = %(protocol)s://%(domain)s:%(http_port)s/ #这是原来默认的,但是我们已经用Nginx做了代理就可以用下面的了 root_url = %(protocol)s://%(domain)s
#这样报警发出去是一个链接,然后是以http://grafana.51niux.com开头的,这样大家点开你钉钉消息就可以打开一个页面了。
6.2 针对钉钉报警消息我们具体来说一说
#这里先不要关心怎么去触发报警,先要明确这个加载图片怎么用,也就是钉钉报警Include image怎么来实现。
# vim grafana.ini #我们就用默认截图存储到本地就好,特别注意provider一定要给一个类型比如local,不然你会发现你的报警不加载图片。
[external_image_storage] provider = local
先说不启动grafana-image-renderer:
#我们先假设我们没有按照上面的方式配置grafana-image-renderer插件,还是用的默认的PhantomJS。
#然后我们现在选择了加载图片然后试着触发一个报警,然后等了好长时间你发现你并没有收到报警,然后查看日志发现有报错:
# tail -f /application/grafana/data/log/grafana.log
INFO[12-31|17:49:01] Rendering logger=rendering path="d-solo/T3IZTHYZz/new-dashboard-copy?orgId=1&panelId=2" t=2019-12-31T17:49:01+0800 lvl=info msg=Rendering logger=rendering path="d-solo/T3IZTHYZz/new-dashboard-copy?orgId=1&panelId=2" INFO[12-31|17:49:31] Rendering timed out logger=rendering EROR[12-31|17:49:31] Failed to upload alert panel image. logger=alerting.notifier error="Timeout error. You can set timeout in seconds with &timeout url parameter" t=2019-12-31T17:49:31+0800 lvl=info msg="Rendering timed out" logger=rendering t=2019-12-31T17:49:31+0800 lvl=eror msg="Failed to upload alert panel image." logger=alerting.notifier error="Timeout error. You can set timeout in seconds with &timeout url parameter" ......省略中间内容 EROR[12-31|17:49:31] Failed to send DingDing logger=alerting.notifier.dingding error="context deadline exceeded" dingding=钉钉报警 EROR[12-31|17:49:31] failed to send notification logger=alerting.notifier uid=1CQspNLZz error="context deadline exceeded" EROR[12-31|17:49:31] failed to send notification logger=alerting.notifier uid=1CQspNLZz error="context deadline exceeded"
#啥意思呢,其实也很简单就是当你触发报警的时候,grafana根据触发报警的面板当时的状态往后台提交想做个截图然后一并随着报警消息发送出去,结果等的都超时了也没有得到返回,于是乎整条报警消息就发送失败了。
#然后你把Include image关闭掉发现报警可以发出来了,所以如果你想加载图片报警的话在grafana6.4以后的版本就要进行grafana-image-renderer插件的安装了。
先说Link形式:
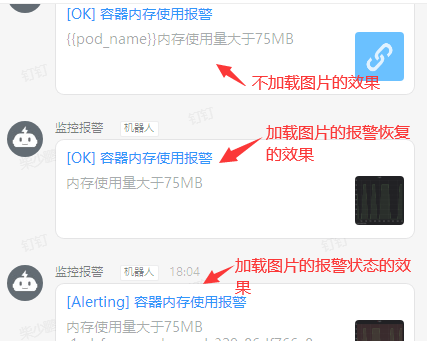
#所有警报通知都包含一个指向Grafana实例中已触发警报的链接。 该网址基于Grafana中的域设置,你点下消息就会跳转到grafana报警的页面。
#通过上面的截图可以看到,Link模式是可以直接将图片加载到消息中的,但是图太小了......,然后其实可以看下第三张图,其实下面还是有内容的就是说的哪个机器触发报警的值是多少,当然如果你数据众多也就显示一条,需要你点开这个报警连接跳转到报警的页面来仔细的查看。
#那么消息中的图片是哪来的呢?
#可以看到当报警触发的时候先触发了一个报警
t=2019-12-31T18:04:01+0800 lvl=info msg="New state change" logger=alerting.resultHandler ruleId=1 newState=alerting prev state=ok
#然后下面可以看到截图插件给我们返回了一个图片的url地址
t=2019-12-31T18:04:03+0800 lvl=info msg="uploaded screenshot of alert to external image store" logger=alerting.notifier url=http://grafana.51niux.com/public/img/attachments/P6NL1pA0Q7BV3FJrCdtp.png
#然后下面就是把这条消息发送出去了
t=2019-12-31T18:04:03+0800 lvl=info msg="Sending dingding" logger=alerting.notifier.dingding
t=2019-12-31T18:04:03+0800 lvl=info msg="messageUrl:dingtalk://dingtalkclient/page/link?pc_slide=false&url=需要点开的grafana的报警的url地址" logger=alerting.notifier.dingding
然后再说钉钉的actionCard形式:
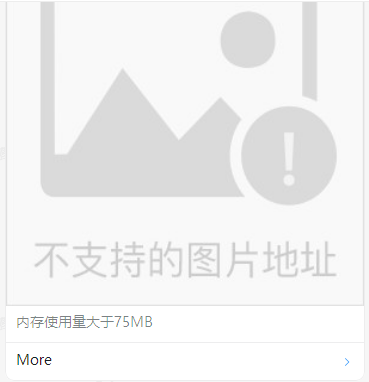
#可以看到首先你无法从这个消息体里面看到这是一个警告还是恢复状态,当然在群外面看群消息里面的表示是可以看到的。其实从报警消息中也可以理解为是报警还是恢复的,如果是报警的话会有提示什么实例触发了报警,如果是恢复的话就会像上图只有标题什么都不显示。其次呢就是这个图片你看不到,那怎么办呢?怎么来显示这个图片呢?
#很简单就是配置文件domain这里配置一个公网的IP或者你grafana本身的域名就是公网的,这样返回的那个图片的URL地址自然就是公网的自然可以被访问了。
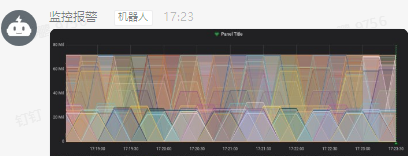
#上面就是将我们的grafana配置文件中的domain变成公网地址之后的效果,虽然是可以跟着消息一起放出来的,但是其实是两部分,消息是一部分图片是另一部分,我这种图片看着密密麻麻是想上百个容器的数据图,所以当报警出来的时候图片哪里是先从空白变为有图因为要加载会。
#Link方式呢如果报警的信息太多的话不会将报警信息全部显示出来,需要点击链接进入到grafana界面进行具体的查看的。比如可以点击grafana的State history来查看都有哪些实例触发了报警。而actionCard是可以把哪些实例触发了报警都列在报警消息中的。
#可以看到Link这种情况只需要你的网络跟grafana的网络是想通的就能看到消息中的图片,但是actionCard这种方式呢需要配置公网。
6.3 报警规则的配置
视觉阀值和报警规则是互斥的:
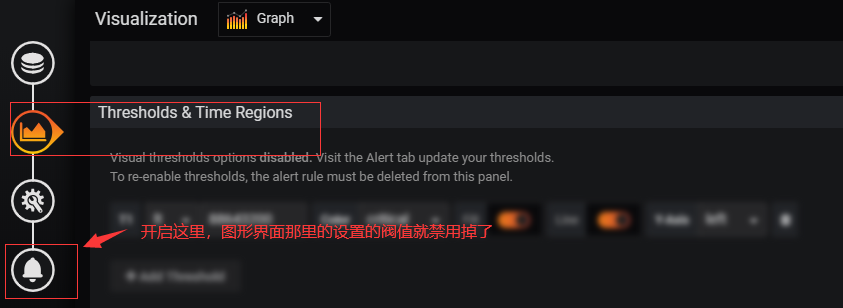
#首先要了解开启了Alert,视觉阈值选项就会禁用。要重新启用视觉阈值,必须从此面板中删除警报规则。
Alter之Rule:

#主要是for的理解:如果警报规则具有配置的For,并且查询到了阀值状态,它将首先从OK转到Pending。 Grafana从“OK”转到“待定Pending”将不会发送任何通知。 警报规则的触发时间超过“持续时间”后,它将更改为“Alerting”并发送警报通知。
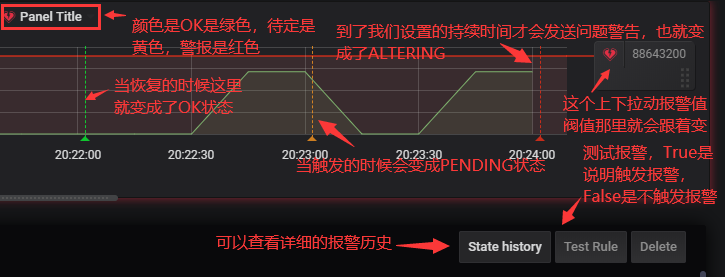
#比如上面我们设置了一个For是1m的持续时间,当每分钟检查的时候发现触发了阀值,如果持续一分钟还未解决就会报警出来。
#那么问题来了如果你For设置2m或者5m之类的持续时间,那么恢复的时候会遵从这个持续时间吗,显然恢复是不遵从这个For时间的,当下次循环检查的时候没问题就会变为OK状态并进行恢复报警。当然恢复也没有其他监控系统的单独的恢复报警设置。
Alter之Conditions(条件):
WHEN判断有:last(),avg(),min(),max(),sum(),count(),median(),diff(),percent_diff(),count_non_null() #这里其实是grafana内置的一些运算函数,有的可能一眼就知道怎么回事有些就比较蒙圈了。
count() #数据点数(在单位时间里去抓取了几次metric)。 median() #MEDIAN 函数是一种计算机函数,能够返回给定数值的中值,中值是在一组数值中居于中间的数值,如果参数集合中包含偶数个数字,函数 MEDIAN 将返回位于中间的两个数的平均值。 diff() #起始值和最终值之间的差异 percent_diff() #起始值与最终值之差/起始值与最终值的平均值*100 count_non_null() #value不为空的count
#count通常是指(单位时间内的)metric数据的数量(例如,名称为qps的metric,在过去1分钟内,每隔15s去获取1次qps的值,那么过去1分钟的count(qps)就是5),如果数据源是ElasticSearch,这个count通常指单位时间内的日志条目(日志数量)。但是如果数据源是Prometheus的的话,由于Prometheus的配置文件指定了每隔多久去抓取1次数据,因此count的数量比较固定。
然后中间有个阀值的类型:
IS ABOVE #在什么值以上也就是大于某个值 IS BELOW #在什么值下面也就是小于某个值 IS OUTSIDE RANGE #在两个值的范围以外 IS WITHIN RANGE #在两个值的范围内 HAS NO VALUE #没有值

query(A, 5m, now): 字母定义从“Metrics”选项卡执行的查询,比如我们只有一条metrics查询语句就是A,如果你又加了一条查询语句那么就会有B。 后两个参数定义时间范围5m,即现在到之前的的5分钟。 你也可以设置成从10m开始,now为2m,以定义10分钟前到2分钟前的时间范围。 如果你要忽略最后2分钟的数据,这将很有用。
警报规则中使用的查询不能包含任何模板变量。 目前,仅支持条件之间的AND和OR运算符,并且它们是串行执行的。 例如,有3个条件,其顺序如下:condition:A(评估为:TRUE)或condition:B(评估为:FALSE)AND condition:C(评估为:TRUE),因此结果将计算为 ((TRUE OR FALSE) AND TRUE) = TRUE。
Multiple Series:
如果查询返回多个序列,则将针对每个序列评估聚合函数和阈值检查。 Grafana当前不执行的是每个系列的跟踪警报规则状态。 这具有以下场景中详细介绍的含义。
查询的警报条件返回2个系列:server1和server2 server1系列导致警报规则触发并切换到状态警报 通知随消息一起发送:负载峰值(server1) 在对同一警报规则的子序列评估中,server2系列也会导致警报规则触发 由于警报规则已处于警报状态,因此不会发送新的通知。
因此,从上述情况中可以看到,如果规则已经处于Alerting状态,则其他系列导致警报触发时,Grafana不会发出通知。 为了改善对返回多个系列的查询的支持,计划在将来的版本中跟踪每个系列的状态。从Grafana v5.3开始,可以配置要发送的警报提醒。 当警报继续触发时,这将发送其他通知。 如果其他系列(例如上例中的server2)也导致触发警报规则,则它们将包含在提醒通知中。 根据你正在使用的通知渠道,可以利用此功能来识别导致警报触发的new/existing的系列series。
Clustering:
当前,警报支持有限形式的高可用性。 从Grafana v4.2.0开始,运行多个服务器时将删除警报通知。 这意味着所有警报都在每台服务器上执行,但是由于重复数据删除逻辑,不会发送重复的警报通知。 未来将引入适当的警报负载平衡。
Execution(执行):
警报规则在Grafana核心的一部分的调度程序和查询执行引擎的Grafana后端中进行评估。 目前仅支持某些数据源。 它们包括Graphite,Prometheus,InfluxDB,Elasticsearch,Stackdriver,Cloudwatch,Azure Monitor,MySQL,PostgreSQL,MSSQL,OpenTSDB,Oracle和Azure Data Explorer。Azure Monitor的警报支持仅在Grafana v6.0及更高版本中可用。
Alter之No Data & Error Handling:

No Data / Null values(无数据/空值):
可以配置规则评估引擎应如何处理不返回数据或仅返回空值的查询。
NoData #将警报规则状态设置为NoData Alerting #将警报规则状态设置为“Alerting” Keep Last State #保持当前警报规则状态,无论状态如何。 OK #将警报规则状态设置为OK
执行错误或超时
最后一个选项告诉你如何处理执行或超时错误。
Alerting #将警报规则状态设置为“Alerting” Keep Last State #保持当前警报规则状态,无论状态如何。
如果有一个不可靠的时间序列存储库,该存储库中的查询有时会超时或随机失败,则可以将此选项设置为Keep Last State以便基本忽略它们。
#下图是我们把数据源去掉之类的查看一下没有数据的报警状态:

Notifications:
在警报选项卡中,还可以指定警报规则通知以及有关警报规则的详细消息。 该消息可以包含任何内容,有关如何解决问题的信息,指向Runbook的链接等。实际的通知已配置并在多个警报之间共享。
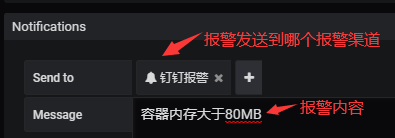
#注意这个Message只是一个固定的内容,比如你监控容器,容器报警了,消息中还会在此固定内容下面显示都哪些容器触发报警了,当然消息太多的话并不会完全显示。
Use alert rule tags in notifications(在通知中使用警报规则标签):
上图其实在界面下面还有Tags一栏,仅在Grafana v6.3 +中可用。Grafana可以在通知中包含标签列表(key/value)。 称为警报规则标签,可与从时间序列中解析出的标签进行对比。 当前仅支持Prometheus Alertmanager通知程序。这是一项可选功能。 可以在不使用警报规则标签的情况下获得通知。
Troubleshooting(故障排除):
可以做的第一级故障排除是单击“Test Rule”按钮。 将获得结果,可以扩展到可以查看查询返回的原始数据的位置。还可以通过检查grafana服务器日志来完成进一步的故障排除。 如果不是错误或出于某种原因,日志中没有任何内容,则可以为某些相关组件启用调试日志记录。 这是在Grafana的ini配置文件中完成的。该示例显示了在对警报进行故障排除时可能相关的记录器。
[log] filters = alerting.scheduler:debug \ alerting.engine:debug \ alerting.resultHandler:debug \ alerting.evalHandler:debug \ alerting.evalContext:debug \ alerting.extractor:debug \ alerting.notifier:debug \ alerting.notifier.slack:debug \ alerting.notifier.pagerduty:debug \ alerting.notifier.email:debug \ alerting.notifier.webhook:debug \ tsdb.graphite:debug \ tsdb.prometheus:debug \ tsdb.opentsdb:debug \ tsdb.influxdb:debug \ tsdb.elasticsearch:debug \ tsdb.elasticsearch.client:debug \
如果要记录发送到TSDB的原始查询和日志中的原始响应,还必须将grafana.ini选项app_mode设置为development。
6.4 Notifications
查看当前总的报警状态:

#上图右边那个一个暂停图片很好理解就是禁用此报警,另一个齿轮就是重新配置此条报警。
重复报警:
#默认报警规则触发后,只报一次,不会重复报警,如果你想重复报警的话就需要在你所创建的消息channels里面进行设置了。
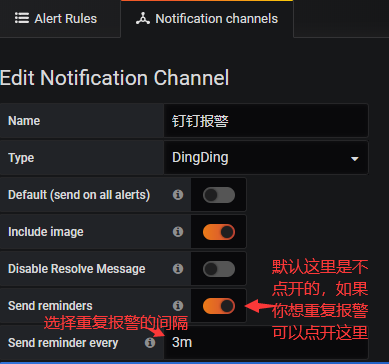
#要特别注意重复报警的间隔不能比再次检查的时间频率要短。当再次报警的时候State history那里只会显示第一次报警的时间,Alter Rules那里也只会显示最后一次报警的时间,当然如果你加载图片的话,重复报警消息就只有问题消息不会再加载图片了。
Send reminders(发送提醒):
仅在Grafana v5.3及更高版本中可用。选中此选项时,将为触发的警报发送其他通知(提醒)。 可以使用秒数,分钟(m)或小时(h)(例如30s,3m,5m或1h等)指定发送提醒的频率。重要提示:评估规则后,将发送警报提醒。 因此,永远不要比配置的警报规则评估间隔更频繁地发送提醒。这些示例显示了发送触发警报的提醒的频率和时间。
Alert rule evaluation interval 警报规则评估间隔 | Send reminders every 每次发送提醒 | Reminder sent every (after last alert notification) 每次提醒发送(最后一次警报通知后) |
|---|---|---|
30s | 15s | ~30 seconds |
1m | 5m | ~5 minutes |
5m | 15m | ~15 minutes |
6m | 20m | ~24 minutes |
1h | 15m | ~1 hour |
1h | 2h | ~2 hours |
Metrics from the alert engine(警报引擎的指标)
警报引擎发布有关其自身的一些内部指标。
| Description | Type | Metric name |
|---|---|---|
| Total number of alerts(警报总数) | counter | alerting.active_alerts |
| Alert execution result(警报执行结果) | counter | alerting.result |
| Notifications sent counter(通知发送计数) | counter | alerting.notifications_sent |
| Alert execution timer(警报执行计时) | timer | alerting.execution_time |
Supported Notification Types(支持的通知类型):
Email:
要启用电子邮件通知,必须在Grafana配置中设置SMTP设置。 电子邮件通知会将警报图的图像上载到外部图像目标(如果可用),或者将其后退以将图像附加到电子邮件。 请注意,如果使用local图像存储,则电子邮件服务器和客户端可能无法访问该图像。
Webhook:
Webhook通知是一种通过HTTP将状态更改信息发送到自定义端点的简单方法。 使用此通知,可以将Grafana集成到选择的系统中。示例json主体:
{
"title": "My alert",
"ruleId": 1,
"ruleName": "Load peaking!",
"ruleUrl": "http://url.to.grafana/db/dashboard/my_dashboard?panelId=2",
"state": "alerting",
"imageUrl": "http://s3.image.url",
"message": "Load is peaking. Make sure the traffic is real and spin up more webfronts",
"evalMatches": [
{
"metric": "requests",
"tags": {},
"value": 122
}
]
}state-警报状态的可能值为:ok, paused, alerting, pending, no_data。
DingDing/DingTalk:
如下所示:https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxx。 将此URL复制到grafana Dingtalk设置页面,然后单击“finish”。Dingtalk支持以下“message type”:text, link and markdown。
Kafka:
可以使用Kafka REST Proxy将通知从Grafana发送到Kafka主题。 需要在Grafana UI中的“ Kafka Settings”下设置几个配置选项:
Kafka REST Proxy endpoint、Kafka Topic。设置完这两个属性后,可以将警报发送到Kafka进行进一步处理或限制。
6.5 grafana发送Prometheus中的容器报警
#这里最后小提一下,到现在我用的6.5版本还是没能解决模板中使用变量进行报警,现在是直接关闭了此功能。
Template variables are not supported in alert queries #警报查询中不支持模板变量

#如果你的面板中引用了变量就不能进行Alter报警设置。
#那么我们怎么做容器监控呢,不能用变量就只能使用正则了。
比如我们Metrics的查询语句是:
sum(rate(container_memory_usage_bytes{image!="",pod_name=~"^(docker|ingress)-.*"}[1m])) by (pod_name)#那么前提呢就是你的容器名称最好开头最好就是一个固定唯一的,因为结尾k8s会给你随机加字符你控制不了。这样通过正则就能进行Alter设置了。
#这样报警其实有带来几个问题:
第一个就是你原来做的展示图只能作为展示用,你还要单独做张图进行报警用,如果你容器少还好,如果有几千个上万个,都汇聚到一张图上面进行渲染那可能直接就卡死了,因为是正则匹配所有并不是选择某几个进行出图。
第二个问题呢就是大家这些容器可能限制不同但是都要公用一个固定值或者一个百分比很不灵活。
第三个问题呢就是比如你这次有50个容器触发了报警,会汇总到一个报警消息里面发出去告诉你这50个容器分别当前值是多少,当然现在如果选择用钉钉的actionCard类型会给你一条条列出来,如果是选择Link类型也就给你显示一条剩下的就需要你点击链接跳转到grafana界面查看了。当然这都不是问题,真正的问题是这些报警是一起报警了,就算中间有容器恢复了也不会恢复体现,是得所有都恢复才会发送恢复消息。
第四个问题呢就是要注意官网有提高alter报警并不支持高可用什么意思呢,就是如果你又两个grafana你配置了alter,这个规则其实并没有写入到数据库中,是写到某一个grafana实例中的,当你发生跳转到另一个grafana中的配置报警规则什么的都不见得,我测试着是这样。
