zabbix之高级进阶(十)
#翻看了下之前写的东西,距离写Zabbix系列已经过去了好几年,当时还是2.X现在已经5.X,当然我没有去了解5.X的新特性,就是再补充一些之前没有写到了,也算给还在用Zabbix的一些帮助吧。
一、主机监控自动化
#不管是云主机还是IDC硬件主机,现在新增了一台一台主机,现在我们要把主机自动添加到监控中并跟对应的主机组和模块相关联如何弄?
下面我们提一下可能遇到的问题:
如何发现一台新增主机。
如何知道此主机跟哪个部门挂钩。
如何让不同类型的主机跟不同的模板关联。
当主机状态发生变更的时候如何更新。
当主机发生报警时如何发送到指定联系人。
当主机问题迟迟不解决或者严重时如何升级报警。
当主机消亡的时候如何从主机中移除。
#好了带上上述的问题,我们来设计下这个监控自动化的全流程。
1.1 发现新增主机
#如果是IDC机房,一般都有CMDB管理平台,当有一台主机新增的时候,可以让CMDB平台的资产信息变化来获取新增的主机。
#下面我们就以阿里云平台简单举例吧:
#首先我们本地要有一份比如redis缓存或者mysql数据库,用来缓存主机信息,用来和阿里云接口返回的数据做对比用来判断如何进行增删改查。
这就属于代码逻辑细节的东西了可以自己根据自己的需求写了。
不过有一点要注意,就是肯定是用多线程处理不然数据处理时间会随着数量级页数的增多而增多,另一点就是接口经常会有不稳定或者调用接口不通了返回的数据不准的时候,比如漏了一部分啊或者直接取不到数据了,这时候你判断云主机已经没这台主机了,而本地库有,就要进行删除操作了,这样就会形成误删。然后下一次或者下几次再读取发现又新增主机了,又判断为是新增主机了。为了避免这种误删和误增,在删除主机的时候最好加个ping判断如下图,最好多线程的判断多主机的存活状态,这样不会导致信息监测脚本执行时间过长:
del_host_dict = dict()
#对ip进行ping检测查看是否能ping通,如果不通的话加入到redis的删除缓存中
def ping_check(self,*args):
ecs_ip = args[0]
InstanceId = args[1]
cmd_fild = 'ping %s -c 1 -w 1 >/dev/null' % (ecs_ip)
result = os.system("%s" % (cmd_fild))
if result != 0:
del_host_dict[InstanceId]=ecs_ip
print(del_host_dict)
#检查资产是否进行删除操作
def alive_check(self):
threadl = []
for InstanceId,ecs_ip in tmp_del_dict.items():
t = threading.Thread(target=self.ping_check,args=(ecs_ip,InstanceId,))
threadl.append(t)
for x in threadl:
x.start()
for x in threadl:
x.join()1.2 获取主机组
#通过上面的小例子我们已经简单了解了获取一个主机信息变更(新增/修改/删除)的方法,那么我们怎么让主机跟对应的主机组相关联呢。
#要么就是主机名设置成部门那种方式,比如技术中心-运维部-主机应用类型,或者是tag标签标注这个IP是哪个部门的,比如我们以主机名为例:
z_tmp=InstanceName.split('-')#把主机名切割一下,然后就可以取到部门了,那么问题又来了有的部门有三级部门,有的部门只有二级,有的部门还有四级部门,如何让主机跟最低的那层部门挂钩呢?那么就需要维护一个部门结构元数据,或者比如我们默认就是三级部门切割,但是特殊的只有二级部门或者有四级部门的单独在一个表里记录下来,通过表查询筛选的方式获得正确的部门,这样是有一个类似于CMDB平台的东西来维护一些映射关系,更有灵活性。
主机和主机组绑定:
好的比如我们现在已经取得了主机组,怎么让zabbix中的主机和主机组绑定呢?
#比如我们定义一个函数只需要将IP和主机组交给它,它就去做绑定 host_group(ecs_ip,groupname,'Discovered hosts')
#上面传了一个Discovered hosts,也就是一个主机会跟两个组关联,一个部门组和一个自动发现组,为什么要传两个组呢?这是跟zabbix的机制有关系的,因为是zabbix的用户和zabbix的主机组关联来获得拥有哪些主机的权限,默认自动发现的主机都会把主机丢到Discovered hosts组中。那么我们就把Discovered hosts当成一个all组也就是这个组拥有所有主机,那么报警和出图的用户跟只要拥有这个组的权限就相当于拥有了所有主机的权限,就不会造成因为没有权限而收不到某些主机的报警或者某些图出不来了。因为你部门会变化,主机组肯定肯定会有新增,如果你不能及时的将新增的主机组和报警和出图用户相关联就会受影响,当然也可以通过自动化的方式解决。
data = {
"jsonrpc": "2.0",
"method": "host.update",
"params": {
"hostid": hostid,
"groups": [
{
"groupid": groupid
},
{
"groupid": default_groupid
}
]
},
"auth": token,
"id": 1
}#然后通过zabbix的数据库获取到id号,然后调用zabbix的接口进行主机和主机组绑定就好了。
API接口文档:https://www.zabbix.com/documentation/5.0/manual/api
#当然这个主机和主机组绑定是先得有主机和主机组才能绑定哈。
如果没有主机组我们可以先创建:
data = {
"jsonrpc": "2.0",
"method": "hostgroup.create",
"params": {
"name": groupname
},
"auth": token,
"id": 1
}1.3 如何跟不同模板绑定
主机一般会分为线上/线下主机,业务机,运维管理机,大数据机型,k8s宿主机等等。
首先我们可以通过主机名或者tag标签获得这个主机是什么类型的主机,比如主机名可以带有线上/线下标识,k8s主机带有k8s标识等等,如:
node_type,department,env_type = self.host_check(InstanceName)
#如上面,我们可以定义一个函数通过主机名获取到我们想要的信息,是主机类型,什么部门,线下/线下主机
#可以基于上面获得的信息再获得应该交给哪个zabbix_proxy,定义什么样的HostMetadata
#然后把变量统统的交给模板文件:zabbix_agentd.conf.j2
PidFile=/opt/zabbix/logs/zabbix_agentd.pid
LogFile=/opt/zabbix/logs/zabbix_agentd.log
LogFileSize=20
Server={{zabbix_server}}
ServerActive={{zabbix_proxy_host}}
HostMetadata={{HostMetadata}} {{ansible_distribution}}
Hostname={{ecs_host}}
Include=/opt/zabbix/conf/zabbix_agentd.conf.d#然后我们再针对不同的HostMetadata做不同的自动注册动作,这样就能让不同的主机和不同的模板绑定了。
博文来自:www.51niux.com
1.4 主机信息更新
#前面已经提到了,通过调用接口来跟本地的库进行比较判断是否需要更新,这个代码逻辑就要复杂点,要考虑是IP变了,还是部门变了,还是主机和部门都发生了变化。然后经过判断写三个函数根据不同的判断调用不同的函数。
update_dict = dict() #如果IP没变化,只是实例名称发生了变化,定义变化类型为Name if PrimaryIpAddress == Old_PrimaryIpAddress and InstanceName != Old_InstanceName: update_dict['type'] = 'Name' Mredis().update_hash(key='update_hash',dn=InstanceId,value=update_dict) #如果IP变化了,但是名称未变化,定义变化类型为IP elif PrimaryIpAddress != Old_PrimaryIpAddress and InstanceName == Old_InstanceName: update_dict['type'] = 'IP' Mredis().update_hash(key='update_hash',dn=InstanceId,value=update_dict) #如果IP和实例名称都发生了变化,定义变化类型为ALL也就是都发生了变化 elif PrimaryIpAddress != Old_PrimaryIpAddress and InstanceName != Old_InstanceName: update_dict['type'] = 'All' Mredis().update_hash(key='update_hash',dn=InstanceId,value=update_dict)
#如上面是一个小例子,为了异步不影响信息处理的进度,我们把更新的操作记录到一个redis的缓存中再有一个任务来读取缓存去进行操作。因为不管IP和名称怎么变ID是不会变的,所以我们用ID作为dn。比如IP改变了,下面是zabbix的api调用结构:
#先把旧的ip改为新的ip
data = {
"jsonrpc": "2.0",
"method": "host.update",
"params": {
"hostid": hostid,
"host": new_ecs_ip,
},
"auth": token,
"id": 1
}
#再把旧的连接接口地址改为新的ip地址
data = {
"jsonrpc": "2.0",
"method": "hostinterface.update",
"params": {
"interfaceid": interfaceid,
"ip": new_ecs_ip
},
"auth": token,
"id": 1
}#当然部门发生变化的话就走上面的ip和主机组绑定的接口就行了,这样就做到了源头一变zabbix也跟着发生变化的效果。
1.5 主机报警关联负责人
#很久以前的报警方式可能是邮件的形式,先做一个脚本的媒介,然后传递报警联系人,报警人联系人也就是用户那里配置的个人邮箱,如下图:

#如果按照上面图形的方式,就要创建很多的用户,然后不同的用户跟不同的邮箱绑定,然后创建很多的报警动作让不同的主机和用户绑定,来做到不同的主机发送到不同联系人的目的。
上面的方式显然是一种很繁琐而且不能自动化的方式,我们如何化繁为简呢,其实还是用脚本的方式,我们可以写一个python脚本,然后根据传过来的IP地址去cmdb库中搜出负责人,然后通过钉钉群组或者单独钉钉的方式发送给指定负责人。

#如上图我们可以定义一个Python脚本的报警媒介
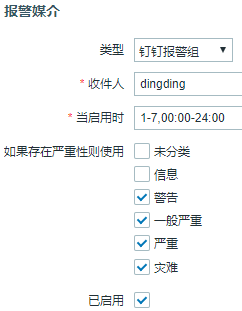
#然后我们再可以创建一个用户跟此报警媒介绑定。

#然后让报警动作跟创建的用户绑定也就是跟python脚本绑定。
报警格式化:
告警地址: {HOST.IP}
监控取值: {ITEM.LASTVALUE}
告警等级: {TRIGGER.SEVERITY}
告警信息: {TRIGGER.NAME}
告警时间: {EVENT.DATE}-{EVENT.TIME}
持续时间:{EVENT.AGE}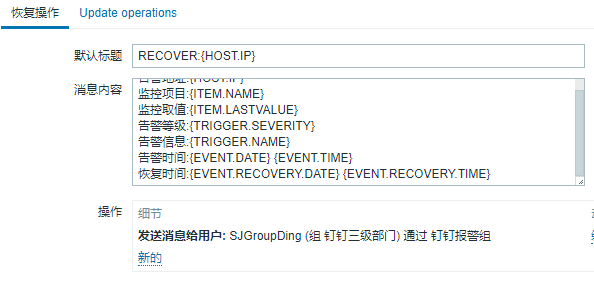
#如上图,恢复报警也做同样的格式化处理:
告警地址:{HOST.IP}
监控项目:{ITEM.NAME}
监控取值:{ITEM.LASTVALUE}
告警等级:{TRIGGER.SEVERITY}
告警信息:{TRIGGER.NAME}
告警时间:{EVENT.DATE} {EVENT.TIME}
恢复时间:{EVENT.RECOVERY.DATE} {EVENT.RECOVERY.TIME}通过上面一系列的设置,整个自动化就串起来了,所有的信息都会发送给这个python脚本,这个Python脚本可以通过标题获取是恢复报警还是故障报警,然后通过标题中的IP去cmdb库中拿到负责人信息,然后就可以把报警信息或者恢复消息发送给指定的负责人了。
1.6 做升级报警
升级报警的简单说呢就是报警媒介的升级,一开始可能是邮箱或者钉钉群组,如果问题一段时间不解决是不是就应该升级到短信、微信、电话等其他通知渠道了呢,然后就是报警接收人是不是就应该往通知更上级的人员了呢。也就是报警媒介和报警接收人的升级,报警消息时间间隔是不是也要发生变化呢。但是并不是所有的报警都要升级吧,不如一般的故障报警可能报一天都不影响业务,是不是只有一些我们关心的比较敏感的或者是严重级别的报警信息才会用到报警升级呢?这又要做分级报警。
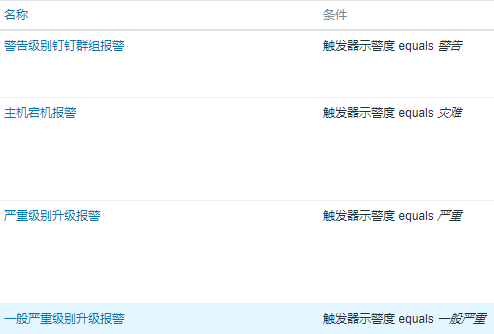
#如上图我们可以根据不同的报警级别做一些不同的报警动作来做到报警分级的目的,因为不同的报警动作可以设置不同的报警间隔和媒介。
报警升级呢,就是我们做几个报警媒介有短信的有电话的等等,然后与之对应的呢创建几个用户跟报警媒介绑定,然后报警动作可以设置问题多长时间不解决就发送给指定的用户,也就相当于调用了不同媒介的脚本,那么在脚本中就可以控制报警发给谁用什么媒介报警了。

#上图是一个严重级别动作报警的例子,我们先是钉钉群组通知,10分钟不解决就单独发送机器负责人和所属领导,还不解决就升级短信再不解决就升级电话,因为一般严重级别的报警要迅速关注并解决不然就可能影响业务了。
1.7 主机如何自动删除
这个问题就简单了,就跟一开始的自动化添加主机相悖就行了,我们通过程序发现主机已经消失后,就可以将此主机加入删除队列,然后负责删除的程序从队列中拿到此主机调用接口进行删除操作就可以了。
data = {
"jsonrpc": "2.0",
"method": "host.delete",
"params": [
hostid
],
"auth": token,
"id": 1
}#上面就是调用接口的data部分,就是通过主机的IP拿到主机的hostid然后调用接口删除就可以了,当然也得拿到用户的token哈。
二、自定义监控项
#我们使用zabbix肯定不是想就单纯的使用程序本身自带的一些监控系统性能指标的功能,我们还需要自定义开发,前面也有提到怎么监控TCP等。
博文来自:www.51niux.com
2.1、进程监控存活
#zabbix自带的是系统进程总数和运行数,如果我们想检测某个进程是否存活呢。
以NTP进程监控为例:

#这样图形上会显示ntpd这个关键字的进程数量,一般就是一个进程就是1。那么触发器就是判断获取到的值<1就可以报进程不存在的警了。
下面翻译下官网关于proc.num的用法:
proc.num[<name>,<user>,<state>,<cmdline>,<zone>]
name - 进程名称(默认为所有进程) user - 用户名(默认为所有用户) state - possible values: all (default), run, sleep, zomb(全部(默认),运行,睡眠,僵尸) cmdline - 通过命令行过滤(这是一个正则表达式) zone - 目标区域:当前(默认),全部。 仅在Solaris上支持此参数。
例子:
⇒ proc.num[,mysql] → mysql用户下运行的进程数 ⇒ proc.num[apache2,www-data] → 在www-data用户下运行的apache2进程数 ⇒ proc.num[,oracle,sleep,oracleZABBIX] → 在命令行中有oracleZABBIX的oracle下处于睡眠状态的进程数
注意:当从命令行调用此项目并包含命令行参数时(例如,使用agent 测试模式:zabbix_agentd -t proc.num [,,, apache2]),由于agent 将对其自身进行计数,因此将计入一个额外的进程 。
2.2 进程资源占用监控
#上面已经检测了进程的存活状况,如果CPU和内存报警了后来又恢复了,我们想看是什么进程比较高的导致的报警怎么方便我们回查呢?
在服务端定义模板:

#现在模板中定义两个自动发现规格,注意键值是用来调用客户端的自定义脚本传参用的,键值里面用了宏变量,是为了灵活的采集Top NUM的指标。

#上面以CPU自动发现规则为例,重点要关注一个更新时间和一个资源周期不足时间,更新时间很好理解就是多久去执行一次自动发现,对于进程来说变动还是比较大的最好更新间隔设置的小一点,像磁盘分区啊哪些变动频率比较低一般会设置的比较大。资源周期不足这个就要重点关注了,打个比方你原来的Top3进程是ABC,后来进程ABC重启了,如果你的指标名称包含有进程id那么现在就相当于你发现了6个指标,3个存在3个已经不存在了,如果你这里回收时间设置的比较长,那么你的不存在过期指标就会很多,在监控中会出现大量的无用的监控项,如果配置了触发器也会有大量无用的触发器。简而言之资源周期不足就是过期key的回收时间。
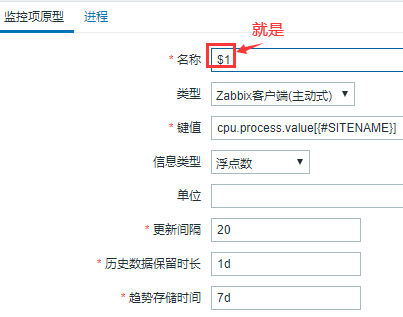
#还是以CPU为例,我们将{#SITENAME}也就是自动发现的采集指标项定义为监控项的名称。

#上图为监控的效果图,我这里在自动发现的时候就把重要信息拼接到了一个cpu-进程用户-进程ID-进程名称,然后作为参数交给监控采集。
#然后想哪个主机进行CPU和内存的进程监控就关联这个模板就可以了。
在客户端的配置:
# cat /application/zabbix/conf/zabbix_agentd.conf.d/userparameter_process.conf
UserParameter=cpu.process.discovery[*],/application/zabbix/conf/zabbix_agentd.conf.d/scripts/process_discovery.sh cpu_process_discovery $1 UserParameter=mem.process.discovery[*],/application/zabbix/conf/zabbix_agentd.conf.d/scripts/process_discovery.sh mem_process_discovery $1 UserParameter=cpu.process.value[*],/application/zabbix/conf/zabbix_agentd.conf.d/scripts/process_info.sh $1 UserParameter=mem.process.value[*],/application/zabbix/conf/zabbix_agentd.conf.d/scripts/process_info.sh $1
#process_discovery.sh这个脚本的大概意思就是根据传参获取到是CPU进程自动发现还是内存进程自动发现,然后是取TOP几的进程。然后把进程转换成我们上图中的格式返回给服务端。
#process_info.sh的意思简单了,就是将键值拆分后取到对应的值,如下面
#/bin/bash
PID=`echo $1|awk -F "-" {'print $3'}`
if [ `echo $1|awk -F "-" {'print $1'}` = 'cpu' ];then
value=`top -p $PID -bn1 |grep "$PID "|awk {'print $(NF-3)'}`
elif [ `echo $1|awk -F "-" {'print $1'}` = 'mem' ];then
value=`ps -p $PID -o pmem --no-headers`
fi
echo $value#然后重启此主机的zabbix客户端就好了。
最后我们通过grafana将我们的进程结果展示一下:

#上图为一个不同机器内存占用情况的效果图,一般服务内存都是比较平稳的。
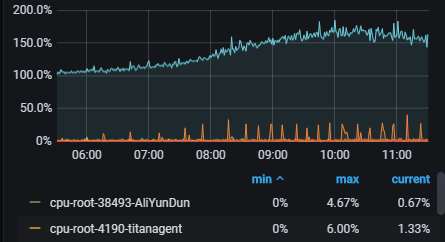
#上图是一个不同进程的CPU占用情况,可以看到CPU的波动还是比较大的。
好了通过上面一系列的操作,当我们的主机出现CPU和内存报警的时候可以通过grafana来查看到底是哪个进程导致的,当然瞬时报警很快恢复也可以通过监控去回查是哪个进程的问题。
2.3 系统关键字监控
#系统运行过程中有些问题是会体现到message日志或者其他日志中的,比如时钟不稳、系统内核异常导致服务假死、被攻击、磁盘有问题等等,所以将系统日志的一些异常关键字监控起来,对我们及时的发现问题还是很有帮助的。
实现方式呢也很简单,前面我们已经了解了自定义监控了,就是再做一个脚本去检测比如/var/log/message日志,发现近段时间出现了我们定义的关键字就报警出来,具体的脚本就不贴了,大家可以自己写实现这个功能:
grep 'kernel:' /var/log/messages|egrep -v 'IPVS|IPv6|overlayfs|entered promiscuous mode|left promiscuous mode|local_softirq_pending|entered blocking|entered forwarding|hrtimer: interrupt took|RT throttling activated|net_ratelimit|entered disabled|docker0'
#上面是根据长期的检测核查比较通用性的屏蔽一些不必要的系统关键字减少误报。给大家做一个参考。
博文来自:www.51niux.com
2.4 触发器灵活运用
#自动发现的时候一般会用到触发器,简单的说就是整个过滤,http://blog.51niux.com/?id=153这里有介绍触发器。
这里就是再说一下,K8S的Node节点的监控跟普通的主机的监控采集有点不一样,因为它会产生很多的网卡名称和盘符出来,如果你引用zabbix本身的磁盘发现和网卡发现就可能是下面的效果:

#因为随着容器频繁的创建销毁,你这里就存储了好多已经无用的监控项,就会出现很多无效的触发器和图形。
解决办法也很简单,就是重新定义正则表达式供K8S集群引用:



#然后模板引用一下我们自定义的正则表达式就可以了。
三、数据统计
3.1 Grafana主机组显示
#如果我想一个dashboard一张图就查看我们部门主机的整体情况呢?也就是把load\CPU\内存\网卡啊都集中到一个大屏中来。
首先定义好变量(一个主机组,一个主机变量):

制作出图面板:
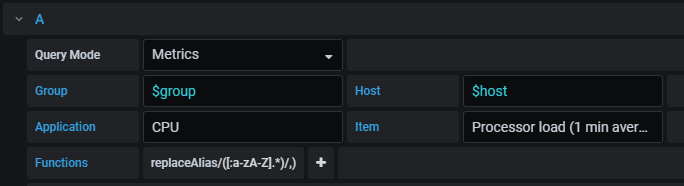
#上图为load的Graph图形,我们通过Functions将IP获取出来。
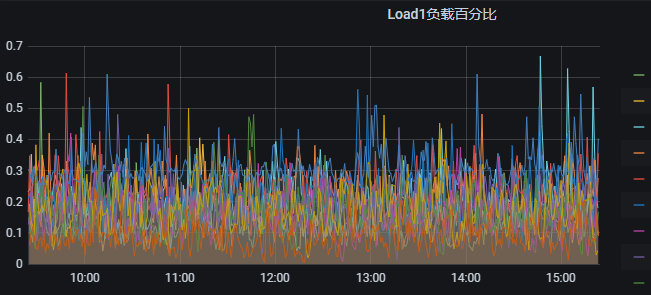
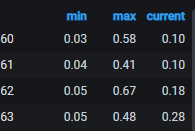
#上图就是load的效果图,这样通过选择主机组的方式就可以将一个部门的所有主机某一项指标的数据绘制到一张图中了。其他图的制作同上。
#不过有一点需要注意的,这个不能几百台主机同时显示,接口返回不了那么大量的数据查询。
3.2 脚本进行资源使用情况统计
比如这时候需要出一版主机资源利用率的情况,想很直观的制作成表格来分析哪些主机空闲率比较高或者比较繁忙,这就需要写python脚本去数据库中去读取了。
简单写个python脚本以CPU空闲率为例:
#start_clock=1604160000 #开始时间样例
#end_clock=1605024000 #结束时间样例
class Zabbix_Select(object):
def select_cpu_idle(**kwargs):
ecs_ip = kwargs['ecs_ip']
#将host的hostid查询出来
hostid = Zabbix_Mysql.select_hostid(ecs_ip=ecs_ip)
if hostid:
hostid = hostid[0][0]
#将主机的指标id查询出来
itemid = Zabbix_Mysql.select_itemid(hostid=hostid,key='system.cpu.util[,idle]')
if itemid:
itemid = itemid[0][0]
cpu_idle = Zabbix_Mysql.select_cpuidle(itemid=itemid,start_clock=start_clock,end_clock=end_clock)
if cpu_idle:
print(ecs_ip+" "+str(round(cpu_idle[0][0],2)))
else:
print("未获取到cpu_idle")
else:
print("未获取到itemid")
else:
print("未获取到hostid")
if __name__ == '__main__':
with open('/tmp/ecs_ip.txt', 'r') as f:
for info in f.read().split("\n"):
ecs_ip = info.split("\t")[0]
if ecs_ip:
Zabbix_Select.select_cpu_idle(ecs_ip=ecs_ip)上面python脚本用到的mysql语句:
#查询主机的id def select_hostid(**kwargs): ecs_ip = kwargs['ecs_ip'] sql = 'select hostid from hosts where name="%s";' % (ecs_ip) cur.execute(sql) res = cur.fetchall() return res #select itemid def select_itemid(**kwargs): hostid = kwargs['hostid'] key = kwargs['key'] sql = 'select itemid from items where key_="%s" and hostid="%s";' %(key,hostid) cur.execute(sql) res = cur.fetchall() return res #查询CPU空闲剩余百分比平均最高值 def select_cpuidle(**kwargs): itemid = kwargs['itemid'] start_clock = kwargs['start_clock'] end_clock = kwargs['end_clock'] sql = 'select value_min from trends where itemid=%s and clock >=%s and clock<=%s order by value_min limit 1;' % (itemid,start_clock,end_clock) cur.execute(sql) res = cur.fetchall() return res
执行下脚本查看下效果:
# python zabbix_manager.py
192.168.1.101 43.78 192.168.1.102 63.97 192.168.1.103 2.67 192.168.1.104 0.12 192.168.1.105 12.8
#其他的监控指标都可以参照这种方式去执行,这里采集的是trends里面的指标,是合并后的趋势指标多少有点不那么精准,但是也可以达到效果了。
#既然已经获得了通过数据库查询数据的方法,那么下一步是不是可以把报警信息获取到存储到比如es中做展示,就可以可以将根据不同的需求取出不同的数据做不同的分析,然后报警或者展示。其他的功能都是一些大相径庭的操作按照自己的需求来吧就不一一列举了,很多都是python脚本编写然后数据聚合后存储到es等其他存储中然后用grafana展示或者做报警的功能,或者提供API供别人数据调取的操作。
#报表那几个功能没事多看看,尤其是动作日志和触发器Top 100可以发现一些配置不合理的地方和问题。
写到这里感觉这个zabbix系统基本也就说的差不多了,如果有人感兴趣有问题可以在评论里面或者留言板沟通。
