大数据(十六)Hbase常用操作
#紧接上文:http://blog.51niux.com/?id=312
一、Hbase常用操作
1.1 hbase命令行介绍
$ /opt/soft/hbase/bin/hbase --help
Usage: hbase [<options>] <command> [<args>] Options: --config DIR 使用的配置目录。默认值:./conf --hosts HOSTS 覆盖“regionserver”文件中的列表 --auth-as-server 作为服务器身份验证使用服务器配置向ZooKeeper进行身份验证 --internal-classpath 内部类路径跳过尝试使用面向客户端的jar --help or -h 打印此帮助消息 Commands: 有些命令接受参数。不传递参数或-h以了解用法。 shell 运行HBase shell hbck 运行HBase 'fsck' 工具。默认为只读hbck1。Pass '-j /path/to/HBCK2.jar' to run hbase-2.x HBCK2. snapshot 用于管理快照的快照工具 jshell 在类路径上运行带有HBase的jshell classpath Dump hbase CLASSPATH mapredcp mapredcp转储mapreduce所需的CLASSPATH条目 pe 运行性能评估 ltt 运行LoadTestTool canary 运行canary工具 version 打印版本 completebulkload Run BulkLoadHFiles tool regionsplitter Run RegionSplitter tool rowcounter Run RowCounter tool cellcounter Run CellCounter tool pre-upgrade Run Pre-Upgrade validator tool hbtop Run HBTop tool CLASSNAME Run the class named CLASSNAME
1.2 hbase表的常用操作
创建表操作
$ /opt/soft/hbase/bin/hbase shell
hbase:002:0> create 'test','cf'
#上面是建立一个叫test的表,表里面有个叫'cf'的列族。HBase的表都是由列族(Column Family)组成的。没有列族的表是没有意义的。列并不是依附于表上,而是依附于列族上。所以HBase的表跟列之间的关系中间还有一层:列族,如下图:
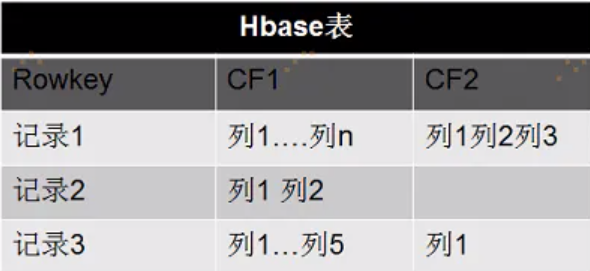
hbase的表的属性都定义在列族上。HBase同一个表的不同列族可以定义完全不同的属性。
hbase:004:0> alter 'test','cf1' Updating all regions with the new schema... 1/1 regions updated. Done. Took 2.1121 seconds
#在生产环境下执行上面命令之前,最好先停用(disable)这个表。因为对列族的所有操作都会同步到所有拥有这个表的RegionServer上,执行命令的时候可以看到总共有多少个RegionServer,当前执行了几个RegionServer。当有很多客户端都在连着的时候,直接新增一个列族对性能的影响较大。
#上面的语句是给test表再增加一个cf1的列族,注意增加列族不能用create
hbase:005:0> list => ["test"]
#上面的语句是查看当前有那些表
查看表
查看表属性:
hbase:006:0> describe 'test'

#上图可以看到分别输出了两个列族的属性
插入数据
在HBase中,如果你的一行有5列,那存储一行的数据得写5行的语句。这是因为HBase中行的每一个列都存储在不同的位置,你必须指定你要存储在哪个单元格;而单元格需要根据表、行、列这几个维度来定位,插入数据的时候你必须告诉HBase你要把数据插入到哪个表的哪个列族的哪个行的哪个列。如下面的命令:
hbase:007:0> put 'test','row1','cf:name','hello' hbase:008:0> put 'test','row1','cf:name','world'
上面命令的意思是,往test表插入一个单元格。这个单元格的rowkey为row1,也就是说它是属于row1这个行中的一个列。该单元格的列族为cf。该单元格的列名为name。数据值为hello,然后我们又插入了一个world,然后我们查看下显示:
hbase:009:0> scan 'test' ROW COLUMN+CELL row1 column=cf:name, timestamp=2022-11-07T19:21:09.500, value=world 1 row(s)
上面显示的内容,ROW列显示的就是rowkey,COLUMN+CELL显示的就是这个记录的具体列族(column里面冒号前面的部分)、列(colum里面冒号后面的部分)、时间戳(timestamp)、值(value)信息。
关于时间戳
上面的结果带来了下一个问题,是不是world把hello覆盖掉了,结果是没有覆盖,只是作为了不同的版本,而默认只显示最新的版本。Hbase中并没有版本的概念,所以时间戳就类似于版本。但是默认Hbase只保留一个版本,所以如果你不对列族做设置的话,还是只保留最新的一条数据。
修改列族属性,让其支持多版本,比如5个版本:
hbase:010:0> alter 'test',{NAME=>'cf',VERSIONS=>5}然后再来插入,特别提示可以制定插入时间戳哈比如(1699356932000)单位是毫秒:
hbase:011:0> put 'test','row1','cf:name','hello' hbase:012:0> put 'test','row1','cf:name','world' hbase:013:0> put 'test','row1','cf:name','nihao',1699356932000
查看单个rowkey数据,默认显示最新的,在表的数据很大的时候,get查询的速度远远高于scan:
hbase:028:0> get 'test','row1',{COLUMN=>'cf:name'}下面让我们来查看多版本
hbase:015:0> get 'test','row1',{COLUMN=>'cf:name',VERSIONS=>5}
COLUMN CELL
cf:name timestamp=2023-11-07T19:35:32, value=nihao
cf:name timestamp=2022-11-07T19:35:06.920, value=world
cf:name timestamp=2022-11-07T19:35:04.290, value=hello
cf:name timestamp=2022-11-07T19:30:51.064, value=world注意get或者scan的输出结果中,HBase总是把列族和列用“列族:列”的组合方式来一起显示,无论是put存储还是scan的查询使用的列定义,都是“列族:列”的格式。比如,cf:name表示列族为cf,列为name。
当然scan也可以查看多个版本的信息,如下面的命令:
hbase:033:0> scan 'test',{VERSIONS=>5}用scan查看
实际环境下很少直接scan 表名称,因为表的数据太大了。如果你就这么输入的话,会从第一条数据开始把所有数据全部显示一遍,那么如何来显示数据的显示呢?下面就是类似于mysql的limit命令:
从row3到最后:
hbase:023:0> scan 'test',{STARTROW=>'row3'}从row3到row4:
hbase:024:0> scan 'test',{STARTROW=>'row3',ENDROW=>'row4'}从开始一直到row2:
hbase:025:0> scan 'test',{ENDROW=>'row2'}结果就不截图了,直接说结论,首先记得起始行(STARTROW)和结束行(ENDROW),它这个是显示>=STARTROW并且<ENDROW中的数据。不写STARTROW就是从第一行开始,不写ENDROW就是从起始行一直查到最后。
博文来自:www.51niux.com
删除数据
先看看我们的数据:
hbase:021:0> scan 'test',{STARTROW=>'row5'}
ROW COLUMN+CELL
row5 column=cf:name, timestamp=2022-11-07T21:27:22.993, value=del1
row5 column=cf1:name, timestamp=2022-11-07T21:27:29.104, value=del2
row5 column=cf3:name, timestamp=2022-11-07T21:30:39.638, value=del3用delete命令删除表中的数据,注意这条命令只是删除了row5行上面的'cf:name',row5行上面其他的数据还在:
hbase:001:0> delete 'test','row5','cf:name'
如果想要删除整行数据请执行下面的命令:
hbase:025:0> deleteall 'test','row5'
如果我们要删除指定版本的数据:
hbase:048:0> get 'test','row5',{COLUMN=>'cf:name',VERSIONS=>5}
hbase:049:0> delete 'test','row5','cf:name',3
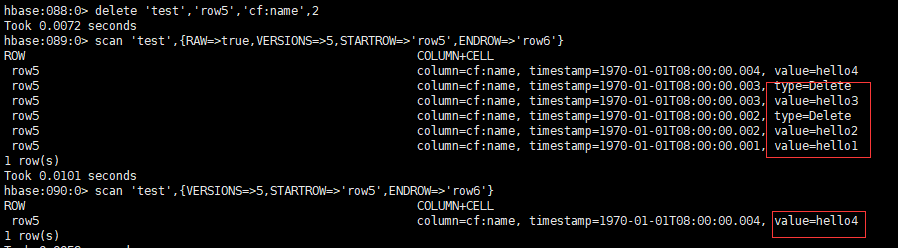
#从上图的时间戳看来时间戳版本为3和以前的数据已经消失掉了。
下面让我们重新put一个时间戳是3的数据:
hbase:053:0> put 'test','row5','cf:name','hello3',3

#但是查询结果会发现我们put的数据并没有出现。为什么会这样呢?我们再用下面一个命令:
hbase:058:0> scan 'test',{RAW=>true,VERSIONS=>5,STARTROW=>'row5',ENDROW=>'row6'}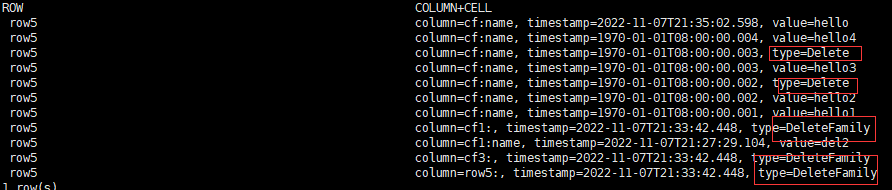
删除的数据都被打上了标签,type=Delete 和type=DeleteFamily类型的记录,在某个时间点,由数据库统一删除处理。
删除表操作
在删除表之前先要停用表(没人使用此表会很快,但是线上环境会很慢,disable要通知所有的RegionServer来下线这个表,并且有很多涉及该表的操作需要被停用掉):
hbase:059:0> disable 'test'
再次查看停用表(会有报错提示):
hbase:061:0> scan 'test' org.apache.hadoop.hbase.TableNotEnabledException: test is disabled
在表停用之后就可以删除表了:
hbase:062:0> drop 'test'
查看帮助
如果想要自助的学习有哪些命令操作,如何学习?先来一个全部的命令输出
hbase:065:0> help
再来一个指定的命令帮助:
hbase:066:0> help 'put'
常用命令介绍
通用:
status:查看集群状态
version:当前hbase版本
whoami:查看当前用户
table_help:表操作的帮助说明
表操作:
list: 支持查看通配符,比如list 'test.*'
alter:更改表或者列族定义。如果你传入一个新的列族名,则意味着创建一个新的列族。比如 alter 'test', {NAME=>'cf1',VERSIONS=>4},{NAME=>'cf2',VERSIONS=>5}命令创建多个列族和设置不同的属性。删除列族:alter 'test','delete'=>'cf2'。
alter_status 'test':查看表的各个Region的更新状况,这条命令在异步更新表的时候,用来查看更改命令执行的情况,判断该命令是否执行完毕。
alter_async:异步更新表。使用这个命令你不需要等待表的全部Region更新完后才返回。记得配合alter_status来检查异步表更改命令的执行进度。
disable_all:通过正则表达式来停用多个表。
is_disabled:检测指定表是否被停用了。
drop_all:通过正则表达式来删除多个表。
enable:启动指定表。
enable_all:通过正则表达式来启动指定表。
is_enabled:判断指定表是否启用。
exists:判断指定表是否存在。
show_filters:列出所有过滤器。
get_table:使用这条命令,你可以把表名转化成一个对象,在下面的脚本中使用这个对象来操作表,达到面向对象的语法风格。格式:变量 = get_table '表名'
locate_region:通过这条命令可以知道你所传入的行键(rowkey)对应的行(row)在哪个Region里面。格式:locate_region '表名', '行键'
数据操作:
scan:按照行键的字典排序来遍历指定表的数据。遍历所有数据所有列族。格式:scan '表名', { COLUMNS => ['列1', '列2', …] },指定行数:格式:scan '表名', { LIMIT => 行数量},指定时间戳:scan '表名', { TIMERANGE => [最小时间戳, 最大时间戳]}
count: 计算表的行数。简单计算。格式:count '表名'
append: 给某个单元格的值拼接上新的值。
truncate: 这个命令跟关系型数据库中同名的命令做的事情是一样的:清空表内数据,但是保留表的属性。不过HBase truncate表的方式其实就是先帮你删掉表,然后帮你重建表。
truncate_preserve:这个命令也是清空表内数据,但是它会保留表所对应的Region。当你希望保留Region的拆分规则时,可以使用它,避免重新定制Region拆分规则。
get_splits:获取表所对应的Region个数。因为一开始只有一个Region,由于Region的逐渐变大,Region被拆分(split)为多个,所以这个命令叫get_splits。
工具方法:
close_region:下线指定的Region。下线Region可以通过指定Region名,也可以指定Region名的hash值。
unassign:下线指定的Region后马上随机找一台服务器上线该Region。
assign:上线指定的Region
move:移动一个Region。你可以传入目标服务器的服务器标识码来将Region移动到目标服务器上。如果你不传入目标服务器的服务器标识码,那么就会将Region随机移动到某一个服务器上,就跟unassign操作的效果一样。
split:拆分(split)指定的Region。除了可以等到Region大小达到阈值后触发自动拆分机制来拆分Region,我们还可以手动拆分指定的Region。
merge_region:合并(merge)两个Region为一个Region。如果传入第二个参数'true',则会触发一次强制合并(merge)。
compact:调用指定表的所有Region或者指定列族的所有Region的合并(compact)机制。通过compact机制可以合并该Region或者该Region的列族下的所有HFile(StoreFile),以此来提高读取性能。compact跟合并(merge)并不一样。merge操作是合并2个Region为1个Region,而compact操作着眼点在更小的单元:StoreFile,一个Region可以含有一个或者多个StoreFile,compact操作的目的在于减少StoreFile的数量以增加读取性能。
compact_rs:调用指定RegionServer上的所有Region的合并机制,加上第二个参数true,意味着执行major compaction。
balancer:手动触发平衡器(balancer)。平衡器会调整Region所属的服务器,让所有服务器尽量负载均衡。如果返回值为true,说明当前集群的状况允许运行平衡器;如果返回false,意味着有些Region还在执行着某些操作,平衡器还不能开始运行。
balance_switch:打开或者关闭平衡器。传入true即为打开,传入false即为关闭。
balancer_enabled:检测当前平衡器是否开启。
catalogjanitor_run:开始运行目录管理器(catalog janitor)。所谓的目录指的就是hbase:meta表中存储的Region信息。当HBase在拆分或者合并的时候,为了确保数据不丢失,都会保留原来的Region,当拆分或者合并过程结束后再等待目录管理器来清理这些旧的Region信息。
catalogjanitor_enabled:查看当前目录管理器的开启状态。
catalogjanitor_switch:启用/停用目录管理器。该命令会返回命令执行后状态的前一个状态。
normalize:规整器用于规整Region的尺寸,通过该命令可以手动启动规整器。
normalizer_enabled:查看规整器的启用/停用状态。
normalizer_switch:启用/停用规整器。该命令会返回规整器的前一个状态。
flush:手动触发指定表/Region的刷写。所谓的刷写就是将memstore内的数据持久化到磁盘上, 称为HFile文件。
trace:启用/关闭trace功能。不带任何参数地执行该命令会返回trace功能的开启/关闭状态。
wal_roll:手动触发WAL的滚动。
zk_dump:打印出ZooKeeper集群中存储的HBase集群信息。
快照:
snapshot:快照(snapshot)就是表在某个时刻的结构和数据。可以使用快照来将某个表恢复到某个时刻的结构和数据。
list_snapshots:列出所有快照。可以传入正则表达式来查询快照列表。
restore_snapshot:使用快照恢复表。由于表的数据会被全部重置,所以在根据快照恢复表之前,必须要先停用该表。
clone_snapshot:使用快照的数据创建出一张新表。创建的过程很快,因为使用的方式不是复制数据,并且修改新表的数据也不会影响旧表的数据。
delete_snapshot:删除快照。
delete_all_snapshot:同时删除多个跟正则表达式匹配的快照。
命名空间:
list_namespace:列出所有命名空间。你还可以通过传入正则表达式来过滤结果。
list_namespace_tables:列出该命名空间下的表。
create_namespace:创建命名空间。你还可以在创建命名空间的同时指定属性。
describe_namespace:显示命名空间定义。
alter_namespace:更改命名空间的属性或者删除该属性。如果METHOD使用set表示设定属性,使用unset表示删除属性。
drop_namespace:删除命名空间。不过在删除之前,请先确保命名空间内没有表,不然会有报错
配置:
update_config:要求指定服务器重新加载配置文件。参数为服务器标识码。
update_all_config:要求所有服务器重新加载配置文件。
标签:
list_labels:列出所有系统标签。
add_labels:添加系统标签。
set_auths:为用户或者组设置标签。
get_auths:获取用户或者组的标签。
clear_auths:删除用户或者组绑定的标签。
set_visibility:批量设置单元格的标签。
集群备份:
add_peer一个备份节点(peer节点)可以是一个HBase集群,也可以是自定义的备份存储。
remove_peer_tableCFs:从指定备份节点的配置中删除指定表或者列族信息,这样该表或者列族将不再参与备份操作。
set_peer_tableCFs:设定指定备份节点的备份表或者列族信息。
show_peer_tableCFs:列出指定备份节点的备份表或者列族信息。
append_peer_tableCFs:为现有的备份节点(peer节点)配置增加新的列族。
disable_peer:终止向指定集群发送备份数据。
disable_table_replication:取消指定表的备份操作。
enable_table_replicationdiable_table_replication:操作之后,重新启用指定表的备份操作。
list_peers:列出所有备份节点。
list_replicated_tables:列出所有参加备份操作的表或者列族。
remove_peer:停止指定备份节点,并删除所有该节点关联的备份元数据。
安全:
list_security_capabilities:列出所有支持的安全特性。
user_permission:列出指定用户的权限,或者指定用户针对指定表的权限。如果要表示整个命名空间,而不特指某张表,请用@命名空间名。
grant:赋予用户权限。
revoke:取消用户的权限。如果要表示整个命名空间,而不特指某张表,请用@命名空间名。
博文来自:www.51niux.com
二、hbase备份恢复表
2.1 CopyTable
先来段官网翻译:
CopyTable是一个实用程序,可以将表的部分或全部复制到同一个集群或另一个集群。目标表必须首先存在。用法如下:
$ hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help
Usage: CopyTable [general options] [--starttime=X] [--endtime=Y] [--new.name=NEW] [--peer.adr=ADR] <tablename | snapshotName> Options: rs.class: hbase.regionserver.class对等群集的类指定是否与当前群集不同 rs.impl: hbase.regionserver.impl of the peer cluster startrow: 起始行 stoprow:结束行 starttime:时间范围的开始时间(单位:毫秒),没有endtime意味着从开始到最后 endtime:时间范围的结束时间结束。如果未指定开始时间,则忽略。 versions:要复制的单元版本数 new.name:新表的名称 peer.adr:对等集群的地址,格式为hbase.zookeeper.quorum:hbase.zookeeper.client.port:zookeeper.znode.parent families:要复制的列族用逗号隔开,要从cf1复制到cf2,请提供sourceCfName:destCfName。要保持相同的名称,只需输入“cfName” all.cells:全部的单元格还复制删除标记和删除的单元格 bulkload: 将输入写入HFiles并批量加载到目标表 snapshot:将数据从快照复制到目标表。 Examples: 要将“TestTable”复制到使用复制1小时窗口的群集,请执行以下操作: $ hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1265875194289 --endtime=1265878794289 --peer.adr=server1,server2,server3:2181:/hbase --families=myOldCf:myNewCf,cf2,cf3 TestTable 要将数据从“sourceTableSnapshot”复制到“destTable”: $ hbase org.apache.hadoop.hbase.mapreduce.CopyTable --snapshot --new.name=destTable sourceTableSnapshot 要将数据从“sourceTableSnapshot”复制并批量加载到“destTable”,请执行以下操作: $ hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=destTable --snapshot --bulkload sourceTableSnapshot 对于性能,考虑以下一般选项: 建议将以下值设置为>=100。较高的值会占用更多内存,减少到服务器的往返时间,并且可以提高性能:-Dhbase.client.scanner.caching=100 以下内容应始终设置为false,以防止两次写入数据结果不准确:-Dmapreduce.map.speculative=false
下面让我们实操一下:
$ hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=test02 test #下面报错了,提醒很明显就是不存在test02这个表,那就是要提前创建一下,注意不加--peer.adr=ZK地址:2181:/hbase就是本机向本机复制,加上了就是向远端复制
Exception in thread "main" org.apache.hadoop.hbase.TableNotFoundException: Can't write, table does not exist:test02 at org.apache.hadoop.hbase.mapreduce.TableOutputFormat.checkOutputSpecs(TableOutputFormat.java:172) at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:279)
下面我们创建下表再执行一下:
hbase:003:0> create 'test02','cf'
$ hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=test02 test #然后再次报错,这个错误就很恶心了,尝试解决了很久没有解决,看是hbase2.5增加的新特性基于OpenTelemetry的跟踪检修,怀疑跟版本不兼容有关系,所以把hbase回退到2.4问题解决,下面是报错信息:
Error: java.lang.NoClassDefFoundError: io/opentelemetry/context/ImplicitContextKeyed at java.lang.ClassLoader.defineClass1(Native Method) ...... Caused by: java.lang.ClassNotFoundException: io.opentelemetry.context.ImplicitContextKeyed
好了,我们把hbase版本回退到2.4.14再来执行,总算好了:
#hbase表的test02已经有test表完整的数据了,这里就不结果展示了。
CopyTable就是以表级别进行迁移,其本质也是使用MapReduce的方式进行数据的同步,它是利用MapReduce去scan源表数据,然后把scan出来的数据写到目标集群,从而实现数据的迁移和备份。这种方式需要通过scan数据,对于很大的表,如果这个表本身又读写比较频繁的情况下,会对性能造成比较大的影响,并且效率比较低。
那么我们来判断一下这个复制是完全复制还是增量复制:
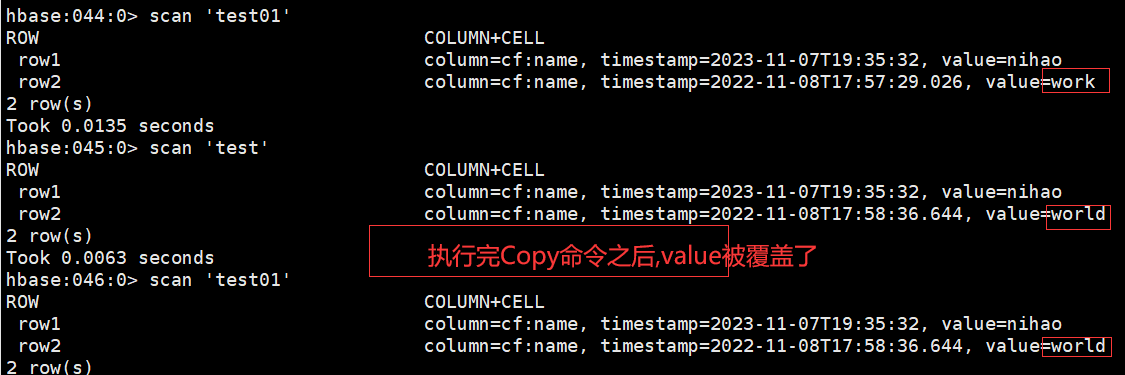
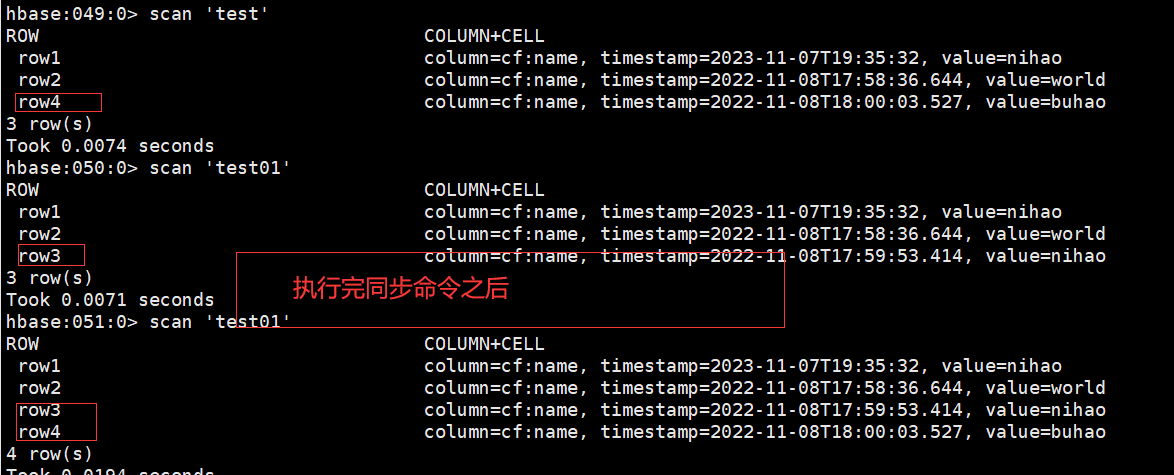
#上面两个命令我们基本已经可以断定,就是如果同一个row会覆盖,目标表没有row就是增量,所以如果要想一模一样,目标表要是一个空表
如果列族不一致呢?
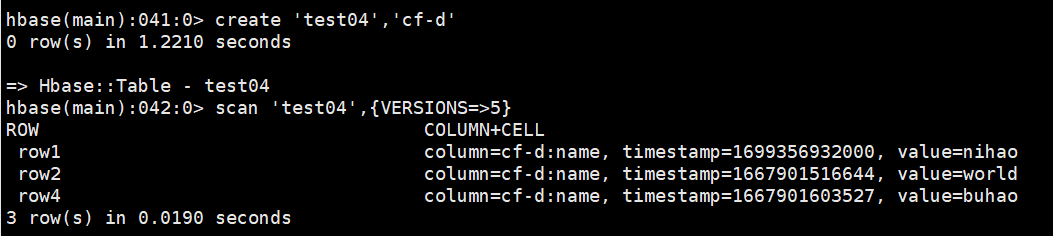
hbase:054:0> create 'test04','cf-d'
$ hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=test04 test #得又报错了
Error: org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException: Failed 3 actions: org.apache.hadoop.hbase.regionserver.NoSuchColumnFamilyException: Column family cf does not exist in region test04
$ hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=test04 --families=cf:cf-d test #就要加families参数
2.2 HDFS拷贝的方式
首先了解下hbase在hdfs上面的目录结构:
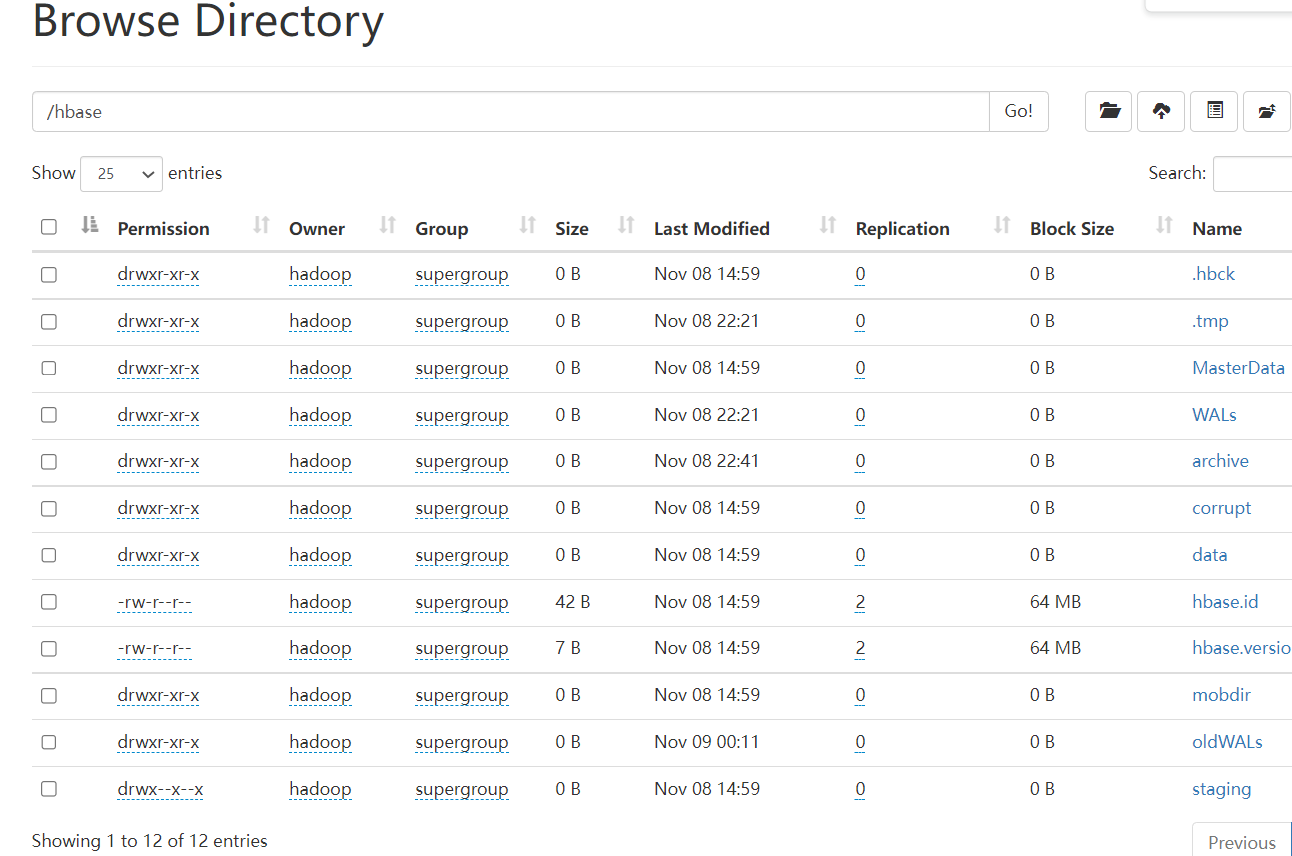
.hbck #当遇到元数据不一致时,使用hbck工具修复,修复过程中会使用该目录作为临时目录。 .tmp #当创建或删除表时,会将表移动到该此目录下,然后再处理。 MasterData #master节点的记录的数据信息 WALs #存储集群中所有RegionServer的HLog日志文件 archive #存储表的归档和快照,HBase在做Split或者compact操作完成之后,会将之前的HFile移到archive目录中,该目录由HMaster上的一个定时任务定期去清理。 corrupt #存储损坏的HLog文件或者HFile文件 data #最重要的目录,存储hbase数据,下面含有两个命名空间default和hbase,其中default是默认命名空间,如果创建的表未指定命名空间,将存放在该命名空间下,hbase是系统命名空间。 hbase.id #它是一个文件,存储集群唯一的cluster id号,是一个uuid。 hbase.version #一个文件,存储集群的版本号 mobdir #MOB文件目录 oldWALs #与hbase操作相关的旧日志存放目录.当/hbase/WALs中的HLog文件被持久化到存储文件中,不再需要日志文件时,它们会被移动到/hbase/oldWALs目录。 staging #在bulkload时会创建并使用这个文件夹
#有上面的目录介绍我们知道了我们的表都在/hbase/data/default下面
distcp方法
distcp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具。 它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生。注意distcp使用绝对路径进行操作并且都是本段的active master到对端的active master节点。这种方式的缺点就是源Hbase的表需要停写,不然会导致数据不一致,比较适合迁移历史表(数据不会被修改的情况).
下面是最简单的命令,拷贝源端的hdfs目录到目标集群的hdfs目录:
$ /opt/soft/hadoop/bin/hadoop distcp -overwrite hdfs://hadoop-master02:8020/hbase/data/default/test/ hdfs://smaster-hadoop01:8020/hbase/data/default/test/
在对端看一下,可以看到目录已经拷贝过来了:
# /opt/soft/hadoop/bin/hdfs dfs -ls /hbase/data/default/|grep "/test" drwxr-xr-x - hadoop supergroup 0 2022-11-09 01:06 /hbase/data/default/test
但是执行hbase查看缺空空如也:
hbase(main):001:0> list 'test.*' => []
之所以这样是因为还缺少元数据,在目标master节点执行下面的命令,修复HBase表元数据($ hbase hbck -repair 表名称):
$ hbase hbck -repair test
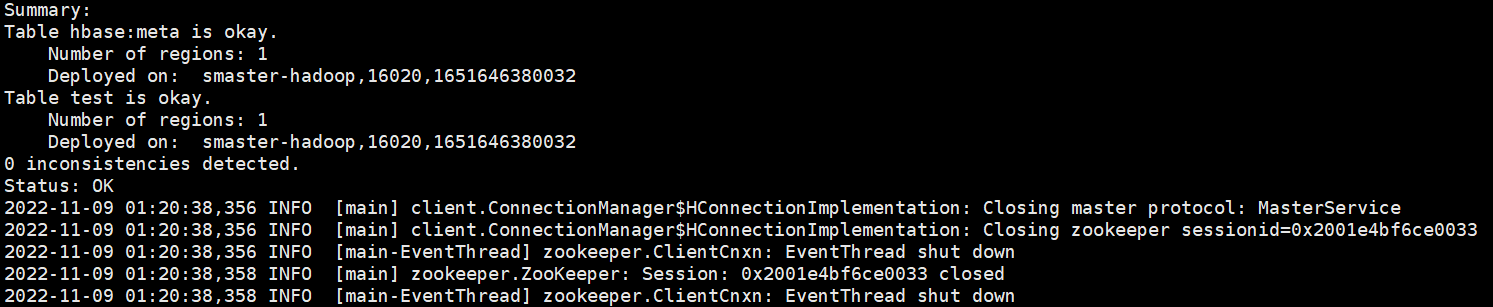
下面再次查看hbase,会发现数据有了:
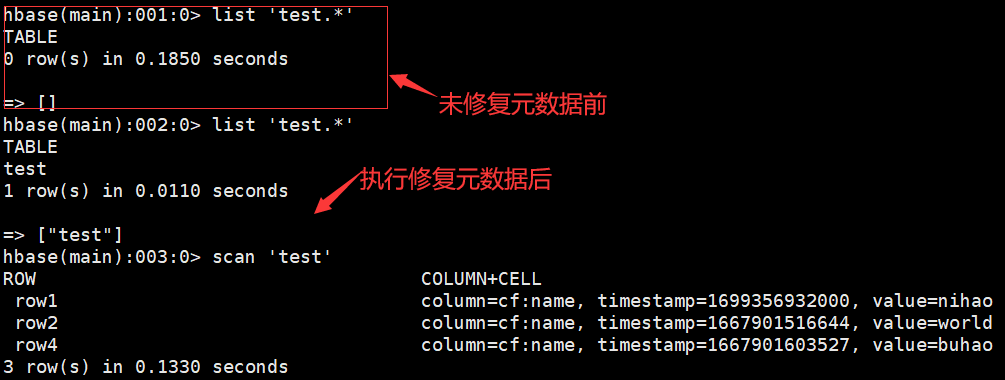
distcp的详细用法请看命令帮助:$ /opt/soft/hadoop/bin/hadoop distcp --help或者参照网上其他的文章。
博文来自:www.51niux.com
fs get/put的方法
同理,我们是否可以直接使用hdfs的方式把表数据目录拷贝到本地进行全备呢?
$ /opt/soft/hadoop/bin/hadoop fs -get /hbase/data/default/test /tmp/
$ ls -l /tmp/test/
drwxr-xr-x 5 hadoop hadoop 4096 11月 9 15:20 53675bf8818997468f6a245929e57f8c
#先把我们把目录同步到另一个hbase集群然后重新提交上去试一试意这个表明要跟拷贝过来的表名一致哦
$ hadoop fs -put /tmp/test/ hdfs://mycluster:8020/hbase/data/default/test
$ hbase hbck -fixMeta #修复.META.表
$ hbase hbck -fixAssignments #重新分配数据到各RegionServer
2.3 Export/Import
官网文档:https://hbase.apache.org/book.html#export
通过Export导出数据到目标集群的hdfs,再在目标集群执行import导入数据,Export支持指定开始时间和结束时间,因此可以做增量备份。Export导出工具与CopyTable一样是依赖hbase的scan读取数据,并且采用的InportFormat与CopyTable一样是TableInputFormat类,从该类的getSplits()方法可以看出MR的map数与hbase表的region数相同。
格式是:
$ hbase org.apache.hadoop.hbase.coprocessor.Export <tablename> <outputdir> [<versions> [<starttime> [<endtime>]]]
$ /opt/soft/hbase/bin/hbase org.apache.hadoop.hbase.mapreduce.Export test01 /tmp/test01 #我们先把test01表拷贝到hdfs的一个目录中,前提是这个目录不能存在哦
$ /opt/soft/hadoop/bin/hadoop dfs -get /tmp/test01 /tmp/ #把目录下载到本地
$ /opt/soft/hadoop/bin/hadoop dfs -rmr /tmp/test01 #现在可以把hdfs上面的临时test01的目录删除掉了
$ ls -l /tmp/test01/
总用量 4 -rw-r--r-- 1 hadoop hadoop 324 11月 9 23:55 part-m-00000 -rw-r--r-- 1 hadoop hadoop 0 11月 9 23:55 _SUCCESS
现在我们把这个test01拷贝到另一个hbase集群然后上传上去看看什么效果,格式是:
hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
$ hbase org.apache.hadoop.hbase.mapreduce.Import test01 /tmp/test01 #如下面直接报错,因为这种方式要提前把表创建好,需要scan数据,会对HBase造成负载的影响,效率不高。
Exception in thread "main" org.apache.hadoop.hbase.TableNotFoundException: Can't write, table does not exist:test01
#把表创建好再执行import就OK了,就不截图了。
2.4 replication方式
官网介绍:https://hbase.apache.org/book.html#_cluster_replication
如何像mysql一样实现读写分离呢?让实时查询的查询主Hbase,让那种大表扫描各种全变scan的操作去从库查询呢,上面我们备份的方式都偏离线了,如何像mysql一样主从复制呢?就用到了现在的replication的方式。HBase目前共支持3种Replication,分别是异步Replication、串行Replication和同步Replication。其中串行Replication是2.1以后引入的,我们这里就用这种方式。
串行Replication指的是:对于某个Region来说,严格按照主集群的写入顺序复制到备集群,其是一种特殊的Replication。同时默认的异步Replication不是串行的。
首先配置主从hbase
配置主hbase然后同步配置文件重启hbase服务
$ vim /opt/soft/hbase/conf/hbase-site.xml
<property> <name>hbase.replication</name> <value>true</value> </property> <property> <name>replication.source.nb.capacity</name> <value>25000</value> <description>主集群每次向从集群发送的entry最大的个数,默认值25000,可根据集群规模做出适当调整</description> </property> <property> <name>replication.source.size.capacity</name> <value>67108864</value> <description>主集群每次向从集群发送的entry的包的最大值大小,默认为64M</description> </property> <property> <name>replication.source.ratio</name> <value>1</value> <description>主集群使用的从集群的RS的数据百分比,默认为0.1,需调整为1,充分利用从集群的RS</description> </property> <property> <name>replication.sleep.before.failover</name> <value>2000</value> <description>主集群在RS宕机多长时间后进行failover,默认为2秒,具体的sleep时间是: sleepBeforeFailover + (long) (new Random().nextFloat() * sleepBeforeFailover) </description> </property> <property> <name>replication.executor.workers</name> <value>1</value> <description>从事replication的线程数,默认为1,如果写入量大,可以适当调大</description> </property>
配置从hbase然后同步配置文件重启hbase服务
$ vim /opt/soft/hbase/conf/hbase-site.xml
<property> <name>hbase.replication</name> <value>true</value> </property>
其次主Hbase针对表进行设置
先创建一个串行的复制链路:
格式如下:add_peer ‘ID’ ‘CLUSTER_KEY’,这个ID可以是任意数字,CLUSTER_KEY为从集群的zookeeper下的一个Znode
hbase:002:0> add_peer '1', CLUSTER_KEY => "master-hadoop:2181:/hbase", SERIAL => true
然后进行指定表同步操作:
#在从集群中创建一个与master集群相同的表
表开启同步(默认是关闭的):
hbase:014:0> alter 'test01',{NAME =>'cf', REPLICATION_SCOPE=>'1'}博文来自:www.51niux.com
2.5 借助shell命令导出数据
#比如我想常态记录下我当前Hbase里面的一些表信息:
记录表列表:
$ echo "list"|hbase shell>/tmp/table_list
记录表结构信息:
$ for num in `cat /tmp/table_list |grep "\["|grep -o "\[.*\]"`;do table_name=`echo $num|grep -o "[a-z].*[a-z0-9]"`&& echo "describe '${table_name}'"|hbase shell;done>/tmp/table_info那记录每个表的信息就是(每个表肯定是一个文件的形式):
$ for num in `cat /tmp/table_list |grep "\["|grep -o "\[.*\]"`;do table_name=`echo $num|grep -o "[a-z].*[a-z0-9]"`&& echo "scan '${table_name}'"|hbase shell>/tmp/hbase_data/$table_name;done2.6 DATAX
我们很多使用迁移Hbase的时候就是使用datax的方式,当然datax的功能更加强大,DataX是阿里云DataWorks数据集成的开源版本。
github地址:https://github.com/alibaba/DataX
安装datax:
$ wget https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz
$ tar xf datax.tar.gz
$ cd datax/
使用datax:
你首先要支持datax现在支持哪个软件版本,并且如何编写读写的语句:

#如上图点开之后就能看到使用说明信息了

#我们以test04这个表为例:读取后数据(4列)| rowKey | column:qualifier| timestamp | value |
说明中有个限制:目前不支持动态列的读取。考虑网络传输流量(支持动态列,需要先将hbase所有列的数据读取出来,再按规则进行过滤),现支持的两种读取模式中需要用户明确指定要读取的列。--这句话也就是说列是写死的,有多个列我们就要写多个。
有两种模式:
normal 模式:把HBase中的表,当成普通二维表(横表)进行读取,读取最新版本数据。
multiVersionFixedColumn模式:把HBase中的表,当成竖表进行读取。读出的每条记录一定是四列形式,依次为:rowKey,family:qualifier,timestamp,value。读取时需要明确指定要读取的列,把每一个 cell 中的值,作为一条记录(record),若有多个版本就有多条记录(record)。
我们直接用multiVersionFixedColumn模式试一下:
读取hbase到本地文件:
$ vim job/test1.json
{
"job": {
"setting": {
"speed": {
//指定用几个子线程去跑这个任务,线程越多,速度越快
"channel": 1
}
},
//内容
"content": [
{
//读数据部分
"reader": {
//指明什么类型的reader
"name": "hbase11xreader",
//参数
"parameter": {
//连接HBase集群需要的配置信息,JSON格式
"hbaseConfig": {
"hbase.zookeeper.quorum": "hadoop-master01:2181"
},
//要读取的 hbase 表名(大小写敏感)
"table": "test04",
//编码方式,UTF-8 或是 GBK,用于对二进制存储的 HBase byte[] 转为 String 时的编码
"encoding": "utf-8",
//读取hbase的模式,支持normal 模式、multiVersionFixedColumn模式,即:normal/multiVersionFixedColumn
"mode": "multiVersionFixedColumn",
//指定在多版本模式下的hbasereader读取的版本数,取值只能为-1或者大于1的数字,-1表示读取所有版本
"maxVersion": "-1",
//描述:要读取的hbase字段,normal 模式与multiVersionFixedColumn 模式下必填项。
"column": [
{
"name": "rowkey",
"type": "string"
},
{
"name": "cf-d: name",
"type": "string"
},
{
"name": "cf: name",
"type": "string",
}
],
//指定hbasereader读取的rowkey范围,startRowkey:指定开始rowkey;endRowkey指定结束rowkey;
"range": {
"startRowkey": "",
"endRowkey": ""
}
}
},
"writer": {
"name": "txtfilewriter",
"parameter": {
"path": "/tmp/datax_test/",
"fileName": "test04",
"writeMode": "truncate"
}
}
}
]
}
}$python bin/datax.py job/test1.json

$ cat /tmp/datax_test/test04__db5f2508_dcb3_491a_b056_1ec167c24e69 #我们看看生成的文件,注意每次执行都会清空目标目录
row1,cf-d:name,1699356932000,nihao row2,cf-d:name,1667901516644,world row4,cf:name,3,hello3 row4,cf-d:name,1667901603527,buhao row4,cf-d:name,3,datax3 row4,cf-d:name,2,datax2 row4,cf-d:name,1,datax1
再来个读取本地文件到远端Hbase的例子:
$ cat /tmp/datax_test/test04.txt #这是测试样例文本,注意啊 只有一种列族,多了的话会出现多个列族用同一个值的情况
row1,cf-d:name,1699356932000,nihao row2,cf-d:name,1667901516644,world row4,cf-d:name,1667901603527,buhao row4,cf-d:name,3,datax3 row4,cf-d:name,2,datax2 row4,cf-d:name,1,datax1
$ vim job/test2.json
{
"setting": {},
"job": {
"setting": {
"speed": {
"channel": 2
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
//本地文件系统的路径信息,注意这里可以支持填写多个路径。TxtFileReader目前只支持*作为文件通配符
"path": ["/tmp/datax_test/test04.txt"],
//读取文件的编码配置。默认值:utf-8
"encoding": "UTF-8",
//读取字段列表,type指定源数据的类型,index指定当前列来自于文本第几列(以0开始),value指定当前类型为常量,不从源头文件读取数据,而是根据value值自动生成对应的列。
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
//Long是指本地文件文本中使用整形的字符串表示形式,例如"19901219"。
//Double是指本地文件文本中使用Double的字符串表示形式,例如"3.1415"。
//Boolean是指本地文件文本中使用Boolean的字符串表示形式,例如"true"、"false"。不区分大小写。
//Date是指本地文件文本中使用Date的字符串表示形式,例如"2014-12-31",Date可以指定format格式。
"type": "long"
},
{
"index": 3,
"type": "string"
}
],
//读取的字段分隔符
"fieldDelimiter": ","
}
},
"writer": {
"name": "hbase11xwriter",
"parameter": {
//连接HBase集群需要的配置信息,JSON格式
"hbaseConfig": {
"hbase.zookeeper.quorum": "master-hadoop:2181,smaster-hadoop:2181,slave01-hadoop:2181"
},
//要写的 hbase 表名(大小写敏感)
"table": "test04",
//写hbase的模式,目前只支持normal 模式
"mode": "normal",
//要写入的hbase的rowkey列。index:指定该列对应reader端column的索引,从0开始,若为常量index为-1;
//type:指定写入数据类型,用于转换HBase byte[];value:配置常量,常作为多个字段的拼接符。
"rowkeyColumn": [
{
"index":0,
"type":"string"
}
],
//要写入的hbase字段。index:指定该列对应reader端column的索引,从0开始;
//name:指定hbase表中的列,必须为列族:列名 的格式;type:指定写入数据类型,用于转换HBase byte[]。
"column": [
{
"index":3,
"name": "cf-d:name",
"type": "string"
}
],
//指定写入hbase的时间戳。支持:当前时间、指定时间列,指定时间,三者选一。若不配置表示用当前时间。
//index:指定对应reader端column的索引,从0开始,需保证能转换为long,若是Date类型,会尝试用yyyy-MM-dd HH:mm:ss
//和yyyy-MM-dd HH:mm:ss SSS去解析;若为指定时间index为-1;value:指定时间的值,long值。
"versionColumn":{
"index": -1,
"value":"123456789"
},
//编码方式,UTF-8 或是 GBK,用于 String 转 HBase byte[]时的编码
"encoding": "utf-8"
}
}
}
]
}
}#注意目标端要先创建好表哦,不然写入失败,并且写入的列族也要存在哦
$ python bin/datax.py job/test2.json #结果就不截图了,跟上面执行成功的图形一致。
#我们在目标端看下同步的结果:
#从上图可以看到虽然我们row4有多个版本,因为写入的时候只支持normal模式,所以写入的也是就一条最新的版本的值。
Hbase同步到Hbase
#上面了解了datax的大致用法,我们直接来个hbase直接拷贝数据至另一个Hbase集群
先看下目标端的情况:

再看下源端的情况:

在源端执行job:
$ vim job/test_hbase.json
{
"job": {
"setting": {
"speed": {
"channel": 5
}
},
"content": [
{
"reader": {
"name": "hbase11xreader",
"parameter": {
"hbaseConfig": {
"hbase.zookeeper.quorum": "hadoop-master01:2181"
},
"table": "test04",
"encoding": "utf-8",
"mode": "normal",
"column": [
{
"name": "rowkey",
"type": "string"
},
{
"name": "cf-d:name",
"type": "string"
}
],
"range": {
"startRowkey": "",
"endRowkey": ""
}
}
},
"writer": {
"name": "hbase11xwriter",
"parameter": {
"hbaseConfig": {
"hbase.zookeeper.quorum": "master-hadoop:2181"
},
"table": "test04",
"mode": "normal",
"rowkeyColumn": [
{
"index":0,
"type":"string"
}
],
"column": [
{
"index":1,
"name": "cf-d:name",
"type": "string"
}
],
"encoding": "utf-8"
}
}
}
]
}
}$ python bin/datax.py job/test_hbase.json #执行下任务
然后再看看目标端(可以拿到并非全量覆盖,只会同步cf-d:name):
hbase(main):024:0> scan 'test04' ROW COLUMN+CELL row1 column=cf-d:name, timestamp=1668156686626, value=nihao row2 column=cf-d:name, timestamp=1668156686626, value=world row4 column=cf:name, timestamp=1668156303932, value=hello3 row4 column=cf-d:name, timestamp=1668156686626, value=buhao
#再说一个小例子,从上面的例子可以看到name也就是"列族:列名"是固定值,现在如何批量的跑一遍数据呢?
#从上面的例子我们也可以看出主要也就是column下面的name要变化一下,比如我们把这里做一个模板,只需要批量的替换这里就行了,比如我们把所有的"列族:列"去重搞出来放到一个文件,如/tmp/2.txt,然后这就是一个循环嘛,然后再循环的替换模板里面的那个变量然后产生新的job.json文件,然后再执行这个文件就行了。
$ for num in `cat /tmp/2.txt`;do cp job/moban.json test_job/${num}.json && sed -i "s/CF-D/${num}/g" test_job/${num}.json && bin/datax.py test_job/${num}.json;done >/dev/null
#大概就是上面这么一个意思,这也是一个实际的小例子,当然前提也是对方Hbase已经创建好对应的表,列族。
关于Hbase的备份和恢复就先写到这里把,网上也有很多其他的例子,条条大路通罗马,目的实现便可。
