大数据(八)学习部署Hbase
Hbase官网:http://hbase.apache.org/
一、Hbase介绍
1.1 Hbase简介
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase 是Google Bigtable 的开源实现,与Google Bigtable 利用GFS作为其文件存储系统类似(Hbase依托于Hadoop的HDFS作为最基本存储基础单元,通过使用hadoop的DFS工具就可以看到这些这些数据存储文件夹的结构,还可以通过Map/Reduce的框架(算法)对HBase进行操作), HBase 利用Hadoop HDFS 作为其文件存储系统;Google 运行MapReduce 来处理Bigtable中的海量数据, HBase 同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable 利用Chubby作为协同服务, HBase 利用Zookeeper作为对应。
HBase是一种构建在HDFS之上的分布式、面向列的存储系统。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。HBase不同于关系型数据库(RDBMS全称为 Relational Database Management System),从另一个角度处理伸缩性问题。它通过线性方式从下到上增加节点来进行扩展。HBase不是关系型数据库,也不支持SQL,但是它有自己的特长,这是RDBMS不能处理的,HBase巧妙地将大而稀疏的表放在商用的服务器集群上。
1.2 Hbase特性
线性和模块化的可扩展性。
严格一致的读取和写入。
自动和可配置的表分片
RegionServers之间的自动故障转移支持。
方便的基类,用于使用Apache HBase表来支持Hadoop MapReduce作业。
易于使用Java API进行客户端访问。
阻止高速缓存和Bloom Filters进行实时查询。
通过服务器端过滤器查询谓词下推
Thrift网关和支持XML,Protobuf和二进制数据编码选项的REST-ful Web服务
可扩展的jruby-based(JIRB)外壳
支持通过Hadoop指标子系统将度量输出到文件或Ganglia; 或通过JMX
1.3 HBase 与传统关系数据库的区别
ACID 是指数据库事务正确执行的四个基本要素的缩写,其包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)以及持久性(Durability)。对于一个支持事务(Transaction)的数据库系统,必需要具有这四种特性,否则在事务过程(Transaction Processing)当中无法保证数据的正确性,交易过程极可能达不到交易方的要求。下面,我们就简单的介绍下这 4 个特性的含义。
原子性(Atomicity) #是指一个事务要么全部执行,要么全部不执行。换句话说,一个事务不可能只执行了一半就停止了。比如一个事情分为两步完成才可以完成,那么这两步必须同时完成,要么一步也不执行,绝不会停留在某一个中间状态。如果事物执行过程中,发生错误,系统会将事物的状态回滚到最开始的状态。 一致性(Consistency) #是指事务的运行并不改变数据库中数据的一致性。也就是说,无论并发事务有多少个,但是必须保证数据从一个一致性的状态转换到另一个一致性的状态。例如有 a、b 两个账户,分别都是 10。当 a 增加 5 时,b 也会随着改变,总值 20 是不会改变的。 隔离性(Isolation) #是指两个以上的事务不会出现交错执行的状态。因为这样可能会导致数据不一致。如果有多个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。 持久性(Durability) #指事务执行成功以后,该事务对数据库所作的更改便是持久的保存在数据库之中,不会无缘无故的回滚。
HBase 与 RDBMS 的区别:
容错性:HBase由软件架构实现,由于由多个节点组成所以不担心某节点宕机情况。RDBMS一般需要额外硬件设备实现HA机制。 数据库大小:HBase是PB级别的。RDBMS是GB和TB级别的。 数据排布方式:稀疏的、分布的多维的Map.RDBMS是以行和列组织。 数据类型:HBase是Bytes(hbase的存储的数据都是字符串,所有的类型都有用户自己处理,它只保存字符串)。RDBMS是以行和列组织(有丰富的数据类型和存储 方式)。 事务支持:HBase只支持单个Row级别。RDBMS是全面的ACID支持,对Row和表。 查询语言:只支持Java API(除非与其他框架一起使用,如Hive,Phoenix). RDBMS是SQL。 索引:HBase只支持Row-key,除非与其他技术一起应用(如Hive,Phoenix)。RDBMS原生支持索引。 吞吐量:HBase是百万查询/每秒。RDBMS是数千查询/每秒。 数据操作:HBase只有简单的插入,查询,删除,清空等操作。表与表之间都是分离的,没有那么多的表关系。RDBMS有复杂的表关系。 存储的模式:HBase是基于列存储,每一个列族都是有好几个文件存储,不同列族的文件是分离的。RDBMS是基于表结构和行模式存储。 数据的维护:HBase对数据的修改,实际上是插入了一条新的数据,而修改前的数据任旧保存在就版本中.EDBMS是在原数据的基本上直接进行修改.
1.4 HBase架构组成
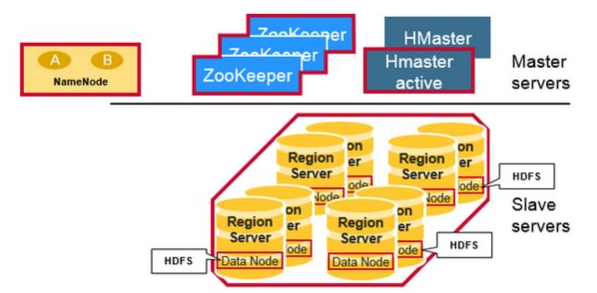
HBase采用Master/Slave架构搭建集群,由HMaster节点、HRegionServer节点、ZooKeeper集群组成,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NN、DN等,总体结构如下:
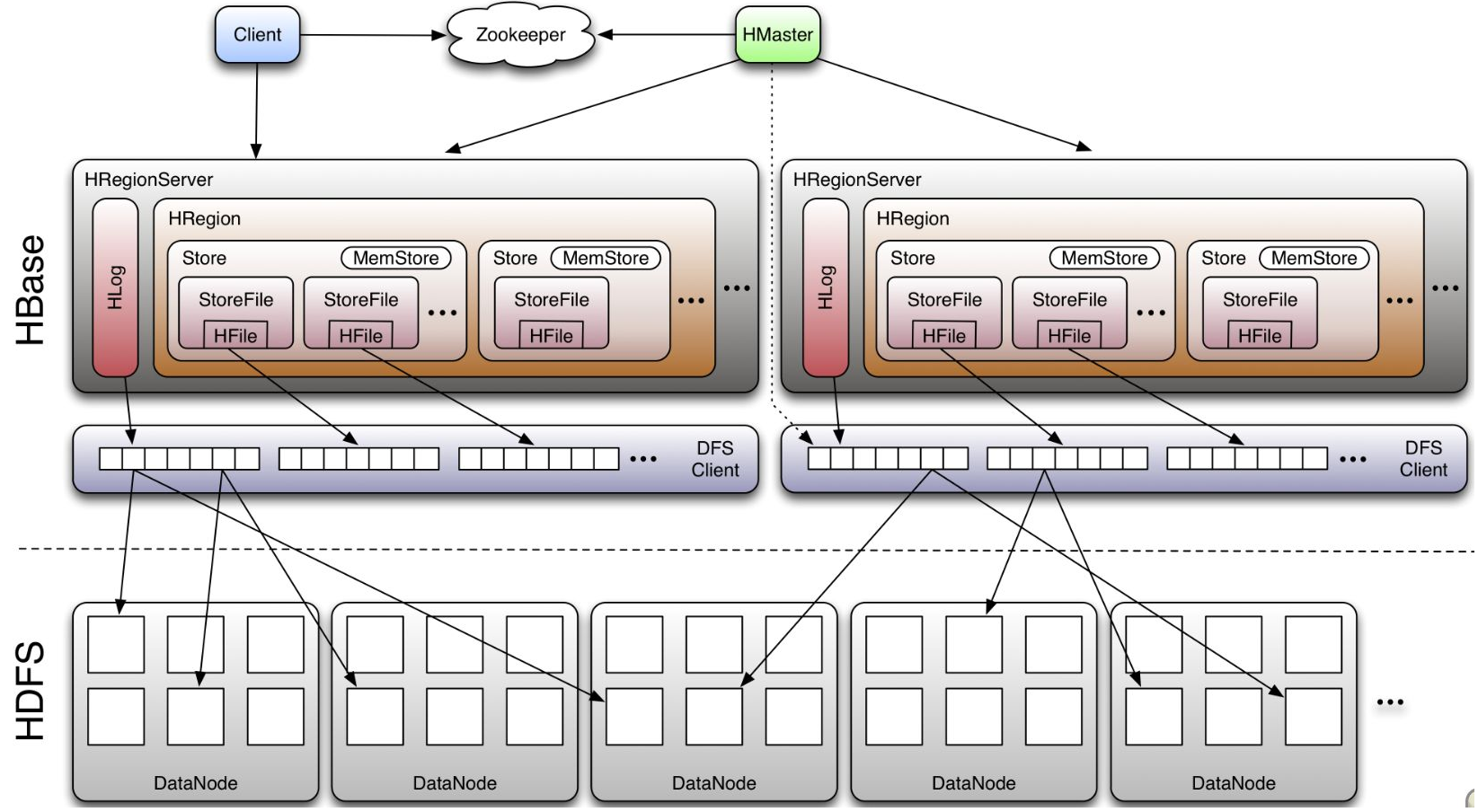
Client的主要功能:
使用HBase的RPC机制与HMaster和HRegionServer进行通信 对于管理类操作,Client与HMaster进行RPC 对于数据读写类操作,Client与HRegionServer进行RPC
Zookeeper功能:
通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册 实时监控Region server的上线和下线信息,并实时通知给Master 存贮所有Region的寻址入口和HBase的schema和table元数据 Zookeeper的引入实现HMaster主从节点的failover
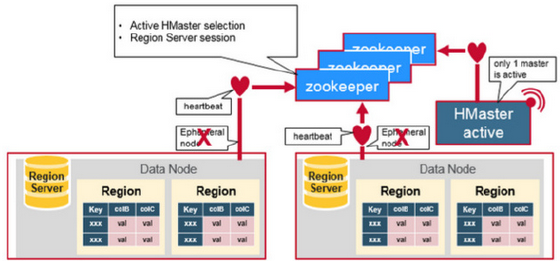
#在HMaster和HRegionServer连接到ZooKeeper后创建Ephemeral节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节点失效,则HMaster会收到通知,并做相应的处理 #HMaster通过监听ZooKeeper中的Ephemeral节点(默认:/hbase/rs/*)来监控HRegionServer的加入和宕机 #在第一个HMaster连接到ZooKeeper时会创建Ephemeral节点(默认:/hbasae/master)来表示Active的HMaster,其后加进来的HMaster则监听该Ephemeral节点, #如果当前Active的HMaster宕机,则该节点消失,因而其他HMaster得到通知,而将自身转换成Active的HMaster,在变为Active的HMaster之前,它会创建在/hbase/back-masters/下创建自己的Ephemeral节点
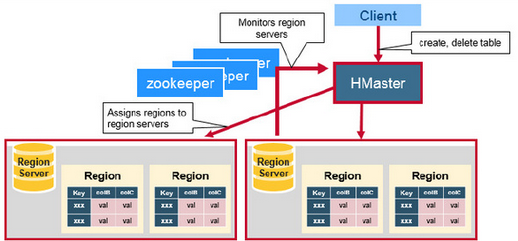
HMaster功能:
管理HRegionServer,实现其负载均衡 管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上 实现DDL操作(Data Definition Language,namespace和table的增删改,column familiy的增删改等)。 管理namespace和table的元数据(实际存储在HDFS上)。 权限控制(ACL)。 监控集群中所有HRegionServer的状态(通过Heartbeat和监听ZooKeeper中的状态) 处理schema更新请求 (创建、删除、修改Table的定义), 如下图:
HRegionServer功能:
存放和管理本地HRegion。 读写HDFS,管理Table中的数据。 Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)。 Region server维护Master分配给它的region,处理对这些region的IO请求 Region server负责切分在运行过程中变得过大的region
RegionServer一般和Datanode在同一台机器上运行,实现数据的本地性,HRegionServer包含多个HRegion,由WAL(HLog)、BlockCache、MemStore、HFile组成:
WAL(Write Ahead Log):它是HDFS上的一个文件,所有写操作都会先保证将数据写入这个Log文件后,才会真正更新MemStore,最后写入HFile中。采用这种模式,可以保证HRegionServer宕机后,依然可以从该Log文件中读取数据,Replay所有的操作,来保证数据的一致性。一个HRegionServer只有一个WAL实例,即一个HRegionServer的所有WAL写都是串行,这当然会引起性能问题,在HBase 1.0之后,通过HBASE-5699实现了多个WAL并行写(MultiWAL),该实现采用HDFS的多个管道写,以单个HRegion为单位。Log文件会定期Roll出新的文件而删除旧的文件(那些已持久化到HFile中的Log可以删除)。WAL文件存储在/hbase/WALs/${HRegionServer_Name}的目录中。
BlockCache:是一个读缓存,将数据预读取到内存中,以提升读的性能 。HBase中提供两种BlockCache的实现:默认on-heap LruBlockCache和BucketCache(通常是off-heap)。通常BucketCache的性能要差于LruBlockCache,然而由于GC的影响,LruBlockCache的延迟会变的不稳定,而BucketCache由于是自己管理BlockCache,而不需要GC,因而它的延迟通常比较稳定,这也是有些时候需要选用BucketCache的原因。
HRegion:是一个Table中的一个Region在一个HRegionServer中的表达,是Hbase中分布式存储和负载均衡的最小单元。一个Table拥有一个或多个Region,分布在一台或多台HRegionServer上。一台HRegionServer包含多个HRegion,可以属于不同的Table。HRegion由多个Store(HStore)构成,每个HStore对应了一个Table在这个HRegion中的一个Column Family,即每个Column Family就是一个集中的存储单元。HStore是HBase中存储的核心,它实现了读写HDFS功能,一个HStore由一个MemStore 和0个或多个StoreFile组成。
MemStore:是一个写缓存(In Memory Sorted Buffer),所有数据的写在完成WAL日志写后,会 写入MemStore中,由MemStore根据一定的算法将数据Flush到底层HDFS文件中(HFile),通常每个HRegion中的每个 Column Family有一个自己的MemStore。
HFile(StoreFile): 用于存储HBase的数据(Cell/KeyValue)。在HFile中的数据是按RowKey、Column Family、Column排序,对相同的Cell(即这三个值都一样),则按timestamp倒序排列
注意:
client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。
HRegion所处理的数据尽量和数据所在的DataNode在一起,实现数据的本地化。
详细的介绍可参考下面的链接:
http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html
https://www.cnblogs.com/tgzhu/p/5857035.html
博文来自:www.51niux.com
二、HBase集群的部署
hadoop集群的部署:https://blog.51niux.com/?id=175
Zookeeper集群的部署:https://blog.51niux.com/?id=182
HBase官网文档:http://hbase.apache.org/book.html#arch.overview
2.1 HBase的下载并安装:
# wget mirror.bit.edu.cn/apache/hbase/stable/hbase-1.2.6-bin.tar.gz
# tar zxf hbase-1.2.6-bin.tar.gz -C /home/hadoop/
# chown -R hadoop:hadoop /home/hadoop/hbase-1.2.6
# ln -s /home/hadoop/hbase-1.2.6 /home/hadoop/hbase
2.2 HBase的环境配置并修改配置文件:
设置环境变量(所有节点):
# vim /etc/profile
##########hbase################### export HBASE_HOME=/home/hadoop/hbase export PATH=$PATH:$HBASE_HOME/bin
# source /etc/profile
修改hbase-env.sh:
# vim /home/hadoop/hbase/conf/hbase-env.sh
# export JAVA_HOME=/usr/java/jdk1.6.0/ export JAVA_HOME=/usr/java/jdk # export HBASE_MANAGES_ZK=true export HBASE_MANAGES_ZK=false #Hbase依赖一个zookeeper集群所有的节点和客户端都必须能够访问zookeeper。默认的情况下Hbase会管理一个zookeep集群。这个集群会随着Hbase的启动而启动。当然,你也可以自己管理一个zookeeper集群,但需要配置Hbase。 #你需要修改conf/hbase-env.sh里面的HBASE_MANAGES_ZK 来切换。这个值默认是true的,作用是让Hbase启动的时候同时也启动zookeeper.让Hbase使用一个现有的不被Hbase托管的Zookeep集群,需要设置 conf/hbase-env.sh文件中的HBASE_MANAGES_ZK 属性为 false
博文来自:www.51niux.com
修改hbase-site.xml :
# cat /home/hadoop/hbase/conf/hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> </property> <property> <name>hbase.hregion.max.filesize</name> <value>10737418240</value> </property> <property> <name>hbase.hregion.memstore.flush.size</name> <value>134217728</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>zookeeper.session.timeout</name> <value>120000</value> </property> <property> <name>hbase.zookeeper.property.tickTime</name> <value>6000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>slave04.hadoop,slave05.hadoop,slave06.hadoop</value> </property> <property> <name>hbase.tmp.dir</name> <value>/home/hadoop/hbase/tmp</value> </property> </configuration>
下面是对上面参数的介绍:
hbase.rootdir #HBase集群中所有RegionServer共享目录,用来持久化HBase的数据,一般设置的是hdfs的文件目录。
hbase.hregion.max.filesize #单个ColumnFamily的region大小(最大HFile大小。如果一个region的HFiles的总和已经超过这个数值),若按照ConstantSizeRegionSplitPolicy策略,超过设置的该值则自动split。默认值是:10737418240,也就是是10GB。
hbase.hregion.memstore.flush.size #如果memstore的大小超过此字节数,Memstore将被刷新到磁盘。默认值是134217728,也就是128MB
hbase.cluster.distributed #群集所处的模式。对于独立模式,可能的值为false,对于分布式模式,可能的值为true。 如果为false,启动将在一个JVM中一起运行所有HBase和ZooKeeper守护进程。默认值是false。
hbase.zookeeper.property.clientPort #来自ZooKeeper的配置zoo.cfg的属性。 客户端将连接的端口。默认是2081端口
zookeeper.session.timeout #ZooKeeper会话超时(以毫秒为单位)。 它以两种不同的方式使用。 首先,这个值用于HBase用来连接到集合的ZK客户端。 当它启动一个ZK服务器时它也被HBase使用,它被作为'maxSessionTimeout'传递。如果HBase区域服务器连接到也由HBase管理的ZK集合,那么会话超时将是由此配置指定的。 但是,连接到以不同配置管理的合奏的区域服务器将受到合奏的maxSessionTimeout的限制。 所以,尽管HBase可能会建议使用90秒,但是整体的最大超时时间可能会低于此值,因此优先。 ZK目前的默认值是40秒,比HBase的低。默认值是9000
hbase.zookeeper.property.tickTime #客户端与zk发送心跳的时间间隔。默认值就是6000,也就是6秒钟
hbase.zookeeper.quorum #zookeeper集群的URL配置,多个host中间用逗号(,)分割
hbase.zookeeper.quorum #默认情况下,对于本地和伪分布式操作模式,将其设置为localhost。 对于完全分布式安装,应将其设置为ZooKeeper集成服务器的完整列表。 如果在hbase-env.sh中设置了HBASE_MANAGES_ZK,这是hbase将作为群集启动/停止的一部分启动/停止ZooKeeper的服务器列表。 客户端,我们将把这个集合成员的列表,并把它与hbase.zookeeper.property.clientPort配置放在一起。 并将其作为connectString参数传递给zookeeper构造函数。默认是localhost
hbase.tmp.dir #本地文件系统上的临时目录。 将此设置更改为指向比“/ tmp”更持久的位置,这是java.io.tmpdir的常见解决方案,因为在重新启动计算机时清除了“/ tmp”目录。默认$ {java.io.tmpdir}/ HBase的 - $ {user.name}# mkdir /home/hadoop/hbase/tmp
# chown -R hadoop:hadoop /home/hadoop/
#有人总结的Hbase的配置参数:https://www.cnblogs.com/qinersky902/p/6217741.html
修改regionservers配置文件
# vim /home/hadoop/hbase/conf/regionservers #类似于hadoop的slave,regionservers的服务节点设置到这里,regionservers服务节点一般跟datanode节点在一起。
slave01.hadoop slave02.hadoop slave03.hadoop slave04.hadoop slave05.hadoop slave06.hadoop
2.3 将 /home/hadoop/hbase-1.2.6发送到其他hadoop节点
然后做软连接:# ln -s /home/hadoop/hbase-1.2.6 /home/hadoop/hbase
2.4 启动Hbase并查看
$ /home/hadoop/hbase/bin/start-hbase.sh
#然后查看slave端的日志发现有报错:
$ tail -f /home/hadoop/hbase/logs/hbase-hadoop-regionserver-slave06.hadoop.log
2017-11-17 16:49:02,538 ERROR [main] regionserver.HRegionServerCommandLine: Region server exiting java.lang.RuntimeException: Failed construction of Regionserver: class org.apache.hadoop.hbase.regionserver.HRegionServer at org.apache.hadoop.hbase.regionserver.HRegionServer.constructRegionServer(HRegionServer.java:2682) at org.apache.hadoop.hbase.regionserver.HRegionServerCommandLine.start(HRegionServerCommandLine.java:64) at org.apache.hadoop.hbase.regionserver.HRegionServerCommandLine.run(HRegionServerCommandLine.java:87) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:126) at org.apache.hadoop.hbase.regionserver.HRegionServer.main(HRegionServer.java:2697) Caused by: java.lang.reflect.InvocationTargetException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.hbase.regionserver.HRegionServer.constructRegionServer(HRegionServer.java:2680) ... 5 more Caused by: java.lang.IllegalArgumentException: java.net.UnknownHostException: mycluster at org.apache.hadoop.security.SecurityUtil.buildTokenService(SecurityUtil.java:373) at org.apache.hadoop.hdfs.NameNodeProxies.createNonHAProxy(NameNodeProxies.java:258) at org.apache.hadoop.hdfs.NameNodeProxies.createProxy(NameNodeProxies.java:153) at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:602) at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:547) at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:139) at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2591) at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:89) at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2625) at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2607) at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:368) at org.apache.hadoop.fs.Path.getFileSystem(Path.java:296) at org.apache.hadoop.hbase.util.FSUtils.getRootDir(FSUtils.java:1003) at org.apache.hadoop.hbase.regionserver.HRegionServer.initializeFileSystem(HRegionServer.java:609) at org.apache.hadoop.hbase.regionserver.HRegionServer.<init>(HRegionServer.java:564) ... 10 more Caused by: java.net.UnknownHostException: mycluster ... 25 more
#因为我们配置的是hdfs://mycluster/hbase,这里提示找不到mycluster。
解决办法:
[hadoop@master ~]$ cp /home/hadoop/hadoop/etc/hadoop/core-site.xml /home/hadoop/hbase/conf/
[hadoop@master ~]$ cp /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml /home/hadoop/hbase/conf/
#然后再把配置文件全部节点同步一点。
$ /home/hadoop/hbase/bin/stop-hbase.sh
$ /home/hadoop/hbase/bin/start-hbase.sh #重新启动一下
master.hadoop节点查看:
$ jps
28111 HMaster
$ lsof -i :16000 #hbase的master端口默认是16000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 28914 hadoop 306u IPv6 263145 0t0 TCP master.hadoop:fmsas (LISTEN) java 28914 hadoop 376u IPv6 263161 0t0 TCP master.hadoop:fmsas->slave02.hadoop:54033 (ESTABLISHED) java 28914 hadoop 377u IPv6 263163 0t0 TCP master.hadoop:fmsas->slave05.hadoop:34019 (ESTABLISHED) java 28914 hadoop 378u IPv6 263165 0t0 TCP master.hadoop:fmsas->slave06.hadoop:41143 (ESTABLISHED) java 28914 hadoop 379u IPv6 263167 0t0 TCP master.hadoop:fmsas->slave03.hadoop:58112 (ESTABLISHED) java 28914 hadoop 380u IPv6 270337 0t0 TCP master.hadoop:fmsas->slave04.hadoop:48841 (ESTABLISHED) java 28914 hadoop 381u IPv6 270339 0t0 TCP master.hadoop:fmsas->slave01.hadoop:53878 (ESTABLISHED)
slave节点查看:
$ jps
24116 HRegionServer
$ lsof -i :16020 #regionserver默认监听在16020端口
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 24116 hadoop 126u IPv6 1990424 0t0 TCP slave06.hadoop:jwpc (LISTEN)
博文来自:www.51niux.com
zk节点上面查看:
$ /home/hadoop/zookeeper/bin/zkCli.sh -server localhost:2181
[zk: localhost:2181(CONNECTED) 4] ls / [zookeeper, yarn-leader-election, spark, hadoop-ha, hbase] [zk: localhost:2181(CONNECTED) 7] ls2 /hbase [replication, meta-region-server, rs, splitWAL, backup-masters, table-lock, flush-table-proc, region-in-transition, online-snapshot, master, running, recovering-regions, draining, namespace, hbaseid, table] cZxid = 0xf000000ed ctime = Fri Nov 17 16:41:53 CST 2017 mZxid = 0xf000000ed mtime = Fri Nov 17 16:41:53 CST 2017 pZxid = 0xf000001c5 cversion = 30 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 16 #可以看到产生了好多的子节点 [zk: localhost:2181(CONNECTED) 8] get /hbase/master �master:16000�i�,�uPBUF master.hadoop�}�����+�} cZxid = 0xf00000198 ctime = Fri Nov 17 17:01:15 CST 2017 mZxid = 0xf00000198 mtime = Fri Nov 17 17:01:15 CST 2017 pZxid = 0xf00000198 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x15fbb2555140013 dataLength = 61 numChildren = 0
HDFS上面的查看:
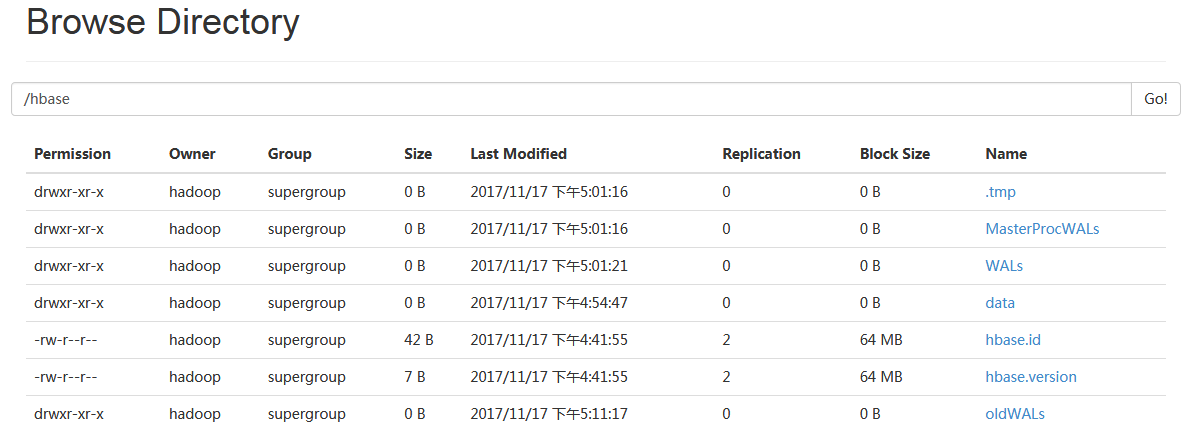
HBase在HDFS上面构建的目录树:
/hbase/.tmp #当对表做创建或者删除操作的时候,会将表move 到该 tmp 目录下,然后再去做处理操作。 /hbase/MasterProcWALs /hbas/WALs #预先写入日志(WAL)将HBase中数据的所有更改记录到基于文件的存储中。 在正常操作下,不需要WAL,因为数据更改从MemStore移动到StoreFiles。 但是,如果在刷新MemStore之前RegionServer崩溃或变得不可用,则WAL确保可以重播对数据的更改。 如果写入WAL失败,整个操作修改数据失败。 #HBase使用WAL接口的实现。 通常,每个RegionServer只有一个WAL实例。 在将它们记录到受影响商店的MemStore之前,RegionServer会记录它们并将其删除。 /hbase/data #hbase 的核心目录,系统会预置两个 namespace 即:hbase和default。 /hbase/hbase.id #它是一个文件,存储集群唯一的 cluster id 号,是一个 uuid。 /hbase/hbase.version #同样也是一个文件,存储集群的版本号,是加密的,看不到,只能通过web-ui才能正确显示出来。 /hbase/oldWALs #旧的.oldlogs目录。
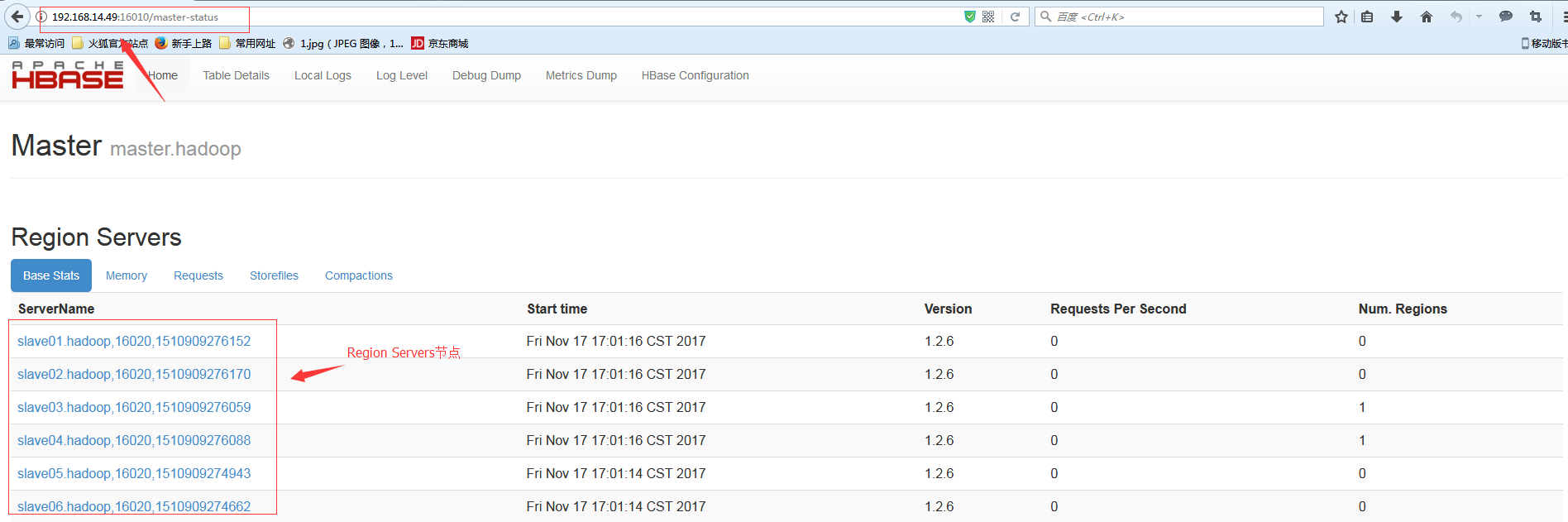
访问web ui:
网址:master的ip:16010
2.5 启动从Hbase并做HA测试
#在master.hadoop上面将/home/hadoop/hbase的整个目录拷贝到smaster.hadoop节点上面。
$ /home/hadoop/hbase/bin/hbase-daemon.sh start master #然后再备节点上面启动Hmaster服务
#web页面访问:http://192.168.14.49:16010/master-status

#备用节点出现了。
$ lsof -i :16000 #在smaster.hadoop上面查看,现在还没有其他slave节点的连接
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 22834 hadoop 304u IPv6 297175 0t0 TCP smaster.hadoop:fmsas (LISTEN)
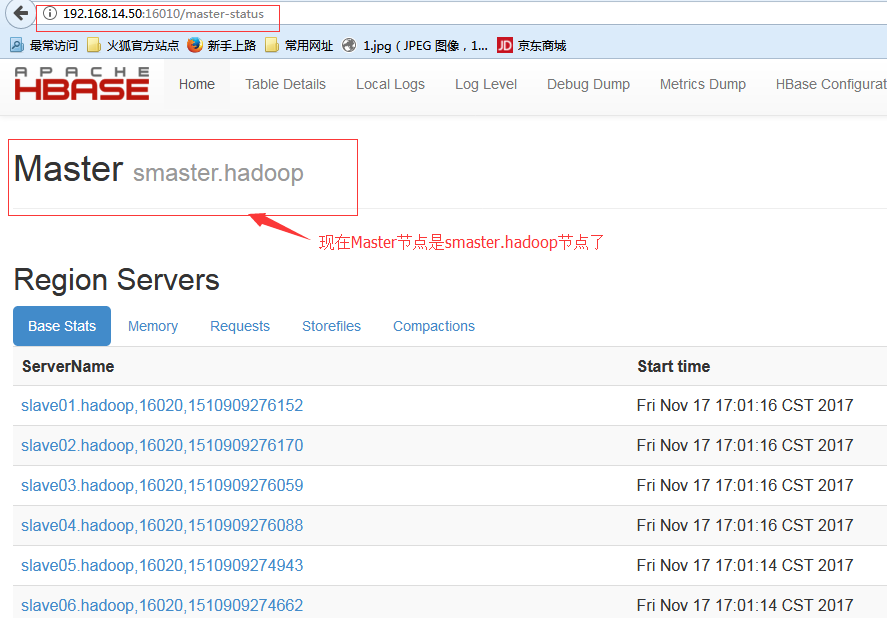
$ /home/hadoop/hbase/bin/hbase-daemon.sh stop master #在master.hadoop节点上面执行关闭Hmaster的操作
[hadoop@smaster ~]$ lsof -i :16000 #可以看到slave节点都跟smaster.hadoop节点建立连接了
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java 22834 hadoop 304u IPv6 297175 0t0 TCP smaster.hadoop:fmsas (LISTEN) java 22834 hadoop 375u IPv6 298583 0t0 TCP smaster.hadoop:fmsas->slave01.hadoop:34236 (ESTABLISHED) java 22834 hadoop 376u IPv6 298584 0t0 TCP smaster.hadoop:fmsas->slave02.hadoop:36961 (ESTABLISHED) java 22834 hadoop 377u IPv6 298585 0t0 TCP smaster.hadoop:fmsas->slave06.hadoop:34253 (ESTABLISHED) java 22834 hadoop 378u IPv6 298586 0t0 TCP smaster.hadoop:fmsas->slave05.hadoop:43371 (ESTABLISHED) java 22834 hadoop 379u IPv6 298588 0t0 TCP smaster.hadoop:fmsas->slave04.hadoop:41175 (ESTABLISHED) java 22834 hadoop 380u IPv6 298590 0t0 TCP smaster.hadoop:fmsas->slave03.hadoop:33348 (ESTABLISHED)
$ /home/hadoop/hbase/bin/hbase-daemon.sh start master #再次启动master.hadoop节点上面的Hmaster服务
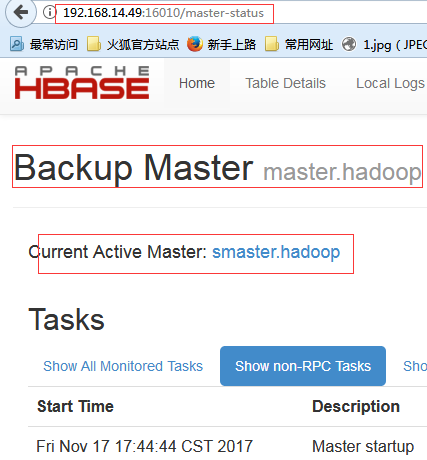
现在再来看zk里面的信息:
[zk: localhost:2181(CONNECTED) 9] get /hbase/master �master:16000����!��PBUF smaster.hadoop�}�����+�} cZxid = 0xf000001dc ctime = Fri Nov 17 17:42:19 CST 2017 mZxid = 0xf000001dc mtime = Fri Nov 17 17:42:19 CST 2017 pZxid = 0xf000001dc cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x25fbb253154001e dataLength = 62
博文来自:www.51niux.com
三、HBase的使用
3.1 HBase Shell
HBase包含可以与HBase进行通信的Shell。 HBase使用Hadoop文件系统来存储数据。它拥有一个主服务器和区域服务器。数据存储将在区域(表)的形式。这些区域被分割并存储在区域服务器。主服务器管理这些区域服务器,所有这些任务发生在HDFS。
$ /home/hadoop/hbase/bin/hbase shell
hbase(main):002:0> status #提供HBase的状态 1 active master, 1 backup masters, 6 servers, 0 dead, 0.3333 average load hbase(main):003:0> version #提供正在使用HBase的版本 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017 hbase(main):005:0> whoami #正在操作的用户信息 hadoop (auth:SIMPLE) groups: hadoop hbase(main):006:0> table_help #表引用命令帮助
3.2 表的常用操作
创建表和列出表:
格式:create ‘<table name>’,’<column family>’ #指定表名和列族名
hbase(main):008:0> create 'member','member_id','address','info' 0 row(s) in 5.1950 seconds => Hbase::Table - member hbase(main):009:0> list #可以用list查看一下,可以看到member表已经创建了,list就是列出表操作 TABLE member 1 row(s) in 0.0470 seconds => ["member"]
#可以使用HBaseAdmin类的createTable()方法创建表。
#可以使用HBaseAdmin中有一个方法叫 listTables(),列出HBase中所有的表的列表。
禁用和启动表:
hbase(main):011:0> disable 'member' #禁用member表,表都要用''引起来啊 hbase(main):015:0> scan 'member' #扫描这个表,下面的结果是扫描不到 ROW COLUMN+CELL ERROR: member is disabled. hbase(main):018:0> is_disabled 'member' #查看表是否被禁用,如果禁用会返回true,如下面的结果 true 0 row(s) in 0.0170 seconds hbase(main):019:0> disable_all 'me.*' #用来禁用所有匹配到的表,下面是结果输出 member Disable the above 1 tables (y/n)? y 1 tables successfully disabled hbase(main):020:0> enable 'member' #这表示启用member表 hbase(main):021:0> scan 'member' #扫描member表,下面是结果输出 ROW COLUMN+CELL 0 row(s) in 0.0840 seconds hbase(main):022:0> is_enabled 'member' #如果是启动就返回true true 0 row(s) in 0.0200 seconds
#要验证一个表是否被禁用,使用isTableDisabled()方法和disableTable()方法禁用一个表。这些方法属于HBaseAdmin类
#要验证一个表是否被启用,使用isTableEnabled()方法;并且使用enableTable()方法使一个表启用。这些方法属于HBaseAdmin类
表描述:
hbase(main):026:0> describe 'member' #查看member表的描述信息,下面为结果输出。
Table member is ENABLED
member
COLUMN FAMILIES DESCRIPTION
{NAME => 'address', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '
0'}
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'member_id', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE =>
'0'}
3 row(s) in 0.0410 seconds
#在web页面也可以查看到创建的表以及表的描述。
#剩下的常用操作可以网上搜一波。
