Docker(二)容器详解
https://blog.51niux.com/?id=185 #已经记录了docker的简单操作,这里进行一些比较深入的记录。
一、Docker架构概览
Docker架构:http://www.infoq.com/cn/articles/docker-source-code-analysis-part1/
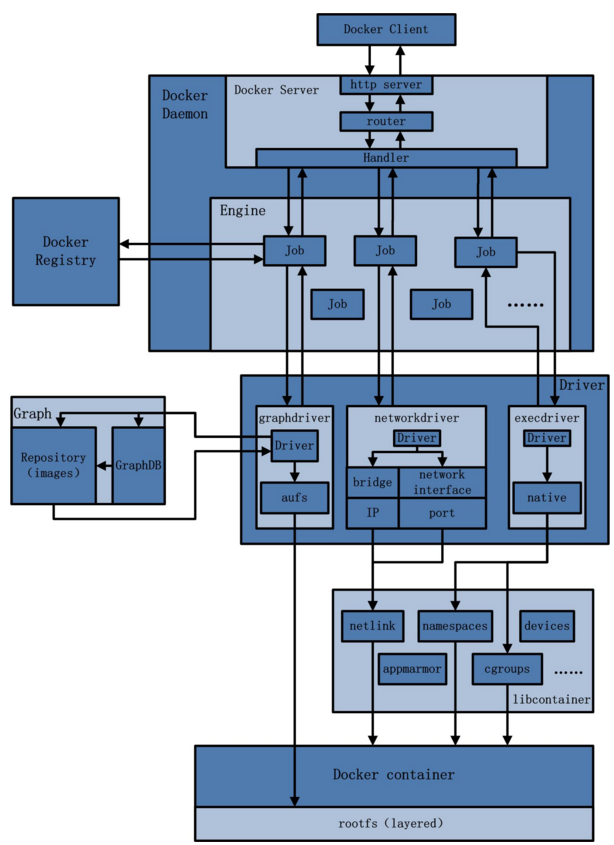
#上图是一张Docker的总架构图。
1.1 各个功能模块的功能简述:
Docker client:
Docker client是一个泛称,用来向指定的Docker daemon发起请求,执行相应的容器管理操作。它既可以使docker命令行工具,也可以是任何遁循了Docker API的客户端。
Docker daemon:
Docker daemon是Docker架构的主要用户接口,也是最核心的后台进程(service docker start 就是启动DOcker daemon进程),它负责响应来自Docker client的请求,然后将这些请求翻译成系统调用完成容器管理操作。该进程会在后台启动一个API server,负责接收由Docker client 发送的请求;接收到的请求将通过Docker daemon内部的一个路由分发调度,再由具体函数来执行请求。
Graph:
Graph组件负责维护已下载的镜像信息及它们之间的关系,所以大部分Docker镜像相关的操作都会由graph组件来完成。graph通过镜像“层”和每层的元数据来记录这些镜像的信息,用户发起的镜像管理操作最终都转换成了graph对这些层和元数据的操作。但正是由于这个原因,而且很多时候Docker操作都需要加载当前Docker daemon维护者的所有镜像信息,graph组件常常会成为性能瓶颈。
GraphDB:
Docker daemon通过GraphDB记录它所维护的所有容器以及它们之间的link关系,所以这里就采用了一个图结构来保存这些数据。具体来说,GraphDB就是一个基于SQLite的最简单版本的图形数据库,能够为调用者提供节点、删、遍历、连接、所有父子节点的查询等操作。这些节点对应的就是一个容器,而节点间的边就是一个Docker link关系。每创建一个容器,Docker daemon都会在GraphDB里添加一个节点,而当为某个容器设置了link操作后,在GraphDB中就会为它创建一个父子关系。
drive:
Docker通过driver模块来实现对Docker容器执行环境的定制。Docker daemon负责将用户请求转译成系统调用,为了将这些系统调用抽象成统一的操作接口方便调用者使用,Docker把这些操作分类成容器管理驱动(execdriver)、网络管理驱动(networkdriver)、文件存储驱动(graphdriver)三种。
execdriver是对Linux操作系统的namespace、cgroups、apparmor、SELinux等容器运行所需的系统操作进行的一层二次封装,其本质作用类似于LXC,但功能更全面。execdriver最主要的实现是Docker官方编写的libcontainer库。libcontainer是一个独立的容器管理包,networkdriver和execdriver都通过libcontainer来实现对容器的具体操作(包括利用UTS、IPC、PID、Network、Mount、User等namespace来实现容器之间的资源隔离和利用cgroup实现对容器的资源限制)。当运行容器的命令执行完毕后,一个实际的容器就处于运行状态,该容器拥有独立的文件系统、安全且相互隔离的运行环境。
networkdriver是对容器网络环境操作所进行的封装。对于容器来说,网络设备的配置相比较独立,并且应该允许用户进行更多的配置。这些操作具体包括创建容器通信所需的网络,容器的network namespace,这个网络所需的虚拟网卡,分配通信所需的IP,服务访问的端口和容器与宿主机之间的端口映射(设置hosts、resolv.conf、iptables等)。
graphdriver是所有与容器镜像相关操作的最终执行者。graphdriver会在Docker工作目录下维护一组与镜像层对应的目录,并记下容器和镜像之间的关系等元数据。这样,用户对镜像的操作最终会被映射成对这些目录文件及元数据的增删改查,从而屏蔽掉不同文件存储实现对于上层调用者的影响。目前Docker已经支持的文件存储包括aufs、btrfs、devicemapper、overlay和vfs.
1.2 daemon 对象的创建和初始化过程
Docker容器的配置信息:
容器的配置信息主要功能是供用户自由配置Docker容器的可选功能,使得Docker容器的运行更贴近用户期待的运行场景,配置信息的处理包含以下部分:
设置默认的网络最大传输单元:当用户没有对-mtu参数进行指定时,将其设置为1500.否则,沿用用户指定的参数值。 检测网桥配置信息:此部分配置为进一步配置Docker网络提供铺垫。 查验容器通信配置:主要用于确定用户设置是否允许对iptables配置及容器间通信,分别用--iptables和--icc参数表示,若两者皆为false则报错。
验证系统支持及用户权限:
初步处理完Docker的配置信息之后,Docker对自身运行的环境进行了一系列的检查,主要包括:
操作系统类型对Docker daemon的支持,目前Docker daemon只能运行在Linux系统上。 用户权限的级别,必须是root权限。 内核版本上与处理器的支持,只支持“amb64”架构的处理器,且内核版本必须升至3.10.0及以上。
配置daemon工作路径:
配置Dockerdaemon的工作路径,主要是创建Docker daemon运行中所在的工作目录,默认为/var/lib/docker。若目录不存在,则会创建并赋予“0700”权限。
配置Docker容器所需的文件环境:
这一步Docker daemon会在Docker工作根目录/var/lib/docker下面初始化一些重要的目录和文件来构建Docker容器工作所需的文件系统环境。
配置graphdriver目录,它用于完成Docker镜像管理所需的联合文件系统的驱动层。所以,这一步的配置工作就是加载并配置镜像存储驱动graphdriver,创建镜像管理所需的目录和环境。
创建容器配置文件目录。Docker daemon在创建Docker容器之后,需要将容器内的配置文件放到这个目录下统一管理。目录默认位置为:/var/lib/docker/containers,它下面会为每个具体容器创建一个目录,下面保存一些配置文件。
配置镜像目录,主要工作是:在工作根目录下创建一个graph目录来存储所有镜像描述文件,默认目录为/var/lib/docker/graph。对于每一个镜像层,Docker在这里使用json和layersize两个文件描述这一层镜像的父镜像ID和本层大小,而正在的镜像内容保存在aufs的diff工作目录的同名目录下。
创建volume驱动目录(默认/var/lib/docker/volumes),Docker中volume是宿主机上挂载到Docker容器内部的特定目录。由于Docker需要使用graphdriver来挂载这些volumes,所以采用vfs驱动实现volumes的管理。这里的volumes目录下仅保存一个volume配置文件config.json,其中会以Path指出这个目录的真正位置。
准备“可信镜像”所需的工作目录。在Docker工作目录下创建trust目录,并创建一个TrustStore。这个存储目录可以根据用户给出的可信url加载授权文件,用来处理可信镜像的授权和验证过程。
创建TagStore,用于存储镜像的仓库列表。
创建Docker daemon网络
创建GraphDB。这一步初始化GraphDB实际上就是建立数据库连接的过程。
初始化execdriver.
恢复已有的Docker容器。当Docker daemon启动时,会去查看在daemon.repository也就是在/var/lib/docker/containers/中的内容。若有已经存在的Docker容器,则将相应的信息收集并进行维护,同时重启restart policy为always的容器。
Docker daemon进程的启动都要遵循以下3步:
首先启动一个APIServer,它工作在用户通过-H指定的socker上面 然后Docker使用NewDaemon方法创建一个daemon对象来保存信息和处理业务逻辑。 最后将上述APIServer和daemon对象绑定起来,接受并处理client的请求。
libcontainer详解:http://www.infoq.com/cn/articles/docker-container-management-libcontainer-depth-analysis
二、Docker里的内核知识
Docker容器本质是宿主机上的进程,Docker通过namespace实现了资源隔离,通过cgroups实现了资源限制,通过写时复制机制(copy-on-write)实现了高效的文件操作。
2.1 namespace资源隔离
linux内核中提供了6种namespace隔离的系统调用,如下图:
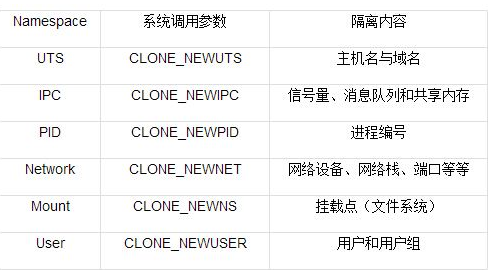
实际上,Linux内核实现namespace的主要目的之一就是实现轻量级虚拟化(容器)服务。在同一个namespace下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,仿佛自己置身于一个独立的系统环境中,以达到独立和隔离的目的。
进行namespace API操作的四种方式包括clone()在创建新进场的同时创建namespace,sent()加入一个已经存在的namespace以及unshare()在原先进场上进行namespace隔离还有/pro下的部分文件。为了确定隔离的到底是哪6项namespace,在使用这些API时,通常需要制定以下6个参数的一个或多个,通过|(位或)操作来实现。这6个参数就是上图上面那6个系统调用参数。
下面对6种namespace做下简单介绍:
UTS namespace: UTS(UNIX Time-sharing System)namespace提供了主机名和域名的隔离,这样每个Docker容器就可以拥有独立的主机名和域名了。在网络上可以被视作一个独立的节点,而非宿主机上的一个进程。Docker中,每个镜像基本都以自身所提供的服务名称来命名镜像的hostname,且不会对宿主机产生任何影响,其原理就是利用UTS namespace。
IPC namespace:进程间通信(Inter-Process Communication,IPC)涉及的IPC资源包括常见的信号量、消息队列和共享内存。申请IPC资源就申请了一个全局唯一的32位ID,所以IPC namespace中实际上包含了系统IPC标识符以及实现POSIX消息队列的文件系统。在同一个IPC namespace下的进程彼此可见,不同IPC namespace下的进程互相不可见。目前使用IPC namespace机制其中比较有名的有PostgreSQL。Docker当前也使用IPC namespace实现了容器与宿主、容器与容器之间的IPC隔离。# ipcs -q #可以查看已经开启的message queue。
PID namespace : PID namespace隔离非常实用,它对进程PID重新标号,即两个不同namespace下的进程可以有相同的PID。 每个PID namespace都有自己的计数程序。内核为所有的PID namespace维护了一个树状结构,最顶层的是系统初始时创建的,被称为root namespace。它创建的新的PID namespace被称为child namespace(树的子节点),而原先的PID namespace就是新创建的PID namespace的parent namespace(树的父节点)。通过这种方式,不同的PID namespace会形成一个层级体系。所属的父节点可以看到子节点的进程,并可以通过信号灯方式对子节点中的进程产生影响。反过来,子节点却不能看到父节点的PID namespace中的任何内容。
Network namespace : network namespace主要提供了关于网络资源的隔离,包括网络设备、IPV4和IPV6协议栈、IP路由表、防火墙、/proc/net目录、/sys/class/net目录、套接字(socket)等。一个物理的网络设备最多存在于一个network namespace中,可以通过创建veth pair(虚拟网络设备对:有两端,类似管道,如果数据从一端传入另一端也能接收到)在不同的network namespace间创建通道,以达到通信目的。
Mount namespace : 通过隔离文件系统挂载点对隔离文件系统提供支持,它是历史上第一个Linux namespace,所以标示位比较特殊,就是CLONE_NEWNS。隔离后不同mount namespace中的文件结构发生变化也互不影响。可以通过/proc/[pid]/mounts查看所有挂载到当前namespace中的文件系统,还可以通过/proc/[pid]/mountstats看到mount namespace中文件设备的统计信息,包括挂载文件的名字、文件系统类型、挂载位置等。进程在创建mount namespace时,会把当前的文件结构复制给新的namespace。新的namespace中的所有mount操作都只影响自身的文件系统,对外界不会产生任何影响。
user namespace : 这个主要隔离了安全相关的标识符(identifiers)和属性(attributes),包括用户ID、用户组ID、root目录、key(指密钥)以及特殊权限。user namespace直到Linux内核3.8版本的时候还未完全实现。
2.2 cgroups资源限制
cgroups在2007年更名为(control groups)并整合进Linux内核。cgroups可以限制、记录任务组所使用的物理资源(包括CPU、memory、IO等),为容器实现虚拟化提供了基本保证,是构建Docker等一系列虚拟化管理工具的基石。
cgroups的作用:
实现cgroups的主要目的是为不同用户层面的资源管理,提供一个统一化的接口。从单个任务的资源控制到操作系统层面的虚拟化,cgroups提供了以下四大功能:
资源限制 #cgroups可以对任务使用的资源总额进行限制。如设定应用运行时使用内存的上限,一旦超过这个配额就发出OOM(Out of Memory)提示。 优先级分配 #通过分配的CPU时间片数量及磁盘IO带宽大小,实际上就相当于控制了任务运行的优先级。 资源统计 #cgroups可以统计系统的资源使用量,如CPU使用时长、内存用量等,这个功能非常适用于计费。 任务控制 #cgroups可以对任务执行挂起、恢复等操作。
cgroups术语表:
task(任务) #在cgroups的术语中,任务表示系统的一个进程或线程。 cgroups(控制组) #cgroups中的资源控制都以cgroup为单位实现。cgroup表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个cgroup,也可以从某个cgroup迁移到另一个cgroup。 subsystem(子系统) #cgroups中的子系统就是一个资源调度控制器。比如CPU子系统可以控制CPU时间分配,内存子系统可以限制cgroup内存使用量。 hierarchy(层级) #层级由一系统cgroup以一个树状结构排列而成,每个层级通过绑定对应的子系统进行资源控制。层级中的cgroup节点可以包含零或多个子节点,子节点继承父节点挂载的子系统。整个操作系统可以有多个层级。
cgroups、任务、子系统、层级四者间的关系以及基本规则:
规则1: 同一个层级可以附加一个或多个子系统。
规则2:一个子系统可以附加到多个层级,当且仅当目标层级只有唯一一个子系统时。
规则3:系统每次新建一个层级时,该系统上的所有任务默认加入这个新建层级的初始化cggroup,这个cgroup也被称为root cgroup。对于创建的每个层级,任务只能存在于其中一个cgroup中,即一个任务不能存在于同一个层级的不同cgroup中,但一个任务可以存在于不同层级中的多个cgroup中。如果操作时把一个任务添加到同一个层级中的另一个cgroup中,则会将它从第一个cgroup中移除。
规则4: 任务在for/clone自身时创建的子任务默认与原任务在同一个cgroup中,但是子任务允许被移动到不同的cgroup中,即fork/clone完成后,父子任务间在cgroup方面是互不影响的。
子系统简介:
子系统实际上就是cgroups的资源控制系统,每种子系统独立地控制一种资源。目前Docker使用如下9种子系统:
bikio #可以为块设备设定输入/输出限制,比如物理驱动设备(包括磁盘、固态硬盘、USB等) cpu #使用调度程序控制任务对CPU的使用 cpuacct #自动生成cgroup中任务对CPU资源使用情况的报告。 cpuset #可以为cgroup中的任务分配独立的CPU(此处针对多处理器系统)和内存。 devices #可以开启或关闭cgroup中任务对设备的访问 freezer #可以挂起或恢复cgroup中的任务 memory #可以设定cgroup中任务对内存使用量的设定,并且自动生成这些任务对内存资源使用情况的报告。 perf_event #使用后使cgroup中的任务可以进行统一的性能测试。 *net_cls #Docker没有直接使用它,它通过使用等级标识符(classid)标识网络数据包,从而允许Linux流量控制程序(Traffic Controller,TC)识别从具体cgroup中生成的数据包。
cgroup实现方式及工作原理简介:
cgroups的实现本质上是给任务挂上钩子,当任务运行的过程中涉及某种资源时,就会触发钩子上所附带的子系统进行检测,根据资源类别的不同使用对应的技术进行资源限制和优先级分配。
cgroups如何判断资源超限及超出限额之后的措施: 对于不同的系统资源,cgroups提供了统一的接口对资源进行控制和统计,但限制的具体方式则不仅相同。比如memory子系统,会在描述内存状态的“mm_struct”结构体重记录它所属的cgroup,当进程需要申请更多内存时,就会触发cgroup用量检测,如果用量超过cgroup规定的限额则拒绝用户的内存申请,否则就给予相应内存并在cgroup的统计信息中记录。实际实现要比以上描述复杂得多,不仅需要考虑内存的分配与回收,还需考虑不同类型的内存和Cache(缓存)和Swap(交换区内存拓展)等。
cgroups的子系统与任务之间的关联关系: cgroup与任务之间是多对多的关系。所以它们并不直接关联,而是通过一个中间结构把双向的关联信息记录起来。每个任务结构体task_struct中都包含了一个指针,可以查询到对应cgroup的情况,同时也可以查询到各个子系统的状态,这些子系统状态中也包含了找到任务的指针,不同类型的子系统按需定义本身的控制信息结构体,最终在自定义的结构体中把子系统状态指针包含进去,然后内核通过container_of(这个宏可以通过一个机构体的成员找到结构体自身)等宏定义来获取对应的结构体,关联到任务,以此达到资源限制的目的。同时为了让cgroups便于用户理解和使用,也为了用精简的内核代码为cgroup提供熟悉的权限和命名空间管理,内核开发者们按照Linux虚拟文件系统转换器(Virtual Filesystem Switch,VFS)接口实现了一套名为cgroup的文件系统,非常巧妙的用来表示cgroups的层级概念。把各个子系统的实现都封装到文件系统的各项操作中。
三、容器的操作
容器是Docker的一个核心概念。容器是镜像的一个运行实例,所不同的是,它带有额外的可写文件层。Docker的设计理念是希望用户能够保证一个容器只运行一个进程,即只提供一种服务。
3.1 容器的创建
Docker的容器十分轻量级,用户可以随时创建或删除容器。
# docker create --help
用法:docker create [OPTIONS] IMAGE [COMMAND] [ARG...] 选项: --add-host value #添加自定义的主机到IP映射(主机:IP)(默认[]) -a, --attach value #附加到STDIN,STDOUT或STDERR(默认[]) --blkio-weight value #块IO(相对权重),在10和1000之间 --blkio-weight-device value #块IO权重(相对设备重量)(默认[]) --cap-add value #添加Linux功能(默认[]) --cap-drop value #删除Linux功能(默认[]) --cgroup-parent string #容器的可选父cgroup --cidfile string #将容器ID写入文件 --cpu-percent int #CPU百分比(仅限Windows) --cpu-period int #限制CPU CFS(完全公平调度程序)期间 --cpu-quota int #限制CPU CFS(完全公平调度程序)配额 -c, --cpu-shares int #CPU份额(相对权重) --cpuset-cpus string #在其中允许执行的CPU(0-3,0,1) --cpuset-mems string #允许执行的MEM(0-3,0,1) --device value #添加主机设备到容器(默认[]) --device-read-bps value #限制设备(默认[])的读取速率(每秒字节数) --device-read-iops value #限制来自设备的读取速率(IO每秒)(默认[]) --device-write-bps value #限制写入速率(每秒字节数)到设备(默认[]) --device-write-iops value #限制写入速率(每秒IO)到设备(默认[]) --disable-content-trust #跳过镜像验证(默认为true) --dns value #设置自定义DNS服务器(默认[]) --dns-opt value #设置DNS选项(默认[]) --dns-search value #设置自定义DNS搜索域(默认[]) --entrypoint string #覆盖镜像的默认入口点 -e, --env value #设置环境变量(默认[]) --env-file value #读入环境变量文件(默认[]) --expose value #公开一个端口或一系列端口(默认[]) --group-add value #添加其他群组加入(默认[]) --health-cmd string #运行命令来检查运行状况 --health-interval duration #运行检查之间的时间(默认为0) --health-retries int #连续失败需要报告不健康 --health-timeout duration #允许一次检查运行的最长时间(默认为0) -h, --hostname string #容器主机名称 -i, --interactive #即使未连接,也要保持STDIN打开状态 --io-maxbandwidth string #系统驱动器的最大IO带宽限制(仅限Windows) --io-maxiops uint #系统驱动器的最大IOps限制(仅限Windows) --ip string #容器的 IPv4地址(例如172.30.100.104) --ip6 string #容器IPv6地址(例如2001:db8 :: 33) --ipc string #IPC命名空间使用 --isolation string #容器隔离技术 --kernel-memory string #内核内存限制 -l, --label value #在容器上设置元数据(默认[]) --label-file value #阅读标签的行分隔文件(默认[]) --link value #添加链接到另一个容器(默认[]) --link-local-ip value #容器IPv4 / IPv6链接本地地址(默认[]) --log-driver string #记录容器的驱动程序 --log-opt value #日志驱动程序选项(默认[]) --mac-address string #容器MAC地址(例如92:d0:c6:0a:29:33) -m, --memory string #内存限制 --memory-reservation string #内存软限制 --memory-swap string #交换限制等于内存加交换:'-1'以启用无限交换 --memory-swappiness int #调整容器内存swappiness(0到100)(默认-1) --name string #为容器指定一个名称 --network string #将容器连接到网络(默认“默认”) --network-alias value #为容器添加网络范围的别名(默认[]) --no-healthcheck #禁用任何容器指定的HEALTHCHECK --oom-kill-disable #禁用OOM killer --oom-score-adj int #调整主机的OOM首选项(从-1000到1000) --pid string #要使用的PID名称空间 --pids-limit int #调整容器的pid限制(无限制地设置-1) --privileged #给这个容器赋予扩展权限 -p, --publish value #将容器的端口发布到主机(默认[]) -P, --publish-all #将所有暴露的端口发布到随机端口 --read-only #将容器的根文件系统挂载为只读 --restart string #重新启动策略以在容器退出时应用(默认为“no”) --runtime string #运行时用于此容器 --security-opt value #安全选项(默认[]) --shm-size string #/dev/shm的大小,默认值是64MB --stop-signal string #停止容器的信号,默认为SIGTERM(默认为“SIGTERM”) --storage-opt value #容器的存储驱动程序选项(默认[]) --sysctl value #Sysctl选项(默认map[]) --tmpfs value #挂载一个tmpfs目录(默认[]) -t, --tty #分配一个伪TTY --ulimit value #Ulimit选项(默认[]) -u, --user string #用户名或UID(格式:<name | uid> [:<group | gid>]) --userns string #要使用的用户名称空间 --uts string #UTS命名空间使用 -v, --volume value #绑定装入卷(默认[]) --volume-driver string #容器的可选卷驱动程序 --volumes-from value #装载指定容器的卷(默认[]) -w, --workdir string #容器内的工作目录
(上面的IPC,UTS等是什么?)Linux内核中就提供了这六种namespace隔离的系统调用。
# docker create --name test01 docker.io/ubuntu:latest #创建一个名称叫做test01的新容器,最后那是镜像
c90e392d1dfe9c16821e2c914c7cdf40af41886d8385dd3bc9cca39b17e54018
3.2 容器的启动
基于镜像新建一个容器并启动:
利用docker run命令新建一个容器时,Docker将自动为每个新容器分配一个唯一的ID作为标识。docker run等价于先执行docker create命令再执行docker start命令。因为docker run相当于先执行docker create,所以上面列出的docker create的参数docker run也能用。
# docker run docker.io/ubuntu:latest /bin/echo "hello world\!I am 51niux\!" #下面是输出
hello world\!I am 51niux\!
#当利用docker run来创建并启动容器时,docker在后台运行的标准操作包括:
检查本地是否存在指定的镜像,不存在就从公有仓库下载
利用镜像创建并启动一个容器
分配一个文件系统,并在只读的镜像层面挂载一层可读写层
从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去
从地址池配置一个IP地址给容器
指定用户指定的应用程序
指定完毕后容器被终止
# docker run -i -t --name test02 ubuntu:latest /bin/bash #这样不仅创建了test02容器,也会进入容器。
#如果要正常退出不关闭容器,请按Ctrl,P+Ctrl,Q进行退出容器。
#docker run命令启动一个容器,并为它分配一个伪终端执行/bin/bash命令,用户可以在该伪终端与容器进行交互,其中:
-i #表示使用交互模式,始终保持输入流开放 -t #表示分配一个为终端,一般两个参数结合时使用-it,即可在容器中利用打开的伪终端进行交互操作。 --name #指定docker run命令启动的容器的名字,若无此选项,Docker将为容器随机分配一个名字。 -c #用于给运行在容器中的所有进程分配CPU的shares值,这是一个相对权重,实际的处理速度还与宿主机的CPU相关。 -m #用于限制为容器中所有进程分配的内存总量,以B、K、M、G为单位。 -v #用于挂载一个volume,可以用多个-v参数同时挂载多个volume。volume的格式为:[host-dir]:[container-dir]:[rw|ro] -p #用于将容器的端口暴露给宿主机的端口,其常用格式为hostPort:containerPort.通过端口暴露,可以让外部主机通过宿主机暴露的端口来访问容器内的应用。
设置Docker的ulimit参数
这是Docker在1.6版本退出的新功能,用户可以设置容器的ulimit参数。使用时加入--ulimit参数,后面输入ulimit资源的种类,如nofile,再确定软限制和硬件限制,用冒号隔开,具体示例如下:
#docker run --ulimit nofile=1024:1024 --rm centos ulimit -n
Docker中ulimit项常用的配置参数如下所示:
nofile #可以打开文件描述符的最大数量 core #最大内核文件的大小,以blocks为单位 cpu #指定CPU使用时间的上限,以秒为单位 data #进程最大数据块的大小,以Kbytes为单位 fsize #进程可以创建文件的最大值,以blocks为单位 locks #能同时保持的文件锁的最大数量 memlock #最大可加锁的内存大小,以Kbytes为单位 stack #分配线程堆栈的最大值,以Kbytes为单位 nproc #一个用户可创建的最大进程数 sigpending #最大待处理的信号数量 rss #用户可获得的最大物理内存 msgqueue #可以在消息队列中分配的最大字节 rtprio #非特权用户进程所能请求的实时优先级的上限 nice #设置进程优先级的nice值,nice值越高,优先级越低
#注意:对于root权限的用户来说,ulimit的效果并不能全部生效。
start方式启动已经存在的容器:
可以通过docker start/stop/restart命令来启动、停止和重启容器。
# docker start 82402b25999c #指定容器的ID号来启动容器

3.3 终止容器
可以使用docker stop来终止一个运行中的容器,命令的格式为docker stop[-t|--time[=10]]。它会首先向容器发送SIGTERM信号,等待一段时间后(默认为10秒),再发送SIGKILL信号终止容器。
此外当Docker容器中指定的应用终结时,容器也自动终止。另外可以使用docker stop来终止一个运行中的容器,如下面的命令:# docker stop 82402b25999c #通过指定容器的ID号来关闭容器
另外docker kill命令会直接发送SIGKILL信号来强行终止容器。如:# docker kill vol_from_host_no2 #指定容器名来kill掉
# docker ps -a -q #查看包括处于终止状态的容器的ID信息。
3.4 进入容器
在使用-d参数时,容器启动后会进入后台,用户无法看到容器中的信息。某些时候如果需要进入容器进行操作,有很多种方法,包括使用docker attach命令、docker exec命令。
docker attach命令:
docker attach命令对于开发者来说十分有用,它可以连接到正在运行的容器,观察该容器的运行情况,或与容器的主进程进行交互。使用方法如下:
# docker attach --help
用法:docker attach [OPTIONS] CONTAINER 选项: --detach-keys string #覆盖分离容器的键序列 --no-stdin #不要连接STDIN --sig-proxy #将所有接收到的信号代理到进程(默认为true)
# docker attach 82402b25999c #要按两下回车才能进入

#注意我上面按的是exit,不能exit,如果使用exit退出,那么在退出容器后会关闭容器
# docker attach 82402b25999c
You cannot attach to a stopped container, start it first
#如果要正常退出不关闭容器,请按Ctrl+P+Q进行退出容器。
#使用attach命令有时候并不方便。当多个窗口同时attach到同一个容器的时候,所有窗口都会同步显示。当某个窗口因命令阻塞时,其他窗口也无法执行操作了。要attach上去的容器必须正在运行,可以同时连接上同一个container来共享屏幕(与screen命令的attach类似)。
docker exec命令(SSH服务器的替代方案):
Docker自1.3版本起,提供了一个更加方便的工具exec,可以直接再容器内运行命令。这也是进入一个运行的容器的命令。
# docker exec --help
用法:docker exec [OPTIONS] CONTAINER COMMAND [ARG...] -d, --detach #分离模式:在后台运行命令 --detach-keys #覆盖分离容器的键序列 -i, --interactive #即使未连接,也要保持STDIN打开状态 --privileged #赋予命令扩展权限 -t, --tty #分配一个伪TTY -u, --user #用户名或UID(格式:<name | uid> [:<group | gid>])
# docker exec -it 82402b25999c /bin/bash #在容器82402b25999c中开启一个交互模式的终端。这种就是可以直接在容器中启动一个shell,然后就可以进入容器进行一系列操作了。
#当然还有nsenter方式也可以进入容器,还有ssh登录的方式,也就是说四种方式也可以进入容器。
#这个exec命令实际上可以解决大部分需要ssh进入容器的问题,提供与宿主机原有功能的结合,同样也可以解决诸如定时任务等问题。
删除容器:
docker rm命令用于删除处于终止状态的容器容器。
# docker rm --help
用法:docker rm [OPTIONS] CONTAINER [CONTAINER...] 选项: -f, --force #强制删除正在运行的容器(使用SIGKILL) -l, --link #删除指定的链接 -v, --volumes #删除与容器关联的卷
# docker rm 82402b25999c -f #不执行-f的时候不能删除一个正在运行的容器
导入和导出容器:
导出容器是指导出一个已经创建的容器快照到本地文件,不管此时这个容器是否处于运行状态,可以使用docker export命令。
# docker ps -a #可以用这个命令查看所有的容器包括运行和不在运行的。
# docker export 3e79547ccd2f -o test03_for_run.tar #将运行3e79547ccd2f 的容器的导出为test03_for_run.tar
# docker export 3e79547ccd2f > test03_for_run2.tar #当然这种方式也是可以的。

#这样可将这些文件传输到其他机器上,再其他机器上通过导入命令实现容器的迁移。
导入容器快照可以使用# docker import命令导入为镜像,下面是其用法:
# docker import --help
用法:docker import [OPTIONS] file|URL|- [REPOSITORY[:TAG]] 选项: -c, --change value #将Dockerfile指令应用于创建的映像(默认[]) -m, --message string #为导入的镜像设置提交消息
# docker import test03_for_run.tar test/ubuntu:v1 #将刚才的容器文件导入,名称为test/ubuntu:v1
# docker images #查看下镜像

#docker load命令来导入一个镜像文件到本地的镜像库,又可以使用docker import命令来导入一个容器快照到本地镜像库。这两者的区别在于容器快照文件将丢弃所有的历史记录和元数据信息(即仅保持容器当时的快照状态)而镜像存储文件将保存完整记录,体积也要大。此外,从容器快照文件导入时可以重新指定标签等元数据信息。
3.4 Docker 容器的迁移方法
Docker技术兴起的原动力之一,就是在不同的机器上创建无差别的应用运行环境,因此能够方便的实现“在某台机器上导出一个Docker容器并且在另外一台机器上导入”这一操作,就显得非常必要。上面的docker export和docker import命令实现了这一功能。当然由于Docker容器与镜像的天然联系性,容器持久化的操作也可以通过镜像的方式达到,这里可以用到的方法是docker save和docker load命令进行迁移。
docker export用于持久化容器,而docker save用于持久化镜像;将容器导出后再导入(exported-imported)后的容器会丢失所有的历史,而保存后再加载(save-loaded)的镜像则没有丢失历史和层,这意味着后者可以通过docker tag命令实现层回滚,而前者不行。
下面从实现角度来看一下export和save。
docker export命令导出容器:
Docker server接收相应的HTTP请求后,会通过daemon实例调用ContainerExport方法来进行具体的操作,这个过程的主要步骤如下:
根据命令行参数(容器名称)找到待导出的容器。
对该容器调用container.Export()函数导出容器中的所有数据,包括:挂载待导出容器的文件系统 ; 打包该容器basefs(即graphdriver上的挂载点)下的所有文件,以aufs为例,对于没有父镜像的容器,basefs对应的是aufs根目录下的diff路径,否则对应mnt路径 ; 返回打包文档的结果并卸载该容器。
将导出的数据回写到HTTP请求应答中。
docker save命令保存镜像:
根据待处理的容器数目发送不同格式的HTTP请求,分别为/images/get与/images/{name:.*}/get,前者对应数量为1的情况,后者对应数量大于1的情况。
Docker client发来的以上两种请求均由getImagesGetHandler进行处理,该Handler调用ImageExport函数进行具体的处理。
CmdImageExport函数负责查询到所有被要求export的镜像ID,并调用exportImage函数。如果用户没有指定镜像标签,则导出该repository下所有的镜像。另外,还会将被导出的repository的名称、标签及ID信息以JSON格式写入到名为repositories的文件中。最后执行文件压缩并写入到输出流。
exportImage函数是一个for循环,将对各个依赖的layer进行export工作,即从顶层layer、其父layer及至base layer。循环内的具体工作如下:
为每个被要求导出的镜像创建一个文件夹,以其镜像ID命名。
在该文件夹下创建VERSION文件,写入“1.0”。
在该文件夹下创建json文件,在该文件中写入镜像的元数据信息,包括镜像ID、父镜像ID、以及对应的Docker容器ID等。
在该文件夹下创建layer.tar文件,压缩镜像的filesystem。该过程的核心函数为TarLayer,对存储镜像的diff路径中的文件进行打包。
对该layer的父layer执行下一次循环。
