大数据(十五)Hadoop3.x+Hbase2.x部署
一晃数年过去,Hadoop到3.X版本,部署方式跟前面稍有不同,这里记录一下。
hadoop2.x可参照前面的文章,写的还是比较详细的:https://blog.51niux.com/?id=175
一、Hadoop 3.x部署
配置hosts和ssh打通,基本的java环境就不介绍了,参照之前的文章就行了。
1.1 先跟着官网简单了解一波
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
在非安全模式下配置Hadoop
Hadoop的Java配置有两种类型的重要配置文件:
只读默认配置:core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml 特定配置:etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml
此外,还可以通过etc/hadoop/hadoop-env.sh and etc/hadoop/yarn-env.sh进行环境配置。
要配置Hadoop集群,需要配置Hadoop守护程序执行的环境以及Hadoop守护程序的配置参数。
HDFS守护程序包括NameNode、SecondaryNameNode和DataNode。YARN守护程序包括ResourceManager、NodeManager和WebAppProxy。如果要使用MapReduce,那么MapReduceJob History Server也将运行。对于大型场景,它们通常在单独的主机上运行。
配置Hadoop守护程序的环境
使用etc/hadoop/hadoop-env.sh和可选的etc/hadomop/mapred-env.sh及etc/haduop/yarn-env_sh脚本对hadoop守护程序的进程环境进行特定配置。
可以使用下表中显示的配置选项配置各个守护程序:
| Daemon | Environment Variable |
|---|---|
| NameNode | HDFS_NAMENODE_OPTS |
| DataNode | HDFS_DATANODE_OPTS |
| Secondary NameNode | HDFS_SECONDARYNAMENODE_OPTS |
| ResourceManager | YARN_RESOURCEMANAGER_OPTS |
| NodeManager | YARN_NODEMANAGER_OPTS |
| WebAppProxy | YARN_PROXYSERVER_OPTS |
| Map Reduce Job History Server | MAPRED_HISTORYSERVER_OPTS |
例如,要将Namenode配置为使用parallelGC和4GB Java Heap,应该在hadoop-env.sh中添加以下语句:
export HDFS_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx4g"
参考etc/hadoop/hadoop-env.sh其他示例。可以自定义的其他有用配置参数包括:
HADOOP_PID_DIR:存储守护程序进程id文件的目录 HADOOP_LOG_DIR:存储守护程序日志文件的目录。如果日志文件不存在,则会自动创建它们。 HADOOP_HEAPSIZE_MAX:用于Java堆大小的最大内存量。这里也支持JVM支持的单元。如果不存在单元,则假定数字以兆字节为单位。 默认情况下,Hadoop将让JVM决定使用多少。可以使用上面列出的相应_OPTS变量按守护进程覆盖此值。 例如,设置HADOOP_HEAPSIZE_MAX=1g and HADOOP_NAMENODE_OPTS="-Xmx5g"将为NAMENODE配置5GBheap。
在大多数情况下,应该指定HADOOP_PID_DIR和HADOOP_LOG_DIR目录,以便只有要运行HADOOP守护程序的用户才能写入这些目录。否则,可能会发生symlink attack(符号链接攻击)。
在系统范围的shell环境配置中配置HADOOP_HOME也是一种传统做法。例如,/etc/profile.d中:
HADOOP_HOME=/path/to/hadoop export HADOOP_HOME
配置Hadoop守护程序
配置文件中指定的重要参数:
etc/hadoop/core-site.xml
| Parameter | Value | Notes |
|---|---|---|
| fs.defaultFS | NameNode URI | hdfs://host:port/ |
| io.file.buffer.size | 131072 | 读写缓存区大小 |
etc/hadoop/hdfs-site.xml
NameNode的配置:
| Parameter | Value | Notes |
|---|---|---|
| dfs.namenode.name.dir | NameNode持久存储命名空间和事务日志的本地文件系统上的路径。 | 多个目录逗号隔开启到冗余的作用 |
| dfs.hosts / dfs.hosts.exclude | permitted/excluded DataNodes的列表 | 如有必要,使用这些文件控制允许的数据节点列表。 |
| dfs.blocksize | 268435456 | 对于大型文件系统,HDFS块大小为256MB。 |
| dfs.namenode.handler.count | 100 | 更多NameNode服务器线程来处理来自大量DataNode的RPC。 |
DataNode的配置:
| Parameter | Value | Notes |
|---|---|---|
| dfs.datanode.data.dir | DataNode应在其中存储其块的本地文件系统上的路径的逗号分隔列表。 | 逗号分割的话多个数据会存储到不同的目录中 |
etc/hadoop/yarn-site.xml
ResourceManager和NodeManager的配置:
| Parameter | Value | Notes |
|---|---|---|
| yarn.acl.enable | true / false | Enable ACLs? Defaults to false. |
| yarn.admin.acl | Admin ACL | ACL用于设置群集上的管理员。ACL用于逗号分隔的用户空格逗号分隔的组。默认为特殊值*,表示任何人。 |
| yarn.log-aggregation-enable | false | 用于启用或禁用日志聚合的配置 |
ResourceManager的配置:
| Parameter | Value | Notes |
|---|---|---|
| yarn.resourcemanager.address | ResourceManager host:port(提交jobs的端口) | host:port如何设置将覆盖yarn.resourcemanager.hostname中设置的hostname |
| yarn.resourcemanager.scheduler.address | ResourceManager host:port(ApplicationMasters与Scheduler对话以获取资源的端口) | 同上 |
| yarn.resourcemanager.resource-tracker.address | ResourceManager host:port(NodeManager的端口) | 同上 |
| yarn.resourcemanager.admin.address | ResourceManager host:port(管理命令的端口) | 同上 |
| yarn.resourcemanager.webapp.address | ResourceManager web-ui host:port. | 同上 |
| yarn.resourcemanager.hostname | ResourceManager host. | ResourceManager寻址地址 |
| yarn.resourcemanager.scheduler.class | ResourceManager Scheduler class. | CapacityScheduler(推荐)、FairScheduleer(也推荐)或FifoScheduler。 |
| yarn.scheduler.minimum-allocation-mb | 在Resource Manager上分配给每个容器请求的最小内存限制。 | In MBs |
| yarn.scheduler.maximum-allocation-mb | 在Resource Manager上分配给每个容器请求的最大内存限制。 | In MBs |
| yarn.resourcemanager.nodes.include-path / yarn.resourcemanager.nodes.exclude-path | 允许/排除的NodeManager列表。 | 如有必要,使用这些文件控制允许的NodeManager列表。 |
NodeManager的设置:
| Parameter | Value | Notes |
|---|---|---|
| yarn.nodemanager.resource.memory-mb | 给定NodeManager的可用物理内存(MB) | 定义NodeManager上可用于运行容器的总可用资源 |
| yarn.nodemanager.vmem-pmem-ratio | 任务的虚拟内存使用量可能超过物理内存的最大比率 | 每个任务的虚拟内存使用量可能会超过其物理内存限制的此比率。NodeManager上的任务使用的虚拟内存总量可能会超过其物理内存使用量的此比率。 |
| yarn.nodemanager.local-dirs | 写入数据的本地文件系统上以逗号分隔的路径列表。 | 多路径有助于分散磁盘i/o。 |
| yarn.nodemanager.log-dirs | 写入日志的本地文件系统上以逗号分隔的路径列表。 | 多路径有助于分散磁盘i/o。 |
| yarn.nodemanager.log.retain-seconds | 10800 | NodeManager上保留日志文件的默认时间(秒)仅在禁用日志聚合时适用。 |
| yarn.nodemanager.remote-app-log-dir | /logs | 应用程序完成时将应用程序日志移动到的HDFS目录。需要设置适当的权限。仅在启用日志聚合时适用。 |
| yarn.nodemanager.remote-app-log-dir-suffix | logs | 附加到远程日志目录的后缀。日志将聚合到${yarn.nodemanager.remote-app-log-dir}/${user}/$}thisParam}仅在启用日志聚合时适用。 |
| yarn.nodemanager.aux-services | mapreduce_shuffle | 需要为Map Reduce应用程序设置的Shuffle service 。 |
| yarn.nodemanager.env-whitelist | containers从NodeManager继承的环境属性 | 对于mapreduce应用程序,除了默认值之外,还应添加HADOOP_MAPRED_HOME。属性值应为JAVA_HOME、HADOOP_COMMON_HOME,HADOOP_HDFS_HOME和HADOOP_CONF_DIR、CLASSPATH_PREPEND_DISTCACHE、HADOOP和YARN_HOME以及HADOOP、HOME、PATH、LANG、TZ、HADOOP和MAPRED_HOME |
历史服务器的配置(需要移动到其他位置):
| Parameter | Value | Notes |
|---|---|---|
| yarn.log-aggregation.retain-seconds | -1 | 在删除聚合日志之前保留多长时间-1禁用。请小心,将其设置得太小,将向name node发送垃圾邮件。 |
| yarn.log-aggregation.retain-check-interval-seconds | -1 | 聚合日志保留检查之间的时间间隔。如果设置为0或负值,则该值将计算为聚合日志保留时间的十分之一。请小心,将其设置得太小,将向name node发送垃圾邮件。 |
etc/hadoop/mapred-site.xml
MapReduce应用程序的配置:
| Parameter | Value | Notes |
|---|---|---|
| mapreduce.framework.name | yarn | 执行框架 |
| mapreduce.map.memory.mb | 1536 | 一个 Map Task 可使用的内存上限(单位:MB) |
| mapreduce.map.java.opts | -Xmx1024M | maps子jvm的head大小 |
| mapreduce.reduce.memory.mb | 3072 | 一个 Reduce Task 可使用的资源上限(单位:MB) |
| mapreduce.reduce.java.opts | -Xmx2560M | Reduce Task 的 JVM 参数 |
| mapreduce.task.io.sort.mb | 512 | sort排序时的内存限制 |
| mapreduce.task.io.sort.factor | 100 | More streams merged at once while sorting files. |
| mapreduce.reduce.shuffle.parallelcopies | 50 | 运行的并行副本数量越大,从大量映射中获取输出的次数就越少。 |
MapReduce JobHistory服务器的配置
| Parameter | Value | Notes |
|---|---|---|
| mapreduce.jobhistory.address | MapReduce JobHistory Server host:port | Default port is 10020. |
| mapreduce.jobhistory.webapp.address | MapReduce JobHistory Server Web UI host:port | Default port is 19888. |
| mapreduce.jobhistory.intermediate-done-dir | /mr-history/tmp | MapReduce作业写入历史文件的目录。 |
| mapreduce.jobhistory.done-dir | /mr-history/done | MR JobHistory Server管理历史文件的目录。 |
监测NodeManager的运行状况
监视Hadoop NodeManager的运行状况提供了一种机制,管理员可以通过该机制配置NodeManager定期运行管理员提供的脚本,以确定节点是否正常。
管理员可以通过在脚本中执行他们选择的任何检查来确定节点是否处于健康状态。如果脚本检测到节点处于不健康状态,则必须将一行打印到以字符串ERROR开头的标准输出。NodeManager定期生成脚本并检查其输出。如果脚本的输出包含字符串ERROR(如上所述),则节点的状态将报告为不正常,并且该节点将由ResourceManager列出为黑色。不会向此节点分配更多任务。但是,NodeManager会继续运行脚本,因此如果节点再次恢复健康,它将自动从ResourceManager上的黑名单节点中删除。节点的运行状况以及脚本的输出(如果不正常)可在ResourceManager web界面中供管理员使用。自节点正常运行以来的时间也显示在web界面上。
以下参数可用于控制etc/hadoop/yarn-site.xml中的节点健康监视脚本。
| Parameter | Value | Notes |
|---|---|---|
| yarn.nodemanager.health-checker.script.path | Node health script | 用于检查节点运行状况的脚本。 |
| yarn.nodemanager.health-checker.script.opts | Node health script options | 用于检查节点运行状况的脚本的选项。 |
| yarn.nodemanager.health-checker.interval-ms | Node health script interval | 检查运行状况脚本的时间间隔。 |
| yarn.nodemanager.health-checker.script.timeout-ms | Node health script timeout interval | 运行状况脚本执行超时时间。 |
如果只有部分本地磁盘损坏,健康检查程序脚本不应该给出ERROR。NodeManager能够根据配置属性yarn.NodeManager.disk-health-checker设置的值,定期检查本地磁盘的健康状况(特别是检查NodeManager本地目录和NodeManager-log目录),并在达到坏目录数阈值后检查。最小健康磁盘数,则整个节点被标记为不健康,并且此信息也会发送到资源管理器。启动磁盘已被磁盘扫描,或者启动磁盘中的故障由运行状况检查程序脚本识别。
Slaves File
在etc/hadoop/workers文件中列出所有工作主机名或IP地址,每行一个。Helper脚本(如下所述)将使用etc/hadoop/workers文件在多台主机上同时运行命令。它不用于任何基于Java的Hadoop配置。为了使用此功能,必须为用于运行Hadoop的帐户建立ssh信任(通过无密码ssh或其他方式,如Kerberos)。
Hadoop Rack Awareness(hadoop机架感知)
许多Hadoop组件都支持机架,并利用网络拓扑提高性能和安全性。Hadoop守护程序通过调用管理员配置的模块来获取集群中工作线程的机架信息。强烈建议在启动HDFS之前配置机架感知。
Logging
Hadoop通过Apache Commons Logging框架使用Apache log4j进行日志记录。编辑etc/hadoop/log4j。属性文件来定制Hadoop守护程序的日志配置(日志格式等)。
操作Hadoop群集
完成所有必要的配置后,将文件分发到所有计算机上的HADOOP_CONF_DIR目录。这应该是所有计算机上的同一目录。通常,建议HDFS和YARN作为单独的用户运行。
Hadoop Startup
要启动Hadoop集群,需要同时启动HDFS和YARN集群。
第一次启动HDFS时,必须对其进行格式化。将新的分布式文件系统格式化为hdfs:
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format
在指定为HDFS的节点上,使用以下命令启动HDFS NameNode:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode
在每个指定节点上使用以下命令启动HDFS DataNode作为HDFS:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start datanode
如果配置了etc/hadoop/workers和ssh可信访问,则可以使用实用程序脚本启动所有HDFS进程。作为hdfs:
[hdfs]$ $HADOOP_HOME/sbin/start-dfs.sh
使用以下命令启动YARN,在指定的ResourceManager上作为YARN运行:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon start resourcemanager
运行脚本以在每个指定主机上启动NodeManager作为yarn:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon start nodemanager
启动独立的WebAppProxy服务器。作为yarn在WebAppProxy服务器上运行。如果使用多台服务器进行负载平衡,则应在每台服务器上运行:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon start proxyserver
如果配置了etc/hadoop/workers和ssh可信访问,则可以使用实用程序脚本启动所有YARN进程。As yarn:
[yarn]$ $HADOOP_HOME/sbin/start-yarn.sh
使用以下命令启动MapReduce JobHistory Server,在指定的映射服务器上运行:
[mapred]$ $HADOOP_HOME/bin/mapred --daemon start historyserver
Hadoop Shutdown
使用以下命令停止NameNode,在指定的NameNode上作为hdfs运行:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon stop namenode
运行脚本以将DataNode作为hdfs停止:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon stop datanode
如果配置了etc/hadoop/workers和ssh可信访问,则可以使用实用程序脚本停止所有HDFS进程。as hdfs:
[hdfs]$ $HADOOP_HOME/sbin/stop-dfs.sh
使用以下命令停止ResourceManager,在指定的ResourceManager上运行yarn:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon stop resourcemanager
Run a script to stop a NodeManager on a worker as yarn:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon stop nodemanager
如果配置了etc/hadoop/workers和ssh可信访问,则可以使用实用程序脚本停止所有YARN进程。As yarn:
[yarn]$ $HADOOP_HOME/sbin/stop-yarn.sh
停止WebAppProxy服务器。作为yarn在WebAppProxy服务器上运行。如果使用多台服务器进行负载平衡,则应在每台服务器上运行:
[yarn]$ $HADOOP_HOME/bin/yarn stop proxyserver
使用以下命令停止MapReduce JobHistory Server,在指定的映射服务器上运行:
[mapred]$ $HADOOP_HOME/bin/mapred --daemon stop historyserver
Web界面
Hadoop集群启动并运行后,检查组件的web ui,如下所述:
| Daemon | Web Interface | Notes |
|---|---|---|
| NameNode | http://nn_host:port/ | Default HTTP port is 9870. |
| ResourceManager | http://rm_host:port/ | Default HTTP port is 8088. |
| MapReduce JobHistory Server | http://jhs_host:port/ | Default HTTP port is 19888. |
博文来自:www.51niux.com
1.2 Hadoop集群部署
机器列表
| hadoop-master01 | hadoop-master02 | hadoop-node01 | hadoop-node02 | hadoop-node03 |
| zookeeper | zookeeper | zookeeper | zookeeper | zookeeper |
| Namenode | Namenode | |||
| JournalNode | JournalNode | JournalNode | JournalNode | JournalNode |
| ResourceManager | ResourceManager | DateNode | DateNode | DateNode |
| ZKFailoverController | ZKFailoverController | NodeManager | NodeManager | NodeManager |
配置环境变量:
#cat /etc/profile #我把运行目录都安装到了/opt/soft,按自己的习惯来,设置了hadoopy用户,直接给/opt/soft目录hadoop用户授权
export JAVA_HOME=/opt/soft/java export CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib export ZOOKEEPER_HOME=/opt/soft/apache-zookeeper export HADOOP_HOME=/opt/soft/hadoop export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/sbin
#master两个节点可以无密码SSH到其他机器自行配置。我这里使用的是apache-zookeeper-3.8.0-bin.tar.gz和hadoop-3.3.4.tar.gz
修改文件描述符:
# cat /etc/security/limits.conf
* soft nofile 1000000 * hard nofile 1000000
# cat /etc/security/limits.d/20-nproc.conf
* soft nproc 1000000 root soft nproc unlimited
运行zookeeper服务
#cat /opt/soft/apache-zookeeper/conf/zoo.cfg #特别注意端口号后面不要有空格省的启动报错
tickTime=2000 initLimit=10 syncLimit=5 clientPort=2181 dataDir=/opt/soft/apache-zookeeper/data dataLogDir=/opt/soft/apache-zookeeper/datalog server.1=hadoop-master01:2888:3888 server.2=hadoop-master02:2888:3888 server.3=hadoop-node01:2888:3888 server.4=hadoop-node02:2888:3888 server.5=hadoop-node03:2888:3888
#mkdir /opt/soft/apache-zookeeper/{data..datalog}
#echo 1 >/opt/soft/apache-zookeeper/data/myid #把zookeeper目录拷贝到其他机器之后,按server上面的id依次echo
# su - hadoop -c "zkServer.sh start" #所有机器都启动zk服务
# jps
18823 QuorumPeerMain
hadoop配置
hadoop-env.sh
# cat /opt/soft/hadoop/etc/hadoop/hadoop-env.sh
#指定JAVA_HOME export JAVA_HOME=/opt/soft/java #指定hadoop用户,hadoop3.x之后必须配置 export HDFS_NAMENODE_USER=hadoop export HDFS_DATANODE_USER=hadoop export HDFS_ZKFC_USER=hadoop export HDFS_JOURNALNODE_USER=hadoop export YARN_RESOURCEMANAGER_USER=hadoop export YARN_NODEMANAGER_USER=hadoop #对启动内存的一些调整 export HADOOP_HEAPSIZE=4096 #给HADOOP后台进程用的内存大小,默认是1000M,大型集群一般设置2000M或以上,开发环境中设置500M足够了。 export HADOOP_NAMENODE_INIT_HEAPSIZE="10240" export HADOOP_PORTMAP_OPTS="-Xmx2048m $HADOOP_PORTMAP_OPTS" #内存调优从512调到2048 export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS" #设定hadoop提交程序时client的jvm大小,从512跳到2048
core-site.xml
官方文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
# cat /opt/soft/hadoop/etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!--为hadoop客户端配置HA集群的URI作为默认路径。这里是使用"mycluster"作为名称服务ID--> <property> <name>fs.default.name</name> <value>hdfs://mycluster</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <!--指定所有用户可以访问--> <property> <name>hadoop.proxyuser.hduser.hosts</name> <value>*</value> </property> <!--指定所有用户组可以访问--> <property> <name>hadoop.proxyuser.hduser.groups</name> <value>*</value> </property> <property> <name>io.compression.codecs </name> <value>org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.SnappyCodec</value> </property> <!--zk&ha --> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>hadoop-master01:2181,hadoop-master02:2181,hadoop-node01:2181,hadoop-node02:2181,hadoop-node03:2181</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> <description>Number of minutes between trash checkpoints. If zero, the trash feature is disabled. </description> </property> </configuration>
hdfs-site.xml
官方文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
# cat /opt/soft/hadoop/etc/hadoop/hdfs-site.xml
<configuration> <!--既然已经有了journalnode同步edit.log这里就一个目录就可以了--> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///opt/hadoop/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.block.size</name> <value>67108864</value> </property> <property> <name>dfs.balance.bandwidthPerSec</name> <value>104857600</value> </property> <property> <name>dfs.datanode.max.transfer.threads</name> <value>4096</value> </property> <property> <name>dfs.hosts.exclude</name> <value>/opt/soft/hadoop/etc/hadoop/excludes</value> </property> <!-- ha&zk --> <!--命名空间的逻辑名称。如果使用HDFS Federation,可以配置多个命名空间的名称,使用逗号分开即可。--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--命名空间中所有NameNode的唯一标示名称。可以配置多个,使用逗号分隔。该名称是可以让DataNode知道每个集群的所有NameNode。当前,每个集群最多只能配置两个NameNode。--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--namenode监听的RPC地址--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop-master01:8020</value> </property> <!--namenode监听的http地址--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop-master01:50070</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop-master02:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop-master02:50070</value> </property> <!-- 这是NameNode读写JNs组的uri。通过这个uri,NameNodes可以读写edit log内容。URI的格式"qjournal://host1:port1;host2:port2;host3:port3/journalId"。 这里的host1、host2、host3指的是Journal Node的地址,这里必须是奇数个,至少3个;其中journalId是集群的唯一标识符,对于多个联邦命名空间,也使用同一个journalId。--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop-master01:8485;hadoop-master02:8485;hadoop-node01:8485;hadoop-node02:8485;hadoop-node03:8485/mycluster</value> </property> <!--HA模式下的edit log文件会同时写入多个JournalNodes节点的dfs.journalnode.edits.dir路径下--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoop/data/journal</value> </property> <!--HDFS客户端连接到Active NameNode的一个java类--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--配置active namenode出错时的处理类。当active namenode出错时,一般需要关闭该进程。处理方式可以是ssh也可以是shell。这个机制在hadoop中称为fencing(包括ssh发送kill指令,执行自定义脚本两道保障) 如果配置为sshfence,当主NameNode异常时,使用ssh登录到主NameNode,然后使用fuser将主NameNode杀死,因此需要确保所有NameNode上可以使用fuser。用来保证同一时刻只有一个主NameNode,以防止脑裂。--> <property> <name>dfs.ha.fencing.methods</name> <!--当master宕机的时候单纯的sshfence会一直去尝试关闭master的namenode服务,所以会一直无法完成自动切换。 使用/bin/true是因为此处无需shell真正的去执行kill namenode的任务,因为如果active node可连通,已经被sshfence隔离,如果active node不可连通则由此shell执行--> <value> sshfence shell(/bin/true) </value> </property> <!--使用sshfence隔离机制时需要ssh免登陆,指定私钥--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!--dfs.ha.automatic-failover.enabled 为 true (即自动故障状态切换),默认是false也就是需要手工切换--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
workers
# cat /opt/soft/hadoop/etc/hadoop/workers
hadoop-node01 hadoop-node02 hadoop-node03
yarn-site.xml
官网文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
# cat /opt/soft/hadoop/etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> <!-- 指定RM的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定RM的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop-master01</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop-master02</value> </property> <property> <name>yarn.resourcemanager.address.rm1</name> <value>hadoop-master01:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>hadoop-master01:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>hadoop-master01:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>hadoop-master01:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>hadoop-master01:8088</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>hadoop-master02:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>hadoop-master02:8031</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>hadoop-master02:8032</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>hadoop-master02:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>hadoop-master02:8088</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4092</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>2</value> </property> <property> <name>yarn.application.classpath</name> <value>/opt/soft/hadoop/etc/hadoop:/opt/soft/hadoop/share/hadoop/common/lib/*:/opt/soft/hadoop/share/hadoop/common/*:/opt/soft/hadoop/share/hadoop/hdfs:/opt/soft/hadoop/share/hadoop/hdfs/lib/*:/opt/soft/hadoop/share/hadoop/hdfs/*:/opt/soft/hadoop/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop/share/hadoop/mapreduce/*:/opt/soft/hadoop/share/hadoop/yarn:/opt/soft/hadoop/share/hadoop/yarn/lib/*:/opt/soft/hadoop/share/hadoop/yarn/*</value> </property> <!--防止MapReduce踩坑:Aggregation is not enabled. Try the nodemanager at IP:HOST --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop-master01:2181,hadoop-master02:2181,hadoop-node01:2181,hadoop-node02:2181,hadoop-node03:2181</value> </property> </configuration>
mapred-site.xml
# cat /opt/soft/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-master01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master01:19888</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>BLOCK</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.DefaultCodec</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx1024m</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/soft/hadoop/etc/hadoop:/opt/soft/hadoop/share/hadoop/common/lib/*:/opt/soft/hadoop/share/hadoop/common/*:/opt/soft/hadoop/share/hadoop/hdfs:/opt/soft/hadoop/share/hadoop/hdfs/lib/*:/opt/soft/hadoop/share/hadoop
/hdfs/*:/opt/soft/hadoop/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop/share/hadoop/mapreduce/*:/opt/soft/hadoop/share/hadoop/yarn:/opt/soft/hadoop/share/hadoop/yarn/lib/*:/opt/soft/hadoop/share/hadoop/yarn/*</value>
</property>
</configuration>启动hadoop
#mkdir /opt/hadoop && chown hadoop:hadoop /opt/hadoop #每个节点执行
#在master节点把hadoop目录同步到其他节点,如:# rsync -avz /opt/soft/hadoop hadoop-master02:/opt/soft/ >/dev/null
启动journalnode(每台机器都执行,只需第一次)
$ /opt/soft/hadoop/sbin/hadoop-daemon.sh start journalnode
在hadoop-master01节点格式化namenode并启动(只需第一次)
$ /opt/soft/hadoop/bin/hdfs namenode -format
$ /opt/soft/hadoop/sbin/hadoop-daemon.sh start namenode
在hadoop-master02节点同步数据并启动namenode(只需第一次)
$ /opt/soft/hadoop/bin/hdfs namenode -bootstrapStandby
$ /opt/soft/hadoop/sbin/hadoop-daemon.sh start namenode
初始化zkfc服务(只需第一次)
#再其中一个namenode上执行,仅在第一次的时候执行此操作
$ /opt/soft/hadoop/bin/hdfs zkfc -formatZK
重新启动服务
$ /opt/soft/hadoop/sbin/stop-all.sh #在master节点上面执行
$ /opt/soft/hadoop/sbin/start-all.sh #启动所有服务
Starting namenodes on [hadoop-master01 hadoop-master02] Starting datanodes Starting journal nodes [hadoop-master01 hadoop-node01 hadoop-master02 hadoop-node02 hadoop-node03] Starting ZK Failover Controllers on NN hosts [hadoop-master01 hadoop-master02] Starting resourcemanagers on [ hadoop-master01 hadoop-master02] Starting nodemanagers
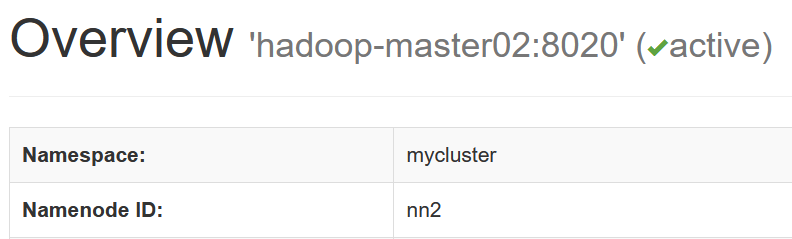
博文来自:www.51niux.com
#下面模拟下自动切换,把nn2网络隔离一下
$ tail -f /opt/soft/hadoop/logs/hadoop-hadoop-zkfc-hadoop-master01.log #可以看日志切换

#由上图可以看出zk上面的master信息也发送了变化
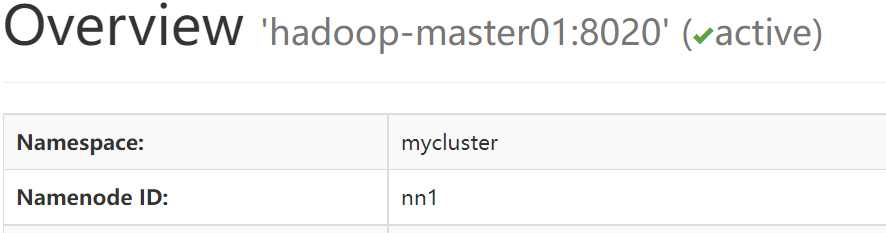
#上图可以看到master节点也发生了切换
#zkfc服务节点来负责进行ha的自动切换,所以要有两个master节点的ssh权限。
二、Hbase2.X集群部署
比较详细的部署文档可参考:https://blog.51niux.com/?id=187
官网文档:https://hbase.apache.org/book.html#_preface
官网API文档:https://hbase.apache.org/2.5/apidocs/index.html
2.1 官网文档配置了解(可略过)
配置文件:
Apache HBase使用与Apache Hadoop相同的配置系统。所有配置文件都位于conf/目录中,需要为集群中的每个节点保持同步。HBase配置文件说明:
backup-masters:默认情况下不存在。一个纯文本文件,列出Master应在其上启动备份Master进程的主机,每行一个host。
hadoop-metrics2-hbase.properties: 用于连接HBase Hadoop的Metrics2框架。
hbase-env.cmd and hbase-env.sh: 用于为HBase设置工作环境,包括Java、Java选项和其他环境变量。
hbase-policy.xml: RPC服务器用于对客户端请求进行授权决策的默认策略配置文件。仅在启用HBase安全性时使用。
hbase-site.xml: HBase主要配置文件。此文件指定覆盖HBase默认配置的配置选项。可以在hbase-common/src/main/resources/hbase-default.xml中查看(但不要编辑)默认配置文件。还可以在HBase Web UI的HBase configuration选项卡中查看集群的整个有效配置(默认值和覆盖)。
log4j2.xml:通过log4j2记录HBase的配置文件。
regionservers:包含应在HBase集群中运行RegionServer的主机列表的纯文本文件。默认情况下,此文件包含单个条目localhost。它应该包含主机名或IP地址的列表,每行一个。
基本先决条件:
https://hbase.apache.org/book.html#basic.prerequisites #一句话用jdk1.8就完事了,新搭hadoop使用3.3+就完事了,ZK最低3.x
HDFS DataNode在任何时候都有一个文件数量的上限。在加载之前,确保已经配置了Hadoop的conf/hdfs-site.xml,设置dfs.datanode.max.transfer.threads至少为以下值:
<property> <name>dfs.datanode.max.transfer.threads</name> <value>4096</value> </property>
确保在完成上述配置后重新启动HDFS。没有这种配置会导致奇怪的故障。
HBase默认配置
hbase.tmp.dir: 本地文件系统上的临时目录,java.io.tmpdir是/tmp,应该更换永久目录。默认值是${java.io.tmpdir}/hbase-${user.name}
hbase.rootdir:HBase保存在该目录中,默认值是${hbase.tmp.dir}/hbase
hbase.cluster.distributed:群集将处于的模式。false为单机模式,true为分布式模式。默认值是false。
hbase.zookeeper.quorum:以逗号隔开的ZooKeeper服务列表,默认值是127.0.0.1
zookeeper.recovery.retry.maxsleeptime:zookeeper的重试时间单位是毫秒,默认值是60000。
hbase.local.dir:用作本地存储的本地文件系统上的目录,默认值是${hbase.tmp.dir}/local/
hbase.master.port:HBase Master的监听端口,默认值是16000
hbase.master.info.port:HBase Master web UI的端口。如果不希望运行UI实例,请设置为-1。默认值是16010.
hbase.master.info.bindAddress:HBase Master web UI的bind address,默认值是0.0.0.0
hbase.master.logcleaner.plugins:日志清理插件。默认值是 org.apache.hadoop.hbase.master.cleaner.TimeToLiveLogCleaner,org.apache.hadoop.hbase.master.cleaner.TimeToLiveProcedureWALCleaner,org.apache.hadoop.hbase.master.cleaner.TimeToLiveMasterLocalStoreWALCleaner。
hbase.master.logcleaner.ttl: WAL在存档({hbase.rootdir}/oldWALs)目录中保留多长时间,之后将由主线程进行清理。该值以毫秒为单位。默认值600000。
hbase.master.hfilecleaner.plugins:由HFileCleaner服务调用的BaseHFileCleanerDelegate的逗号分隔列表。这些HFiles清洁器是按顺序调用的,默认值 org.apache.hadoop.hbase.master.cleaner.TimeToLiveHFileCleaner,org.apache.hadoop.hbase.master.cleaner.TimeToLiveMasterLocalStoreHFileCleaner
hbase.master.infoserver.redirect:Master是否侦听Master web UI端口(hbase.Master.info.port)并将请求重定向到Master和RegionServer共享的web UI server。默认值是true。
hbase.master.fileSplitTimeout:Splitting a region,在中止尝试之前等待file-splitting步骤的时间。默认是600000毫秒
hbase.regionserver.port:HBase RegionServer绑定到的端口。默认值是16020
hbase.regionserver.info.port:如果不希望RegionServer UI运行,则HBase RegionServer web UI的端口设置为-1。默认值是16030
hbase.regionserver.info.bindAddress:HBase RegionServer web UI的地址,默认值是0.0.0.0
hbase.regionserver.info.port.auto:Master或RegionServer UI是否应搜索要绑定到的端口。默认值是false.
hbase.regionserver.handler.count:RegionServers上启动的RPC侦听器实例计数。默认值是30.
hbase.ipc.server.callqueue.handler.factor:call queues的数量,值1表示处理程序共享一个队列,0是处理程序独享队列。默认值是0.1。
hbase.ipc.server.callqueue.read.ratio:将呼叫队列拆分为读队列和写队列(0-1之间)。0为不拆分队列,默认值是0
hbase.ipc.server.callqueue.scan.ratio:给定读取调用队列的数量,由调用队列总数乘以callqueue.read计算得出。默认值是0
hbase.regionserver.msginterval:从RegionServer到Master的消息间隔(毫秒)。默认值是3000
hbase.regionserver.logroll.period:无论提交日志有多少次编辑,我们都将滚动提交日志的时间段。默认值是3600000
hbase.regionserver.logroll.errors.tolerated:触发服务器中止之前,我们允许的连续WAL关闭错误数。默认值是2
hbase.regionserver.hlog.reader.impl:WAL文件读取器实现。默认org.apache.hadoop.hbase.regionserver.wal.ProtobufLogReader
hbase.regionserver.hlog.writer.impl:WAL文件编写器实现。默认org.apache.hadoop.hbase.regionserver.wal.ProtobufLogWriter
hbase.regionserver.global.memstore.size:在阻止新更新并强制刷新之前,区域服务器中所有内存存储的最大大小。默认为堆的40%(0.4)。默认值是none
不行太多了翻译不过来,详细的参考:https://hbase.apache.org/book.html#config.files
2.2 Hbase分布式集群部署
下载并配置环境变量
# wget https://dlcdn.apache.org/hbase/2.5.0/hbase-2.5.0-bin.tar.gz
# tar xf hbase-2.5.0-bin.tar.gz
# mv hbase-2.5.0 hbase
# chown -R hadoop:hadoop hbase
# vim /etc/profile
export ZOOKEEPER_HOME=/opt/soft/apache-zookeeper export HADOOP_HOME=/opt/soft/hadoop export HBASE_HOME=/opt/soft/hbase export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin
# source /etc/profile
# vim /opt/soft/hbase/conf/hbase-env.sh
export JAVA_HOME=/opt/soft/java #默认是使用自带的ZK,我们这里用外部zk所以改成false,自带的zk进程是HQuorumPeer export HBASE_MANAGES_ZK=false #让HBase读取到HDFS的配置有三种方式: #HBase会根据HDFS的客户端配置来做一些策略调整,比如HBase默认存储的备份数是3,当你把dfs.replication数设置为5的时候,如果HBase能读到这个配置,它会自动把备份数提高到5。 #1.把HADOOP_CONF_DIR添加到HBASE_CLASSPATH中, #2.把HDFS的配置文件复制一份到HBase的conf文件夹下,或者直接建一个hdfs-site.xml的软链接到hbase/conf下, #3.把HDFS的几个配置项直接写到hbase-site.xml文件里面去。 export HBASE_CLASSPATH=/opt/soft/hadoop/etc/hadoop export HBASE_LOG_DIR=/opt/hbase/logs #解决hadoop和hbase的jar包冲突问题,让hbase不扫描hadoop的jar包 export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
#mkdir /opt/hbase && chown hadoop:hadoop /opt/hbase #每个节点都执行
# vim /opt/soft/hbase/conf/regionservers
hadoop-node01 hadoop-node02 hadoop-node03
修改hbase-site.xml
#vim /opt/soft/hbase/conf/hbase-site.xml
<configuration> <!--HBase会通过集群id,连接ZooKeeper来查询namenode的情况--> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> </property> <!--分布式开关--> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!--ZooKeeper集群配置--> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>zookeeper.session.timeout</name> <value>120000</value> </property> <property> <name>hbase.zookeeper.property.tickTime</name> <value>6000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop-master01,hadoop-master02,hadoop-node01,hadoop-node02,hadoop-node03</value> </property> <property> <name>hbase.tmp.dir</name> <value>/opt/hbase/tmp</value> </property> </configuration>
#把/opt/soft/hbase目录同步到其他机器
启动相关服务:
$ /opt/soft/hbase/bin/start-hbase.sh #在hadoop-master01节点执行启动hbase服务
$ /opt/soft/hbase/bin/hbase-daemon.sh start master #在hadoop-master02节点上面再启动一个hmaster服务
#Master关掉,也可以从HBase中读取数据和写入数据,只是不能建表或者修改表。客户端读取数据的时候只是跟ZooKeeper和RegionServer交互。
#用master节点的webui端口16010端口浏览器访问一下(也可以试下将一台master节点网络隔离是不是master节点就发生了切换):
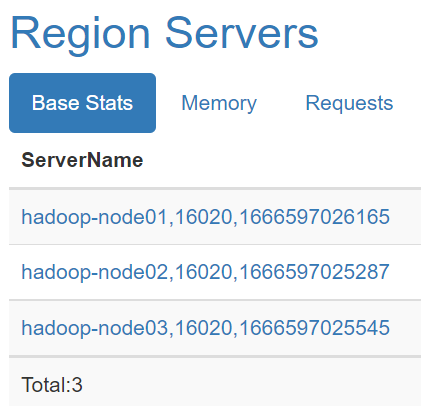
博文来自:www.51niux.com
三、简单了解下Hadoop和Hbase的监控
#除了监控这些机器基础的性能指标外,还可以调用一些服务的信息接口获取信息,另外也可以通过jmx接口。
如:http://hbase的master节点:16010/jmx
http://hadoop的master节点:50070/jmx
hadoop的指标项:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/Metrics.html
Hbase的jmx监控:https://hbase.apache.org/metrics.html
hbase的指标详细信息:https://hbase.apache.org/book.html#hbase_metrics
3.1 JMX配置
$ vim /opt/soft/hadoop/etc/hadoop/yarn-env.sh
export YARN_RESOURCEMANAGER_OPTS="$YARN_RESOURCEMANAGER_OPTS -javaagent:/opt/soft/jmx_prometheus_javaagent-0.17.2.jar=30001:/opt/soft/jmx_exporte r/prometheus_config.yml" export YARN_NODEMANAGER_OPTS="$YARN_NODEMANAGER_OPTS -javaagent:/opt/soft/jmx_prometheus_javaagent-0.17.2.jar=30002:/opt/soft/jmx_exporter/promet heus_config.yml"
$ vim /opt/soft/hadoop/etc/hadoop/hadoop-env.sh
export HDFS_NAMENODE_OPTS="$HDFS_NAMENODE_OPTS -javaagent:/opt/soft/jmx_prometheus_javaagent-0.17.2.jar=30003:/opt/soft/jmx_exporter/prometheus_config.yml" export HDFS_DATANODE_OPTS="$HDFS_DATANODE_OPTS -javaagent:/opt/soft/jmx_prometheus_javaagent-0.17.2.jar=30004:/opt/soft/jmx_exporter/prometheus_config.yml"
$ vim /opt/soft/hbase/conf/hbase-env.sh
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -javaagent:/opt/soft/jmx_prometheus_javaagent-0.17.2.jar=30005:/opt/soft/jmx_exporter/prometheus_con fig.yml" export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -javaagent:/opt/soft/jmx_prometheus_javaagent-0.17.2.jar=30006:/opt/soft/jmx_exporter/pr ometheus_config.yml"
#然后将上面这三个配置文件同步到其他机器,然后每台机器执行下面的配置
# cd /opt/soft/ && wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.17.2/jmx_prometheus_javaagent-0.17.2.jar && mkdir /opt/soft/jmx_exporter && chown hadoop:hadoop /opt/soft/jmx_exporter
# /opt/soft/jmx_exporter/prometheus_config.yml
--- rules: - pattern: '.*'
#然后将hadoop和hbase都重启一次
3.2 prometheus的配置
# vim /opt/soft/prometheus/prometheus.yml
- job_name: "YARN_RESOURCEMANAGER" static_configs: - targets: ['hadoop-master01:30001','hadoop-master02:30001'] - job_name: "YARN_NODEMANAGER" static_configs: - targets: ['hadoop-node01:30002','hadoop-node02:30002','hadoop-node03:30002'] - job_name: "HADOOP_NAMENODE" static_configs: - targets: ['hadoop-master01:30003','hadoop-master02:30003'] - job_name: "HADOOP_DATANODE" static_configs: - targets: ['hadoop-node01:30004','hadoop-node02:30004','hadoop-node03:30004'] - job_name: "HBASE_MASTER" static_configs: - targets: ['hadoop-master01:30005','hadoop-master02:30005'] - job_name: "HBASE_REGION" static_configs: - targets: ['hadoop-node01:30006','hadoop-node02:30006','hadoop-node03:30006']
#启动下prometheus,查看下指标数据
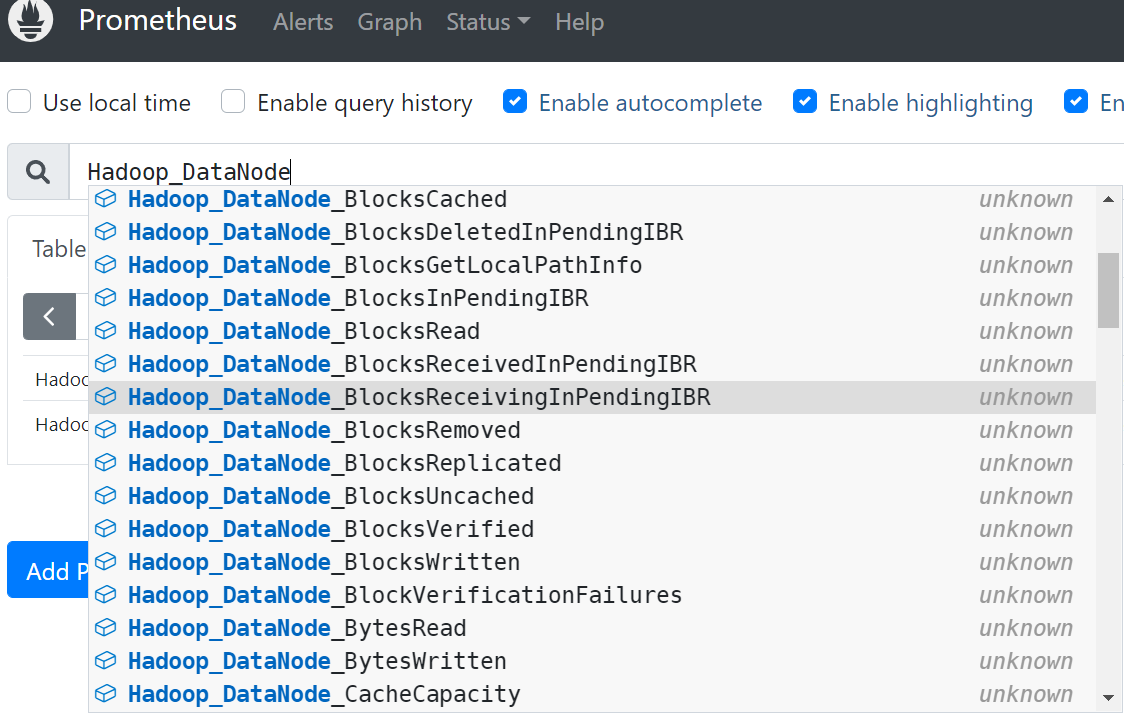
#你说指标太多了也不知道指标什么意思啊,这怎么办,可以看指标注释如下面的方面:
$ curl hadoop-node02:30002 #可以看着注释把每一个指标项理解下具体意思,当然也可以试着网上搜索,数据有了就可以利用grafana出图显示了,这里就不是本文的重点了就不着重阐述了。
博文来自:www.51niux.com
四、Hbase shell使用
4.1 官网介绍
官网介绍:https://hbase.apache.org/book.html#shell
Apache HBase Shell是(J)Ruby's IRB,添加了一些特定于HBase的命令。
$ ./bin/hbase shell
也可以通过下面的方式运行ruby编写的脚本:
$ ./bin/hbase org.jruby.Main PATH_TO_SCRIPT
4.2 阿里hbase使用
#实际线上可能使用的阿里的产品而非自建,这时候如何登录hbase进行命令操作呢?
官网文档:https://help.aliyun.com/document_detail/205533.html?spm=a2c4g.11186623.0.0.74135b78sXEUUG
#wget https://public-hbase.oss-cn-hangzhou.aliyuncs.com/installpackage/hbase-1.x-shell.tar.gz?spm=5176.connect.0.0.27074fa4CWZMhm&file=hbase-1.x-shell.tar.gz
#tar xf hbase-1.x-shell.tar.gz\?spm\=5176.connect.0.0.27074fa4CWZMhm
#cd alihbase-1.1.4/
#vim conf/hbase-site.xml
<configuration> <property> <name>hbase.zookeeper.quorum</name> <value>ZK地址(多个逗号隔开)</value> </property> </configuration>
# /tmp/alihbase-1.1.4/bin/hbase shell
4.3 无交互hbase shell使用
$ echo "create 'test1','f2'"|/opt/soft/hbase/bin/hbase shell
$ echo "describe 'test1'"|/opt/soft/hbase/bin/hbase shell
Table test1 is ENABLED
test1, {TABLE_ATTRIBUTES => {METADATA => {'hbase.store.file-tracker.impl' => 'DEFAULT'}}}
COLUMN FAMILIES DESCRIPTION
{NAME => 'f2', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZ
E => '65536 B (64KB)', REPLICATION_SCOPE => '0'}