grep命令详解
一、grep介绍
1.1 什么是grep?
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep 家族包括grep、egrep 和fgrep。egrep 和fgrep 的命令只跟grep 有很小不同。
egrep 是grep 的扩展,支持更多的re元字符, fgrep 就是 fixed grep 或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux 使用GNU 版本的grep。它功能更强,可以通过-G、-E、-F 命令行选项来使用egrep 和fgrep 的功能。 grep 的工作方式是它在一个或多个文中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。
grep 可用于shell 脚本,因为grep 通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文 不存在,则返回2 。我们利用这些返回值就可进行一些自动化的文本处理工作。
grep支持正则表达式匹配查找,egrep支持扩展正则表达式匹配查找,fgrep不支持正则表达式匹配查找。
1.2 grep的使用格式:
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
1.3 grep的常用选项:
-V: 打印grep的版本号
-E: 解释PATTERN作为扩展正则表达式,也就相当于使用egrep。
-F : 解释PATTERN作为固定字符串的列表,由换行符分隔,其中任何一个都要匹配。也就相当于使用fgrep。
-G: 将范本样式视为普通的表示法来使用。这是默认值。加不加都是使用grep。
匹配控制选项:
-e : 使用PATTERN作为模式。这可以用于指定多个搜索模式,或保护以连字符( - )开头的图案。指定字符串做为查找文件内容的样式。
-f : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-i : 搜索时候忽略大小写
-v: 反转匹配,选择没有被匹配到的内容。
-w:匹配整词,精确地单词,单词的两边必须是非字符符号(即不能是字母数字或下划线)
-x:仅选择与整行完全匹配的匹配项。精确匹配整行内容(包括行首行尾那些看不到的空格内容都要完全匹配)
-y:此参数的效果和指定“-i”参数相同。
一般输出控制选项:
-c: 抑制正常输出;而是为每个输入文件打印匹配线的计数。
--color [= WHEN]:让关键字高亮显示,如--color=auto
-L:列出文件内容不符合指定的范本样式的文件名称
-l : 列出文件内容符合指定的范本样式的文件名称。
-m num:当匹配内容的行数达到num行后,grep停止搜索,并输出停止前搜索到的匹配内容
-o: 只输出匹配的具体字符串,匹配行中其他内容不会输出
-q:安静模式,不会有任何输出内容,查找到匹配内容会返回0,未查找到匹配内容就返回非0
-s:不会输出查找过程中出现的任何错误消息,-q和-s选项因为与其他系统的grep有兼容问题,shell脚本应该避免使用-q和-s,并且应该将标准和错误输出重定向到/dev/null 代替。
输出线前缀控制:
-b:输出每一个匹配行(或匹配的字符串)时在其前附加上偏移量(从文件第一个字符到该匹配内容之间的字节数)
-H:在每一个匹配行之前加上文件名一起输出(针对于查找单个文件),当查找多个文件时默认就会输出文件名
-h:禁止输出上的文件名的前缀。无论查找几个文件都不会在匹配内容前输出文件名
--label = LABEL:显示实际来自标准输入的输入作为来自文件LABEL的输入。这是特别在实现zgrep等工具时非常有用,例如gzip -cd foo.gz | grep --label = foo -H的东西。看到 也是-H选项。
-n:输出匹配内容的同时输出其所在行号。
-T:初始标签确保实际行内容的第一个字符位于制表位上,以便对齐标签看起来很正常。在匹配信息和其前的附加信息之间加入tab以使格式整齐。
上下文线控制选项:
-A num:匹配到搜索到的行以及该行下面的num行
-B num:匹配到搜索到的行以及该行上面的num行
-C num:匹配到搜索到的行以及上下各num行
文件和目录选择选项:
-a: 处理二进制文件,就像它是文本;这相当于--binary-files = text选项。不忽略二进制的数据。
--binary-files = TYPE:如果文件的前几个字节指示文件包含二进制数据,则假定该文件为类型TYPE。默认情况下,TYPE是二进制的,grep通常输出一行消息二进制文件匹配,或者如果没有匹配则没有消息。如果TYPE不匹配,grep假定二进制文件不匹配;这相当于-I选项。如果TYPE是文本,则grep处理a二进制文件,如果它是文本;这相当于-a选项。警告:grep --binary-files = text可能会输出二进制的垃圾,如果输出是一个终端和如果可能有讨厌的副作用终端驱动程序将其中的一些解释为命令。
-D:如果输入文件是设备,FIFO或套接字,请使用ACTION处理。默认情况下,读取ACTION,这意味着设备被读取,就像它们是普通文件一样。如果跳过ACTION,设备为 默默地跳过。
-d: 如果输入文件是目录,请使用ACTION处理它。默认情况下,ACTION是读的,这意味着目录被读取,就像它们是普通文件一样。如果跳过ACTION,目录将静默跳过。如果ACTION是recurse,grep将递归读取每个目录下的所有文件;这是相当于-r选项。
--exclude=GLOB:跳过基本名称与GLOB匹配的文件(使用通配符匹配)。文件名glob可以使用*,?和[...]作为通配符,和\引用通配符或反斜杠字符。搜索其文件名和GLOB通配符相匹配的文件的内容来查找匹配使用方法:grep -H --exclude=c* "old" ./* c*是通配文件名的通配符./* 指定需要先通配文件名的文件的范围,必须要给*,不然就匹配不出内容,(如果不给*,带上-r选项也可以匹配)
--exclude-from = FILE:在文件中编写通配方案,grep将不会到匹配方案中文件名的文件去查找匹配内容
--exclude-dir = DIR:匹配一个目录下的很多内容同时还要让一些子目录不接受匹配,就使用此选项。
--include = GLOB:仅搜索其基本名称与GLOB匹配的文件(使用--exclude下所述的通配符匹配)。
-R ,-r :以递归方式读取每个目录下的所有文件; 这相当于-d recurse选项。
其他选项:
--line-buffered: 在输出上使用行缓冲。这可能会导致性能损失。
--mmap:启用mmap系统调用代替read系统调用
-U:将文件视为二进制。
-z:将输入视为一组行,每一行由一个零字节(ASCII NUL字符)而不是a终止新队。与-Z或--null选项一样,此选项可以与排序-z等命令一起使用来处理
任意文件名。
博文来自:www.51niux.com
1.4 正则表达式
. :匹配任意单个字符
?:匹配其前的单个字符0或1次
* :匹配其前的单个字符0或多次
[] :匹配指定任意范围内的字符
[^] :匹配指定任意范围外的字符
\{ m,\}:匹配前面的字符至少出现m次
\{m,n\} :匹配前面的字符至少m次,至多n次
\{m\}:匹配前面的字符出现m次
\<(\b):锚定单词首部
word\>:锚定以word单词尾部
^ :锚定行首,^要放在PATTERN的最前面
$:锚定行尾,$要放在PATTERN的最后面
\(..\) :标记匹配字符,如'\(love\)',love被标记为1。
\w: 匹配文字和数字字符,也就是[A-Za-z0-9]
\W: \w的反置形式,匹配一个或多个非单词字符,如点号句号等。也就是非字母和数字。
\b : 单词锁定符,如: '\bgrep\b'只匹配grep。
扩展正则表达式(其支持的元字符和标准正则表达式稍有区别):
+:匹配+前的一个字符1次或多次
| :STR1|STR2|STR3,支持以字符串为一个整体进行单个字符串的匹配
():分组。()+表示多个重复的分组
{}:匹配精确次数,和标准正则表达式语法相同
注: 像\d(匹配【0-9】数字),\D(匹配非数字),\s(匹配任意空白字符,匹配【\t\n\r\f】),\S(匹配非空字符)等一些正则,你会发现用grep和egrep,这些正则是失效的,而Pgrep支持这些。
1.5 POSIX字符
[:alnum:]: 字母字符和数字字符,与[A-Za-z0-9]等效
[:alpha:]: 字母字符,等效于[A-Za-z]
[:digit:]: 数字字符 ,等效于[0-9]
[:graph:]: 非空字符(非空格、控制字符
[:lower:]: 小写字母字符
[:cntrl:]: 控制字符 ,包括ASCII字符0~31以及127
[:print:]: 可打印字符;包括[:graph:]中的所有字符再加上空格字符
[:punct:]: 标点符号 ,在ASCII中,与[-!"#$%&'()*+,./:;<=>?@[\\\]_`{|}~]等效
[:space:]: 空白字符如空格符、制表符、回车符、换行符、垂直制表符以及换页符。在ASCII中,等效为[ \t\r\n\v\f]
[:xdigit:]: 十六进制数字(0-9,a-f,A-F)
[:upper:]: 大写字母 字符
博文来自:www.51niux.com
二、grep的使用实例
2.1 E和e的区别
# netstat -an|grep "ESTABLISHED|WAIT" #默认grep不支持多条件匹配
# netstat -an|grep -E "ESTABLISHED|WAIT" #加上-E 多条件用""包起来,然后多条件之间用|管道符分开
tcp 0 52 192.168.1.108:22 192.168.1.104:54127 ESTABLISHED
# ps -aux|grep -e udevd -e master|awk {'print $(NF-1)'}|sort|uniq #而-e呢不用""包起来,-e 指定一个匹配条件 -e指定一个匹配条件
/sbin/udevd
/usr/bin/salt-master
2.2 -f的作用
# cd /etc/sysconfig/network-scripts/
# grep "IPADDR" ifcfg-eth0 ifcfg-lo #默认不加参数指定过滤关键字,外加多个文件,只是将多个文件里面有匹配的行输出
ifcfg-eth0:IPADDR=192.168.1.108
ifcfg-lo:IPADDR=127.0.0.1
# grep -f ifcfg-eth0 ifcfg-lo #grep -f 文件1 文件2 ,会将多个文件之间相同的行输出出来
ONBOOT=yes
2.3 -i的使用
# cat test.txt #这是我的测试文本,有四行内容
abc dsadsad
ABC dada
123 ab123213
dasd 13131
# grep "abc" test.txt #不加i只会过滤出一行输出
abc dsadsad
# grep -i "abc" test.txt #加i忽略大小写会将ABC所在的行也过滤出来
abc dsadsad
ABC dada
2.4 -v的使用
# grep -v "abc" test.txt #将没有abc的行过滤出来
ABC dada
123 ab123213
dasd 13131
# grep -vi "abc" test.txt #可以加上多个参数
123 ab123213
dasd 13131
2.5 -w的使用
# cat test1.txt
abcde 123
abc 325
abc_321
abc888
nihaoabc
zou abc ni
# grep -w "abc" test1.txt #-w 就是精确的匹配abc为单独的一个单词的行,左右两边没有任何数字啊字母啥的
abc 325
zou abc ni
2.6 -x的使用
# grep -x "abc_" test1.txt #模糊匹配已经不生效了,过滤不出什么信息了
# grep -x "abc_321" test1.txt #-x是精确匹配一个整行,直接将正行的内容进行过滤。
abc_321
2.7 -c的使用
# grep -i "abc" test.txt|wc -l #不分大小写。test.txt里面包含abc过滤条件的为2行
2
# grep -yc "abc" test.txt #-c呢,就是不显示行的内容,直接显示有几行
2
# cat /etc/passwd|wc -l
55
# grep -c "^.*$" /etc/passwd #那么我们除了wc -l用来统一一个文件有多少行以外,又多了一种统计文件多少行的方法
55
2.8 --color=auto 高亮显示

2.9 -L和-l的区别
# cat /opt/1.txt #这是三个测试文件,有的带root关键字,有的文件里面没有root
root haha
Root ququ
# cat /opt/2.txt #2.txt不带root关键字,其他两个文件都带root关键字
zouqi
buzou
oo
# cat /opt/3.txt
rootbushiwo
rootjiushini
Rootbuzou
# grep -l "root" /opt/*.txt #-l 将带有root关键字的文件输出了出来
/opt/1.txt
/opt/3.txt
# grep -L "root" /opt/*.txt #-L将不带有root关键字的文件输出了出来
/opt/2.txt
2.10 -m的使用
# cat test2.txt #这是测试文件
abc 1
abc 2
abc 3
abc 4
abc 5
# grep -m 3 "abc" test2.txt #只匹配到了第三行就退出了
abc 1
abc 2
abc 3
2.11 -o的使用外加一个-b的配合使用
# grep "root" /etc/passwd #先看下正常的过滤,会将整个一行过滤出来
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
# grep -o "root" /etc/passwd #加o之后的操作,只过滤关键字出来,但是貌似这样使用没啥意思啊
root
root
root
root
# grep -o "root:.*0" /etc/passwd #加上正则表达式,这样才是正确的用法,不用输出一整行,只是输出一小段
root:x:0:0
# grep -o "root" -b /etc/passwd #-b和-o一般是配合使用的,一行中字符串的字符是从该行的第一个字符开始计算,起始值为0。这里左边的数字就是此关键字在此文件中的起始位置,第一个root出现在0位置,然后字符字母啥的有一个算一个,你就一个个的向右数吧,下一个root出现在11位置以此类推。
0:root
11:root
17:root
414:root
2.12 H和h的区别
# grep -H 'root' /opt/*.txt #grep 默认是H,在输出的首部显示是来自于那个文件,当然也可以指定单个文件
/opt/1.txt:root haha
/opt/3.txt:rootbushiwo
/opt/3.txt:rootjiushini
# grep -h 'root' /opt/*.txt #-h不显示带有匹配条件的行来自于哪个文件,只显示匹配的行的内容。
root haha
rootbushiwo
rootjiushini
2.13 --label的用法
# cat /etc/passwd|grep --label=/etc/passwd -H nagios
/etc/passwd:nagios:x:2528:2528::/home/nagios:/bin/bash
# cat /etc/passwd|grep --label=test -H nagios #打印标签作为文件名的标准输入(主要用于管道处理)
test:nagios:x:2528:2528::/home/nagios:/bin/bash
# cat /etc/passwd|grep -H nagios #下面是不加 --label 的效果
(standard input):nagios:x:2528:2528::/home/nagios:/bin/bash
2.14 -n 的使用
# grep -n "root" /etc/passwd #-n就是不仅显示匹配内容所在行的行号
1:root:x:0:0:root:/root:/bin/bash
11:operator:x:11:0:operator:/root:/sbin/nologin
2.15 -T的使用
# grep "root" /opt/*.txt #不加-T的效果,文件名与后面的内容是连载一起没有分隔的
/opt/1.txt:root haha
/opt/3.txt:rootbushiwo
/opt/3.txt:rootjiushini
# grep -T "root" /opt/*.txt #将标签排队(标签即文件名)加入tab以使格式整齐。
/opt/1.txt :root haha
/opt/3.txt :rootbushiwo
/opt/3.txt :rootjiushini
2.16 -A,-B,-C的用法
# cat test3.txt #这是我们的测试文本,测试结果比较直观
1
2
3
4
5
6
7
8
9
10
# grep -A 3 "4" test3.txt #-A后面加数字3,就代表过滤4所在的行以及向下三行的内容
4
5
6
7
# grep -B 3 "4" test3.txt #-B后面加数字3,就代表过滤4所在的行以及向上三行的内容
1
2
3
4
# grep -C 3 "4" test3.txt #-C后面加数字3,就代表过滤4所在行向上三行以及向下三行的内容
1
2
3
4
5
6
7
2.16 -R和-r的使用
上面用到的grep “root” /opt/*.txt 只能对一层目录进行过滤,并不能递归的进行过滤,如果要递归的进行过滤呢。还是需要-R或者-r
# grep "root" -R /opt/ #我们将3.txt移动到了/opt/greptest目录下面,用递归的方式依旧是可以将其找出来的。
/opt/greptest/3.txt:rootbushiwo
/opt/greptest/3.txt:rootjiushini
/opt/1.txt:root haha
# grep "root" /opt/* #这里是不加递归的结果,只能查找当前目录。
/opt/1.txt:root haha
2.17 --exclude-from=file 的使用
# grep "root" -R /opt/* --exclude /opt/5.txt #对/opt/目录进行过滤,/opt/5.txt 被排除掉,不在被过滤的范围内。
/opt/1.txt:root haha
/opt/greptest/3.txt:rootbushiwo
/opt/greptest/3.txt:rootjiushini
# grep "root" -R /opt/* --exclude /opt/1.txt --exclude /opt/5.txt #可以制定多个目录,但是也仅限于当前目录。
/opt/greptest/3.txt:rootbushiwo
/opt/greptest/3.txt:rootjiushini
# grep "root" -R /opt/* --exclude "*.txt" #当然也可以用这种形式,将某一类型的文件排除掉。
/opt/2.test:root #非.txt格式的文件还是能正常输出的
注意:
第一点:# grep "root" -R /opt/* --exclude-from=/opt/5.txt #以--exclude-from=file这种形式,是成功不了的。
第二点:格式要摸是# grep "root" -R /opt/* --exclude /opt/5.txt ,要摸就要进入到要过滤的目录下:# grep "root" -R . --exclude 5.txt ,--exclude后面的文件是否指定路径,跟前面是否指定目录路径有关系。
第三点:这种文件过滤,只能对指定目录当前一级目录进行排除,如果指定的文件是当前的目录的下一级目录里面的文件,当不起作用。
# grep "root" -R /opt/* --exclude-from=/opt/5.txt #这种格式没有起作用
/opt/1.txt:root haha
/opt/5.txt:root 231321
/opt/greptest/3.txt:rootbushiwo
/opt/greptest/3.txt:rootjiushini
# grep "root" -R /opt/* --exclude /opt/greptest/3.txt #这种格式也没有起作用
/opt/1.txt:root haha
/opt/5.txt:root 231321
/opt/greptest/3.txt:rootbushiwo
/opt/greptest/3.txt:rootjiushini
2.18 --exclude-dir的使用
# grep "root" -R /opt/* --exclude-dir /opt/greptest#将/opt/greptest目录排除在外,不参与过滤
/opt/1.txt:root haha
/opt/greptes2/5.txt:root 231321
# grep "root" -R /opt/* --exclude-dir /opt/greptest --exclude-dir /opt/greptes2 #可以指定排除多个目录
/opt/1.txt:root haha
2.19 --include的使用
# grep -rn --include={1,6}.txt "root" /opt/ #这里可以指定过个文件,进行过滤查看,相当于:# grep -rn --include=1.txt --include=6.txt "root" /opt/ ,当然include的作用也仅限于/opt当前目录下面,无法递归
/opt/1.txt:1:abc root 123
/opt/1.txt:2:root123
/opt/6.txt:1:root132132131
# grep -rn --include=*.txt "root" /opt/* #只过滤/opt/目录下面,关键字为root的,txt格式的文件。
/opt/1.txt:1:abc root 123
/opt/1.txt:2:root123
/opt/6.txt:1:root132132131
/opt/greptest/4.txt:1:root321
/opt/greptest/5.txt:1:root132131
/opt/greptest2/7.txt:1:wokao root
/opt/greptest2/8.txt:2:rootfeiq
# grep -rn --include=*.{txt,test} "root" /opt/* #这是选择多个格式文件,.txt文件和.test文件都选上了。
/opt/1.txt:1:abc root 123
/opt/1.txt:2:root123
/opt/3.test:1:rootzouqi
/opt/6.txt:1:root132132131
/opt/greptest/4.txt:1:root321
/opt/greptest/5.txt:1:root132131
/opt/greptest/9.test:1:rootdas
/opt/greptest/9.test:2:dadasroot
/opt/greptest2/7.txt:1:wokao root
/opt/greptest2/8.txt:2:rootfeiq
下面几种方式都是取不到值:
# grep -rn --include=/opt/greptest/*.txt "root" /opt/*
# grep -rn --include=/opt/greptest/*.{txt,test} "root" /opt/*
# grep -rn --include=/opt/greptest/9.test "root" /opt/*
如果想取/opt/目录下面的某一个目录,只能继续向下指目录了,如下面的例子:
# grep -rn --include=/opt/greptest/*.txt "root" /opt/greptest/*
/opt/greptest/4.txt:1:root321
/opt/greptest/5.txt:1:root132131
博文来自:www.51niux.com
三、正则表达式的使用示例
3.1 .(匹配单个任意字符)的用法
# grep -r "r..t" /etc/passwd --color #过滤/etc/passwd文件中,带关键字“r中间有任意两个字符t”的行,中间的字符为任意,空格、字母什么的都可以。
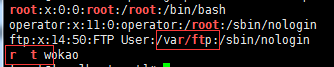
3.2 ?(匹配前面字符0次或1次)的用法
# grep -r "u\?cp" /etc/passwd --color #匹配以u开头后面出现0次或者1次的u,以up结尾的关键字被匹配的行。注意?号前面加\。
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
3.3 *(匹配前面单个字符0次或者多次)的用法
# grep -r "sp*l" /etc/passwd #匹配文件中出现sp(p出现0次或者多次)l的行。
saslauth:x:499:76:Saslauthd user:/var/empty/saslauth:/sbin/nologin #注意这里根本没有什么sp什么l,只有一个Saslauthd 里面有个sl被匹配到了。
# grep -r "spo*l" /etc/passwd #匹配文件中出现spo(o出现0次或者多次)l的行。
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
一般*经常事跟.配合使用的,比如下面的例子:
# cat /etc/sysconfig/network-scripts/ifcfg-eth0 |grep "s$" #如果我们想过滤出以O开头O^,以s结尾或者以yes结尾的行呢?中间的那些字符就需要.*表示了。
ONBOOT=yes
NM_CONTROLLED=yes
# cat /etc/sysconfig/network-scripts/ifcfg-eth0 |grep "^O.*s$" #这就是.*混合在一起使用,代表O和s之间出现的那些我们不知道是多少或者是什么的字符。
ONBOOT=yes
3.4 [](匹配任意范围内的字符)以及[^](匹配指定任意范围外的字符)的用法:
# grep "[2-4]" /etc/inittab #inittab文件中行中有2,3,4的行显示出来,也就是显示数字2-4范围内的行。
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
id:3:initdefault:
S0:12345:respawn:/sbin/agetty ttyS0 115200
# grep "[A-B]" /etc/inittab #过滤有大写字母A,B的行,小写字母也可以这样过滤,如[a-z]就是过滤带有小写字母的行
# ADDING OTHER CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
# Ctrl-Alt-Delete is handled by /etc/init/control-alt-delete.conf
# grep "[24]" /etc/inittab #过滤出现了2或者出现了4的行。
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 4 - unused
S0:12345:respawn:/sbin/agetty ttyS0 115200
下面是关于[^]的示例:
# grep '[^0-9]' /root/1.txt #这个用法是没错的,是过滤关键字里面非数字关键字的内容,但是行首都是纯字母的行,所以看不出效果来。
list listen321 list123
listn listen111 list123
listen list222 listen123
listen listen333 listen123
wskas zsuqi
LSL zsuqi
# grep "[^0-9]$" /root/1.txt #再看这个例子,过滤不是数字结尾的行,所以[^]单独使用作用不太大,跟其他的一些字母啊正则啊配合使用比较好。
wskas zsuqi
LSL zsuqi
3.5 {}的用法
# grep "ro\{0,3\}t" /etc/passwd --color #查询ro(出现0次到3次之间)t的行

# grep "ro\{0\}t" /etc/passwd #查询ro(出现0次)的行
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
# grep "ro\{1,\}t" /etc/passwd #查询ro(至少出现1次)的行
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
3.6 \<和\>的用法
# grep "\<c" /etc/passwd --color #查找/etc/passwd文件中单词以c开头的行。

# grep "p\>" /etc/passwd --color #查找/etc/passwd文件中单词以p结尾的行

# grep '\<daemon\>' /etc/passwd --color #查找单词是daemon的行

# grep '\<d.*n\>' /etc/passwd --color #查找以d开头,以n结尾的单词的行,这种查找范围就比较广了。

2.7 ^和$的作用
# grep "^f" /etc/init.d/acpid #以f开头的行
force-reload)
# grep "3$" /etc/init.d/acpid #以3结尾的行
RETVAL=3
# grep "^#.*\.$" /etc/init.d/acpid --color #以#开头以.结尾的行,注意这里的最后的.因为就是表示.,而不是任意一个字符的意思,所以要用\转义一下。
# Source function library.
# See how we were called.
2.8 \(..\)的作用
# grep "\(ow\)" /etc/passwd #把ow作为一个整体匹配字符,去查询文本中包含ow的行
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
# grep "\(ow\)\{1,\}" /etc/passwd #当然也可以将ow作为一个整体,来匹配ow出现多少次的行
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
# grep "\(ow\).*\1n" /etc/passwd #这里\1就是引用第一个左括号里面的内容,然后再后面加了个n,就是过滤一行中出现了,开头是ow,后面也要出现一个own。
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
# grep "\(tn\).*\11" /root/1.txt --color #就是找tn.*tn1所在的行

# grep "\(t.n\).*\11" /root/1.txt --color #找t中间任何字符n,然后后面还有个t.n1的字符,这个1可以是任意其他的字符,但是\1 就是代表了\(\)里的内容。

# grep "\(t\)\(e\)\(n\).*\1\2\31" /root/1.txt --color #那么我们可以多搞几个\(\)啊,里面的整体匹配字符,我们可以组合使用,也可以单个使用啊。
listen list222 listen123

2.9 \b,\w,\W的使用
# grep "\broot" 1.txt --color #\broot 就是以root开头的的单字符,这里的开头并非指一行的开头,而是单字符的开头,从下面可以看出,前面可以是空格,或者其他符号,或者前面没有任何的东西。
abc rootwokao 123
H!root:zou ni
123 root feiqi
root123
# grep "root\b" 1.txt --color #root\b,就是以root结尾的单字符,这里的结尾并非一行的结尾,而是单字符的结尾,后面可以是空格,或者其他符号,或者后面什么都没有。
H!root:zou ni
123 root feiqi
# grep "\broot\b" 1.txt --color #\broot\b,就是以root为一个单独的单字符的行,root前面可以什么都没有可以是空格或者什么符号,后面也不可以有数字或者字母什么的。
H!root:zou ni
123 root feiqi
# grep "\w" 1.txt --color #匹配文件中带有[0-9],[a-z],[A-Z]等关键字的行

# grep "\W" 1.txt --color #匹配文件中带有标点符号过滤条件的行
2.10 扩展正则表达式的用法
# grep "spo\+" /etc/passwd --color #\+的用法。以spo中的o出现1次或者多次为匹配条件,过滤/etc/passwd文件。# egrep "spo+" /etc/passwd --color这种方式的效果是一样的,这样+前面就不用加\了。
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
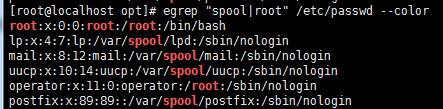
# egrep "spool|root" /etc/passwd --color #|用或的方式,查找多个匹配条件,这里就是查找行里面带spool的匹配条件,或者行里面带root的匹配条件。再多的匹配条件就是s1|s2|s3以此类推
# grep -E "s(ync|shd)" /etc/passwd --color #|和()结合使用,将()的当做一个单独的字符,如果有|就以|来切分单独的字符,这里就是既查找sync又查找sshd所在的行。
sync:x:5:0:sync:/sbin:/bin/sync
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
# grep -E "sp{1,2}" /etc/passwd --color #也没什么好说的,就是这里的格式不用\{\}这样了,这里就是sp的p出现1次或者2次的行。
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
# grep -E "u{2}cp" /etc/passwd --color #这里就是u出现2次,也就是直接过滤uucp所在的行。
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
博文来自:www.51niux.com
四、POSIX字符集的用法示例
# grep -E "^[[:upper:]].*[[:digit:]]{1}$" /etc/init.d/acpid --color #查找文件中以大写字母开头,以数字出现1次结尾的行,也就是以数字结尾的行。
RETVAL=0
# grep -E "[[:space:]]{5}" /etc/init.d/acpid --color #查找文件中空白字符连续5次的行,因为是空行所以加颜色高亮也不显示

# grep -E "^[[:lower:]].*[[:digit:]]{1,3}" /etc/init.d/acpid --color #查找文件中以小写字母开头,中间数字出现1到三次的行
case "$1" in
五、写一些小例子
例子1:查找当前系统有哪些用户可以登录。
# grep "bash$" /etc/passwd #这个比较简单,因为/etc/passwd里面能登录的用户尾部是/bin/bash,不能登录的用户尾部是/sbin/nologin
root:x:0:0:root:/root:/bin/bash
例子2:查找functions中,单词后面加()的行,也就是查找是小写字母命名的函数,并打印行号
# grep -o -E -n "\<[[:alpha:]]+\>\(\).*" /etc/rc.d/init.d/functions #这里就是打印出小写字母出现1次或者多次,后面跟()的行,\(\)是将()进行了转义
59:checkpid() {
357:daemon() {
447:killproc() {
530:pidfileofproc() {
545:pidofproc() {
571:status() {
688:success() {
694:failure() {
702:passed() {
709:warning() {
716:action() {
742:strstr() {
748:confirm() {
例子3:取服务器的对外IP地址
#ip addr|grep -o -E "\<[0-9]{1,3}.*\.[0-9]{1,3}/[[:digit:]]{2}\>"|awk -F "/" {'print $1'} #这里还是需要根据实际情况,比如服务器上面有多IP之类的,还需要做下小调节。
192.168.1.101
#或者这样:ifconfig |grep -m 1 -o "\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}" |head -1
例子4:将文件中的注释部分和空行去掉,只看未注释部分
# grep -Ev "^#|^$" /usr/local/nagios/etc/nrpe.cfg #结果比较多就不粘贴了,^#就是以#开头的行,^$就表示空行
