Ceph手工部署osd和mon集群(二)
一、CRUSH算法介绍及调优方法
1.1 CRUSH算法介绍
CRUSH(Controlled Replication Under Scalable Hashing)是一种基于可扩展哈希的控制复制算法,在Ceph中,CRUSH是其中负责数据对象实际分布与数据恢复的算法,对于大规模分布式存储系统来说,有一些问题是必须要关注的,比如分布数据和负载(提高资源利用率),最大化系统的性能,处理系统的扩展和硬件失效等。要做到当发生存储设备故障、存储设备添加和移除时,能最小化地迁移数据来恢复故障其实很有必要,可以有效地减少磁盘因为频繁读/写而降低Ceph集群的性能。
CRUSH算法三要素:
CRUSH算法从根本上来说,是通过存储设备的权重来计算数据对象的分布的。在计算过程中,由Cluster Map,Data Distribution Policy和给出的一个随机的证书x共同决定数据对象最终的位置。
Cluster Map(集群映射):
它的主要作用是记录所有可用的存储资源及相互之间的空间层次架构(比如,Ceph集群包含多少个机架,每个机架上有多少台服务器,每个服务器上有多个磁盘这些信息)。Cluster Map使得Ceph集群存储设备在物理层面做了一层防护,比如数据和备份不放在同一台服务器上面避免服务器宕机的影响。
Data Distribution Policy(数据分布规则):
它由Placement Rules(配置规则)组成。Placement Rules决定了每个数据对象的副本份数,以及这些副本存储的限制条件(如3个副本放在不同的服务器)。
CRUSH算法利用多参数Hash函数:
Hash函数中的参数含有x,使得从x到OSD集合是确定性的和独立的。CRUSH又是伪随机算法,所以相似输入的结果之间并没有相关性。
CRUSH map官网文档:http://docs.ceph.org.cn/rados/operations/crush-map/
1.2 CRUSH算法调优
CRUSH算法不同于其他一致性算法,它提供了一些可以调优的参数,使最终的数据分布变得更加可控,通过人为干预的方式来避免一些故障的发生。
CRUSH通过调整CRUSH MAP的配置来实现Ceph的架构调优
CRUSH MAP描述了包含当前磁盘、服务器、机架等元素的层级结构,通过对它的更改来实现调优。
# ceph osd getcrushmap -o crushmap #导出当前Ceph集群的CRUSH MAP,此时的CRUSH MAP是一个二进制文件。
got crush map from osdmap epoch 46
# crushtool -d crushmap -o crush.map #使用crushtool解析之前导出的CRUSH MAP二进制文件,保存为crush.map
# cat crush.map #打开crush.map文件
# devices #省略相似输出
device 0 device0
device 1 osd.1
device 2 osd.2
# types #Bucket types默认包含10种类型,也可以自定义新的type
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
# buckets #剩下的host一致就不打印了
host ceph-host-01 {
id -2 # do not change unnecessarily
# weight 0.088
alg straw #每个Bucket内部都支持4种算法,Uniform,List、Tree、Straw,4种算法在性能和数据重组效率方面有区别,默认情况下CRUSH MAP使用Straw
hash 0 # rjenkins1 #hash 算法,0表示 rjenkins1
item osd.1 weight 0.044 #OSD的权重,默认情况下由OSD的容量确定,1.00相关于1TB,0.50相关与500GB,3.00相关于3TB,所以0.044就相关于45G
item osd.6 weight 0.088 #如果这个盘的性能要比上面的好的话,这里的值可以调大比如调整到上面两倍, 数据传输速率较慢的可略低于此相关率,速率较快的可略高于此相关率。
}
root default { #定义root类型的bucket,命名为default
id -1 # do not change unnecessarily
# weight 0.263
alg straw #这里也设计到Bucket算法的配置,默认也是straw
hash 0 # rjenkins1
item ceph-host-01 weight 0.088 #定义了root中包含三个item,每个item表示一个host
item ceph-host-02 weight 0.088
item ceph-host-03 weight 0.088
}
# rules
rule replicated_ruleset { #定义rule,命名为replicated_ruleset,下面定义详细的规则
ruleset 0
type replicated #规则类型是replicated,默认就是这个
min_size 1 #定义副本的最少个数,如果创建的pool不满足将不使用这个rule
max_size 10 #定义副本的最大个数,如果创建的pool不满足将不使用这个rule
step take default #定义副本从哪个bucket往下检索cluster map tree
step chooseleaf firstn 0 type host #选择副本存放的位置,0表示所有副本都放到host下。
step emit #执行退出
}
# end crush map# crushtool -c crush.map -o crush.new.map #将crush.map文件编译成CRUSH MAP支持的二进制文件。
# ceph osd setcrushmap -i crush.new.map #应用编译好的CRUSH MAP策略。
set crush map
Ceph性能调优:
这个还是要和实际场景结合的,比如Ceph集群里面有部分OSD是大容量的SATA盘,有些SAS盘,这两种盘在读写性能上面肯定不一样的。Ceph定义了对象数据的读/写操作都是在主OSD上进行,这样就需要调整CRUSH算法变量来避免这部分使用SATA盘的OSD称为主OSD,而调整OSD的亲和度可以使指定OSD降低或者拒绝成为主OSD。
OSD亲和度:在Ceph集群中,每个数据被分割为一个或多个对象,每个对象都将映射到唯一一个PG中,每个PG最终映射到OSD,数据对象定义的保留份数决定了包含这个对象的PG所需要映射OSD的个数。简单来说,如果一个对象需要保留3份数据,那么这个对象数据映射的PG就会同时写在3个OSD钟,其中一个是主OSD,其余两个是备份OSD。OSD的亲和度指的就是这个OSD的优先权。默认每个OSD的亲和度权重配置都是1,也就是都可能会成为主OSD,对于容量大的OSD来说成为主OSD的概率就高。可以通过降低OSD的亲和度权重,来使配置大容量SATA盘的OSD尽可能少地被指定为OSD。
在Ceph集群中少部分OSD使用SSD硬盘,每个OSD都包含两部分,一分部是DATA,另一部分是Journal,这两部分可以任意定义位置。在实际进行写操作时,只要数据写入Journal之后就会返回成功,Journal可以理解为一个数据缓存空间,所以将Journal存放在SSD中性能会有显著提升,主要体现在IOPS性能方面,所以可以将SSD按10G大小进行分区,专门用来存放Journal,非SSD盘在OSD中用来存放DATA。
博文来自:www.51niux.com
二、Ceph的手工安装
官网链接:http://docs.ceph.com/docs/master/install/install-storage-cluster/
2.1 相关依赖的安装
我这里操作系统都是Centos7.2的操作系统。
#yum install yum-plugin-priorities -y
# cat /etc/yum/pluginconf.d/priorities.conf #确保priority.conf启用插件。
[main] enabled = 1
# vim /etc/yum.repos.d/ceph.repo #做ceph源文件
[Ceph] name=Ceph packages for $basearch baseurl=http://download.ceph.com/rpm-jewel/el7/$basearch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc [Ceph-noarch] name=Ceph noarch packages baseurl=http://download.ceph.com/rpm-jewel/el7/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc [ceph-source] name=Ceph source packages baseurl=http://download.ceph.com/rpm-jewel/el7/SRPMS enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc
#yum install snappy leveldb gdisk python-argparse gperftools-libs -y
2.2 ceph安装
#yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
#yum install ceph -y #最简单的就是直接yum安装ceph
如果要编译安装的话:
官方下载链接:http://download.ceph.com/tarballs/
官网指定的github链接:https://github.com/ceph
博文来自:www.51niux.com
三、ceph集群的简单配置
这里搞了4台Centos7.2的虚拟机,192.168.1.153-156
# lsblk -l #挂了6块50G的硬盘,第一块挂载盘分成了五个区每个10G用来存放journal,剩下的没有分区的盘用来存放data数据。
3.1 集群映射的介绍
Ceph依赖于拥有集群拓扑知识的Ceph客户端和Ceph OSD守护进程,其中包含统称为“集群映射”的5个映射:
监视器映射(The Monitor Map):
包含每个监视器的集群fsid,位置,名称地址和端口。它还指示当前状态,当地图创建时,最后一次更改。要查看监视器地图,请执行ceph mon dump。
OSD映射(The OSD Map):
包含集群fsid,当映射创建和上次修改时,池列表,副本大小,PG编号,OSD列表及其状态(例如,UP)。要查看OSD地图,请执行ceph osd dump。
PG MAP(The PG Map):
包含PG版本,其时间戳,最后一个OSD map 时期,全部比例和每个放置组的详细信息,例如PG ID,Up Set,Acting Set,PG的状态(例如,active + clean)和每个池的数据使用统计信息。
CRUSH MAP(The CRUSH Map):
包含存储设备列表,故障域层次结构(例如,设备,主机,机架,行,房间等)以及存储数据时遍历层次结构的规则。 要查看CRUSH地图,请执行ceph osd getcrushmap -o {filename}; 然后通过执行crushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename}进行反编译。 您可以在文本编辑器或cat查看反编译的地图。
元数据映射(The MDS Map):
包含当前MDS Map记录,当地图创建时,以及最后一次更改。 它还包含用于存储元数据的池,元数据服务器的列表以及哪些元数据服务器已启动并进入。要查看MDS映射,请执行ceph fs dump。
另外:
每个地图维护其操作状态变化的迭代历史。 Ceph监视器维护集群映射的主副本,包括集群成员,状态,更改以及Ceph存储集群的总体运行状况。
3.2 高可用监视器介绍(HIGH AVAILABILITY MONITORS)
为了增加可靠性和容错性,Ceph支持一组监视器。在一组监视器中,延迟和其他故障可能导致一个或多个监视器落在集群的当前状态之后。因此,Ceph必须在各种监视器实例之间就集群的状态达成一致。 Ceph总是使用大多数监视器(例如,1, 2:3, 3:5, 4:6等)和Paxos算法来建立监视器之间关于集群当前状态的共识。
官网介绍ceph-mon的链接:http://docs.ceph.com/docs/master/rados/configuration/mon-config-ref/
BACKGROUND
Ceph监视器维护集群映射的“主副本”,这意味着Ceph客户端可以通过连接到一个Ceph监视器并检索当前的集群映射来确定所有Ceph监视器,Ceph OSD守护程序和Ceph元数据服务器的位置。在Ceph客户端可以读取或写入Ceph OSD守护进程或Ceph元数据服务器之前,必须先连接到Ceph监视器。使用集群映射和CRUSH算法的当前副本,Ceph客户端可以计算任何对象的位置。计算对象位置的能力允许Ceph客户端直接与Ceph OSD守护进程通信,这是Ceph高度可扩展性和性能的一个非常重要的方面。
Ceph Monitor的主要作用是维护集群映射的主副本。 Ceph监视器还提供认证和记录服务。
Ceph监视器将监视器服务中的所有更改写入单个Paxos实例,并将Paxos将更改写入密钥/值存储,以实现一致性。 Ceph监视器可以在同步操作期间查询最新版本的集群映射。 Ceph监视器利用键/值存储的快照和迭代器(使用leveldb)来执行存储范围的同步。在Ceph版本0.58及更早版本中,Ceph监视器对每个服务使用Paxos实例,并将映射存储为文件(后来这种方式就弃用了)。如下图:
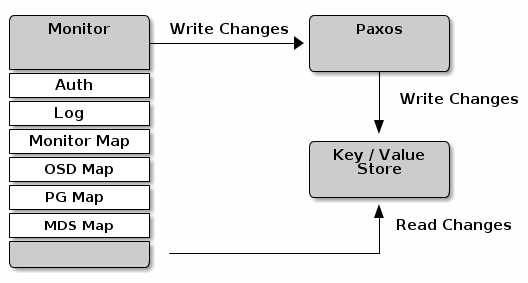
集群映射
集群映射是映射的组合,包括监视器映射,OSD映射,放置组映射和元数据服务器映射。集群映射跟踪了许多重要的事情:Ceph存储集群中有哪些进程; Ceph存储集群中的进程正在运行或关闭;布局组是否处于活动状态或非活动状态,干净或处于某种其他状态;以及反映集群当前状态的其他细节,如存储空间总量以及所使用的存储量。
当集群状态发生重大变化时,例如Ceph OSD守护程序关闭,放置组处于降级状态等,集群映射将被更新以反映集群的当前状态。此外,Ceph Monitor还保留了群集的先前状态的历史记录。监视器地图,OSD地图,放置组地图和元数据服务器映射各自保留其地图版本的历史记录。我们称每个版本为“时代”。
操作Ceph存储集群时,跟踪这些状态是系统管理职责的重要组成部分。
MONITOR法定数量
为了确保在生产Ceph的存储集群的高可用性,应该使用多MON运行的Ceph,防止单一MON造成的失败毁了整个集群。Ceph的存储集群,当Ceph存储集群运行多个Ceph监视器以实现高可用性时,Ceph监视器使用Paxos来建立关于主集群映射的共识。 共识要求大多数监视员运行建立一个关于集群映射的协商一致的法定人数(例如,1; 2 out of 3; 3 out of 5; 4 out of 6;等)。mon force quorum join #默认值是false,强制监视器加入仲裁,即使以前已从地图中删除
一致性(CONSISTENCY)
当将监视器设置添加到Ceph配置文件时,需要了解Ceph监视器的一些架构方面。当发现群集中的另一个Ceph监视器时,Ceph对Ceph监视器施加了严格的一致性要求。而Ceph客户端和其他Ceph守护程序使用Ceph配置文件发现监视器,监视器使用监视器映射(mon map)而不是Ceph配置文件发现对方。
当发现Ceph存储集群中的其他Ceph监视器时,Ceph监视器始终指的是monmap的本地副本。使用monmap而不是Ceph配置文件避免了可能破坏集群的错误(例如,在指定监视器地址或端口时,在ceph.conf中打印错误)。由于监视器使用单图进行发现,并且与客户端和其他Ceph守护程序共享monmap,monmap为监视器提供严格保证其共识是有效的。
严格一致性也适用于更新monmap。与Ceph监视器上的任何其他更新一样,monmap的更改总是通过称为Paxos的分布式共享算法运行。 Ceph监视器必须同意对monmap的每次更新,例如添加或删除Ceph监视器,以确保法定人数中的每个监视器具有相同版本的monmap。对monmap的更新是递增的,因此Ceph监视器具有最新的同意版本和一组以前的版本。维护历史记录使得具有较早版本的monmap的Ceph Monitor可以赶上Ceph Storage Cluster的当前状态。
如果Ceph监视器通过Ceph配置文件而不是通过monmap发现对方,则会引入额外的风险,因为Ceph配置文件不会自动更新和分发。 Ceph监视器可能会无意中使用较旧的Ceph配置文件,无法识别Ceph监视器,不在法定范围内,或发展出Paxos无法准确确定系统当前状态的情况。
引导监视器(BOOTSTRAPPING MONITORS)
在大多数配置和部署案例中,部署Ceph的工具可能有助于通过为您生成监视器映射(例如,ceph-deploy等)来引导Ceph监视器。 Ceph监视器需要几个显式设置:
文件系统ID(Filesystem ID):
fsid是对象存储的唯一标识符。由于您可以在同一硬件上运行多个集群,因此在引导监视器时必须指定对象存储的唯一ID。部署工具通常为您做这个工作(例如,ceph-deploy可以调用uuidgen等工具),但您也可以手动指定fsid。
监视器ID(Monitor ID):
监视器ID是分配给集群中每个监视器的唯一ID。它是一个字母数字值,按照惯例,标识符通常遵循字母增量(例如,a,b等)。这可以通过部署工具或使用ceph命令行在Ceph配置文件(例如,[mon.a],[mon.b]等)中进行设置。
键(Keys):
显示器必须有密钥。诸如ceph-deploy之类的部署工具通常会为您执行此操作,但您也可以手动执行此步骤。
详细介绍请参照:http://docs.ceph.com/docs/master/dev/mon-bootstrap/
3.3 建立mon集群
现在192.168.1.153上面操作:
# uuidgen #用命令产生一个uuid,这也是这个ceph集群的唯一值的fsid,一个集群一个唯一uuid。
9ec20e59-1033-4505-920d-113183167b31
# vim /etc/ceph/ceph.conf #先写一个简单的ceph.conf配置文件
[global] #全局,要将配置设置应用于整个集群,请在[global]下输入配置设置。 fsid = 9ec20e59-1033-4505-920d-113183167b31 #CLUSTER ID,每个Ceph存储集群都有唯一的标识符(fsid)。 mon initial members = ceph-153,ceph-154,ceph-155 #初始成员,建议最少运行三个ceph监视器在生产存储集群,以确保高可用性。启动期间集群中初始监视器的ID。 如果指定,Ceph需要奇数个监视器来形成初始定额 mon host = 192.168.1.153,192.168.1.154,192.168.1.155 #这里是主机名并非主机IP,当然如果是主机IP的形式,可以省略下面的[mon] auth_cluster_required = cephx #如果启用了,集群守护进程(如 ceph-mon 、 ceph-osd 和 ceph-mds )间必须相互认证。可用选项有 cephx 或 none 。默认是cephx启用。 auth_service_required = cephx #如果启用,客户端要访问 Ceph 服务的话,集群守护进程会要求它和集群认证。可用选项为 cephx 或 none 。类型:String是否必需:No默认值:cephx. auth_client_required = cephx #如果启用,客户端会要求 Ceph 集群和它认证。可用选项为 cephx 或 none 。 默认就是cephx。 public_network = 192.168.1.0/24 #设置在[global]。可以指定以逗号分隔的子网。这是分配集群的外网网段,即对外数据交流的网段。 osd journal size = 1024 #缺省值为0。你应该使用这个参数来设置日志大小。日志大小应该至少是预期磁盘速度和filestore最大同步时间间隔的两倍。如果使用了SSD日志,最好创建大于10GB的日志,并调大filestore的最小、最大同步时间间隔。 osd pool default size = 2 #osd的默认副本数,如果不设置默认是3份。 osd pool default min size = 1 #缺省值是0.这是处于degraded状态的副本数目,它应该小于osd pool default size的值,为存储池中的object设置最小副本数目来确认写操作。即使集群处于degraded状态。如果最小值不匹配,Ceph将不会确认写操作给客户端。 osd pool default pg num = 333 #每个存储池默认的pg数 osd pool default pgp num = 333 #PG和PGP的个数应该保持一致。PG和PGP的值很大程度上取决于集群大小。 osd crush chooseleaf type = 1 #CRUSH规则用到chooseleaf时的bucket的类型,默认值就是1. [osd] osd_journal_size = 5120 [mon] mon osd allow primary affinity = true
配置文件参数解释官网链接:http://docs.ceph.com/docs/master/rados/configuration/mon-config-ref/#data
注:下面这种[mon]的配置方式,将来的版本中将删除该要求,不再一个[mon.id]一个区域了
[global] fsid = 9ec20e59-1033-4505-920d-113183167b31 mon initial members = 153,154,155 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx public_network = 192.168.1.0/24 [osd] osd_journal_size = 5120 [mon] mon osd allow primary affinity = true mon host = ceph-153,ceph-154,ceph-155 [mon.153] host = ceph-153 mon addr = 192.168.1.153:6789 [mon.154] host = ceph-154 mon addr = 192.168.1.154:6789 [mon.155] host = ceph-155 mon addr = 192.168.1.155:6789
# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *' #为群集创建密钥环,并生成监视密钥。
creating /tmp/ceph.mon.keyring
#ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --set-uid=0 --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow *' --cap mgr 'allow *' #生成一个管理员密钥环,生成一个client.admin用户,并将该用户添加到密钥环中。
creating /etc/ceph/ceph.client.admin.keyring
# ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring #将client.admin密钥添加到ceph.mon.keyring
importing contents of /etc/ceph/ceph.client.admin.keyring into /tmp/ceph.mon.keyring
# mkdir /var/lib/ceph/mon/ceph-ceph-153 #创建目录,这里有点绕第一个ceph是集群的名称,第一个ceph集群默认的集群名称就是ceph。后面的ceph-153是主机名
# monmaptool --create --add ceph-153 192.168.1.153 --add ceph-154 192.168.1.154 --add ceph-155 192.168.1.155 --fsid 9ec20e59-1033-4505-920d-113183167b31 /tmp/monmap #使用主机名,主机IP地址和FSID生成监视器映射。保存为/tmp/monmap。其实这里可以把/tmp/monmap发送到其他的mon节点的/tmp目录下面,其他的mon节点就可以省去monmaptool --create --add 这步了,这里为了演示就不scp了。
monmaptool: monmap file /tmp/monmap
monmaptool: set fsid to 9ec20e59-1033-4505-920d-113183167b31
monmaptool: writing epoch 0 to /tmp/monmap (1 monitors)
[root@bogon ~]# mkdir /var/lib/ceph/mon/ceph-ceph-153
# chown -R ceph:ceph /var/lib/ceph/
# chown ceph:ceph /tmp/monmap
# chown ceph:ceph /tmp/ceph.mon.keyring
# sudo -u ceph ceph-mon --mkfs -i ceph-153 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring #使用监视器映射和密钥环填充监视器守护程序。
ceph-mon: set fsid to 9ec20e59-1033-4505-920d-113183167b31
ceph-mon: created monfs at /var/lib/ceph/mon/ceph-ceph-153 for mon.ceph-153
# scp /etc/ceph/* 192.168.1.154:/etc/ceph/
# scp /etc/ceph/* 192.168.1.155:/etc/ceph/
# scp /tmp/ceph.mon.keyring 192.168.1.154:/tmp/
# scp /tmp/ceph.mon.keyring 192.168.1.155:/tmp/
# /usr/bin/ceph-mon -f --cluster ceph --id ceph-153 --setuser ceph --setgroup ceph #启动ceph-mon,应该加上&,但是第一次先让其他前台运行吧
starting mon.ceph-153 rank 0 at 192.168.1.153:6789/0 mon_data /var/lib/ceph/mon/ceph-ceph-153 fsid 9ec20e59-1033-4505-920d-113183167b31
现在再154上面的操作:
# monmaptool --create --add ceph-154 192.168.1.154 --fsid 9ec20e59-1033-4505-920d-113183167b31 /tmp/monmap
# mkdir /var/lib/ceph/mon/ceph-ceph-154
# chown -R ceph:ceph /var/lib/ceph/
# chown ceph:ceph /tmp/monmap
# chown ceph:ceph /tmp/ceph.mon.keyring
# sudo -u ceph ceph-mon --mkfs -i ceph-154 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
# /usr/bin/ceph-mon -f --cluster ceph --id ceph-154 --setuser ceph --setgroup ceph
starting mon.ceph-154 rank 0 at 192.168.1.154:6789/0 mon_data /var/lib/ceph/mon/ceph-ceph-154 fsid 9ec20e59-1033-4505-920d-113183167b31
现在再155上面的操作:
# monmaptool --create --add ceph-154 192.168.1.155 --fsid 9ec20e59-1033-4505-920d-113183167b31 /tmp/monmap
# mkdir /var/lib/ceph/mon/ceph-ceph-155
# chown -R ceph:ceph /var/lib/ceph/
# chown ceph:ceph /tmp/monmap
# chown ceph:ceph /tmp/ceph.mon.keyring
# sudo -u ceph ceph-mon --mkfs -i ceph-155 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
# /usr/bin/ceph-mon -f --cluster ceph --id ceph-155 --setuser ceph --setgroup ceph
starting mon.ceph-155 rank 0 at 192.168.1.155:6789/0 mon_data /var/lib/ceph/mon/ceph-ceph-155 fsid 9ec20e59-1033-4505-920d-113183167b31
然后在192.168.1.153上面查看一下:
# lsof -i :6789 #有图中可以看出已经三台主机已经连接上了
# cat /etc/hosts #都在hosts文件里面定义了,不然可能会有DNS反解
192.168.1.153 ceph-153 192.168.1.154 ceph-154 192.168.1.155 ceph-155
# ceph -s #查看集群状态
cluster 9ec20e59-1033-4505-920d-113183167b31
health HEALTH_ERR #添加OSD并启动它们后,展示位置组运行状况错误就会消失。
64 pgs are stuck inactive for more than 300 seconds
64 pgs stuck inactive
64 pgs stuck unclean
no osds
monmap e3: 3 mons at {ceph-153=192.168.1.153:6789/0,ceph-154=192.168.1.154:6789/0,ceph-155=192.168.1.155:6789/0}
election epoch 22, quorum 0,1,2 ceph-153,ceph-154,ceph-155
osdmap e1: 0 osds: 0 up, 0 in
flags sortbitwise,require_jewel_osds
pgmap v2: 64 pgs, 1 pools, 0 bytes data, 0 objects
0 kB used, 0 kB / 0 kB avail
64 creating3.4 创建osd集群
创建新的OSD(三台机器上面都执行)
# ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vdc /dev/vdb1 #前面是data盘符,自动会创建一个/dev/vdc1来存放数据,后面是journal存放分区
#ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vdd /dev/vdb2
# ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vde /dev/vdb3
#ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vdf /dev/vdb4
#ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vdg /dev/vdb5
prepare_device: OSD will not be hot-swappable if journal is not the same device as the osd data prepare_device: Journal /dev/vdb5 was not prepared with ceph-disk. Symlinking directly. Creating new GPT entries. The operation has completed successfully. meta-data=/dev/vdg1 isize=2048 agcount=4, agsize=3276735 blks = sectsz=512 attr=2, projid32bit=1 = crc=0 finobt=0 data = bsize=4096 blocks=13106939, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=0 log =internal log bsize=4096 blocks=6399, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 The operation has completed successfully.
注:
#ceph-disk prepare -v --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vdg /dev/vdb5
#可以通过加-v的方式查看此工具创建osd的详细过程,主要用的是一个sgdisk的分区工具,https://xiexianbin.cn/linux/2017/01/01/sgdisk-basic #此篇博客对于此工具的使用记录的还是很详细的。
分别在机器上面创建ceph.keyring
如在192.168.1.153上面执行:
# ceph-create-keys --id ceph-153 #其他的就是把cepbh-153改为ceph-154等
INFO:ceph-create-keys:Key exists already: /etc/ceph/ceph.client.admin.keyring
INFO:ceph-create-keys:Talking to monitor...
INFO:ceph-create-keys:Talking to monitor...
INFO:ceph-create-keys:Talking to monitor...
# chown -R ceph:ceph /dev/vdb* #都要授权成ceph,不然激活osd的时候报错。
#ceph-disk activate /dev/vdc1
#ceph-disk activate /dev/vdd1
#ceph-disk activate /dev/vde1
#ceph-disk activate /dev/vdf1
#ceph-disk activate /dev/vdg1
got monmap epoch 3
added key for osd.4
Created symlink from /etc/systemd/system/ceph-osd.target.wants/ceph-osd@4.service to /usr/lib/systemd/system/ceph-osd@.service.
查看一下:
# ps -ef|grep ceph
#可以看到一块硬盘是一个osd进程,然后id编号是从0开始的。然后编号依次递增,那么154的id编号就应该是5-9.

#从上图可以看出我们这个简单小集群是OK的状态,mons那里有三个主机IP,osds那里可以看到15个osd是启动状态,总空间也是15*50G=750G
一些小注意:
激活OSD报错问题:
# ceph-disk activate /dev/vdc1
mount_activate: Failed to activate ceph-disk: Error: ceph osd create failed: Command '/usr/bin/ceph' returned non-zero exit status 1: 2017-08-16 15:18:51.248000 7f3072ccb700 -1 auth: unable to find a keyring on /var/lib/ceph/bootstrap-osd/ceph.keyring: (2) No such file or directory 2017-08-16 15:18:51.248025 7f3072ccb700 -1 monclient(hunting): ERROR: missing keyring, cannot use cephx for authentication 2017-08-16 15:18:51.248028 7f3072ccb700 0 librados: client.bootstrap-osd initialization error (2) No such file or directory Error connecting to cluster: ObjectNotFound
解决:# ceph-create-keys --id ceph-01
# ceph-disk activate /dev/vdc1
got monmap epoch 1 mount_activate: Failed to activate ceph-disk: Error: ['ceph-osd', '--cluster', 'ceph', '--mkfs', '--mkkey', '-i', u'0', '--monmap', '/var/lib/ceph/tmp/mnt.diKBMX/activate.monmap', '--osd-data', '/var/lib/ceph/tmp/mnt.diKBMX', '--osd-journal', '/var/lib/ceph/tmp/mnt.diKBMX/journal', '--osd-uuid', u'31ba28a6-a52b-4dff-a58e-d87d1bc5b613', '--keyring', '/var/lib/ceph/tmp/mnt.diKBMX/keyring', '--setuser', 'ceph', '--setgroup', 'ceph'] failed : 2017-08-16 15:28:32.770285 7f570e2cb800 -1 filestore(/var/lib/ceph/tmp/mnt.diKBMX) mkjournal error creating journal on /var/lib/ceph/tmp/mnt.diKBMX/journal: (13) Permission denied 2017-08-16 15:28:32.770321 7f570e2cb800 -1 OSD::mkfs: ObjectStore::mkfs failed with error -13 2017-08-16 15:28:32.770441 7f570e2cb800 -1 ** ERROR: error creating empty object store in /var/lib/ceph/tmp/mnt.diKBMX: (13) Permission denied
解决:chown -R ceph:ceph /dev/vdb1 #对应的journal授权属主属组
关于创建osd指定目录和分区的区别
我们可能习惯了将磁盘分区挂载到/data01,/data02这样的形式。如果你创建osd的时候或者激活的时候指定的是下面的语句:
# ceph-disk activate /data01 #类似于这种将data存放的磁盘分区换成目录的形式。
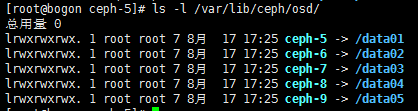
#就成了上图中的形式,指向的不是盘符而是软连接到目录的形式。
而直接指定盘符而非目录的话是下面截图的形式:

关于ceph -s的一些警告:
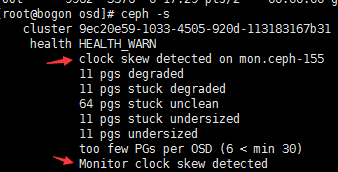
#上面第一个箭头指向问题(Monitor clock skew detected):是说集群中的时间有偏差,所以保证各节点的时间要一致。
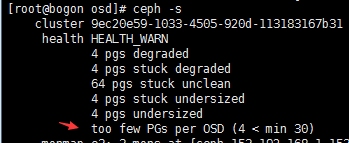
#上面第二个箭头指向的问题(too few PGs per OSD (4 < min 30)):是说osd集群中的pg和pgs数太少了,一个OSD最小也得来30个pgs啊
# ceph osd pool stats #先获取池的名称
pool rbd id 0
nothing is going on
#ceph osd pool set rbd pg_num 500 #pg和pgs都给设置成500,你就大概这么算本地有五个osd*30*副本数=约等于一个比较大的值
# ceph osd pool set rbd pgp_num 500
# ceph osd pool get rbd pg_num #查看一下设置成功了,需要注意, pg_num只能增加, 不能缩小
pg_num: 500
# ceph osd pool get rbd pgp_num
pgp_num: 50
博文来自:www.51niux.com
3.5 添加一个osd节点
上面分别在192.168.1.153-155上面创建了mon和osd,现在我们再192.168.1.156上面创建一个纯osd,然后添加到集群中去。
# scp /etc/ceph/* 192.168.1.156:/etc/ceph/ #先从192.168.1.153上面把/etc/ceph下面的内容拷贝过来
查看现在osd的状态:
# ceph osd dump #查看osd的映射信息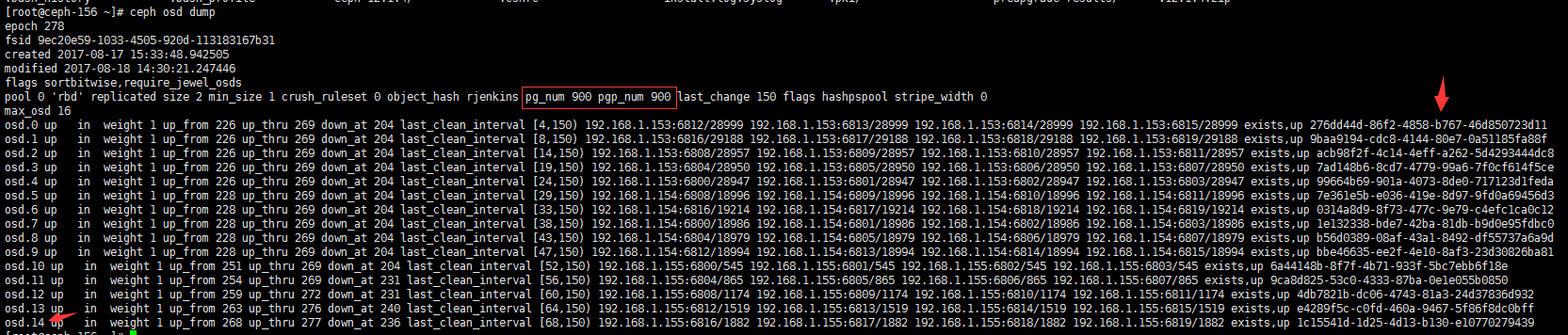
#从这个我们可以看到osd的id号已经分到了14,然后每个的weight都是1(这个是通过修改了CRUSH映射),然后看结尾会发现每一个osd都有一个唯一的uuid,前面我们没有设,没关系,启动的时候会给分配一个。
# ceph osd tree #可以看下osd的目录树
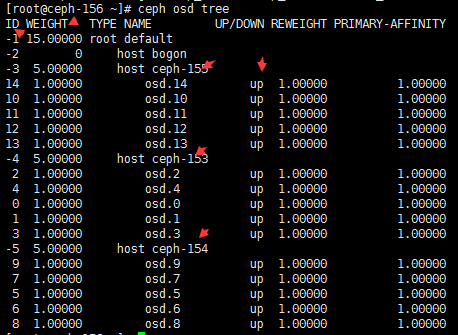
#这个输出就简单点了,可以看到哪个主机下面有哪几个osd,然后状态是up还是down状态。
在新增节点上面创建osd:
官网链接:http://docs.ceph.com/docs/master/install/manual-deployment/#long-form #上面我们用的是简单的方式,这里我们用复杂的方式。
创建uuid号为了给OSD分配:
# uuidgen b737261e-8a8d-4cb0-baf1-53c08c42be2a # uuidgen ccffaf82-17db-4f95-b764-ff9864073ed1 # uuidgen 6656314f-11b2-4977-b54e-efdf90e1dc86 # uuidgen 534758e8-5425-49ef-9dcf-f17172914326 # uuidgen c5e50a75-dcb6-49f2-a4b7-3a35707a4c45
创建OSD,如果没有指定UUID,将会在OSD首次启动时分配一个:
# ceph osd create b737261e-8a8d-4cb0-baf1-53c08c42be2a 15 #是按照ceph osd create [{uuid} [{id}]]这个格式来的
15
# ceph osd create ccffaf82-17db-4f95-b764-ff9864073ed1 16
16
# ceph osd create 6656314f-11b2-4977-b54e-efdf90e1dc86 17
17
# ceph osd create 534758e8-5425-49ef-9dcf-f17172914326 18
18
# ceph osd create c5e50a75-dcb6-49f2-a4b7-3a35707a4c45 #这里我们直接给了一个uuid,也是会自动分配一个id号的
19在新的OSD主机上创建默认目录:
#mkfs.xfs /dev/vdc -f #都格式化xfs分区
#mkfs.xfs /dev/vdd -f
#mkfs.xfs /dev/vde -f
#mkfs.xfs /dev/vdf -f
#mkfs.xfs /dev/vdg -f
#mkdir /var/lib/ceph/osd/ceph-{15..19} #创建挂载目录
#mount /dev/vdc /var/lib/ceph/osd/ceph-15 #都挂载到指定目录
#mount /dev/vdd /var/lib/ceph/osd/ceph-16
#mount /dev/vde /var/lib/ceph/osd/ceph-17
#mount /dev/vdf /var/lib/ceph/osd/ceph-18
#mount /dev/vdg /var/lib/ceph/osd/ceph-19
#ceph-osd -i 15 --mkfs --mkjournal --mkkey --osd-uuid b737261e-8a8d-4cb0-baf1-53c08c42be2a --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-15 --osd-journal=/dev/vdb1
#ceph-osd -i 16 --mkfs --mkjournal --mkkey --osd-uuid ccffaf82-17db-4f95-b764-ff9864073ed1 --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-16 --osd-journal=/dev/vdb2
#ceph-osd -i 17 --mkfs --mkjournal --mkkey --osd-uuid 6656314f-11b2-4977-b54e-efdf90e1dc86 --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-17 --osd-journal=/dev/vdb3
#ceph-osd -i 18 --mkfs --mkjournal --mkkey --osd-uuid 534758e8-5425-49ef-9dcf-f17172914326 --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-18 --osd-journal=/dev/vdb4
#ceph-osd -i 19 --mkfs --mkjournal --mkkey --osd-uuid c5e50a75-dcb6-49f2-a4b7-3a35707a4c45 --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-19 --osd-journal=/dev/vdb5
#上面的格式-i是osd的id号,--osd-uuid后面跟的是osd的uuid号,--osd-data后面跟的是data的存放目录,--osd-journal后面跟的是journal的盘符分区
#加 --mkkey 选项运行 ceph-osd 之前,此目录必须是空的;另外,如果集群名字不是默认值,还要给 ceph-osd 指定 --cluster 选项。注册OSD认证key:
# ceph auth list #查看ceph集群中的认证用户及相关的key,下面是部分内容
installed auth entries: osd.0 key: AQB9X5VZakP+HBAA0dnjXu7FDSTj4vgjpb7V4w== caps: [mon] allow profile osd caps: [osd] allow * osd.1 key: AQDBX5VZW2u2ChAAzDUF22je3SILbh7EwjMUbw== caps: [mon] allow profile osd caps: [osd] allow *
#根据上面的内容你会发现一个osd都有一个key。
# ceph auth add osd.15 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-15/keyring
added key for osd.15 #这是结果,提示你添加注册成功
# ceph auth add osd.16 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-16/keyring
added key for osd.16
# ceph auth add osd.17 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-17/keyring
added key for osd.17
# ceph auth add osd.18 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-18/keyring
added key for osd.18
# ceph auth add osd.19 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-19/keyring
added key for osd.19
#格式是:sudo ceph auth add osd.{osd-num} osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/{cluster-name}-{osd-num}/keyring#这种情况很多时候是更换硬盘的时候会出现,如下面的提示:
# ceph auth add osd.15 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-15/keyring
Error EINVAL: entity osd.15 exists but key does not match
解决办法:# ceph auth del osd.15 #将之前的注册key删除掉。
把此节点加入 CRUSH MAP:
# ceph osd crush add-bucket ceph-156 host #我们的主机是ceph-156
added bucket ceph-156 type host to crush map
#语句格式是:ceph [--cluster {cluster-name}] osd crush add-bucket {hostname} host
把此 Ceph 节点放入 default 根下:
# ceph osd crush move ceph-156 root=default
moved item id -6 name 'ceph-156' to location {root=default} in crush map
把此 OSD 加入 CRUSH MAP:
# ceph osd crush add osd.15 1.0 host=ceph-156
add item id 15 name 'osd.15' weight 1 at location {host=ceph-156} to crush map #这里是结果提示你已经加入到crush map中了
# ceph osd crush add osd.16 1.0 host=ceph-156
add item id 16 name 'osd.16' weight 1 at location {host=ceph-156} to crush map
# ceph osd crush add osd.17 1.0 host=ceph-156
add item id 17 name 'osd.17' weight 1 at location {host=ceph-156} to crush map
# ceph osd crush add osd.18 1.0 host=ceph-156
add item id 18 name 'osd.18' weight 1 at location {host=ceph-156} to crush map
# ceph osd crush add osd.19 1.0 host=ceph-156
add item id 19 name 'osd.19' weight 1 at location {host=ceph-156} to crush map格式就是:ceph [--cluster {cluster-name}] osd crush add {id-or-name} {weight} [{bucket-type}={bucket-name} ...]
#把此 OSD 加入 CRUSH map之后,它就能接收数据了。你也可以反编译 CRUSH map.
# ceph osd crush tree #可以通过此命令看看是否加入到了crush中
# ceph osd tree #或者用这个直观的查看一下目录树,osd是up还是down,属于哪个主机。
启动OSD:
把 OSD 加入 Ceph 后, OSD 已经在配置里了。但它还没开始运行,这时处于 down 且 in 状态,要启动进程才能收数据。
#chown -R ceph:ceph /dev/vdb* #sudo -u ceph /usr/bin/ceph-osd -i 15 --pid-file /var/run/ceph/osd.15.pid -c /etc/ceph/ceph.conf --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-15 --osd-journal=/dev/vdb1 #sudo -u ceph /usr/bin/ceph-osd -i 16 --pid-file /var/run/ceph/osd.16.pid -c /etc/ceph/ceph.conf --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-16 --osd-journal=/dev/vdb2 #sudo -u ceph /usr/bin/ceph-osd -i 17 --pid-file /var/run/ceph/osd.17.pid -c /etc/ceph/ceph.conf --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-17 --osd-journal=/dev/vdb3 #sudo -u ceph /usr/bin/ceph-osd -i 18 --pid-file /var/run/ceph/osd.18.pid -c /etc/ceph/ceph.conf --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-18 --osd-journal=/dev/vdb4 #sudo -u ceph /usr/bin/ceph-osd -i 19 --pid-file /var/run/ceph/osd.19.pid -c /etc/ceph/ceph.conf --cluster ceph --osd-data=/var/lib/ceph/osd/ceph-19 --osd-journal=/dev/vdb5
#这是命令启动方式以ceph用户,指定osd的id,指定pid-file,指定配置文件,指定集群组,指定data目录,指定journal位置
#上面的命令注意:chown -R ceph:ceph /dev/vdb* 给journal目录授权,不然执行完命令也不报错,进程也拉不起来。
# ps -ef|grep ceph

有个坑:
ceph-osd -i 15 --mkfs --mkjournal --mkkey --osd-uuid 9ec20e59-1033-4505-920d-113183167b31 --cluster ceph #上面这种方式不能再data分区下面创建软连接到journal,还要自己做软连接,下图是正确的目录结构:

#关于这个journal_uuid可以查看此博客:http://blog.csdn.net/guzyguzyguzy/article/details/46729391
#systemctl start ceph-osd@18 #如果想用这种方式启动的话,就要检查data分区下面是否有journal的软连接,如果没有软连接的话,这种方式就不行,就启动不了osd服务。
要让守护进程开机自启,必须创建一个空文件:sudo touch /var/lib/ceph/osd/{cluster-name}-{osd-num}/sysvinit

#查看一下五个osd节点已经都启动起来了。
3.6 删除osd

#如上图,我们把这几个down的osd从集群中删除掉
把osd从集群中踢出去
#ceph osd out 20 #ceph osd out 21 #ceph osd out 22
#删除 OSD 前,它通常是 up 且 in 的,要先把它踢出集群,以使 Ceph 启动重新均衡、把数据拷贝到其他 OSD 。删除 OSD 前,它通常是 up 且 in 的,要先把它踢出集群,以使 Ceph 启动重新均衡、把数据拷贝到其他 OSD 。
#一旦把 OSD 踢出( out )集群, Ceph 就会开始重新均衡集群、把归置组迁出将删除的 OSD 。你可以用 ceph (#ceph w)工具观察此过程。你会看到归置组状态从 active+clean 变为 active, some degraded objects 、迁移完成后最终回到 #active+clean 状态。( Ctrl-c 中止)
#然后就将对应的osd进程关闭掉。
从CRUSH图删除osd
#ceph osd crush remove osd.20 #ceph osd crush remove osd.21 #ceph osd crush remove osd.22
#从图中看已经从crush映射图中删除掉了。
删除 OSD 认证密钥
# ceph auth del osd.20 updated # ceph auth del osd.21 updated # ceph auth del osd.22 updated
从OSD集群删除OSD

#从上图可以看出现在这三个osd还存在osd集群中。
# ceph osd rm osd.20 removed osd.20 # ceph osd rm osd.21 removed osd.21 # ceph osd rm osd.22 removed osd.22
#其他
如果ceph.conf配置文件里面都定义了[osd],如下面这种:
[osd.1]
host = {hostname}#还要登录到对端的主机上面删除掉ceph.conf 配置文件里面对应的设置,然后从保存 ceph.conf 主拷贝的主机,把更新过的 ceph.conf 拷贝到集群其他主机的 /etc/ceph 目录下。
注:那如何删除一个osd节点呢?
前面的那些都做完之后,加入我们的osd节点名称再集群里面叫localhost:# ceph osd crush rm localhos(如果里面的osd不删除的话会提示你非空不能删除)
#下面是简单的添加osd节点的方式:
#scp /var/lib/ceph/bootstrap-osd/ceph.keyring 192.168.1.160:/var/lib/ceph/bootstrap-osd/ #这个key集群里面的所有osd节点是一样的 #ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vdc /dev/vdb1 #ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vdd /dev/vdb2 #ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vde /dev/vdb3 #ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vdf /dev/vdb4 #ceph-disk prepare --cluster ceph --cluster-uuid 9ec20e59-1033-4505-920d-113183167b31 --fs-type xfs /dev/vdg /dev/vdb5 #chown -R ceph:ceph /dev/vdb* #chown -R ceph:ceph /var/lib/ceph/ #ceph-disk active /dev/vdc1 #ceph-disk active /dev/vdd1 #ceph-disk active /dev/vde1 #ceph-disk active /dev/vdf1 #ceph-disk active /dev/vdg1 #就是第一点/var/lib/ceph/bootstrap-osd/ceph.keyring是通用的,第二个uuid是cluster集群的uuid值
3.7 osd的一些查看方法
# ceph -w #查看ceph的实时状态
# ceph health #查看ceph的监控状态
# ceph health detail #查看集群监控状态的细节
# ceph -s #检查信息状态信息
# ceph df #查看ceph存储空间
# ceph auth list #查看ceph集群中的认证用户及相关的key
# ceph --admin-daemon /var/run/ceph/ceph-osd.{osd.num}.asok config show|grep osd_journal #可以查看此osd的journal日志的位置,而不加grep的话是查看此osd的详细参数
# ceph mon dump #查看mon的映射状态
# ceph osd stat #查看osd的状态
# ceph osd dump #查看osd的映射信息

# ceph osd tree #查看osd的目录树
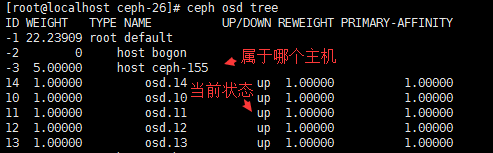
# ceph-disk list #列出硬盘分区和OSD
