Ceph跟着官网学一波(三)
一、Ceph存储集群
官网链接:http://docs.ceph.com/docs/master/rados/
常用命令的man帮助:http://docs.ceph.com/docs/master/rados/man/
故障排查:http://docs.ceph.com/docs/master/rados/troubleshooting/
CEPH存储群APIS:http://docs.ceph.com/docs/master/rados/api/
1.1 配置
1.1.1 存储设备:
有两个Ceph守护进程在磁盘上存储数据:
Ceph OSD(或对象存储守护进程)是大多数数据存储在Ceph中的地方。 一般来说,每个OSD由单个存储设备支持,如传统硬盘(HDD)或固态硬盘(SSD)。 OSD也可以由一些设备组合来支持,如大多数数据的HDD,以及一些元数据的SSD(或SSD的分区)。 群集中的OSD数量通常是存储数据量,存储设备的大小以及冗余级别和类型(复制或擦除编码)的函数。
Ceph Monitor守护进程管理关键的集群状态,如集群成员资格和认证信息。 对于较小的集群,需要几千兆字节,但是对于较大的集群,监视数据库可以达到几十或几百GB。
OSD管理数据存储由两种方式,12.2版本后开始默认使用BlueStore,以前默认和唯一的选择是FILESTORE。
BLUESTORE:
BlueStore是专门用于管理Ceph OSD工作负载的磁盘上的数据的专用存储后端。它是由过去十年来使用FileStore支持和管理OSD的经验的。关键BlueStore功能包括:
直接管理存储设备。 BlueStore消耗原始块设备或分区。这避免了任何介入的抽象层(如本地文件系统,如XFS),可能会限制性能或增加复杂性。
使用RocksDB进行元数据管理。我们嵌入RocksDB的键/值数据库,以便管理内部元数据,例如从对象名称到磁盘上的块位置的映射。
完整的数据和元数据校验和。默认情况下,写入BlueStore的所有数据和元数据都受到一个或多个校验和的保护。没有数据或元数据将从磁盘读取或返回给用户,而不经过验证。
内联压缩。在写入磁盘之前,写入的数据可以被压缩。
多设备元数据分层。 BlueStore允许将其内部日志(预写日志)写入单独的高速设备(如SSD,NVMe或NVDIMM)以提高性能。如果大量更快的存储空间可用,内部元数据也可以存储在更快的设备上。
高效的写时复制。 RBD和CephFS快照依赖于在BlueStore中高效实现的写时复制机制。这样可以实现高效的IO,用于常规快照和擦除编码池(依靠克隆来实现高效的两阶段提交)。
BlueStore的配置参考:http://docs.ceph.com/docs/master/rados/configuration/bluestore-config-ref/
BlueStore迁移:http://docs.ceph.com/docs/master/rados/operations/bluestore-migration/
FILESTORE:
FileStore是在Ceph中存储对象的传统方法。 它依赖于标准文件系统(通常是XFS)与一些元数据的键/值数据库(传统上是LevelDB,现在是RocksDB)。
FileStore经过良好的测试和广泛应用于生产,但由于其整体设计和依赖传统文件系统存储对象数据而遭受许多性能缺陷。
虽然FileStore通常能够在大多数与POSIX兼容的文件系统(包括btrfs和ext4)上运行,但我们只推荐使用XFS。 btrfs和ext4都有已知的错误和缺陷,并且它们的使用可能导致数据丢失。 默认情况下,所有Ceph配置工具都将使用XFS。
FileStore的配置参考:http://docs.ceph.com/docs/master/rados/configuration/filestore-config-ref/
1.1.2 配置Ceph:
Ceph配置文件定义:
集群的身份 身份验证设置 集群成员 主机名 主机地址 keyring路径 日志路径 数据路径 其他运行时选项
配置文件可以配置Ceph存储集群中的所有Ceph守护程序,或者特定类型的所有Cep守护程序。 要配置一系列后台进程,必须将这些设置包含在接收配置的进程中,如下所示:
[global] #[全局]下的设置影响Ceph存储集群中的所有后台进程。 [osd] #[osd]下的设置会影响Ceph Storage Cluster中的所有ceph-osd守护程序,并覆盖[global]中相同的设置。 [mon] #[mon]下的设置影响Ceph Storage Cluster中的所有ceph-mon守护进程,并覆盖[global]中相同的设置。 [mds] #[mds]下的设置会影响Ceph Storage Cluster中的所有ceph-mds守护程序,并覆盖[global]中的相同设置。 [client] #[客户端]下的设置会影响所有Ceph客户端(例如,安装的Ceph文件系统,安装的Ceph块设备等)。
NETWORKS
官网链接:http://docs.ceph.com/docs/master/rados/configuration/network-config-ref/
网络配置对于构建高性能Ceph存储集群至关重要。 Ceph存储集群不代表Ceph客户端执行请求路由或调度。相反,Ceph客户端直接向Ceph OSD守护进程请求。 Ceph OSD Daemons代表Ceph客户端执行数据复制,这意味着复制和其他因素在Ceph Storage Cluster网络上施加额外的负载。
现在快速启动配置提供了一个简单的Ceph配置文件,仅设置监视器IP地址和守护程序主机名。除非指定集群网络,否则Ceph承担一个单一的“公共”网络。 Ceph功能只适用于公共网络,但是在大型群集中,第二个“群集”网络可能会显着提升性能。
建议运行带有两个网络的Ceph存储集群:公共(前端)网络和集群(后端)网络。为了支持两个网络,每个Ceph节点都需要有多个NIC。
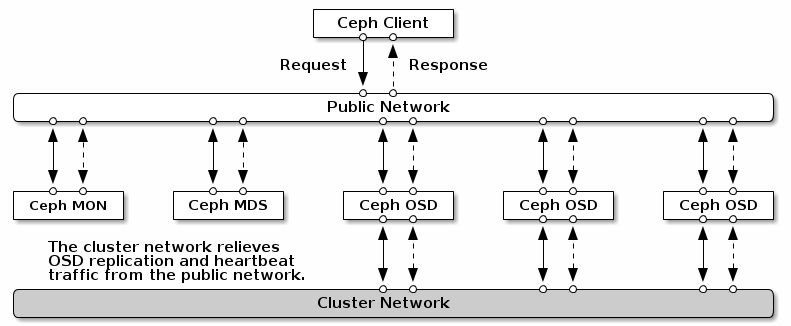
考虑运行两个不同的网络有几个原因:
性能:Ceph OSD Daemons处理Ceph客户端的数据复制。当Ceph OSD守护进程多次复制数据时,Ceph OSD守护进程之间的网络负载与Ceph客户端和Ceph存储群集之间的网络负载相差很小。这可能会引入延迟并产生性能问题。恢复和重新平衡也可能在公共网络上引入显着的延迟。
ceph如何复制数据:http://docs.ceph.com/docs/master/architecture/#scalability-and-high-availability
ceph有关心跳流量:http://docs.ceph.com/docs/master/rados/configuration/mon-osd-interaction/
安全:公网可能会有DOS攻击。当Ceph OSD后台程序之间的流量中断时,放置组可能不再反映活动+清除状态,这可能会阻止用户读取和写入数据。打败这种类型的攻击的好方法是维护一个完全不同的群集网络,不能直接连接到互联网。另外,考虑使用消息签名来打败欺骗攻击。
默认情况下,守护进程绑定到6800:7300范围内的端口。
Ceph监视器默认侦听端口6789。 此外,Ceph监视器始终在公共网络上运行。
Ceph元数据服务器侦听从端口6800开始的公共网络上的第一个可用端口。请注意,此行为不是确定性的,因此,如果在同一主机上运行多个OSD或MDS,或者如果重新启动内部守护程序 一个短暂的时间,守护进程将绑定到更高的端口。 您应该默认打开整个6800-7300范围如有有防火墙。
Ceph节点上的每个Ceph OSD守护程序最多可以使用四个端口:一个用于与客户和监视器交谈。一个用于向其他OSD发送数据。两个用于心跳。

要配置Ceph网络,必须将网络配置添加到配置文件的[global]部分。
配置好网络后,您可以重新启动群集或重新启动每个守护程序。 Ceph守护程序动态绑定,因此如果更改网络配置,则不必一次重新启动整个群集。
公共网络示例:
[global]
public network = {public-network/netmask}集群网络示例:
#如果您声明集群网络,OSD将通过集群网络路由心跳,对象复制和恢复流量。 与使用单个网络相比,这可能会提高性能。
[global]
cluster network = {cluster-network/netmask}CEPH DAEMONS(ceph守护进程)
Ceph有一个适用于所有守护程序的网络配置要求:Ceph配置文件必须为每个守护程序指定主机(当然也不是非要指定本host)。 Ceph还要求Ceph配置文件指定监视器IP地址及其端口。
先看下面的配置文件例子:
[mon.a]
host = {hostname} mon addr = {ip-address}:6789
[osd.0]
host = {hostname} #host:主机设置是主机的短名称(即不是fqdn)。 它也不是IP地址。 在命令行中输入主机名-s以检索主机的名称。不必为守护程序设置主机IP地址。 如果有静态IP配置并且运行公共和群集网络,则Ceph配置文件可能会为每个守护程序指定主机的IP地址。 要为守护程序设置静态IP地址,以下选项应显示在ceph.conf文件的守护程序实例部分中。
[osd.0]
public addr = {host-public-ip-address}
cluster addr = {host-cluster-ip-address}NETWORK CONFIG SETTINGS(网络配置设置)
不需要网络配置设置。 除非您专门配置集群网络,Ceph将承担所有主机运行的公共网络。
公共网络
公共网络配置允许您专门定义公网的IP地址和子网。 您可以使用特定守护程序的public addr设置来专门分配静态IP地址或覆盖公网设置。
public network #公共(前端)网络的IP地址和网络掩码(例如,192.168.0.0/24)。 设置在[全局]。 可以指定以逗号分隔的子网。 public addr #公共(前端)网络的IP地址。 为每个守护进程设置。
集群网络
集群网络配置允许声明集群网络,并具体定义集群网络的IP地址和子网。 可以使用特定OSD守护程序的集群地址设置专门分配静态IP地址或覆盖群集网络设置。
cluster network #集群(后端)网络的IP地址和网络掩码(例如,10.0.0.0/24)。设置在[全局]。您可以指定以逗号分隔的子网。 cluster addr #集群(后端)网络的IP地址。 为每个守护进程设置。
BIND(绑定)
绑定设置设置默认端口范围Ceph OSD和MDS守护进程使用。 默认范围为6800:7300。 确保IP表配置允许您使用配置的端口范围。还可以使Ceph守护程序绑定到IPv6地址而不是IPv4地址。
ms bind port min #OSD或MDS守护程序将绑定的最小端口号。默认是6800端口 ms bind port max #OSD或MDS守护程序将绑定的最大端口号。默认是7300端口 ms bind ipv6 #默认是false,使Ceph守护程序绑定到IPv6地址。 目前,信使使用IPv4或IPv6,但不能同时使用。 public bind addr # 如果设置了public bind addr,Ceph MON守护程序将在本地绑定到它,并在monmaps中使用public addr向对等体发布其地址。 此行为仅限于MON守护进程。
HOSTS
Ceph期望至少有一个在Ceph配置文件中声明的监视器,每个声明的监视器下都有一个mon addr设置。 Ceph希望在Ceph配置文件中的每个声明的监视器,元数据服务器和OSD下的主机设置。 可选地,可以为监视器分配优先级,并且如果指定,则客户端将始终连接到具有较低优先级值的监视器。
mon addr #客户端可以用来连接Ceph监视器的{hostname}:{port}条目列表。 如果没有设置,Ceph搜索[mon.*]部分。
mon priority #声明的监视器的优先级,当客户端尝试连接到群集时选择监视器时,较低的值被更优先。默认是0.
host #主机名。 对特定守护程序实例使用此设置(例如[osd.0])。默认是localhost.千万不,要使用localhost。TCP
Ceph默认禁用TCP缓冲。
ms tcp nodelay #默认是true.Ceph启用ms tcp nodelay,以便每个请求立即发送(无缓冲)。禁用Nagle的算法会增加网络流量,从而导致延迟。如果您遇到大量小数据包,可以尝试禁用ms tcp nodelay。 ms tcp rcvbuf #网络连接接收端的套接字缓冲区的大小。 默认情况下禁用。默认是0. ms tcp read timeout #如果客户端或守护进程向另一个Ceph守护程序发出请求,并且不会丢弃未使用的连接,则ms tcp是秒数。默认是900秒也就是15分钟。
Auth Settings(授权设置)
CEPHX配置参考(cephx协议默认启用)
要创建用户,请参阅用户管理:http://docs.ceph.com/docs/master/rados/operations/user-management/
有关Cephx架构的详细信息,请参阅架构 - 高可用性认证:http://docs.ceph.com/docs/master/architecture/#high-availability-authentication
部署:
auth_cluster_required = cephx #设置为node就是不启用验证 auth_service_required = cephx auth_client_required = cephx
#上面配置文件中的三句话表示Ceph默认启用身份验证
手动部署群集时,必须手动引导监视器,并创建client.admin用户和密钥环。
要引导bootstrap monitors请按照:http://docs.ceph.com/docs/master/install/manual-deployment/#monitor-bootstrapping #步骤操作
当cephx启用时,Ceph将在默认搜索路径中查找密钥环,其中包括/etc/ceph/$cluster.$name.keyring。
CONFIGURATION SETTINGS(配置设置)
#关于启用 auth cluster required #如果启用,Ceph存储集群守护程序(即,ceph-mon,ceph-osd和ceph-mds)必须相互认证。默认为cephx。 auth service required #如果启用,ceph存储集群守护程序要求ceph客户端与ceph存储集群进行身份验证,以访问ceph服务。 auth client required #如果启用,Ceph客户端需要Ceph存储集群与Ceph客户端进行身份验证。 #关于keys #当运行Ceph启用身份验证时,ceph管理命令和ceph客户端需要验证密钥才能访问ceph存储集群。将Ceph密钥环包含在/etc/ceph目录下。文件名通常是ceph.client.admin.keyring(或$ cluster.client.admin.keyring)。 keyring #密钥环文件的路径。默认查找位置:/etc/ceph/$cluster.$name.keyring,/etc/ceph/$cluster.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin keyfile #密钥文件的路径(即仅包含密钥的文件)。默认是None key #密钥(即密钥本身的文本字符串)。 不推荐。默认None #关于DAEMON KEYRINGS #管理用户或部署工具(例如,ceph-deploy)可以以与生成用户密钥结构相同的方式生成守护进程密钥环。 默认情况下,Ceph在其数据目录中存储守护进程密钥。 缺省密钥环位置以及守护程序功能所需的功能如下所示。 ceph-mon #位置:$mon_data/keyring 功能:mon 'allow *' ceph-osd #位置:$osd_data/keyring 功能:mon 'allow profile osd' osd 'allow *' ceph-mds #位置:$mds_data/keyring 功能:mds 'allow' mon 'allow profile mds' osd 'allow rwx' radosgw #位置:$rgw_data/keyring 功能:mon 'allow rwx' osd 'allow rwx' #关于签名(默认情况下消息签名关闭。 如果您正在运行Bobtail或更高版本的守护程序,请将Ceph配置为需要签名。) cephx require signatures #如果设置为true,Ceph需要在Ceph客户端和Ceph存储集群之间以及包含Ceph存储集群的守护程序之间的所有消息流量上签名。 cephx cluster require signatures #如果设置为true,Ceph需要在包含Ceph存储集群的Ceph守护程序之间的所有消息流量上签名。 cephx service require signatures #如果设置为true,Ceph需要Ceph客户端和Ceph存储集群之间的所有消息流量的签名。 cephx sign messages #如果Ceph版本支持消息签名,Ceph将签署所有消息,以免被欺骗。 #TIME TO LIVE auth service ticket ttl #当Ceph存储集群向Ceph客户端发送一张用于验证的故障单时,Ceph Storage Cluster会为该机票分配一段时间。默认是60*60
#注意监视器密钥环(即mon。)包含密钥但不包含任何功能,并且不是集群验证数据库的一部分。
守护程序数据目录位置默认为以下形式的目录:/var/lib/ceph/$type/$cluster-$id,如:/var/lib/ceph/osd/ceph-12
Monitor Settings(监控器设置)
了解如何配置Ceph Monitor是构建可靠的Ceph存储集群的重要组成部分。 所有Ceph存储集群至少有一个monitor。
#好多前面已经提到过了
#通过Ceph配置文件的Ceph监视器的裸机最小监视器设置包括每个显示器的主机名和监视器地址。 您可以在[mon]下或在特定监视器的条目下配置这些。
[mon] mon host = hostname1,hostname2,hostname3 mon addr = 10.0.0.10:6789,10.0.0.11:6789,10.0.0.12:6789 [mon.a] host = hostname1 mon addr = 10.0.0.10:6789
#关于CLUSTER ID
fsid #集群ID。每个群集一个UUID.
#关于初始成员
mon initial members #建议至少运行三个Ceph监视器来生产Ceph存储集群,以确保高可用性。 运行多个监视器时,可以指定必须是群集成员的初始监视器,以建立法定人数。
#关于DATA
Ceph提供了Ceph监视器存储数据的默认路径。为了在生产Ceph存储集群中获得最佳性能,建议在Ceph OSD守护进程的不同主机和驱动器上运行Ceph监视器。由于leveldb正在使用mmap()来写入数据,Ceph监视器会将数据从内存刷新到磁盘非常频繁,如果数据存储与OSD守护程序位于同一位置,则可能会干扰Ceph OSD守护进程的工作负载。
在Ceph版本0.58及更早版本中,Ceph Monitors将其数据存储在文件中。这种方法允许用户使用像ls和cat这样的常用工具检查监视数据。但是,它并没有提供很强的一致性。
在Ceph版本0.59及更高版本中,Ceph监视器将其数据存储为键/值对。 Ceph监视器需要ACID交易。使用数据存储可防止恢复Ceph监视器通过Paxos运行损坏的版本,并且它可以在一个单一原子批中实现多个修改操作,以及其他优点。
通常,不建议更改默认数据位置。如果修改默认位置,建议通过在配置文件的[mon]部分中设置Ceph监视器。
mon data #monitor的数据位置,默认:/var/lib/ceph/mon/$cluster-$id mon data size warn #当监视器的数据存储超过15GB时,在集群日志中发出HEALTH_WARN。默认:15*1024*1024*1024*。 mon data avail warn #当监视器的数据存储的可用磁盘空间低于或等于该百分比时,在集群日志中发出HEALTH_WARN。默认是:30 mon data avail crit #当监视器数据存储的可用磁盘空间低于或等于该百分比时,在集群日志中发出HEALTH_ERR。默认是:5 mon warn on cache pools without hit sets #如果缓存池没有设置hitset类型集,则在集群日志中发出HEALTH_WARN。默认是true。 mon warn on crush straw calc version zero #如果CRUSH的straw_calc_version为零,则在集群日志中发出HEALTH_WARN。默认是true. mon crush min required version #集群所需的最小可调配置文件版本。默认是:firefly mon warn on osd down out interval zero #如果mon osd down out interval为零,则在群集日志中发出HEALTH_WARN。默认是true。 mon cache target full warn ratio #在pools的cache_target_full and target_max_object 之间就报警,默认是0.66 mon health data update interval #监视器在法定人数中的频率与同行分享其健康状况。(负数禁用),默认是:60 mon health to clog #启用定期向集群日志发送运行状况摘要。默认:true mon health to clog tick interval #监视器将集群日志的健康状况摘要发送到多长时间(以秒计)。 如果当前运行状况摘要为空或与上次相同,则监视器将不会将其发送到群集日志。默认是:3600 mon health to clog interval #监视器将集群日志的健康状况摘要发送到多长时间(以秒计)。 监视器将始终将摘要发送到集群日志,无论摘要是否更改。默认是:60
#关于STORAGE CAPACITY(存储容量)
当Ceph存储集群接近其最大容量(即,mon osd full ratio)时,Ceph可防止写入或读取Ceph OSD守护进程,作为防止数据丢失的安全措施。 因此,让生产Ceph存储集群处理其全部比例不是一个好的做法,因为它牺牲了高可用性。 默认的完全比例是.95或95%的容量。 这对于具有少量OSD的测试集群来说非常激进。

#上图描绘了一个简单的Ceph存储集群,其中包含每个主机一个Ceph OSD守护程序的33个Ceph节点,每个Ceph OSD守护程序从3TB驱动器读取和写入。所以这个典型的Ceph存储集群的最大实际容量为99TB。如果Ceph存储集群的剩余容量为5TB,那么集群将不允许Ceph客户端读取和写入数据。所以Ceph存储集群的运行能力是95TB,而不是99TB。
[global] mon osd full ratio = .80 #在OSD被视为已满之前使用的磁盘空间的百分比。默认是.95 mon osd backfillfull ratio = .75 #在将OSD视为太满以备填写之前使用的磁盘空间的百分比。默认是.90 mon osd nearfull ratio = .70 #在将OSD视为近似之前使用的磁盘空间的百分比,默认是.85 #上面的例子是考虑到,集群不是正常的osd硬盘故障,而是一个跑着多个osd进程的服务器断电的情况,不会对集群的数据安全造成影响。
#关于HEARTBEAT(心跳)
Ceph监视器通过要求每个OSD的报告以及通过OSD接收关于其相邻OSD的状态的报告来了解集群。 Ceph为监视/ OSD交互提供合理的默认设置。 但是,您可以根据需要修改它们。
Monitor/OSD的交互:http://docs.ceph.com/docs/master/rados/configuration/mon-osd-interaction/
#关于监控存储同步
当您运行具有多个监视器的生产群集(推荐)时,每个监视器将检查邻近监视器是否具有更新版本的集群映射(例如,一个或多个具有一个或多个数据行的周期监视器中的映射 即时监视器地图中的当前时期)。 定期地,集群中的一个监视器可能会落在其他监视器之后,以至于必须离开仲裁的位置,同步才能检索有关集群的最新信息,然后重新加入仲裁。 为了同步,监视器可以承担三个角色之一:
Leader #领导者是实现最新Paxos版本的集群映射的第一个监视器。 Provider #提供者是具有最新版本的集群映射的监视器,但不是第一个实现最新版本的监视器。 Requester #请求者是一个已经落后于领导者的监视器,并且必须进行同步以便在重新加入仲裁之前检索有关集群的最新信息。
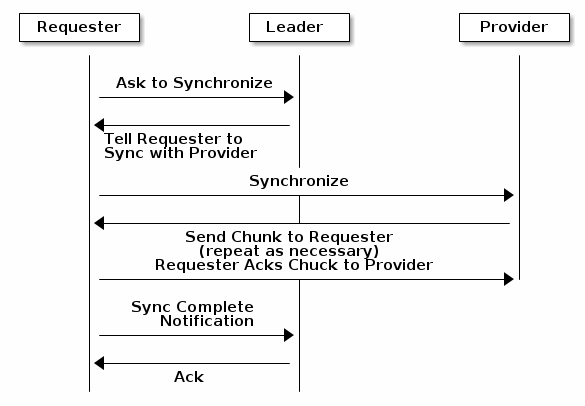
#在上图中,请求者已经知道自己落后于其他监视器,请求者要求Leader同步,Leader告诉其跟Provider同步。这些角色使领导者能够将同步任务委托给Provider,从而防止同步请求超负载提升性能。
当新的监视器加入集群时,始终会发生同步。 在运行时操作期间,监视器可以在不同时间接收到集群映射的更新。 这意味着领导者和提供者角色可能会从一个监视器迁移到另一个 如果在同步(例如,提供者落后于领导者)时发生这种情况,则提供者可以终止与请求者的同步。
同步完成后,Ceph需要在整个集群中进行修整。 修整要求放置组处于active + clean。
下面是一些关于这三个角色的配置:
mon sync trim timeout #操作超时(默认30s),默认值是30.0 mon sync heartbeat timeout #同步时心跳超时(默认30s),默认值是30.0 mon sync heartbeat interval #同步时心跳检查间隔(默认5s),默认值是5.0 mon sync backoff timeout #同步超时(默认30s),默认值是30.0 mon sync timeout #在再次放弃和引导之前,监视器将等待来自其同步提供商的下一个更新消息的秒数。默认是30.0 mon sync max retries #同步最大重试次数(默认5次),默认值是5 mon sync max payload size #同步有效负载的最大大小(以字节为单位)。默认是:1045676 paxos max join drift #在我们必须首先同步监视数据存储之前,最大Paxos迭代。 当监视器发现其对等端远远超过它时,它将首先与数据存储同步,然后继续。默认是10 paxos stash full interval #多久(提交)存放PaxosService状态的完整副本。 当前此设置仅影响mds,mon,auth和mgr PaxosServices。默认值是25 paxos propose interval #在提交map更新之前收集此时间间隔的更新。默认是1.0 paxos min #保持最低数量的paxos状态,默认是500 paxos min wait #经过一段时间不活动后收集更新的最短时间(默认是0.05秒)。默认是0.05 paxos trim min #操作前允许的其他操作数量,最小,默认值是250 paxos trim max #操作前允许的其他操作数量,最大,默认值是500 mon max log epochs #监视器应该保留的最大日志数量,默认值是500 mon max pgmap epochs #维护的最多的PG map版本号数量,默认值是500 mon mds force trim to #强制监视器修剪mdsmaps到这一点,默认是0禁用的很危险。 mon osd force trim to #强制监视器将osdmaps修剪到这一点,即使PG在指定的时期没有清理(0禁用它,危险,谨慎使用) mon osd cache size #osdmaps缓存的大小,不依赖于底层store的缓存,默认值是10 mon election timeout #monitor选举过程的最大等待时长,默认值是5 mon lease #Monitor版本租约秒数。默认是5秒 mon lease renew interval factor #leader去更新其他monitor租约的时间间隔数,默认是0.6 mon lease ack timeout factor #leader等待provider告知其版本的秒数,默认是2.0 mon accept timeout factor #leader等待requester同步的最大时间(默认2s),默认值是2.0 mon min osdmap epochs #OSD map维持的最小版本号数量(默认500),默认值是500 mon max pgmap epochs #monitor维护的最多的PG map版本号数量(默认500),默认值是500 mon max log epochs #monitor保留的最大的log版本号数量(默认500),默认值是500
#关于CLOCK(时钟)
Ceph守护进程将关键消息传递给彼此,这些消息必须在守护进程达到超时阈值之前进行处理。 如果Ceph监视器中的时钟不同步,则可能会导致一些异常。 不同节点间时钟应该同步,否则一些超时和时间戳相关的机制将无法正确运行。在monitor节点应该允许NTP来同步时钟,然而NTP 级别的时钟同步还不够,即使NTP同步好,ceph也会报出时钟偏移警告,工作量,网络延迟,配置覆盖等也会对同步有影响。
Ceph提供以下可调选项,以便找到可接受的值:
clock offset #相对于系统时间的偏移,默认是0 mon tick interval #monitor计时间隔秒数,默认是5 mon clock drift allowed #mon之间的时钟漂移允许的秒数。默认是0.50 mon clock drift warn backoff #时钟漂移警告的指数,默认是5 mon timecheck interval #loader的时间检查间隔(时钟漂移检查)以秒为单位。默认是300.0 mon timecheck skew interval #当loader出现倾斜(以秒为单位)时,时间检查间隔(时钟漂移检查)以秒为单位。more是30.0
#关于CLIENT(客户端)的一些参数设置
mon client hunt interval #客户端将每N秒钟尝试一个新的监视器,直到建立连接。默认值是3.0 mon client ping interval #客户端将每N秒钟ping监视器。默认值是10 mon client max log entries per message #监视器每个客户端消息将生成的最大日志条目数。默认值是1000 mon client bytes #内存中允许的客户端消息数据量(以字节为单位)。默认值是100ul << 20
POOL SETTINGS(池设置)
自版本v0.94以来,支持池标志,允许或不允许对池进行更改。监视器也可以禁止删除池,如果配置为下面那样:
mon allow pool delete #如果监视器应该允许池被删除。不管泳池flag提示怎么说。默认是false。 osd pool default flag hashpspool #在新的池上设置hashpspool标志,默认是true osd pool default flag nodelete #在新的池上设置删除标志。 防止以任何方式使用此标志进行池删除,默认值是false osd pool default flag nopgchange #在新池上设置nopgchange标志。 不允许更改池的PG数。默认值是false osd pool default flag nosizechange #在新池上设置nosizechange标志。 不允许更改池的大小。默认值是false
#有关存储池的更多信息:http://docs.ceph.com/docs/master/rados/operations/pools/#set-pool-value
MISCELLANEOUS(杂项)
mon max osd #群集中允许的最大OSD数量。默认值是10000 mon globalid prealloc #要为群集中的客户端和守护程序预先分配的全局ID数。默认是100 mon subscribe interval #订阅的刷新间隔(以秒为单位)。 订阅机制可以获得集群映射和日志信息。默认值是300 mon stat smooth intervals #使最近的N个PGmap统计数据呈现平滑趋势(默认2),默认值是2 mon probe timeout #monitor在bootstrapping前寻找其他Monitor的时间(默认2s),默认值是2.0 mon daemon bytes #元数据和OSD信息可以在内存中驻留的信息大小,默认值是400ul << 20 mon max log entries per event #每个事件的最大日志条目数。默认值是4096 mon osd prime pg temp #当out OSD返回到群集时,启用或禁用使用先前的OSD启动PGMap。 通过真正的设置,客户端将继续使用以前的OSD,直到新的OSD与PG对等。默认值是true mon osd prime pg temp max time #当外部OSD返回到群集时,显示器应花费多少时间来尝试引导PGMap。默认值是0.5 mon osd prime pg temp max time estimate #在我们对所有PG并行排列之前,在每个PG上花费的时间的最大估计。默认值是0.25 mon osd allow primary affinity #允许在osdmap中设置primary_affinity。默认值是false mon osd pool ec fast read #是否打开快速阅读池或不。 如果在创建时没有指定fast_read,它将被用作新创建的擦除池的默认设置。默认值是false mon mds skip sanity #跳过FSMap上的安全声明(如果我们想要继续的错误的话)。 如果FSMap理性检查失败,则Monitor会终止,但是我们可以通过启用此选项来禁用它。默认值是false mon max mdsmap epochs #在单个提交中,操作mdsmap的最大数量。默认值是500 mon config key max entry size #配置密钥条目的最大大小(以字节为单位)。默认值是4096 mon scrub interval #通过将存储的校验和与所有存储的键中计算出的校验和进行比较,显示器将刷新其存储的频率(秒)。默认值是3600*24 mon scrub max keys #每次刷卡的最大数量。默认值是100 mon compact on start #压缩在Ceph-mon启动时用作Ceph Monitor存储的数据库。 如果常规压缩失败,手动压缩有助于缩小监视数据库并提高性能。默认值是false mon compact on bootstrap #将用作Ceph Monitor的数据库压缩在引导上。 启动后,监视器开始相互探测创建法定人数。 如果在加入法定人数之前超时,它将重新开始并重新启动。默认值是false mon compact on trim #当我们修剪旧状态时,压缩某个前缀(包括paxos)。默认是true mon cpu threads #在监视器上执行CPU密集型工作的线程数。默认值是true mon osd mapping pgs per chunk #我们从块中计算从放置组到OSD的映射。 此选项指定每个块的展示位置组数。默认值是4096 mon osd max split count #每个“涉及”OSD的最大数量的PG让分裂创建。 当我们增加一个池的pg_num时,放置组将被分割在为该池服务的所有OSD上。 我们想要避免PG分裂处的极端乘法器。默认值是300 mon session timeout #监视器将终止非活动会话在此时间限制内空闲。默认值是300
Heartbeat Settings(心跳设置)
这里主要记录的是配置Mon/OSD交互。
完成初始的Ceph配置后,您可以部署并运行Ceph。 执行ceph health或ceph -s等命令时,Ceph Monitor会报告Ceph Storage Cluster的当前状态。 Ceph监视器通过要求每个Ceph OSD守护进程的报告以及从Ceph OSD守护进程接收关于其邻近Ceph OSD守护进程状态的报告,了解Ceph存储群集。 如果Ceph监视器没有收到报告,或者如果收到Ceph存储集群中的更改报告,则Ceph Monitor会更新Ceph Cluster Map的状态。
Ceph为Ceph Monitor / Ceph OSD Daemon交互提供合理的默认设置。 但是,您可以覆盖默认值。 以下部分将介绍Ceph监视器和Ceph OSD守护进程如何与监视Ceph存储集群的情况相互作用。
OSD检查心跳
每个Ceph OSD守护进程每6秒检查其他Ceph OSD守护进程的心跳。 您可以通过在Ceph配置文件的[osd]部分添加osd心跳间隔设置或通过在运行时设置值来更改心跳间隔。 如果相邻的Ceph OSD守护进程在20秒的宽限期内没有显示心跳,则Ceph OSD守护进程可以将相邻的Ceph OSD守护进程下降,并将其报告回Ceph监视器,这将更新Ceph Cluster Map。 您可以通过在Ceph配置文件的[mon]和[osd]或[global]部分添加osd心跳宽度设置,或者通过在运行时设置值来更改此宽限期。
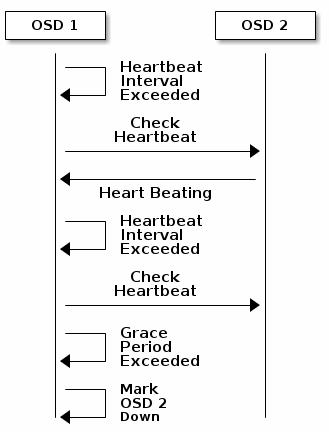
OSD报告OSD DOWN
默认情况下,来自不同主机的两个Ceph OSD守护进程必须向Ceph监视器报告另一个Ceph OSD守护程序在Ceph监视器确认报告的Ceph OSD守护程序关闭之前已关闭。但是,所有报告故障的OSD都有机会托架在一个坏的交换机上,连接到另一个OSD时出现问题。为了避免这种虚假警报,我们认为对等体报告失败的代理潜在的“亚群”在总体集群上是相似的滞后。这在所有情况下显然是不正确的,但有时会帮助我们将恩典修正本身化到不快乐的系统的一部分。 mon osd记录子树级用于通过其在CRUSH映射中的共同祖先类型将对等体分组到“子集群”中。默认情况下,只有两个不同子树的报告需要报告另一个Ceph OSD守护进程。您可以将唯一子树的记录数和通过在Ceph监视器中报告Ceph OSD守护进程所需的共同祖先类型的数量,通过在您的“[mon]”部分下添加一个记录器记录器和mon osd记录器子树级别设置Ceph配置文件,或通过在运行时设置值。
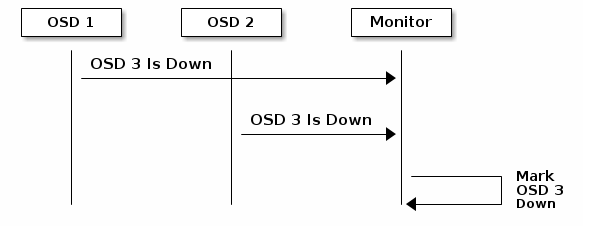
OSDS报告对等失败
如果Ceph OSD后台程序无法与其Ceph配置文件(或集群映射)中定义的任何Ceph OSD守护程序进行对等,它将每30秒ping一个Ceph Monitor以查看最新的集群映射副本。 您可以通过在Ceph配置文件的[osd]部分添加osd mon心跳间隔设置或通过在运行时设置值来更改Ceph Monitor心跳间隔。
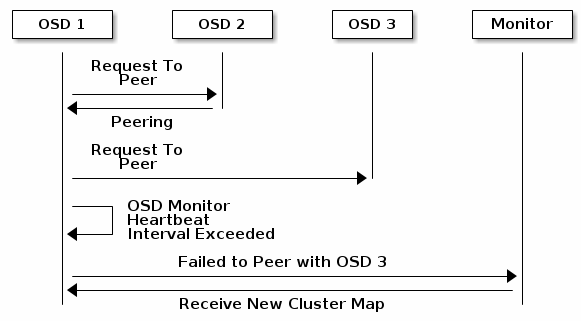
OSDS报告其状态
如果Ceph OSD守护程序没有向Ceph监视器报告,则Ceph监视器将在经过mon osd报告超时后考虑Ceph OSD守护程序。 Ceph OSD守护程序在可报告事件(如故障,位置组状态更改,up_thru更改或5秒内启动时)向Ceph监视器发送报告。 您可以通过在Ceph配置文件的[osd]部分添加一个osd mon报告间隔最小设置,或者通过在运行时设置值来更改Ceph OSD守护进程的最小报告间隔。 Ceph OSD守护进程每120秒向Ceph监视器发送报告,无论是否发生任何显着的更改。 您可以通过在Ceph配置文件的[osd]部分添加osd mon报告间隔最大值设置或通过在运行时设置值来更改Ceph Monitor报告间隔。

配置参数设置:
修改心跳设置时,应将其包含在配置文件的[global]部分。
#monitor设置 mon osd min up ratio #在把 OSD 标记为 down 前,保持处于 up 状态的 OSD 最小比例。默认值是.3 mon osd min in ratio #在把 OSD 标记为 out 前,保持处于 in 状态的 OSD 最小比例。默认值是.75 mon osd laggy halflife #滞后量消退时间,秒。默认值60*60. mon osd laggy weight #滞后量消退时新样本的权重。默认值是0.3 mon osd laggy max interval #该值将用于计算该OSD的宽限期。默认值是300 mon osd adjust heartbeat grace #如果设置为true,Ceph将根据滞后估计进行缩放。默认是true。 mon osd adjust down out interval #如果设置为true,Ceph将根据滞后估计进行缩放。默认值是true mon osd auto mark in #Ceph将在Ceph存储集群中标记任何启动Ceph OSD守护进程。默认值是false mon osd auto mark auto out in #Ceph将标记启动Ceph OSD守护进程自动标记出Ceph存储群集,如集群中所示。默认值是true mon osd auto mark new in #Ceph将在Ceph存储集群中标记启动新的Ceph OSD守护进程。默认值是true mon osd down out interval #如果Ceph OSD守护进程没有响应,则Ceph等待等待的秒数。默认值是600 mon osd down out subtree limit #Ceph不会自动标记的最小的CRUSH单位类型。 例如,如果设置为主机,并且主机的所有OSD都关闭,Ceph将不会自动标记这些OSD。默认值是rack mon osd report timeout #在声明无响应的Ceph OSD守护进程之前的秒钟内的宽限期。默认值是900 mon osd min down reporters #报告Ceph OSD守护进程所需的Ceph OSD守护程序的最小数量。默认值是2 mon osd reporter subtree level #在哪个级别的父级桶中记录计数器。 OSD发送故障报告来监控是否发现其对等体没有响应。 并且监视器将报告的OSD标记出来,然后在宽限期后向下。默认值是host #OSD设置 osd heartbeat address #Ceph OSD守护进程的心跳网络地址。默认是主机IP地址。 osd heartbeat interval #Ceph OSD守护进程ping检测的频率(秒)。默认值是6 osd heartbeat grace #Ceph OSD后台程序没有显示Ceph存储集群将其忽略的心跳所花费的时间。 必须在[mon]和[osd]或[global]部分中设置此设置,以便它们被MON和OSD守护程序读取。默认值是20 osd mon heartbeat interval #Ceph OSD守护进程会多长时间ping一个Ceph监视器。默认值是30 osd mon report interval max #Ceph OSD守护进程可以等待的最长时间(秒)可以向Ceph Monitor报告。默认值是120 osd mon report interval min #Ceph OSD后台程序在启动前等待的最小秒数或另一个可报告事件,然后再报告给Ceph监视器。默认值是5。应该小于osd mon报告间隔最大值 osd mon ack timeout #monitor恢复ACK的超时(默认30s),默认值是30
BlueStore Settings
DEVICES(设备)
BlueStore管理一个,两个或(在某些情况下)三个存储设备。在最简单的情况下,BlueStore会消耗单个(主)存储设备。 存储设备通常分为两部分:
1. 一个小分区用XFS格式化,并包含OSD的基本元数据。 该数据目录包含有关OSD(其标识符,属于哪个集群及其私钥)的信息。
2. 设备的其余部分通常是占用由BlueStore直接管理的设备的其余部分的大型分区,其中包含所有实际数据。 此主设备通常由数据目录中的块符号链接识别。
还可以在两个附加设备上部署BlueStore:
1. WAL设备可用于BlueStore的内部日志或预写日志。 它由数据目录中的block.wal符号链接标识。 如果设备比主设备更快(例如,当它在SSD上,并且主设备是HDD)时,使用WAL设备才是有用的。
2. 可以使用DB设备来存储BlueStore的内部元数据。 BlueStore(或者说,嵌入式RocksDB)将在数据库设备上放置尽可能多的元数据,以提高性能。 如果数据库设备填满,元数据将会溢出到主设备(否则将丢弃)。 同样,如果配置数据库设备的速度比主设备快,则这是有帮助的。
可以配置单一设备BlueStore OSD:
ceph-disk prepare --bluestore <device>
要指定WAL设备和/或DB设备:
ceph-disk prepare --bluestore <device> --block.wal <wal-device> --block-db <db-device>
CACHE SIZE(缓存大小)
BlueStore的高速缓存的每个OSD消耗的内存量由bluestore_cache_size配置选项决定。 如果该配置选项未设置(即保持为0),则根据主设备是否使用HDD或SSD(由bluestore_cache_size_ssd和bluestore_cache_size_hdd配置选项设置)使用不同的默认值。
BlueStore和Ceph OSD的其余部分最有效地支持预算内存。 请注意,除了配置的高速缓存大小之外,还有一些由OSD本身消耗的内存,通常由于内存碎片和其他分配器开销而导致的一些开销。
配置的高速缓存内存预算可以通过几种不同的方式使用:
键/值元数据(即RocksDB的内部缓存) BlueStore元数据 BlueStore数据(即最近读取或写入的对象数据)
下面是一些参数设置:
bluestore_cache_size #BlueStore将用于其缓存的内存量。 如果为零,则将使用bluestore_cache_size_hdd或bluestore_cache_size_ssd。默认值是0. bluestore_cache_size_hdd #当由HDD支持时,BlueStore将用于其缓存的默认内存量。默认值是1 * 1024 * 1024 * 1024 (1 GB) bluestore_cache_size_ssd #由SSD支持的默认内存BlueStore将用于其缓存。默认值是:3 * 1024 * 1024 * 1024 (3 GB) bluestore_cache_meta_ratio #缓存专用于元数据的比例。默认是:.01 bluestore_cache_kv_ratio #缓存专用于密钥/值数据的比例(rocksdb)。默认值是.99 bluestore_cache_kv_max #用于键/值数据的最大缓存量(rocksdb)。默认值是:512 * 1024*1024 (512 MB)
CHECKSUMS(检验)
BlueStore校验和将所有元数据和数据写入磁盘。元数据校验和由RocksDB处理,并使用crc32c。数据校验和由BlueStore完成,可以使用crc32c,xxhash32或xxhash64。默认值为crc32c,应适用于大多数用途。
完整的数据校验和确实增加了BlueStore必须存储和管理的元数据量。例如,当客户端提示数据被顺序写入和读取时,BlueStore将检查较大的块,但在许多情况下,它必须为每4千字节的数据块存储校验和值(通常为4个字节)。
可以通过将校验和截断为两个或一个字节来减少校验和值,减少元数据开销。权衡是随机误差不能被检测到的概率越高,校验和越小,从大约一个,如果40比特(4字节)校验和为40比特,则16比特(4字节) 2字节)校验和或256位中的一个用于8位(1字节)校验和。可以通过选择crc32c_16或crc32c_8作为校验和算法来使用较小的校验和值。
校验和算法可以通过每个池csum_type属性或全局配置选项进行设置。 例如:
ceph osd pool set <pool-name> csum_type <algorithm> #参数为 bluestore_csum_type #使用默认校验和算法。默认值是crc32c,可以设置为:none, crc32c, crc32c_16, crc32c_8, xxhash32, xxhash64
INLINE COMPRESSION(在线压缩)
BlueStore支持使用snappy,zlib或lz4进行内联压缩。 请注意,lz4压缩插件没有在官方发行版中发布。
BlueStore中的数据是否被压缩是由压缩模式和与写入操作相关联的任何提示的组合决定的。 模式是:
none #不压缩数据。 passive #不要压缩数据,除非写操作作为可压缩提示集。 aggressive #压缩数据,除非写操作为不可压缩的提示集。 force #无论什么都要压缩数据
有关可压缩和不可压缩IO提示的详细信息,http://docs.ceph.com/docs/master/rados/api/librados/#c.rados_set_alloc_hint
请注意,不管模式如何,如果数据块的大小没有足够的减少,则不会被使用,并且将存储原始(未压缩的)数据。 例如,如果将蓝调压缩所需比例设置为.7,则压缩数据必须为原始大小(或更小)的70%。
可以通过per-pool属性或全局配置选项设置压缩模式,压缩算法,压缩所需比例,最小blob大小和最大BOB大小。 泳池属性可以设置为:
ceph osd pool set <pool-name> compression_algorithm <algorithm> ceph osd pool set <pool-name> compression_mode <mode> ceph osd pool set <pool-name> compression_required_ratio <ratio> ceph osd pool set <pool-name> compression_min_blob_size <size> ceph osd pool set <pool-name> compression_max_blob_size <size>
下面是配置文件里面参数的设置:
bluestore compression algorithm #如果没有设置每池属性compression_algorithm,则使用默认压缩器(如果有).请注意,由于在压缩少量数据时CPU占用高昂,zstd不推荐用于bluestore。默认值是snappy。有效的设置:lz4, snappy, zlib, zstd bluestore compression mode #如果没有设置每个池的属性compression_mode,则使用压缩的默认策略。默认值是:none。有效值:none, passive, aggressive, force bluestore compression required ratio #压缩后数据块的大小相对于原始大小的比例必须至少为了保存压缩版本而小。默认值:.875 bluestore compression min blob size #小于此的块从未压缩。 每个池的属性compressed_min_blob_size将覆盖此设置。默认值:0 bluestore compression min blob size hdd #轮询的bluestore压缩min blob大小的默认值。默认是128K bluestore compression min blob size ssd #solid state状态的bluestore压缩min blob大小的默认值.默认值是8K bluestore compression max blob size #大于此的块被分解成更小的blob,以在压缩之前调整bluestore压缩max blob大小。每个池的属性compressed_max_blob_size将覆盖此设置。默认值:0 bluestore compression max blob size hdd #用于旋转介质的bluestore压缩最大斑点大小的默认值。默认值是512K bluestore compression max blob size ssd #非旋转(固态)介质的bluestore压缩最大斑点大小的默认值。默认值是64K
FileStore Settings
EXTENDED ATTRIBUTES(扩展属性)
扩展属性(XATTR)是配置中的一个重要方面。 某些文件系统对XATTRS中存储的字节数有限制。 另外,在某些情况下,文件系统可能不如存储XATTR的替代方法一样快。 以下设置可以通过使用存储对基础文件系统非本征的XATTR的方法来帮助提高性能。
Ceph XATTR存储为内联xattr,使用底层文件系统提供的XATTR,如果它不强加大小限制。 如果存在大小限制(例如,ext4上总共为4KB),则当达到filestore max inline xattr size或filestore max inline xattrs threshold时,一些Ceph XATTR将被存储在键/值数据库中。
filestore max inline xattr size #存储在文件系统中的XATTR的最大大小(即,XFS,btrfs,ext4等)每个对象。不应该大于文件可以处理的大小。 默认值为0表示使用特定于底层文件系统的值。默认值是0 filestore max inline xattr size xfs #存储在XFS文件系统中的XATTR的最大大小。 只有在filestore max inline xattr size == 0才使用。默认值是65535 filestore max inline xattr size btrfs #存储在btrfs文件系统中的XATTR的最大大小。 只有在filestore max inline xattr size == 0才使用.默认值是2048 filestore max inline xattr size other #存储在其他文件系统中的XATTR的最大大小。 只有在filestore max inline xattr size == 0才使用。默认值是512 filestore max inline xattrs #每个对象存储在文件系统中的XATTR的最大数量。 默认值为0表示使用特定于底层文件系统的值。默认值是0 filestore max inline xattrs xfs #存储在每个对象的XFS文件系统中的XATTR的最大数量。 只有当filestore max inline xattrs == 0才使用。默认值是10 filestore max inline xattrs btrfs #存储在每个对象的btrfs文件系统中的XATTR的最大数量。 只有当filestore max inline xattrs == 0才使用。默认值是10 filestore max inline xattrs other #每个对象存储在其他文件系统中的XATTR的最大数量。 只有当filestore max inline xattrs == 0才使用。默认值是2
SYNCHRONIZATION INTERVALS(同步间隔)
定期地,文件存储需要停顿写入并同步文件系统,从而创建一致的提交点。 然后它可以将日记帐分录直到提交点。 更频繁的同步倾向于减少执行同步所需的时间,并减少需要保留在日志中的数据量。 较不频繁的同步允许支持文件系统更好地合并小写入和元数据更新,从而可能导致更高效的同步。
filestore max sync interval #同步文件存储的最大间隔(以秒为单位),默认值是5 filestore min sync interval #同步文件存储的最小间隔(以秒为单位)。默认值是.01
FLUSHER
文件存储flusher强制来自大写入的数据将在同步之前使用同步文件范围写出,以(希望)降低最终同步的成本。 实际上,在某些情况下,禁用“filestore flusher”似乎可以提高性能。
filestore flusher #启用filestore flusher.默认值是false filestore flusher max fds #设置flusher文件描述符的最大数量,默认值是512 filestore sync flush #启用同步flush,默认值是false filestore fsync flushes journal data #在文件系统同步期间刷新日志数据,默认值是false
QUEUE(队列)
以下设置对文件存储队列的大小提供限制。
filestore queue max ops #定义文件存储在排队新操作之前阻止之前接受的最大进行中操作数。默认值是50 filestore queue max bytes #操作的最大字节数,默认值100 << 20
TIMEOUTS(超时)
filestore op threads #并行执行的文件系统操作线程数,默认值是2 filestore op thread timeout #文件系统操作线程的超时(以秒为单位)。默认值是60 filestore op thread suicide timeout #取消提交之前提交操作的超时(以秒为单位)。默认值是180
B-TREE FILESYSTEM
filestore btrfs snap #启用btrfs文件存储的快照,默认值是true filestore btrfs clone range #启用btrfs文件存储区的克隆范围。默认值是true
JOURNAL(日志)
filestore journal parallel #启用并行日记功能,默认为btrfs。默认值是false filestore journal writeahead #启用writeahead日记功能,默认为xfs。默认值是false
MISC(杂项)
filestore merge threshold #在合并到父中之前,子目录中的最小文件数注意:负值意味着禁用子目录合并。默认值是10 filestore split multiple #默认值是2.filestore_split_multiple * abs(filestore_merge_threshold) * 16 是分割为子目录前某目录内的最大文件数。 filestore split rand factor #添加到拆分阈值的随机因子,以避免一次发生太多的文件存储拆分。默认值是20 filestore update to #限制文件存储自动升级到特定版本,默认值是1000 filestore blackhole #丢弃任何讨论中的事务,默认值是false filestore dump file #文件写到哪个转储文件,默认值是false filestore kill at #在第N 机会后注入一个失效,默认值是false filestore fail eio #在 eio错误的时候失败或崩溃,默认值是true
Journal Settings
Ceph OSD使用日志有两个原因:速度和一致性。
Speed(速度):该日志使Ceph OSD守护程序能够快速提交小写入。 Ceph按顺序将小而随机的I/O写入日志中,这样可以通过允许支持文件系统更多的时间来合并写入来加快突发性的工作量。 然而,Ceph OSD守护进程的日记可以通过短时间的高速写入引发尖锐的表现,随后文件系统赶上日志,而没有任何写入进程。
Consistency(一致性):Ceph OSD守护进程需要一个保证原子复合操作的文件系统接口。 Ceph OSD守护进程将操作的描述写入日志,并将该操作应用于文件系统。 这样可以对对象进行原子更新(例如,展示位置组元数据)。 每隔几秒 - 文件存储最大同步间隔和文件存储最小同步间隔 - Ceph OSD守护程序停止写入并将日志与文件系统同步,允许Ceph OSD守护进程修改日志的操作并重新使用该空间。 失败后,Ceph OSD守护进程在最后一次同步操作后重新开始记录。
Ceph OSD守护进程支持以下日志设置:
journal dio #启用日志的直接I/0。要求日志块对齐设置为true。默认值是true journal aio #启用使用libaio进行日志的异步写入。要求日志dio设置为true。版本0.61及更高版本,true。 journal block align #块对齐写入操作。 需要dio和aio。默认值true journal max write bytes #日志将在任何时候写入的最大字节数。默认值是10 << 20 journal max write entries #日志将在任何时候写入的最大条目数。默认值是100 journal queue max ops #任何一个时间队列中允许的最大操作数。默认值是500 journal queue max bytes #任何一个时间队列中允许的最大字节数。默认值是10 << 20 journal align min size #对齐数据有效载荷大于指定的最小值。默认值是64 << 10 journal zero on create #导致文件存储在mkfs期间用0覆盖整个日志。默认值是false
Pool, PG & CRUSH Settings
当创建池并设置池的位置组数时,Ceph在不专门覆盖默认值时使用默认值。 建议重写某些默认值。 具体来说,建议设置池的副本大小,并覆盖默认的展示位置组数。 可以在运行池命令时专门设置这些值。 还可以通过在Ceph配置文件的[global]部分添加新的默认值来覆盖默认值。
mon max pool pg num #每个存储池最大的pg数,默认是65536
mon pg create interval #在同一个Ceph OSD守护程序中创建PG之间的秒数。默认是30.0
mon pg stuck threshold #可以认为PG被卡住的秒数。默认值是300
mon pg min inactive #如果PG的数量超过mon_pg_stuck_threshold超过此设置,则在集群日志中发出HEALTH_ERR。非正数表示禁用,不会进入ERR。默认值是1.
mon pg warn min per osd #如果每个(in)OSD中的PG的平均数目在此数字下,则在集群日志中发出HEALTH_WARN。(非正数禁用此项)默认值是30
mon pg warn max per osd #如果每个(in)OSD中的PG的平均数高于该数字,则在集群日志中发出HEALTH_WARN。(非正数禁用此项)默认值是300
mon pg warn min objects #如果集群中的对象总数低于此数字,请不要警告。默认值是1000
mon pg warn min pool objects #不要对对象编号低于此数字的池进行警告,默认值是1000
mon pg check down all threshold #降低OSD的阈值百分比,之后我们检查所有PG的陈旧值。默认值是0.5
mon pg warn max object skew #如果某个池的平均对象编号大于mon pg warn max对象的斜率乘以整个池的平均对象编号,则在群集日志中发出HEALTH_WARN。(非正数禁用此项),默认值是10
mon delta reset interval #我们将pg delta重置为0之前的不活动次数。默认值是10
mon osd max op age # 如果请求被阻止的时间超过此限制,则会发出HEALTH_WARN。默认值是32.0
osd pg bits #每个Ceph OSD守护进程的位置组位数。默认值是6
osd pgp bits #每个OSD为PGP留的位数。默认值是6
osd crush chooseleaf type #在一个 CRUSH 规则内用于 chooseleaf 的桶类型。用序列号而不是名字。默认值:1 ,通常一台主机包含一或多个OSD。
osd crush initial weight #新添加的osds进入crushmap的初步压缩重量。在TB中新增加的osd的大小。 默认情况下,新添加的osd的初始压碎重量设置为TB的卷大小。
osd pool default crush replicated ruleset #创建复制池时要使用的默认CRUSH规则集。默认:CEPH_DEFAULT_CRUSH_REPLICATED_RULESET ,也就是说,“挑选数字 ID 最小的规则集”。这样,没有规则集 0 时也能成功创建存储池。
osd pool erasure code stripe width #设置每个已编码池内的对象条带尺寸(单位为字节)。尺寸为 S 的各对象将存储为N个条带,且各条带将分别编码/解码。默认值是4096
osd pool erasure code stripe unit #设置擦除代码池的对象条带块的默认大小(以字节为单位)。 默认值是409
osd pool default size #设置池中对象的副本数。 默认值与ceph osd pool set {pool-name} size {size}相同。默认是3.
osd pool default min size #设置存储池中已写副本的最小数量,以向客户端确认写操作。如果未达到最小值,Ceph 就不会向客户端回复已写确认。此选项可确保降级( degraded )模式下的最小副本数。默认是:0,意思是没有最小值。如果为0,最小值是 size-(size/2)。
osd pool default pg num #池的pg的默认数量。 默认值与使用mkpool的pg_num相同。默认值是8
osd pool default pgp num #池的展示位置的默认pg组数。默认值与使用mkpool的pgp_num相同。PG和PGP应该相等(现在)。默认值是8
osd pool default flags #新池的默认标志。默认值是0
osd max pgls #将列出的最大归置组数量,一客户端请求量大时会影响 OSD 。默认值是1024
osd min pg log entries #清理日志文件的时候保留的归置组日志量。默认值是1000
osd default data pool replay window #OSD等待客户端重播请求的时间(秒)。默认值是45.Messaging Settings(消息设置)
GENERAL SETTINGS(常规设置)
ms tcp nodelay #在信差的 TCP 会话上禁用 nagle 算法。默认true ms initial backoff #出错时重连的初始等待时间。默认.2 ms max backoff #出错重连时等待的最大时间。默认15.0 ms nocrc #禁用网络消息的 crc 校验,CPU不足时可提升性能。默认false ms die on bad msg #调试选项,不要配置。默认false ms dispatch throttle bytes #等着传送的消息尺寸阀值。默认100 << 20 ms bind ipv6 #如果想让守护进程绑定到 IPv6 地址而非 IPv4 就得启用(如果你指定了守护进程或集群 IP 就不必要了)默认false ms rwthread stack bytes #堆栈尺寸调试选项,不要配置。默认1024 << 10 ms tcp read timeout #控制信差关闭空闲连接前的等待秒数。默认900 ms inject socket failures #调试选项,别配置。默认0
ASYNC MESSENGER OPTIONS(消息同步选项)
ms async transport type #Async Messenger使用的传输类型。 可以是posix,dpdk或rdma。 Posix使用标准TCP/IP网络,是默认值。 其他运输可能是实验性的,支持可能受到限制。默认是posix ms async op threads #每个Async Messenger实例使用的工作线程的初始数。 应该至少等于最高数量的副本,但是如果CPU内核计数不足和/或在单个服务器上托管大量OSD,则可以减少它。默认值3 ms async max op threads #每个Async Messenger实例使用的最大工作线程数。 当您的机器的CPU计数有限时,设置为较低的值,并且在CPU未充分利用时增加(即,I/O操作期间,一个或多个CPU不断处于100%负载)。默认值5 ms async set affinity #设置为true将Async Messenger工作程序绑定到特定的CPU内核。默认true ms async affinity cores #当ms异步设置的亲和性为真时,此字符串指定Async Messenger工作者如何绑定到CPU内核。默认空 ms async send inline #直接从生成它们的线程发送消息,而不是从Async Messenger线程排队和发送。 已知此选项会降低具有大量CPU内核的系统的性能,因此默认情况下禁用此选项。默认false
1.2 操作
官网文档:http://docs.ceph.com/docs/master/rados/operations/
在前两篇已经记录了部署和好多操作,所以集群部署就忽略掉了,这里操作也是记录一部分。
1.2.1 OPERATING A CLUSTER(操作一个集群)
sudo systemctl start ceph.target #启动所有的守护进程 sudo systemctl stop ceph\*.service ceph\*.target #停止所有的守护进程 sudo systemctl status ceph-osd@12 #检查osd.12的状态 sudo systemctl status ceph\*.service ceph\*.target #要列出节点上的Ceph系统单元 sudo systemctl start ceph-osd.target #启动ceph-osd类型的守护进程 sudo systemctl start ceph-mon.target #启动ceph-mon类型的守护进程 sudo systemctl start ceph-mds.target #启动ceph-mds类型的守护进程 sudo systemctl stop ceph-mon\*.service ceph-mon.target #这三个就是按类型停止了 sudo systemctl stop ceph-osd\*.service ceph-osd.target sudo systemctl stop ceph-mds\*.service ceph-mds.target
要在Ceph节点上管理特定守护程序实例(停止就是把start换成stop)
sudo systemctl start ceph-osd@{id}
sudo systemctl start ceph-mon@{hostname}
sudo systemctl start ceph-mds@{hostname}
#下面是对应上面三个例子:
sudo systemctl start ceph-osd@1
sudo systemctl start ceph-mon@ceph-server
sudo systemctl start ceph-mds@ceph-server1.2.2 HEALTH CHECKS(健康检查)
#CRUSH层次结构中删除指定osd ceph osd crush rm osd.<id> #调整阈值 ceph osd set-backfillfull-ratio <ratio> ceph osd set-nearfull-ratio <ratio> ceph osd set-full-ratio <ratio> #池检查利用率 ceph df #目前定义的全部比例 ceph osd dump | grep full_ratio #通过以下方式设置或清除这些标志 ceph osd set <flag> ceph osd unset <flag> #每个OSD标志可以通过以下设置和清除: ceph osd add-<flag> <osd-id> ceph osd rm-<flag> <osd-id> #可以在缓存池上配置命中集: ceph osd pool set <poolname> hit_set_type <type> ceph osd pool set <poolname> hit_set_period <period-in-seconds> ceph osd pool set <poolname> hit_set_count <number-of-hitsets> ceph osd pool set <poolname> hit_set_fpp <target-false-positive-rate> #安全地设置标志: ceph osd set sortbitwise #查看池配额和利用率 ceph df detail #可以通过以下方式提高池配额: ceph osd pool set-quota <poolname> max_objects <num-objects> ceph osd pool set-quota <poolname> max_bytes <num-bytes> #查看哪些PG的受影响的详细信息: ceph health detail #具体问题PG的状态可以查询: ceph tell <pgid> query # pgp_num值可以通过以下方式进行调整: ceph osd pool set <pool> pgp_num <value> #标记池 rbd pool init <poolname> #如果池被自定义应用程序'foo'使用,您还可以通过低级命令进行标签: ceph osd pool application enable foo #查询所涉及的OSD上的请求队列: ceph daemon osd.<id> ops #最近的最慢请求的总结可: ceph daemon osd.<id> dump_historic_ops #查看OSD的位置 ceph osd find osd.<id> #手动启动清洁PG的擦洗: ceph pg scrub <pgid> #手动启动清洁PG的深度擦洗: ceph pg deep-scrub <pgid>
1.2.3 MONITORING A CLUSTER(监控一个集群)
使用命令行查看
#互动模式。要以交互模式运行ceph工具,请在命令行中键入ceph,不带参数。 例如:
ceph
ceph> health
ceph> status
ceph> quorum_status
ceph> mon_status
#如果为配置或密钥环指定了非默认位置,则可以指定其位置:
ceph -c /path/to/conf -k /path/to/keyring health
#检查集群状态
ceph status 或者 ceph s
#除了每个守护进程的本地日志记录之外,Ceph群集还会维护一个集群日志,用于记录整个系统的高级别事件。 这将记录到监视器服务器上的磁盘(默认为/var/log/ceph/ceph.log),但也可以通过命令行进行监视。
ceph -w
#查看日志中最近的n行
ceph log last [n]
#检查集群的使用状态
ceph df
#检查监视器状态
ceph mon stat 或者ceph mon dump
#检查监视器的仲裁状态
ceph quorum_status
#检查元数据服务器的状态
ceph mds stat
#显示元数据集群的详细信息
ceph fs dump
#Ceph管理套接字允许您通过套接字接口查询守护进程。 默认情况下,Ceph套接字驻留在/var/run/ceph下。要通过管理套接字访问守护程序,请登录运行守护程序的主机并使用以下命令:
ceph daemon {daemon-name}
ceph daemon {path-to-socket-file}
#要查看可用的管理套接字命令
ceph daemon {daemon-name} help1.2.4 MONITORING OSDS AND PGS
监控OSDS
OSD的状态位于群集中(或)群集中(out); 并且,它是向上运行(up),或者是关闭而不是运行(down)。 如果OSD已启动,则可能位于群集中(可以读取和写入数据),也可能位于群集中。 如果在群集中并且最近移出群集,Ceph将迁移群集到其他OSD。 如果OSD不在集群中,则CRUSH不会将展示位置组分配给OSD。 如果OSD失败,它也应该out。
注意如果OSD处于关闭状态,则出现问题,并且群集不会处于健康状态。
如果您执行ceph health,ceph -s或ceph -w等命令,您可能会注意到集群并不总是回传HEALTH OK。 不要惊慌 关于OSD,您应该期望在几种预期情况下,集群将不会回传健康状况:
还没有启动集群(它不会响应)。 刚刚启动或重新启动了集群,并且尚未准备好,因为放置组正在创建,OSD正在进行对等。 刚刚添加或删除了OSD。 刚刚修改了你的集群映射。
监控OSD的一个重要方面是确保集群启动并运行时,群集中的所有OSD都启动并运行。 要查看所有OSD是否正在运行,请执行:
ceph osd stat
如果集群中的OSD数量大于OSD的数量,请执行以下命令来识别未运行的ceph-osd守护程序:
ceph osd tree
#提示通过精心设计的CRUSH层次结构进行搜索的能力可以帮助您更快地识别物理位置来对群集进行故障排除。
PG SETS
当CRUSH将展示位置组分配给OSD时,它会查看池的副本数,并将展示位置组分配给OSD,以便将展示位置组的每个副本分配给不同的OSD。 例如,如果池需要放置组的三个副本,则CRUSH可以分别将它们分配给osd.1,osd.2和osd.3。 CRUSH实际上会寻找一个伪随机位置,它将考虑您在CRUSH地图中设置的失败域,因此很少会在大型群集中看到分配给最近邻OSD的布局组。 我们提及应将包含特定展示位置组的副本作为代理集的OSD集合。 在某些情况下,代理集中的OSD已关闭或以其他方式无法为展示位置组中的对象提供服务请求。 当这些情况出现时,不要惊慌。 常见的例子包括:
添加或删除OSD。 然后,CRUSH将展示组重新分配给其他OSD,从而改变代理集的组合,并通过“补余”过程产生数据迁移。 OSD已经关闭,重新启动,正在恢复。 代理组中的OSD正在关闭或无法服务请求,另一个OSD已暂时履行其职责。
Ceph使用Up Set处理客户端请求,Up Set是实际处理请求的一组OSD。 在大多数情况下,Up Set和Acting Set几乎相同。 当它们不存在时,可能表明Ceph正在迁移数据,OSD正在恢复,或者存在问题(即,Ceph通常会在这种情况下回应“健康警告”状态,并显示“stuck stale"即“卡住的陈旧”消息)。
#要检索展示位置组列表
ceph pg dump
#要查看给定展示位置组中的“代理集”或“上一集”中的哪些OSD
ceph pg map {pg-num}PEERING
在将数据写入放置组之前,它必须处于活动状态,并且应处于干净状态。 对于Ceph来确定一个放置组的当前状态,放置组的主要OSD(即代理集中的第一个OSD),与第二和第三个OSD进行对等,就放置组的当前状态达成一致 假设有3个副本的PG的池)。

MONITORING PLACEMENT GROUP STATES
如果您执行ceph health,ceph -s或ceph -w等命令,您可能会注意到集群并不总是回传HEALTH OK。 检查OSD是否正在运行后,您还应检查放置组状态。 您应该期望集群在多个放置组对等相关情况下不会回显HEALTH OK:
刚刚创建了一个池,而展示位置组尚未对等。 展示位置组正在恢复。 刚刚从集群中添加了OSD或从其中删除OSD。 刚刚修改了您的CRUSH地图,您的展示位置组正在迁移。 展示位置组的不同副本中的数据不一致。 Ceph正在擦洗一个放置组的副本。 Ceph没有足够的存储空间来完成回填操作。
如果上述情况之一导致Ceph回应健康警告,请不要惊慌。 在许多情况下,集群将自行恢复。 在某些情况下,您可能需要采取行动。 监控展示位置组的一个重要方面是确保在集群启动并运行时,所有展示组都处于活动状态,最好处于清洁状态。
#要查看所有展示位置组的状态
ceph pg stat
#展示pgID
{pool-num}.{pg-id}
#要检索展示位置组列表
ceph pg dump
#格式化JSON格式的输出并将其保存到文件中:
ceph pg dump -o {filename} --format=json
#要查询特定的展示位置组
ceph pg {poolnum}.{pg-id} query识别故障排除
如前所述,安置组不一定是有问题的,因为它的状态不是活动的+干净的。 一般来说,CEPE自我修复的能力可能在布局组被卡住时可能不起作用。 stuck states(卡住状态)包括:
Unclean(不清楚):展示位置组包含未复制所需次数的对象。 他们应该恢复。 Inactive(无效):展示位置组无法处理读取或写入,因为它们正在等待具有最新数据的OSD以备份。 Stale(陈旧):展示位置组处于未知状态,因为托管它们的OSD没有在一段时间内报告给监视器集群(由mon osd报告超时配置)。
要识别卡住的布局组,请执行以下操作:
ceph pg dump_stuck [unclean|inactive|stale|undersized|degraded]
要解决卡住的布局组故障:http://docs.ceph.com/docs/master/rados/troubleshooting/troubleshooting-pg/#troubleshooting-pg-errors
查找对象位置
要将对象数据存储在Ceph对象存储中,Ceph客户端必须:设置对象名称,指定一个池
Ceph客户端检索最新的集群映射,CRUSH算法计算如何将对象映射到一个放置组,然后计算如何动态地将一个布局组分配给一个OSD。 要查找对象位置,您需要的是对象名称和池名称。 例如:
ceph osd map {poolname} {object-name}要验证Ceph对象存储存储对象:
rados -p data ls
识别对象位置:
ceph osd map {pool-name} {object-name}
ceph osd map data test-object-1要删除测试对象,只需使用rados rm命令删除它。 例如:
rados rm test-object-1 --pool=data
随着集群的发展,对象位置可能会动态变化。 Ceph动态平衡的一个好处是,Ceph可以免除手动执行迁移。 有关详细信息,请参阅架构部分:http://docs.ceph.com/docs/master/architecture/
1.2.5 USER MANAGEMENT(用户管理)
本文档描述了Ceph客户端用户,以及他们对Ceph存储集群的认证和授权。 用户是个人或系统角色,例如使用Ceph客户端与Ceph存储集群守护进程进行交互的应用程序。

当Ceph运行认证和授权启用(默认启用)时,您必须指定包含指定用户(通常通过命令行)的密钥的用户名和密钥环。 如果不指定用户名,Ceph将使用client.admin作为默认用户名。 如果您没有指定密钥环,Ceph将通过Ceph配置中的密钥环设置查找密钥环。
BACKGROUND
不管Ceph客户端的类型(例如Block Device,Object Storage,Filesystem,native API等),Ceph将所有数据作为对象存储在池中。 Ceph用户必须访问池才能读取和写入数据。 此外,Ceph用户必须具有使用Ceph管理命令的执行权限。 以下概念将帮助您了解Ceph用户管理。
USER
用户是个人或系统角色,如应用程序。创建用户可以控制哪些(或什么)可以访问您的Ceph存储集群,其池和池中的数据。
Ceph有一种用户的概念。为了用户管理的目的,类型将始终是客户端。 Ceph识别由用户类型和用户ID组成的句点(。)分隔表单中的用户:例如TYPE.ID,client.admin或client.user1。用户键入的原因是Ceph监视器,OSD和元数据服务器也使用Cephx协议,但它们不是客户端。区分用户类型有助于区分客户端用户和其他用户 - 简化访问控制,用户监控和可追溯性。
有时Ceph的用户类型可能会令人困惑,因为Ceph命令行允许您指定具有或不具有该类型的用户,具体取决于您的命令行用法。如果指定--user或--id,可以省略类型。所以client.user1可以简单地输入为user1。如果指定-name或-n,则必须指定类型和名称,如client.user1。我们建议尽可能使用类型和名称作为最佳做法。
注意:Ceph存储集群用户与Ceph对象存储用户或Ceph Filesystem用户不同。 Ceph对象网关使用Ceph存储集群用户在网关守护进程和存储集群之间进行通信,但网关具有用于最终用户的自己的用户管理功能。 Ceph文件系统使用POSIX语义。 与Ceph文件系统相关联的用户空间与Ceph Storage Cluster用户不同。
AUTHORIZATION (CAPABILITIES)
Ceph使用术语“能力”(caps)来描述授权认证用户行使监视器,OSD和元数据服务器的功能。 功能还可以限制访问池内的数据或池中的命名空间。 Ceph管理用户在创建或更新用户时设置用户的功能。能力语法遵循以下格式:
{daemon-type} '{capspec}[, {capspec} ...]'
#监视器caps:监视功能包括r,w,x访问设置或配置文件{name}。 例如:
mon 'allow rwx'mon 'profile osd'
#OSD Caps:OSD功能包括r,w,x,类读,类写访问设置或配置文件{name}。 此外,OSD功能还允许池和命名空间设置。
osd 'allow {access} [pool={pool-name} [namespace={namespace-name}]]'
osd 'profile {name} [pool={pool-name} [namespace={namespace-name}]]'
#Metadata Server Caps: 对于管理员,请使用allow *。 对于所有其他用户(如CephFS客户端),请查阅CephFS客户端功能:http://docs.ceph.com/docs/master/cephfs/client-auth/#注意Ceph对象网关守护程序(radosgw)是Ceph存储集群的客户端,因此它不表示为Ceph Storage Cluster守护程序类型。
以下条目描述每个功能:
allow #先前设置一个守护进程。 仅适用于MDS。 r #给用户读取访问权限。 监视器需要检索CRUSH映射。 w #给用户写入对象的访问权限。 x #给用户提供调用类方法(即读取和写入)的能力,并对监视器进行认证操作。 class-read #给用户提供调用类读取方法的功能。 x的子集。 class-write #使用户能够调用类写入方法。 x的子集。 * #给予用户对特定守护程序/池的读取,写入和执行权限以及执行管理命令的能力。 profile osd (Monitor only) #提供用户作为OSD连接到其他OSD或显示器的权限。 授予OSD以使OSD能够处理复制心跳流量和状态报告。 profile mds (Monitor only) #给予用户作为MDS连接到其他MDS或监视器的权限。 profile bootstrap-osd (Monitor only) #给用户启动OSD的权限。 授予诸如ceph-disk,ceph-deploy等部署工具,以便在引导OSD时有权添加密钥等。 profile bootstrap-mds (Monitor only) #给用户启动元数据服务器的权限。 授予诸如ceph-deploy等部署工具,因此当引导元数据服务器时,他们有权添加密钥等。 profile rbd (Monitor and OSD) #给予用户操纵RBD图像的权限。 当用作监视器上限时,它提供RBD客户端应用程序所需的最小权限。 当用作OSD上限时,它提供对RBD客户端应用程序的读写访问。 profile rbd-read-only (OSD only) #向RBD图像提供用户只读权限。
POOL
池是用户存储数据的逻辑分区。 在Ceph部署中,通常将池创建为类似数据类型的逻辑分区。 例如,当将Ceph部署为OpenStack的后端时,典型的部署将具有卷,映像,备份和虚拟机以及诸如client.glance,client.cinder等用户的池。
NAMESPACE(命名空间)
池中的对象可以与命名空间相关联 - 池中的对象的逻辑组。用户对池的访问可以与命名空间相关联,使得用户的读取和写入仅在命名空间内进行。写入池中命名空间的对象只能由访问命名空间的用户访问。
注意命名空间主要用于写在Librados之上的应用程序,其中逻辑分组可以减轻创建不同池的需要。 Ceph对象网关(从发光)使用各种元数据对象的命名空间。
命名空间的理由是,为了授权单独的用户集合,池可以是计算上昂贵的隔离数据集的方法。例如,每个OSD应该具有〜100个布局组。因此,具有1000个OSD的示例性集群将具有用于一个池的100,000个放置组。每个池将在示例性集群中创建另外100,000个放置组。相比之下,将对象写入命名空间只需将命名空间与对象名称相关联,而不需要单独池的计算开销。您可以使用命名空间,而不是为用户或用户组创建单独的池。注意:此时只能使用库存。
MANAGING USERS(管理用户)
用户管理功能为Ceph Storage Cluster管理员提供了直接在Ceph存储集群中创建,更新和删除用户的能力。在Ceph存储集群中创建或删除用户时,可能需要将密钥分发给客户端,以便将其添加到密钥环。可以参考键管理:http://docs.ceph.com/docs/master/rados/operations/user-management/#keyring-management
#要列出群集中的用户
ceph auth ls
#要检索特定的用户,密钥和功能
ceph auth get {TYPE.ID} 如:ceph auth get client.admin
#有几种方法来添加用户:
ceph auth add:此命令是添加用户的规范方式。它将创建用户,生成一个密钥并添加任何指定的功能。
ceph auth get-or-create:该命令通常是创建用户最方便的方式,因为它返回一个带有用户名(括号中)和密钥的密钥文件格式。如果用户已经存在,则该命令只返回密钥文件格式的用户名和密钥。您可以使用-o {filename}选项将输出保存到文件。
ceph auth get-or-create-key:此命令是创建用户并返回用户密钥(仅)的一种便捷方式。这对于仅需要密钥的客户端(例如,libvirt)很有用。如果用户已经存在,则该命令只需返回该键。您可以使用-o {filename}选项将输出保存到文件。创建客户端用户时,您可以创建一个没有功能的用户。因为客户端无法从监视器中检索到集群映射,所以没有能力的用户在纯认证之外是无用的。但是,如果您希望稍后使用ceph auth caps命令推迟添加功能,则可以创建没有功能的用户。
典型的用户至少具有Ceph监视器上的读取功能以及Ceph OSD上的读写能力。此外,用户的OSD权限通常限于访问特定池。如下面的例子:
ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool' ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool' ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyringceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key
#如果向用户提供OSD功能,但不要限制对特定池的访问,则用户将可以访问群集中的所有池!
修改用户能力
ceph auth caps命令允许您指定用户并更改用户的功能。 设置新功能将覆盖当前功能。 要查看当前功能,运行ceph auth获取USERTYPE.USERID。 要添加功能,应该在使用表单时指定现有功能:
ceph auth caps USERTYPE.USERID {daemon} 'allow [r|w|x|*|...] [pool={pool-name}] [namespace={namespace-name}]' [{daemon} 'allow [r|w|x|*|...] [pool={pool-name}] [namespace={namespace-name}]']
#如下面的例子
ceph auth get client.john
ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool'
ceph auth caps client.paul mon 'allow rw' osd 'allow rwx pool=liverpool'
ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
#要删除功能,您可以重置该功能。 如果希望用户无法访问先前设置的特定守护程序,请指定一个空字符串。
ceph auth caps client.ringo mon ' ' osd ' 'DELETE A USER(删除用户)
ceph auth del {TYPE}.{ID}
#其中{TYPE}是客户端,osd,mon或mds之一,{ID}是守护程序的用户名或ID。PRINT A USER’S KEY(打印用户key)
要将用户的身份验证密钥打印到标准输出,请执行以下操作:
ceph auth print-key {TYPE}.{ID} #其中{TYPE}是客户端,osd,mon或mds之一,{ID}是守护程序的用户名或ID。#当您需要使用用户密钥填充客户端软件(例如,libvirt)时,打印用户密钥很有用。如:
mount -t ceph serverhost:/ mountpoint -o name=client.user,secret=`ceph auth print-key client.user`
IMPORT A USER(S)(导入用户)
要导入一个或多个用户,请使用ceph auth import并指定密钥环:
ceph auth import -i /path/to/keyring #比如下面的例子 sudo ceph auth import -i /etc/ceph/ceph.keyring
#注意ceph存储集群将添加新用户,其密钥及其功能,并将更新现有用户及其密钥及其功能。
KEYRING MANAGEMENT
当您通过Ceph客户端访问Ceph时,Ceph客户端将寻找一个本地密钥环。 Ceph默认使用以下四个键盘名称来设置键盘设置,因此不必将它们设置在Ceph配置文件中,除非要覆盖默认值(不推荐)。下面是默认找的位置:
/etc/ceph/$cluster.$name.keyring /etc/ceph/$cluster.keyring /etc/ceph/keyring /etc/ceph/keyring.bin
CREATE A KEYRING
当您使用“管理用户”部分中的过程创建用户时,需要向Ceph客户端提供用户密钥,以便Ceph客户端可以检索指定用户的密钥,并与Ceph存储集群进行身份验证。 Ceph客户端访问键盘以查找用户名并检索用户的密钥。
ceph-authtool实用程序允许您创建密钥环。 要创建一个空键盘,请使用--create-keyring或-C。 例如:
ceph-authtool --create-keyring /path/to/keyring
当创建具有多个用户的密钥环时,我们建议使用集群名称(例如,$ cluster.keyring)作为密钥文件名,并将其保存在/etc/ceph目录中,以使密钥环配置默认设置将不需要 您可以在Ceph配置文件的本地副本中指定它。 例如,通过执行以下命令创建ceph.keyring:
sudo ceph-authtool -C /etc/ceph/ceph.keyring
当使用单个用户创建密钥环时,建议使用集群名称,用户类型和用户名,并将其保存在/etc/ ceph目录中。 例如,client.admin用户的ceph.client.admin.keyring。
要在/ etc / ceph中创建密钥环,您必须以root用户身份。 这意味着该文件将仅具有root用户的rw权限,这在密钥环包含管理员密钥时是适当的。 但是,如果您打算为特定用户或用户组使用密钥环,请确保执行chown或chmod以建立适当的密钥环所有权和访问权限。
ADD A USER TO A KEYRING
将用户添加到Ceph存储集群时,可以使用“获取用户”过程来检索用户,密钥和功能,并将用户保存到密钥环。
当您只想在每个密钥环中使用一个用户时,使用-o选项获取用户过程将以密钥文件格式保存输出。 例如,要为client.admin用户创建密钥环,请执行以下操作:
sudo ceph auth get client.admin -o /etc/ceph/ceph.client.admin.keyring
当您要将用户导入密钥环时,可以使用ceph-authtool来指定目标密钥环和源密钥环。 例如:
sudo ceph-authtool /etc/ceph/ceph.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
CREATE A USER
Ceph提供添加用户功能,直接在Ceph存储集群中创建用户。 但是,您、也可以直接在Ceph客户端密钥环上创建用户,密钥和功能。 然后,您、可以将用户导入到Ceph存储集群。 例如:
sudo ceph-authtool -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' /etc/ceph/ceph.keyring
还可以创建一个密钥环,并同时向密钥环添加新用户。 例如:
sudo ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' --gen-key
#在上述情况下,新用户client.ringo只在密钥环中。 要将新用户添加到Ceph存储集群,仍然必须将新用户添加到Ceph存储集群。如下:
sudo ceph auth add client.ringo -i /etc/ceph/ceph.keyring
MODIFY A USER
要修改密钥环中的用户记录的功能,请指定密钥环,然后指定用户跟随的功能。 例如:
sudo ceph-authtool /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx'
要将用户更新为Ceph Storage Cluster,必须将密钥环中的用户更新为Ceph Storage Cluster中的用户条目。如下:
sudo ceph auth import -i /etc/ceph/ceph.keyring
#还可以直接在群集中修改用户功能,将结果存储到密钥环文件中; 然后,将keyring导入到你的主ceph.keyring文件中。
COMMAND LINE USAGE(命令行使用)
Ceph支持用户名和密码的以下用法:
--id | --user #Ceph标识具有类型和ID的用户(例如,TYPE.ID或client.admin,client.user1)。 使用id,name和-n选项可以指定用户名的ID部分(例如admin,user1,foo等)。 您可以使用-id指定用户,并忽略该类型。 例如,要指定用户client.foo,请输入以下内容:
ceph --id foo --keyring /path/to/keyring health ceph --user foo --keyring /path/to/keyring health
--name | -n #Ceph标识具有类型和ID的用户(例如,TYPE.ID或client.admin,client.user1)。 --name和-n选项可以指定完全限定的用户名。 您必须使用用户标识指定用户类型(通常为客户端)。 例如:
ceph --name client.foo --keyring /path/to/keyring health ceph -n client.foo --keyring /path/to/keyring health
--keyring #包含一个或多个用户名和密码的密钥环的路径。 --secret选项提供相同的功能,但它不适用于Ceph RADOS网关,它使用--secret作为另一目的。 您可以使用ceph auth获取或创建密钥环,并将其存储在本地。 这是一种首选方法,因为您可以在不切换密钥环路径的情况下切换用户名。 例如:
sudo rbd map --id foo --keyring /path/to/keyring mypool/myimage
1.2.6 DATA PLACEMENT OVERVIEW(数据存储概述)
Ceph动态存储,复制和重新分配RADOS集群中的数据对象。许多不同的用户在不同的OSD中将对象存储在不同的池中,用于不同的OSD,Ceph操作需要进行一些数据布局规划。 Ceph的主要数据布局规划概念包括:
Pools:
Ceph存储池内的数据,它们是用于存储对象的逻辑组。池管理展示位置组数,副本数和池的规则集。要将数据存储在池中,您必须具有对该池具有权限的经过身份验证的用户。 Ceph可以快照池。
Placement Groups:
Ceph将对象映射到展示位置组(PG)。放置组(PG)是将对象作为组放置到OSD中的逻辑对象池的碎片或碎片。当Ceph将数据存储在OSD中时,放置组减少每个对象元数据的数量。更多数量的展示位置组(例如,每个OSD为100)会导致更好的平衡。
CRUSH Maps:
CRUSH是允许Ceph在没有性能瓶颈的情况下进行扩展的大部分,而不会限制可扩展性,并且没有单点故障。 CRUSH映射将集群的物理拓扑提供给CRUSH算法,以确定应存储对象及其副本的数据的位置,以及如何在故障域中执行此操作,以增加数据安全性。
1.2.7 POOLS
当首次部署群集而不创建池时,Ceph使用默认池来存储数据。 池为您提供:
Resilience(弹性):可以设置允许多少OSD失败,而不会丢失数据。对于复制池,它是对象的所需数量的副本/副本。典型的配置存储一个对象和一个附加副本(即size = 2),但是可以确定副本/副本的数量。对于擦除编码池,它是编码块的数量(即,擦除码简档中的m = 2) Placement Groups(展示位置组):可以设置池的展示位置组数。典型的配置每个OSD使用大约100个布局组,以提供最佳的平衡,而不用太多的计算资源。设置多个池时,请小心确保为池和群集整体设置合理数量的位置组。 CRUSH Rules(CRUSH规则):将数据存储在池中时,映射到池的CRUSH规则集使CRUSH能够识别集群中对象及其副本(或擦除编码池的块)的位置的规则。可以为池创建自定义CRUSH规则。 Snapshots(快照):使用ceph osd pool mksnap创建快照时,可以有效地拍摄特定池的快照。
要将数据组织到池中,您可以列出,创建和删除池。 还可以查看每个池的利用率统计信息。
#列出群集的池 ceph osd lspools #在新安装的群集中,只有rbd池存在。 #要显示池的利用率统计信息 rados df # 理想情况下,应该覆盖Ceph配置文件中位置组数的默认值,默认值不理想。下面是覆盖举例: osd pool default pg num = 100 osd pool default pgp num = 100
要创建池,请执行:
ceph osd pool create {pool-name} {pg-num} [{pgp-num}] [replicated] \
[crush-rule-name] [expected-num-objects]
ceph osd pool create {pool-name} {pg-num} {pgp-num} erasure \
[erasure-code-profile] [crush-rule-name] [expected_num_objects]#下面是上述命令里面各参数所代表的意思:
{pool-name} #池的名称。 它必须是独一无二的。必须要输入
{pg-num} #池的展示位置组总数。默认值8不适用于大多数系统。
{pgp-num} #用于放置目的的展示位置组的总数。 这应该等于展示位置组的总数,但展示位置组拆分情况除外。默认值是8
{replicated|erasure} #可以通过保留对象的多个副本或通过删除来获得一种广义的RAID5功能来复制丢失OSD的池类型。 复制的池需要更多的原始存储,但实现所有Ceph操作。 擦除池需要较少的原始存储,但仅实现可用操作的一个子集。默认值是:replicated
[crush-rule-name] #用于此池的CRUSH规则的名称。 指定的规则必须存在。非必须选项。
[erasure-code-profile=profile] #仅用于擦除池使用擦除代码配置文件它必须是由osd erasure-code-profile定义的现有配置文件。非必要选项
[expected-num-objects] #该池的预期数量。 通过设置此值(连同负的文件存储合并阈值),PG文件夹拆分将在池创建时发生,以避免延迟影响以执行运行时文件夹拆分。默认是:0,在池创建时没有分裂。
ASSOCIATE POOL TO APPLICATION
池需要在使用前与应用程序相关联。 将用于与RGW自动创建的CephFS或池一起使用的池将自动关联。 要用于RBD的池应使用rbd工具进行初始化。对于其他情况,您可以手动将自由格式的应用程序名称与池相关联:
ceph osd pool application enable {pool-name} {application-name}#注意CephFS使用应用程序名称cephfs,RBD使用应用程序名称rbd,RGW使用应用程序名称rgw。
SET POOL QUOTAS
您可以为每个池的最大字节数和/或最大对象数量设置池配额。如:
ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}]
#下面是实际的例子
ceph osd pool set-quota data max_objects 10000 #要删除配额,请将其值设置为0。DELETE A POOL
要删除池,请执行:
ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]#要删除池,在监视器的配置中,mon_allow_pool_delete标志必须设置为true。 否则他们将拒绝删除游泳池。
如果为创建的池创建了自己的规则集和规则,则在不再需要池时应考虑删除它们:
ceph osd pool get {pool-name} crush_ruleset
#例如,如果规则集是“123”,可以像这样检查其他池:
ceph osd dump | grep "^pool" | grep "crush_ruleset 123"如果没有其他池使用该自定义规则集,则可以从集群中删除该规则集。如果创建的用户权限严格适用于不再存在的池,则应考虑删除这些用户:
ceph osd pool rename {current-pool-name} {new-pool-name}#如果重命名一个池,并且对于经过身份验证的用户,具有每个池的功能,则必须使用新的池名称更新用户的功能(即大写)。
池快照的管理
#要创建池的快照,请执行:
ceph osd pool mksnap {pool-name} {snap-name}
#要删除池的快照,请执行:
ceph osd pool rmsnap {pool-name} {snap-name}SET POOL VALUES(设置池的值)
要将值设置为池的值,请执行以下操作:
ceph osd pool set {pool-name} {key} {value}可以为以下键设置值:
compression_algorithm #设置内联压缩算法用于底层的BlueStore。 此设置将覆盖bluestore压缩算法的全局设置。有效值是:lz4, snappy, zlib, zstd compression_mode #设置底层BlueStore的内联压缩算法的策略。 此设置将覆盖bluestore压缩模式的全局设置。有效值是:none, passive, aggressive, force compression_min_blob_size #小于此的块从未压缩。 此设置将覆盖bluestore压缩min blob *的全局设置。 compression_max_blob_size #大于此的块在被压缩之前被分解成更小的blob来缩小compression_max_blob_size。 size #设置池中对象的副本数。 min_size #设置I/O所需的最小副本数。 pg_num #计算数据放置时使用的放置组的有效数量。 pgp_num #计算数据放置时使用的展示位置的有效数量。 crush_ruleset #用于在集群中映射对象放置的规则集。 allow_ec_overwrites #是否写入擦除编码池可以更新对象的一部分,cephfs和rbd可以使用它。 hashpspool #在给定的池中设置/取消设置HASHPSPOOL标志。 nodelete #在给定的池中设置/取消设置NODELETE标志。 nopgchange #在给定的池中设置/取消设置NOPGCHANGE标志. nosizechange #在给定的池中设置/取消设置NOSIZECHANGE标志。 write_fadvise_dontneed #在给定的池中设置/取消设置WRITE_FADVISE_DONTNEED标志。 noscrub #在给定的池中设置/取消设置NOSCRUB标志。 nodeep-scrub #在给定的池中设置/取消设置NODEEP_SCRUB标志。 hit_set_type #启用缓存池的命中集跟踪。默认值是bloom.其他值用于测试 hit_set_count #要存储缓存池的命中集的数量。 数字越高,ceph-osd守护进程所消耗的内存就越多。 hit_set_period #缓存池的命中设置周期(以秒为单位)的持续时间。 数字越高,ceph-osd消耗的RAM越多 hit_set_fpp #默认值是0.05,范围是0.0-0.10 cache_target_dirty_ratio #在缓存分层代理程序之前,包含修改(脏)对象的缓存池的百分比将刷新到后备存储池。默认值是.4 cache_target_dirty_high_ratio #在缓存分层代理程序之前,包含修改(脏)对象的缓存池的百分比将以更高的速度将它们刷新到后台存储池。默认值是.6 cache_target_full_ratio #在高速缓存分层代理程序之前,包含未修改(干净)对象的缓存池的百分比将从高速缓存池中撤出它们。默认值.8 target_max_bytes #当触发max_bytes阈值时,Ceph将开始刷新或逐出对象。比如:1000000000000 #1-TB target_max_objects #当触发max_objects阈值时,Ceph将开始刷新或逐出对象。比如:1000000 #1M objects hit_set_grade_decay_rate #两个连续hit_sets之间的衰减率,默认值是20,范围是0-100 hit_set_search_last_n #计数最多N个在hit_sets中进行计算,默认值是1 cache_min_flush_age #高速缓存分层代理程序将缓存池中的对象从存储池中刷新的时间(秒)。 cache_min_evict_age #高速缓存分层代理程序之前的时间(以秒为单位)将从高速缓存池中取出一个对象。 fast_read #在擦除编码池中,如果此标志被打开,则读取请求将向所有分片发出子读取,并等待直到它接收到足够的分片来解码以服务于客户端。默认是0 scrub_min_interval #负载低时池洗涤的最小间隔(秒)。如果为0,则使用来自config的值osd_scrub_min_interval。默认是0 scrub_max_interval #池擦除的最大间隔(以秒为单位),与群集负载无关。如果为0,则使用来自config的值osd_scrub_max_interval。默认是0 deep_scrub_interval #池“深”擦洗的间隔(秒)。如果为0,则使用来自config的值osd_deep_scrub_interval。默认是0
GET POOL VALUES(获取池的值)
要从池获取值,请执行以下操作:
ceph osd pool get {pool-name} {key} #key也是上面举例的哪些key设置对象的数量
要设置复制池上的对象副本数,请执行以下操作:
ceph osd pool set {poolname} size {num-replicas}例如:
ceph osd pool set data size 3
可以为每个池执行此命令。 注意:对象可能会使用少于池大小副本的降级模式中的I/O。 要设置I/O所需的副本的最小数量,应使用min_size设置。 例如:
ceph osd pool set data min_size 2
#这样可确保数据池中的任何对象都不会收到少于min_size副本的I/O。
要获取对象副本的数量,请执行以下操作:
ceph osd dump | grep 'replicated size'
#Ceph将列出池,突出显示复制的大小属性。 默认情况下,ceph创建一个对象的两个副本(总共三个副本,或大小为3)。
