Ceph跟着官网学一波(四)
上一章http://blog.51niux.com/?id=164字数太长了,这里继续跟着官网学习。
1.2.8 ERASURE CODE(擦除代码)
Ceph池与一种类型相关联,以维持OSD的丢失(即,磁盘,因为大多数时间每个磁盘有一个OSD)。 复制创建池时的默认选项,这意味着每个对象都复制在多个磁盘上。 可以使用擦除代码池类型来节省空间。
创建样品擦除编码池
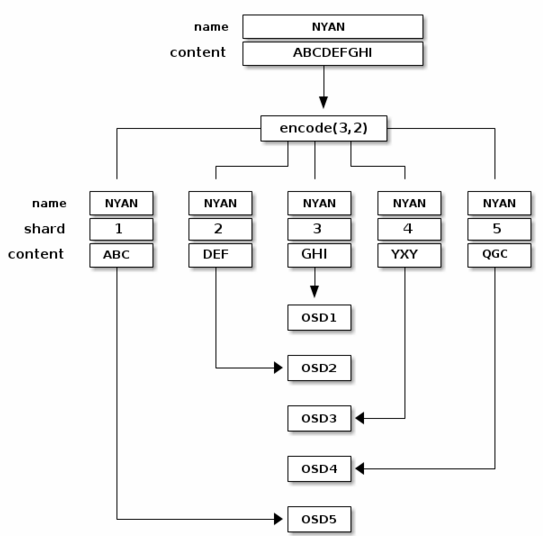
最简单的擦除编码池相当于RAID5,至少需要三台主机:
$ ceph osd pool create ecpool 12 12 erasure pool 'ecpool' created $ echo ABCDEFGHI | rados --pool ecpool put NYAN - $ rados --pool ecpool get NYAN - ABCDEFGHI
注意:池创建中的12表示展示位置组的数量。
ERASURE CODE PROFILES(擦除代码配置文件)
默认擦除代码配置文件维护单个OSD的丢失。 它相当于大小为2的复制池,但需要1.5TB而不是2TB来存储1TB的数据。 默认配置文件可以显示:
$ ceph osd erasure-code-profile get default k=2 m=1 plugin=jerasure crush-failure-domain=host technique=reed_sol_van
选择正确的配置文件很重要,因为在创建池后无法修改:需要创建具有不同配置文件的新池,并将上一个池中的所有对象移动到新的池中。
配置文件的最重要参数是K,M和压缩失败域,因为它们定义了存储开销和数据持久性。 例如,如果所需的体系结构必须维持两个机架的丢失,并且间接开销为40%,则可以定义以下配置文件:
$ ceph osd erasure-code-profile set myprofile \ k=3 \ m=2 \ crush-failure-domain=rack $ ceph osd pool create ecpool 12 12 erasure myprofile $ echo ABCDEFGHI | rados --pool ecpool put NYAN - $ rados --pool ecpool get NYAN - ABCDEFGHI
NYAN对象将被分为三个(K = 3),并且将创建两个附加块(M = 2)。 M的值定义了可以同时丢失多少OSD同时丢失任何数据。 crush-failure-domain = rack将创建一个CRUSH规则集,确保没有两个块存储在同一个机架中。
更多信息在:http://docs.ceph.com/docs/master/rados/operations/erasure-code-profile/
使用OVERWRITES进行擦除编码
默认情况下,擦除编码池仅适用于执行完整对象写入和追加的用途,如RGW。
由于Luminous,可以使用每池设置启用擦除编码池的部分写入。 这使得RBD和Cephfs将其数据存储在擦除编码池中:
ceph osd pool set ec_pool allow_ec_overwrites true
这只能在驻留在bluestore OSD上的池中启用,因为bluestore的校验和用于在深度擦洗时检测bitrot或其他损坏。 除了不安全之外,与bluestore相比,使用文件存储与ec覆盖产生低性能。
擦除编码池不支持omap,因此要使用RBD和Cephfs,您必须指示他们将其数据存储在ec池中,并将其元数据存储在复制池中。 对于RBD,这意味着在映像创建期间使用擦除编码的池作为 - 数据池:
rbd create --size 1G --data-pool ec_pool replicated_pool/image_name
#对于Cephfs,使用擦除编码池意味着在http://docs.ceph.com/docs/master/cephfs/file-layouts/中设置该池。
ERASURE CODED POOL AND CACHE TIERING
擦除编码池需要比复制池更多的资源,并且缺少一些功能,如omap。 为了克服这些限制,可以在擦除编码池之前设置缓存层。
例如,如果池热存储由快速存储器组成:
$ ceph osd tier add ecpool hot-storage $ ceph osd tier cache-mode hot-storage writeback $ ceph osd tier set-overlay ecpool hot-storage
#将热存储池作为ecpool的层次放置在回写模式,以便每次对ecpool的写入和读取实际上都是使用热存储,并从其灵活性和速度中获益。
GLOSSARY
chunk #当调用编码函数时,它返回相同大小的块。 可以连接的数据块可以重建原始对象,并且可以用来重建丢失的块的编码块。 K #数据块的数量,即原始对象被划分的块的数量。 例如,如果K=2,一个10KB的对象将被划分为每个5KB的K个对象。 M #编码块的数量,即由编码功能计算的附加块的数量。 如果有2个编码块,这意味着2个OSD可以在不丢失数据的情况下出来。
1.2.9 CACHE TIERING(高速缓存)
缓存层为Ceph客户端提供了更好的I/O性能,用于存储在后备存储层中的数据的一部分。 高速缓存分层涉及创建一个相对快速/昂贵的存储设备(例如,固态驱动器)的池,其被配置为用作高速缓存层,以及被配置为充当经济存储器的擦除编码或相对较慢/更便宜的设备的后台池层。 Ceph反对者处理放置对象的位置,分层代理决定何时将对象从缓存中刷新到后备存储层。因此缓存层和后备存储层对Ceph客户端是完全透明的。
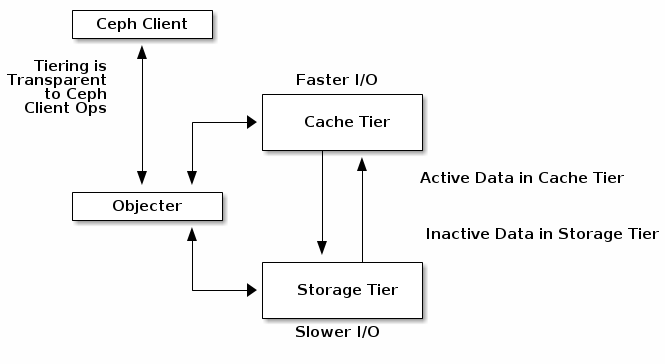
缓存分层代理自动处理缓存层和后备存储层之间的数据迁移。 但是,管理员可以配置如何进行迁移。 主要有两种情况:
Writeback Mode(回写模式) #当管理员使用回写模式配置层时,Ceph客户端将数据写入高速缓存层,并从缓存层接收ACK。及时,写入高速缓存层的数据将迁移到存储层,并从高速缓存层中刷新。在概念上,缓存层叠加在后端存储层的“前面”。当Ceph客户端需要驻留在存储层中的数据时,高速缓存分层代理在读取时将数据迁移到缓存层,然后将其发送到Ceph客户端。此后,Ceph客户端可以使用高速缓存层执行I/O,直到数据变为非活动状态。这对于可变数据(例如,照片/视频编辑,事务数据等)是理想的。 Read-proxy Mode(读取代理模式) #此模式将使用高速缓存层中已存在的任何对象,但如果缓存中不存在对象,则该请求将被代理到基础层。这对于从回写模式转换为禁用高速缓存非常有用,因为它允许工作负载在高速缓存耗尽时正常运行,而不会向缓存中添加任何新对象。
A WORD OF CAUTION(使用要小心)
缓存分层将降低大多数工作负载的性能。使用此功能之前,用户应特别小心:
依赖于工作负载(Workload dependent):缓存是否提高性能高度依赖于工作负载。因为存在与移动对象进出高速缓存的成本相关的成本,所以只有在数据集中的访问模式存在大的偏斜时才能有效,使得大部分请求触及少量的对象。缓存池应该足够大,以捕获工作负载的工作集以避免抖动。
难以测试(Difficult to benchmark:用户运行的测量性能的大多数基准将显示高速缓存分层的可怕性能,部分原因是很少有人将请求偏移到一小部分对象,缓存需要很长时间才能“预热” “因为预热费用可能很高。
通常较慢(Usually slower):对于不缓存分层友好的工作负载,性能通常比正常的RADOS池慢,而不启用缓存分层。
librados对象枚举(librados object enumeration):库存级别的对象枚举API并不意味着在案件存在的情况下是一致的。如果您的应用程序直接使用librados并依赖对象枚举,缓存分层可能无法正常工作。 (这不是RGW,RBD或CephFS的问题。)
复杂性(Complexity):启用缓存分层意味着正在使用RADOS集群中的大量额外的机械和复杂性。这增加了系统中遇到其他用户尚未遇到的错误并将部署置于更高风险的可能性。
已知好的工作:
RGW时间偏移:如果RGW工作负载使得几乎所有的读取操作都针对最近写入的对象,则在可配置的时间段之后将最近写入的对象从缓存运行到基础层的简单缓存分层配置可以正常工作。
已知的工作负载:
已知以下配置在缓存分层方面工作不佳。
具有复制缓存和擦除编码基数的RBD:这是一个通用请求,但通常表现不佳。 即使合理的偏移工作负载仍然会向冷对象发送一些小写入,并且由于擦除编码池不支持小写,因此必须将整个(通常为4 MB)的对象迁移到缓存中,以满足较小的(通常为4 KB)写。 只有少数用户已经成功部署了这种配置,它只适用于他们,因为他们的数据非常冷(备份),而且对性能不敏感。
具有复制缓存和基数的RBD:具有复制基本层的RBD比基数被擦除编码时更好,但是它仍然高度依赖于工作负载中的偏斜量,并且非常难以验证。 用户需要对其工作负载有很好的了解,并且需要仔细调整缓存分层参数。
SETTING UP POOLS
要设置缓存分层,您必须有两个池。一个将作为后备存储,另一个将作为缓存。
设置后备存储池
设置备份存储池通常涉及两种情况之一:
Standard Storage(标准存储):在这种情况下,池在Ceph存储集群中存储对象的多个副本。 Erasure Coding:在这种情况下,池使用擦除编码以更小的性能权衡来更有效地存储数据。 #在标准存储方案中,可以设置CRUSH规则集以建立故障域(例如,osd,主机,机箱,机架,行等)。Ceph OSD守护进程在规则集中的所有存储驱动器具有相同的大小,速度(RPM和吞吐量)以及类型时执行最佳性能。创建规则集后,创建后备存储池。
设置缓存池
设置缓存池遵循与标准存储方案相同的过程,但存在差异:缓存层的驱动器通常是驻留在其自己的服务器中并具有自己的规则集的高性能驱动器。 设置规则集时,应考虑具有高性能驱动器的主机,同时省略不具备该功能的主机。
对于缓存层配置和默认值,请参照上面记录的设置池值。
创建高速缓存
#设置缓存层包括将后备存储池与缓存池相关联
ceph osd tier add {storagepool} {cachepool}
#上面的实际例子如下:
ceph osd tier add cold-storage hot-storage
#要设置缓存模式,请执行以下操作:
ceph osd tier cache-mode {cachepool} {cache-mode}
#上面的实际例子如下:
ceph osd tier cache-mode hot-storage writeback
#高速缓存层覆盖后备存储层,因此需要一个额外的步骤:您必须将存储池中的所有客户端流量引导到缓存池。 要直接将客户端流量引导到缓存池,请执行以下操作:
ceph osd tier set-overlay {storagepool} {cachepool}
#上面的实际例子如下:
ceph osd tier set-overlay cold-storage hot-storage配置高速缓存
缓存层有几个配置选项。 您可以使用以下用法设置缓存层配置选项:
ceph osd pool set {cachepool} {key} {value}
ceph osd pool set {cachepool} hit_set_count 12
ceph osd pool set {cachepool} hit_set_period 14400
ceph osd pool set {cachepool} target_max_bytes 1000000000000
ceph osd pool set {cachepool} min_read_recency_for_promote 2
ceph osd pool set {cachepool} min_write_recency_for_promote 2
ceph osd pool set {cachepool} hit_set_type bloom
#上面的实际例子如下:
ceph osd pool set hot-storage hit_set_type bloom
#绝对尺寸,高速缓存分层代理可以基于字节总数或对象总数来刷新或取出对象。 要指定最大字节数,请执行以下操作:
ceph osd pool set {cachepool} target_max_bytes {#bytes}
#上面的实际例子例如,要冲洗或驱逐1 TB,请执行以下操作::
ceph osd pool set hot-storage target_max_bytes 1099511627776
#要指定最大对象数,请执行以下操作:
ceph osd pool set {cachepool} target_max_objects {#objects}
#上面的实际例子例如,例如,要刷新或逐出1M对象,请执行以下操作:
ceph osd pool set hot-storage target_max_objects 1000000
#相对尺寸,缓存分层代理可以相对于缓存池的大小来刷新或驱逐对象(由绝对大小中由target_max_bytes / target_max_objects指定)。 当缓存池由一定百分比的修改(或脏)对象组成时,高速缓存分层代理将将它们刷新到存储池。 要设置cache_target_dirty_ratio,请执行以下操作:
ceph osd pool set {cachepool} cache_target_dirty_ratio {0.0..1.0}
#例如,将值设置为0.4将在缓存池的容量达到40%时开始刷新修改(脏)对象:
ceph osd pool set hot-storage cache_target_dirty_ratio 0.4
#当脏物体达到其容量的一定百分比时,以较高的速度冲洗脏物。 要设置cache_target_dirty_high_ratio:
ceph osd pool set {cachepool} cache_target_dirty_high_ratio {0.0..1.0}
#例如,将值设置为0.6将开始积极地刷新脏对象,当它们达到缓存池容量的60%时。 显然,我们最好在dirty_ratio和full_ratio之间设置值:
ceph osd pool set hot-storage cache_target_dirty_high_ratio 0.6
#当缓存池达到其容量的一定百分比时,缓存分层代理将驱逐对象以维护可用容量。 要设置cache_target_full_ratio,请执行以下操作:
ceph osd pool set {cachepool} cache_target_full_ratio {0.0..1.0}
#例如,将值设置为0.8将在缓存池的容量达到80%时开始刷新未修改(干净)的对象:
ceph osd pool set hot-storage cache_target_full_ratio 0.8
#缓存时间,在缓存分层代理程序将最近修改(或脏)的对象刷新到后台存储池之前,可以指定对象的最小时间:
ceph osd pool set {cachepool} cache_min_flush_age {#seconds}
#例如,要在10分钟后刷新修改(或脏)对象,请执行以下操作:
ceph osd pool set hot-storage cache_min_flush_age 600
#可以在对象从缓存层中逐出之前指定对象的最小年龄:
ceph osd pool {cache-tier} cache_min_evict_age {#seconds}
#例如,要在30分钟后取消对象,请执行以下操作:
ceph osd pool set hot-storage cache_min_evict_age 1800
#删除高速缓存,删除高速缓存层根据是否是回写高速缓存还是只读高速缓存而有所不同。
#删除只读高速缓存,由于只读缓存不具有修改的数据,因此您可以禁用并删除它,而不会丢失任何最近对缓存中的对象的更改。
#将缓存模式更改为none以禁用它。
ceph osd tier cache-mode {cachepool} none 如:ceph osd tier cache-mode hot-storage none
#从后台池中删除缓存池。
ceph osd tier remove {storagepool} {cachepool} 如:ceph osd tier remove cold-storage hot-storage
#删除一个写入缓存。由于回写缓存可能具有修改的数据,因此您必须采取措施确保在禁用和删除缓存之前,不要丢失缓存中对象的任何最近更改。
#将缓存模式更改为转发,以便新的和修改的对象将刷新到后备存储池。
ceph osd tier cache-mode {cachepool} forward 如:ceph osd tier cache-mode hot-storage forward
#确保缓存池已被刷新。 这可能需要几分钟的时间:
rados -p {cachepool} ls
#如果缓存池仍然有对象,您可以手动刷新它们。 例如:
rados -p {cachepool} cache-flush-evict-all
#删除覆盖层,以便客户端不会将流量引导到缓存。
ceph osd tier remove-overlay {storagetier} 如:ceph osd tier remove-overlay cold-storage
#最后,从后备存储池中删除缓存层池。
ceph osd tier remove {storagepool} {cachepool} 如:ceph osd tier remove cold-storage hot-storage注意Ceph不能自动确定缓存池的大小,所以这里需要绝对大小的配置,否则flush / evict将不起作用。 如果同时指定了这两个限制,则当触发任何阈值时,缓存分层代理将开始刷新或逐出。
注意仅当达到target_max_bytes或target_max_objects时,所有客户端请求才会被阻止
1.2.10 PLACEMENT GROUPS(放置组)
预选择一个放置组
当创建一个新的池时:
ceph osd pool create {pool-name} pg_num由于不能自动计算,因此必须选择pg_num的值。 以下是常用的几个值:
少于5个OSD设置pg_num为128 5到10个OSD将pg_num设置为512 10到50个OSD将pg_num设置为1024 如果有超过50个OSD,您需要了解自己的权衡和如何计算pg_num值 要自己计算pg_num值,可以通过pgcalc工具来帮助:http://ceph.com/pgcalc/
#随着OSD数量的增加,为pg_num选择正确的值变得更为重要,因为它对群集的行为有显着的影响以及出现错误时数据的持久性(即灾难性事件导致 数据丢失)。
如何使用放置组?
放置组(PG)聚合池中的对象,因为在每个对象的基础上跟踪对象位置和对象元数据在计算上是昂贵的,即具有数百万个对象的系统无法实际地跟踪每个对象的位置。
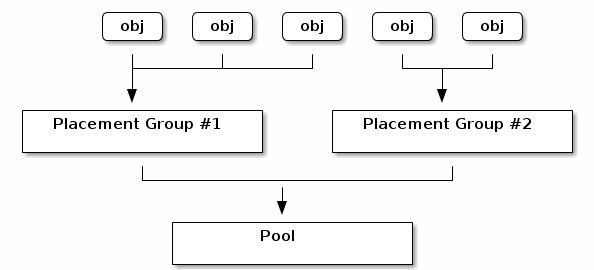
Ceph客户端将计算一个对象应该在哪个布局组中。它通过散列对象ID并根据定义的池中的PG数和池的ID应用操作来实现。
展示位置组中的对象的内容存储在一组OSD中。 例如,在大小为2的复制池中,每个放置组将在两个OSD上存储对象,如下所示。
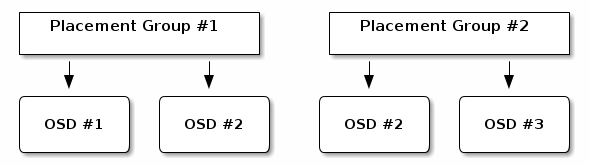
如果OSD#2失败,则另一个将被分配到放置组#1,并且将填充OSD#1中的所有对象的副本。 如果池大小从2更改为3,则将向该位置组分配一个附加的OSD,并将接收该位置组中所有对象的副本。
展示位置组不拥有OSD,它们与来自同一个池或其他池的其他展示位置组共享。 如果OSD#2发生故障,则安置组#2也将使用OSD#3恢复对象副本。
当展示位置组数量增加时,新的展示位置组将被分配OSD。 CRUSH功能的结果也会发生变化,并且来自前一个展示位置组的一些对象将被复制到新的展示位置组并从旧展示位置组中移除。
PLACEMENT GROUPS TRADEOFFS
所有OSD之间的数据持久性和均匀分配需要更多的放置组,但是它们的数量应该最小化以节省CPU和内存。
DATA DURABILITY(数据耐久性)
OSD失败后,数据丢失的风险会增加,直到其包含的数据完全恢复。 让我们想象一个在单个展示位置组中导致永久性数据丢失的情况:
OSD失败,并且其包含的对象的所有副本都丢失。 对于展示位置组中的所有对象,副本数量从3个下降到2个。 Ceph通过选择一个新的OSD来重新创建所有对象的第三个副本,为此放置组启动恢复。 在新的OSD完全填充第三个副本之前,同一位置组中的另一个OSD失败。 一些对象将只有一个幸存的副本。 Ceph选择另一个OSD,并保持复制对象以恢复所需的份数。 在同一个展示位置组中的第三个OSD在恢复完成之前失败。 如果此OSD包含对象的唯一剩余副本,则会永久丢失。
在包含10个OSD的集群中,在三个副本池中具有512个放置组,CRUSH将为每个展示组分配三个OSD。最后,每个OSD将最终托管(512 * 3)/ 10 =〜150个放置组。当第一个OSD失败时,上述情况将同时开始对所有150个放置组进行恢复。
正在恢复的150个安置组可能会在剩余的9个OSD中均匀分布。因此,每个剩余的OSD可能会将对象的副本发送给所有其他人,并且还会收到一些要存储的新对象,因为它们成为新的放置组的一部分。
完成此恢复所需的时间完全取决于Ceph群集的架构。假设每个OSD由单台机器上的1TB SSD进行托管,并且所有的OSD都连接到10Gb / s的交换机,单个OSD的恢复在M分钟内完成。如果每台机器使用两个不带SSD日志和1Gb / s交换机的转盘,则至少要慢一个数量级。
在这种大小的集群中,放置组的数量对数据的耐久性几乎没有影响。它可能是128或8192,恢复不会更慢或更快。
然而,将相同的Ceph集群增长到20个OSD而不是10个OSD可能会加快恢复速度,从而显着提高数据的耐久性。每个OSD现在仅参与〜75个放置组,而不是〜150,而只有10个OSD,并且仍然需要所有19个剩余的OSD来执行相同量的对象拷贝才能恢复。但是,如果10个OSD不得不复制大约100GB,那么它们现在必须复制50GB。如果网络成为瓶颈,恢复速度将会快两倍。换句话说,当OSD的数量增加时,恢复会更快。
如果这个群集增长到40个OSD,那么它们每个只能托管〜35个位置组。如果OSD死机,恢复将保持更快速度,除非被另一个瓶颈阻挡。但是,如果这个群集增长到200个OSD,那么它们每个只能容纳7个放置组。如果OSD死亡,这些放置组中最多可以在〜21(7 * 3)个OSD之间恢复恢复:恢复将比40个OSD更长,这意味着应该增加放置组的数量。
无论恢复时间多短,在进行中第二个OSD都有可能会失败。在上述10个OSD集群中,如果其中任何一个失败,则〜17个放置组(即〜150/9个放置组正在恢复)将只有一个存活副本。如果剩下的8个OSD中的任何一个失败,两个放置组的最后一个对象可能会丢失(即〜17个/ 8个放置组,只有一个剩余的副本被恢复)。
当集群的大小增加到20个OSD时,丢失三个OSD的放置组数量将下降。第二个OSD丢失将降级〜4(即〜75/19个放置组正在恢复)而不是〜17,第三个OSD丢失只会丢失数据,如果它是包含幸存副本的四个OSD之一。换句话说,如果在恢复时间段内丢失一个OSD的概率为0.0001%,则在具有20个OSD的集群中,具有10个OSD的集群中的17 * 10 * 0.0001%变为4 * 20 * 0.0001%。
简而言之,更多的OSDs意味着恢复速度更快,并且级联故障的风险降低,导致Placement Group的永久性损失。在数据持久性方面,拥有512或4096个放置组的群集与少于50个OSD的群集大致相同。
注意:添加到群集中的新OSD可能需要很长时间才能填充分配给它的展示位置组。然而,任何对象都不会降级,并且对集群中包含的数据的耐久性没有影响。
OBJECT DISTRIBUTION WITHIN A POOL(在池内的对象分配)
理想情况下,对象均匀分布在每个放置组中。由于CRUSH计算每个对象的放置组,但实际上并不知道此放置组内每个OSD中存储的数据量多少,所以放置组数与OSD数之间的比率可能会显着影响数据的分布。
例如,如果在三个副本池中存在十个OSD的单个放置组,则仅使用三个OSD,因为CRUSH将不再有其他选择。当更多的展示位置组可用时,对象更有可能在其中均匀分布。 CRUSH还尽力在所有现有的展示位置组中均匀分布OSD。
只要安置组比OSD多一个或两个数量级,分配应该是均匀的。例如,3个OSD的300个放置组,10个OSD的1000个放置组等。
数据分布不均匀可能是因为OSD和布局组之间的比例以外的因素。由于CRUSH不考虑对象的大小,所以几个非常大的对象可能会产生不平衡。总共4GB的一百万4K个物体在10个OSD中的1000个放置组中均匀分布。他们将在每个OSD上使用4GB / 10 = 400MB。如果一个400MB对象被添加到池中,则支持放置对象的放置组的三个OSD将填充400MB + 400MB = 800MB,而另外7个则将仅占用400MB。
MEMORY, CPU AND NETWORK USAGE(内存,CPU和网络使用)
对于每个放置组,OSD和MONs在恢复期间始终需要内存,网络和CPU,甚至更多。 通过将展示位置组中的对象进行聚类来共享此开销是其存在的主要原因之一。
放置组数量最小化可节省大量资源。
选择放置组的数量
如果您有超过50个OSD,建议每个OSD约50-100个放置组,以平衡资源使用,数据持久性和分发。 如果OSD不到50个,则在上述之前选择最佳选择。 对于单个对象池,可以使用以下公式获取基准:
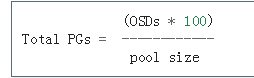
其中池大小是复制池的副本数或擦除编码池的K + M之和(由ceph osd erasure-code-profile get返回)。
然后,应该检查结果是否符合设计Ceph群集的方式,以最大限度地提高数据持久性,对象分布和最小化资源使用。
结果应该四舍五入为最接近的两个权力。 舍入是可选的,但推荐使用CRUSH均匀平衡展示位置组中的对象数量。
例如,对于具有200个OSD和3个副本的池大小的集群,您可以估计您的PG数,如下所示:

当使用多个数据池存储对象时,需要确保平衡每个池的展示位置组数与每个OSD的展示位置数量,以便达到合理的总排列数,每个OSD提供合理的低差异 不征税系统资源或使对等过程太慢。
例如,10个池中的10个池的集群,每个在10个OSD上具有512个放置组,总共有5,120个放置组,分布在10个OSD中,每个OSD为512个放置组。 那没有太多的资源。 但是,如果每个池中创建了1,000个池,每个池将分配512个组,OSD将会处理每个约50,000个位置组,同时需要更多的资源和时间进行对等。
设置放置组的数量
要设置池中的展示位置组数,必须在创建池时指定展示位置组数。为泳池设置展示位置组后,可能会增加展示位置组的数量(但不能减少展示位置组数)。 要增加展示位置组数,请执行以下操作:
ceph osd pool set {pool-name} pg_num {pg_num}增加展示位置组数后,您还必须增加展示位置组数(pgp_num),然后集群才能重新平衡。 pgp_num将是由CRUSH算法考虑放置的放置组数。 增加pg_num会拆分展示位置组,但不会将数据迁移到较新的展示位置组,直到展示位置的展示位置组为准。 pgp_num增加。 pgp_num应该等于pg_num。 要增加展示位置组的数量,请执行以下操作:
ceph osd pool set {pool-name} pgp_num {pgp_num}获取放置组的数量
要获取池中的展示位置组数,请执行以下操作:
ceph osd pool get {pool-name} pg_num获得一个群组的PG统计数据
要获取集群中的展示位置组的统计信息,请执行以下操作:
ceph pg dump [--format {format}] #有效的格式是plain(默认)和json。获得STUCK PGS的统计资料
要获取所有位于指定状态的展示位置组的统计信息,请执行以下操作:
ceph pg dump_stuck inactive|unclean|stale|undersized|degraded [--format <format>] [-t|--threshold <seconds>]
Inactive:非活动放置组无法处理读取或写入,因为它们正在等待具有最新数据的OSD并进入。
Unclean:不清楚的展示位置组包含未复制所需次数的对象。 他们应该恢复。
Stale:陈旧的展示位置组处于未知状态 - 托管它们的OSD未在一段时间内报告给监视器集群(由mon_osd_report_timeout配置)。
有效的格式是plain(默认)和json。 阈值定义了放置组在将其包含在返回的统计信息(默认300秒)之前的最小秒数。
获取PG MAP
要获取特定展示位置组的展示位置组 map,请执行以下操作:
ceph pg map {pg-id}
#实际例子如:
ceph pg map 1.6c#Ceph将返回布局组地图,展示位置组和OSD状态,如:osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]
获得PGS统计
要检索特定展示位置组的统计信息,请执行以下操作:
ceph pg {pg-id} query擦洗一个放置组
要刷新展示位置组,请执行以下操作:
ceph pg scrub {pg-id}Ceph检查主节点和任何副本节点,生成放置组中所有对象的目录,并对其进行比较,以确保没有对象丢失或不匹配,并且其内容一致。 假设副本全部匹配,最终语义扫描确保所有与快照相关的对象元数据是一致的。 错误通过日志报告。
优先GROUP(S)的重新布置/恢复
可能会遇到一群放置组需要恢复和/或回填的情况,而某些特定的组保存数据比其他数据更重要(例如,那些PG可能会保存运行机器和其他PG所使用的图像的数据) 由非活动机器使用/较少的相关数据)。 在这种情况下,您可能希望优先恢复这些组,以便早期恢复存储在这些组中的数据的性能和/或可用性。 要做到这一点(将特定的展示位置组标记为在回填或恢复期间优先),请执行以下操作:
ceph pg force-recovery {pg-id} [{pg-id #2}] [{pg-id #3} ...]
ceph pg force-backfill {pg-id} [{pg-id #2}] [{pg-id #3} ...]这将导致Ceph首先在其他展示位置组之前对指定的展示位置组执行恢复或回填。 这不会中断当前正在进行的回填或恢复,而是会尽快处理指定的PG。 如果您改变主意或确定错误组的优先级,请使用:
ceph pg cancel-force-recovery {pg-id} [{pg-id #2}] [{pg-id #3} ...]
ceph pg cancel-force-backfill {pg-id} [{pg-id #2}] [{pg-id #3} ...]这将从这些PG中删除“force”标志,它们将以默认顺序进行处理。 同样,这并不影响当前处理的展示位置组,也不影响仍处于排队状态。
“force”标志在组合恢复或回填完成后自动清除。
还原丢失
如果集群丢失了一个或多个对象,并且您决定放弃对丢失的数据的搜索,则必须将未对齐的对象标记为丢失。
如果查询了所有可能的位置,并且对象仍然丢失,您可能必须放弃丢失的对象。 这可能是由于异常组合的故障,允许集群了解在写入本身被恢复之前执行的写入。
目前唯一支持的选项是“还原”,它将回滚到先前版本的对象,或者(如果它是一个新对象)完全忘记了。 要将“未确定”对象标记为“丢失”,请执行以下操作:
ceph pg {pg-id} mark_unfound_lost revert|delete#重要请谨慎使用此功能,因为它可能会混淆预期对象存在的应用程序。
1.2.11 USING THE PG-UPMAP
从Luminous v12.2.z开始,在OSDMap中有一个新的pg-upmap异常表,允许集群将特定的PG显式地映射到特定的OSD。 这允许集群在多数情况下微调数据分发到跨OSD的完美分布式PG。
介绍链接:http://docs.ceph.com/docs/master/rados/operations/upmap/
1.2.12 CRUSH MAPS
CRUSH算法通过计算数据存储位置来确定如何存储和检索数据。 CRUSH授权Ceph客户直接与OSD通信,而不是通过集中式服务器或代理商进行通信。使用算法确定的存储和检索数据的方法,Ceph避免了单点故障,性能瓶颈以及其可扩展性的物理限制。
CRUSH需要您的集群映射,并使用CRUSH映射在OSD中伪随机存储和检索整个集群中数据均匀分布的数据。有关CRUSH的详细讨论,请参见CRUSH - 受控的,可扩展的,分散放置的复制数据:https://ceph.com/wp-content/uploads/2016/08/weil-crush-sc06.pdf
CRUSH地图包含OSD列表,用于将设备聚合到物理位置的“桶”列表,以及告诉CRUSH如何在Ceph群集池中复制数据的规则列表。通过反映安装的基础物理组织,CRUSH可以对相关设备故障的潜在来源进行建模。典型的来源包括物理接近,共享电源和共享网络。通过将该信息编码到集群映射中,CRUSH放置策略可以在不同的故障域之间分离对象副本,同时仍然保持所需的分布。例如,为了解决并发故障的可能性,可能希望确保数据副本位于使用不同货架,机架,电源,控制器和/或物理位置的设备上。
部署OSD时,它们将自动放置在CRUSH映射下的主机节点下,该主机节点以其运行的主机名称为主机名。这与默认的CRUSH故障域结合确保复制副本或擦除代码碎片在主机之间分离,单个主机故障不会影响可用性。然而,对于较大的集群,管理员应仔细考虑其对故障域的选择。例如,跨机架分离副本对于中型到大型集群是常见的。
CRUSH位置
根据CRUSH图的层次结构,OSD的位置被称为CRUSH位置。该位置说明符采用描述位置的键和值对列表的形式。 例如,如果OSD位于特定的行,机架,机箱和主机中,并且是“默认”CRUSH树的一部分(绝大多数群集都是这种情况),则其压缩位置可以描述为:
root=default row=a rack=a2 chassis=a2a host=a2a1
注意:
键的顺序并不重要。
键名称(=的左侧)必须是有效的CRUSH类型。 默认情况下,这些包括root,数据中心,房间,行,pod,pdu,机架,机箱和主机,但是可以通过修改CRUSH映射将这些类型定制为任何适当的类型。
并不是所有的键都需要指定。 例如,默认情况下,Ceph自动将ceph-osd守护程序的位置设置为root = default host = HOSTNAME(根据主机名-s的输出)。
OSD的crush位置通常通过ceph.conf文件中设置的压缩位置配置选项来表示。 每次OSD启动时,它会验证它是否在CRUSH地图中的正确位置,如果不是,它会自动移动。 要禁用此自动CRUSH映射管理,请在[osd]部分中将以下内容添加到您的配置文件中:
osd crush update on start = false
CUSTOM LOCATION HOOKS(自定义地址)
可以使用自定义的位置钩子在启动时生成更完整的挤压位置。 样本ceph-crush-location实用程序将为给定的守护程序生成一个CRUSH位置字符串。 该位置是基于,按照优先顺序:
ceph.conf中的位置选项。 默认的root = default host = HOSTNAME,其中使用hostname -s命令生成主机名。
这本身并不有用,因为OSD本身具有完全相同的行为。 但是,可以修改脚本以提供其他位置字段(例如,机架或数据中心),然后通过配置选项启用挂接:
crush location hook = /path/to/customized-ceph-crush-location
这个钩子传递了几个参数(下面),应该使用CRUSH位置描述输出一行到stdout:
$ ceph-crush-location --cluster CLUSTER --id ID --type TYPE
#集群名称通常为“ceph”,id为守护程序标识符(OSD编号),守护程序类型通常为osd。
CRUSH结构
CRUSH图由松散地描述了描述集群的物理拓扑的层次,以及一组定义关于如何在这些设备上放置数据的策略的规则。 层次结构在叶子上具有设备(ceph-osd守护进程),对应于其他物理特征或分组的内部节点:主机,机架,行,数据中心等。 这些规则描述了如何根据该层次结构放置副本(例如,“不同机架中的三个副本”)。
DEVICES(设备)
设备是可以存储数据的单独的ceph-osd守护程序。 通常,您的群集中的每个OSD守护进程通常都有一个定义。 设备由id(非负整数)和名称(通常为osd.N,其中N为设备标识)标识。
设备还可以具有与其相关联的设备类(例如,hdd或ssd),从而允许它们被crush规则方便地定向。
TYPES AND BUCKETS
bucket 是用于层次结构中内部节点的CRUSH术语:主机,机架,行等。CRUSH映射定义了一系列用于描述这些节点的类型。 默认情况下,这些类型包括:osd (or device)、host、chassis、rack、row、pdu、pod、room、datacenter、region、root
大多数集群只能使用这些类型,其他集合可以根据需要进行定义。
层次结构使用设备(通常类型为osd)在叶上,具有非设备类型的内部节点和根类型的根节点构建。 例如,
层次结构中的每个节点(设备或bucket)具有与之相关联的权重,指示设备或层次结构子树应存储的总数据的相对比例。 权重设置在叶子上,指示设备的大小,并从那里自动总结树,这样默认节点的权重将是其下包含的所有设备的总和。 通常权重以兆字节(TB)为单位。
可以简单地查看集群的CRUSH层次结构,包括权重,其中包括:
ceph osd crush tree
RULES(规则)
规则定义关于如何在层次结构中的设备之间分布数据的策略。
CRUSH规则定义了布局和复制策略或分发策略,允许您准确指定CRUSH放置对象副本的方式。 例如,您可以为双向镜像创建一个选择一对目标的规则,另一个规则用于在两个不同的数据中心中选择三个目标进行三向镜像,另一个规则用于在六个存储设备上进行擦除编码。
在几乎所有情况下,可以通过CLI指定要用于(复制或擦除编码)的池类型,故障域和可选的设备类来创建CRUSH规则。 在极少数情况下,手动编辑CRUSH地图必须手工编写。
可以通过以下方式查看为集群定义的规则:
ceph osd crush rule ls
可以查看规则的内容:
ceph osd crush rule dump
DEVICE CLASSES(设备类)
每个设备可以可选地具有与其相关联的类。 默认情况下,OSD会根据所支持的设备类型自动将其启动类设置为hdd,ssd或nvme。
一个或多个OSD的设备类可以通过以下方式明确设置:
ceph osd crush set-device-class <class> <osd-name> [...]
一旦设备类被设置,它不能被改变到另一个类,直到旧类被取消设置:
ceph osd crush rm-device-class <osd-name> [...]
这允许管理员设置设备类,而OSD重新启动或其他脚本不改变类。
可以使用以下方式创建定位特定设备类的放置规则:
ceph osd crush rule create-replicated <rule-name> <root> <failure-domain> <class>
然后可以更改池以使用新规则:
ceph osd pool set <pool-name> crush_rule <rule-name>
通过为仅包含该类的设备的每个使用设备类创建“阴影”CRUSH层次结构来实现设备类。 然后规则可以通过阴影层次结构分发数据。 这种方法的一个好处是它与旧的Ceph客户完全向后兼容。 您可以使用以下方式查看具有影子项目的CRUSH层次结构:
ceph osd crush tree --show-shadow
WEIGHTS SETS(权重设置)
权重集是计算数据放置时使用的一组权重。 根据设备大小设置与CRUSH映射中每个设备相关联的正常权重,并指示我们应该存储多少数据。 然而,因为CRUSH是基于伪随机放置过程,所以总是有一些这种理想分布的变化,同样的方式,滚动一个骰子六十次不会导致滚动正好10和10 sixes。 权重集允许集群根据集群(层次结构,池等)的细节进行数值优化,以实现均衡分配。
支持两种类型的重量组:
compat weight : 一个compat权重集是集群中每个设备和节点的一组权重。这不太适合于纠正所有的异常情况(例如,不同池的放置组可能是不同的大小,并且具有不同的负载水平,但是平衡器大多被处理相同)。然而,均衡器具有巨大的优势,它们与以前版本的Ceph向后兼容,这意味着即使重量组首先在Luminous v12.2.z中引入,较老的客户端仍然可以连接到当使用compat权重集合来平衡数据时,会发生群集。
per-pool weight : 每池重量集更灵活,因为它可以为每个数据池优化布局。另外,可以针对每个放置位置来调整权重,从而允许优化器将数据的偏倚修正为相对于其对等体的权重较小的设备(以及通常仅显示在非常大的集群中但可能导致平衡问题的效果) )。
当使用权重集时,与命令中的每个节点关联的权重作为单独的列(标记为(compat)或池名称)可见):
ceph osd crush tree
当使用compat和每池重量组时,特定池的数据放置将使用其自身的每池重量集(如果存在)。 如果没有,它将使用compat重量集(如果存在)。 如果两者都不存在,它将使用正常的CRUSH权重。虽然可以手动设置和操作重量组,但建议使平衡器模块自动执行。
修改CRUSH MAP
ADD/MOVE AN OSD(添加/移动 osd)
要在正在运行的集群的CRUSH映射中添加或移动OSD:
ceph osd crush set {name} {weight} root={root} [{bucket-type}={bucket-name} ...]#上面参数的意思:
name #osd的全称,比如osd.10 weight #OSD的CRUSH重量,通常其大小测量单位为TB(TB)。比如2.0 root #OSD所在的树的根节点(通常默认),比如:root=default bucket-type #可以在CRUSH层次结构中指定OSD的位置。比如:datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-1
以下示例将osd.0添加到层次结构中,或将OSD从先前位置移动:
ceph osd crush set osd.0 1.0 root=default datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-1
ADJUST OSD WEIGHT(调整OSD的权重)
要调整运行集群的CRUSH映射中的OSD压缩权重,请执行以下操作:
ceph osd crush reweight {name} {weight}REMOVE AN OSD(删除OSD)
要从正在运行的集群的CRUSH映射中删除OSD,请执行以下操作:
ceph osd crush remove {name}ADD A BUCKET(添加一个BUCKET)
要在正在运行的集群的CRUSH映射中添加存储桶,请执行ceph osd crush add-bucket命令:
ceph osd crush add-bucket {bucket-name} {bucket-type}#以上参数的意思:
bucket-name #bucket的全称,比如rack12 bucket-type #bucket的类型,类型必须已经存在于层次结构中。比如rack
以下示例将rack12 bucket添加到层次结构中:
ceph osd crush add-bucket rack12 rack
MOVE A BUCKET(移动一个BUCKET)
要将存储桶移动到CRUSH映射层次结构中的其他位置或位置,请执行以下操作:
ceph osd crush move {bucket-name} {bucket-type}={bucket-name}, [...]
#bucket-name #bucket的名称移动/重新定位。比如foo-bar-1
#bucket-type #可以在CRUSH层次结构中指定该bucket的位置。比如:datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-1REMOVE A BUCKET(取出一个BUCKET)
要从CRUSH映射层次结构中删除bucket,请执行以下操作:
ceph osd crush remove {bucket-name}#注意将bucket从CRUSH层次结构中删除之前,bucket必须为空。
CREATING A COMPAT WEIGHT SET(创建一个COMPAT的权重设置)
#创建一个compat的权重设置:
ceph osd crush weight-set create-compat
#一个小型的compat权重设置:
ceph osd crush weight-set reweight-compat {name} {weight}
#compat权重设置可以被删除:
ceph osd crush weight-set rm-compatCREATING PER-POOL WEIGHT SETS(创建PER-POOL的权重设置)
要为特定池创建一个权重集:
ceph osd crush weight-set create {pool-name} {mode}
#pool-name #RADOS池的名称,比如rbd
#mode #flat or positional。位置权重集合对于结果位置映射中的每个位置具有潜在的不同权重。 例如,如果池的副本计数为3,那么位置权重集对于每个设备和存储桶将具有三个权重。比如flat。#注意per-pool权重集要求所有服务器和守护程序运行Luminous v12.2.z或更高版本。
#调整一个项目的权重设置
ceph osd crush weight-set reweight {pool-name} {item-name} {weight [...]}
#列出现有的权重设置:
ceph osd crush weight-set ls
#删除一个权重设置:
ceph osd crush weight-set rm {pool-name}创建一个备份池
对于复制池,创建CRUSH规则时的主要决定是故障域将要做的。例如,如果选择了主机的故障域,则CRUSH将确保数据的每个副本都存储在不同的主机上。如果选择了机架,则每个副本将被存储在不同的机架中。您选择的失败域主要取决于集群的大小以及层次结构的结构。
通常,整个集群层次结构嵌套在名为default的根节点之下。如果您已经自定义了层次结构,则可能需要创建一个嵌套在层次结构中某个其他节点的规则。什么类型与该节点相关联无关紧要(它不必是根节点)。
也可以创建一个将数据放置限制到特定类别的设备的规则。默认情况下,Ceph OSD会自动将其自身分类为hdd或ssd,具体取决于所使用设备的基础类型。这些类也可以定制。
要创建复制规则:
ceph osd crush rule create-replicated {name} {root} {failure-domain-type} [{class}]
#name #规则的名称比如rbd-rule
#root #要放置数据的节点的名称。比如default
#failure-domain-type #crush节点是跨越的,所以我们要分开副本,比如rack
#class #什么类型的设备放置数据,比如ssdCREATING A RULE FOR AN ERASURE CODED POOL(创建一个ERASURE CODED 规则)
erasure code配置文件可以列出:
ceph osd erasure-code-profile ls
现有的配置文件可以查看:
ceph osd erasure-code-profile get {profile-name}通常不应修改配置文件; 相反,在创建新池或为现有池创建新规则时,应创建并使用新的配置文件。
相关的属性是:
crush-root #将数据放在[default:default]下的CRUSH节点的名称。 crush-failure-domain #CRUSH类型,以跨[default:host]分隔erasure-coded的分片。 crush-device-class #将数据放在[default:none,意思是使用所有设备]的设备类。 k and m(并且对于lrc插件,l)#这些确定erasure-coded 分片的数量,影响生成的CRUSH规则。
一旦配置文件被定义,你可以创建一个CRUSH规则:
ceph osd crush rule create-erasure {name} {profile-name}DELETING RULES(删除规则)
池中未使用的规则可以删除:
ceph osd crush rule rm {rule-name}PRIMARY AFFINITY
当Ceph客户端读取或写入数据时,它始终与代理集中的主OSD相关联。 对于集合[2,3,4],osd.2是主要的。 有时,与其他OSD(例如,它具有慢磁盘或慢速控制器)相比,OSD不太适合作为主要操作。 为了防止性能瓶颈(尤其是读取操作),同时最大程度地提高硬件的利用率,您可以设置Ceph OSD的主要亲和性,以使CRUSH不太可能将OSD用作代理集中的主要。
ceph osd primary-affinity <osd-id> <weight>
默认情况下,主要亲和度为1(即,OSD可以充当主要关联)。 您可以将OSD的主要范围设置为0-1,其中0表示OSD不能用作主关联,1表示可以将OSD用作主关联。 当权重<1时,CRUSH将不太可能选择Ceph OSD后台程序作为主要功能。
还有个可调参数:http://docs.ceph.com/docs/master/rados/operations/crush-map/#tunables没有记录。
MANUALLY EDITING A CRUSH MAP(手工编辑crush map)
官方链接:http://docs.ceph.com/docs/master/rados/operations/crush-map-edits/
http://blog.51niux.com/?id=162 #第一部分已经记录了怎么手工编辑crush map.
1.2.13 添加/删除 OSDS
当启动并运行集群时,可以在运行时添加OSD或从集群中删除OSD。
官网文档:http://docs.ceph.com/docs/master/rados/operations/add-or-rm-osds/
前面已经通过实例介绍了这里面的内容。
1.2.14 添加/删除监视器
集群启动并运行时,可以在运行时从集群添加或删除监视器。
官网文档:http://docs.ceph.com/docs/master/rados/operations/add-or-rm-mons/
#这种操作过程就不翻译了,用到了来照着走一遍就行了。
1.2.15 控制命令
官网文档:http://docs.ceph.com/docs/master/rados/operations/control/
#这里面都是一些常用命令
1.2.16 故障排查
minitor故障排查:http://docs.ceph.com/docs/master/rados/troubleshooting/troubleshooting-mon/
OSDS故障排查:http://docs.ceph.com/docs/master/rados/troubleshooting/troubleshooting-osd/
PGS故障排查:http://docs.ceph.com/docs/master/rados/troubleshooting/troubleshooting-pg/
1.2.17 登录和调试
通常,当将调试添加到Ceph配置中时,可以在运行时执行此操作。 如果在启动集群时遇到问题,还可以将Ceph调试日志记录添加到Ceph配置文件。 您可以在/var/log/ceph(默认位置)下查看Ceph日志文件。
日志记录是资源密集型的。 如果在群集的特定区域遇到问题,请启用群集区域的日志记录。 例如,如果OSD运行正常,但元数据服务器不是,则应首先启用针对特定元数据服务器实例的调试日志记录,以遇到问题。 根据需要启用每个子系统的记录。
重要详细日志记录可以每小时生成超过1GB的数据。 如果操作系统磁盘达到其容量,则节点将停止工作。
如果启用或提高Ceph日志记录的速率,请确保OS磁盘上有足够的磁盘空间。 当系统运行良好时,删除不必要的调试设置,以确保您的群集运行最佳。记录调试输出消息相对较慢,并且在运行集群时浪费资源。
RUNTIME(运行)
如果希望在运行时看到配置设置,则必须使用运行的守护程序登录到主机并执行以下操作:
ceph daemon {daemon-name} config show | less
#如:
ceph daemon osd.0 config show | less要在运行时激活Ceph的调试输出,请使用ceph tell命令将参数注入到运行时配置中:
ceph tell {daemon-type}.{daemon id or *} injectargs --{name} {value} [--{name} {value}]用osd,mon或mds替换{daemon-type}。 可以将运行时设置应用于具有*的特定类型的所有守护程序,或指定特定守护程序的ID。 例如,要增加名为osd.0的ceph-osd守护程序的调试日志记录,请执行以下操作:
ceph tell osd.0 injectargs --debug-osd 0/5
ceph tell命令通过监视器。 如果无法绑定到监视器,仍然可以通过登录要使用ceph守护程序更改其配置的守护程序的主机进行更改。 例如:
sudo ceph daemon osd.0 config set debug_osd 0/5
BOOT TIME(开机时间)
要在引导时激活Ceph的调试输出,必须将设置添加到Ceph配置文件中。每个守护程序通用的子系统可以在配置文件的[global]下设置。 用于特定守护进程的子系统设置在配置文件的守护程序部分(例如,[mon],[osd],[mds]))。 例如:
[global] debug ms = 1/5 [mon] debug mon = 20 debug paxos = 1/5 debug auth = 2 [osd] debug osd = 1/5 debug filestore = 1/5 debug journal = 1 debug monc = 5/20 [mds] debug mds = 1 debug mds balancer = 1
加速log的轮询
如果操作系统磁盘相对完整,可以通过修改/etc/logrotate.d/ceph上的Ceph日志旋转文件来加速日志轮换。 如果日志超过大小设置,请在旋转频率之后添加大小设置以加速日志旋转(通过cronjob)。 例如,默认设置如下所示:
rotate 7 weekly compress sharedscripts
通过添加大小设置进行修改:
rotate 7 weekly size 500M compress sharedscripts
然后,为用户空间启动crontab编辑器:
crontab -e
最后,添加一个条目来检查/etc/logrotate.d/ceph文件:
30 * * * * /usr/sbin/logrotate /etc/logrotate.d/ceph >/dev/null 2>&1
#上述示例每30分钟检查一次/etc/logrotate.d/ceph文件。
SUBSYSTEM, LOG AND DEBUG SETTINGS(子系统,日志和调试设置)
在大多数情况下,通过子系统启用调试日志输出。
CEPH SUBSYSTEMS(子系统)
每个子系统具有其输出日志的日志记录级别及其内存中的日志记录。 可以通过设置日志文件级别和调试日志记录的内存级别为每个子系统设置不同的值。 Ceph的记录级别以1到20的比例操作,其中1是简洁的,20是冗长的[1]。 通常,内存中的日志不会发送到输出日志,除非:
一个致命的信号被提高或 源代码中的断言被触发或 根据要求。 有关详细信息,请参阅管理套件上的文档。http://docs.ceph.com/docs/master/man/8/ceph/#daemon
调试日志记录设置可以为日志级别和内存级别采用单一值,将其设置为相同的值。 例如,如果指定调试ms = 5,Ceph将其视为日志级别和内存级别5.您还可以单独指定它们。 第一个设置是日志级别,第二个设置是内存级别。 必须用正斜杠(/)分隔它们。 例如,如果要将ms子系统的调试日志记录级别设置为1,其内存级别设置为5,则将其指定为调试ms = 1/5。 例如:
debug {subsystem} = {log-level}/{memory-level}
#for example
debug mds balancer = 1/20LOGGING SETTINGS(登录设置)
Ceph配置文件中不需要记录和调试设置,但您可以根据需要覆盖默认设置。 Ceph支持以下设置:
log file #集群的日志文件的位置。默认是/var/log/ceph/$cluster-$name.log log max new #新日志文件的最大数量。默认是1000 log max recent #日志文件中包含的最近事件的最大数量。默认是1000000 log to stderr #确定日志消息是否应显示在stderr中。默认是true err to stderr #确定错误消息是否应显示在stderr中。默认是true log to syslog #确定日志消息是否应该出现在syslog中。默认是false err to syslog #确定错误消息是否应该出现在syslog中。默认是false log flush on exit #确定Ceph是否应在退出后刷新日志文件。默认是true clog to monitors #确定是否将clog消息发送到监视器。默认是true clog to syslog #确定是否将clog消息发送到syslog。默认是false mon cluster log to syslog #确定是否应将集群日志输出到syslog。默认是false mon cluster log file #集群日志文件的位置。默认是/var/log/ceph/$cluster.log #OSD osd debug drop ping probability #默认值是0 osd debug drop ping duration #默认值是0 osd debug drop pg create probability #默认值是0 osd debug drop pg create duration #默认值是1 osd tmapput sets uses tmap #默认值是false osd min pg log entries #展示位置组的日志条目的最小数量。默认值是1000 osd op log threshold #在一次通过中显示多少个操作日志消息。默认值是5 #FILESTORE filestore debug omap check #调试检查同步。默认是0 #MDS mds debug scatterstat #Ceph将断言各种递归统计不变量是真实的(仅适用于开发者)。默认是false mds debug frag #Ceph将在方便时验证目录碎片不变量(仅限开发人员)。默认是false mds debug auth pins #调试验证引脚不变(仅适用于开发人员)。默认是false mds debug subtrees #调试子树不变量(仅适用于开发人员)。默认是false #RADOS GATEWAY rgw log nonexistent bucket #应该记录不存在的存储桶,默认是false rgw log object name #应该记录对象的名称。默认是%Y-%m-%d-%H-%i-%n rgw log object name utc #对象日志名称包含UTC,默认是false rgw enable ops log #启用每个RGW操作的日志记录。默认是true rgw enable usage log #启用RGW的带宽使用记录。默认是true rgw usage log flush threshold #清除挂起的日志数据的阈值。默认是1024 rgw usage log tick interval #每隔几秒清空一次挂起的日志数据。默认是30 rgw intent log object name #默认是%Y-%m-%d-%i-%n rgw intent log object name utc #在intent日志对象名称中包含UTC时间戳。默认是false
1.2.18 CPU配置
如果您从源代码编译Ceph并编译Ceph与oprofile一起使用,您可以配置Ceph的CPU使用情况。
有关详细信息,请参阅安装Oprofile : http://docs.ceph.com/docs/master/dev/cpu-profiler/
初步化OPROFILE
首次使用oprofile时,需要初始化它。 找到与您正在运行的内核对应的vmlinux映像。
ls /boot
sudo opcontrol --init
sudo opcontrol --setup --vmlinux={path-to-image} --separate=library --callgraph=6启动OPROFILE
要启动oprofile,请执行以下命令:
opcontrol --start #关闭命令就是opcontrol --stop
#一旦你开始oprofile,你可以用Ceph运行一些测试。
检索OPROFILE结果
要检索顶部cmon结果,请执行以下命令:
opreport -gal ./cmon | less
要使用附加的调用图检索顶部cmon结果,请执行以下命令:
opreport -cal ./cmon | less
#重要在查看结果后,应重新设置oprofile,然后重新运行。 重置oprofile会从会话目录中删除数据。
重置OPROFILE
要重置oprofile,请执行以下命令:
sudo opcontrol --reset
#重要在分析数据后,应该重新设置oprofile,以便不会使来自不同测试的结果相符。
二、Ceph 文件系统
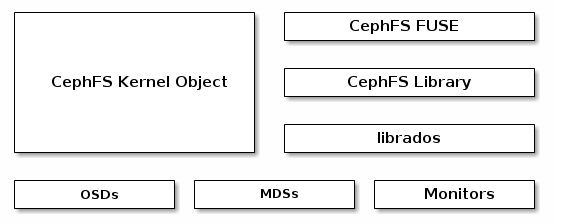
Ceph文件系统(Ceph FS)是符合POSIX的文件系统,使用Ceph存储集群来存储其数据。 Ceph文件系统使用与Ceph Block Devices,Ceph Object Storage及其S3和Swift API或本地绑定(librados)相同的Ceph存储集群系统。
2.1 使用CephFS
2.1.1 添加/删除元数据服务器
使用ceph-deploy,添加和删除元数据服务器是一项简单的任务。 只需使用一个命令在命令行中添加或删除一个或多个元数据服务器。
必须部署至少一个元数据服务器才能使用CephFS。 有运行多个元数据服务器的实验支持。 在生产中不要运行多个活动的元数据服务器。
有关配置元数据服务器的详细信息,请参考:http://docs.ceph.com/docs/master/cephfs/mds-config-ref/
添加元数据服务器
部署监视器和OSD后,可以部署元数据服务器。
ceph-deploy mds create {host-name}[:{daemon-name}] [{host-name}[:{daemon-name}] ...]#如果要在单个服务器上运行多个守护程序,则可以将守护程序实例指定为名称(可选)。
2.1.2 术语
Ceph集群可能具有零个或多个CephFS文件系统。 CephFS文件系统具有可读的名称(在fs新设置)和整数ID。该ID称为文件系统集群ID或FSCID。
每个CephFS文件系统都有多个等级,一个默认为从零开始。排名可能被认为是元数据分片。在配置多个活动的MDS守护程序中描述了控制文件系统中的排名数量
每个CephFS ceph-mds进程(守护进程)最初没有排名启动。监视器集群可以分配一个。守护进程一次只能持有一个等级。守护进程仅在ceph-mds进程停止时才放弃等级。
如果一个等级与守护进程没有关联,则排名被认为是失败的。一旦一个等级被分配给一个守护进程,排名被考虑。
守护程序在管理员首次配置时,具有由管理员静态设置的名称。典型配置使用守护程序作为守护程序名称运行的主机名。
每次守护程序启动时,还会分配一个GID,这对守护进程的这个特定进程的生命周期是唯一的。 GID是一个整数。
引用MDS DAEMONS
引用MDS守护程序的大多数管理命令接受可能包含排名,GID或名称的灵活参数格式。
使用排名时,可以选择使用主要文件系统名称或ID进行限定。 如果一个守护进程是备用的(即它当前没有被分配一个等级),那么它只能由GID或者名称引用。
例如,如果我们有一个称为“myhost”的MDS守护程序,则具有GID 5446,并且在具有FSCID 3的文件系统“myfs”中被分配了0级,则以下任何一种将是“fail”命令:
ceph mds fail 5446 # GID ceph mds fail myhost # Daemon name ceph mds fail 0 # Unqualified rank ceph mds fail 3:0 # FSCID and rank ceph mds fail myfs:0 # Filesystem name and rank
管理失败
如果MDS守护程序停止与监视器通信,则在将守护程序标记为滞后之前,监视器将等待mds_beacon_grace秒(默认15秒)。
每个文件系统可以指定一些备用守护进程被认为是健康的。 此数字包括待机重播中的守护程序等待级别失败(请记住,不会分配备用重放守护程序来接管其他级别的故障或另一个CephFS文件系统中的故障)。 备用守护进程池不在重播中计数到任何文件系统计数。 每个文件系统可以使用以下命令设置待机守护程序的数量:
ceph fs set <fs name> standby_count_wanted <count>
#设置为0将禁用运行状况检查。
配置STANDBY DAEMONS
有四种配置设置可以控制待机中守护进程的行为:
mds_standby_for_name mds_standby_for_rank mds_standby_for_fscid mds_standby_replay
这些可以在运行MDS守护程序的主机上的ceph.conf中设置(而不是在监视器上)。 守护程序启动时加载这些设置,并将其发送到监视器。
默认情况下,如果没有使用这些设置,则不保留排名的所有MDS守护程序将被用作任何等级的备用。
将备用守护程序与特定名称或等级相关联的设置不保证守护程序将仅用于该级别。 这意味着当有几个standbys可用时,将使用相关的备用守护程序。 如果排名失败,并且待机状态可用,即使它与不同的排名或命名守护程序相关联,也将被使用。
MDS重播支持
如果设置为true,则备用守护程序将持续读取升级的元数据日志。 这将给它一个温暖的元数据缓存,并且如果服务于排名的守护程序失败,则可以加快失败的过程。
如果两个守护进程都设置为待机重播,则其中一个将任意获胜,另一个将成为正常的非重放待机。
一旦守护程序进入待机重播状态,它将只能用作其所遵循的等级的备用。 如果另一个排名失败,则此备用重播守护程序将不会用作替换,即使没有其他备用数据库可用。
历史记录:在v.10.2.1之前的Ceph中,当设置mds_standby_for_ *时,此设置(当为false时)始终为真。
简单主副
两个MDS守护程序'a'和'b'作为一对,其中当前不分配一个等级的人将是另一个的备用重播追随者。
[mds.a] mds standby replay = true mds standby for rank = 0 [mds.b] mds standby replay = true mds standby for rank = 0
#MDS_STANDBY_FOR_RANK将其设置为使备用守护程序仅接管指定的等级。 如果另一个排名失败,则该守护程序将不会被替换。
#与mds_standby_for_fscid结合使用,具体说明您要定位的文件系统的排名,如果您有多个文件系统。
两个mds文件系统
有两个文件系统,我有四个MDS守护程序,我想要两个作为一个文件系统的一对,另外两个作为另一个文件系统的一对
[mds.a] mds standby for fscid = 1 [mds.b] mds standby for fscid = 1 [mds.c] mds standby for fscid = 2 [mds.d] mds standby for fscid = 2
#如果设置了mds_standby_for_rank,这只是一个限定词来说明哪个文件系统的等级被引用。
#如果未设置mds_standby_for_rank,则设置FSCID将导致此守护程序定位到指定的FSCID中的任何等级。 如果您有一个要用于任何等级的守护程序,但仅在特定的文件系统中,请使用此功能。
2.1.3 MDS配置参考
mon force standby active #monitors强制待机-重播至活动。设置在[mon]或[global]下。默认是true mds max file size #创建新文件系统时允许设置的最大文件大小。默认是1ULL << 40 mds cache size #要缓存的inode的数量。默认是100000 mds cache mid #缓存LRU中新项目的插入点(从顶部)。默认是0.7 mds dir commit ratio #Ceph在使用完整更新(而不是部分更新)之前提交的目录的一小部分。默认是0.5 mds dir max commit size #Ceph将目录更新的最大大小更新为较小的事务)(MB)。默认是90 mds decay halflife #MDS缓存的半衰期。默认是5 mds beacon interval #发送到监视器的信标消息的频率(秒)。默认是4 mds beacon grace #在Ceph之前没有信标的间隔声明MDS滞后(并可能取代它)。默认是15 mds blacklist interval #OSD映射中MDS失败的黑名单持续时间。默认是24.0*60.0 mds session timeout #Ceph之前客户端不活动的时间间隔(秒)超出能力和租约。默认是60 mds session autoclose #Ceph之前的间隔(以秒为单位)关闭滞后客户端的会话。默认是300 mds reconnect timeout #在MDS重新启动期间等待客户端重新连接的间隔(以秒为单位)。默认是45 mds tick interval #MDS执行内部周期性任务的频率。默认是5 mds dirstat min interval #尝试避免在树上传播递归统计信息的最小间隔(以秒为单位)。默认是1 mds scatter nudge interval #dirstat变化如何快速传播。默认是5 mds client prealloc inos #每个客户端会话预先分配的inode号的数量。默认是1000 mds early reply #确定MDS是否应允许客户端在提交到日志之前查看请求结果。默认是true mds use tmap #使用trivialmap进行目录更新。默认是true mds default dir hash #用于跨目录片段散列文件的功能。默认是2(即rjenkins) mds log skip corrupt events #确定在日记重播期间MDS是否应尝试跳过损坏的日记事件。默认是false mds log max events #在我们开始操作之前,journal中的最大事件。 设置为-1以禁用限制。默认是-1 mds log max segments #在我们开始操作之前,journal中最大段数(对象)。 设置为-1以禁用限制。默认是30 mds log max expiring #最多可以同时到期的细分数。默认是20 mds log eopen size #Open事件中的inode的最大数量。默认是100 mds bal sample interval #确定样本目录的频率(用于碎片决定)。默认是3 mds bal replicate threshold #Ceph尝试将元数据复制到其他节点之前的最大热度。默认是8000 mds bal unreplicate threshold #热度低到多少时 Ceph 就不再把元数据复制到其它节点。默认是0 mds bal frag #MDS 是否应该给目录分片。 默认是false mds bal split size #目录尺寸大到多少时 MDS 就把片段拆分成更小的片段。默认是10000 mds bal split rd #目录的最大读取热度达到多大时 Ceph 将拆分此片段。默认是25000 mds bal split wr #目录的最大写热度达到多大时 Ceph 将拆分此片段。默认是10000 mds bal split bits #分割目录片段的位数。。默认是3 mds bal merge size #Ceph尝试合并相邻目录片段之前的最小目录大小。默认是50 mds bal interval #MDS之间工作量交换的频率(秒)。默认是10 mds bal fragment interval #片段之间的延迟(以秒为单位)有资格进行拆分或合并,并执行碎片更改。默认是5 mds bal fragment fast factor #在拆分之前,碎片可能超过拆分大小的比率立即执行(跳过片段间隔)默认是1.5 mds bal fragment size max #任何新条目之前的片段的最大大小被ENOSPC拒绝,默认是100000 mds bal idle threshold #热度低于此值时 Ceph 把子树迁移回父节点。默认是0 mds bal max #在Ceph停止之前运行平衡器的迭代次数。(仅用于测试目的)默认是-1 mds bal min rebalance #子树热度最小多少时开始迁移。默认是0.1 mds bal min start #子树热度最小多少时 Ceph 才去搜索。默认是0.2 mds bal need min #要接受的目标子树大小的最小分数。默认是0.8 mds bal need max #要接受的目标子树大小的最大分数。默认是1.2 mds bal midchunk #Ceph将迁移大于目标子树大小的这个分数的任何子树。默认是0.3 mds bal minchunk #Ceph将忽略小于目标子树大小的这个分数的任何子树。默认是0.001 mds bal target removal min #Ceph之前的平衡器迭代的最小次数从MDS映射中删除一个旧的MDS目标。默认是5 mds bal target removal max #Ceph之前平衡器迭代的最大次数从MDS映射中删除一个旧的MDS目标。默认是10 mds replay interval #在待机重播模式下的日志轮询间隔。(“热备”)默认是1 mds shutdown check #在MDS关机期间轮询缓存的时间间隔。默认是0 mds thrash exports #Ceph将随机导出节点之间的子树(仅测试)。默认是0 mds thrash fragments #Ceph会随机分割或合并目录。默认是0 mds dump cache on map #Ceph会将MDS缓存内容转储到每个MDSMap上的文件中。默认是false mds dump cache after rejoin #重新加入高速缓存后,Ceph会将MDS缓存内容转储到文件(在恢复期间)。默认是flase mds verify scatter #Ceph将断言各种分散/收集不变量是真实的(仅限开发人员)。默认是false mds debug scatterstat #Ceph将断言各种递归统计不变量是真实的(仅适用于开发者)。默认是false mds debug frag #Ceph将在方便时验证目录碎片不变量(仅限开发人员)。默认是false mds debug auth pins #调试验证引脚不变(仅适用于开发人员)。默认是false mds debug subtrees #调试子树不变量(仅适用于开发人员)。默认是false mds kill mdstable at #Ceph将在MDSTable代码中注入MDS失败(仅适用于开发人员)。默认是false mds kill export at #Ceph将在子树导出代码中注入MDS失败(仅适用于开发人员)。默认是false mds kill import at #Ceph将在子树导入代码中注入MDS失败(仅适用于开发者)。默认是false mds kill link at #Ceph将在硬链接代码中注入MDS失败(仅适用于开发人员)。默认是false mds kill rename at #Ceph将在重命名代码中注入MDS失败(仅适用于开发人员)。默认是false mds wipe sessions #Ceph将在启动时删除所有客户端会话(仅用于测试)。默认是0 mds wipe ino prealloc #Ceph将在启动时删除ina预分配元数据(仅用于测试)。默认是0 mds skip ino #启动时跳过的inode号码数(仅用于测试)。默认是0 mds standby for name #MDS守护程序将为此设置中指定的名称的另一个MDS守护程序备用。默认是N/A mds standby for rank #MDS守护程序将为此级别的MDS守护程序备用。默认是-1 mds standby replay #确定ceph-mds守护程序是否应轮询并重播活动MDS(热备用)的日志。默认是false
2.1.4 客户端配置参考
client acl type #设置ACL类型。 目前,只有可能的值为“posix_acl”来启用POSIX ACL或空字符串。 此选项仅在fuse_default_permissions设置为false时生效。默认为“”(无ACL执行) client cache mid #设置客户端缓存中点。 中点将最近使用最少的列表分成热门和热门列表。默认是0.75 client_cache_size #设置客户端保存在元数据缓存中的inode的数量。默认是16384 client_caps_release_delay #在几秒钟内设置能力发布之间的延迟。 延迟设置客户端等待释放其不再需要的功能的秒数,以防需要另外的用户空间操作。默认是5 client_debug_force_sync_read #如果设置为true,则客户端可以直接从OSD读取数据,而不是使用本地页面缓存。默认是false client_dirsize_rbytes #如果设置为true,请使用目录的递归大小(即所有后代的总和)。默认是true client_max_inline_size #设置存储在文件inode中而不是在RADOS中的单独数据对象中的内联数据的最大大小。 此设置仅适用于在MDS映射上设置inline_data标志。默认是4096 client_metadata #发送到每个MDS的客户端元数据的逗号分隔字符串,以及自动生成的版本,主机名和其他元数据。默认是""(无ACL执行) client_mount_gid #设置CephFS mount的组ID。默认是-1 client_mount_timeout #设置CephFS挂载的超时秒数。默认300.0 client_mount_uid #设置CephFS mount的用户ID。默认是-1 client_mountpoint #安装在CephFS文件系统上的目录。 替代ceph-fuse命令的-r选项。默认是"/" client_oc #启用对象缓存。默认是true client_oc_max_dirty #设置对象缓存中最大的脏字节数。默认104857600 (100MB) client_oc_max_dirty_age #在回写前设置对象缓存中脏数据的最大年龄(秒)。默认是5.0 client_oc_max_objects #设置对象缓存中的最大对象数。默认是1000 client_oc_size #设置客户端缓存的数据字节数。默认209715200 (200 MB) client_oc_target_dirty #设置脏数据的目标大小。 建议保持这个数字低。默认8388608 (8MB) client_permissions #检查所有I/O操作的客户端权限。默认true client_quota #如果设置为true,则启用客户端配额检查。默认true client_quota_df #报告statfs操作的根目录配额。默认true client_readahead_max_bytes #设置内核向前读取的最大字节数,以备将来读取操作。 被client_readahead_max_periods设置覆盖。默认是0 client_readahead_max_periods #设置内核向前读取的文件布局周期数(对象大小*条纹数)。 覆盖client_readahead_max_bytes设置。默认是4 client_readahead_min #设置内核向前读取的最小字节数。默认131072 (128KB) client_reconnect_stale #自动重新连接失败的会话。默认是false client_snapdir #设置快照目录名称。默认".snap" client_tick_interval #在能力更新和其他维护之间设置间隔(以秒为单位)。默认是1.0 client_use_random_mds #为每个请求选择随机MDS。默认是false fuse_default_permissions #当设置为false时,ceph-fuse实用程序检查执行自己的权限检查,而不是依赖于FUSE中的权限执行。设置为false与客户端acl type = posix_acl选项一起启用POSIX ACL。默认是true
2.1.5 JOURNALER设置
journaler write head interval #更新日志头对象的频率,默认是15 journaler prefetch periods #在日志重播上有多少条带期待读取,默认是10 journal prezero periods #在写入位置之前有多少条带周期为零,默认是10 journaler batch interval #以秒为单位的最大额外延迟我们人为引发。默认.001 journaler batch max #我们将延迟刷新的最大字节数。默认0
2.1.6 Ceph-mds 元数据服务器守护进程
ceph-mds -i name [ –hot-standby [rank] ]
描述
ceph-mds是Ceph分布式文件系统的元数据服务器守护进程。 ceph-mds的一个或多个实例共同管理文件系统命名空间,协调对共享OSD集群的访问。
每个ceph-mds守护进程实例都应该有一个唯一的名称。 该名称用于标识ceph.conf中的守护程序实例。
一旦守护程序启动,监视器集群通常会将其分配给逻辑排名,或将其放在备用池中以接管另一个崩溃的守护程序。 某些指定的选项可能会导致其他行为。
如果指定热备份,则必须在命令行中指定排名,或者指定配置中的mds_standby_for_ [rank | name]参数之一。 命令行规范覆盖配置,并指定名称的rank覆盖。
选项
-f, --foreground #前台:启动后不要守护进程(在前台运行)。不要生成一个pid文件。 -d #调试模式:如-f,也可以将所有日志输出发送到stderr。 --setuser userorgid #启动后设置uid。 如果指定了用户名,则查找用户记录以获取uid和gid,并且还设置了gid,除非还指定了-setgroup。 --setgroup grouporgid #启动后设置gid。 如果指定了组名称,则查找组记录以获取gid。 -c ceph.conf, --conf=ceph.conf #使用ceph.conf配置文件而不是默认的/etc/ceph/ceph.conf来确定启动期间的监视器地址。 -m monaddress[:port] #连接到指定的监视器(而不是查看ceph.conf)。 --hot-standby <rank> #开始作为MDS <等级>的热备用。
2.1.7 CEPHFS命令
前面cephfs的搭建与挂载已经在别的地方操作过了,这里就不记录了。
FILESYSTEMS
这些命令在Ceph群集中的CephFS文件系统上运行。 请注意,默认情况下只允许一个文件系统:启用多个文件系统的创建使用ceph fs flag set enable_multiple true。
fs new <filesystem name> <metadata pool name> <data pool name> fs ls fs rm <filesystem name> [--yes-i-really-mean-it] fs reset <filesystem name> fs get <filesystem name> fs set <filesystem name> <var> <val> fs add_data_pool <filesystem name> <pool name/id> fs rm_data_pool <filesystem name> <pool name/id>
#设置
fs set <fs name> max_file_size <size in bytes>
#CephFS具有可配置的最大文件大小,默认值为1TB。 如果您希望在CephFS中存储大文件,您可能希望将此限制设置为更高。 它是一个64位字段。将max_file_size设置为0不会禁用限制。 它只会将客户端限制为仅创建空文件。
最大文件大小和性能
CephFS在附加文件或设置其大小的时候强制执行最大文件大小限制。 它不影响任何东西的存储方式。
当用户创建一个巨大的文件(不一定要写任何数据)时,一些操作(如删除)会导致MDS必须执行大量操作来检查是否有任何RADOS对象在该范围内 可能存在(根据文件大小)真的存在。
max_file_size设置可防止用户创建出现的例如。 大小的字节数,导致MDS上的负载,因为它在操作期间尝试枚举对象,例如统计信息或删除。
守护进程
这些命令行为特定的mds守护程序或等级。
mds fail <gid/name/role>
#将MDS守护程序标记为失败。 这相当于如果一个MDS守护程序无法向mds_beacon_grace发送一个消息,集群将会做什么。 如果守护程序处于活动状态并且可用的备用程序可用,则使用mds失败将强制将故障切换到备用。
#如果MDS守护程序实际上仍在运行,则使用mds失败将导致守护程序重新启动。 如果它是活动的并且备用可用,则“失败”守护程序将作为备用数据库返回。
mds deactivate <role>
停用MDS,使其刷新整个日志以支持RADOS对象并关闭所有打开的客户端会话。 停用MDS主要是在减少活动MDS(max_mds)的数量后降低排名。 一旦等级被禁用,MDS守护程序将作为备用数据重新加入集群。 <role>可以采取三种形式之一:
<fs_name>:<rank> <fs_id>:<rank> <rank>
将mds停用与max_mds的调整结合使收缩MDS群集。 请参阅配置多个活动的MDS守护程序
tell mds.<daemon name> mds metadata <gid/name/role> mds repaired <role>
全局设置
fs dump fs flag set <flag name> <flag val> [<confirmation string>]
#“flag name”必须是['enable_multiple']之一,有些标志要求您用“-yes-i-really-mean-it”确认您的意图或者他们会提示您的类似字符串。 在进行前仔细考虑这些行动; 它们是特别危险的活动。
高级
这些命令在正常操作中不是必需的,并且在特殊情况下存在。 错误地使用这些命令可能会导致严重的问题,例如不可访问的文件系统。
mds compat rm_compat mds compat rm_incompat mds compat show mds getmap mds set_state mds rmfailed
LEGACY
ceph mds set命令是ceph fs set的弃用版本,从每个群集以前有多个文件系统。 它以任何文件系统被标记为默认值(参见ceph fs set-default)进行操作。
mds #统计 mds dump #替换为“fs get” mds stop #替换为“mds deactivate” mds set_max_mds #替换为“fs set max_mds” mds set #替换为“fs set” mds cluster_down #替换为“fs set cluster_down” mds cluster_up #替换为“fs set cluster_up” mds newfs #替换为“fs new” mds add_data_pool #替换为“fs add_data_pool” mds remove_data_pool #replaced by“fs remove_data_pool”
2.1.8 配额
CephFS允许在系统中的任何目录上设置配额。 配额可以限制存储在目录层次结构中该点之下的字节数或文件数。
限制
1. 配额是合作的和非对抗的。 CephFS配额依赖于正在安装文件系统的客户端的合作,以在达到限制时停止作者。修改或对抗的客户端无法防止写入所需的数据。不要依靠配额来防止在客户完全不信任的环境中填充系统。
2. 配额不精确。正在写入文件系统的进程将在达到配额限制后的短时间内停止。它们将不可避免地被允许在配置的限制上写入一些数据量。他们能够离开的配额有多远,主要取决于时间量,而不是数据量。一般来说,作者将在超过配置限制的十秒钟内停止。
3. 配额尚未在内核客户端中实现。配额由用户空间客户端(libcephfs,ceph-fuse)支持,但尚未在Linux内核客户端中实现。
4. 使用基于路径的安装限制时,必须仔细配置配额。客户端需要访问配置配额的目录inode才能执行配额。如果客户端基于MDS能力限制了对特定路径(例如/ home / user)的访问,并且在祖先目录上配置了配额,则他们无法访问(例如/ home),客户端将不会强制执行当使用基于路径的访问限制时,请确保在目录上配置配额,客户端也被限制(例如/ home / user)或嵌套在其下的东西。
构造
像CephFS中的大多数其他事情一样,使用虚拟扩展属性配置配额:
ceph.quota.max_files – file limit ceph.quota.max_bytes – byte limit
如果属性出现在目录索引节点上,这意味着配置了配额。 如果它们不存在,那么该目录上没有设置配额(尽管仍可以在父目录上配置)。
设定配额:
setfattr -n ceph.quota.max_bytes -v 100000000 /some/dir # 100 MB setfattr -n ceph.quota.max_files -v 10000 /some/dir # 10,000 files
查看配额设置:
getfattr -n ceph.quota.max_bytes /some/dir getfattr -n ceph.quota.max_files /some/dir
请注意,如果扩展属性的值为0,表示未设置配额。
删除配额:
setfattr -n ceph.quota.max_bytes -v 0 /some/dir setfattr -n ceph.quota.max_files -v 0 /some/dir
2.1.9 客户端驱逐
当文件系统客户机无响应或其他行为不当时,可能需要强制终止其对文件系统的访问。 这个过程叫做驱逐。
驱逐CephFS客户端可防止其与MDS守护程序和OSD守护程序进一步通信。 如果客户端正在对文件系统进行缓冲IO,则任何未刷新的数据都将丢失。
客户端可能会自动被驱逐(如果他们不能及时与MDS通信),或手动(由系统管理员)。
客户驱逐过程适用于各种客户端,包括FUSE挂载,内核挂载,nfs-ganesha网关以及使用libcephfs的任何进程。
自动驱逐客户端
有两种情况可以自动排除客户:
在活动的MDS守护程序上,如果客户端尚未通过mds_session_autoclose秒(默认为300秒)与MDS进行通信,则会自动将其逐出。
在MDS启动期间(包括故障转移),MDS通过称为重新连接的状态。 在此状态下,它等待所有客户端连接到新的MDS守护程序。 如果任何客户端在时间窗口(mds_reconnect_timeout,默认值为45秒)内未能这样做,那么它们将被逐出。
如果出现任何一种情况,将向集群日志发送警告消息。
手动客户端驱逐
有时,管理员可能想手动取消客户端。 如果客户端死机,并且管理员不想等待其会话超时,则可能会发生这种情况,如果客户端行为不正确,并且管理员无法访问客户机节点以卸载它,则可能会发生这种情况。
首先检查客户端列表是有用的:
ceph tell mds.0 client ls
一旦您确定要驱逐的客户端,您可以使用其唯一的ID或其他各种属性来识别客户端:
# These all work ceph tell mds.0 client evict id=4305 ceph tell mds.0 client evict client_metadata.=4305
让黑名单用户连接
通常,黑名单客户端可能无法重新连接到服务器:它必须被卸载,然后重新安装。
然而,在某些情况下,允许被驱逐的客户端尝试重新连接可能是有用的。
因为CephFS使用RADOS OSD黑名单来控制客户端的迁移,所以可以通过从黑名单中删除CephFS客户端来重新连接:
ceph osd blacklist ls # ... identify the address of the client ... ceph osd blacklist rm <address>
如果其他客户端已访问黑名单客户端正在执行缓冲IO的文件,则可能会使数据完整性处于危险之中。 也不能保证产生一个功能齐全的客户端 - 在驱逐之后,让客户端恢复正常的最佳方式是卸载客户端并做新的安装。
如果您尝试以这种方式重新连接客户端,您也可能会发现在FUSE客户端中将client_reconnect_stale设置为true是有用的,以提示客户端尝试重新连接。
配置黑名单
如果您的客户端频繁出现,由于客户端主机或网络不稳定,您无法解决潜在的问题,那么您可能希望要求MDS不太严格。
可以通过简单地删除MDS会话来响应缓慢的客户端,但是允许他们重新打开会话,并允许他们继续与OSD进行通话。 要启用此模式,请在MDS节点上将mds_session_blacklist_on_timeout设置为false。
对于手动驱逐的等效行为,请将mds_session_blacklist_on_evict设置为false。
请注意,如果禁用黑名单,则驱逐客户端将仅对您发送命令的MDS有影响。 在具有多个活动MDS守护程序的系统上,您需要向每个活动守护程序发送一个逐出命令。 当启用黑名单(默认)时,发送逐出命令到只有一个MDS就足够了,因为黑名单传播给其他的。
高级选项
mds_blacklist_interval - 此设置控制黑名单中剩余的条目数。
2.1.10 CEPHFS健康信息与故障排除
记录了消息对应的意思:http://docs.ceph.com/docs/master/cephfs/health-messages/
故障排除:http://docs.ceph.com/docs/master/cephfs/troubleshooting/
恢复损坏的文件系统:http://docs.ceph.com/docs/master/cephfs/disaster-recovery/ #危险的操作,针对专家
2.1.11 CEPHFS客户端功能限定
使用Ceph身份验证功能将您的文件系统客户端限制在最低可能的权限级别。
路径限制
默认情况下,客户端不受限于允许挂载的路径。 此外,当客户端安装子目录(例如/home/user)时,MDS不通过默认验证后续操作在该目录内“锁定”。
要限制客户端仅在某个目录中进行安装和工作,请使用基于路径的MDS身份验证功能。
SYNTAX
要仅授予rw访问指定的目录,我们在使用以下语法为客户端创建密钥时提及指定的目录。
ceph fs authorize *filesystem_name* client.*client_name* /*specified_directory* rw
例如,限制客户端foo仅在文件系统cephfs的bar目录中使用:
ceph fs authorize cephfs client.foo / r /bar rw
要完全限制客户端到bar目录,请省略根目录:
ceph fs authorize cephfs client.foo /bar rw
请注意,如果客户端的读取访问权仅限于路径,则在mount命令中指定可读路径时,它们将只能装入文件系统(见下文)。
要将客户端限制为指定的子目录,我们使用以下语法提及安装时指定的目录。
./ceph-fuse -n client.*client_name* *mount_path* -r *directory_to_be_mounted*
例如,要将客户端foo限制为mnt / bar目录,我们将使用。
./ceph-fuse -n client.foo mnt -r /bar
FREE SPACE REPORTING(空闲空间报告)
默认情况下,当客户端正在安装子目录时,将从该子目录的配额计算已用空间(df),而不是报告集群上使用的总空间量。
如果希望客户端报告文件系统的整体使用情况,而不仅仅是挂载子目录上的配额使用情况,请在客户端上设置以下配置选项:
client quota df = false
如果未启用配额,或者在已安装的子目录上未设置配额,则会报告文件系统的总体使用情况,而不考虑此设置的值。
设置布局与配额
要设置布局或配额,客户端除了'rw'之外还需要'p'标志。 这限制了具有“ceph。”前缀的特殊扩展属性设置的所有属性,并限制了设置这些字段的其他方法(例如具有布局的openc操作)。
例如,在以下代码段中,client.0可以修改布局和配额,但是client.1不能。
client.0 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rwp caps: [mon] allow r caps: [osd] allow rw pool=dataclient.1 key: AQAz7EVWygILFRAAdIcuJ12opU/JKyfFmxhuaw== caps: [mds] allow rw caps: [mon] allow r caps: [osd] allow rw pool=data
2.1.12 配置目录片段
在CephFS中,当它们变得非常大或非常繁忙时,目录是碎片化的。 这样可以拆分元数据,以便它可以在多个MDS守护程序之间以及元数据池中的多个对象之间共享。
在正常操作中,目录碎片对于用户和管理员来说是不可见的,并且这里提到的所有配置设置应该保持默认值。
虽然目录碎片使CephFS能够处理单个目录中的大量条目,但是应用程序员对于创建非常大的目录应该保持保守,因为它们在列出目录的CephFS客户端的情况下仍然具有资源成本,其中所有碎片 必须立即加载。
所有目录最初都是作为单个片段创建的。 可以将该片段拆分为更多的片段,并将这些片段合并以减少目录中的片段数。
分割和合并
如果MDS的配置文件中的mds_bal_frag设置为true,则MDS将仅考虑执行拆分和合并,并在文件系统映射(mons)中设置allow_dirfrags设置为true。默认情况下,这些设置都是真实的,因为Ceph的发光(12.2.x)版本。
当MDS标识要分割的目录片段时,它不会立即进行拆分。因为分裂中断元数据IO,所以使用短延迟来允许客户机IO的短突发在分裂开始之前完成。此延迟由mds_bal_fragment_interval配置,默认为5秒。
当分割完成时,目录片段被分解成两个新片段的力量。新的片段的数量由两个给予功率mds_bal_split_bits,即如果mds_bal_split_bits为2,则将创建四个新的片段。默认设置为3,即拆分创建8个新片段。
以下部分将介绍启动拆分或合并的标准。
尺寸阀值
当目录片段的大小超过mds_bal_split_size(默认为10000)时,目录片段是可拆分的。通常,这个拆分是由mds_bal_fragment_interval延迟的,但是如果片段大小超过了mds_bal_fragment_fast_factor分裂大小的因子,则会立即发生拆分(在目录上放置任何客户端元数据IO)。
mds_bal_fragment_size_max是目录片段大小的硬限制。如果达到,如果客户端尝试在片段中创建文件,则会收到ENOSPC错误。在正确配置的系统上,绝对不能在普通目录上达到此限制,因为它们将在之前分裂。默认情况下,这被设置为拆分大小的10倍,给出了10000的dirfrag大小限制。增加此限制可能会导致元数据池中的大小过大的目录碎片对象,OSD可能无法处理。
当目录片段的大小小于mds_bal_merge_size时,目录片段可以合并。没有合并等效的“快速分裂”解释如上:快速分裂存在避免创建超大的目录片段,没有等同的问题,以避免合并时。默认合并大小为50。
活动阈值
除了基于它们的大小分割片段之外,如果MDS的活动超过阈值,则MDS可以分割目录片段。
MDS为目录片段上的读写操作维护单独的时间衰减负载计数器。衰减的负载计数器基于mds_decay_halflife设置具有指数衰减。
在写入时,写入计数器递增,并与mds_bal_split_wr进行比较,如果超过阈值则触发分裂。写操作包括元数据IO,如重命名,取消链接和创建。
基于读操作负载计数器应用mds_bal_split_rd阈值,该计数器跟踪readdir操作。
默认情况下,读取阈值为25000,写入阈值为10000,即触发分割所需的写入次数为2.5倍。
在片段由于活动阈值分裂之后,它们只能根据大小阈值(mds_bal_merge_size)进行合并,因此活动中的尖峰可能导致目录永远分散,除非某些条目被取消链接。
另外:配置多个主MDS:http://docs.ceph.com/docs/master/cephfs/multimds/
