Beats详解(四)
#前面一篇博客已经接触过Filebeat这个轻量级客户端,这里跟着官网详细介绍一下。此篇就是翻译官网,可略过。
一、Beats平台介绍
1.1 Beats介绍
Beats是开源数据发送者,可以将其作为代理安装在您的服务器上,以将不同类型的运营数据发送到Elasticsearch。Beats可以直接发送数据到Elasticsearch或通过Logstash发送到Elasticsearch,可以使用它来分析和转换数据。
Packetbeat,Filebeat,Metricbeat和Winlogbeat是Beats的一些例子。Packetbeat是一个网络数据包分析器,提供有关你的应用程序服务器之间交换的事务的信息。Filebeat从你的服务器发送日志文件。 Metricbeat是一个服务器监视代理程序,它定期从服务器上运行的操作系统和服务中收集指标。 Winlogbeat提供Windows事件日志。如下图:
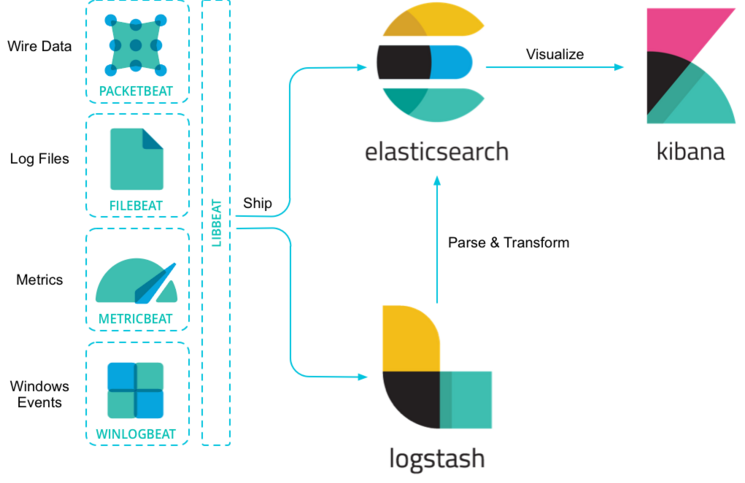
如果有特定的用例需要解决,可以创建自己的Beat。 ELK创建了一个基础设施来简化流程。 完全由Golang编写的libbeat库提供了所有Beats用来将数据发送到Elasticsearch,配置输入选项,实现日志记录等的API。
1.2 Beats社区
开源社区(https://discuss.elastic.co/c/beats/community-beats)一直在努力开发新的Beats。 你可以在这里查看一些。下面是一些其他的beat工具(https://github.com可以找到):
amazonbeat #从指定的Amazon产品读取数据。 apachebeat #从Apache HTTPD服务器状态读取状态。 apexbeat #通过APEX工具包从Java应用程序中提取可配置的上下文数据和指标。 burrowbeat #使用Burrow监控Kafka消费者滞后。 cassandrabeat #使用Cassandra的nodetool cfstats实用程序来监视Cassandra数据库节点和滞后。 cloudflarebeat #索引记录来自Cloudflare企业日志共享API的条目。 cloudfrontbeat #从Amazon Web Services CloudFront中读取日志事件。 cloudtrailbeat #从Amazon Web Services的CloudTrail中读取事件。 cloudwatchmetricbeat #Amazon Web Services的CloudWatch指标。 cloudwatchlogsbeat #从Amazon Web Services的CloudWatch Logs中读取日志事件。 collectbeat #在像Kubernetes这样的环境中在Filebeat和Metricbeat之上添加发现。 connbeat #公开有关TCP连接的元数据。 consulbeat #从领事读取服务健康检查,并将其推送到Elastic。 dockbeat #读取Docker容器统计信息并在Elasticsearch中将其编入索引。 elasticbeat #从Elasticsearch集群读取状态并在Elasticsearch中将其编入索引。 etcdbeat #从Etcd v2 API读取统计信息并将其编入Elasticsearch。 execbeat #定期执行shell命令并将标准输出和标准错误发送到Logstash或Elasticsearch。 factbeat #收集Facter的信息。 flowbeat #收集,分析和索引sflow样本。 gabeat #从Google Analytics实时API中收集数据。 githubbeat #轻松监视GitHub存储库活动。 gpfsbeat #收集GPFS指标和配额信息。 hsbeat #读取Java HotSpot VM中的所有性能计数器。 httpbeat #轮询多个HTTP(S)端点并将数据发送到Logstash或Elasticsearch。支持所有的HTTP方法和代理。 hwsensorsbeat #从OpenBSD读取传感器信息。 icingabeat #Icingabeat将事件和状态从Icinga 2发送到Elasticsearch或Logstash。 iobeat #从Linux上的/ proc / diskstats读取IO统计信息。 jmxproxybeat #将通过JMX Proxy Servlet公开的Tomcat JMX度量读取到HTTP。 journalbeat #用于从基于systemd / journald的Linux系统进行日志传送。 kafkabeat #从Kafka主题中读取数据。 krakenbeat #在Kraken加密平台上收集关于每笔交易的信息。 lmsensorsbeat #从光电传感器收集数据(例如CPU温度,风扇速度和来自i2c和smbus的电压)。 logstashbeat #从Logstash监控API(v5起)收集数据并在Elasticsearch中将其编入索引。 mcqbeat #从memcacheq读取队列的状态。 mongobeat #监控MongoDB实例,可以配置为将多个文档类型发送到Elasticsearch。 mqttbeat #从mqtt主题添加消息到Elasticsearch。 mysqlbeat #在MySQL上运行任何查询并将结果发送到Elasticsearch。 nagioscheckbeat #对于Nagios检查和性能数据。 nginxbeat #从Nginx读取状态。 nginxupstreambeat #从nginx上游模块读取上游状态。 nvidiagpubeat #使用nvidia-smi来获取NVIDIA GPU的指标。 openconfigbeat #从支持OpenConfig的网络设备流式传输数据 packagebeat #从软件包管理器收集有关系统软件包的信息。 phpfpmbeat #从PHP-FPM读取状态。 pingbeat #将ICMP ping发送到目标列表并将往返时间(RTT)存储在Elasticsearch中。 prombeat #索引普罗米修斯指标。 prometheusbeat #通过远程写入功能将Prometheus指标发送给Elasticsearch。 protologbeat #通过UDP或TCP接受结构化和非结构化日志。也可以用来接收系统日志消息或GELF格式的消息。 (作为udplogbeat的继承者使用) redditbeat #收集一个或多个Subreddits的新的Reddit提交。 redisbeat #用于Redis监控。 retsbeat #收集来自多个列表服务(MLS)服务器的RETS资源/类记录的计数。 rsbeat #将redis缓慢的日志发送到elasticib和Kibana的anlyze。 saltbeat #从盐主事件巴士读取事件。 springbeat #从执行器模块运行的Spring Boot应用程序收集健康和指标数据。 twitterbeat #读取指定屏幕名称的推文。 udpbeat #通过UDP发送结构化日志。 udplogbeat #通过本地UDP套接字接受事件(纯文本或JSON能够执行模式)。也可以用于仅支持系统日志记录的应用程序。 unifiedbeat #从Unified入侵检测软件生成的Unified2二进制文件中读取记录,并在Elasticsearch中对记录进行索引。 uwsgibeat #从uWSGI读取统计数据。 varnishlogbeat #从Varnish实例读取日志数据并将其发送到Elasticsearch。 varnishstatbeat #从varnish实例读取统计数据并将其发送到Elasticsearch。 wmibeat #使用WMI来获取您最喜爱的,可配置的Windows指标。
1.3 Beat 6.0版本的新变化
管道的变化:
6.0版本为所有Beats的内部管道提供了一个新的体系结构。 这个体系结构重构主要是内部的,但更明显的效果之一是Filebeat的后台程序组件Spooler被删除。 后台Spooler程序的功能类似于来自libbeat(所有Beats共享的代码)的发布程序队列,并且存在多个队列使得Filebeat的性能调整比所需要的更复杂。
结果,以下选项被删除:
filebeat.spool_size filebeat.publish_async filebeat.idle_timeout queue_size bulk_queue_size
#前三个特定于Filebeat,而queue_size和bulk_queue_size存在于所有Beats中。 如果设置了这些选项,Filebeat 6.0将会拒绝启动。
#引入了queue.mem设置,而不是上面的设置。 如果您之前必须调整spool_size或queue_size,则可能需要在升级时调整queue.mem.events。 但是,最好将queue.mem的其余部分保留为默认值,因为它们适用于所有负载。
#publish_async选项(从5.3开始不推荐使用)被删除,因为新管道默认已经异步工作。
在6.0以前的版本中,可以同时启用多个输出,但只能使用不同的类型。 例如,可以启用Elasticsearch和Logstash输出,但不能启用两个Logstash输出。 启用多个输出的缺点是在继续之前等待确认(Filebeat和Winlogbeat)的Beats减慢到最慢的输出。 这种含义并不明显,阻碍了多个产出有用的用例。
6.0所做的管道重新架构的一部分们删除了同时启用多个输出的选项。 这有助于简化管道并明确Beats中的输出范围。
如果需要多个输出,有以下选择:
使用Logstash输出,然后使用Logstash将事件传送到多个输出 运行相同Beat的多个实例
如果使用file或console输出进行调试,除了主输出之外,建议使用-d“publish”选项,将发布的事件记录在Filebeat日志中。
Logstash索引设置现在需要的版本:
如果使用Logstash输出将数据从Beats发送到Logstash,则需要更新Logstash配置中的index设置以包含Beat版本:
output {
elasticsearch {
hosts => "localhost:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}}在6.0之前,推荐的设置是:
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"使用6.0的索引模板应用于匹配模式[beat]-[version]-*的新索引。您必须更新您的日志存储配置,否则模板将不会被应用。
Filebeat prospector类型和文档的变化:
来自prospector配置的document_type设置已被删除,因为_type概念正在从Elasticsearch中移除。 而不是document_type设置,可以使用自定义字段。
这也导致将input_type配置设置重命名为type。 这个改变是向后兼容的,因为旧的设置仍然有效。 但是,input_type输出字段已重命名为prospector_type。
Filebeat在配置文件中默认的prospector禁用了:
Filebeat的默认启动行为(基于包含的示例配置)是读取所有匹配/var/log/*.log模式的文件。 从版本6.0开始,Filebeat不会以默认配置读取任何文件。 但是,您可以轻松地启用系统模块,例如使用CLI标志:
filebeat --modules=system
其他设置更改或移动:
outputs.elasticsearch.template.* settings 已经移动到setup.template.*下面,但是其他的没有变化。
dashboards.* settings已经移到setup.dashboards.*.下面。
Filebeat弃用的选项force_close_files和close_older被删除。
更改导入Kibana dashboards:
用于在先前版本的Beats中加载Kibana仪表板的import_dashboards程序被setup命令替换。 例如,下面的命令:
./scripts/import_dashboards -user elastic -pass YOUR_PASSWORD
可以替换为:
./filebeat setup -E "output.elasticsearch.username=elastic" -E "output.elasticsearch.password=YOUR_PASSWORD"
请注意,只有在配置文件中尚未配置Elasticsearch输出的情况下,才需要-E标志。
除了这些命令的改变之外,重要的是要注意,加载Kibana仪表板在6.0版本的堆栈中工作方式不同。 在6.0之前,仪表板被直接插入到.kibana Elasticsearch索引中。 从6.0开始,Beats使用Kibana服务器API。 这意味着加载仪表板的节拍需要直接访问Kibana,并且需要设置Kibana URL。 设置Kibana URL的选项是setup.kibana.host,可以在配置文件中或通过-E CLI标志设置该选项:
./filebeat setup -E "setup.kibana.host=http://kibana-host:5601"
#Kibana主机的默认值是localhost:5601。
Metricbeat过滤器重新命名为processors:
在本模块级配置的“local”processors曾经在Metricbeat中称为filters,但是它们提供了与全局处理器类似的功能。 两者之间的显着区别在于筛选器相对于度量标准集(例如,mount_point)访问字段,而处理器则以其全限定名称(例如system.filesystem.mount_point)引用字段。
从版本6.0开始,筛选器被重命名为处理器,并且只能通过使用完全限定的名称来访问这些字段。
二进制文件是针对libc动态编译:
在6.0之前,使用Cgo编译Metricbeat和Packetbeat,而使用纯Go编译器编译Filebeat,Winlogbeat和Heartbeat。 编译Cgo的一个作用是libc是动态编译的。从6.0开始,所有的Beats都是使用Cgo编译的,因此可以动态编译libc。 这可以降低二进制文件的可移植性,但是所有受支持的平台都不受影响。
博文来自:www.51niux.com
1.4 Beats版本发布
#链接地址:https://www.elastic.co/guide/en/beats/libbeat/current/release-notes.html
二、配置文件格式
http://blog.51niux.com/?id=203 #已经对Filebeat的样例yaml文件进行了解释,这里在根据官网进行下记录。
2.1 配置文件格式
官网网站:https://www.elastic.co/guide/en/beats/libbeat/current/config-file-format.html
Beats配置文件基于YAML(http://www.yaml.org/),这是一种比XML或JSON等其他常见数据格式更容易读写的文件格式。
在Beats中,所有的YAML文件都以一个字典开始,一个无序的name/value对集合。 除字典之外,YAML还支持列表,数字,字符串和许多其他数据类型。 同一个列表或字典中的所有成员都必须具有相同的缩进级别。
字典由简单的key:value对表示,它们都具有相同的缩进级别。 键后面的冒号必须跟一个空格。
name: John Doe age: 34 country: Canada
列表是由破折号“ - ”引入的。 所有列表成员都是以` - `开头的行,在相同的缩进级别。
- Red - Green - Blue
在Beats中使用列表和词典来构建结构化配置。
filebeat: prospectors: - type: log paths: - /var/log/*.log multiline: pattern: '^[' match: after
列表和字典也可以用缩写形式表示。缩写形式有点类似于使用{}为字典和[]列表的JSON。
person: {name: "John Doe", age: 34, country: "Canada"}
colors: ["Red", "Green", "Blue"]下面的主题提供了更多的细节,以帮助理解和处理YAML中的config文件:
命名空间 配置文件数据类型 环境变量 引用变量 配置文件的所有权和权限 命令行参数 YAML的技巧和陷阱
2.2 Namespacing(命名空间)
所有设置均使用字典和列表进行结构化。当读取配置文件时,通过使用设置名称的完整路径和它的父结构名称创建一个设置,这些设置被折叠为“名称空间”设置。例如这个设置:
output:
elasticsearch:
index: 'beat-%{+yyyy.MM.dd}'被折叠成output.elasticsearch.index: 'beat-%{+yyyy.MM.dd}'。设置的全名是基于所涉及的所有父母结构。列表创建以0开头的数字名称。例如这个filebeat设置:
filebeat: prospectors: - type: log
获取合并到filebeat.prospectors.0.type: log。也可以使用缩进,设置名称也可以以折叠形式使用。注意:具有完全折叠路径的两个设置是无效的。
简单的filebeat例子,部分折叠的设置名称和使用紧凑的形式:
filebeat.prospectors: - type: log paths: ["/var/log/*.log"] multiline.pattern: '^[' multiline.match: after output.elasticsearch.hosts: ["http://localhost:9200"]
2.3 Config file data types(配置文件数据类型)
配置设置的值被解释为beats所要求的值。 如果某个值无法正确解释为所需的类型(例如,在需要数字时给出字符串),beats将无法启动。
Boolean:
布尔值可以是true或false。替代名称为true是yes和no。可以使用no和off的值而不是false。
enabled: true disabled: false
Number:
数字值要求输入要使用的数字,而不使用单引号或双引号。 但是有些设置只支持有限的数字范围。
integer: 123 negative: -1 float: 5.4
String:
在YAML [http://www.yaml.org],支持多种类型的字符串定义:双引号,单引号,不带引号。
双引号样式是通过将字符串包围“”来指定的。该样式提供了使用\转义不可打印字符的支持,但代价是必须转义\和“字符。
单引号样式是通过用'包围'字符串来指定的。 此样式不支持转义(使用''引用单引号)。 使用此表单时只能使用可打印的字符。
不带引号的样式不需要引号,但不支持任何转义,需要注意的是不要使用任何在YAML中有特殊含义的符号。
注:定义正则表达式,事件格式字符串,窗口文件路径或非字母符号字符时,建议使用单引号样式。
Duration:
持续时间需要包含可选分数和必需单位的数字值。 有效时间单位是ns,us,ms,s,m,h。 有时基于持续时间的功能可以通过使用零或负的持续时间来禁用。
duration1: 2.5s duration2: 6h duration_disabled: -1s
Regular expression:
正则表达式是在加载时被编译成正则表达式的特殊字符串。
由于正则表达式和YAML使用\来转义字符串中的字符,强烈建议在定义正则表达式时使用单引号字符串。 当使用单引号字符串时,YAML解析器不会将\字符解释为换码符号。
Format String(sprintf):
格式化字符串使能够根据正在处理的当前事件来引用创建字符串的事件字段值。 变量扩展包含在扩展大括号%{<accessor>:default value}中。 事件字段使用字段引用[fieldname]进行访问。 如果事件中缺少字段名称,可以指定可选的缺省值。
还可以使用+FORMAT语法来格式化存储在@timestamp字段中的时间,其中FORMAT是有效的时间格式。
time format格式:https://godoc.org/github.com/elastic/beats/libbeat/common/dtfmt
constant-format-string: 'constant string'
field-format-string: '%{[fieldname]} string'
format-string-with-date: '%{[fieldname]}-%{+yyyy.MM.dd}'2.4 Environment variables(环境变量)
可以在配置文件中使用环境变量引用来设置在部署期间需要配置的值。 要做到这一点,使用:
${VAR} #其中VAR是环境变量的名称。每个变量引用在启动时被环境变量的值替换。 替换区分大小写,并在解析YAML文件之前进行。 除非您指定默认值或自定义错误文本,否则对未定义变量的引用将替换为空字符串。要指定默认值,请使用:
${VAR:default_value}如果环境变量未定义,则default_value是要使用的值。要指定自定义错误文本,请使用:
${VAR:?error_text}其中error_text是自定义文本,如果环境变量不能被扩展,将被添加到错误消息中。如果你需要在你的配置文件中使用$ {,那么你可以编写$$ {来避开扩展。在更改环境变量的值之后,您需要重新启动Beat来获取新值。
也可以通过使用-E选项从命令行覆盖配置设置时指定环境变量。 例如:-E name = $ {NAME}
例如:以下是一些使用环境变量的配置示例,以及替换后每个配置的样子:
#配置来源 #环境设置 #更换后的配置
name: ${NAME} export NAME=elastic name: elastic
name: ${NAME} no setting name:
name: ${NAME:beats} no setting name: beats
name: ${NAME:beats} export NAME=elastic name: elastic
name: ${NAME:?You need to set the NAME environment variable} no setting none.返回自定义文本前面的错误消息。
name: ${NAME:?You need to set the NAME environment variable} export NAME=elastic name: elastic在环境变量中指定复杂的对象
可以使用类似JSON的语法在环境变量中指定复杂的对象,如列表或字典。和JSON一样,字典和列表也是使用{}和[]来构造的。 但是与JSON不同,语法允许使用尾随逗号和稍微不同的字符串引用规则。 字符串可以不加引号,单引号或双引号,以方便简单的设置,并使你更容易在shell中混合使用引用。 顶层数组不需要括号([])。
例如,以下环境变量设置为一个列表:
ES_HOSTS="10.45.3.2:9220,10.45.3.1:9230"
你可以在配置文件中引用这个变量:
output.elasticsearch:
hosts: '${ES_HOSTS}'当Beat加载配置文件时,它会在读取主机设置之前解析环境变量并将其替换为指定的列表。注意:不要使用双引号(")来包装正则表达式,否则反斜线(\)将被解释为转义字符。
2.5 Reference variables(引用变量)
Beats设置可以引用其他设置将多个可选的自定义命名设置拼接成新的值。 引用使用与环境变量相同的语法。 只能引用完全折叠的设置名称。
例如,filebeat注册表文件默认为:
filebeat.registry: ${path.data}/registry由于path.data是一个隐含的配置设置,可以从命令行以及配置文件覆盖。在output.elasticsearch.hosts中引用es.host的示例:
es.host: '${ES_HOST:localhost}'
output.elasticsearch:
hosts: ['http://${es.host}:9200']在介绍es.host时,可以使用-E es.host = another-host从命令行覆盖主机。纯引用,没有默认值,不与其他引用或字符串拼接可以引用完整的名称空间。这些设置与重复的内容:
namespace1: subnamespace: host: localhost sleep: 1s namespace2: subnamespace: host: localhost sleep: 1s
可以重写:
namespace1: ${shared}
namespace2: ${shared}
shared:
subnamespace:
host: localhost
sleep: 1s2.6 Config file ownership and permissions(配置文件的所有权和权限)
#本节不适用于Windows或其他非POSIX操作系统。
在具有POSIX文件权限的系统上,所有Beats配置文件都受到所有权和文件权限检查。 这些检查的目的是防止未经授权的用户提供或修改由Beat运行的配置。 配置文件的所有者必须是root用户或执行Beat进程的用户。 每个文件的权限必须禁止所有者以外的任何人写入。
当通过RPM或DEB软件包安装时,/etc/{beatname}/{beatname}.yml中的配置文件将具有正确的所有者和权限。 该文件由root拥有,文件权限为0644(-rw-r - r--)。
如果配置文件未能通过这些检查,可能会遇到以下错误:
Exiting: error loading config file: config file ("{beatname}.yml") must be
owned by the beat user (uid=501) or root若要更正此问题,可以使用chown root {beatname} .yml或chown 501 {beatname} .yml来更改配置文件的所有者。
Exiting: error loading config file: config file ("{beatname}.yml") can only be
writable by the owner but the permissions are "-rw-rw-r--" (to fix the
permissions use: 'chmod go-w /etc/{beatname}/{beatname}.yml')#要解决此问题,请使用chmod go-w /etc/{beatname}/{beatname}.yml删除除所有者以外的任何人的写入权限。其他配置文件(如modules.d目录中的文件)受到相同的所有权和文件权限检查。
禁用严格的权限检查
可以使用-strict.perms = false禁用命令行中的严格权限检查,但强烈建议启用检查。
博文来自:www.51niux.com
2.7 Command line arguments(命令行参数)
要加载的配置文件在命令行上使用-c标志设置。 如果没有给出标志,则将假定beat和OS特定的默认文件路径。
可以通过重复-c标志来指定多个配置文件。 例如,可以使用它来在基本配置文件中设置默认值,并通过本地配置文件覆盖设置。
除了使用多个配置文件覆盖设置外,还可以使用 -E <setting>=<value>来覆盖单个设置。 <value>可以是单个值,也可以是复杂对象,如列表或字典。
例如,给出以下配置:
output.elasticsearch: hosts: ["http://localhost:9200"] username: username password: password
可以禁用Elasticsearch输出,并通过设置将所有事件写入控制台:
-E output='{elasticsearch.enabled: false, console.pretty: true}'在命令行中指定的任何复杂对象都将与原始配置合并,并将以下配置传递给Beat:
output.elasticsearch: enabled: false hosts: ["http://localhost:9200"] username: username password: password output.console: pretty: true
2.8 YAML tips and gotchas(YAML技巧和陷阱)
配置文件的语法使用YAML(http://yaml.org/)。
使用空格缩进
缩进在YAML中是有意义的。确保使用空格而不是制表符来缩进部分。在默认配置文件和文档中的所有示例中,使用每个缩进级别2个空格。
查看结构的默认配置文件
了解在哪里定义配置选项的最好方法是查看提供的示例配置文件。 配置文件包含大部分Beat可用的默认配置。 要更改设置,只需取消注释并更改值。
测试配置文件
可以测试配置文件以验证结构是否有效。 只需转到安装二进制文件的目录,然后使用指定的-configtest标志在前台运行Beat。 例如:
beatname -c beatname.yml -configtest #如果Beat在文件中发现错误,将看到一条提示消息。
用单引号包装正则表达式
如果需要在YAML文件中指定正则表达式,最好将正则表达式包装在单引号中,以解决YAML对字符串转义的棘手规则。有关YAML的更多信息,请参阅http://yaml.org/。
用单引号包装路径
Windows路径特别有时包含可能被YAML解析器误解的空格或字符,如驱动器号或三个点。为了避免这个问题,将路径换成单引号是个好主意。
避免在数值中使用前导零
如果在数值字段中使用前导零(例如09)而不用单引号包装值,则YAML解析器可能会错误地解释该值。 如果该值是有效的八进制数,则将其转换为整数。 如果不是,则转换为浮点数。为防止不必要的类型转换,请避免在字段值中使用前导零,或将值包装在单引号中。
三、Filebeats参考
3.1 Filebeat概述
Filebeat是本地文件的日志数据发送者。 作为服务器上的代理安装,Filebeat监视日志目录或特定的日志文件,tails文件,并转发到Elasticsearch或Logstash索引。Filebeat是一个Beat,它是基于libbeat框架。
以下是Filebeat的工作原理:启动Filebeat时,它会启动一个或多个prospectors(查找器),查看日志文件指定的本地路径。 对于prospector所在的每个日志文件,Filebeat启动harvester(采集器)。 每个采集器都会为新内容读取一个日志文件,并将新的日志数据发送到libbeat,后者将聚合这些事件并将聚合的数据发送到为Filebeat配置的输出。如下图:
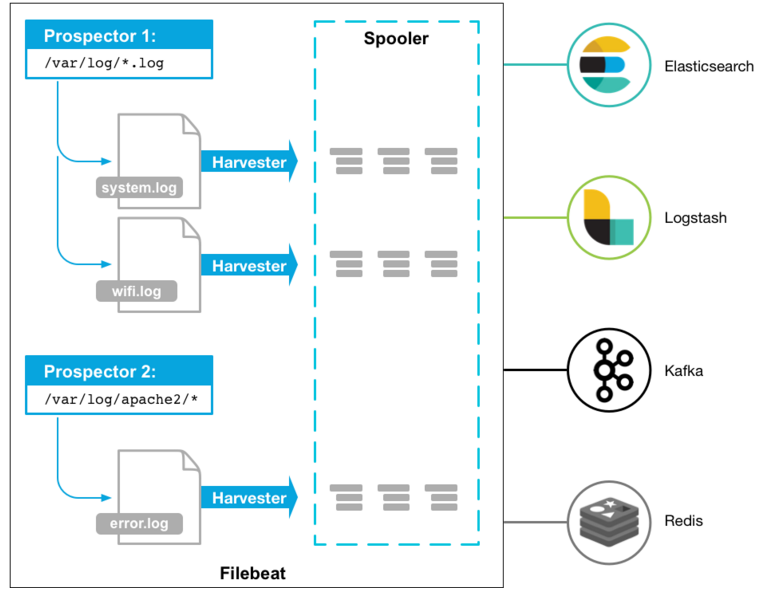
#更多信息请参考:https://www.elastic.co/guide/en/beats/filebeat/current/how-filebeat-works.html
3.2 开始使用Filebeat
官网链接:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-getting-started.html
http://blog.51niux.com/?id=203 #这里已经有一个完整的例子了,如何使用就不做过多介绍了。
3.3 Filebeat的命令
# /home/elk/filebeat/filebeat --help
Usage: filebeat [flags] filebeat [command] Available Commands: export #导出当前配置或索引模板 help #帮助 modules #管理配置的模块 run #运行filebeat setup #设置索引模板,仪表板和ML jobs test #测试配置 version #显示当前版本信息 Flags: -E, --E Flag #配置覆盖(默认为空) -M, --M Flag #模块配置覆盖(默认为空) -N, --N #禁用实际发布进行测试 -c, --c argList #配置文件,相对于path.config(默认为beat.yml) --cpuprofile string #将cpu配置文件写入文件 -d, --d string #启用某些调试选择器 -e, --e #stderr到日志和禁用syslog/file输出。 -h, --help #filebeat帮助 --httpprof string #启动pprof http服务器 --memprofile string #将内存配置文件写入此文件 --modules string #启用模块列表(逗号分隔) --once #运行filebeat只有一次,直到所有harvesters到达EOF --path.config flagOverwrite #配置路径 --path.data flagOverwrite #数据路径 --path.home flagOverwrite #家目录 --path.logs flagOverwrite #Logs path --plugin pluginList #加载额外的插件 --setup #加载示例Kibana仪表板 --strict.perms #对配置文件进行严格的权限检查(默认为true) -v, --v #日志INFO-level消息
# /home/elk/filebeat/filebeat modules --help #可以查看每个子命令的详细帮助,如modules。
3.4 Filebeat是如何工作的
Filebeat由两个主要组件组成: prospectors和harvesters。 这些组件一起工作来tail文件并将事件数据发送到指定的输出。
什么是harvester?
一个harvester负责读取单个文件的内容。harvester逐行读取每个文件,并将内容发送到输出。 每个文件启动一个harvester。harvester负责打开和关闭文件,这意味着在harvester运行时文件描述符保持打开状态。如果在收获文件时删除或重命名文件,Filebeat将继续读取文件。 这有副作用,在harvester关闭之前,磁盘上的空间被保留。 默认情况下,Filebeat保持文件打开,直到达到close_inactive。
关闭harvester有以下后果:
文件处理程序关闭,释放基础资源,如果在harvester还在读取文件时文件被删除。 只有在scan_frequency过后,文件的采集才会重新开始。 如果在harvester关闭的情况下移动或移除文件,文件的harvesting将不会继续。
#要控制收割机何时关闭,请使用close_ *(https://www.elastic.co/guide/en/beats/filebeat/current/configuration-filebeat-options.html#close-options)配置选项。
什么是prospector?
一个prospector负责管理harvesters并找到所有的读取源。
如果输入类型是日志,则prospector会查找驱动器上与所定义的全局路径匹配的所有文件,并为每个文件启动一个harvester。每个prospector都在自己的Go例程中运行。
以下示例将Filebeat配置为从与指定的glob模式匹配的所有日志文件中获取行:
filebeat.prospectors: - type: log paths: - /var/log/*.log - /var/path2/*.log
Filebeat目前支持两种prospector类型:log和stdin。 每个prospector类型可以定义多次。 log prospector检查每个文件以查看是否需要启动harvester,是否已经运行,还是可以忽略文件(请参阅ignore_older)。 只有在prospector关闭后文件的大小发生了变化的情况下,才会选择新行。
注:Filebeat prospector只能读取本地文件。 没有功能连接到远程主机读取存储的文件或日志。
Filebeat如何保持文件的状态?
Filebeat保持每个文件的状态,并经常刷新注册表文件中的磁盘状态。 状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。 如果输出(如Elasticsearch或Logstash)无法访问,Filebeat将跟踪发送的最后一行,并在输出再次可用时继续读取文件。 当Filebeat正在运行时,每个prospector的状态信息也被保存在内存中。 当Filebeat重新启动时,将使用来自注册表文件的数据来重建状态,而Filebeat将在最后一个已知位置上继续每一个harvester。
每个prospector都为它找到的每个文件保存一个状态。因为文件可以重命名或移动,文件名和路径不足以识别文件。对于每个文件,Filebeat存储唯一标识符,以检测是否在之前捕获了一个文件。
如果您的使用案例涉及每天创建大量新文件,您可能会发现注册表文件会变得太大。 请参阅注册表文件太大?编辑有关可以设置为解决此问题的配置选项的详细信息。https://www.elastic.co/guide/en/beats/filebeat/current/faq.html#reduce-registry-size
Filebeat如何确保至少一次传输?
Filebeat保证事件至少被传递到配置的输出一次,没有数据丢失。 Filebeat能够实现此行为,因为它将每个事件的传递状态存储在注册表文件中。
在定义的输出被阻止并且没有确认所有事件的情况下,Filebeat会一直尝试发送事件,直到输出确认已经收到事件。
如果Filebeat在发送事件的过程中关闭,则不会等待输出在关闭之前确认所有事件。 任何发送到输出的事件,在Filebeat关闭之前没有被确认,在重新启动Filebeat时会再次发送。 这可确保每个事件至少发送一次,但最终可能会将重复事件发送到输出。 可以通过设置shutdown_timeout选项来配置Filebeat以在关闭之前等待特定时间。
注:Filebeat的至少一次交付保证包括日志轮换和删除旧文件的限制。 如果将日志文件写入磁盘并且旋转速度超过Filebeat可以处理的速度,或者如果在输出不可用的情况下删除文件,数据可能会丢失。 在Linux上,Filebeat也可能因inode重用而跳过行。 有关inode重用问题的更多详细信息,请参阅常见问题解答https://www.elastic.co/guide/en/beats/filebeat/current/faq.html。
四、配置Filebeat
Filebeat配置文件的语法使用YAML。
指定要运行的模块 成立prospectors 管理多行消息 指定一般设置 加载外部配置文件 配置内部队列 配置输出 负载平衡输出主机 指定SSL设置 筛选并增强导出的数据 使用摄取节点解析日志 设置项目路径 设置Kibana端点 加载Kibana仪表板 加载Elasticsearch索引模板 设置日志记录 在配置中使用环境变量 YAML技巧和陷阱 正则表达式支持 filebeat.reference.yml
4.1 指定要运行的模块
使用Filebeat模块是可选的。 如果您使用的是不受支持的日志文件类型,或者您想使用其他设置,则可以决定手动设置prospectors 。Filebeat模块(https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-modules.html)为您提供了一种快速处理常见日志格式的方法。它们包含默认配置、 Elasticsearch的节点管道定义,以及Kibana指示板,以帮助您实现和部署日志监视解决方案。
Filebeat提供了几种不同的方式来启用模块。 可以:
在modules.d目录下启用模块配置 运行Filebeatedit时启用模块 在filebeat.yml文件中启用模块配置
注:在具有POSIX文件权限的系统上,所有Beats配置文件都受到所有权和文件权限检查。
在modules.d目录下启用模块配置
modules.d目录包含Filebeat中所有可用模块的默认配置。 可以通过运行modules enable或modules disable命令启用或禁用modules.d下的特定模块配置。
例如,要启用modules.d目录中的apache2和mysql配置,可以使用:
./filebeat modules enable apache2 mysql
然后在运行Filebeat时,它会加载modules.d目录中指定的相应模块配置(例如,modules.d/apache2.yml和modules.d/mysql.yml)。
要查看启用和禁用模块的列表,请运行:
./filebeat modules list
运行Filebeat时启用模块
要在命令行运行Filebeat时启用特定模块,可以使用--modules标志。当开始使用这种方法时,需要在每次运行Filebeat时指定不同的模块和设置。 在命令行中指定的任何模块将与在配置文件或modules.d目录中启用的所有模块一起加载。 如果有冲突,则使用命令行中指定的配置。
以下示例显示如何启用和运行nginx,mysql和系统模块:
./filebeat -e --modules nginx,mysql,system
启用filebeat.yml文件中的模块配置
如果可能的话,应该使用modules.d目录中的配置文件。但是,如果从Filebeat以前的版本升级并且不想将模块配置移动到modules.d目录,则直接在配置文件中启用模块是一种实用的方法。 可以继续在filebeat.yml文件中配置模块,但是您将无法使用modules命令启用和禁用配置,因为该命令需要modules.d布局。
要启用filebeat.yml配置文件中的特定模块,可以将条目添加到filebeat.modules列表中。 列表中的每个条目都以破折号( - )开始,然后是该模块的设置。以下示例显示了运行nginx,mysql和system模块的配置。
filebeat.modules: - module: nginx - module: mysql - module: system
4.2 指定变量设置
每个模块和文件集都有变量,可以设置这些变量来更改模块的默认行为,包括模块查找日志文件的路径。 例如,以下示例中的var.paths设置将设置nginx访问日志文件的路径:
- module: nginx access: var.paths: ["/var/log/nginx/access.log*"]
要在命令行设置Nginx访问日志文件的路径,可以使用-M标志。 例如:
./filebeat -M "nginx.access.var.paths=[/var/log/nginx/access.log*]"
在命令行设置变量时,变量名称需要包含模块和文件集名称。 可以指定多个覆盖。 每个覆盖必须以-M开头。在这里,将看到如何将-M标志和--modules标志一起使用。 此示例显示如何设置访问和错误日志的路径:
./filebeat --modules nginx -M "nginx.access.var.paths=[/var/log/nginx/access.log*]" -M "nginx.error.var.paths=[/var/log/nginx/error.log*]"
4.3 高级设置
每个模块启动一个Filebeat prospector。 高级用户可以添加或覆盖任何prospector设置。 例如,您可以在模块配置中将close_eof设置为true:
- module: nginx access: prospector: close_eof: true
或者像这样的命令行:
./filebeat -M "nginx.access.prospector.close_eof=true"
如何将-M标志与--modules标志一起使用:
./filebeat --modules nginx -M "nginx.access.prospector.close_eof=true"
可以使用通配符一次更改多个模块/文件集的变量或设置。 例如,以下命令为nginx模块中的所有文件集启用close_eof:
./filebeat -M "nginx.*.prospector.close_eof=true"
以下命令为由任何模块创建的所有prospector启用close_eof:
./filebeat -M "*.*.prospector.close_eof=true"
4.4 创建prospector
Filebeat使用prospector来定位和处理文件。要配置Filebeat,您需要在filebeat.yml配置文件的filebeat.prospectors部分指定一个prospector列表。列表中的每个项目都以破折号( - )开头,并指定探测器特定的配置选项,包括搜寻的文件路径列表。下面一个示例配置:
filebeat.prospectors: - type: log paths: - /var/log/apache/httpd-*.log - type: log paths: - /var/log/messages - /var/log/*.log
type
在此处指定的值用作发布到Logstash和Elasticsearch的每个事件的类型。以下输入类型之一:
log #读取日志文件的每一行(默认)。 stdin #读入标准 redis #从redis中读取慢日志条目(实验性)。 udp #通过UDP读取事件。
paths
应该被抓取和抓取的基于全局路径的列表。 Golang Glob支持的所有模式也支持这里。
recursive_glob
enabled:启用扩展**为递归全局模式。 启用此功能后,每条路径中最右边的**将扩展为固定数量的全局模式。例如:/ foo/**展开为/ foo,/ foo/*,/ foo/*/*等等。 该功能默认是禁用的,如果启用,则会将单个**扩展为8级深度*模式。
encoding
用于读取包含国际字符的文件的文件编码。以下是W3C推荐的一些示例编码:
plain, latin1, utf-8, utf-16be-bom, utf-16be, utf-16le, big5, gb18030, gbk, hz-gb-2312, euc-kr, euc-jp, iso-2022-jp, shift-jis, and so on
#plain的编码是特殊的,因为它不验证或转换任何输入。
exclude_lines
正则表达式的列表,以匹配您希望Filebeat排除的行。 Filebeat删除与列表中正则表达式匹配的所有行。 默认情况下,不会删除行。如果还指定了多行,则在由exclude_lines过滤行之前,每条多行消息都合并为一行。以下示例配置Filebeat以删除以“DBG”开头的所有行。
filebeat.prospectors: - paths: - /var/log/myapp/*.log exclude_lines: ['^DBG']
#正则表达式:https://www.elastic.co/guide/en/beats/filebeat/current/regexp-support.html
include_lines
正则表达式的列表,以匹配您希望Filebeat包含的行。 Filebeat仅导出与列表中正则表达式匹配的行。 默认情况下,所有行都被导出。如果还指定了多行,则在行被include_lines过滤之前,每条多行消息都合并为一行。以下示例将Filebeat配置为导出以“ERR”或“WARN”开头的所有行:
filebeat.prospectors: - paths: - /var/log/myapp/*.log include_lines: ['^ERR', '^WARN']
注意:如果同时定义了include_lines和exclude_lines,则Filebeat首先执行include_lines,然后执行exclude_lines。 这两个选项的定义顺序无关紧要。 即使exclude_lines出现在配置文件中的include_lines之前,include_lines选项也会始终在exclude_lines选项之前执行。
以下示例导出除调试消息(DBG)以外的所有Apache日志行:
include_lines: ['apache'] exclude_lines: ['^DBG']
exclude_files
正则表达式的列表,以匹配您希望Filebeat忽略的文件。 默认情况下没有文件被排除。以下示例将Filebeat配置为忽略所有具有gz扩展名的文件:
exclude_files: ['\.gz$']
tags
Beat包含在每个发布事件的标签字段中的标签列表。 标签可以很容易地在Kibana中选择特定的事件,或者在Logstash中应用条件过滤。 这些标签将被追加到一般配置中指定的标签列表中。例如下面的例子:
filebeat.prospectors: - paths: ["/var/log/app/*.json"] tags: ["json"]
fields
可以指定的可选字段将其他信息添加到输出。 例如,您可以添加可用于过滤日志数据的字段。 字段可以是标量值,数组,字典或这些的任何嵌套组合。 默认情况下,您在此处指定的字段将被分组在输出文档的fields 子字典下。 要将自定义字段存储为顶级字段,请将fields_under_root选项设置为true。 如果在通用配置中声明了重复字段,则其值将由此处声明的值覆盖。
filebeat.prospectors: - paths: ["/var/log/app/*.log"] fields: app_id: query_engine_12
fields_under_root
如果此选项设置为true,则自定义字段将作为顶级字段存储在输出文档中,而不是在字段子字典下进行分组。 如果自定义字段名称与由Filebeat添加的其他字段名称冲突,则自定义字段将覆盖其他字段。
processors
要应用于processors生成的数据的处理器列表。
有关在配置中指定处理器的信息,请参阅筛选并增强导出的数据:https://www.elastic.co/guide/en/beats/filebeat/current/filtering-and-enhancing-data.html
ignore_older
如果启用此选项,Filebeat将忽略在指定时间范围之前修改的任何文件。 如果长时间保存日志文件,配置ignore_older会特别有用。 例如,如果要启动Filebeat,但只想从上周发送最新的文件和文件,则可以配置此选项。可以使用 2h (2 hours) 和5m (5 minutes)的时间字符串。 默认值是0,禁用设置。 注释掉配置与将其设置为0的效果相同。注:必须将ignore_older设置为大于close_inactive。
受此设置影响的文件分为两类:
never harvested的文件 harvested但未更新的时间超过ignore_older的文件
ignore_older设置依赖于文件的修改时间来确定文件是否被忽略。 如果在将行写入文件(可能发生在Windows上)时文件的修改时间未更新,那么忽略文件夹设置可能会导致Filebeat忽略文件,即使稍后添加了内容。
要从注册表文件中删除先前收集的文件的状态,请使用clean_inactive配置选项。在prospector可以忽略一个文件之前,它必须关闭。 为了确保文件在被忽略时不再被捕获,必须将ignore_older设置为比close_inactive更长的持续时间。如果当前正在采集的文件属于ignore_older,则harvester将首先完成读取文件并在达到close_inactive后关闭该文件。 然后,之后,该文件将被忽略。
close_*
close_ *配置选项用于在一定的标准或时间后关闭harvester。 关闭harvester意味着关闭文件处理程序。 如果harvester关闭后文件被更新,则在scan_frequency过后,文件将被再次拾取。 但是,如果在harvester关闭的情况下移动或删除文件,Filebeat将无法再次拾取文件,harvester未读取的任何数据将丢失。
close_inactive
启用此选项时,Filebeat将关闭文件句柄(如果文件尚未在指定的时间内收获)。定义期间的计数器从harvester读取最后一个日志行开始。它不是基于文件的修改时间。如果关闭的文件再次发生变化,则会启动一个新的采集器,并在scan_frequency过去后采集最新的更改。建议将close_inactive设置为大于最不频繁的日志文件更新的值。例如,如果日志文件每隔几秒更新一次,则可以安全地将close_inactive设置为1m。如果存在具有完全不同更新速率的日志文件,则可以使用具有不同值的多个prospector配置。
将close_inactive设置为较低的值意味着文件句柄更快关闭。然而,这具有副作用,即如果从harvester关闭,则不近实时地发送新的日志行。关闭文件的时间戳不取决于文件的修改时间。相反,Filebeat使用内部时间戳来反映文件最后一次收获的时间。例如,如果将close_inactive设置为5分钟,则在harvester读取文件的最后一行之后,开始倒计时5分钟。可以使用 2h (2 hours) 和5m (5 minutes)的时间字符串。默认值是5m。
close_renamed
启用此选项时,文件重命名时Filebeat会关闭文件处理程序。 例如,在旋转文件时发生这种情况。 默认情况下,采集器保持打开状态并持续读取文件,因为文件处理程序不依赖于文件名。 如果启用了close_renamed选项,并且文件被重命名或移动的方式不再与为prospector指定的文件模式匹配,则文件将不会被再次读取。Filebeat不会完成读取文件。
close_removed
启用此选项后,Filebeat会在删除文件时关闭harvester。 正常情况下,文件只能在close_inactive指定的时间内处于非活动状态之后才能被删除。 但是,如果文件被提前删除,而没有启用close_removed,Filebeat会保持文件打开以确保harvester已经完成。 如果此设置导致未完全读取的文件,因为它们过早地从磁盘上删除,则禁用此选项。该选项默认启用。 如果禁用此选项,则还必须disable clean_removed。
close_eof
启用此选项后,Filebeat会在文件结束时立即关闭文件。 当文件只写入一次而不是不时更新时,这非常有用。 例如,当将每个日志事件写入新文件时,都会发生这种情况。 该选项默认是禁用的。
close_timeout
启用此选项时,Filebeat会为每个harvester提供预定义的生命周期。无论reader在文件中的哪个位置,close_timeout时间过后reading 都将停止。如果只想在文件上花费预定义的时间,则此选项对于较早的日志文件可能很有用。虽然close_timeout将在预定义的超时后关闭文件,但如果文件仍在更新中,那么prospector将根据定义的scan_frequency再次启动一个新的harvester。此harvester的close_timeout将重新开始,同时暂停倒计时。
该选项在输出被阻塞的情况下特别有用,这使得Filebeat即使对于从磁盘中删除的文件也保持打开的文件处理程序。将close_timeout设置为5m可确保文件定期关闭,以便操作系统释放它们。
如果将close_timeout设置为等于ignore_older,则在harvester关闭时如果修改该文件,则不会拾取文件。这些设置的组合通常会导致数据丢失,并且不会发送完整的文件。
当对包含多行事件的日志使用close_timeout时,harvester可能会停在多行事件的中间,这意味着只会发送部分事件。如果harvester再次启动并且文件仍然存在,则只会发送事件的第二部分。这个选项默认设置为0,这意味着它被禁用。
clean_*
clean_ *选项用于清理注册表文件中的状态条目。 这些设置有助于减小注册表文件的大小,并可以防止潜在的inode重用问题。
clean_inactive
启用此选项后,Filebeat会在指定的非活动时间段过去后移除文件的状态。 如果文件已被Filebeat忽略(该文件比ignore_older早),则只能删除状态。 clean_inactive设置必须大于ignore_older + scan_frequency,以确保在收集文件时不会删除状态。 否则,该设置可能会导致Filebeat不断重新发送全部内容,因为clean_inactive将删除探测器仍然检测到的文件的状态。 如果文件更新或再次出现,则从头开始读取文件。
clean_inactive配置选项对于减少注册表文件的大小非常有用,尤其是在每天生成大量新文件的情况下。此配置选项对于防止Linux上的inode重用导致的Filebeat问题也很有用。每次文件被重命名时,文件状态都会更新,clean_inactive的计数器将再次从0开始。
clean_removed
当启用此选项时,Filebeat将从注册表中清理文件,如果在最后一个已知名称下无法在磁盘上找到它们。这也意味着在收割机完成后重新命名的文件将被删除。默认情况下启用此选项。
如果共享驱动器在短时间内消失并再次出现,那么所有文件将从开始重新读取,因为这些状态是从注册表文件中删除的。在这种情况下,我们建议禁用clean_removed选项。
scan_frequency
prospector在指定采集的路径中检查新文件的频率。 例如,如果指定一个像/var/log/*的glob,则将使用scan_frequency指定的频率扫描目录中的文件。 指定1s以尽可能频繁地扫描目录。而不需要Filebeat过于频繁地扫描,我们不建议将此值设置为<1秒。默认设置是10秒。
如果您需要近实时发送日志行,请不要使用非常低的scan_frequency,而是调整close_inactive,以便文件处理程序保持打开状态并持续轮询文件。
scan.sort和scan.order
此功能是实验性的,可能会在将来的版本中完全更改或删除。 弹性将采取尽最大努力解决任何问题,但实验性功能不受支持官方GA功能的SLA。
harvester_buffer_size
每个harvester 在获取文件时使用的缓冲区的大小(以字节为单位)。 默认是16384。
max_bytes
单个日志消息可以拥有的最大字节数。 max_bytes之后的所有字节被丢弃并且不发送。 此设置对于可能变大的多行日志消息特别有用。 默认值是10MB(10485760)。
json
这些选项使得Filebeat能够解码构造为JSON消息的日志。 Filebeat逐行处理日志,所以JSON解码只在每行有一个JSON对象时才起作用。
解码发生在行滤波和多行之前。 如果设置了message_key选项,则可以将JSON解码与过滤和多行结合使用。 在应用程序日志被包装在JSON对象中的情况下,这可能会很有用,就像Docker发生的情况一样。例如下面的配置:
json.keys_under_root: true json.add_error_key: true json.message_key: log
必须至少指定以下设置之一来启用JSON解析模式:
keys_under_root #默认情况下,解码后的JSON放在输出文档中的“json”键下。 如果启用此设置,则会将键复制到输出文档的顶层。 默认值是false。 overwrite_keys #如果启用了keys_under_root和此设置,那么来自解码的JSON对象的值将覆盖Filebeat通常添加的字段(type, source, offset,等)以防冲突。 add_error_key #如果启用此设置,则在出现JSON解组错误或配置中定义了message_key但无法使用的情况下,Filebeat将添加“error.message”和“error.type:json”键。 message_key #一个可选的配置设置,用于指定应用行筛选和多行设置的JSON密钥。 如果指定,键必须位于JSON对象的顶层,且与键关联的值必须是字符串,否则不会发生过滤或多行聚合。
multiline
控制Filebeat如何处理跨越多行的日志消息的选项。 有关配置多行选项的更多信息,请参阅管理多行消息。https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html
tail_files
如果此选项设置为true,Filebeat开始在每个文件的tail读取新文件,而不是开始。 将此选项与日志循环结合使用时,可能会跳过新文件中的第一个日志条目. 默认设置是false。该选项适用于Filebeat尚未处理的文件。 如果以前运行过Filebeat,并且文件的状态已经被保存,则tail_files将不适用。
pipeline
Ingest节点pipeline标识,用于为prospector生成的事件设置。
symlinks
符号链接选项允许Filebeat除了常规文件以外还收集符号链接。 收集符号链接时,Filebeat会打开并读取原始文件,即使它报告符号链接的路径。当配置收集符号链接时,请确保排除原始路径。如果单个prospector配置为收集符号链接和原始文件,则prospector将检测到该问题并仅处理找到的第一个文件。 但是,如果配置了两个不同的prospectors(一个读取符号链接,另一个读取原始路径),则将采集两个路径,导致Filebeat发送重复数据,并且prospector覆盖彼此的状态。
如果符号链接到日志文件具有文件名中的附加元数据,并且您想要在Logstash中处理元数据,那么符号链接选项可能很有用。 例如,这是Kubernetes日志文件的情况。由于此选项可能会导致数据丢失,因此默认情况下会禁用该选项。
backoff
backoff选项指定Filebeat如何积极地搜索打开的文件以进行更新。在大多数情况下,可以使用默认值。backoff选项定义在到达EOF后再次检查文件之前Filebeat等待的时间。 默认值是1秒,这意味着如果添加了新行,每秒都会检查一次文件。 这使近乎实时的爬行。 每当文件中出现新行时,退避值将重置为初始值。 默认值是1s。
max_backoff
达到EOF后再次检查文件之前Filebeat等待的最长时间。 在检查文件多次退出之后,无论backoff_factor指定什么,等待时间都不会超过max_backoff。由于读取新行最多需要10秒,因此指定10s作为max_backoff意味着,如果Filebeat多次退出,则最坏的情况下可以将新行添加到日志文件中。 默认值是10秒。要求:max_backoff应始终设置为max_backoff <= scan_frequency。 如果max_backoff应该更大,建议关闭文件处理程序,而让prospector重新获取文件。
backoff_factor
此选项指定等待时间增加的速度。backoff factor越大,max_backoff的值就越快。1是禁用。默认值是2。backoff value每次与backoff_factor相乘,直到达到max_backoff.
harvester_limit
harvester_limit选项限制一个prospector并行启动的采集器的数量。这直接关系到打开的文件处理程序的最大数量。 harvester_limit的默认值是0,这意味着没有限制。如果要采集的文件数超过操作系统的打开文件处理程序限制,则此配置很有用。
enabled
enabled选项可与每个prospector一起使用,以定义prospector是否已启用。 默认情况下,enabled被设置为true。
max_message_size
当与type:udp一起使用的时候,指定通过UDP接收的消息的最大大小。默认值是10240。
博文来自:www.51niux.com
4.5 指定多个prospectors
当需要从多个文件中收集行时,可以简单地配置一个探测器,并指定多个路径来为每个文件启动一个harvester。但是,如果要将特定于探测器的其他配置设置(如字段,include_lines,exclude_lines,多行等)应用于从特定文件获取的行,则需要在Filebeat配置文件中定义多个prospectors。
在配置文件中,可以指定多个prospectors,并且每个prospectors可以定义多个要抓取的路径,如以下示例所示:
filebeat.prospectors: - type: log paths: - /var/log/system.log - /var/log/wifi.log - type: log paths: - "/var/log/apache2/*" fields: apache: true fields_under_root: true
#示例中的配置文件启动两个prospector(prospector列表是一个YAML数组,所以每个prospector以 - 开头)。 第一个prospector有两个harvesters,一个harvesting system.log文件,另一个harvesting wifi.log。第二个prospector为apache2目录中的每个文件启动一个收集器,并使用字段配置选项向输出添加一个名为apache的字段。
#确保一个文件在所有的prospectors中都没有定义多次,因为这会导致意外的行为。
4.6 管理多行消息
Filebeat收集的文件可能包含跨越多行文本的消息。 为了正确处理这些多行事件,需要在filebeat.yml文件中配置多行设置,以指定哪些行是单个事件的一部分。
注:如果要将多行事件发送到Logstash,请在将事件数据发送到Logstash之前,使用此处介绍的选项来处理多行事件。 尝试在Logstash中实现多线事件处理(例如,通过使用Logstash多线编解码器)可能会导致混合流和损坏的数据。
配置选项,可以在filebeat.yml配置文件的filebeat.prospectors部分指定以下选项:
multiline
控制Filebeat如何处理跨越多行的日志消息的选项。 多行消息在包含Java堆栈跟踪的文件中很常见。以下示例显示如何配置Filebeat来处理消息的第一行以括号([)开头的多行消息。
multiline.pattern: '^\[' multiline.negate: true multiline.match: after
可以在多行下指定以下设置来控制Filebeat如何组合消息中的行:
pattern:指定要匹配的正则表达式模式。
negate : 定义模式是否被否定。 默认值是false。
match:指定Filebeat如何将匹配行组合到事件中。 该设置是after或before。 这些设置的行为取决于为negate指定的内容:
flush_pattern:指定一个正则表达式,其中当前多行将从内存中清除,结束多行消息。
max_lines:可以组合成一个事件的最大行数。 如果多行消息包含多个max_lines,则会丢弃任何其他行。 默认值是500。
timeout:在指定的超时之后,即使没有找到新模式来启动新事件,Filebeat也会发送多行事件。 默认值是5s。
4.7 指定一般设置
可以在filebeat.yml配置文件中指定设置来控制Filebeat的一般行为。 这包括:
控制诸如发布者行为和某些文件的位置的全局选项。 所有Elastic Beats支持的常规选项。
全局Filebeat配置选项
这些选项位于filebeat命名空间中。
registry_file:注册表文件的名称。 如果使用相对路径,则认为是相对于数据路径。
filebeat.registry_file: registry #无法使用符号链接作为注册表文件。
#注册表文件仅在刷新新事件时更新,而不是在预定义时间段内更新。 这意味着如果有一些TTL过期的状态,只有在处理新事件时才会被删除。
config_dir : 包含其他探测器配置文件的目录的完整路径。每个配置文件必须以.yml结尾。 即使只处理文件的探测器部分,每个配置文件也必须指定完整的Filebeat配置层次结构。 所有全局选项(如registry_file)都将被忽略。
filebeat.config_dir: path/to/configs
#config_dir选项务必指向Filebeat主文件所在目录以外的目录。如果指定的路径不是绝对的,则认为是相对于配置路径。
shutdown_timeout : 在Filebeat关闭之前,Filebeat等待关闭以等待发布者完成发送事件的时间。默认情况下,此选项被禁用,Filebeat不会等待发布者在关闭之前完成发送事件。可以配置shutdown_timeout选项以指定Filebeat在关闭之前等待发布者完成发送事件的最长时间。 如果在达到shutdown_timeout之前确认所有事件,Filebeat将关闭。
filebeat.shutdown_timeout: 5s
一般配置选项
所有Elastic Beats都支持这些选项。 因为它们是常用选项,所以它们不是命名空间。一个示例配置:
name: "my-shipper" #Beat的名字。 如果此选项为空,则使用服务器的主机名。 该名称包含在每个已发布的事务中的beat.name字段中。 tags: ["service-X", "web-tier"] #Beat在每个发布的交易的标签字段中包含的标签列表。 通过标签可以很容易地将服务器按不同的逻辑属性分组
fields:可以指定的可选字段将其他信息添加到输出。 字段可以是标量值,数组,字典或这些的任何嵌套组合。 默认情况下,您在此处指定的字段将被分组在输出文档的字段子字典下。 要将自定义字段存储为顶级字段,请将fields_under_root选项设置为true。
fields: {project: "myproject", instance-id: "574734885120952459"}fields_under_root : 如果此选项设置为true,则自定义字段将作为顶级字段存储在输出文档中,而不是在字段子字典下进行分组。 如果自定义字段名称与其他字段名称冲突,则自定义字段将覆盖其他字段。
fields_under_root: true fields: instance_id: i-10a64379 region: us-east-1
processors : 要应用于Beat生成的数据的处理器列表。
max_procs:设置可以同时执行的最大CPU数量。 缺省值是系统中可用的逻辑CPU数量。
4.8 加载外部配置文件
对于prospector配置,可以在filebeat.yml文件的filebeat.config.prospectors部分中指定路径选项。 例如:
filebeat.config.prospectors: enabled: true path: configs/*.yml
Glob发现的每个文件必须包含一个或多个prospector定义的列表。 例如:
- type: log paths: - /var/log/mysql.log scan_frequency: 10s - type: log paths: - /var/log/apache.log scan_frequency: 5s
#两个正在运行的prospector没有定义重叠的文件路径是至关重要的。 如果多个prospector同时收获同一个文件,可能会导致意想不到的行为。
模块配置
对于模块配置,可以在filebeat.yml文件的filebeat.config.modules部分中指定路径选项。 默认情况下,Filebeat会加载modules.d目录中启用的模块配置。 例如:
filebeat.config.modules:
enabled: true
path: ${path.config}/modules.d/*.yml如果要使用modules命令启用和禁用模块配置,则路径设置必须指向modules.d目录。Glob找到的每个文件都必须包含一个或多个模块定义的列表。 例如:
- module: apache2 access: enabled: true var.paths: [/var/log/apache2/access.log*] error: enabled: true var.paths: [/var/log/apache2/error.log*]
4.9 实时重新加载
可以配置Filebeat以在发生更改时动态地重新加载配置文件。 该功能仅适用于prospector和模块配置文件。要配置此功能,请指定一个路径(Glob)来监视配置更改。 当Glob找到的文件发生变化时,根据配置文件的变化启动和停止新的prospectors and/or模块。
此功能在容器环境中特别有用,其中一个容器用于在同一主机上的其他容器中运行服务的日志。要启用动态配置重新加载,请在filebeat.config.prospectors或filebeat.config.modules部分下指定路径和重新加载选项。 例如:
filebeat.config.prospectors: enabled: true path: configs/*.yml #定义要检查更改的文件的Glob。 reload.enabled: true #设置为true时,启用动态配置重新加载。 reload.period: 10s #指定文件检查更改的频率。 不要将周期设置为小于1秒,因为文件的修改时间通常以秒为单位存储。 将周期设置为小于1s将导致不必要的开销。
4.10 配置内部队列
Filebeat使用内部队列来存储事件,然后发布它们。 队列负责缓冲事件并将其组合成可以被输出消耗的批处理。 输出将使用批量操作在一个事务中发送一批事件。可以通过在filebeat.yml配置文件的queue部分中设置选项来配置内部队列的类型和行为。例如:
queue.mem: events: 4096
配置内存队列
内存队列将所有事件保存在内存中。 这是目前唯一支持的队列类型。 缺省情况下,没有配置刷新周期。 发布到此队列的所有事件将直接由输出消耗。 输出的bulk_max_size设置限制了一次处理事件的数量。
内存队列等待输出确认或放弃事件。 如果队列已满,则不能将新事件插入到Memeory队列中。 只有输出信号后,队列才能腾出空间让更多的事件被接受。
要在队列中强制假脱机,请设置flush.min_events和flush.timeout选项。
如果有512个事件可用或者最早的可用事件已经在队列中等待5秒,则此示例配置将事件转发到输出:
queue.mem: events: 4096 #队列可以存储的事件数量。默认值是4096个事件。 flush.min_events: 512 #发布所需的最小事件数量。 如果此值设置为0,则输出可以开始发布事件,而无需额外的等待时间。 否则,输出必须等待更多事件可用。默认值是0。 flush.timeout: 5s #满足flush.min_events的最长等待时间。 如果设置为0,事件将立即可用于消费。默认值是0s。
4.11 配置输出
官网链接:https://www.elastic.co/guide/en/beats/filebeat/current/configuring-output.html
#上一章也已经介绍了这里就不过多记录了。就记录配置Logstash输出。
Logstash输出通过使用运行在TCP上的lumberjack协议将事件直接发送到Logstash。 Logstash允许额外处理和路由生成的事件。要将Logstash用作输出,必须安装并配置Logstash的Beats输入插件(https://www.elastic.co/guide/en/beats/libbeat/6.0/logstash-installation.html#logstash-setup)。
如果要使用Logstash对Filebeat收集的数据执行其他处理,则需要将Filebeat配置为使用Logstash。为此,可以编辑Filebeat配置文件,通过将Elasticsearch输出注释掉并通过取消注释logstash部分来启用Logstash输出来禁用Elasticsearch输出:
#----------------------------- Logstash output -------------------------------- output.logstash: hosts: ["127.0.0.1:5044"]
访问元数据字段
发送到Logstash的每个事件都包含以下元数据字段,可以在Logstash中使用这些元数据字段进行索引和过滤:
{
...
"@metadata": { #Filebeat使用@metadata字段将元数据发送到Logstash。
"beat": "filebeat", #默认是filebeat。 要更改此值,请在Filebeat配置文件中设置index选项。
"version": "6.0.1" #当前beat的版本
"type": "doc" #类型的值目前被硬编码为doc。 之前的Logstash配置使用它来设置Elasticsearch中文档的类型。
}
}#有关@metadata的更多信息:https://www.elastic.co/guide/en/logstash/6.0/event-dependent-configuration.html#metadata
#@metadata。在日志存储输出中添加的类型字段被弃用,硬编码到doc,并将在Filebeat 7.0中删除。
可以从Logstash配置文件中访问此元数据,以根据元数据的内容动态设置值。例如,版本2.x和5.x的以下Logstash配置文件将Logstash设置为使用Beats报告的索引和文档类型将事件索引到Elasticsearch中:
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}#%{[@ metadata] [beat]}将索引名称的第一部分设置为beat元数据字段的值,%{[@ metadata] [version]}将第二部分设置为beat的版本,%{ YYYY.MM.dd}将名称的第三部分设置为基于Logstash @timestamp字段的日期。 例如:filebeat-6.0.1-2017.03.29。
配置选项
可以在filebeat.yml配置文件的logstash部分中指定以下选项:
enabled :启用的配置是一个布尔设置来启用或禁用输出。 如果设置为false,则输出被禁用。默认值是true。
hosts : 已知的Logstash服务器连接到的列表。 如果禁用负载均衡,但配置了多个主机,则随机选择一个主机(没有优先级)。 如果一台主机变得不可达,另一台主机随机选择。此列表中的所有条目都可以包含一个端口号。 如果未给出端口号,则将为端口指定的值用作默认端口号。
compression_level :gzip压缩级别。 将此值设置为0将禁用压缩。 压缩级别必须在1(最佳速度)到9(最佳压缩)的范围内。
增加压缩级别将减少网络使用,但会增加CPU使用率。默认值是3。
worker: 每个配置的主机发布事件到Logstash的工作者数量。 这最好与启用负载平衡模式一起使用。 示例:如果您有2个hosts和3个worker,则共有6个workers(每个主机3个)启动。
loadbalance:如果设置为true,并且配置了多个Logstash主机,则输出插件将已发布的事件负载平衡到所有Logstash主机上。 如果设置为false,则输出插件会将所有事件发送到只有一个主机(随机确定),并且如果所选事件不响应,将切换到另一个主机。 默认值是false。
ttl : 现在需要连接到Logstash,然后重新建立连接。 当Logstash主机代表负载均衡器时很有用。 由于与Logstash主机的连接在负载平衡器后面粘滞可能会导致实例之间负载分配不均匀。 在连接上指定TTL允许在实例之间实现相等的连接分配。 指定TTL为0将禁用此功能。默认值是0。“ttl”选项在异步Logstash客户端(其中一个设置了“pipelining”选项)上还不被支持。
output.logstash: hosts: ["localhost:5044", "localhost:5045"] loadbalance: true index: filebeat
pipelining:在等待来自logstash的ACK时配置要异步发送到logstash的批次数。 一旦编写了流水线批处理,输出就会被阻塞。 如果配置了值0,则流水线禁用。 默认值是5。
port:如果端口号未在主机中提供,则使用默认端口。 默认端口号是10200。
proxy_url:连接到Logstash服务器时使用的SOCKS5代理的URL。 该值必须是具有socks5://方案的URL。 用于与Logstash进行通信的协议不基于HTTP,所以不能使用Web代理。如果SOCKS5代理服务器需要客户端认证,那么可以在URL中嵌入用户名和密码,如示例所示。使用代理时,主机名将在代理服务器上解析,而不是在客户端上解析。 您可以通过设置proxy_use_local_resolver选项来更改此行为。
output.logstash: hosts: ["remote-host:5044"] proxy_url: socks5://user:password@socks5-proxy:2233
proxy_use_local_resolver:proxy_use_local_resolver选项决定在使用代理时本地解析Logstash主机名。 默认值为false,这意味着使用代理时,代理服务器上会发生名称解析。
index : 要写入事件的索引根名称。 默认值是Beat名称。 例如“filebeat”生成“[filebeat-] YYYY.MM.DD”索引(例如,“filebeat-2015.04.26”)。
ssl:SSL参数的配置选项,例如Logstash连接的根CA。 有关更多信息,请参阅指定SSL设置(https://www.elastic.co/guide/en/beats/filebeat/current/configuration-ssl.html)。 要使用SSL,还必须为Logstash配置Beats输入插件以使用SSL / TLS(https://www.elastic.co/guide/en/logstash/current/plugins-inputs-beats.html)。
timeout:在超时之前等待来自Logstash服务器的响应的秒数。 默认值是30(秒)。
max_retries:发布失败后重试发布事件的次数。 在指定的重试次数之后,事件通常会被丢弃。 一些Beats(如Filebeat)会忽略max_retries设置并重试,直到发布所有事件。将max_retries设置为小于0的值以重试,直到发布所有事件。默认值是3。
bulk_max_size:在单个Logstash请求中批量处理的最大事件数量。 默认是2048。如果Beat发送单个事件,则将事件分批收集。 如果Beat发布大量事件(大于bulk_max_size指定的值),则会批处理。指定较大的批量大小可以通过降低发送事件的开销来提高性能。 但是,大批量处理也会增加处理时间,这可能会导致API错误,连接中断,超时发布请求以及最终的吞吐量下降。将bulk_max_size设置为小于或等于0的值将禁用分批。 当分割被禁用时,队列决定批量中包含的事件的数量。
slow_start:如果启用,则每个事务只传输一批事件中的一部分事件。 如果没有错误发生,发送的事件数量增加到bulk_max_size。 错误时,每个事务的事件数量再次减少。默认值是false。
#后面写了好多没保存上不写了,可以看官网文档......
4.12 配置日志输出
filebeat.yml配置文件的日志记录部分包含用于配置Beats日志记录输出的选项。 日志系统可以将日志写入系统日志或旋转日志文件。 如果未明确配置日志记录,则在Windows系统上使用文件输出,在Linux和OS X上使用syslog输出。
logging.level: warning #输出的日志级别debug, info, warning, error, or critical logging.to_files: true #如果为true,则将所有日志记录输出写入文件。 当达到日志文件大小限制时,日志文件会自动旋转 logging.to_syslog: false #如果为true,则将所有日志输出写入syslog logging.files: path: /var/log/mybeat name: mybeat.log keepfiles: 7 permissions: 0644
链接:https://www.elastic.co/guide/en/beats/filebeat/current/configuration-logging.html
