Logstash多配置文件启动(五)
一、配置Logstash(跟着官网学习一下可直接忽略)
1.1 配置文件结构
Logstash配置文件为要添加到事件处理管道的每种类型的插件都有一个单独的部分。 例如:
# This is a comment. You should use comments to describe
# parts of your configuration.
input {
...
}
filter {
...
}
output {
...
}#每个部分都包含一个或多个插件的配置选项。 如果指定了多个过滤器,则会按照它们在配置文件中的显示顺序应用它们。
插件配置
插件的配置由插件名称和插件的一个设置块组成。 例如,这个输入部分配置两个文件输入:
input {
file {
path => "/var/log/messages"
type => "syslog"
}
file {
path => "/var/log/apache/access.log"
type => "apache"
}
}Value Types
一个插件可以要求设置的值是一个特定的类型,比如布尔值,列表或哈希值。 以下值类型受支持。
Array:
这种类型现在大多被弃用,倾向于使用标准类型如字符串与插件定义:list => true属性更好的类型检查。 仍然需要处理不需要类型检查的散列或混合类型列表。
Lists:
不是一个类型本身,而是一个属性类型。这使得对多个值进行类型检查成为可能。插件作者可以通过指定:list => true在声明参数时启用列表检查。例如:
path => [ "/var/log/messages", "/var/log/*.log" ] uris => [ "http://elastic.co", "http://example.net" ]
#这个例子配置路径,这是一个字符串,它是一个包含三个字符串中的每一个元素的列表。 它还会将uris参数配置为URI列表,如果提供的任何URI无效,则失败。
Boolean :
布尔值必须是true或false。 请注意,true和false关键字不包含在引号中。
Bytes:
字节字段是表示有效字节单位的字符串字段。 在插件选项中声明特定大小是一种方便的方法。 支持SI(k M G T P E Z Y)和二进制(Ki Mi Gi Ti Pi Ei Zi Yi)单元。 二进制单位以1024为底,SI单位以1000为底。 该字段不区分大小写,并且接受值和单位之间的空格。 如果没有指定单位,则整数字符串表示字节数。例如:
my_bytes => "1113" # 1113 bytes my_bytes => "10MiB" # 10485760 bytes my_bytes => "100kib" # 102400 bytes my_bytes => "180 mb" # 180000000 bytes
Codec:
编解码器是用于表示数据的Logstash编解码器的名称。 编解码器可用于输入和输出。输入编解码器提供了一种方便的方式来解码数据,然后再进入输入。 输出编解码器提供了一种在数据离开输出之前进行编码的便捷方式。 使用输入或输出编解码器,无需在Logstash管道中使用单独的过滤器。可用编解码器的列表可以在编解码器插件页面找到。例如:
codec => "json"
Hash:
散列是以“field1”=>“value1”格式指定的键值对的集合。 请注意,多个键值条目由空格而不是逗号分隔。例:
match => {
"field1" => "value1"
"field2" => "value2"
...
}Number:
数字必须是有效的数值(浮点或整数)。例:
port => 33
Password:
密码是一个没有记录或打印的单个值的字符串。例:
my_password => "password"
URI:
URI可以是像http://elastic.co/这样的完整URL,也可以是简单的标识符,比如foobar。 如果URI包含诸如http://user:pass@example.net之类的密码,则不会记录或打印URI的密码部分。例:
my_uri => "http://foo:bar@example.net"
Path:
路径是表示有效的操作系统路径的字符串。例:
my_path => "/tmp/logstash"
String:
一个字符串必须是单个字符序列。 请注意,字符串值用双引号或单引号引起来。
转义序列:
默认情况下,转义序列没有启用。 如果你想在引用的字符串中使用转义序列,你需要在logstash.yml中设置config.support_escapes:true。 如果是true,引用的字符串(双精度和单精度)将会有这样的转换:
\r #回车(ASCII 13) \n #新行(ASCII 10) \t #Tab(ASCII 9) \\ #反斜杠(ASCII 92) \” #双引号(ASCII 34) \' #单引号(ASCII 39)
例如:
name => "Hello world" name => 'It\'s a beautiful day'
注释与perl,ruby和python相同。评论以#开头,不需要在行首。 例如:
# this is a comment
input { # comments can appear at the end of a line, too
# ...
}1.2 访问配置中的事件数据和字段
logstash agent是一个具有3个阶段的处理流水线:输入→过滤器→输出。 输入生成事件,过滤器修改它们,输出将其发送到别处。所有事件都有属性。 例如,apache访问日志会包含状态代码(200,404),请求路径(“/”,“index.html”),HTTP动词(GET,POST),客户端IP地址等.Logstash调用这些 属性“field”。
Logstash中的一些配置选项需要存在字段才能运行。 因为输入会生成事件,所以在输入块中没有要评估的字段 - 它们还不存在!由于它们依赖于事件和字段,以下配置选项只能在过滤器和输出块中使用。
下面介绍的字段引用,sprintf格式和条件在输入块中不起作用。
字段参考:
能够通过名称来引用字段通常是有用的。 为此,可以使用Logstash字段引用语法。访问字段的语法是[fieldname]。 如果你指的是顶级字段,则可以省略[]并简单地使用字段名称。 要引用嵌套字段,请指定该字段的完整路径:[top-level field] [nested field]。
例如,以下事件有五个顶级字段(agent,ip,request,response,ua)和三个嵌套字段(status,bytes,os)。
{
"agent": "Mozilla/5.0 (compatible; MSIE 9.0)",
"ip": "192.168.24.44",
"request": "/index.html"
"response": {
"status": 200,
"bytes": 52353
},
"ua": {
"os": "Windows 7"
}
}#要引用os字段,请指定[ua] [os]。 要引用顶级字段(如请求),只需指定字段名称即可。
sprintf格式
Logstash调用sprintf格式时也使用字段引用格式。这种格式使你能够从其他字符串中引用字段值。 例如,statsd输出有一个增量设置,使你可以通过状态代码保留apache日志的计数:
output {
statsd {
increment => "apache.%{[response][status]}"
}
}同样,你可以将@timestamp字段中的时间戳转换为字符串。 而不是在大括号内指定一个字段名称,使用FORMAT是一个时间格式的+ FORMAT语法。例如,如果要使用文件输出来根据事件的日期和小时以及类型字段写入日志
output {
file {
path => "/var/log/%{type}.%{+yyyy.MM.dd.HH}"
}
}条件语句
有时你只想在某些条件下过滤或输出一个事件。 为此,你可以使用条件。Logstash中的条件与编程语言中的条件相同。 条件支持if,else if和else语句可以嵌套。条件语法是:
if EXPRESSION {
...
} else if EXPRESSION {
...
} else {
...
}什么是表达? 比较测试,布尔逻辑等等!你可以使用以下比较运算符:
比较:==,!=,<,>,<=,> = 正则表达式:=〜,!〜(检查左侧的字符串值的模式) 包含:in,not in
支持的布尔运算符是:
and, or, nand, xor
支持的一元运算符是:
!
表达式可以是漫长而复杂的。 表达式可以包含其他表达式,可以用!来否定表达式,并且可以用圆括号(...)对它们进行分组。例如,如果字段操作具有登录值,则以下条件使用mutate过滤器来删除字段密钥:
filter {
if [action] == "login" {
mutate { remove_field => "secret" }
}
}可以在单个条件中指定多个表达式:
output {
# Send production errors to pagerduty
if [loglevel] == "ERROR" and [deployment] == "production" {
pagerduty {
...
}
}
}可以使用in运算符来测试某个字段是否包含特定的字符串,键或(用于列表)元素:
filter {
if [foo] in [foobar] {
mutate { add_tag => "field in field" }
}
if [foo] in "foo" {
mutate { add_tag => "field in string" }
}
if "hello" in [greeting] {
mutate { add_tag => "string in field" }
}
if [foo] in ["hello", "world", "foo"] {
mutate { add_tag => "field in list" }
}
if [missing] in [alsomissing] {
mutate { add_tag => "shouldnotexist" }
}
if !("foo" in ["hello", "world"]) {
mutate { add_tag => "shouldexist" }
}
}用条件不一样的方式。 例如,当grok成功时,你可以不使用它仅将事件路由到Elasticsearch。
output {
if "_grokparsefailure" not in [tags] {
elasticsearch { ... }
}
}可以检查是否存在特定的字段,但目前无法区分不存在的字段与简单的假字段。 表达式if [foo]在下列情况下返回false:
事件中不存在[foo] [foo]存在于事件中,但是是假的,或者 事件中存在[foo],但为空
@metadata字段
在Logstash 1.5及更高版本中,有一个称为@metadata的特殊字段。 @metadata的内容在输出时不会成为你的任何事件的一部分,这使得它很适合用于条件,或者扩展和构建带有字段引用和sprintf格式的事件字段。
以下配置文件将从STDIN中产生事件。 无论输入什么,都将成为赛事的信息领域。 过滤器块中的mutate事件将添加一些嵌套在@metadata字段中的字段。
input { stdin { } }
filter {
mutate { add_field => { "show" => "This data will be in the output" } }
mutate { add_field => { "[@metadata][test]" => "Hello" } }
mutate { add_field => { "[@metadata][no_show]" => "This data will not be in the output" } }
}
output {
if [@metadata][test] == "Hello" {
stdout { codec => rubydebug }
}
}查看下输出:
$ bin/logstash -f ../test.conf
Pipeline main started
asdf
{
"@timestamp" => 2016-06-30T02:42:51.496Z,
"@version" => "1",
"host" => "example.com",
"show" => "This data will be in the output",
"message" => "asdf"
}输入的“asdf”成为消息字段内容,并且条件成功地评估了嵌套在@metadata字段中的测试字段的内容。 但是输出没有显示一个名为@metadata的字段或其内容。rubydebug编解码器允许您在添加配置标志metadata => true的情况下显示@metadata字段的内容:
stdout { codec => rubydebug { metadata => true } }查看输出的改变:
$bin/logstash -f ../test.conf
Pipeline main started
asdf
{
"@timestamp" => 2016-06-30T02:46:48.565Z,
"@metadata" => {
"test" => "Hello",
"no_show" => "This data will not be in the output"
},
"@version" => "1",
"host" => "example.com",
"show" => "This data will be in the output",
"message" => "asdf"
}#只有rubydebug编码器允许显示@metadata字段的内容。
每当你需要一个临时的字段,但不希望它在最终的输出中时,使用@metadata字段。也许这个新的领域最常见的用例之一是日期过滤器,并有一个临时的时间戳。这个配置文件已被简化,但是使用Apache和Nginx Web服务器通用的时间戳格式。 过去,在使用它来覆盖@timestamp字段之后,你必须自己删除时间戳字段。 使用@metadata字段,这不再是必要的:
input { stdin { } }
filter {
grok { match => [ "message", "%{HTTPDATE:[@metadata][timestamp]}" ] }
date { match => [ "[@metadata][timestamp]", "dd/MMM/yyyy:HH:mm:ss Z" ] }
}
output {
stdout { codec => rubydebug }
}请注意,此配置会将提取的日期放入Grok过滤器的[@metadata] [timestamp]字段中。 让我们给这个配置一个样本日期字符串,看看结果如何:
$ bin/logstash -f ../test.conf
Pipeline main started
02/Mar/2014:15:36:43 +0100
{
"@timestamp" => 2014-03-02T14:36:43.000Z,
"@version" => "1",
"host" => "example.com",
"message" => "02/Mar/2014:15:36:43 +0100"
}输出中没有额外的字段,也没有清洁的配置文件,因为你不必在日期过滤器中转换之后删除“时间戳”字段。另一个用例是CouchDB Changes输入插件(请参阅https://github.com/logstash-plugins/logstash-input-couchdb_changes)。 该插件自动将CouchDB文档字段元数据捕获到输入插件本身的@metadata字段中。 当事件通过Elasticsearch索引时,Elasticsearch输出插件允许您指定动作(删除,更新,插入等)和document_id,如下所示:
output {
elasticsearch {
action => "%{[@metadata][action]}"
document_id => "%{[@metadata][_id]}"
hosts => ["example.com"]
index => "index_name"
protocol => "http"
}
}1.3 在配置中使用环境变量
概述
可以使用${var}在Logstash插件的配置中设置环境变量引用。
在Logstash启动时,每个引用将被替换为环境变量的值。
替换是区分大小写的。
引用未定义的变量会引起Logstash配置错误。
可以使用${var:default value}的形式给出一个默认值。如果环境变量未定义,Logstash使用默认值。
可以在任何插件选项类型中添加环境变量引用:string, number, boolean, array, or hash。
环境变量是不可变的。如果更新环境变量,则必须重新启动Logstash才能获取更新后的值。以下示例显示如何使用环境变量设置一些常用配置选项的值。
Setting the TCP Port
以下是使用环境变量设置TCP端口的示例:
input {
tcp {
port => "${TCP_PORT}"
}
}现在我们来设置TCP_PORT的值:
export TCP_PORT=12345
启动时,Logstash使用以下配置:
input {
tcp {
port => 12345
}
}如果未设置TCP_PORT环境变量,Logstash将返回配置错误。可以通过指定一个默认值来解决这个问题:
input {
tcp {
port => "${TCP_PORT:54321}"
}
}现在,如果变量未定义,而不是返回配置错误,Logstash使用默认值:
input {
tcp {
port => 54321
}
}#如果定义了环境变量,Logstash将使用为变量指定的值而不是缺省值。
Setting the Value of a Tag
以下是一个使用环境变量设置标签值的示例:
filter {
mutate {
add_tag => [ "tag1", "${ENV_TAG}" ]
}
}来设置ENV_TAG的值:
export ENV_TAG="tag2"
启动时,Logstash使用以下配置:
filter {
mutate {
add_tag => [ "tag1", "tag2" ]
}
}设置文件路径
以下是使用环境变量设置日志文件路径的示例:
filter {
mutate {
add_field => {
"my_path" => "${HOME}/file.log"
}
}
}来设置HOME的值:
export HOME="/path"
启动时,Logstash使用以下配置:
filter {
mutate {
add_field => {
"my_path" => "/path/file.log"
}
}
}1.4 配置示例
使用条件
使用条件来控制过滤器或输出处理的事件。 例如,你可以根据每个事件出现在哪个文件(access_log,error_log和其他以“log”结尾的随机文件)来标记每个事件。
input {
file {
path => "/tmp/*_log"
}
}
filter {
if [path] =~ "access" {
mutate { replace => { type => "apache_access" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
} else if [path] =~ "error" {
mutate { replace => { type => "apache_error" } }
} else {
mutate { replace => { type => "random_logs" } }
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}#此示例使用类型字段标记所有事件,但实际上不分析错误或随机文件。 有很多类型的错误日志,他们应该如何标记真正取决于你正在使用的日志。同样,可以使用条件将事件定向到特定的输出。 例如,你可以:
状态为5xx的任何apache事件的alert nagios 将任何4xx状态记录到Elasticsearch 通过statsd记录所有的状态码命中
要告诉nagios任何具有5xx状态码的http事件,首先需要检查type字段的值。 如果是apache,那么可以检查状态字段是否包含5xx错误。 如果是,请将其发送给nagios。 如果不是5xx错误,请检查状态字段是否包含4xx错误。 如果是的话,把它发送给Elasticsearch。 最后,无论状态字段包含什么,都将所有的apache状态码发送到statsd:
output {
if [type] == "apache" {
if [status] =~ /^5\d\d/ {
nagios { ... }
} else if [status] =~ /^4\d\d/ {
elasticsearch { ... }
}
statsd { increment => "apache.%{status}" }
}
}1.5 Glob Pattern Support
Logstash在允许使用全局模式的地方支持以下模式:
* #匹配任何文件。也可以使用*来限制glob中的其他值。例如,*conf匹配以conf结尾的所有文件。 *apache*在名称中匹配任何带有apache的文件。这种模式与类Unix操作系统上的隐藏文件(点文件)不匹配。 要匹配点文件,请使用{*,.*}之类的模式。
** #以递归方式匹配目录。
? #匹配任何一个字符。
[set] #匹配集合中的任何一个字符。例如,[a-z]。还支持设置否定([^a-z])。
{p,q} #匹配文字p或文字q。匹配的文字可以是多个字符,并且可以指定两个以上的文字。这种模式相当于在正则表达式(foo|bar)中使用垂直条的交替。
\ #转义下一个元字符。这意味着您不能在Windows中使用反斜杠作为glob的一部分。模式c:\foo*将不起作用,所以请使用foo*。示例:
"/path/to/*.conf" #匹配指定路径中以.conf结尾的配置文件。
"/var/log/*.log" #在指定的路径中匹配以.log结尾的日志文件。
"/var/log/**/*.log #匹配以指定路径下的子目录中的.log结尾的日志文件。
"/path/to/logs/{app1,app2,app3}/data.log" #匹配指定路径下的app1,app2和app3子目录中的应用程序日志文件。1.6 转换Ingest Node管道
在实现接收管道来分析数据之后,可能会决定要利用Logstash中更丰富的转换功能。 为了使你更容易地迁移配置,Logstash提供了一个摄取管道转换工具。 转换工具将采集管道定义作为输入,并在可能的情况下创建等效的Logstash配置作为输出:https://www.elastic.co/guide/en/logstash/current/ingest-converter.html
博文来自:www.51niux.com
1.7 Data Resiliency
当数据流经事件处理管道时,Logstash可能会遇到阻止将事件传递到配置的输出的情况。 例如,数据可能包含意外的数据类型,或者Logstash可能异常终止。
为了防止数据丢失并确保事件不间断地流经管道,Logstash提供了以下数据弹性功能。
(Persistent Queues)持久性队列通过将事件存储在磁盘上的内部队列中来防止数据丢失。https://www.elastic.co/guide/en/logstash/current/persistent-queues.html
(Dead Letter Queues)死信队列为Logstash无法处理的事件提供磁盘存储。 可以使用dead_letter_queue输入插件轻松重新处理死信队列中的事件。https://www.elastic.co/guide/en/logstash/current/dead-letter-queues.html
这些弹性功能在默认情况下是禁用的。 要打开这些功能,你必须在Logstash设置文件中明确启用它们。
二、转换数据(翻译官网可直接忽略)
在Logstash插件生态系统中有超过200个插件,选择最好的插件来满足您的数据处理需求有时是一个挑战。 在本节中,我们收集了一些流行的插件列表,并根据其处理能力对其进行组织:
2.1 执行核心操作
date filter
从字段解析日期以用作事件的Logstash时间戳。以下配置解析名为logdate的字段以设置Logstash时间戳:
filter {
date {
match => [ "logdate", "MMM dd yyyy HH:mm:ss" ]
}
}drop filter
Drops事件。该过滤器通常与条件结合使用。以下配置将删除调试级别的日志消息:
filter {
if [loglevel] == "debug" {
drop { }
}
}fingerprint filter
Fingerprints fields 通过应用一致的散列。以下配置指纹IP,@timestamp和message字段,并将该散列添加到名为generated_id的元数据字段中:
filter {
fingerprint {
source => ["IP", "@timestamp", "message"]
method => "SHA1"
key => "0123"
target => "[@metadata][generated_id]"
}
}mutate filter
在字段上执行常规突变。 可以重命名,删除,替换和修改事件中的字段。以下配置将HOSTORIP字段重命名为client_ip:
filter {
mutate {
rename => { "HOSTORIP" => "client_ip" }
}
}ruby filter
执行Ruby代码。以下配置执行取消90%事件的Ruby代码:
filter {
ruby {
code => "event.cancel if rand <= 0.90"
}
}2.2 反序列化数据
avro codec
将序列化的Avro记录作为Logstash事件读取。 这个插件反序列化个别Avro记录。 这不适用于阅读Avro文件。 Avro文件具有必须在输入时处理的唯一格式。以下配置反序列化来自Kafka的输入:
input {
kafka {
codec => {
avro => {
schema_uri => "/tmp/schema.avsc"
}
}
}
}
...csv filter
将逗号分隔的值数据分析为单个字段。 默认情况下,筛选器自动生成字段名称(column1,column2等),或者可以指定一个名称列表。 您也可以更改列分隔符。以下配置将CSV数据分析为列字段中指定的字段名称:
filter {
csv {
separator => ","
columns => [ "Transaction Number", "Date", "Description", "Amount Debit", "Amount Credit", "Balance" ]
}
}json codec
解码(通过输入)并编码(通过输出)JSON格式的内容,在JSON数组中为每个元素创建一个事件。以下配置解码文件中的JSON格式的内容:
input {
file {
path => "/path/to/myfile.json"
codec =>"json"
}protobuf codec
读取protobuf编码的消息并将其转换为Logstash事件。 需要将protobuf定义编译为Ruby文件。 可以使用ruby-protoc编译器来编译它们。以下配置解码来自Kafka流的事件:
input
kafka {
zk_connect => "127.0.0.1"
topic_id => "your_topic_goes_here"
codec => protobuf {
class_name => "Animal::Unicorn"
include_path => ['/path/to/protobuf/definitions/UnicornProtobuf.pb.rb']
}
}
}xml filter
将XML解析为字段。以下配置解析存储在消息字段中的整个XML文档:
filter {
xml {
source => "message"
}
}2.3 提取字段和Wrangling数据
dissect filter
使用分隔符将非结构化事件数据提取到字段中。 解剖过滤器不使用正则表达式,速度非常快。 但是,如果数据的结构因行而异,grok过滤器更合适。例如,假设日志中包含以下消息:
Apr 26 12:20:02 localhost systemd[1]: Starting system activity accounting tool...
以下配置解析消息:
filter {
dissect {
mapping => { "message" => "%{ts} %{+ts} %{+ts} %{src} %{prog}[%{pid}]: %{msg}" }
}
}解剖过滤器应用后,事件将被解剖到以下领域:
{
"msg" => "Starting system activity accounting tool...",
"@timestamp" => 2017-04-26T19:33:39.257Z,
"src" => "localhost",
"@version" => "1",
"host" => "localhost.localdomain",
"pid" => "1",
"message" => "Apr 26 12:20:02 localhost systemd[1]: Starting system activity accounting tool...",
"type" => "stdin",
"prog" => "systemd",
"ts" => "Apr 26 12:20:02"
}kv filter
解析键值对。例如,假设有一条包含以下键值对的日志消息:
ip=1.2.3.4 error=REFUSED
以下配置将键值对解析为字段:
filter {
kv { }
}应用过滤器后,示例中的事件将具有以下字段:
ip: 1.2.3.4 error: REFUSED
grok filter
将非结构化事件数据分析到字段中。 这个工具非常适用于系统日志,Apache和其他网络服务器日志,MySQL日志,以及通常为人类而不是计算机消耗的任何日志格式。 Grok通过将文本模式组合成与日志匹配的东西来工作。例如,假设有一个包含以下消息的HTTP请求日志:
55.3.244.1 GET /index.html 15824 0.043
以下配置将消息解析为字段:
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}应用过滤器后,示例中的事件将具有以下字段:
client: 55.3.244.1 method: GET request: /index.html bytes: 15824 duration: 0.043
#如果您需要帮助构建Grok模式,请尝试使用Grok调试器(https://www.elastic.co/guide/en/kibana/6.0/xpack-grokdebugger.html)。 Grok调试器是基本许可下的X-Pack功能,因此可以免费使用。
2.4 丰富的数据查找
dns filter
执行标准或反向DNS查找。以下配置对source_host字段中的地址执行反向查找,并将其替换为域名:
filter {
dns {
reverse => [ "source_host" ]
action => "replace"
}
}elasticsearch
将Elasticsearch中以前的日志事件的字段复制到当前事件中。
以下配置显示了如何使用此过滤器的完整示例。 每当Logstash收到一个“end”事件时,它就会使用这个Elasticsearch过滤器来根据某个操作标识符来查找匹配的“start”事件。 然后它将@timestamp字段从“start”事件复制到“end”事件的新字段。 最后,使用日期过滤器和ruby过滤器的组合,示例中的代码计算两个事件之间的持续时间(小时)。
if [type] == "end" {
elasticsearch {
hosts => ["es-server"]
query => "type:start AND operation:%{[opid]}"
fields => { "@timestamp" => "started" }
}
date {
match => ["[started]", "ISO8601"]
target => "[started]"
}
ruby {
code => 'event.set("duration_hrs", (event.get("@timestamp") - event.get("started")) / 3600) rescue nil'
}
}geoip filter
添加有关IP地址位置的地理信息。 例如:
filter {
geoip {
source => "clientip"
}
}jdbc_streaming
用数据库数据丰富事件。以下示例执行SQL查询并将结果集存储在名为country_details的字段中:
filter {
jdbc_streaming {
jdbc_driver_library => "/path/to/mysql-connector-java-5.1.34-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/mydatabase"
jdbc_user => "me"
jdbc_password => "secret"
statement => "select * from WORLD.COUNTRY WHERE Code = :code"
parameters => { "code" => "country_code"}
target => "country_details"
}
}translate filter
根据散列或文件中指定的替换值替换字段内容。 目前支持这些文件类型:YAML,JSON和CSV。以下示例采用response_code字段的值,将其翻译为基于字典中指定的值的描述,然后从事件中删除response_code字段:
filter {
translate {
field => "response_code"
destination => "http_response"
dictionary => {
"200" => "OK"
"403" => "Forbidden"
"404" => "Not Found"
"408" => "Request Timeout"
}
remove_field => "response_code"
}
}useragent filter
将用户agent字符串解析为字段。以下示例将代理字段中的用户agent字符串解析为用户代理字段,并将用户agent字段添加到名为user_agent的新字段。 它还删除了原始代理字段:
filter {
useragent {
source => "agent"
target => "user_agent"
remove_field => "agent"
}
}过滤器应用后,事件将丰富与用户agent fields。 例如:
"user_agent": {
"os": "Mac OS X 10.12",
"major": "50",
"minor": "0",
"os_minor": "12",
"os_major": "10",
"name": "Firefox",
"os_name": "Mac OS X",
"device": "Other"
}博文来自:www.51niux.com
2.5 拼接多个输入和输出插件
需要管理的信息通常来自多个不同的来源,并且用例可能需要多个目标来存储数据。 Logstash管道可以使用多个输入和输出插件来处理这些需求。在本节中,将创建一个Logstash管道,该管道从Twitter源和Filebeat客户端获取输入,然后将信息发送到Elasticsearch群集,并将信息直接写入文件。
从Twitter Feed中读取
要添加推文,请使用twitter输入插件(https://www.elastic.co/guide/en/logstash/6.0/plugins-inputs-twitter.html)。
将以下行添加到second-pipeline.conf文件的输入部分,用您的值替换此处显示的占位符值:
twitter {
consumer_key => "enter_your_consumer_key_here"
consumer_secret => "enter_your_secret_here"
keywords => ["cloud"]
oauth_token => "enter_your_access_token_here"
oauth_token_secret => "enter_your_access_token_secret_here"
}配置Filebeat将日志行发送到Logstash
正如在前面配置Filebeat以将日志行发送到Logstash时一样,Filebeat客户端是一个轻量级的资源友好的工具,它从服务器上的文件收集日志,并将这些日志转发到Logstash实例进行处理。安装Filebeat后,需要配置它。 打开位于Filebeat安装目录中的filebeat.yml文件,并用以下几行代替内容。 确保路径指向你的系统日志:
filebeat.prospectors: - type: log paths: - /var/log/*.log #Filebeat处理的文件或文件的绝对路径。 fields: type: syslog #type类型为rsylog output.logstash: hosts: ["localhost:5043"]
通过将以下行添加到second-pipeline.conf文件的输入部分,将Logstash实例配置为使用Filebeat输入插件:
beats {
port => "5043"
}将Logstash数据写入文件
可以配置Logstash管道将数据直接写入带有文件输出插件的文件。通过将以下行添加到second-pipeline.conf文件的输出部分,将Logstash实例配置为使用文件输出插件:
file {
path => "/path/to/target/file"
}写入多个Elasticsearch节点:
写入多个Elasticsearch节点可减轻给定Elasticsearch节点上的资源需求,并在特定节点不可用时提供冗余入口点。要将Logstash实例配置为写入多个Elasticsearch节点,请编辑second-pipeline.conf文件的输出节以读取:
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
}#在主机行中的Elasticsearch群集中使用三个非主节点的IP地址。 当hosts参数列出多个IP地址时,Logstash通过地址列表对请求进行负载平衡。 另外请注意,Elasticsearch的默认端口是9200,在上面的配置中可以省略。
测试管道
second-pipeline.conf示例:
input {
twitter {
consumer_key => "enter_your_consumer_key_here"
consumer_secret => "enter_your_secret_here"
keywords => ["cloud"]
oauth_token => "enter_your_access_token_here"
oauth_token_secret => "enter_your_access_token_secret_here"
}
beats {
port => "5043"
}
}
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
file {
path => "/path/to/target/file"
}
}#Logstash正在使用配置的Twitter Feed中的数据,从Filebeat接收数据,并将这些信息编入索引到Elasticsearch集群中的三个节点以及写入文件。在数据源机器上,使用以下命令运行Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"
Filebeat将尝试在端口5043上连接。在Logstash以一个活动的Beats插件开始之前,该端口上将不会有任何答案,因此你看到关于在该端口上无法连接的任何消息现在都是正常的。要验证你的配置,请运行以下命令:
bin/logstash -f second-pipeline.conf --config.test_and_exit
--config.test_and_exit选项解析您的配置文件并报告任何错误。 当配置文件通过配置测试时,使用以下命令启动Logstash:
bin/logstash -f second-pipeline.conf
使用grep实用程序在目标文件中搜索以验证信息是否存在:
grep syslog /path/to/target/file
运行Elasticsearch查询以在Elasticsearch集群中查找相同的信息:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=fields.type:syslog'
用YYYY.MM.DD格式的当前日期替换$DATE。要查看Twitter Feed中的数据,请尝试以下查询:
curl -XGET 'http://localhost:9200/logstash-$DATE/_search?pretty&q=client:iphone'
#同样,请记住用YYYY.MM.DD格式的当前日期替换$DATE。
三、启动使用多个配置文件
#直接进入主题用浅显的例子展示多配置文件的使用。
3.1 发现多配置文件启动的问题
配置测试文件:
# cat /tmp/test_input/1.log
1.log123 1/log231
# cat /tmp/test_input/2.log
2.log123
#mkdir /tmp/logstash/conf.d
# cat /tmp/logstash/conf.d/a.conf
input {
file {
path => "/tmp/test_input/1.log"
start_position => "beginning"
sincedb_path => "/tmp/1_progress"
}
}
output {
file{
path => "/tmp/test_output/1.log"
}
}# cat /tmp/logstash/conf.d/b.conf
input {
file {
path => "/tmp/test_input/2.log"
start_position => "beginning"
sincedb_path => "/tmp/2_progress"
}
}
output {
file{
path => "/tmp/test_output/2.log"
codec => line { format => "custom format: %{message}"}
}
}# /tmp/logstash/bin/logstash -f /tmp/logstash/conf.d/ #启动多配置文件,千万不要用/tmp/logstash/conf.d/*(会报错起不来)
# cat test_output/1.log #查看输出结果
{"path":"/tmp/test_input/2.log","@timestamp":"2017-11-11T10:55:26.856Z","host":"51niux.com","@version":"1","message":"2.log123"}
{"path":"/tmp/test_input/1.log","@timestamp":"2017-11-11T10:55:26.866Z","host":"51niux.com","@version":"1","message":"1.log123"}
{"path":"/tmp/test_input/1.log","@timestamp":"2017-11-11T10:55:26.901Z","host":"51niux.com","@version":"1","message":"1/log231"}# cat test_output/2.log
custom format: 1.log123 custom format: 1/log231 custom format: 2.log123
#发现问题了没有,两个配置文件产生的是同等量的数据,这说明logstash 在写入数据的时候,是将所有的配置文件合并在一起的,运行起来数据写入就会混乱。
博文来自:www.51niux.com
3.2 解决多配置文件数据混乱问题
#解决方法也很简单就是通过增加type字段,然后用if判断的方式来解决此问题。
# cat /tmp/logstash/conf.d/a.conf
input {
file {
path => "/tmp/test_input/1.log"
start_position => "beginning"
#sincedb_path => "/tmp/1_progress"
type => "1-log"
}
}
output {
if [type] == "1-log" {
file{
path => "/tmp/test_output/1.log"
}
}
#其实还存在一个问题,所以把else放到这里了,就算通过if判断生效了,比如该走2.log的生效的,如果这里又else,还会走下else的out,打开注释就可以看到效果
#else{
# stdout {
# #日志输出
# codec => json_lines
# }
#}
}# cat /tmp/logstash/conf.d/b.conf
input {
file {
path => "/tmp/test_input/2.log"
start_position => "beginning"
sincedb_path => "/tmp/2_progress"
type => "2-log"
}
}
output {
if [type] == "2-log" {
file{
path => "/tmp/test_output/2.log"
codec => line { format => "custom format: %{message}"}
}
}
}#重启logstash就可以看到效果了,这里就不截图了。
#但是这种type判断的方式是有问题的,是主要注意的,有可能你的event里本来就有type字段,然后又赋值一个,会出现一个type数组(追加而不是覆盖),这时就有两个问题:filter和output中的if判断失效;你的数据中的type字段被改乱了。
3.3 单实例多进程解决问题
错误的启动:
# /tmp/logstash/bin/logstash -f /tmp/logstash/conf.d/a.conf #先启动一个进程没啥问题
# /tmp/logstash/bin/logstash -f /tmp/logstash/conf.d/b.conf #再启动一个进程报错了启动不起来,下面是报错信息
[FATAL][logstash.runner ] Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the "path.data" setting. [FATAL][org.logstash.Logstash ] Logstash stopped processing because of an error: (SystemExit) exit org.jruby.exceptions.SystemExit: (SystemExit) exit
#上面提示也很明显因为已经有一个实例了不能启动另一个实例,如果一台机器要运行多个实例,必须更改"path.data"设置
正确的启动方式:
# /tmp/logstash/bin/logstash -f /tmp/logstash/conf.d/a.conf --path.data=/tmp/logdata/a/
# /tmp/logstash/bin/logstash -f /tmp/logstash/conf.d/b.conf --path.data=/tmp/logdata/b/
#这样就是让一些UUID啊包括一些记录目录区分开,可以看下/tmp/logdata/下面的目录结构。
#你再看下进程已经是两个进程了,既然是两个进程了肯定数据不会共享了,数据处理也就不会错乱了,多进程这也是一种经常使用的方式。
四、多pipeline的方式
4.1 单pipeline方式
#其实上面/tmp/logstash/bin/logstash -f /tmp/logstash/conf.d/就是单通道模式,所有的消息都在一个通道里面处理。
# vim /tmp/logstash/config/pipelines.yml #在底部添加下面两句话
- pipeline.id: my-pipeline_1 path.config: "/tmp/logstash/conf.d/*.conf"
# /tmp/logstash/bin/logstash 不用指定配置文件,这样启动依旧可以加载多配置文件,然后测试一下效果是一样的。
4.2 了解下pipeline配置文件参数解释
# cat /tmp/logstash/config/pipelines.yml #下面都为默认注释部分哈
#管道名称
pipeline.id: mylogs
#该管道使用的配置字符串
config.string: "input { generator {} } filter { sleep { time => 1 } } output { stdout { codec => dots } }"
#从哪里阅读配置文本的路径
path.config: "/etc/conf.d/logstash/myconfig.cfg"
#设置启动多少个线程执行 fliter 和 output;当 input 的内容出现堆积而 CPU 使用率还比较充足时,可以考虑增加该参数的大小;
pipeline.workers: 1 #实际上默认为CPU的数量
#设置单个工作线程在执行过滤器和输出之前收集的最大事件数,较大的批量大小通常更高效,但会增加内存开销。输出插件会将每个批处理作为一个输出单元。
pipeline.batch.size: 125
#设置 Logstash 管道的延迟时间,管道批处理延迟是 Logstash在当前管道工作线程中接收事件后等待新消息的最长时间(以毫秒为单位);简单来说,当 `pipeline.batch.size` 不满足时,会等待 `pipeline.batch.delay` 设置的时间,超时后便开始执行 filter 和 output 操作。
pipeline.batch.delay: 50
#启用持久队列(PQ),"memory"是基于内存,"persisted"是基于磁盘的持久化队列。默认是基于内存。
queue.type: memory
#If using queue.type: persisted, 页面数据文件大小。队列数据包括仅将数据文件分成页面的数据文件。 默认为64MB.
queue.page_capacity: 64mb
#If using queue.type: persisted, 队列中的未读事件的最大数量。 默认为0(无限制)
queue.max_events: 0
#If using queue.type: persisted,队列的总容量。默认为1024MB或1GB
queue.max_bytes: 1024mb
#If using queue.type: persisted, 强制执行检查点的最大数量,默认是1024,0为不限制
queue.checkpoint.acks: 1024
#If using queue.type: persisted, 强制执行检查点之前的最大数量的写入事件,默认是1024,0为不限制
queue.checkpoint.writes: 1024
#If using queue.type: persisted, 在头页面上强制一个检查点的时间间隔,默认是1000毫秒,0是不限制
queue.checkpoint.interval: 1000
#是否为此管道启动Dead Letter Queueing(死信队列DLQ),默认是禁用
dead_letter_queue.enable: false
#If using dead_letter_queue.enable: true,死信队列的最大大小。死信队列具有内置的文件轮换策略,用于管理队列的文件大小。当文件大小达到预配置阈值时,将自动创建新文件。
#默认情况下,每个死信队列的最大大小设置为1024mb。要更改此设置,请使用该dead_letter_queue.max_bytes选项。如果条目超过此设置会增加死信队列的大小,则会删除条目。
dead_letter_queue.max_bytes: 1024mb
#If using dead_letter_queue.enable: true,写入延迟的间隔,默认是5000毫秒。
dead_letter_queue.flush_interval: 5000
#If using dead_letter_queue.enable: true, 将存储数据文件的目录路径。default是path.data/dead_letter_queue
path.dead_letter_queue: "path/to/data/dead_letter_queue"死信队列(Dead Letter Queues)解释:
默认情况下,当Logstash遇到由于数据包含映射错误或其他问题而无法处理的事件时,Logstash管道会挂起或丢弃不成功的事件。为了防止在这种情况下丢失数据,可以配置Logstash将不成功的事件写入死信队列而不是丢弃它们。
写入死信队列的每个事件都包括原始事件,描述无法处理事件的原因的元数据,有关编写事件的插件的信息以及事件进入死信队列的时间戳。
要处理死信队列中的事件,只需创建一个Logstash管道配置,该配置使用dead_letter_queue输入插件从队列中读取。
input {
dead_letter_queue {
path => "/path/to/data/dead_letter_queue" #包含死信队列的顶级目录的路径。此目录包含写入死信队列的每个管道的单独文件夹。
commit_offsets => true #设置true时,保存偏移量。当管道重新启动时,它将继续从它停止的位置读取,而不是重新处理队列中的所有项目。
pipeline_id => "main" #写入死信队列的管道的ID。默认是"main"。
}
}
output {
stdout {
codec => rubydebug { metadata => true }
}
}4.3 多pipeline方式
# cat /tmp/logstash/config/pipelines.yml #通过多通道的配置,上面测试的两个配置文件就可以取消type判断了,就完全隔离开了。
- pipeline.id: test-01 pipeline.workers: 1 pipeline.batch.size: 1 path.config: "/tmp/logstash/conf.d/a.conf" - pipeline.id: test-02 queue.type: persisted path.config: "/tmp/logstash/conf.d/b.conf"
# /tmp/logstash/bin/logstash #启动测试一下,结果是可以实现的我就不截图了
#如果启动出现:No configuration found in the configured sources.这个报错,要么配置文件没有读权限,要么配置文件不存在,要么文件名写错了
博文来自:www.51niux.com
使用注意事项:
如果当前配置具有不共享相同inputs/filters和outputs的事件流,则使用多个管道尤其有用,并且使用tags 和条件彼此分隔。
单个实例中具有多个管道也允许这些事件流具有不同的性能和耐用性参数(例如,管道workers和持久队列的不同设置)。该分离意味着一个管道中的阻塞输出不会在另一个管道中发生回压。
也就是说,考虑到管道之间的资源竞争,鉴于单个管道调整默认值是很重要的。 因此,例如,考虑减少每个管道使用的管道worker的数量,因为每个管道将默认使用每个CPU内核的1个worker。
每条管道隔离持久队列和死信队列,其位置由pipeline.id命名。
五、运用mutate举个例子
mutate过滤器对字段进行一系列操作,后面也会经常用到,在这里举几个例子。官网简单翻译:http://blog.51niux.com/?id=217
5.1 split字段切割
Nginx测试样例:
# cat /tmp/test_input/test.log
192.168.14.50 - - [10/Dec/2017:20:10:26 +0800] "GET / HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36" "-"
# cat /tmp/logstash/conf.d/test.conf
input {
file {
path => "/tmp/test_input/test.log"
start_position => "beginning"
}
}
filter {
mutate{
split => ['message'," "]
add_field => ["msg", "%{message}"]
}
}
output {
stdout { codec => rubydebug }
}# /tmp/logstash/bin/logstash -f /tmp/logstash/conf.d/test.conf

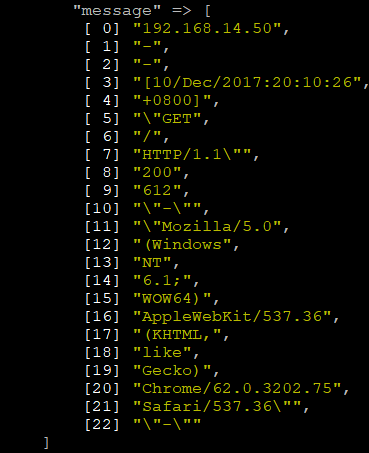
#可以看到message已经被截取成一个列表的形式了,那么如果日志格式统一的话我们是不是可以直接通过split获取我们想要的字段呢,不过切割日志还是不太合适的,你看日期那里就切割的不对带着[。
稍微修改一下切割出一些字段出来:
# cat /tmp/logstash/conf.d/test.conf
input {
file {
path => "/tmp/test_input/test.log"
start_position => "beginning"
}
}
filter {
mutate{
split => ['message'," "]
add_field => ["remote_addr", "%{[message][0]}"]
add_field => ["req_time", "%{[message][3]}"]
add_field => ["request_method", "%{[message][5]}"]
add_field => ["status", "%{[message][8]}"]
add_field => ["body_bytes_sent", "%{[message][9]}"]
remove_field => [message]
}
}
output {
stdout { codec => rubydebug }
}下面是输出效果:
{
"@version" => "1",
"request_method" => "\"GET",
"status" => "200",
"path" => "/tmp/test_input/test.log",
"remote_addr" => "192.168.14.50",
"req_time" => "[10/Dec/2017:20:10:26",
"body_bytes_sent" => "612"
}注意:
如果用的是["remote_addr", "%{message[0]}"],就会出现报错:logstash split Exception caught while applying mutate filter {:exception=>"Invalid FieldReference: `message[0]`"},然后add_field不成功。
5.2 gsub替换字段
# cat /tmp/logstash/conf.d/test.conf
input {
file {
path => "/tmp/test_input/test.log"
start_position => "beginning"
}
}
filter {
mutate{
split => ['message'," "]
add_field => ["remote_addr", "%{[message][0]}"]
add_field => ["req_time", "%{[message][3]}"]
add_field => ["request_method", "%{[message][5]}"]
add_field => ["status", "%{[message][8]}"]
add_field => ["body_bytes_sent", "%{[message][9]}"]
remove_field => [message]
}
mutate{ #另起一个mutate,不然gsub跟上面的放到一起不生效,gsub只能替换string类型
gsub => ["req_time","\[",""]
gsub => ["request_method","\"",""]
}
}
output {
stdout { codec => rubydebug }
}下面是结果:
{
"body_bytes_sent" => "612",
"@version" => "1",
"status" => "200",
"remote_addr" => "192.168.14.50",
"path" => "/tmp/test_input/test.log",
"request_method" => "GET",
"req_time" => "10/Dec/2017:20:10:26"
}#从结果可以看到已经去掉了一些特殊的标识符,如method的/和req_time的[。
#先要了解es的mapping:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html
#另外有精力的话也可以了解下logstash的自定义模板,以后在生产场景中会用到。
#logstash-input-jdbc可以实现把mysql中的数据导入到es中,比如我们可以将zabbix的报警信息从mysql数据库中导入到es中用于出图。
5.3 使用logstash做关键字报警
#另外我们也可以把我们的错误日志啥的都收集到kafka中,然后利用logstash去消费kafka,然后查看message里面有没有我们指定的关键字,如果有的话就记录下来然后有个程序读取到产生的报错信息日志,然后以固定格式转发出去,下面是个小样例:
input {
kafka {
bootstrap_servers => "192.168.1.101:9092,192.168.1.102:9092,192.168.1.103:9092"
topics => ["k8s-error-log"]
consumer_threads => 24
group_id => "k8s-error-log"
auto_offset_reset => "latest"
}
}
filter {
json {
source => "message"
}
if "Error" in [message] or "Exception" in [message] {
mutate {
add_tag => [ "ERR" ]
}
}
}
output {
if "ERR" in [tags] {
file {
path => "/tmp/logerr_%{+YYYY-MM-dd}.txt"
codec => line {
format => "%{[agent][name]} %{[log][file][path]} %{message}"
}
}
}
}